1. 表的增删改查(CRUD)
CRUD 是数据库操作的核心,分别对应:
-
C:Create(创建/插入)。
-
R:Retrieve(查询/读取)。
-
U:Update(更新/修改)。
-
D:Delete(删除)。
2.表的 Create
2.1 基本语法
sql
INSERT [INTO] table_name [(column1, column2, ...)] VALUES (value1, value2, ...);案例:创建一张学生表
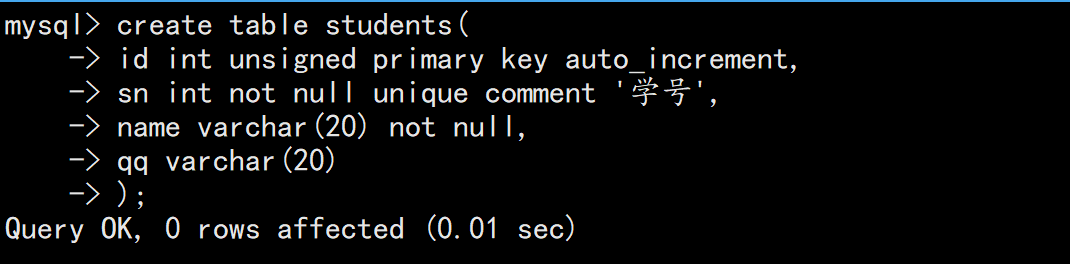
2.2 单行全列插入
sql
INSERT INTO students VALUES (100, 10000, '唐三藏', NULL);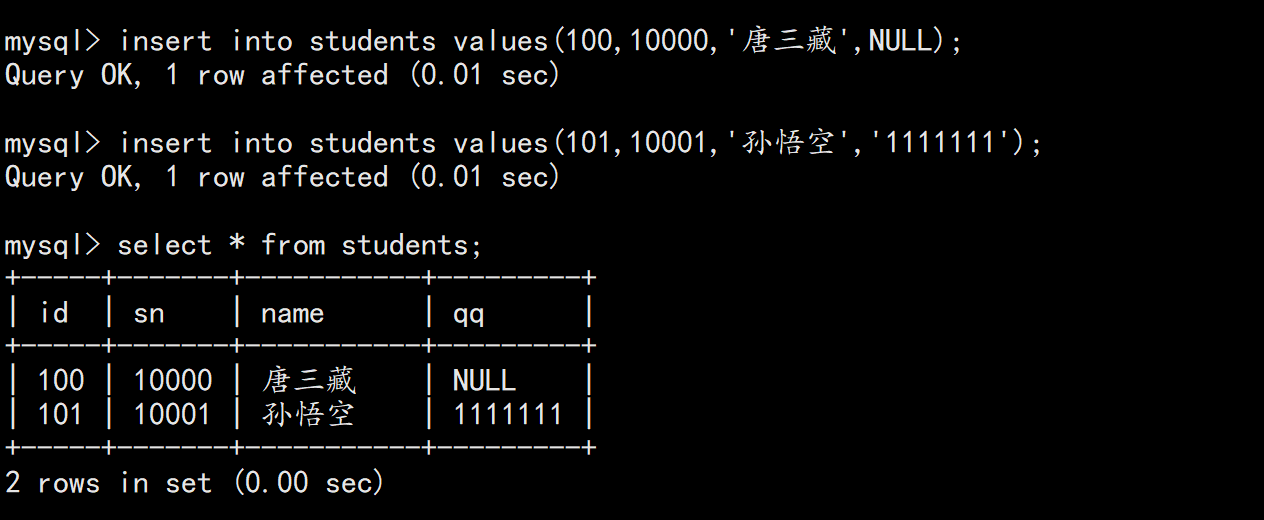
2.3 多行指定列插入
sql
INSERT INTO students (sn, name) VALUES (20001, '曹孟德'), (20002, '孙仲谋');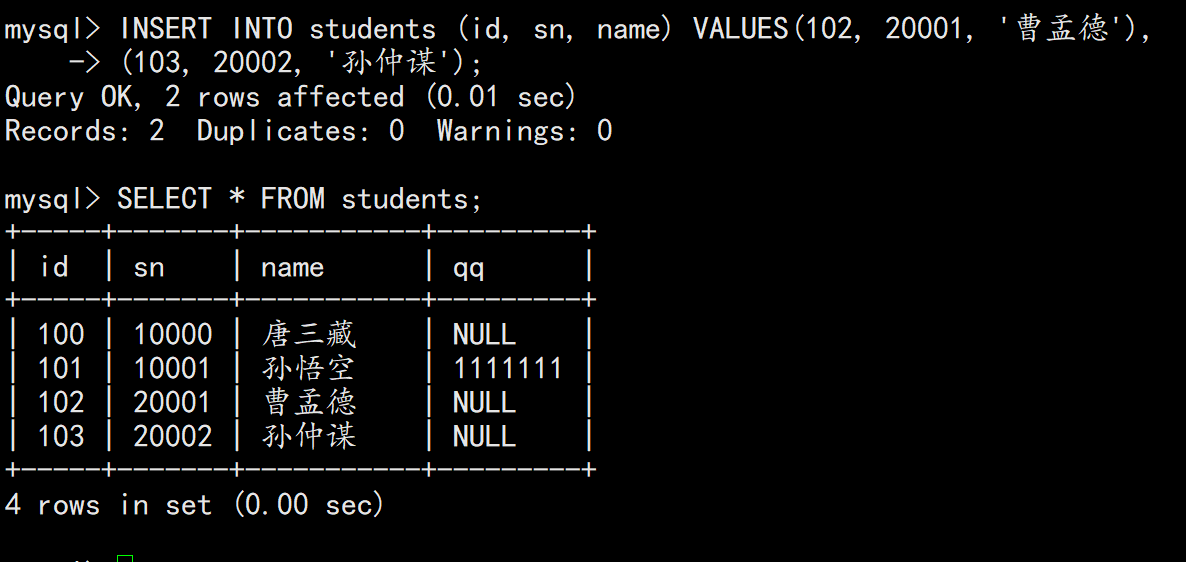
2.4 插入否则更新(ON DUPLICATE KEY UPDATE)
sql
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...当主键或唯一键冲突时,更新数据:
sql
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师')
ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';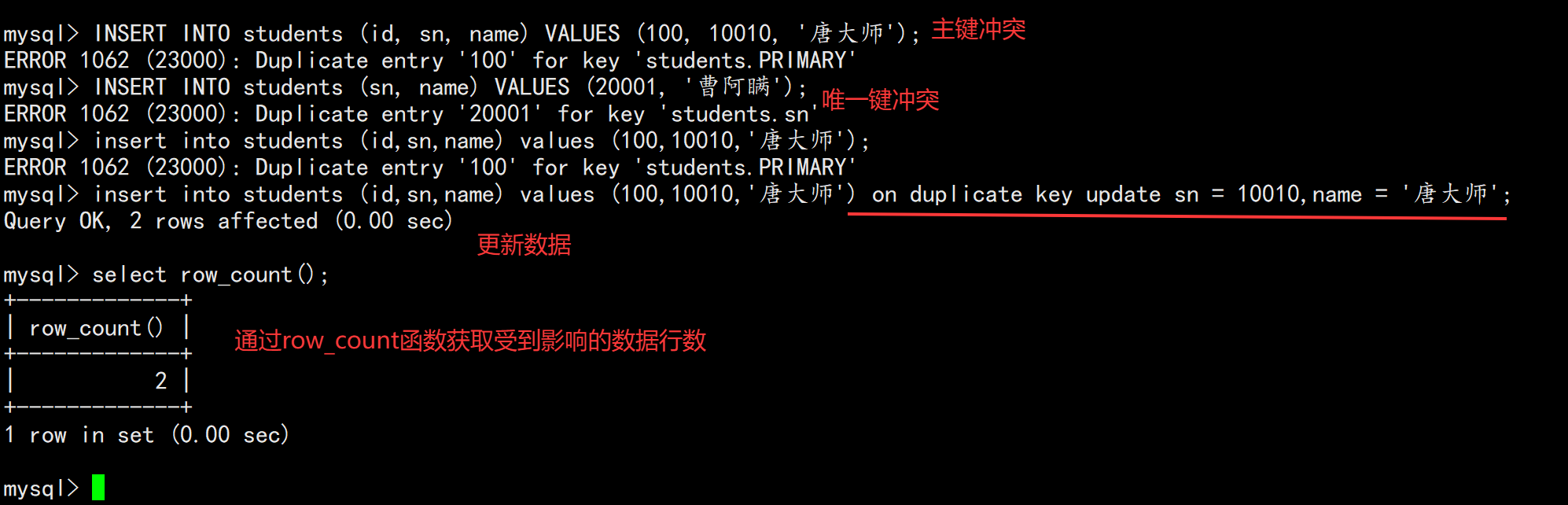
2.5 替换(REPLACE)
-
无冲突:直接插入。
-
