论文总结
1、作者使用了临床诊断的笔记、患者人口统计学信息、时间序列数据和CXR影像数据,构建多模态模型,并在院内死亡率预测、住院时长预测和医院再入院预测三个任务上评估了模型性能;
2、作者对比了早期融合、中期融合和晚期融合三种融合方式。
3、整体来说,这个模型的方法比较简单,序列数据中,临床笔记通过DOC2Vec变成向量,然后是LSTM,患者记录配置等电子健康记录数据用BiLSTM,以及对于CXR影像数据,用ResNet。感觉更多的是把多个模态数据整合起来,并且对比了三种融合方式,这方面的创新,反而在模型每个组件方面,用的比较常规。
4、有开源代码,所使用的三个数据集(MIMIC-IV、MIMIC-CXR 和 MIMIC-IV-Note)均可在 https://physionet.org/ 获得,需凭凭证访问。项目代码可在 https://github.com/Wang-Yuanlong/MultimodalPred 获取。
摘要
电子健康记录(EHR)系统的广泛采用为我们带来了大量临床数据,从而为基于数据的医疗研究提供了解决医疗领域各种临床问题的机会。机器学习和深度学习方法因其能够从原始数据中挖掘洞见的能力,被广泛应用于医疗信息学和医疗领域。在将深度学习模型应用于电子健康记录数据时,必须考虑其异构性:电子健康记录包含来自多种来源的患者记录,包括医学检测(如血液检测、微生物检测)、医学影像、诊断、用药、操作、临床记录等。这些疗法共同提供了患者健康状况的整体视图,并相互补充。因此,将本质上不同的多种模态数据结合起来,在电子健康记录的深度学习中既具有挑战性,又直观上充满希望。为评估多模态数据的预期,我们引入了一个综合融合框架,旨在整合时间变量、医学图像和临床记录,提升临床风险预测表现。采用早期、联合和晚期融合策略,有效整合来自多种方法的数据。我们用三项预测任务测试模型:住院死亡率、长期住院时间和30天再入院。实验结果表明,多模态模型在涉及的任务中优于单模态模型。此外,通过训练不同输入模态组合的模型,我们计算每种模态的夏普利值,以量化它们对多模态表现的贡献。研究表明,时间变量在三项预测任务中通常比CXR图像和临床记录更有帮助。
引言
电子健康记录(EHR)是一种纵向电子记录,包含关于患者健康的全面信息,包括结构化数据如人口统计、生命体征和实验室检测结果,以及非结构化数据,如临床记录和报告。它被用于有效且高效地组织健康记录1,并且如今已广泛应用。例如,美国的医疗系统每年服务超过3000万患者。在2008年至2015年间的七年间,非联邦急诊医院至少采用基础EHR系统的比例显著从9.4%提升至83.8%2。截至2021年,78%的门诊医生和96%的非联邦急诊医院采用了认证的电子健康记录系统3。由于普遍使用,EHR数据库涵盖了庞大人群的信息,为医疗研究人员开展数据驱动研究以改善人类福祉提供了绝佳机会4。由于近期的进展和成功,机器学习和深度学习技术在医疗行业中越来越受欢迎10、11、12。它们在从电子健康记录中获得有意义的见解方面具有巨大潜力,有助于准确预测临床结局,如死亡率13和再入院13、14。预测这些结局有助于早期发现患者生理恶化15,从而促进护理工作流程的优化。因此,许多研究利用深度学习技术开发基于电子健康记录的预测模型。通常,这些模型会检查生命体征、化验结果、既往诊断和用药信息。然而,在患者入院期间,临床记录和X光输出等其他方式中存在更多非结构化信息,这些信息可能对预测任务具有参考价值。因此,在预测过程中充分利用来自不同模态的互补数据以提升模型性能是一个直观的想法。本研究重点结合患者入院期间产生的多模态数据(即临床时间序列、胸部X光X光CXR和放射记录)与一般融合框架,以提升预测住院死亡率、长期住院时间和30天再入院的表现。我们引入了三种不同的融合策略,分别称为早期融合、联合融合和晚期融合,以整合这些异质数据模态。该模型使用 MIMIC-MM 数据集进行训练和测试,该数据集由 MIMIC-IV、MIMIC-CXR 和 MIMIC-IV-Note 数据集 5、6、7、8 组成。此外,我们利用Shapley值9来计算每种模态在训练过程中对预测任务的贡献。我们的实验结果显示多模态预测模型的优越性。
总结来说,我们的研究贡献包括:
