PostgreSQL 页结构深度解析
本文系统拆解 PostgreSQL 14 的页面(Page)机制,涵盖数据页、索引页的物理结构,快照与行版本可见性,页剪枝与 HOT 更新优化,并在关键处与 MySQL InnoDB 进行对比,帮助你从存储引擎底层真正理解 PostgreSQL 的运行方式。
文章目录
- [PostgreSQL 页结构深度解析](#PostgreSQL 页结构深度解析)
-
- [1. 页(Page)是什么](#1. 页(Page)是什么)
- [2. 数据页(堆表页)结构](#2. 数据页(堆表页)结构)
-
- [2.1 页头(PageHeaderData,24 字节)](#2.1 页头(PageHeaderData,24 字节))
- [2.2 ItemId 槽位数组(每项 4 字节)](#2.2 ItemId 槽位数组(每项 4 字节))
- [2.3 空闲空间](#2.3 空闲空间)
- [2.4 元组区(Tuple / HeapTuple)](#2.4 元组区(Tuple / HeapTuple))
- [2.5 Special 空间](#2.5 Special 空间)
- [2.6 fillfactor 参数](#2.6 fillfactor 参数)
- [3. 索引页结构](#3. 索引页结构)
-
- [3.1 索引文件的页面类型](#3.1 索引文件的页面类型)
- [3.2 索引页头与 Special 区](#3.2 索引页头与 Special 区)
- [3.3 内部节点条目](#3.3 内部节点条目)
- [3.4 叶子节点条目(IndexTuple)](#3.4 叶子节点条目(IndexTuple))
- [3.5 不同索引类型的页面差异](#3.5 不同索引类型的页面差异)
- [4. 行版本与 MVCC](#4. 行版本与 MVCC)
-
- [4.1 元组头的 MVCC 字段](#4.1 元组头的 MVCC 字段)
- [4.2 提示位(Hint Bits)](#4.2 提示位(Hint Bits))
- [4.3 INSERT / DELETE / UPDATE 对页面的影响](#4.3 INSERT / DELETE / UPDATE 对页面的影响)
- [5. 快照:可见性的核心机制](#5. 快照:可见性的核心机制)
-
- [5.1 什么是快照](#5.1 什么是快照)
- [5.2 快照的三个核心字段](#5.2 快照的三个核心字段)
- [5.3 可见性判断规则](#5.3 可见性判断规则)
- [5.4 数据库视界(Database Horizon)](#5.4 数据库视界(Database Horizon))
- [6. 页剪枝(Page Pruning)](#6. 页剪枝(Page Pruning))
-
- [6.1 什么是页剪枝](#6.1 什么是页剪枝)
- [6.2 触发条件](#6.2 触发条件)
- [6.3 页剪枝的工作内容](#6.3 页剪枝的工作内容)
- [7. HOT 更新(Heap Only Tuple)](#7. HOT 更新(Heap Only Tuple))
-
- [7.1 普通 UPDATE 的问题](#7.1 普通 UPDATE 的问题)
- [7.2 HOT 更新的原理](#7.2 HOT 更新的原理)
- [7.3 HOT 链的结构](#7.3 HOT 链的结构)
- [7.4 HOT 链剪枝(HOT Chain Pruning)](#7.4 HOT 链剪枝(HOT Chain Pruning))
- [8. HOT 链分裂](#8. HOT 链分裂)
- [9. 索引页的剪枝](#9. 索引页的剪枝)
- [10. 与 MySQL InnoDB 的页结构对比](#10. 与 MySQL InnoDB 的页结构对比)
- [11. 相关辅助文件:FSM、VM、TOAST](#11. 相关辅助文件:FSM、VM、TOAST)
-
- [11.1 空闲空间映射(FSM,`*_fsm`)](#11.1 空闲空间映射(FSM,