有冲突:删除原记录,再插入新记录。
sql
REPLACE INTO students (sn, name) VALUES (20001, '曹阿瞒');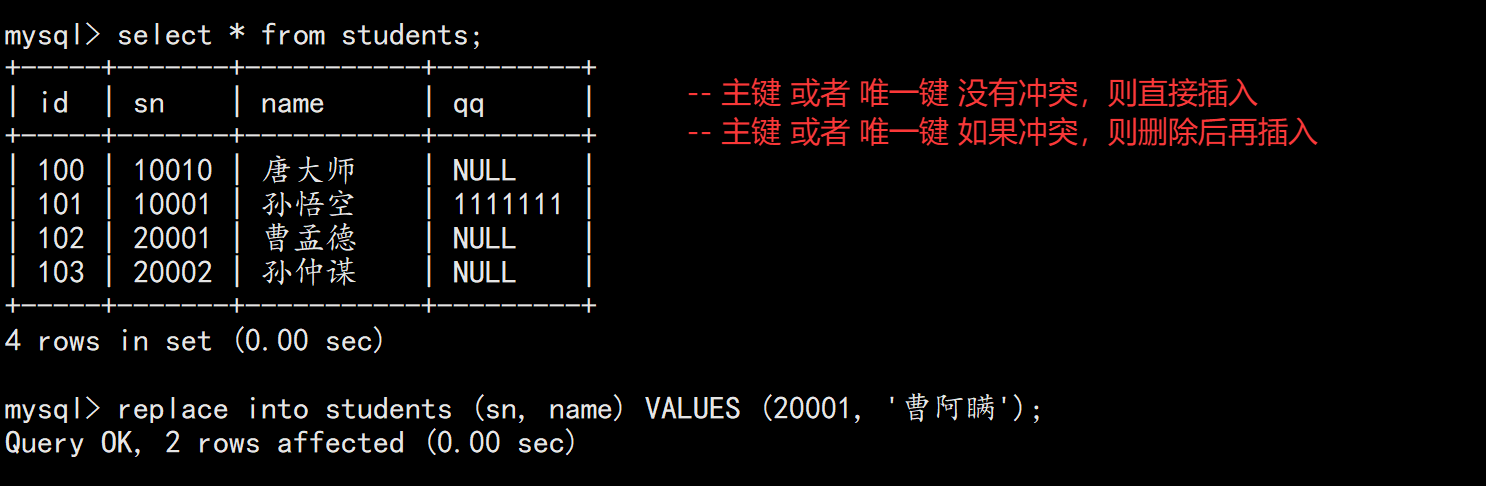
3. 查询数据(Retrieve)
3.1 基本语法
sql
SELECT [DISTINCT] column1, column2, ... FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...];案例:
3.2 查询示例
全列查询
sql
SELECT * FROM exam_result;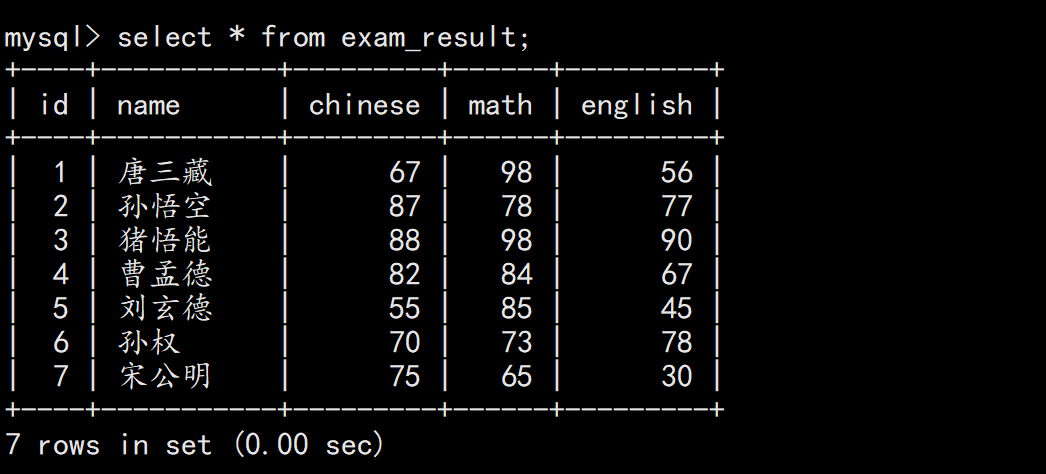
不建议频繁使用 *,查询的列越多,意味着需要传输的数据量越大 , 可能会影响到索引的使用 , 当表中数据量很大的时候会影响性能。
指定列查询
sql
SELECT name, english FROM exam_result;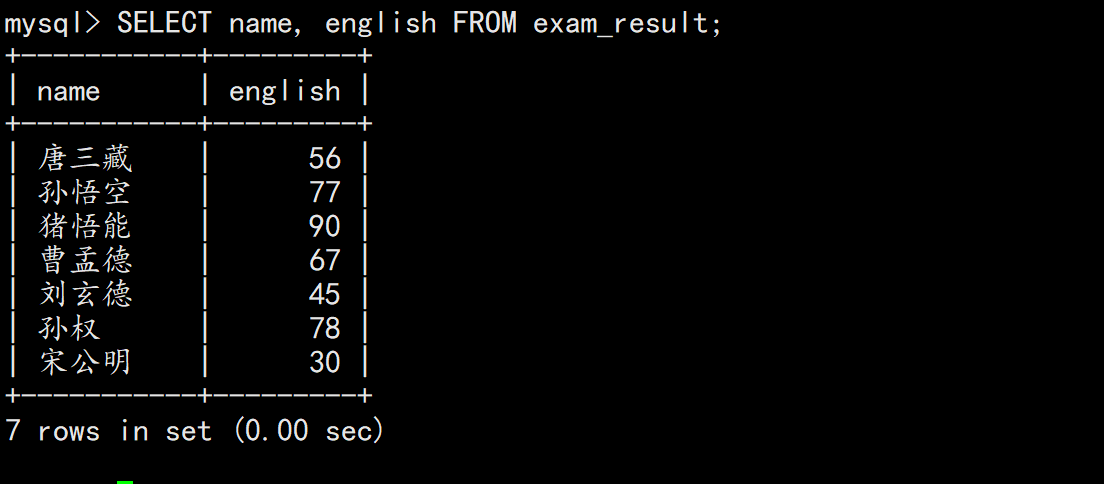
使用表达式
sql
SELECT name, chinese + math + english FROM exam_result;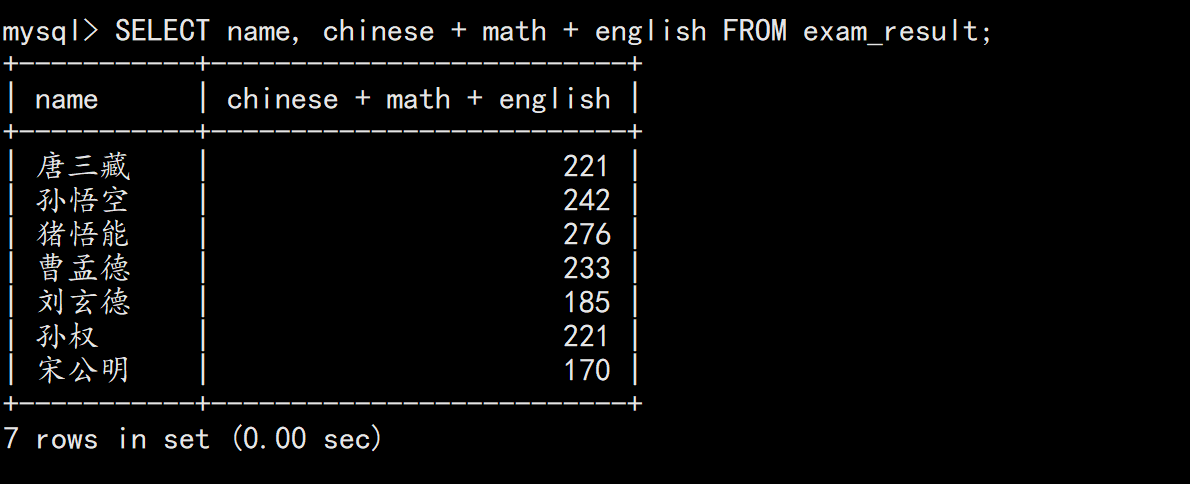
使用别名 (as)
sql
SELECT name, chinese + math + english AS 总分 FROM exam_result;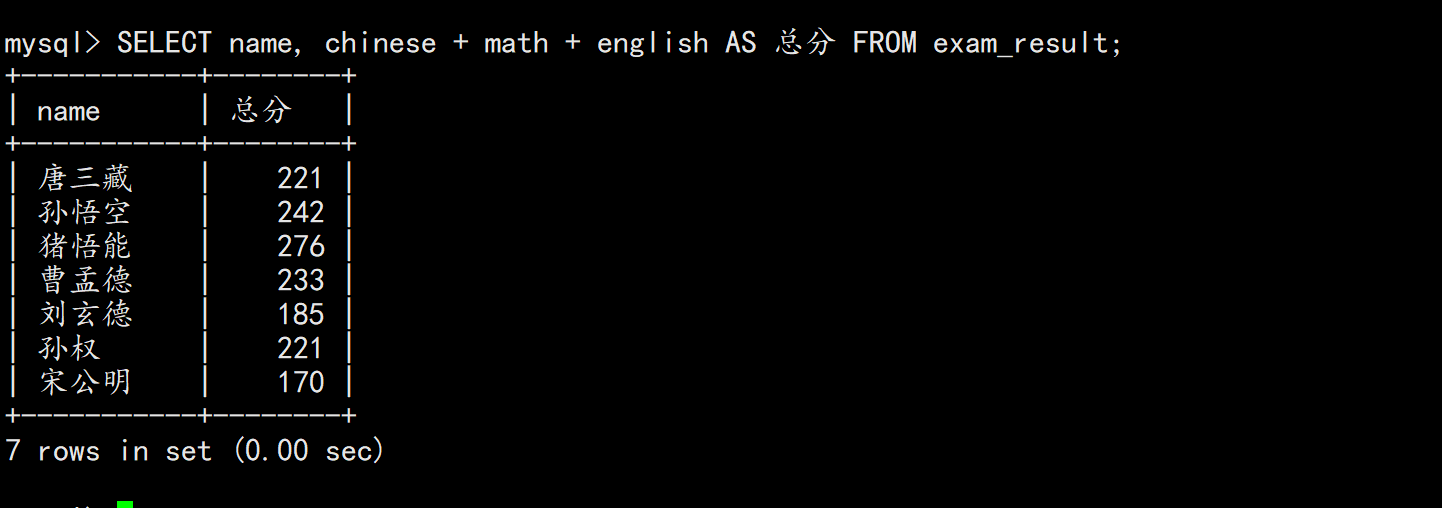
去重查询 (distinct)
sql
SELECT DISTINCT math FROM exam_result;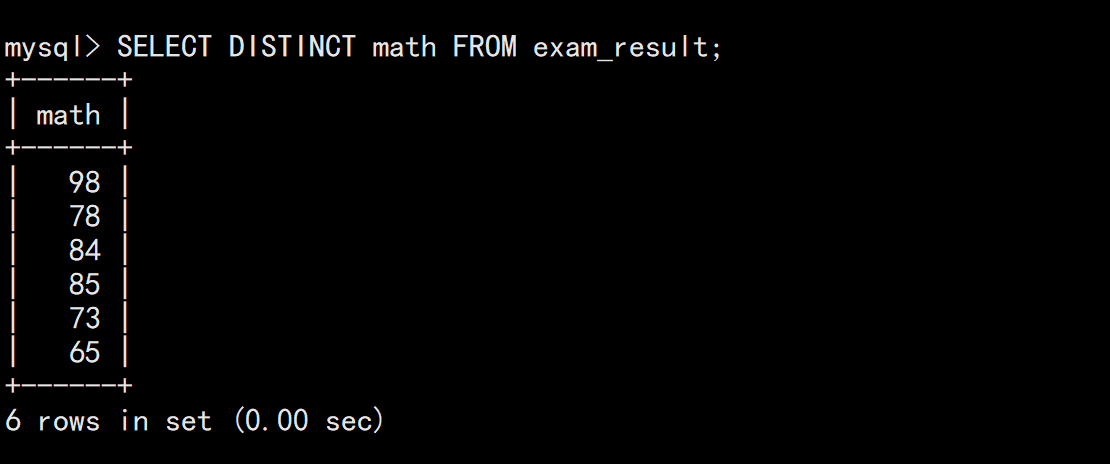