• 我们提出了一种多模态融合框架,包含三种融合策略(早期、联合和晚期),将临床时间序列(如生命体征、实验室检测)与电子健康记录中的CXR影像和放射记录结合起来。
• 我们在真实世界数据集上进行实验,三项任务(即住院死亡率、长期住院和30天再入院)的实验结果显示,多模态模型优于单模态模型。
• 我们采用Shapley值来估算每种模态的贡献,结果显示所有模态都有助于风险预测,进一步证明了所提聚变策略的可行性和有效性。
相关工作
医学数据集是医院患者健康记录的庞大集合,通常涵盖患者健康状况的各个方面,如人口统计信息、实验室检测、生命体征、医学图像、诊断代码、笔记、治疗和用药史以及出院报告。在医疗领域,研究人员越来越多地将机器学习策略应用于多种医疗任务,如医疗预测建模、医疗建议、疾病诊断和医疗结果预测。
研究电子健康记录时间序列变量
有大量尝试利用电子健康记录(EHR)时间序列进行预测建模任务。RETAIN 10 应用RNN产生的反向时间注意力,生成就诊级和可变级注意力评分,用于嵌入临床时间序列的向量。它考虑诊断、用药和手术事件,生成输入向量。同样,Dipole16使用双向RNN将多次就诊嵌入结合起来。Med2Vec 11 通过挖掘就诊序列信息和医疗代码共现信息,从电子健康记录中学习了就诊级表示。通过预测未来医疗代码及其临床风险组(CRG)层级来测试 Med2Vec 的代表性。Med-BERT 12、BEHRT 17 和 G-BERT 18 采用基于 BERT 的框架进行电子健康记录特征提取,并用于诊断代码或用药预测任务。G-BERT 还考虑了 ICD-9 代码的层级医学本体结构,以增强嵌入效果。Ashfaq 等人 14 利用 LSTM 在已学习的 EHR 嵌入基础上预测 30 天再入院。工作于多模态数据输入。医学数据集表现出多模态特征,不同类型的数据如实验室检测和生命体征作为时间序列变量,医学图像和临床笔记作为非结构化文本。利用来自异构数据的互补信息是自然且有前景的19。Zhang等人13在MIMIC-III中将时间序列变量与非结构化临床记录整合,利用LSTM和CNN进行序列特征提取,进行预测建模任务。Golovanevsky等人20将临床测试成绩、遗传信息(SNP)和MRI扫描图像纳入阿尔茨海默病诊断。他们调整了跨模态注意力和自我注意力模块,以捕捉模态内和模态间的相关性。Huang等人21利用电子病历(EMR)和CT扫描图像检测肺栓塞,采用三种融合方法,发现晚期融合模态方法优于其他方法。Yao等人22将部分临床特征与CNN的3D CT图像特征串联,用于肺静脉梗阻(PVO)预测。他们还生成了显著性图,以确定模型关注的区域。作者声称多模态模型在肺部区域激活更为集中。Yan等23通过结合病理图像和29个选定特征进行乳腺癌分类。他们将多个CNN内层的隐藏状态串接为图像特征,应用去噪自编码器获得EMR特征,并将图像与EMR特征串接进行分类。Nie等24结合多通道医学图像、人口学信息和肿瘤相关特征,实现短期总体生存(OS)时间预测。Soenksen等人25提出了早期融合模型实验,利用表格数据、时间序列数据、文本注释和胸部X光片,用于胸部病理诊断、住院时长预测和48小时死亡率预测。先前研究表明,利用异质数据在提升下游任务表现方面具有巨大潜力,早期融合是最常见的模态融合方法,将多模态输入的不同特征直接串联为下游任务的聚合特征。此外,关节融合和晚期融合策略也存在于该领域,值得深入探讨。
因此,本研究对三种代表性风险预测任务13进行了实验,采用三种模态融合风格:早期融合、联合融合和晚期融合。任务和融合策略的详细定义见以下章节。此外,我们旨在量化每种模态在各任务中的贡献。受可解释人工智能(XAI)关于特征重要性解释和模型解释26, 27、28的研究启发,我们计算了三种模态的夏普利值以展示它们的贡献。
方法
在本节中,我们正式介绍我们的问题设置。首先,我们描述了作为模型输入的多模态数据**,包括静态特征、时间序列变量、CXR图像和放射学笔记**。接下来,我们介绍了神经网络的架构,包括数据嵌入、特征提取、模态融合和分类头。
多模态数据描述
患者人口统计
患者人口统计为患者提供了基本背景信息,包括年龄、性别等。我们利用年龄、性别、种族、婚姻状况、语言和保险状况,向预测模型提供患者的初始信息。为了增强模型的稳健性,我们将患者年龄分期10岁。因此,所有用于人口统计信息的变量都是类别性的。请注意,我们实验中的临床时间序列数据中包含了人口统计信息,因为数据集中所有数据均呈表格形式。
