目录
- Δ前言
- 一、拾枝杂谈
-
- 1.最初的方案:采用Surya
-
- [1.1 Surya是什么?它是如何处理OCR的?](#1.1 Surya是什么?它是如何处理OCR的?)
- [1.2 Surya和Paddle相比是什么关系?各自的特点是什么?](#1.2 Surya和Paddle相比是什么关系?各自的特点是什么?)
- [2.关于配置 Surya 时踩过的坑:](#2.关于配置 Surya 时踩过的坑:)
-
- [2.1 Miniconda 部署 Surya 时踩的坑](#2.1 Miniconda 部署 Surya 时踩的坑)
- [2.2 Docker 拉取 Surya镜像 时踩的坑](#2.2 Docker 拉取 Surya镜像 时踩的坑)
- [3.为什么 up 最终放弃了Surya](#3.为什么 up 最终放弃了Surya)
-
- [3.1 核心原因](#3.1 核心原因)
- [3.2 经验教训](#3.2 经验教训)
- 二、正片开始
-
- 1.项目介绍
-
- [1.1 项目用到的技术](#1.1 项目用到的技术)
- [1.2 项目实现的功能](#1.2 项目实现的功能)
- 2.使用步骤
-
- [2.1 创建虚拟环境](#2.1 创建虚拟环境)
- [2.2 安装组件](#2.2 安装组件)
- [2.3 测试环境是否就绪](#2.3 测试环境是否就绪)
- [2.4 执行命令(开始跑我们的模型)](#2.4 执行命令(开始跑我们的模型))
- [2.5 执行 Python 脚本:分门别类整理结果](#2.5 执行 Python 脚本:分门别类整理结果)
- 3.常见问题
- 4.讨论 (DISCUSSION)
-
- 为何选择"逐页处理"而非"整本输出"的处理逻辑?
- [为何运行paddleocr模型时,提示大量的"Model files already exist. Using cached files"?](#为何运行paddleocr模型时,提示大量的“Model files already exist. Using cached files”?)
Δ前言
- 大家好,最近 up 在处理一个通过 OCR 处理 PDF 文档的问题,说人话就是用一个叫作"OCR"的技术去批量扫描 PDF 文档,并将其转换为自己需要的格式(如docx, markdown等),正好踩了不少坑,这里 up 把踩过的坑,以及最后经过验证得到的一套行之有效的方法分享给大家,大伙儿有雷排雷,无雷看个乐呵。
- 文章中的教程部分,以及设计到的源码,up 已经完整放在了 Github 上,Github地址 :++*https://github.com/TYRA9/Paddle-OCR*++。大家如果觉得有用的话,可以帮忙点歌Star.
- 良工不示人以朴,up所有文章都会适时补充完善。大家如果有问题都可以在评论区进行交流或者私信up。感谢阅读!
一、拾枝杂谈
1.最初的方案:采用Surya
1.1 Surya是什么?它是如何处理OCR的?
- up 一开始用的OCR模型其实并不是Paddle,而是Surya。Surya 是一个开源 的多语言文档 OCR工具包,支持90多种语言的文本识别、布局分析和阅读顺序检测,性能可与商业云服务相媲美。