*_fsm)) - [11.2 可见性映射(VM,`*_vm`)](#11.2 可见性映射(VM,
*_vm)) - [11.3 TOAST 表(`pg_toast.*`)](#11.3 TOAST 表(
pg_toast.*))
- [11.1 空闲空间映射(FSM,`*_fsm`)](#11.1 空闲空间映射(FSM,
- [12. 实战:用 pageinspect 观察页面](#12. 实战:用 pageinspect 观察页面)
-
- [12.1 安装和基本用法](#12.1 安装和基本用法)
- [12.2 观察 UPDATE 后的页面状态](#12.2 观察 UPDATE 后的页面状态)
- [12.3 观察索引页的 HOT 链](#12.3 观察索引页的 HOT 链)
- [12.4 观察页剪枝效果](#12.4 观察页剪枝效果)
- [13. 总结](#13. 总结)
1. 页(Page)是什么
PostgreSQL 以 页(Page / Block) 作为磁盘 I/O 的最小单元,默认大小为 8 KB (编译时可通过 ./configure --with-blocksize 修改,最大 32 KB,一旦设定则不可在线更改)。
所有数据文件------无论是堆表、B-tree 索引、Hash 索引还是 TOAST 表------都由若干连续的页面组成,统一编号从 0 开始。读写操作以整页为粒度,页面先被载入 shared_buffers 缓冲区缓存,修改后标记为脏页,再由 writer 进程或 checkpointer 异步刷盘。
与 MySQL InnoDB 类似,PostgreSQL 的页大小也是固定的(InnoDB 默认 16 KB),两者均以页为单位管理缓冲区。但两者的页面内部结构和组织方式存在本质差异,后文详细对比。
2. 数据页(堆表页)结构
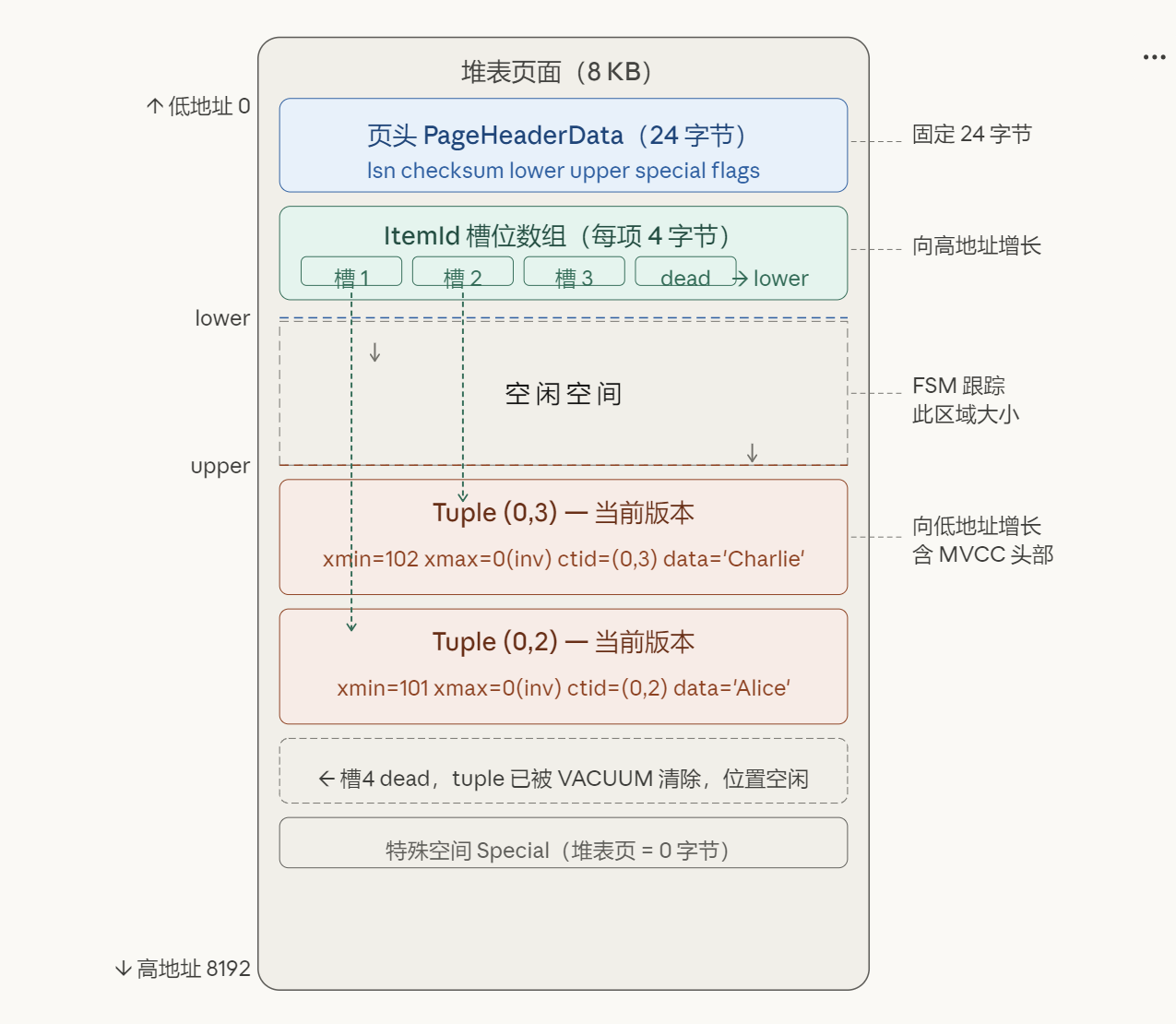
在 PostgreSQL 中,"表"被称为堆(Heap),因为行数据是无序堆放的,不像 MySQL InnoDB 聚簇索引那样按主键排列。
一个 8 KB 的堆表页面从低地址(地址 0)到高地址(地址 8192)依次排列如下五个区域:
地址 0 ┌─────────────────────────────────┐
│ 页头 PageHeaderData(24 字节) │
├─────────────────────────────────┤
│ ItemId[1] (4 字节) │ ← 槽位数组,向高地址增长
│ ItemId[2] │
│ ItemId[3] │
│ ... │
lower ──── ├─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─┤
│ │
│ 空 闲 空 间 │
│ │
upper ──── ├─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─┤
│ Tuple N(最新插入) │ ← 元组区,向低地址增长
│ ... │
│ Tuple 2 │
│ Tuple 1(最早插入) │
├─────────────────────────────────┤
地址 8192 │ Special 空间(堆表 = 0 字节) │
└─────────────────────────────────┘2.1 页头(PageHeaderData,24 字节)
页头字段含义:
| 字段 | 大小 | 说明 |
|---|---|---|
pd_lsn |
8 字节 | 该页最后一次修改对应的 WAL LSN,用于崩溃恢复时判断 redo 是否需要重放 |
pd_checksum |
2 字节 | 页面校验和(需开启 data_checksums 才生效) |
pd_flags |
2 字节 | 标志位,含 PD_HAS_FREE_LINES(有 dead 槽可复用)、PD_ALL_VISIBLE 等 |
pd_lower |
2 字节 | ItemId 数组末端偏移,即下一个新槽的起始位置 |