4. 条件查询(WHERE)
4.1 常用运算符
| 运算符 | 说明 |
|---|---|
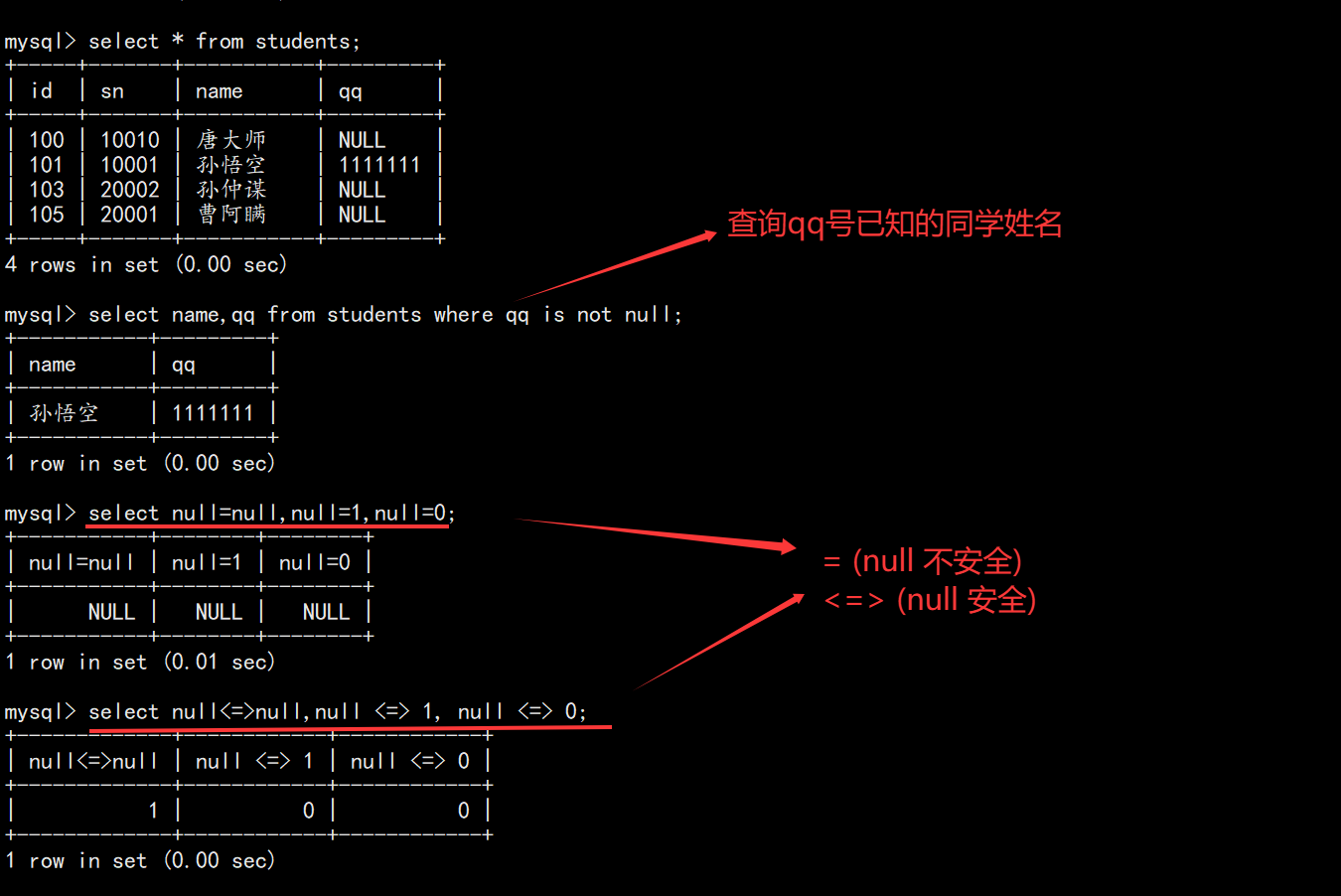
= |
等于(NULL 不安全) |
<=> |
等于(NULL 安全) |
!= 或 <> |
不等于 |
BETWEEN ... AND ... |
范围匹配 |
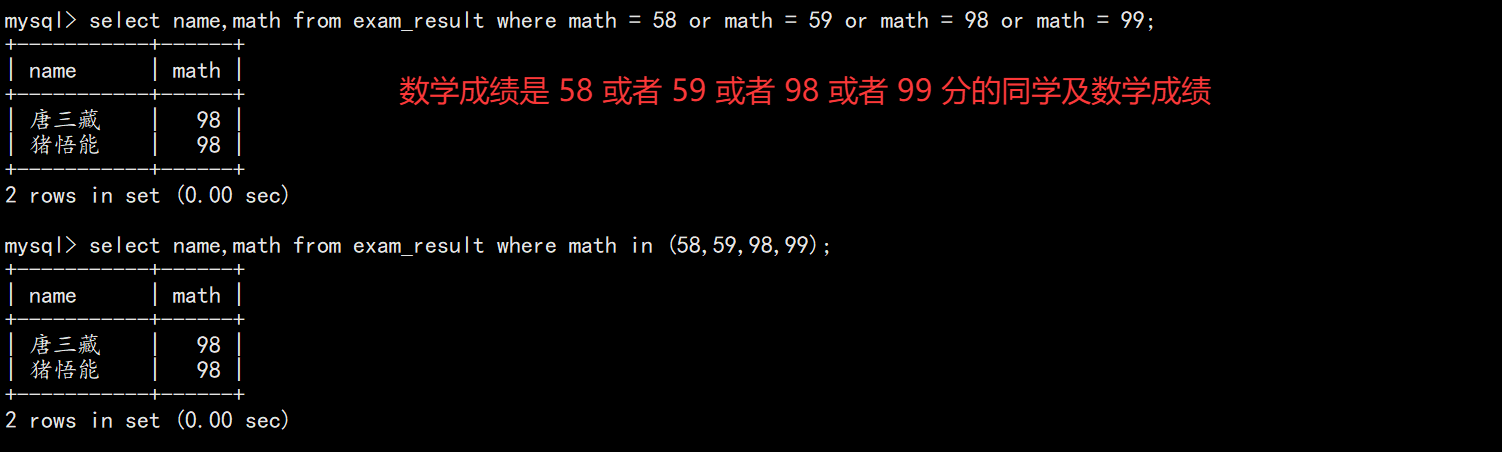
IN (...) |
匹配集合中的值 |
LIKE |
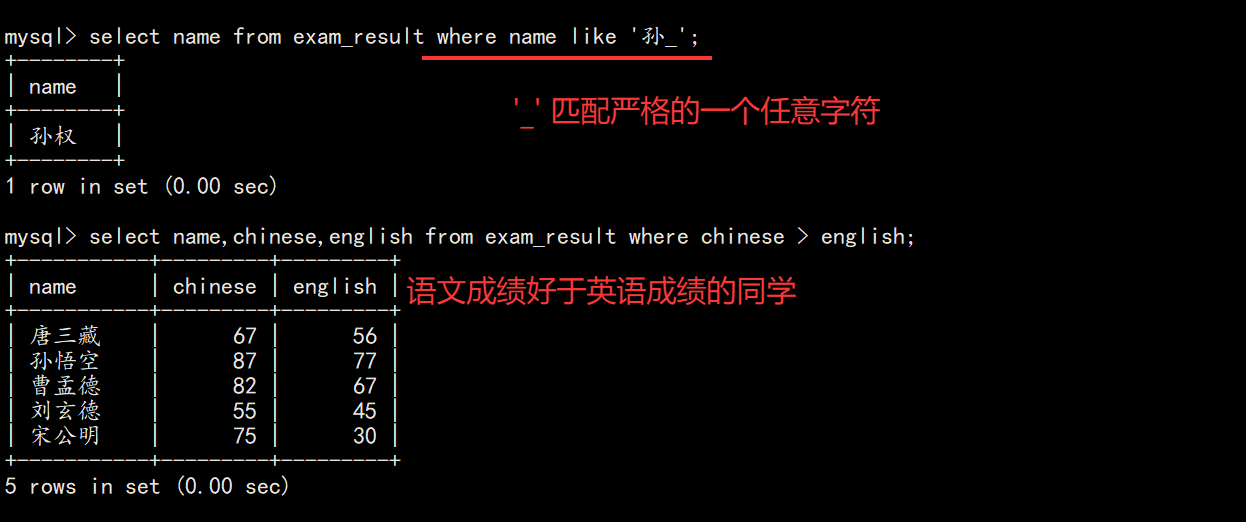
模糊匹配(% 多个字符,_ 一个字符) |
IS NULL / IS NOT NULL |
判断是否为空 |
4.2 示例
sql
-- 英语不及格
SELECT name, english FROM exam_result WHERE english < 60;
-- 语文在 80~90 之间
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;
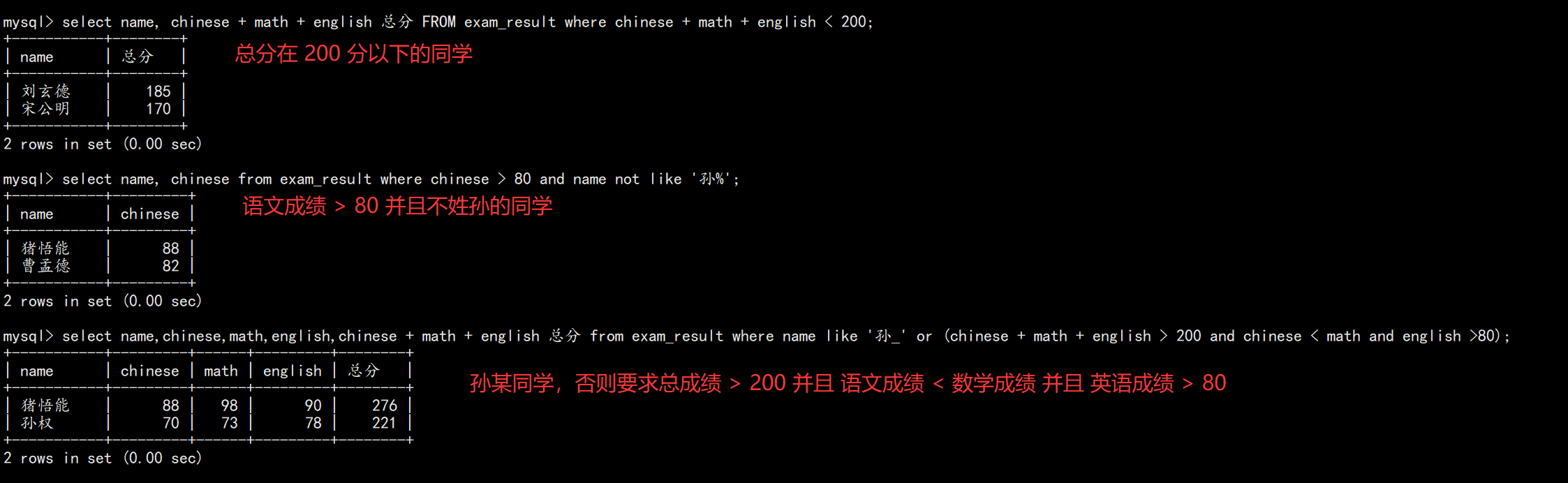
-- 姓孙的同学
SELECT name FROM exam_result WHERE name LIKE '孙%';
-- 语文高于英语
SELECT name, chinese, english FROM exam_result WHERE chinese > english;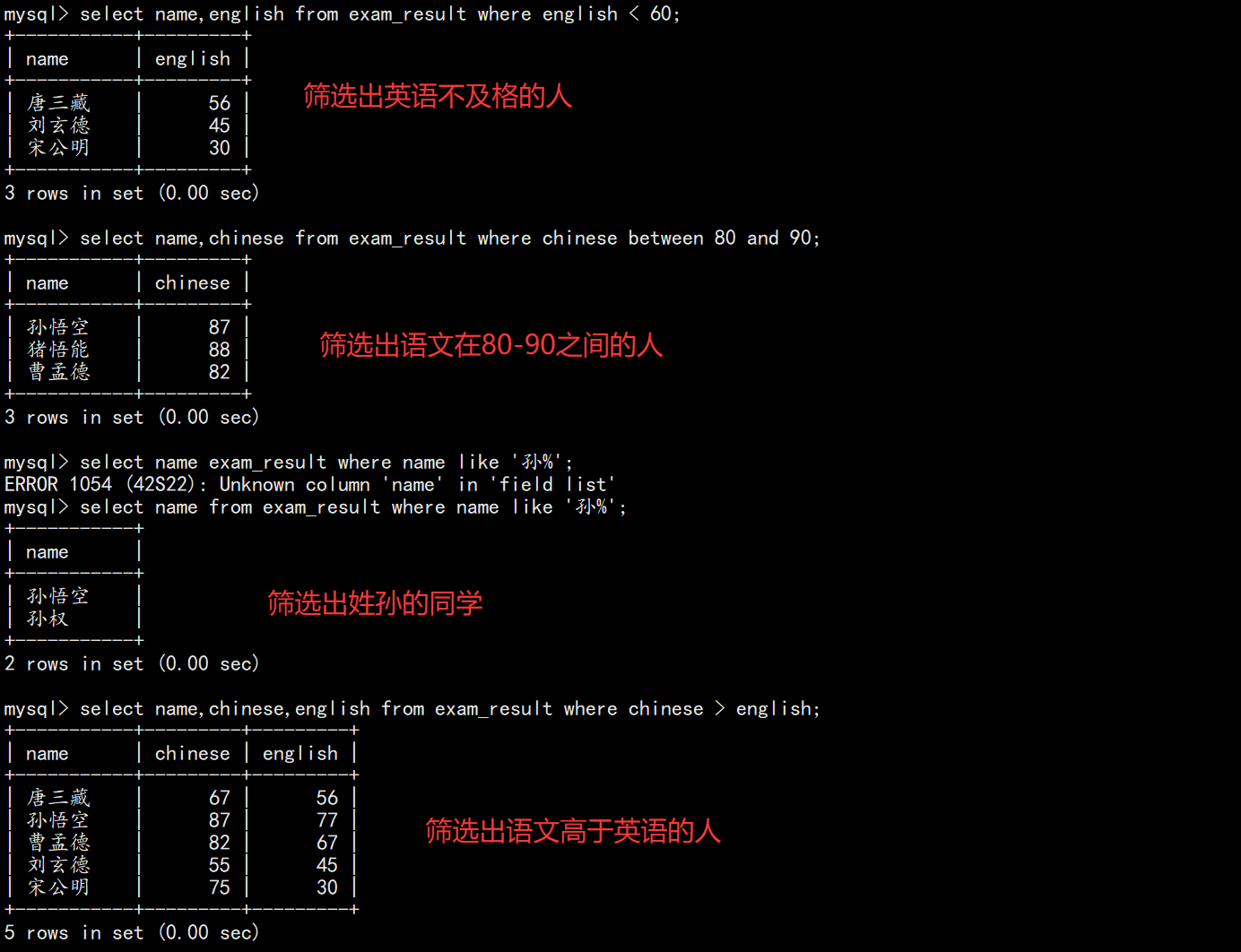
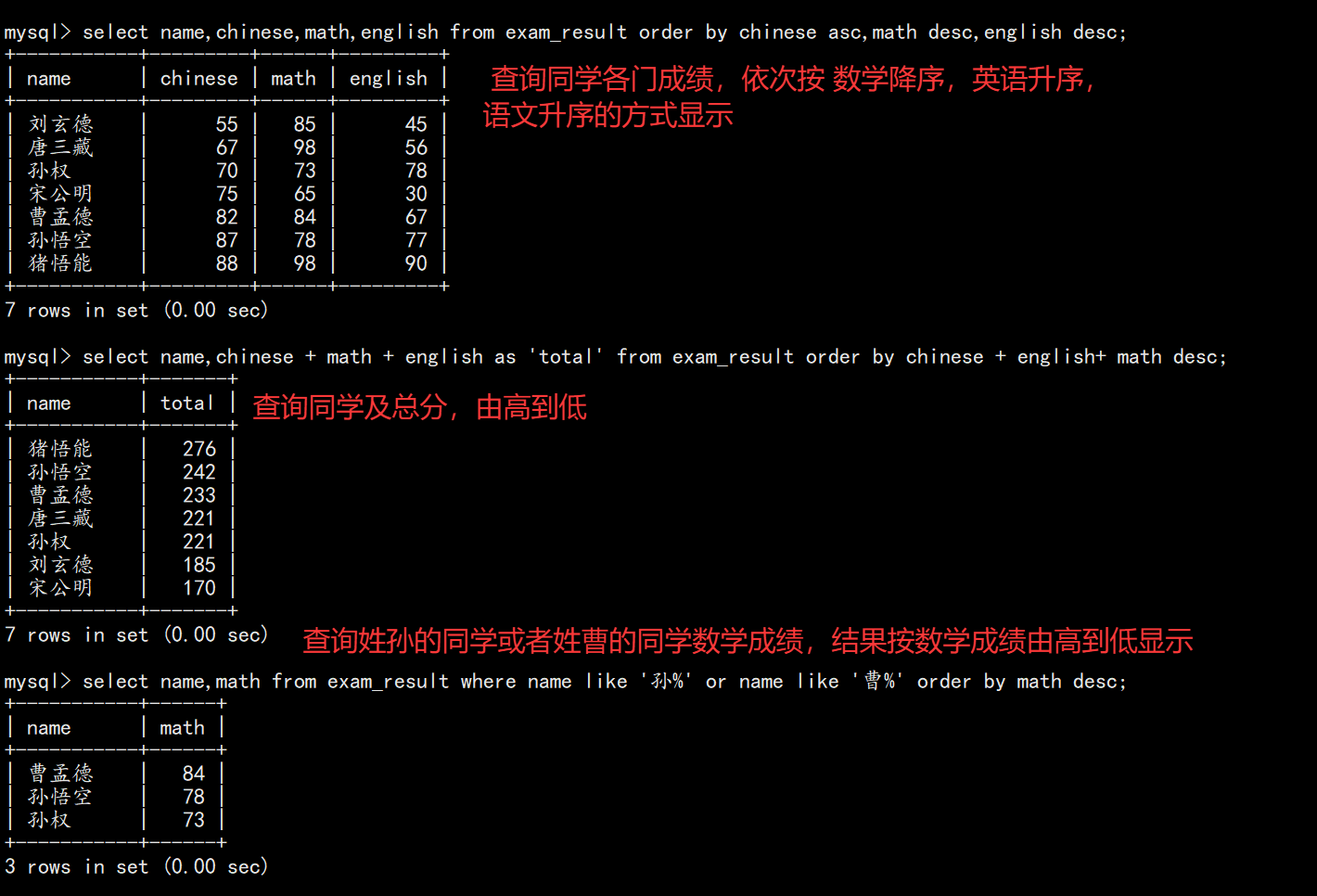
5. 排序(ORDER BY)
5.1 基本语法
sql