时间序列数据
从电子健康记录数据库中的表格患者记录中,我们输入三种类型的临床时间序列事件:
• 病历事件指患者在ICU期间发生的记录项目。这可能包括心率等生命体征,以及其他与健康状况相关的信息,如血氧饱和度、脉搏氧测量和格拉斯哥昏迷量表(GCS)。
• 实验室事件指的是为患者进行的实验室测量。比如,血液中的葡萄糖。
• 手术事件指的是ICU住院期间记录的操作,如通气。在现有研究25基础上,我们关注变量子集。对于图表事件,我们使用了原始特征列表中的6个数值生命体征和3个类别特征。实验活动中,我们重点关注22个实验题目。对于手术事件,我们会进行10项特定手术。完整的变量列表可见表1。
病历事件和实验室事件是临床变量,每个事件对应的是一个数值测量,比如血糖浓度,或者是类别性的测量,比如GCS分数,因此它们的意义是明确的。然而,手术事件是临床操作或干预,直觉上没有价值。因此,类别程序事件意味着该过程是一个瞬时移动,且很快结束,其值为二进制,表示是否在某个时间戳下执行。例如,"胸管拔除"事件表示在特定时间为患者拔除胸管。另一方面,数值程序事件表示连续过程持续一定时间,数值表示其持续时间。嵌入过程在第3.1.5节中有正式描述。
CXR数据
CXR数据包含患者入院期间拍摄的胸部X光图像。患者在入院期间可能进行多项医学放射学检查,并在一次检查中拍摄多张X光片。我们假设该图像系列包含患者健康状况进展的信息。因此,将CXR数据视为图像时间序列,而非仅仅拍摄最新的图像,更为合理。由于我们环境中90%的CXR图像是前后期,我们仅使用前后期图像作为CXR数据分支以便简便。
临床笔记
在患者入院期间,会有各种临床记录,包括他们的医学研究、诊断、出院报告等。例如,MIMIC-IV-Note数据集包含患者入院期间的放射科和出院记录。标识化的笔记和笔记日期均包含在非结构化自由文本中。由于出院记录可能包含死亡信息和诊断结果,我们直接从数据集中提取放射记录,以避免可能的过拟合和捷径。放射科笔记包含多种影像学方式的记录:X光、计算机断层扫描、磁共振成像、超声等。因此,它不仅是CXR疗法的补充,更是对患者入院的补充。
患者记录配置
数据集中的患者X通过患者ID和入院ID唯一标识。我们可以通过将临床时间序列、CXR记录和两个ID字段的Note记录结合起来,构建并形式化多模态患者记录。患者x的记录(记为Rx)是一个元组(Dx,Sx,Mx,Nx)。这里是Dx∈R|D| 是患者的人口统计信息,且 |D| 是用于人口统计信息的变量数量。为避免混淆,以下忽略用于患者识别的不必要下标。S=(c,l,p)是患者的临床时间序列,包含三种类型的事件:病历事件c、实验室检查l和手术事件p。c和l是两组变量,变量v是带时间戳值的集合v={(valuei,ti)|ti∈Tv},Tv是变量v的观察时间集合。变量可以是数值的,也可以是类别的。数值变量取值R,而范畴变量取有限集合取值。 p=(oi,oc) 是瞬时运算和连续运算的并集,oi 是形式为 (f,t) 的瞬时运算集合,这意味着运算 f 发生在时间 t; OC 是一组形如 (f,ts,te) 的连续运算,意味着运算 f 从 ts 开始,到 te 结束。M={(mi,ti)|ti∈R+}是患者的CXR记录,是一组带时间戳的CXR图像。这里的ti指的是图像mi的CXR检查时间。每个mi是一个三维张量mi∈RH×W×C,其中H、W、C代表高度、重量和通道。N={(ni,ti)|ti∈R+} 是患者的笔记记录,一组带时间戳的放射科笔记。 Ti表示患者记录的病历时间。 NI是一串去标识的临床笔记。患者记录概览见图1。简而言之,患者记录是静态人口统计信息和多变量时间序列(如临床系列、CXR影像系列、放射记录系列)的结合。
神经网络结构
本节介绍我们通用预测模型的设计架构。该模型可以分解为数据嵌入、单模态特征提取、时间序列表示、分类器和模态融合模块。我们将治疗方式融合三种不同策略:早期融合、关节融合和晚期融合。
特征Embedding