pd_upper |
2 字节 | 元组区起始偏移,即下一个新 tuple 的起始位置 |
pd_special |
2 字节 | Special 区起始偏移(堆表页此值等于页大小,意味着 special 区为空) |
pd_pagesize_version |
2 字节 | 页大小和格式版本 |
pd_prune_xid |
4 字节 | 页面上最老死元组的 xmax,用于判断是否值得剪枝 |
pd_upper - pd_lower 即页面当前的可用空闲字节数,FSM 文件汇总了所有页面这个值,用于快速找到可容纳新行的页面,避免全表扫描寻找空闲空间。
sql
-- 查看页头信息
SELECT lower, upper, special, pagesize
FROM page_header(get_raw_page('accounts', 0));
-- lower=152, upper=6904, special=8192, pagesize=81922.2 ItemId 槽位数组(每项 4 字节)
紧接页头之后,是指向元组的指针数组,称为 ItemId(项指针 / 槽位),每个槽位 4 字节,包含三个字段:
| 字段 | 位宽 | 说明 |
|---|---|---|
lp_off |
15 bit | 元组在页内的起始字节偏移量 |
lp_flags |
2 bit | 状态标志:0=unused / 1=normal / 2=redirect / 3=dead |
lp_len |
15 bit | 元组的字节长度 |
四种状态含义:
- unused:从未分配过,初始状态
- normal:正常,指向一个有效的 tuple
- redirect :HOT 更新时使用,指向同页另一个槽号,
lp_off此时存的是目标槽号而非偏移 - dead:tuple 已被 VACUUM 物理清除,槽号保留等待复用
TID(Tuple Identifier)的格式是 (页号, 槽号),例如 (3, 2) 表示第 3 页第 2 个槽。索引叶子节点存的就是 TID,而不是 tuple 的直接物理地址。这层间接寻址的设计价值在于:VACUUM 在页内整理碎片时移动 tuple,只需更新 ItemId 里的偏移,所有持有该 TID 的索引条目无需变化。
2.3 空闲空间
pd_lower(槽位数组末端)和 pd_upper(元组区起始)之间的区域是当前页的可用空间。
页面不会产生碎片 :每当 VACUUM 或页剪枝清理死 tuple 后,会调用 PageRepairFragmentation() 将存活 tuple 向高地址紧缩,空闲空间重新聚合成一个连续块。这与 MySQL InnoDB 需要通过 OPTIMIZE TABLE 来整理碎片的方式不同。
2.4 元组区(Tuple / HeapTuple)
元组从高地址向低地址生长,每次插入新行,pd_upper 向低地址移动 tuple_size 字节。
每个 HeapTuple = HeapTupleHeader(头部,最小 23 字节)+ 用户数据列值。行头字段详解请参考《PostgreSQL 行记录结构深度解析》一文,此处不再重复。
2.5 Special 空间
堆表页的 Special 区大小为 0(pd_special 等于页大小)。索引页会在此区域存放索引类型相关的辅助数据,详见下节。
2.6 fillfactor 参数
堆表有一个重要的存储参数 fillfactor(默认 100),表示 INSERT 操作允许填满页面的百分比。
sql
CREATE TABLE orders (id serial, amount numeric)
WITH (fillfactor = 75);设置 fillfactor = 75 意味着:INSERT 只能用到页面的 75% 空间,剩余 25% 预留给 UPDATE 操作在同页生成新版本(这是触发 HOT 更新的前提之一)。对于频繁 UPDATE 非索引列的表,适当降低 fillfactor 可以显著减少索引膨胀。
3. 索引页结构