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...];
sql
-- 按数学升序
SELECT name, math FROM exam_result ORDER BY math;
-- 按总分降序
SELECT name, chinese + math + english AS 总分 FROM exam_result ORDER BY 总分 DESC;
-- 多字段排序
SELECT name, math, english, chinese FROM exam_result ORDER BY math DESC, english ASC;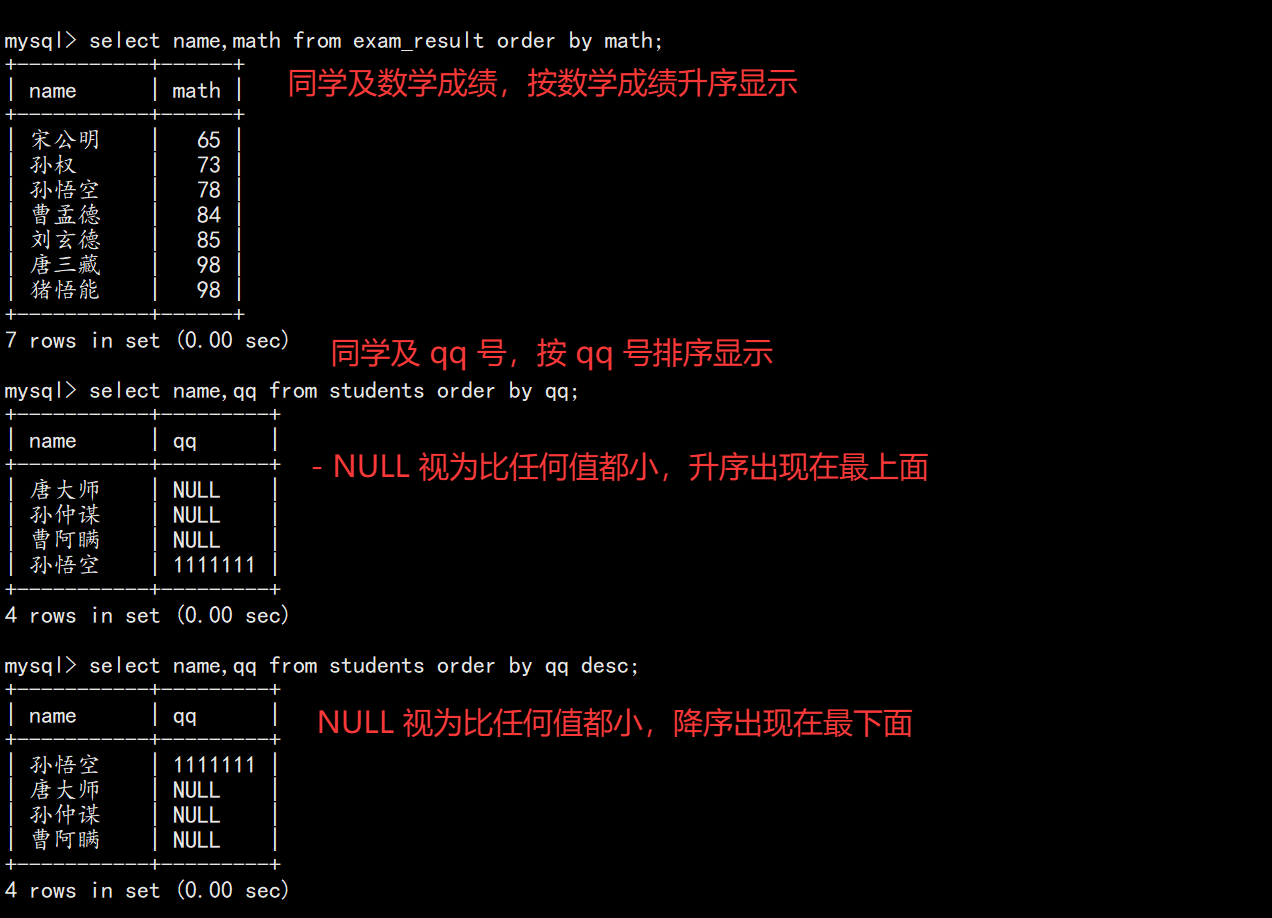
6. 分页查询(LIMIT)
6.1 语法
sql
LIMIT n; -- 前 n 条
LIMIT s, n; -- 从 s 开始取 n 条
LIMIT n OFFSET s; -- 同上,更推荐
sql
-- 第1页,每页3条
SELECT id, name FROM exam_result ORDER BY id LIMIT 3 OFFSET 0;
-- 第2页
SELECT id, name FROM exam_result ORDER BY id LIMIT 3 OFFSET 3;建议:对未知表进行查询时,最好加一条 LIMIT 1 ,避免因为表中数据过大,查询全表数据导致数据库卡死。
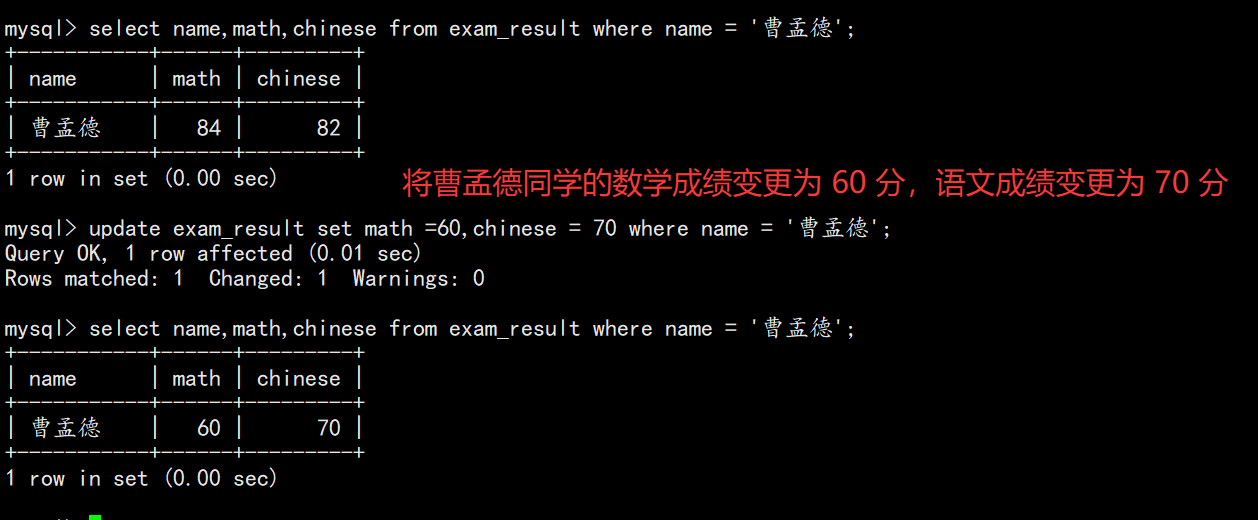
sql
-- 修改单列
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
-- 修改多列
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
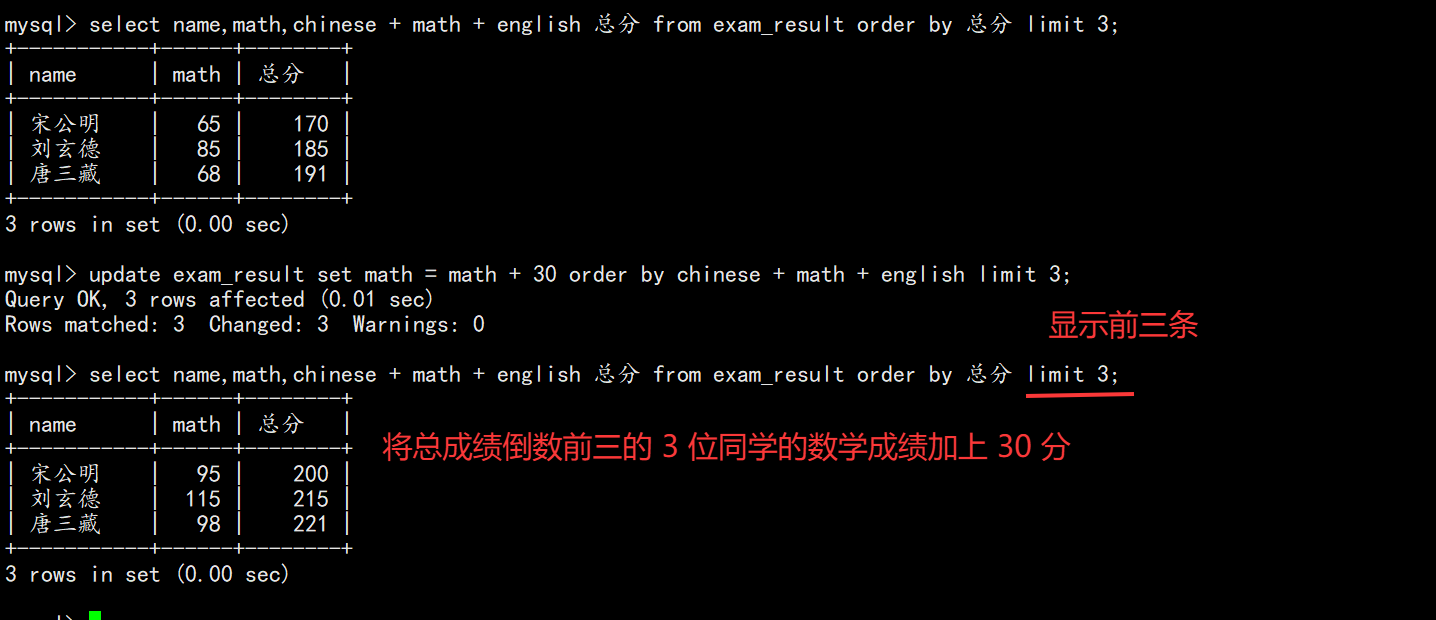