住院时间和事件数量因患者而异。每个变量的值区间也不同。因此,我们需要在将数据输入模型前进一步处理这些数据。此外,可变时间序列进一步嵌入到更具表现力的向量中。给定特定的患者人口统计学和时间序列(D,S),我们首先将它们合并并转换为:S′={(d,ct,lt,pt,t)|t∈R+},其中d∈R|D| 是人口统计学的向量,t是X临床时间序列的时间戳。 ct={(vi,vali)|vi=valiatt} 是图表事件中观测到的变量及其在时间 t 的值集合。 它是实验室事件的集合,形式与CT相同。 PT是患者在时间T时经历的一系列手术事件。在 t 处进行的瞬时过程在 pt 中发生一次,而连续过程则发生在所有在操作开始时间和结束时间之间具有 t 的 pt 中。临床时间序列转换后,我们使用三种嵌入方式:变量嵌入、值嵌入和时间嵌入29。变量嵌入将变量的含义编码成一个向量,不同变量有不同的嵌入方式。给定N个变量,变量v的嵌入是从其唯一热表示rv∈{0,1}N到向量ev=Wrv,W∈Rd×N的线性映射,其中d为嵌入大小。值嵌入将变量的值编码到向量中。对于类别变量,包括人口特征,价值嵌入是从其值区间到实值向量的映射。对于数值变量,我们将数值离散化为L个子区间,根据数据库中所有观测值,确保每个子区间包含相同数量的样本(等频分组)。因此,离散化的值在子范围内均匀分布。对于子范围 1≤l≤L ,嵌入向量 el∈R2k 中,定义为:ejl=sin(l×jL×k)ek+jl=cos(l×jL×k),其中 1≤j≤k 。因此,给定变量v=val在时间t,我们可以得到变量嵌入ev∈Rd ,值嵌入eval∈R2k ,其中d和2k为预定义的嵌入大小,我们设d=2k 。然后我们用线性函数将 ev,eval∈R2d 映射到 evar∈Rd,作为数值变量 v 值 val 事件的嵌入。这种嵌入策略适用于所有人口特征变量、图表事件、实验室事件和手术事件。然后我们尝试将时间戳融入嵌入过程。通过计算患者入院的相对时间,时间戳被转换为实数,因此可以离散化并嵌入为et∈Rd,采用与数值变量相同的嵌入策略。给定患者X,在时间t处可以观察到多个事件(变量)。我们使用自适应最大池来从这些嵌入中提取重要信息。回忆一下,对于任何观测变量及其值,我们都嵌入为 evar∈Rd 。因此,在时间t处观测变量的集合构成一个嵌入{evari|variobservedatt}的集合。通过叠加人口统计嵌入ED∈R|D|×d 和所有变量的嵌入,我们得到一个嵌入矩阵 ⁎ Etts=vstack(eD,evari),Etts∈R⁎×d,其中 ⁎ 由观测到的变量数决定。经过自适应最大池化,我们在时间t处得出嵌入为etts∈Rd 。然后我们将它与时间嵌入et连接,得到时间t处的最终记录嵌入为et′ts∈R2d。做CXR影像的过程很简单。原始的CXR图像是大灰度图像。为了将图像放入我们的ResNet特征提取器,我们将图像调整为224×224,并在3个输入通道上复制。之后,我们得到图像 m∈R3×224×224。对于自由文本笔记,典型的自然语言处理转换用于将自然句子转换为token列表。笔记中的所有单词都被转换为小写并标记化成单词序列,标点符号被去除。例如,句子如"腹泻和倦怠病史,现在伴随心脏骤停"变成一个序列:病史、病史、腹泻,以及,躁郁,现在,伴随心脏骤停。每个单词通过预定义的词典转换为整数,因此我们得到嵌入音符 n∈NL,这里 L 表示音符长度。经过这样的嵌入过程,我们得到了每种模态的张量表示。然后我们使用不同的骨干神经网络从这些模态中提取特征向量。
模态特征提取
数据嵌入后,我们利用神经网络架构从中提取特征并生成特征向量进行分类。临床时间序列特征更与时间维度相关。因此,我们采用双向LSTM网络来实现长期信息的回忆。如上所述,嵌入过程后,时刻t的记录可以表示为et′ts∈R2d。因此,对于任意患者X,我们有Ets∈RTts×2d,其中Tts是临床时间序列中的时间戳数。我们把它放进了双向LSTM网络。该程序可以描述如下:
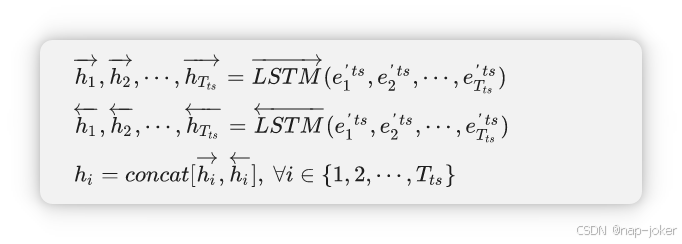
这里的LSTM→和LSTM←分别是双向LSTM的前向传递和后向传递。 hi→,hi←∈Rd,hi∈R2D。在LSTM层之后,我们通过最大池化保留序列中最重要的信息h1,h2,......,hTts,并将输出作为从临床时间序列中提取的最终特征向量。
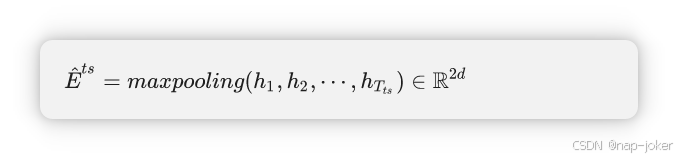