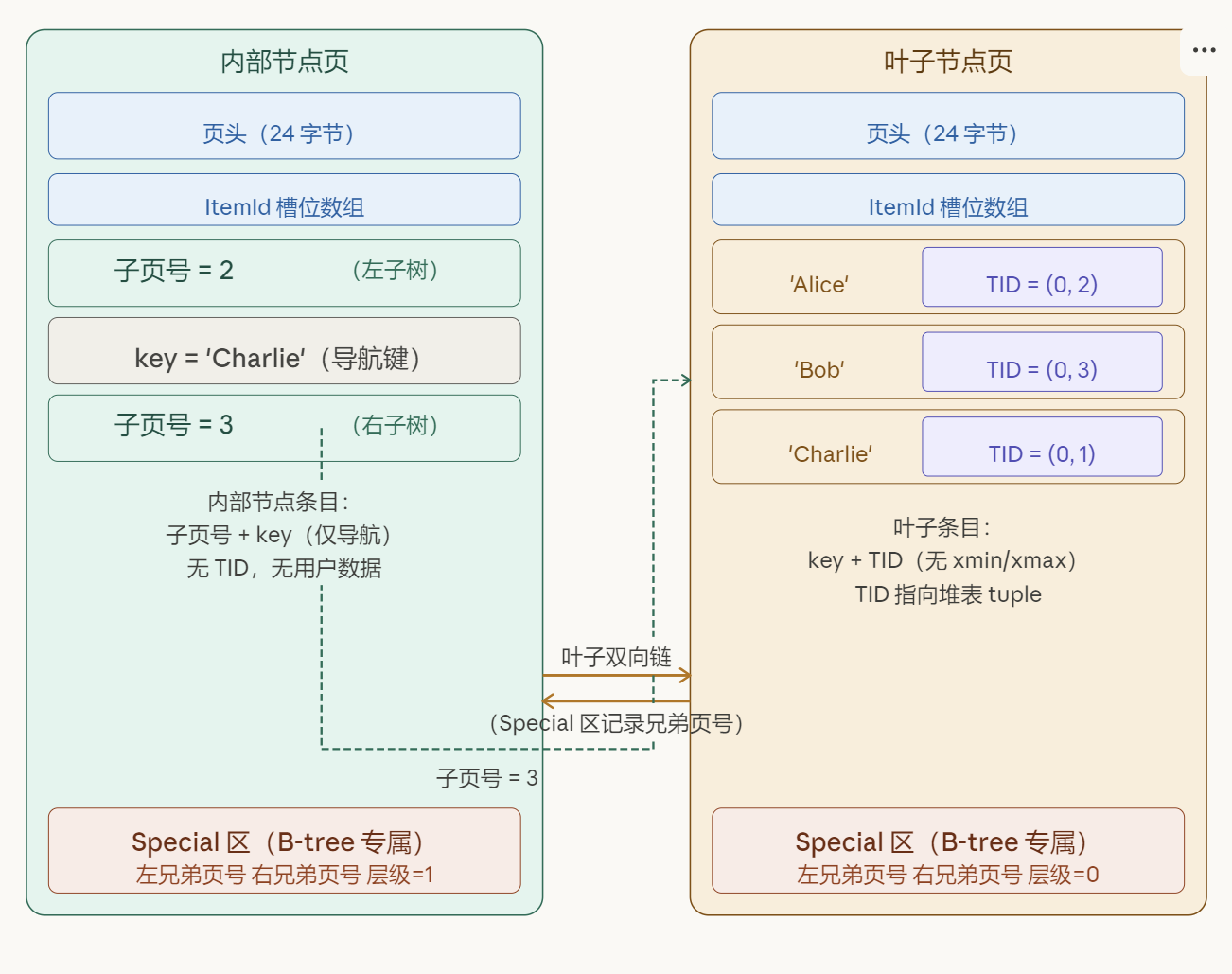
B-tree 索引文件与堆表文件完全独立(relfilenode 不同)。索引文件同样由 8 KB 页面组成,但页面布局和内容与堆表有显著差异。
3.1 索引文件的页面类型
B-tree 索引文件包含三种页面:
- Page 0:元数据页(Meta Page),记录根页号、索引版本等全局信息,不存实际数据
- 内部节点页(Internal Node Page):存储导航键,用于在树中路由
- 叶子节点页(Leaf Node Page) :存储实际的索引条目
(key, TID)
3.2 索引页头与 Special 区
索引页的页头结构与堆表页相同(同样的 PageHeaderData),但 Special 区 (pd_special 到页尾)存放了 B-tree 专属信息:
c
/* B-tree 页 Special 区结构 BTPageOpaqueData */
typedef struct BTPageOpaqueData {
BlockNumber btpo_prev; /* 左兄弟页号(用于叶子层横向链表) */
BlockNumber btpo_next; /* 右兄弟页号 */
uint32 btpo_level; /* 节点层级:0 = 叶子,1 以上为内部节点 */
uint16 btpo_flags; /* 标志位:BTP_LEAF / BTP_ROOT / BTP_META 等 */
BTCycleId btpo_cycleid;/* 用于页分裂时的并发控制 */
} BTPageOpaqueData;btpo_prev 和 btpo_next 将所有叶子页 串联成双向链表。范围扫描(如 WHERE name BETWEEN 'A' AND 'Z')找到起始叶子后,只需沿链表横向遍历,无需回到父节点,这是 B+ 树相对 B 树的核心优势。
这是堆表页与索引页最显著的结构差异:堆表页的 Special 区为空,而 B-tree 索引页的 Special 区存储了兄弟页号,实现了叶子层双向链表。
3.3 内部节点条目
内部节点(非叶子节点)的条目结构极为精简:
内部节点条目 = 子页号(BlockNumber,4 字节)+ 导航 key(索引列值)没有 TID,没有用户数据,没有 MVCC 信息。内部节点的条目只用于路由:决定查找时应该往哪个子节点走。在一个 8 KB 页面中,内部节点可以存放约 400 个子指针(以整数 key 为例),扇出极高,这是 B+ 树即使对于亿级数据也只需 4~5 层的根本原因。
3.4 叶子节点条目(IndexTuple)
叶子节点存储实际的索引条目:
叶子节点条目(IndexTuple)= key 值(索引列的实际数据)+ TID(指向堆表 tuple 的坐标)IndexTuple 不包含 xmin、xmax、ctid、infomask 等 MVCC 字段。索引本身没有版本控制机制,所有版本的 tuple 都可能在索引中有对应条目,可见性判断完全依靠回堆后读取 HeapTuple 的头部字段。
以整数 key + TID(6 字节)为例,每个叶子条目约 20 字节,一个 8 KB 叶子页可以容纳约 400 个条目。这就是"叶子节点 ≠ 叶子条目"的关键所在:10 万条记录对应 10 万个叶子条目 ,但只需约 250 个叶子页面。
3.5 不同索引类型的页面差异
PostgreSQL 支持多种索引类型,各自的 Special 区和页面内容不同:
| 索引类型 | Special 区内容 | 适用场景 |
|---|---|---|
| B-tree | 左右兄弟页号、层级、标志位 | 等值、范围、排序查询(最常用) |
| Hash | 哈希桶编号、分割标志 | 纯等值查询 |
| GiST | 扩展方法自定义内容 | 几何、全文索引 |
| GIN | 待处理列表指针等 | 数组、JSONB、全文索引 |
| BRIN | 范围摘要信息 | 超大表的物理相关性很好的列 |
4. 行版本与 MVCC