-- 使用原值计算
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT 3;
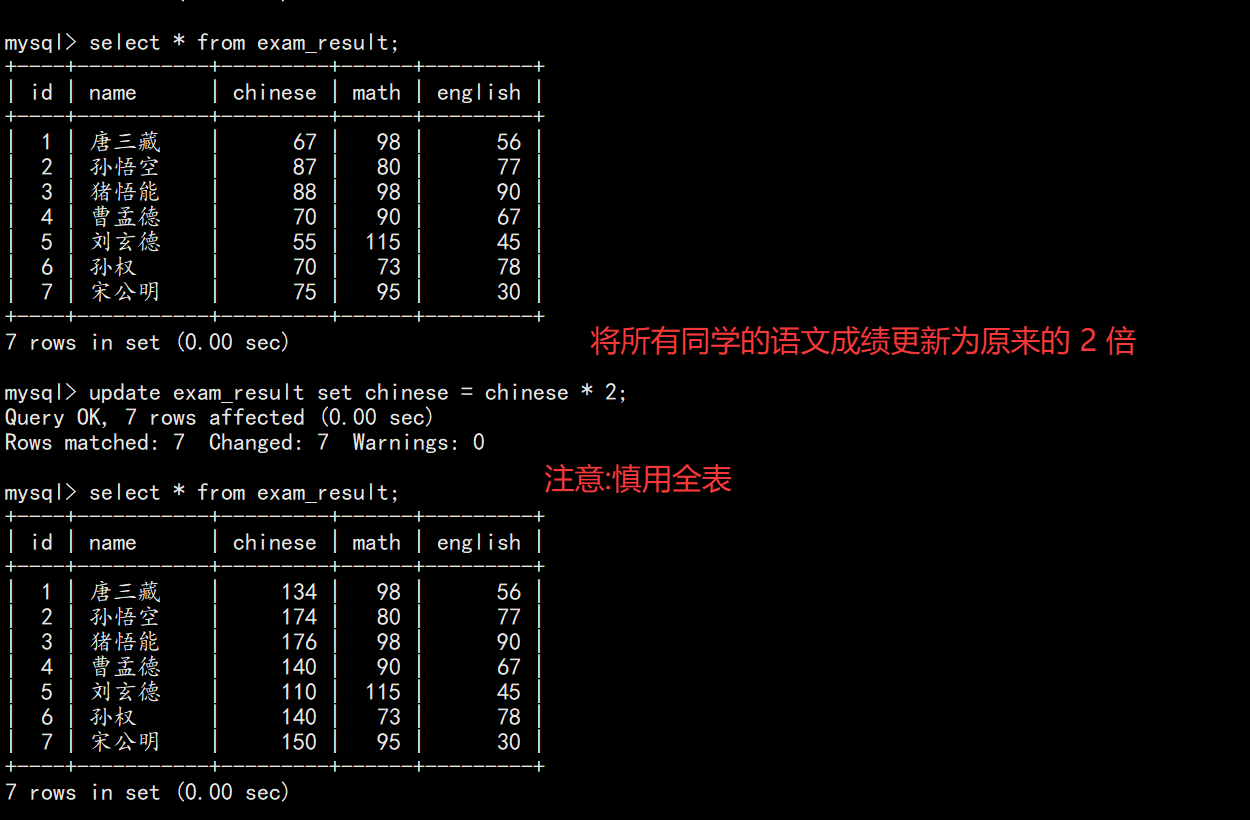
-- 更新全表(慎用)
UPDATE exam_result SET chinese = chinese * 2;7. 更新数据(Update)
对查询到的结果进行列值更新。
7.1 基本语法
sql
UPDATE table_name SET column1 = value1, column2 = value2 WHERE ...;7.2 示例
sql
-- 修改单列
UPDATE exam_result SET math = 80 WHERE name = '孙悟空';
-- 修改多列
UPDATE exam_result SET math = 60, chinese = 70 WHERE name = '曹孟德';
-- 使用原值计算
UPDATE exam_result SET math = math + 30 ORDER BY chinese + math + english LIMIT 3;
-- 更新全表(慎用)
UPDATE exam_result SET chinese = chinese * 2;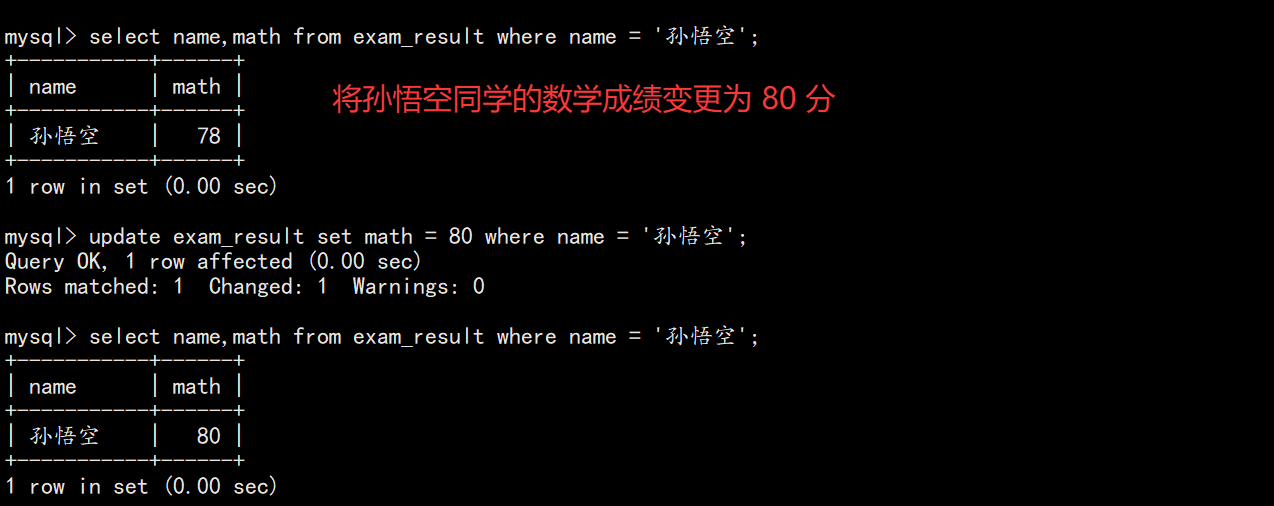
8. 删除数据(Delete)
8.1 基本语法
sql
DELETE FROM table_name WHERE ...;8.2 示例
sql
-- 删除指定记录
DELETE FROM exam_result WHERE name = '孙悟空';
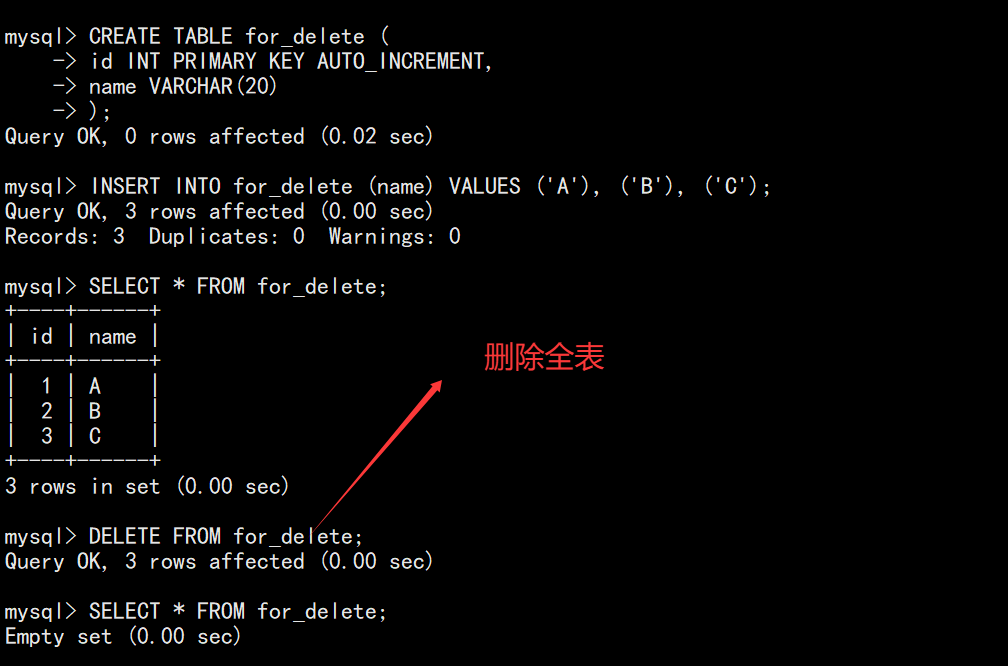