- Surya 底层采用改进的CRNN与Transformer混合架构,同时吸取了CNN和RNN的优点。
- Surya 的处理流程大概是:PDF/图像 → 布局检测 → 文本行检测 → 文字识别 → 阅读顺序排序 → 输出JSON文件。
1.2 Surya和Paddle相比是什么关系?各自的特点是什么?
一句话总结 :Surya的检测和识别模型本身质量不错,但其阅读顺序算法在处理 双栏 或者 三栏 等复杂版面文本时,容易发生左右栏内容混杂。而 Paddle-OCR 的 PP-StructureV3 从模型层面解决了这个问题,这也是 up 最终放弃Surya的直接原因。
2.关于配置 Surya 时踩过的坑:
2.1 Miniconda 部署 Surya 时踩的坑
- ModuleNotFoundError: No module named 'surya.ocr' :
- 问题:升级到Surya 0.9.0后,脚本中的 from surya.ocr import run_ocr 报错找不到模块。
- 原因:Surya 0.9.0的API结构发生改变,run_ocr的导入路径发生了变化。
- 方案:降级到Surya 0.6.0(API稳定的版本)。
- KeyError: 'encoder' :
- 问题:加载 Surya 的识别模型时报错 KeyError: 'encoder'。
- 原因:Surya 0.6.0依赖的transformers库版本与当前环境中的版本不兼容。新版transformers解析Surya模型配置文件时对缺失字段的处理更严格。
- 方案:将transformers降级到4.37.2版本。但随后又遇到新问题------Surya 0.6.0明确要求transformers>=4.41.0,降级后产生新的版本冲突。最终通过安装中间版本transformers==4.44.2暂时规避。
- AttributeError: 'str' object has no attribute 'mode' :
- 问题:调用run_ocr时传入PDF路径字符串报错。
- 原因:Surya 0.6.0的run_ocr函数不接受PDF文件路径,只接受PIL.Image对象列表。而新版本(0.17.x)可以直接传PDF路径。
- 方案:修改脚本,先用pypdfium2将PDF每一页转为PIL.Image对象,再传入run_ocr。
- AssertionError(批处理bug) :
- 问题:OCR识别正常完成,但在保存JSON时抛出AssertionError。
- 原因:Surya 0.6.0内部批处理逻辑存在已知bug,在处理纯中文无空格文本时容易触发。
- 方案 :改为逐页单张处理模式,设置batch_size=1,避开批处理逻辑。
- TypeError: Object of type OCRResult is not JSON serializable :
- 问题:json.dump(all_predictions)失败,提示OCRResult对象无法序列化。
- 原因:Surya返回的OCRResult是自定义对象,不能直接用json.dump序列化。
- 方案:从ocr_result.text_lines中逐行提取文本内容,只保存纯文本和坐标信息。或改用命令行工具surya_ocr直接输出JSON文件,再在脚本中读取。
- pydantic版本冲突(最终无解) :
-
问题:在尝试使用surya_ocr命令行时,报错:
bashpydantic_core._pydantic_core.ValidationError: 1 validation error for ColumnLine polygon ... Input must be either a bbox [x_min, y_min, x_max, y_max] or a polygon with 4 corners -
原因 :Surya 0.9.0依赖pydantic<2.6.0,但环境中pydantic被其他包(如pdftext、pydantic-settings)强制升级到了2.13.0。这种间接依赖冲突导致Surya内部数据校验失败。尝试降级pydantic时,又触发了其他包的版本要求(pdftext要求pydantic>=2.7.1),形成依赖死锁。
-
方案:直接润了,这还玩鸡毛?
-
2.2 Docker 拉取 Surya镜像 时踩的坑
-
Surya 官方镜像不存在 或 提示Docker需要登录 :
-
问题 :
bashdocker pull vikparuchuri/surya:latest-cuda Error: pull access denied for vikparuchuri/surya, repository does not exist or may require 'docker login' -
原因:Surya官方没有发布预构建的Docker镜像到Docker Hub。vikparuchuri/surya这个仓库根本不存在。
-
方案:寻找社区维护的镜像,up 最终找了一个可用的镜像叫xiaoyao9184/surya:latest。
-
-
--langs参数不存在 :
-
问题 :
bashError: No such option: --langs Did you mean --images? -
原因:up 拉取的Docker镜像 xiaoyao9184/surya 镜像内置的Surya版本较旧,命令行参数名与新版不同。
-
方案:改用--images参数,并移除--langs zh。
-
-
命令成功执行但输出目录为空 :
- 问题:Docker命令运行完成,ocr_results下却只有空文件夹。
- 原因:Surya旧版本的输出结构不同于预期。当我们使用--images --output_dir参数时,它把汇总的results.json存到了input子文件夹下,而不是直接放在输出目录根路径。
- 方案:找到.../ocr_results/input/results.json,该JSON文件包含了所有PDF的完整识别结果。
-
WSL2磁盘迁移失败 :
-
问题:
failed to move WSL disk: creating directory to move file: mkdir D:\Docker\mirrors\DockerDesktopWSL: Access is denied. -
原因:Windows权限设置导致Docker Desktop无法在D盘自动创建嵌套目录。
-
方案:手动赋予Everyone完全控制权限,或以管理员身份运行Docker Desktop。部分情况下需要改用WSL命令行手动迁移(wsl --export / wsl --import)。
-
-
Docker Desktop引擎启动失败 :
- 问题:迁移数据后Docker Desktop卡在"正在加载引擎",无法启动。
- 原因:迁移后WSL2虚拟磁盘(ext4.vhdx)未能正确挂载,文件权限或路径问题导致。
- 方案 :以管理员身份运行
wsl --shutdown;手动执行挂载:wsl.exe --mount --bare --vhd "D:\Docker\...\ext4.vhdx";重新启动Docker Desktop