我们使用ResNet进行图像特征提取。ResNet 的原始分类头被替换为线性层,从卷积层的输出生成特征向量。之后,图像mi会转化为向量EMI∈R2d。对于任何患者X,我们得到Ecxr∈RTcxr×2d,作为不同时间戳下的CXR图像特征,这里Tcxr是CXR图像的数量。之后,我们根据时间戳与患者入院时间之间的间隔,对Tcxr特征向量进行加权求和。给定图像特征为 Ecxr=(em1,em2,⋯,emTcxr)T∈RTcxr×2d 及其从入院 t1,t2,⋯,tTcxr 的时间间隙,其加权时间和定义为:
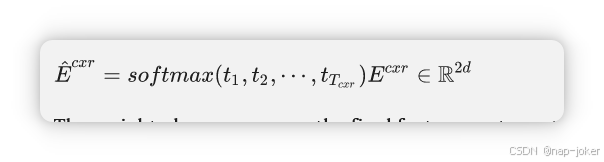
加权和作为从CXR记录中提取的最终特征向量。根据softmax函数,最新的图像特征权重最大,且随着时间间隔的增加,权重呈指数衰减。对于自由文本笔记,我们训练一个包含放射学笔记的Doc2Vec模块30,作为自由文本模态的特征提取器,将标记序列ni映射到表示向量eni∈R2d。对于患者X,Enote∈RTnote×2d被生成为对应患者笔记序列的特征向量时间序列。 Tnote是临床笔记的数量。给定特征序列,我们进一步捕捉LSTM网络中的元素相关性和序列特征31。给定Enote=(en1,en2,‐,enTnote)T∈RTnote×2d,我们通过LSTM网络输入,并对所有隐藏状态进行最大池化,生成包含整个序列信息的单一特征向量:
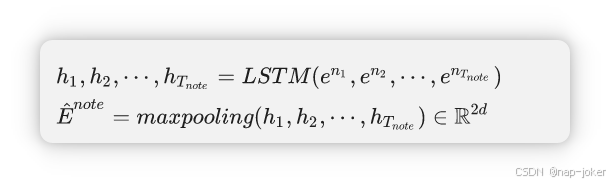
分类层
分类器是在提取的特征之上构建的,将其分类为负类和正类。这两个类别的含义因我们所从事的预测任务而异。例如,在院内死亡率预测中,负值表示患者出院时仍然存活,正值则相反。我们对所有模型设置都采用线性分类器。线性分类器只是形如以下的全连通层:

其中 Wcls∈R2d×2 是权重,b∈R2 是偏置。输入x取决于我们使用的聚变方法。联合或早期融合时,x=sumEˆts,Eˆcxr,Eˆnote。在晚期融合中,这三种模态分别有自己的分类器,结果被平均以形成最终输出,因此 x=Eˆm,m∈{ts,cxr,note} 。我们将在第3.2.4节中进一步解释融合方法。分类器的输出后跟软极大函数,以获得每个类别的预测概率,交叉熵用于测量分类损失。
模态融合
基于从前一步提取的特征向量,灵感来自Kline等人19,并遵循32的定义,我们采用三种融合策略将事件时间序列特征、CXR特征和放射记录特征融合,以生成预测。这些方法包括早期融合、联合融合和晚期融合。
早期融合
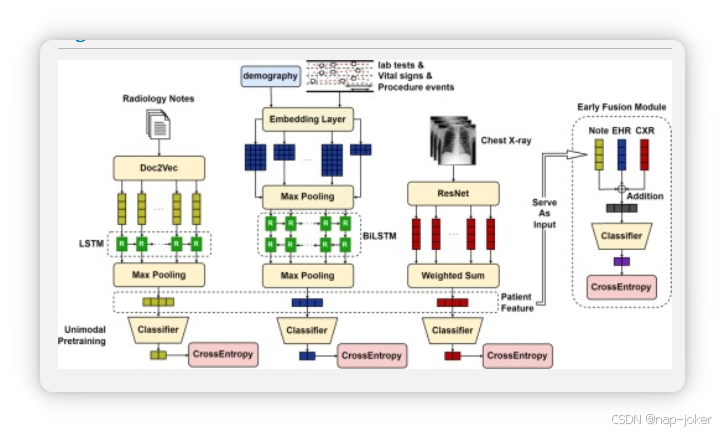
图2。早期聚变模型结构。每种模态的特征提取器会提前针对目标任务进行训练。经过单独训练的收敛,固定在测试数据集中AUROC得分最高的提取器,从每个患者样本中提取患者特征。这些特征用于训练最终分类器。
早期融合将来自多种模态的特征向量合并,然后将它们输入分类网络。实际上,我们直接将不同模态的特征相加,形成多模态特征矢量。之后,我们把数据输入分类器,得到分类结果。在这种情况下,分类层的输入维度与单模态特征维度相同,而在我们的情况下是二维。对于任何预测任务,特征提取器分别对每种模态进行训练,并使用它们各自的分类器。在分别预训练后,我们固定特征提取器,并融合不同模态的特征向量以训练多模分类器。该过程如图2所示。
联合融合
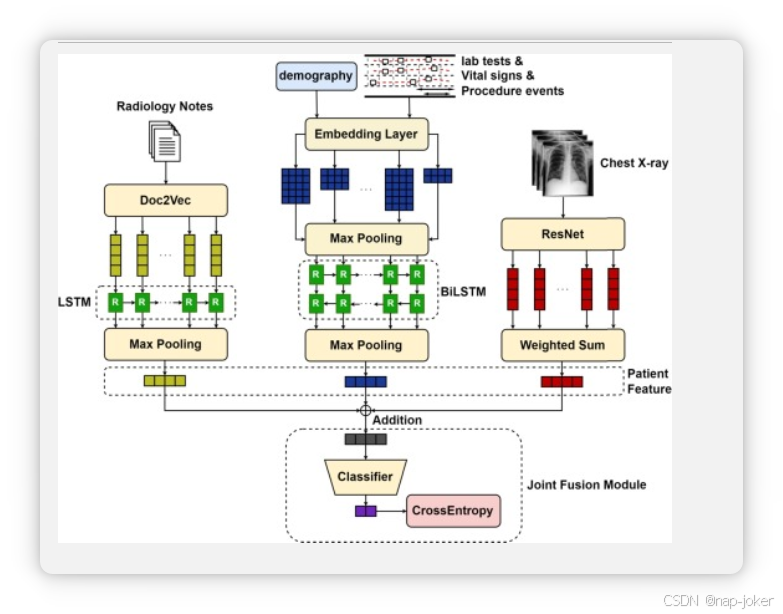
联合融合结合了不同神经网络中间层的学习特征,适用于不同模态。这里联合融合和早期融合的区别在于,早期融合利用了各自模态预训练的不变特征,而联合融合则训练一个端到端模型,将梯度从多模态分类器传播到每个特征提取器。网络结构几乎与早期聚变相同,但训练策略不同。这里还使用直接加法来构造多模特征向量,因此分类层的输入维度也是二维的。关节融合的结构如图3所示。
晚期融合
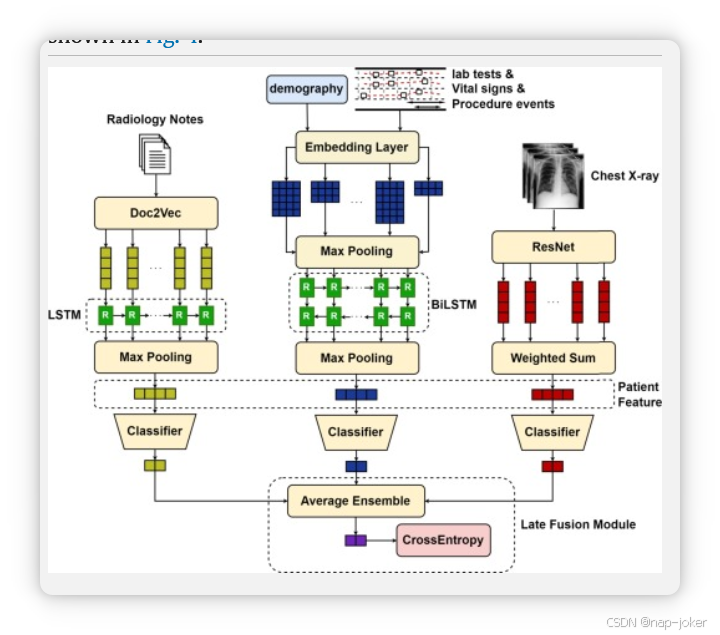
图4。晚期融合模型结构。每个特征提取器对应每种模态都附有三个分类器。三种模态的预测通过计算平均值汇总,得出最终预测。晚期聚变模型也采用端到端训练方式。
晚融合分别训练不同的模态分类器,并将其单模态预测结合形成全局多模态预测。该策略类似于集合学习,也称为决策层融合。预测组装有多种风格,我们在实现中选择平均化。该策略如图4所示。