PostgreSQL 用 Append-Only 的 MVCC 机制 实现多版本并发控制:UPDATE 时不原地修改旧数据,而是追加新版本,旧版本通过 xmax 字段打上删除标记,两者共存于页面,直到 VACUUM 清理。
4.1 元组头的 MVCC 字段
每个 HeapTuple 头部的关键 MVCC 字段:
| 字段 | 大小 | 含义 |
|---|---|---|
t_xmin |
4 字节 | 创建此版本的事务 XID(INSERT / UPDATE 写入新版本时设置) |
t_xmax |
4 字节 | 删除此版本的事务 XID(DELETE / UPDATE 旧版本时设置,0 表示未删) |
t_ctid |
6 字节 | 指向同一行的下一个更新版本(UPDATE 时旧版本的 ctid 改写为新版本 TID) |
t_infomask |
2+2 字节 | 提示位,缓存 xmin/xmax 的提交/中止状态,避免反复查 CLOG |
4.2 提示位(Hint Bits)
t_infomask 中的以下四个 bit 是最常用的提示位:
HEAP_XMIN_COMMITTED (0x0100):xmin 事务已提交
HEAP_XMIN_INVALID (0x0200):xmin 事务已中止或无效
HEAP_XMAX_COMMITTED (0x0400):xmax 事务已提交
HEAP_XMAX_INVALID (0x0800):xmax 无效(行未被删除)提示位的特殊性 :它们由第一个"发现"某事务已完成的进程写回到 tuple 头部,之后所有访问该 tuple 的进程直接读 bit,无需再查 CLOG。这意味着只读 SELECT 也可能产生脏页(只修改了 infomask),这是 PostgreSQL 特有的行为,与 MySQL 不同。
4.3 INSERT / DELETE / UPDATE 对页面的影响
INSERT:
- 在目标页面追加新 tuple,
xmin = 当前 XID,xmax = 0(XMAX_INVALID 位置 1) ctid指向自身
DELETE:
- 找到目标 tuple,将其
xmax设为当前 XID,清除 XMAX_INVALID - 物理数据不变,等 VACUUM 清理
UPDATE(等价于 DELETE 旧版本 + INSERT 新版本):
- 旧 tuple:
xmax写入当前 XID,ctid改写为新版本 TID - 新 tuple:追加到页面,
xmin = 当前 XID,ctid = 自身 TID - 两个版本同时存在于页面,这是表膨胀(Table Bloat)的根源
ROLLBACK:
- 仅在 CLOG 中将 XID 标记为已中止,数据页不变
- 下一个访问该 tuple 的进程发现 xmin/xmax 对应的事务是 aborted,写回 INVALID 提示位,该版本对所有后续事务不可见
5. 快照:可见性的核心机制

5.1 什么是快照
快照(Snapshot)是 PostgreSQL 在某一时刻对"哪些事务已提交"的一张快照记录,它定义了当前查询"能看到什么数据"。快照不是数据的物理副本,而是由几个数字组成的轻量结构。
- Read Committed 隔离级别:每条 SQL 语句执行前重新获取快照
- Repeatable Read / Serializable 隔离级别:事务内第一条语句获取快照,整个事务共用
5.2 快照的三个核心字段
快照结构示例(pg_current_snapshot() 返回:790:792:789)
xmin = 790 最老活跃事务 ID
小于此值的事务:要么已提交(其修改包含在快照中),要么已中止(忽略)
xmax = 792 最新已提交 XID + 1(上边界)
大于等于此值的事务:仍在运行或尚未开始,其修改不可见
xip_list = [789] 快照创建时所有活跃事务的 XID 列表
即使这些 XID 在 [xmin, xmax) 范围内,其修改也不可见5.3 可见性判断规则
对于一个 tuple,当前快照按以下规则判断其可见性:
1. xmin 的事务是否已提交?