3.为什么 up 最终放弃了Surya
3.1 核心原因
- Surya 0.6.0/0.9.0的阅读顺序算法在处理多栏PDF时存在根本性缺陷------它输出的text_lines顺序是左右栏交替混杂的,而非先左栏后右栏,更何况还有那种上下分栏左右又分栏的情况。即使通过后处理脚本按坐标重排序,对于"上下分区且各自分栏"的复杂版面,简单的X/Y坐标划分仍会失效。
- 相比之下,PaddleOCR的PP-StructureV3从模型层面解决了阅读顺序问题,输出的Markdown文件直接就是正确的语义顺序,无需任何后处理。
3.2 经验教训
- 对于依赖管理复杂的开源工具(如Surya),不适合直接在宿主Python环境中安装,应优先使用Docker。
- 但Docker也需官方镜像支持,否则社区镜像的兼容性和稳定性难以保证。
二、正片开始
1.项目介绍
本项目采用 PaddleOCR 作为核心光学字符识别(OCR, Optical character recognition)引擎,并专门调用其 PP-StructureV3 文档解析流水线,以应对大量语料文件中存在的双栏、三栏、竖排、图文混排 等复杂PDF版面。至于 PaddleOCR 和 PP-StructureV3的关系,一句化说明白:PP-StructureV3 是 PaddleOCR 工具包内置的一个"高级文档解析流水线"。
1.1 项目用到的技术
- PddleOCR 是一个开源的 OCR 引擎,Github地址 :PaddleOCR (版本 3.3.1+)
- PP-StructureV3 是 PaddleOCR 中专门用于复杂文档结构化的高级功能,它集成了版面分析、文字检测、文字识别和阅读顺序恢复等多个模型,能够智能地识别文档中的标题、段落、表格、图片等元素,并输出符合人类阅读顺序的结构化文本。
1.2 项目实现的功能
通过跟随本项目的步骤,读者朋友将能够:
- 一键部署:在本地 Windows/Linux 环境下快速搭建 GPU 加速的 PaddleOCR 环境。
- 批量处理:对包含数百个复杂 PDF 的文件夹进行全自动处理。
- 结构化输出:每个 PDF 将生成一个独立的文件夹,内含 Markdown 格式的文本(直接可作为语料用于大模型训练)、对应的.docx文件、JSON 格式的原始数据以及用于质量检验的可视化图片。
2.使用步骤
2.1 创建虚拟环境
这里推荐使用 Miniconda 来管理 Python 环境,以避免包依赖冲突。本项目使用 Python 3.9 ,因为 PaddleOCR 的某些依赖库(如 zoneinfo 和 modelscope)需要 Python 3.9 或更高版本才能稳定运行。具体指令如下:
powershell
# 创建一个名为 paddleocr_env,Python 版本为 3.9 的虚拟环境
conda create -n paddleocr_env python=3.9 -y
# 激活该环境
conda activate paddleocr_env2.2 安装组件
-
安装 PaddlePaddle GPU 核心框架 :
-
这是飞桨(PaddlePaddle)的 GPU 版本,用于调用 NVIDIA 显卡加速 OCR 运算。这里说一下,实测即使是残血的 3060 也妥妥够用。
-
首先我们要在命令行输入
nvidia-smi命令,来查看当前系统的CUDA版本 ,up 自己的CUDA版本如下图所示:
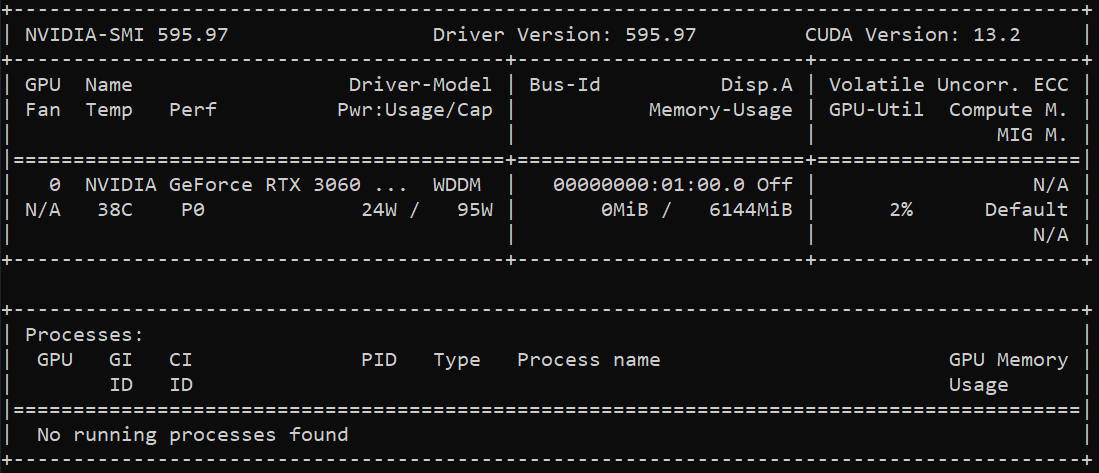
-