现在我们可以对多模态预测模型做出结论。正如图2、图3、图4所示,原始数据经过嵌入、特征提取、模态融合和分类以生成最终预测。请注意,该模型能够处理缺失模态。例如,如果患者没有CXR记录,我们可以在融合阶段忽略CXR特征提取器和CXR分类器,而无需改变网络架构,使用另外两种模态生成预测。
实验和讨论
数据描述
重症监护医疗信息中心IV(MIMIC-IV)包含2008年至2019年间入住贝斯以色列女执事医疗中心(BIDMC)患者的住院数据。我们的实验使用MIMIC-IV的1.0版本。MIMIC-IV分为五个部分:核心部分(患者住院信息)、医院(实验室和微生物数据)、ICU数据(ICU住院及事件详情)、急诊科和CXR(加入MIMIC-CXR的查询表)。我们使用MIMIC-IV 1.0版本中的临床时间序列和患者人口统计数据,提及临床时间序列时,也包括人口统计数据。MIMIC-CXR是一个庞大且公开访问的患者胸部X光数据库,收集自2011年至2017年间的BIDMC急诊科。包含227,835项X光检查,涵盖64,588名患者。单项研究可包含多张从不同视角拍摄的图像,总计377,110张X光片。此外,每项研究均附有研究时创建的自由文本放射报告。MIMIC-IV-Note是MIMIC-IV在自由文本临床笔记上的扩展。使用相同的纳入标准,MIMIC-IV-Note为每位患者入院提供去标识放射学记录和出院记录。其中包含来自145,915名入院患者的331,794份非标识出院摘要和237,427名患者的2,321,355份非识别放射报告。数据库中的所有记录均可通过患者和入院ID编号与MIMIC-IV关联。我们使用MIMIC-IV-MM 25来训练模型。MIMIC-IV-MM通过将MIMIC-IV、MIMIC-CXR和mimic-iv-NOTE在患者主体ID、住院ID和ICU住院ID三元组中组合生成。数据集中的患者记录被对齐形成本研究中的通用多模态患者记录。MIMIC-IV-MM可视为三者数据集的交集。因此,我们的研究只包含所有数据集中记录的患者。尽管患者在ICU住院期间可能缺少某些模态,如前所述,我们的模型能够在融合阶段忽略缺失的模态。然而,在训练模型时,我们假设所有模态对每位患者均可用。此外,一个人可能有多次住院记录。然而,我们将同一人的不同入院视为不同患者,以简化考虑两者之间的潜在相关性。
队列准备
基于MIMIC-IV、MIMIC-CXR和MIMIC-IV-Note数据集,我们评估了基于入院后48小时内记录的住院死亡率预测、长期住院预测和再入院预测的模型。包含所有三种治疗方式的患者。在这些患者中,入院前48小时内无事件记录的患者将被移除。之后,剩余11,636名独立患者,类别分布见表1。针对特定任务的额外排除标准将在下文预测任务部分介绍。
预测任务
我们对三个预测问题进行了实验来测试模型。它们都是二元分类问题。这些问题的详细定义如下。
院内死亡率预测
院内死亡率被视为关注的关键结局。该任务的主要目标是预测患者是否会在住院期间死亡。对于任何患者,我们使用入院后48小时内的事件、图像和笔记作为预测模型的输入,生成二元分类,指示患者出院时是否去世。我们报告F1分数、接受者工作特征曲线下的面积(AUROC)、正类的精度回忆曲线下的面积、精度、回忆率以及整体准确率,以衡量模型在该任务中的表现。
住院时长预测
患者住院时间指的是从患者入院到出院的时间长度。识别可能的长期住院有助于医院资源管理。为简化起见,我们将住院时间问题形式化为二元分类。模型通过观察到的事件、图像和记录,在入院前48小时内尝试判断患者是否会在医院停留超过7天33。阳性样本为住院超过7天的患者,其他所有患者为阴性样本。同样的标准(AUROC、AUPRC、精度、回忆、准确性)用于评估模型表现。为明确展示方法间距,我们排除住院时间少于3天的患者。
医院再入院预测
据报道,美国13%的住院患者通过再入院消耗了超过一半的医院资源34。因此,建立预测模型有助于更好地预防再入院和提高患者满意度。我们将医院再入院定义为首次出院后30天内的非计划性入院13,这是一个二元分类任务。收集入院后48小时内的患者数据记录,以预测患者是否会在出院后30天内再次入院。同样的标准(AUROC、AUPRC、精度、回忆、准确性)用于评估模型表现。
