文字识别模型onnx的输入输出如下:
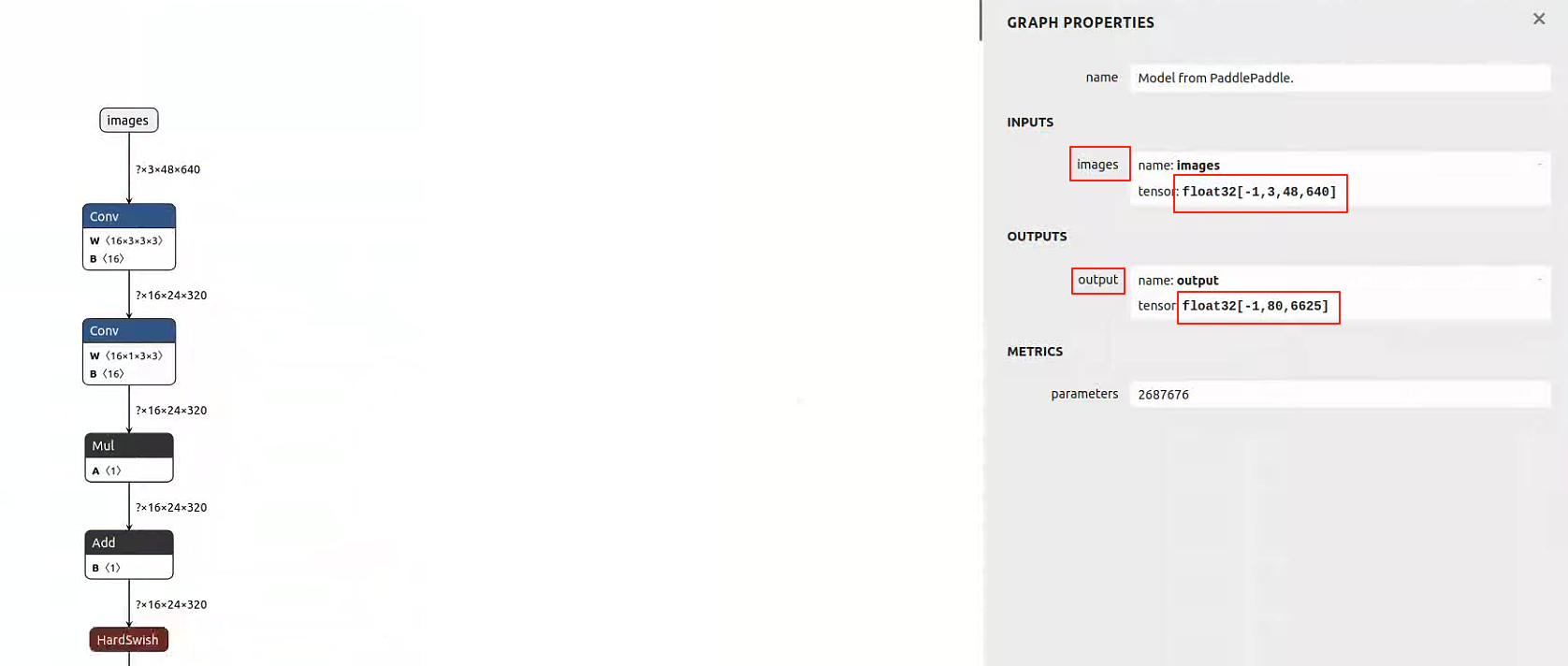
-
模型输出维度 :
[batch_size, 80, 6625]80:时间步(max_chars)6625:词表大小(vocab_size)
-
词表结构 (通过
loadCharDict()构建):cppm_char_dict.push_back("#BLANK#"); // 索引 0 → CTC blank while (getline(file, line)) { m_char_dict.push_back(line); // 索引 1 ~ 6623 → 6623 个有效字符 } m_char_dict.push_back(" "); // 索引 6624 → 空格- 总大小:
1 + 6623 + 1 = 6625✅ - 索引 0 是 blank,索引 6624 是空格
- 总大小:
-
ArgMax 范围:
-
代码中:
cppint argmax_idx = 0; float max_value = p_step[0]; for (int j = 1; j < vocab_size; ++j) { ... } -
这实际上遍历了全部 6625 个维度 (因为初始值是
p_step[0],循环从j=1到6624) -
✅ 包含索引 0(blank)和索引 6624(空格)
-
-
解码时跳过 blank:
- 通过
if (argmax_idx > 0 && ...)实现 - ✅ 空格(索引 6624)会被保留
- 通过
🧠 整体解码思路:CTC Greedy Decoding
输入
- 模型原始输出:
float output[batch_size][80][6625]- 每个
[80][6625]块对应一张图像 - 每个时间步
t ∈ [0,79]输出一个 6625 维 logits 向量
- 每个
输出
std::vector<TextLine>,每个TextLine包含:.text:识别出的字符串(如"粤B88888").score:平均置信度(0~1)
🔁 后处理流程详解(逐步骤)
步骤 1️⃣:遍历每个样本(batch)
cpp
for (int i = 0; i < batch_size; ++i) {
float* parray = p_output + i * 80 * 6625;- 定位到当前图像的输出数据块
步骤 2️⃣:对每个时间步做 ArgMax
cpp
for (int t = 0; t < 80; ++t) {
float* p_step = parray + t * 6625;
// 找出概率最大的类别索引(0~6624)
int argmax_idx = 0;
float max_value = p_step[0];
for (int j = 1; j < 6625; ++j) {
if (p_step[j] > max_value) {
max_value = p_step[j];
argmax_idx = j;
}
}- 结果 :得到长度为 80 的整数序列,如
[0, 0, 27, 27, 27, 0, 64, 64, ..., 6624]
步骤 3️⃣:CTC 解码(去 blank + 去重)