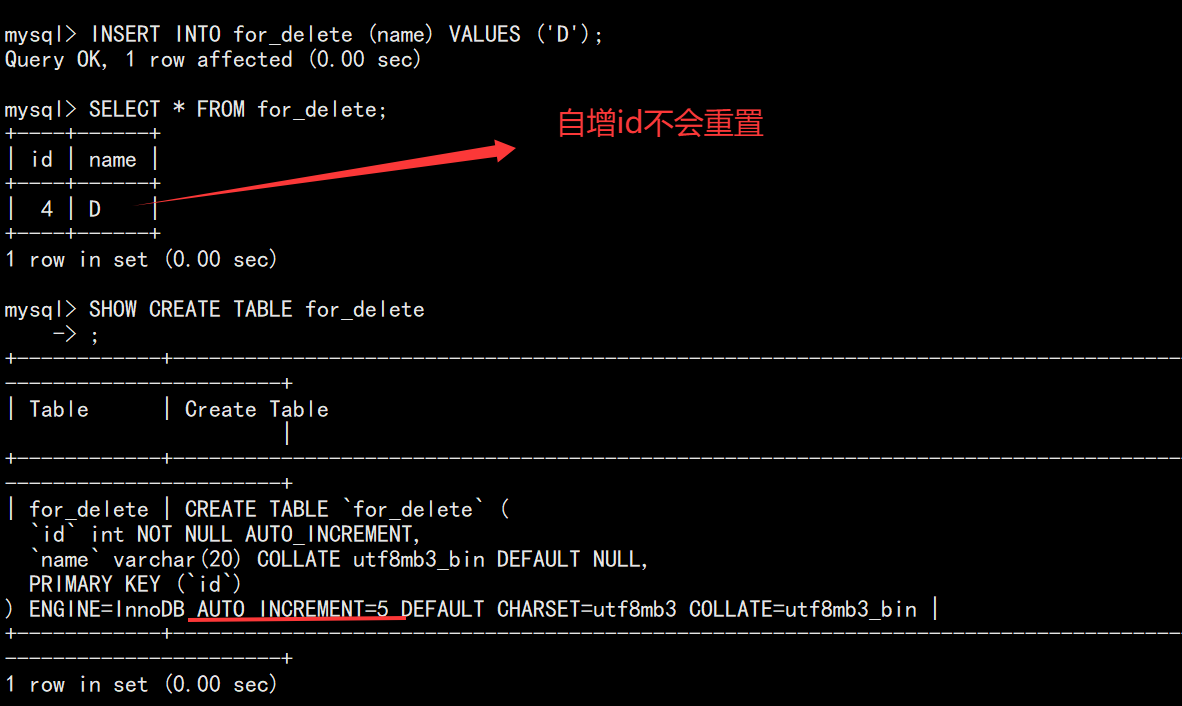
-- 删除全表数据(自增ID不会重置)
DELETE FROM for_delete;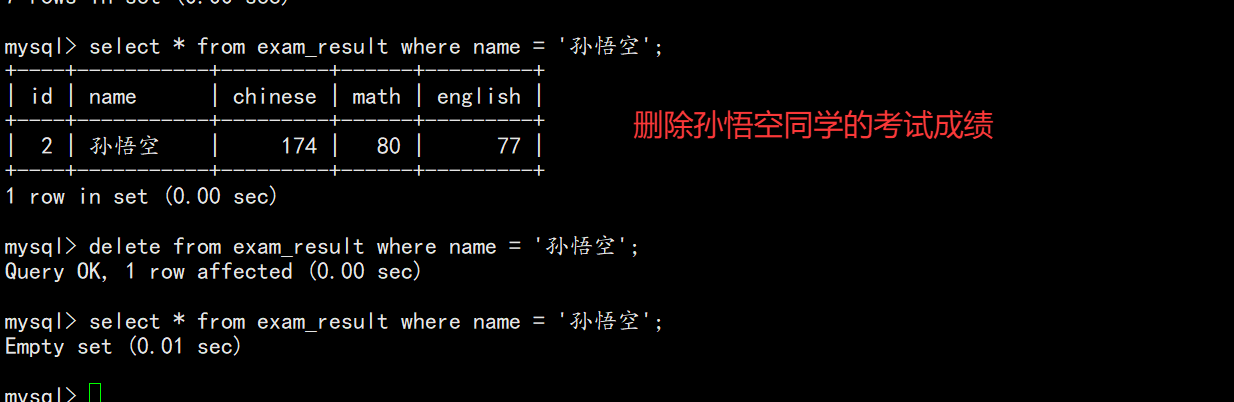
9. 截断表(TRUNCATE)
9.1 特点
-
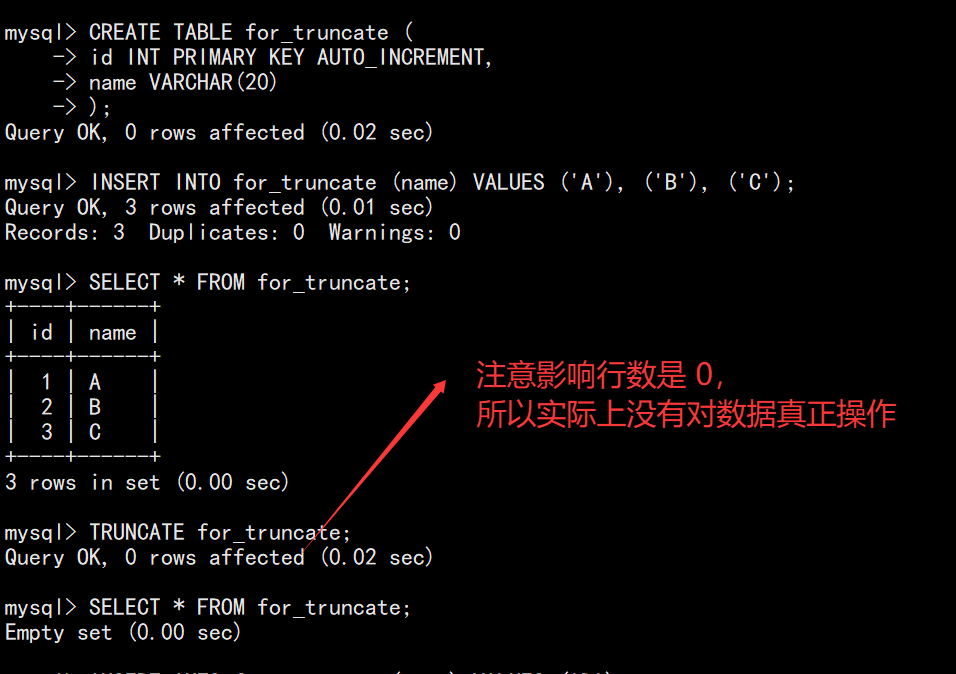
删除全表数据。(只能对整表操作,不能像 DELETE 一样针对部分数据操作)
-
速度快。
-
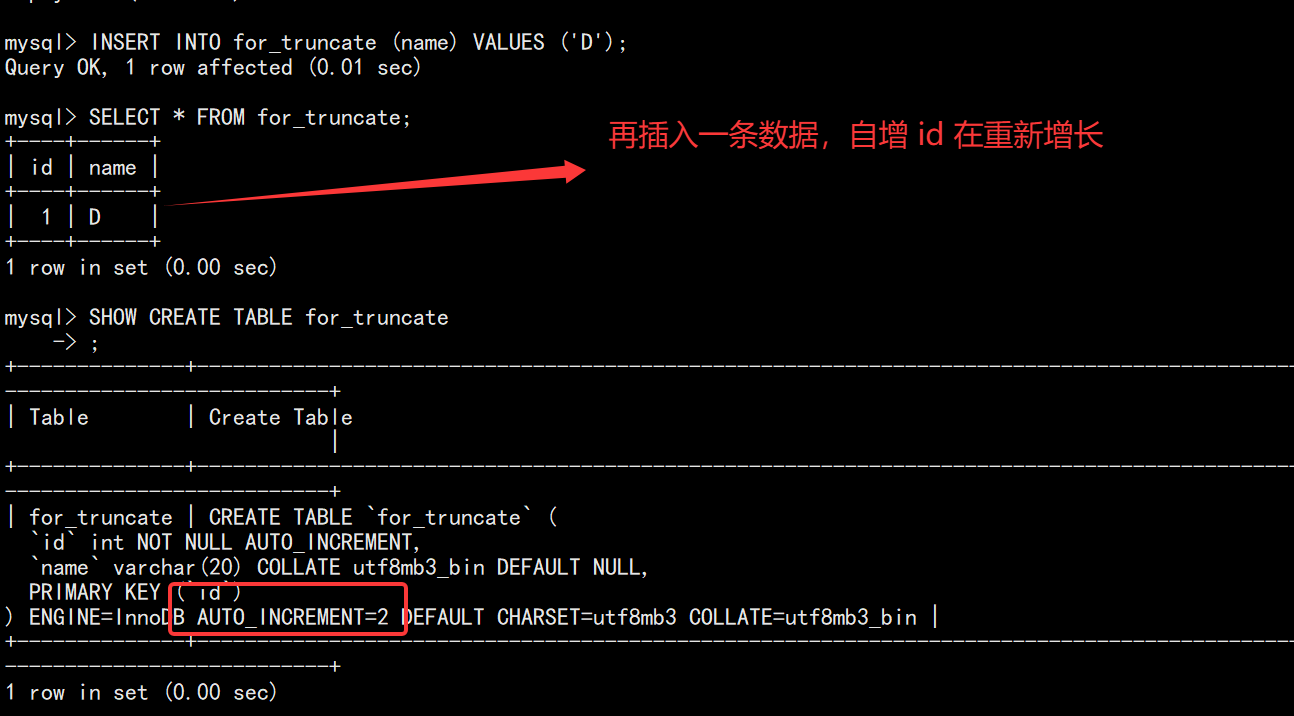
自增ID重置。
-
无法回滚。( 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事务,所以无法回滚 )
10. 插入查询结果
10.1 语法
sql
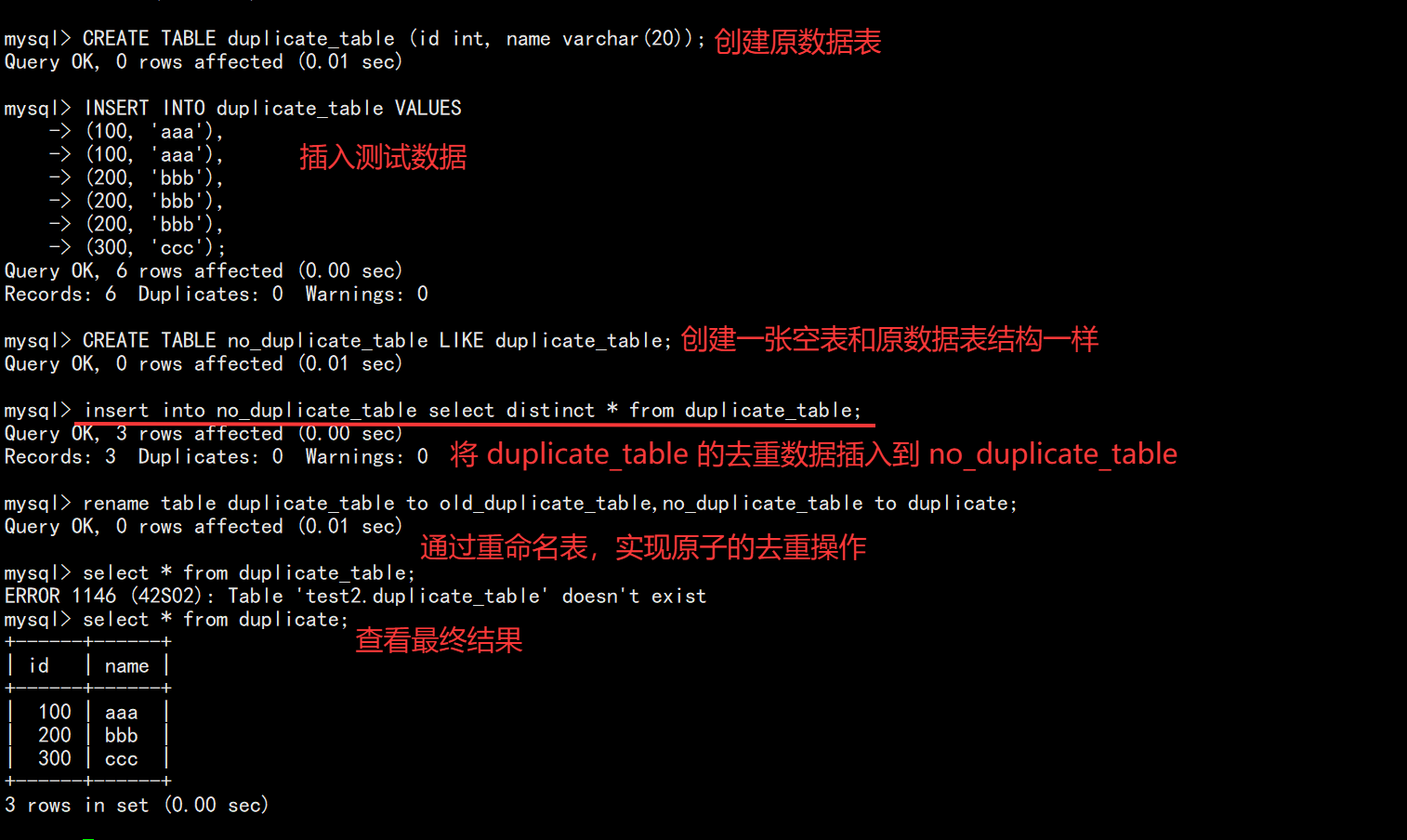
INSERT INTO table_name SELECT ...;10.2 示例:去重插入
sql
CREATE TABLE no_duplicate_table LIKE duplicate_table;
INSERT INTO no_duplicate_table SELECT DISTINCT * FROM duplicate_table;
RENAME TABLE duplicate_table TO old, no_duplicate_table TO duplicate_table;案例:删除表中的的重复复记录,重复的数据只能有一份
11. 聚合函数
| 函数 | 说明 |
|---|---|
COUNT() |
统计行数 |
SUM() |
求和 |
AVG() |
平均值 |
MAX() |
最大值 |
MIN() |
最小值 |