实施详情
该模型采用PyTorch 1.13.1实现。所有实验配置均使用加权交叉熵损失作为损失函数,负类为1,正类为10。在CXR部分模型中,正类权重为15,这里的"部分"意味着模型仅使用胸部X光图像进行训练。模型在收敛约20~30个纪元前,使用Adam优化器以0.001的学习率进行优化。每种模态特征向量的大小设为512。评估时,我们采用了0.70-0.15-0.15的训练-验证-测试分割,遵循前述工作13。不过,我们对验证集和测试集的大小进行了均衡调整,以更好地估计验证集的测试性能。我们根据患者ID和入院ID将数据集拆分,确保训练、验证和测试集之间没有重叠。我们在验证集上使用AUROC进行早期停止。在每个时代,模型都会被训练和验证,验证集上AUROC分数最高的模型会被保存并选定为最终输出模型。之后,在测试集上用保存的模型测试结果,而测试集在训练时从未使用。
结果
本节展示了所提出模型在三项任务上的表现结果:院内死亡率预测、长期住院预测和住院再入院。对于模态消融研究,我们将临床时间序列视为主要模态,CXR和临床笔记为附加模态。因此,除了三个单模实验外,我们还在TimeSeries + CXR(T + C)、TimeSeries + Note(T + N)和TimeSeries + CXR + Note(T + C + N)上进行实验。单模模型在表格中标注为"部分"。为验证不同模型设置间的性能差距,我们在每对模型设置间进行了统计检验。我们在AUROC上进行了跨不同模型的t检验,并报告了比较的p值。我们还用两个基线模型RETAIN 10和Dipole 16比较了最佳多模态模型。我们在相关研究中包含的其他电子健康记录模型是基于语言建模的预训练模型,我们认为它们与我们的框架不一致。展示性能指标后,我们提供Shapley值作为衡量每种模态在训练过程中贡献的指标。
模型表现
结果见表2、表3、表4。每列最佳表现以加粗显示,多个前一表现分数均加粗。表中显示,临床时间序列在单模模型中效果更好,可能是因为生命体征和实验室检测包含更多关于患者整体健康状况的信息,这对三项任务更有利。不过,通过其他模式可以提升表现。其他模式的提升效果在三种融合策略中也保持一致。
基线模型的性能见表5。"部分"表示表2、表3、表4中临床时间序列的部分模型。"多模态"表示每个任务AUROC最高的多模态模型。每个任务的最佳性能分数以加粗显示。结果显示,RETAIN10和Dipole16在死亡率和再入院预测方面优于我们的临床时间序列部分模型,但在长住院任务中表现不佳。与此同时,多模态模型在三项任务中明显优于单模态基线。我们认为这一优势来自多模态带来的额外信息。
统计检验
我们进行了统计t检验,以验证融合方法模型对与部分模型之间的比较。结果见表6、表7和表8。p值低于0.01的在表中表示为"<0.01"。我们可以观察到大多数模型对之间的AUROC差异在p值较低时显著。
Shaply值计算
Shapley值是合作博弈论中的一个概念,它根据玩家的边际贡献将玩家联盟获得的总剩余分配给每个联盟成员。该值由一组公理约束,使其成为满足约束条件的唯一解。这一概念也被广泛应用于可解释人工智能26、27、28,以解释特征和样本等的贡献。在我们的案例中,我们的目标是衡量每种模态信息对训练模型在训练过程中表现(AUROC)的贡献。设N={t,c,n}为模态集,其中t表示临床时间序列,c表示CXR图像,n表示放射记录,我们定义一个函数v:2N→R表示用一组模态训练时的AUROC表现。例如,v({t,c}) 是用临床时间序列和 CXR 图像训练模型的 AUROC 分数,忽略放射记录。根据 Shapley 值的概念,我们通过有无该模态训练时模型表现分数的差值计算出某一模态的边际贡献。因此,v({t,c,n})−v({t,c}) 表示训练过程中放射记录的边际贡献。某些模态 m 的 Shapley 值是通过 m 在所有可能模态子集中的边际贡献加权求得。它可以表述为:
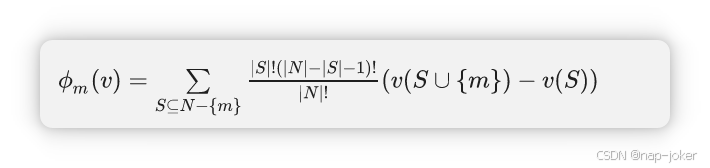