- 已中止 → 不可见(此版本从未真正存在)
- 未提交(在 xip_list 中)→ 不可见
- 已提交且 XID < xmin → 可见(老事务,无条件可见)
- 已提交且 xmin ≤ XID < xmax 且不在 xip_list → 可见
2. 若 xmin 可见,再判断 xmax:
- xmax = 0 或 XMAX_INVALID 位置 1 → 未删除,tuple 可见
- xmax 事务已提交 → 此 tuple 已被删除,不可见
- xmax 事务未提交或已中止 → 删除无效,tuple 仍可见PostgreSQL 为何无法实现时间旅行查询(Temporal / Flashback Query):快照记录的是"当时哪些事务活跃",而不是时间戳。事务完成后,就无法重建"那一刻所有事务的精确状态",因此无法回溯到任意历史时间点。
5.4 数据库视界(Database Horizon)
事务视界(Transaction Horizon) :一个事务当前快照的 xmin 值,即它能看到的最老事务边界。
数据库视界:所有活跃事务视界中最小的那个 xmin。这是 VACUUM 的关键参数------只有超出数据库视界的死元组,才能被安全清理(因为没有任何活跃事务需要看到它们)。
sql
-- 查看当前事务的视界
SELECT backend_xmin FROM pg_stat_activity WHERE pid = pg_backend_pid();长事务对清理的危害:若某事务持有很老的快照(xmin 很小),数据库视界就无法前进,VACUUM 无法清理该视界内的任何死元组------即使那些数据与该长事务毫无关联。这是 PostgreSQL 运维中表膨胀问题的常见根源。
6. 页剪枝(Page Pruning)
6.1 什么是页剪枝
页剪枝是 PostgreSQL 的一种轻量级、单页范围内的清理机制,比全量 VACUUM 更快,发生时机更早,但作用范围仅限于单个堆表页面。
与 VACUUM 的区别:
- VACUUM 需要扫描整张表,会更新 FSM、VM、清理索引
- 页剪枝仅操作单个页面,不更新 FSM 和 VM,执行更快,但回收的空间只对 UPDATE 可用(不对 INSERT 开放)
6.2 触发条件
页剪枝在以下两种情况触发:
-
UPDATE 找不到足够空间 :当 UPDATE 试图在当前页放置新版本 tuple,但发现空间不足时,先触发页剪枝,尝试清理死元组腾出空间。页头的
pd_prune_xid字段记录了页面中最老的可能可清理元组的 xmax,用于快速判断是否值得触发剪枝。 -
超过 fillfactor 阈值 :INSERT 操作发现页面填充率已超过
fillfactor参数设定的百分比时,在下次 UPDATE 访问该页时触发剪枝。
6.3 页剪枝的工作内容
页剪枝只清理超出数据库视界 的死元组------即 xmax < 数据库视界 xmin 的已提交删除操作对应的 tuple。尚有活跃快照需要的旧版本不会被碰。
清理过程:
- 遍历页内所有 ItemId,识别可清理的死 tuple
- 物理移除死 tuple 的数据
- 调用
PageRepairFragmentation()将存活 tuple 向高地址紧缩,空闲空间合并为一个连续块 - 被剪枝 tuple 的槽位状态改为
dead(索引可能仍引用这些槽号)
sql
-- 验证:用 fillfactor=75 的表观察页剪枝行为
CREATE TABLE hot(id integer, s char(2000)) WITH (fillfactor = 75);
CREATE INDEX hot_id ON hot(id);
INSERT INTO hot VALUES (1, 'A');
UPDATE hot SET s = 'B';
UPDATE hot SET s = 'C';
UPDATE hot SET s = 'D';
-- 此时页面有 4 个 tuple,超过 fillfactor 阈值
-- 下次 UPDATE 触发剪枝:
UPDATE hot SET s = 'E';
SELECT * FROM heap_page('hot', 0);
-- ctid | state | xmin | xmax
-- (0,1)| dead | |
-- (0,2)| dead | |
-- (0,3)| dead | |
-- (0,4)| normal| 804 c | 805
-- (0,5)| normal| 805 | 0 a7. HOT 更新(Heap Only Tuple)

7.1 普通 UPDATE 的问题
在没有 HOT 优化的情况下,每次 UPDATE 都会:
- 在堆表追加一个新版本 tuple
- 对表上所有索引新增一个条目(指向新 tuple 的 TID)
即使被修改的列根本没有索引,所有索引也必须增加新条目。这导致了两个问题:
- 索引膨胀:索引中积累大量指向历史旧版本 tuple 的条目
- 写放大:每次 UPDATE 都要写所有索引页
7.2 HOT 更新的原理
**HOT(Heap Only Tuple)**是一种针对"修改非索引列"场景的优化。若满足以下两个条件,PostgreSQL 使用 HOT 路径:
条件一:被修改的列不属于任何索引
条件二:新旧 tuple 在同一个堆表页面内
满足条件时,HOT 更新不会在任何索引中新增条目,而是在堆表页面内通过 ctid 链和 redirect 槽将新旧版本串联。
7.3 HOT 链的结构
HOT 更新后,堆表页面内形成如下结构:
索引条目(只有这一个)
|
↓
槽1(normal 状态)← 索引条目的 TID 指向这里
Tuple(0,1):HHU bit=1(Heap Hot Updated,表示需要沿 ctid 链继续扫描)
t_ctid = (0,2)(指向下一版本)
|
↓ ctid 链
槽2(normal 状态)
Tuple(0,2):HOT bit=1(Heap Only Tuple,表示无索引引用此版本)
t_ctid = (0,2)(指向自身,是最新版本)HHU(Heap Hot Updated)bit:设在旧版本 tuple 上,告知扫描器"需要沿 ctid 链继续找更新版本"。
HOT(Heap Only Tuple)bit:设在新版本 tuple 上,表示"没有任何索引直接引用我"。