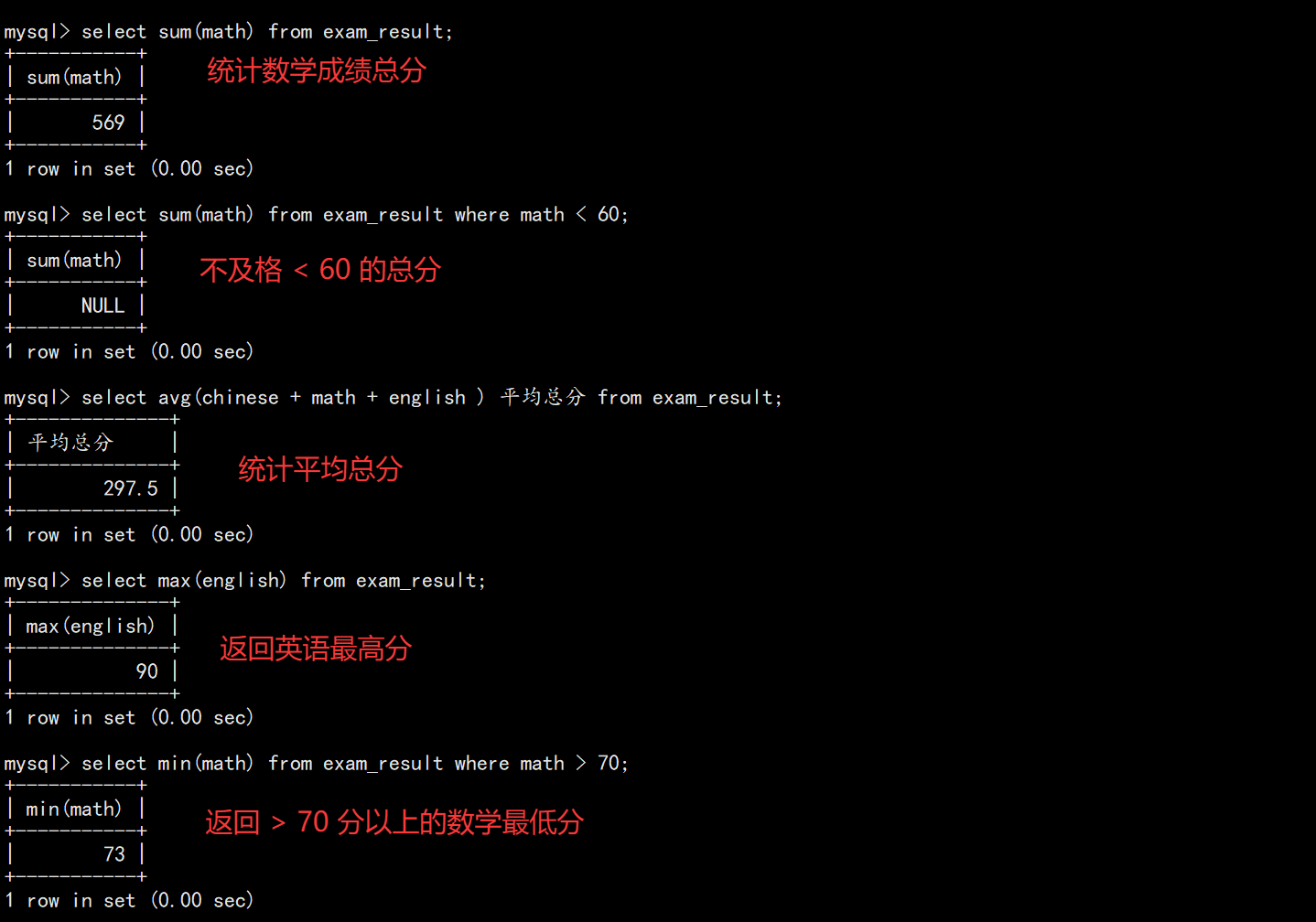
sql
SELECT COUNT(*) FROM students;
SELECT COUNT(qq) FROM students; -- NULL 不计入
SELECT AVG(chinese + math + english) FROM exam_result;
SELECT MAX(english) FROM exam_result;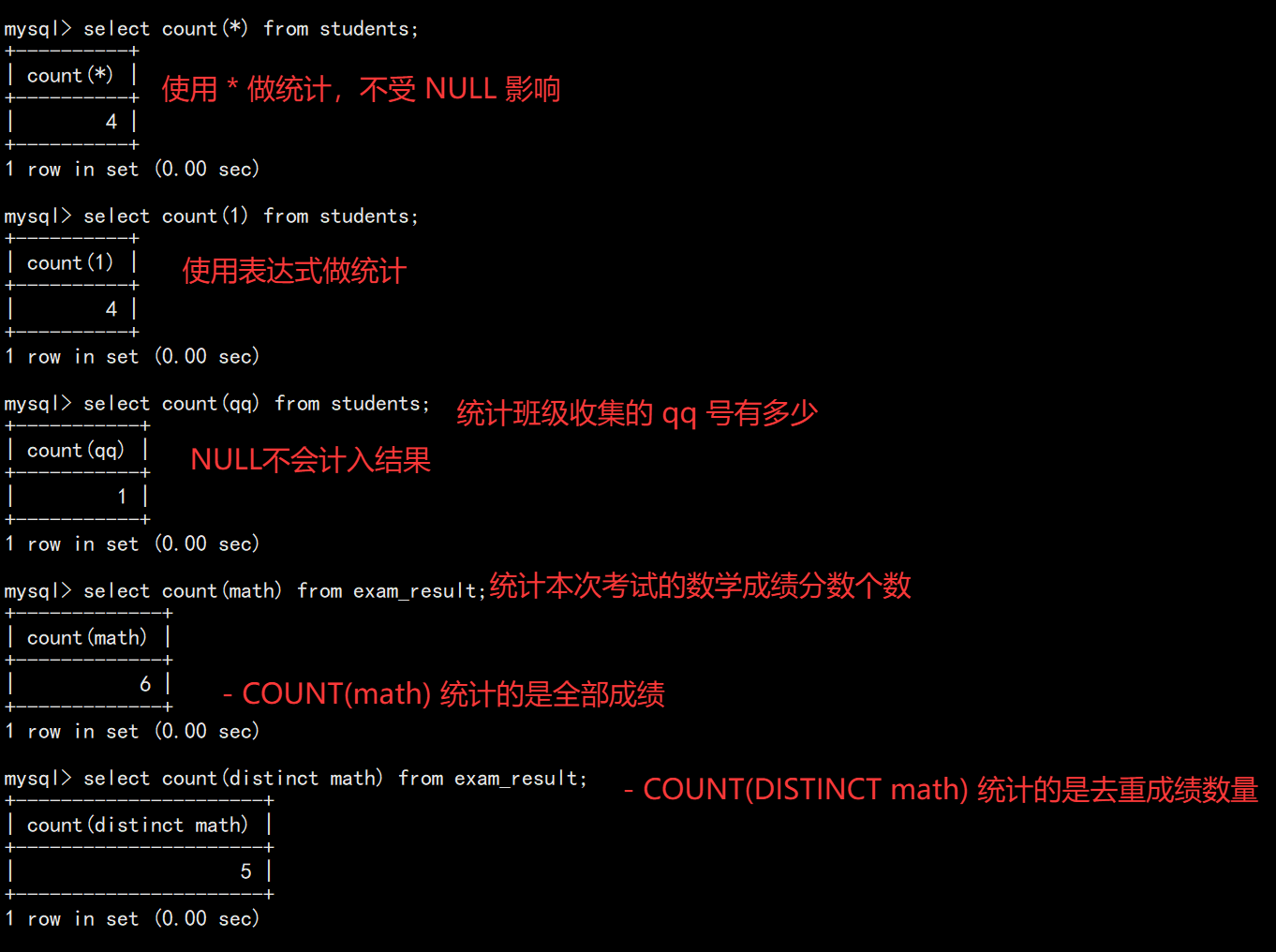
12. 分组查询(GROUP BY)
12.1 基本语法
sql
SELECT column, 聚合函数 FROM table GROUP BY column;案例: 准备工作,创建一个雇员信息表(来自oracle 9i 的经典测试表)
EMP 员工表 DEPT部门表 SALGRADE工资等级表
sql
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);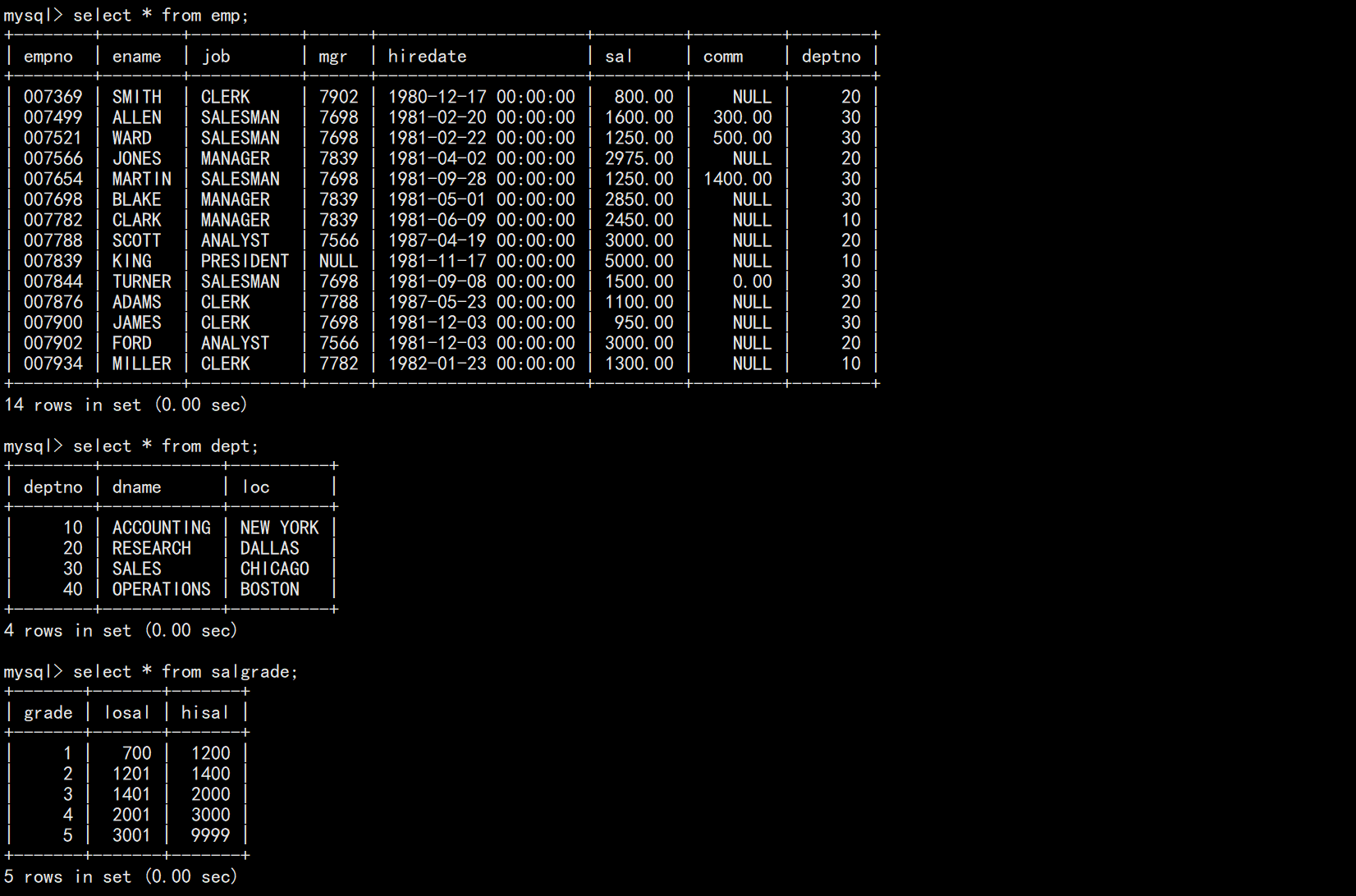
sql
-- 每个部门的平均工资
SELECT deptno, AVG(sal) FROM EMP GROUP BY deptno;
-- 每个部门每种岗位的平均工资
SELECT deptno, job, AVG(sal) FROM EMP GROUP BY deptno, job;
-- 过滤分组结果(HAVING)
SELECT deptno, AVG(sal) AS avg_sal FROM EMP GROUP BY deptno HAVING avg_sal < 2000;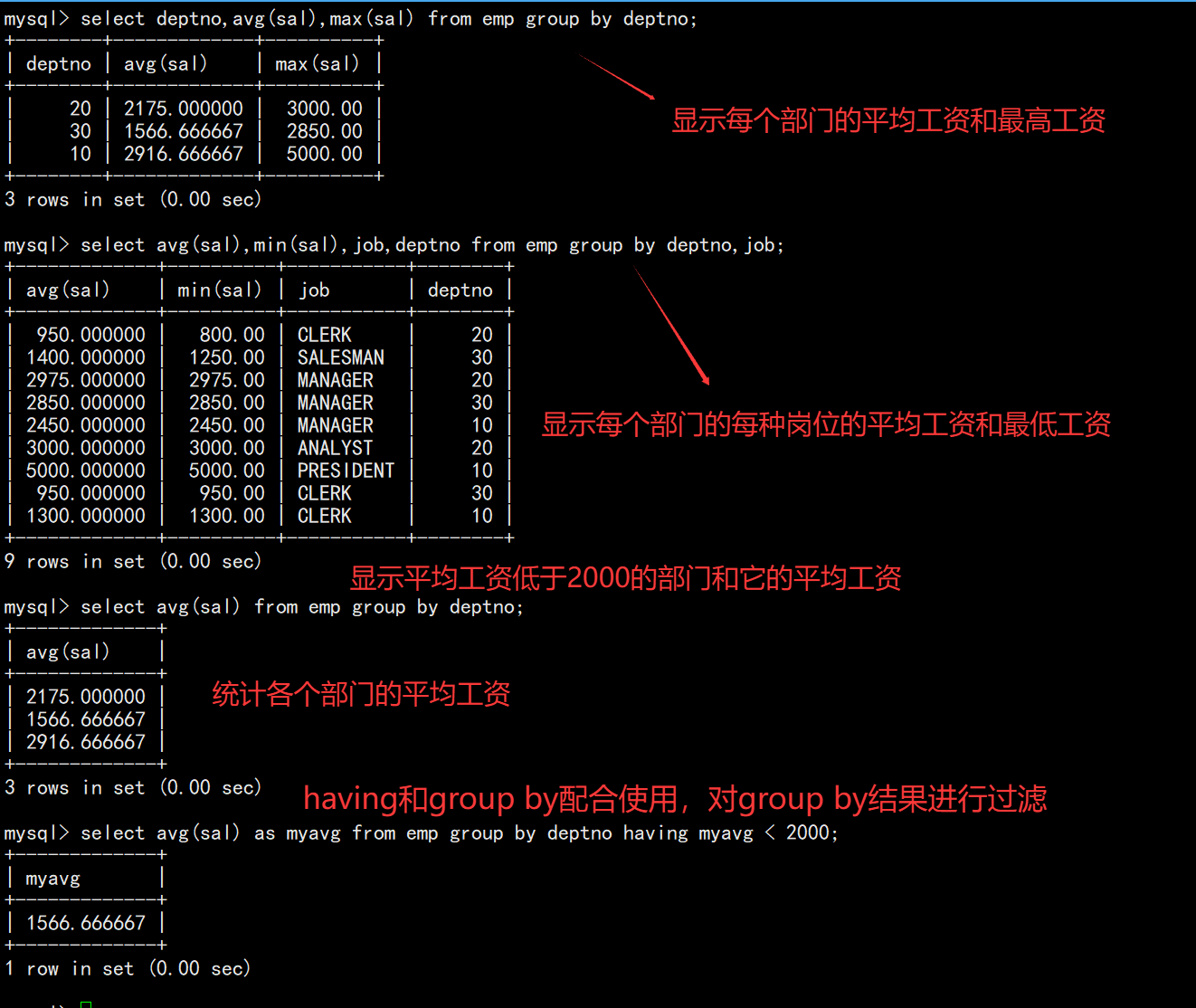
注: having 经常和 group by 搭配使用,作用是对分组进行筛选,作用有些像 where。
13. 查询执行顺序
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
14. 实战OJ推荐
sql
insert into actor values(1,'PENELOPE','GUINESS','2006-02-15 12:34:33');
insert into actor values(2,'NICK','WAHLBERG','2006-02-15 12:34:33');
sql
select distinct(salary) from salaries order by salary desc;
sql
select * from employees order by hire_date desc limit 1;
sql
select * from employees where hire_date = (select max(hire_date) from employees);
sql
select * from employees where hire_date = (select distinct hire_date from employees order by hire_date desc limit 1 offset 2);查找薪水记录超过15条的员工号emp_no以及其对应的记录次_牛客题霸_牛客网
sql
select emp_no,count(emp_no) as t from salaries group by emp_no having t > 15;从titles表获取按照title进行分组_牛客题霸_牛客网
sql
select title,count(*) as t from titles group by title having t >=2;