cpp
if (argmax_idx > 0 && !(t > 0 && argmax_idx == last_index)) {
// 加入字符
result.text += m_char_dict[argmax_idx];
}
last_index = argmax_idx;规则解释:
| 条件 | 作用 | 示例 |
|---|---|---|
argmax_idx > 0 |
跳过 blank(索引 0) | 0 → 忽略 |
!(t > 0 && argmax_idx == last_index) |
折叠连续重复字符 | [..., 27, 27, ...] → 只取第一个 27 |
💡 注意:
- 空格(索引 6624)满足
argmax_idx > 0→ 会被保留- 如果出现
[6624, 6624]→ 第二个空格被去重 → 结果只有一个空格
步骤 4️⃣:安全与评分
- 索引越界检查:防止模型输出非法索引
- NaN/Inf 过滤:避免数值异常
- 平均置信度 :
score = sum(max_value) / count
📊 完整示例演示
假设某图像的 ArgMax 序列为(只展示前 10 步):
| t | argmax_idx | 字符 | 是否加入 | 说明 |
|---|---|---|---|---|
| 0 | 0 | #BLANK# | ❌ | blank 跳过 |
| 1 | 27 | '粤' | ✅ | 首次出现 |
| 2 | 27 | '粤' | ❌ | 与上一重复 |
| 3 | 0 | #BLANK# | ❌ | blank |
| 4 | 64 | 'B' | ✅ | 新字符 |
| 5 | 64 | 'B' | ❌ | 重复 |
| 6 | 32 | '8' | ✅ | 新字符 |
| 7 | 32 | '8' | ❌ | 重复 |
| 8 | 32 | '8' | ❌ | 重复 |
| 9 | 6624 | ' ' | ✅ | 空格(有效字符) |
最终文本 :"粤B8 "(注意末尾有空格)
⚠️ 关键注意事项(再次强调)
-
ArgMax 覆盖全部 6625 维
- 虽然循环从
j=1开始,但max_value初始化为p_step[0]→ 索引 0 被包含 - 空格(6624)也被包含
- 虽然循环从
-
只有 blank(索引 0)被跳过
- 所有其他索引(包括 6624)都是有效字符
-
t > 0是必要的边界保护- 确保第 0 个时间步不会因
last_index初始值被误判为重复
- 确保第 0 个时间步不会因
-
该逻辑适用于 CTC 模型
- PaddleOCR 默认使用 CTC Loss,因此此解码正确
✅ 总结:输入 → 输出映射
| 阶段 | 输入 | 处理 | 输出 |
|---|---|---|---|
| 模型推理 | 图像 [3, H, W] |
CNN + RNN/Transformer | Logits [80, 6625] |
| ArgMax | Logits | 找每列最大值 | 索引序列 [80](0~6624) |
| CTC 解码 | 索引序列 | 去 blank + 去重 | 字符串(如 "粤B88888") |
这套流程高效、鲁棒,是工业 OCR 系统的标准实践。