当索引扫描访问堆页面,找到 HHU 标记的 tuple 时,会继续沿 ctid 链遍历,直到找到最新版本,再由快照规则决定哪个版本可见。
7.4 HOT 链剪枝(HOT Chain Pruning)
当页面空间耗尽需要剪枝时,HOT 链的处理比普通死元组更复杂:
- 链头不能移动:索引条目指向链头的 TID(如槽1),移动它会导致索引引用失效
- 解决方案:redirect 重定向
剪枝后,链头槽位变为 redirect 状态,lp_off 字段存储当前有效链头的槽号(而不是物理偏移),索引扫描通过重定向找到实际 tuple:
剪枝前:
槽1 normal → Tuple(0,1) 旧版本(链头,被索引引用)
槽2 normal → Tuple(0,2) 新版本
槽3 normal → Tuple(0,3) 当前版本
剪枝后(Tuple(0,1)和(0,2)超出视界被清理):
槽1 redirect → 槽3(索引仍指向槽1,通过 redirect 跳到槽3)
槽2 unused(释放,可被新 tuple 复用)
槽3 normal → Tuple(0,3) 当前版本8. HOT 链分裂
HOT 链只能在单个页面内延伸------这是 HOT 更新的天然约束。一旦当前页满了,即使被修改的列没有索引,PostgreSQL 也无法继续 HOT 更新:
- 新 tuple 被写入另一个页面(如 Page 1 槽1)
- 索引必须新增一个条目:
key → TID(1,1) - 原来的 HOT 链在此中断,Page 0 和 Page 1 上各有一条独立的 HOT 链
此后该索引将有两个条目(一个指向 Page 0 的旧链头,一个指向 Page 1 的新链头),HOT 优化的效益被削弱。
延迟 HOT 链分裂的手段 :降低表的 fillfactor,为 UPDATE 预留更多同页空间。
sql
ALTER TABLE orders SET (fillfactor = 70);9. 索引页的剪枝
索引页也有自己的剪枝机制,在 B-tree 页即将分裂时触发(分裂需要空间,若剪枝能腾出足够空间则避免分裂)。
可以被剪枝的两类索引条目:
-
dead 标记的条目:在之前的索引扫描中,某进程访问该条目时发现对应堆 tuple 已超出所有事务的视界,便将此索引条目标记为 dead。
-
LP_DEAD 标记的条目:当同一行有多个版本在索引中都有条目,且这些旧版本已超出数据库视界,PostgreSQL 可以识别出其中哪些是可以清理的。
索引页剪枝是避免索引过度膨胀的重要手段。B-tree 索引一旦分裂,两个分裂出的页面不会因后来数据删减而再合并(这会导致索引长期膨胀),但索引剪枝可以推迟分裂发生的时机。
10. 与 MySQL InnoDB 的页结构对比
| 维度 | PostgreSQL 堆表页 | MySQL InnoDB 页 |
|---|---|---|
| 默认页大小 | 8 KB(可编译时改) | 16 KB(innodb_page_size) |
| 数据组织 | 无序堆放,与索引分离 | 聚簇索引,数据按主键有序 |
| 页内行的物理顺序 | 按插入顺序,无排序 | 按主键排序(聚簇) |
| UPDATE 机制 | Append-Only,旧版本留原处 | 原地修改,旧版本存 Undo Log |
| MVCC 旧版本存放 | 堆表页面内(与当前版本共存) | 独立的 Undo Log 文件 |
| 表膨胀问题 | 存在,需 VACUUM 定期清理 | 不存在,Undo Purge 线程异步清理 |
| 页头信息 | 24 字节 PageHeaderData | 38 字节 FIL_PAGE_HEADER |
| 页内目录 | ItemId 槽位数组(页头后) | Page Directory(页尾,存槽偏移) |
| 空闲空间位置 | 槽位数组与 tuple 区中间 | 页中间 Free Space 区 |
| Special / Trailer 区 | Special 区(堆表=0,索引存兄弟页号) | FIL_PAGE_TRAILER(8 字节,存校验和) |
| 碎片整理 | 页剪枝/VACUUM 自动合并 | OPTIMIZE TABLE 或 ALTER TABLE |
| 索引回表 | 用 TID 直接定位,一次 I/O | 用主键二次查聚簇索引,可能两次 I/O |
| 主键选型敏感度 | 低(堆表无序,UUID 无写放大) | 高(UUID 主键导致聚簇索引页频繁分裂) |
核心差异总结:
MySQL 的数据就是聚簇索引,数据文件和主键 B-tree 是同一棵树,物理有序。旧版本存在独立的 Undo Log,不占用数据页空间。
PostgreSQL 的数据文件(堆)和索引文件完全分离,数据无序堆放,任何索引(包括主键)都是独立的 B-tree 文件,叶子节点存 TID 指回堆表。旧版本就地保留在堆表页面,占用实际存储,必须靠 VACUUM 定期回收。
11. 相关辅助文件:FSM、VM、TOAST
每张表对应的物理文件不只一个,还有三个辅助文件:
11.1 空闲空间映射(FSM,*_fsm)
FSM 文件以 B 树形式组织,存储每个堆表页面当前可用空闲空间的近似值(以 1/256 精度存储)。INSERT 时查询 FSM 找到有足够空间的页,是 O(1) 操作。
sql
-- VACUUM 后 FSM 才会更新
VACUUM accounts;
SELECT * FROM pg_freespace('accounts');
-- blkno | avail
-- 0 | 3456
-- 1 | 720011.2 可见性映射(VM,*_vm)
VM 文件每个堆表页面对应 2 bit:
- All-Visible bit:该页所有 tuple 对所有当前事务均可见(无死元组)。Index Only Scan 若发现该位已设,可跳过回堆,直接返回索引中的数据。
- All-Frozen bit:该页所有 tuple 已被冻结(XID 转为特殊值),不需要 MVCC 检查。
VACUUM 在清理死元组后维护 VM,autovacuum 的健康与否直接影响 Index Only Scan 的效率。
11.3 TOAST 表(pg_toast.*)
当一行的数据加头部超过约 2000 字节(页面的四分之一),PostgreSQL 使用 TOAST 机制处理超长列:
- 先尝试 LZ 压缩
- 若仍超长,切分成约 2000 字节的块,存入单独的 TOAST 表(
pg_toastschema) - 主表 tuple 中只保留一个 18 字节的 TOAST 指针
TOAST 表本身也是普通的堆表(有对应的堆表文件),有自己的 TOAST 索引,也遵循同样的页面结构。对应用完全透明,查询时 PostgreSQL 自动拼接恢复原始值。若查询不涉及超长列,TOAST 表完全不会被读取(避免 SELECT * 的原因之一)。
12. 实战:用 pageinspect 观察页面
pageinspect 扩展可以直接读取页面的原始内容,是观察上述机制的最佳工具。
12.1 安装和基本用法
sql
CREATE EXTENSION pageinspect;
-- 查看页头
SELECT lower, upper, special, pagesize
FROM page_header(get_raw_page('accounts', 0));
-- 查看堆表页所有槽和 tuple
SELECT
lp AS slot,
lp_off AS offset,
lp_len AS length,
CASE lp_flags
WHEN 0 THEN 'unused'
WHEN 1 THEN 'normal'
WHEN 2 THEN 'redirect to ' || lp_off
WHEN 3 THEN 'dead'
END AS state,
t_xmin,
t_xmax,
t_ctid,
(t_infomask & 256) > 0 AS xmin_committed,
(t_infomask & 512) > 0 AS xmin_aborted,
(t_infomask & 1024) > 0 AS xmax_committed,
(t_infomask & 2048) > 0 AS xmax_aborted
FROM heap_page_items(get_raw_page('accounts', 0));12.2 观察 UPDATE 后的页面状态
sql
CREATE TABLE t (id int, s text);
CREATE INDEX ON t(s);
BEGIN;
INSERT INTO t VALUES (1, 'FOO');
-- 查看插入后状态
SELECT lp, t_xmin, t_xmax, t_ctid FROM heap_page_items(get_raw_page('t', 0));
-- lp=1, xmin=776, xmax=0, ctid=(0,1)
COMMIT;
BEGIN;
UPDATE t SET s = 'BAR';
-- 查看 UPDATE 后状态(事务未提交)
SELECT lp, t_xmin, t_xmax, t_ctid FROM heap_page_items(get_raw_page('t', 0));
-- lp=1: xmin=776, xmax=778, ctid=(0,2) ← 旧版本,xmax 打上当前 XID,ctid 指向新版本
-- lp=2: xmin=778, xmax=0, ctid=(0,2) ← 新版本
COMMIT;12.3 观察索引页的 HOT 链
sql
-- 使用 bt_page_items 查看索引页内容
SELECT itemoffset, htid, dead
FROM bt_page_items('t_s_idx', 1);
-- 普通 UPDATE 后:有两个条目(旧 TID 和新 TID)
-- HOT UPDATE 后:只有一个条目(指向链头)12.4 观察页剪枝效果
sql
-- 创建 fillfactor=75 的表
CREATE TABLE hot(id integer, s char(2000)) WITH (fillfactor = 75);
CREATE INDEX ON hot(id);
INSERT INTO hot VALUES (1, 'A');
UPDATE hot SET s = 'B'; UPDATE hot SET s = 'C'; UPDATE hot SET s = 'D';
-- 此时页面满(4个 tuple,超过 75% 阈值)
SELECT upper, pagesize FROM page_header(get_raw_page('hot', 0));
-- 触发页剪枝
UPDATE hot SET s = 'E';
-- 查看剪枝后页面:前3个槽变为 dead
SELECT ctid, state, xmin, xmax FROM heap_page('hot', 0);13. 总结
PostgreSQL 的页面机制围绕"数据无序堆放,版本在页内共存,索引独立指回堆表"的核心设计展开:
| 机制 | 关键点 |
|---|---|
| 堆表页布局 | 页头→槽位数组(↓)→空闲区→元组区(↑)→Special(0字节) |
| 间接寻址 | TID 指向槽位,槽位指向 tuple 偏移,碎片整理无需修改索引 |
| 索引页 | Special 区存兄弟页号(叶子双向链);叶子条目无 MVCC 字段,只有 key+TID |
| MVCC | xmin/xmax 内嵌在 tuple 头,提示位缓存事务状态避免重复查 CLOG |
| 快照 | xmin/xmax/xip_list 三元组定义可见范围;长事务阻塞数据库视界前进 |
| 页剪枝 | 单页、轻量、实时触发,清理超出数据库视界的死元组,不更新 FSM/VM |
| HOT 更新 | 修改非索引列且同页时,不新增索引条目,通过 redirect+ctid 链访问新版本 |
| HOT 链分裂 | 页满时 HOT 链跨页中断,退化为普通 UPDATE,索引新增条目 |
| 索引页剪枝 | 页分裂前触发,清理 dead 或过期索引条目,推迟分裂减少膨胀 |
| VACUUM | 全表扫描,清理所有死元组,更新 FSM/VM,清理索引;autovacuum 自动维护 |
理解页面结构,是排查表/索引膨胀、调优 autovacuum 参数、理解查询计划选择(Seq Scan vs Index Scan vs Index Only Scan)的基础,也是深入掌握 PostgreSQL 性能调优的必经之路。