如公式所示,Shapley值可视为所有v(S),S⊆N的加权和。我们分别计算不同融合策略和任务中AUROC分数的Shapley值。Shapley值具有许多性质,其中之一称为效率规则:∑m∈Nφm(v)=v(N) 。这意味着所有模态的Shapley值加总为获得的利润。因此,我们可以将模态的Shapley值归一化为1,然后归一化后的Shapley值显示博弈中每种模态的贡献比例,并可在不同融合策略和任务的试验间进行比较。计算Shapley值需要对模态集N的所有可能子集(包括空集)进行AUROC。我们假设空集上的AUROC为0。每种模态在三种任务上的归一化夏普利值如图5所示。
图5。不同任务和融合方法路径中,AUROC分数中每种模态的Shapley值。子图呈网格排列。三行对应三个任务,三列对应三种融合方法。三种模态的原始Shapley值经过归一化,使其总和为1,表示该模态在模型表现中的百分比贡献,从而允许试验间比较。图中缩写:TS - 时间序列,CXR - 胸部X光。
讨论
值得指出的是,评估时会报告F1分数、精度、召回率、准确性、AUROC和AUPRC数据。其表现高度依赖任务,依赖数据集的分布。我们可以从上述实验结果中获得若干见解。单模态性能比较。在单模模型中,临床时间序列训练的模型在三种任务中均优于图像和笔记。尽管临床时间序列在30天再入院预测中的AUROC略低,但在其他表现指标上,其表现明显领先于另外两种模式。可能原因是临床时间序列数据包含能直接反映患者健康状况的重要特征。例如,心率异常直接表明健康状况不佳。另一方面,仅靠CXR图像可能不足以准确预测死亡率、长期住院时间和30天再入院。原因可能是CXR图像仅显示肺部状况,无法全面反映患者整体健康状况。多模态性能提升。普遍趋势是,多模态输入模型往往获得更高的AUROC和AUPRC分数,原因是来自多个来源的互补信息,尽管临床时间序列部分模型在F1评分、精度、召回率和准确性方面均可比。此外,拥有三种模态的模型在许多情况下通常表现优于拥有两种模态的模型,即使效果不佳,结果也相当。然而,某些模态可能具有毒性,例如早期融合设定中30天再入院预测的笔记。可能原因是这些记录噪声较大,当在早期融合设置中禁用进一步微调时,可能会使模型感到困惑。融合策略比较。关节融合在AUROC和AUPRC指标上优于早期和晚期融合,可能得益于其精细调优的特征表示。此外,关节融合的参数较晚期融合少,有助于缓解过拟合问题。没有单一策略主导所有测试的性能指标,表明模型性能没有一致趋势。然而,F1分数、精度、召回率和准确性对分类阈值敏感,而AUROC和AUPRC则不依赖阈值。因此我们更倾向于使用关节融合,因为它往往是AUROC和AUPRC上最佳或至少可比之的。此外,关节融合结构更灵活,可以选择不同层次的特征进行融合,赋予关节融合潜力,以结合不同模态的信息。模态贡献讨论。图5显示,临床时间序列变量对三项任务的贡献最大,而CXR贡献最小。每种任务的三种融合方法的贡献分布趋于一致,但不同任务略有差异。在死亡率预测方面,临床时间序列贡献超过43%,而CXR和笔记贡献较低,分别为23%和33%。对于长期住院预测,也存在贡献缺口,时间序列-笔记-CXR的贡献分布为0.41-0.33-0.26。对于30天再入院,贡献分布在不同融合策略间差异较大,但时间序列仍优于另外两种方式。我们认为这是因为患者在入院期间可能只有一到两张胸部X光和放射记录,而住院期间有数十项临床变量观察。这种频率差异使临床时间序列对患者健康状况更具信息量。
总结
本文引入了一个通用框架,可将临床时间序列、医学影像和临床笔记整合到电子健康记录中,并与三种不同的融合策略相结合,并为下游预测任务生成特征向量。三项预测任务的表现表明,额外的模态能提升预测任务的性能。此外,通过计算每种模态与夏普利值的贡献比例,我们发现临床时间序列在这三项任务中最有帮助。请注意,所提出的框架可轻松适应现有的风险预测模型和风险预测相关任务。该框架也兼容除直接求和外的更高级融合方法。例如,我们可以尝试加权和积或张量积来合并不同模态的特征向量。也值得探索,从输入数据样本中生成更细粒度的变量和像素贡献解释。我们认为模型的优势在于能够结合不同模态并具备可扩展性,以配合更多其他模态。然而,我们当前研究的一个局限是我们专注于MIMIC-IV数据集------一个单一站点数据集,这可能不足以实现具有代表性的患者分布。此外,MIMIC-IV数据集规模庞大且全面,提供了丰富的多模态数据用于训练模型。然而,对于相对较小的数据集,我们框架的性能可能会受到缺失值和缺失模态率较高的影响。