拿到CUDA版本后,就可以去PaddleOCR官网去获取下载命令 了。地址:++*https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/develop/install/pip/windows-pip.html*++
-
这里补充一条提示:如果你发现自己的CUDA版本过低,强烈建议去 NVIDIA 官网下载最新的驱动,更新CUDA版本,否则低版本的 CUDA 是不支持某些 Paddle 所需的依赖的,容易报错。
-
在官网,选择自己的机器配置,如下图所示:
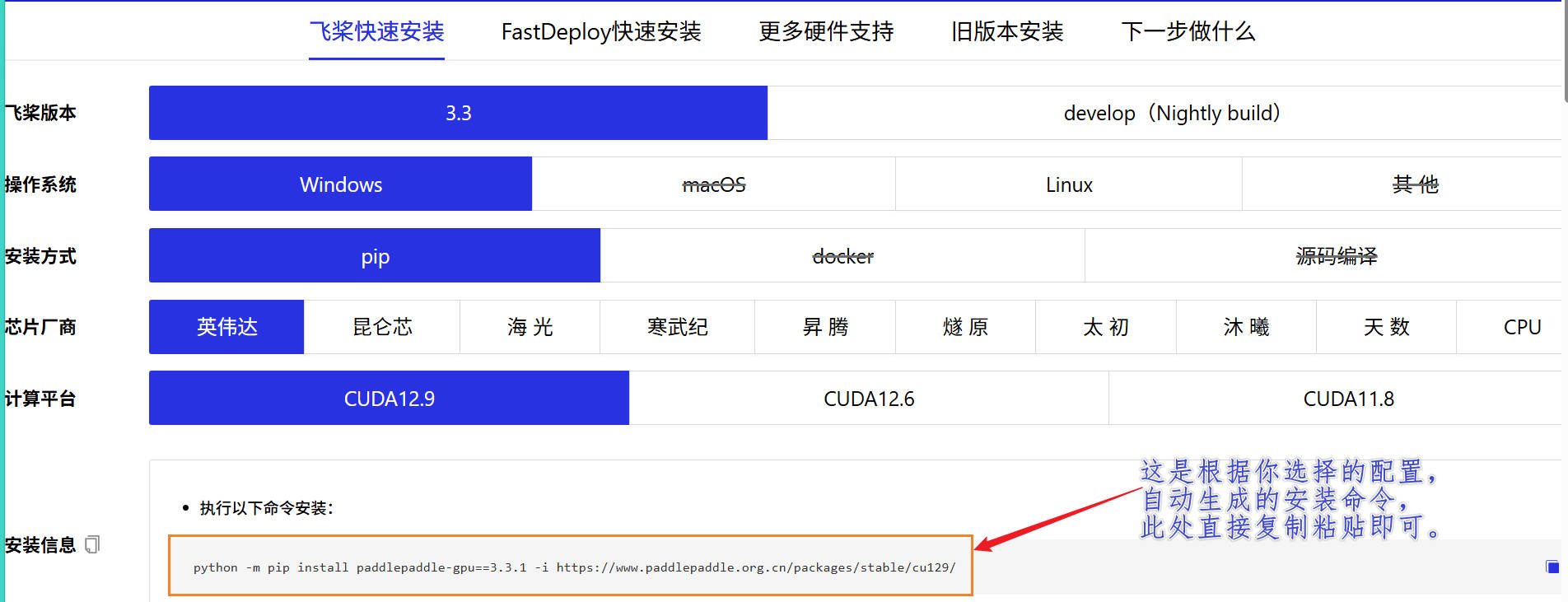
-
以 up 自己的配置为例,因为我的 CUDA 是
13.x版本,所以我直接安装12.9也是兼容的(向前兼容)。这里建议大家直接复制执行官方生成的命令。 -
这里我们第一步安装的,是飞桨深度学习框架 ,它提供 GPU 加速的底层数学运算,这是所有
PaddleOCR功能的基础。
-
-
安装 PaddleOCR 本体 :
-
具体指令如下:
powershellpip install paddleocr -
这一步我们安装的是
PaddleOCR工具包本体,它负责提供命令行入口和基础识别模型。
-
-
安装 PP-StructureV3 所需的附加依赖 :
-
PP-StructureV3 是处理复杂版面的核心模块,它并不包含在基础包中,需要单独安装。具体指令如下:
powershellpip install "paddlex[ocr]" -
这一步我们安装的是
PP-StructureV3所需的附加组件,因为版面分析模型、表格解析模型等高级依赖并不包含在paddleocr基础包中,需单独安装。
-
-
安装 python-docx :
-
PaddleOCR 在保存 Word 文档时会调用此库。安装它也能避免程序在保存环节报错中断。具体指令如下:
powershellpip install python-docx -
PaddleOCR本身支持生成 docx 文件,该功能由PP-StructureV3流水线在输出时自动调用,但需要python-docx库作为运行时依赖。
-
2.3 测试环境是否就绪
测试指令如下:
powershell
# 1. 检查 PaddleOCR 命令是否可用
paddleocr --help
# 2. 验证 GPU 是否被 PaddlePaddle 正确识别
python -c "import paddle; paddle.utils.run_check(); import paddleocr; print('PaddleOCR 导入成功')"如果输出包含 PaddlePaddle works well on 1 GPU. 和 PaddleOCR 导入成功,则环境完美就绪。
2.4 执行命令(开始跑我们的模型)
-
前言 :大家在执行指令之前,一定要确保所对应的两个文件夹已经提前创建好了,否则会报错。而且最好是将两个文件夹放在同一级目录下面,如下图所示:
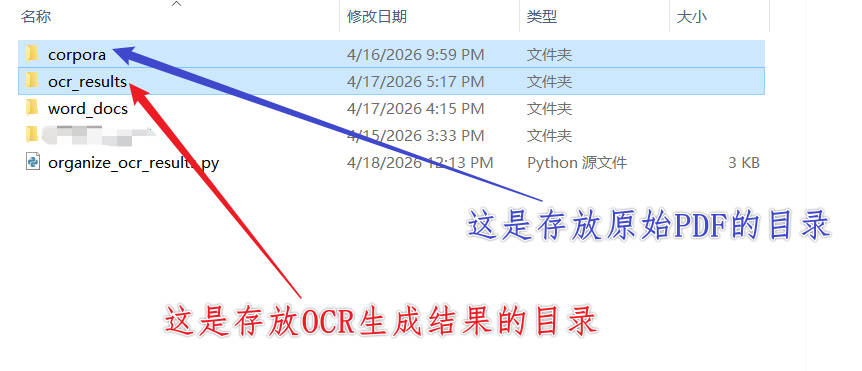
-
指令如下:
powershellpaddleocr pp_structurev3 -i "你的PDF文件夹路径" --save_path "输出结果路径" --device gpu --format markdown -
指令参数详解:
参数 说明 pp_structurev3 指定使用的流水线, 文档解析引擎。 -i 或 --input 输入路径。可以是单个 PDF 文件,也可以是包含多个 PDF 的文件夹。 --save_path 输出目录。所有生成的文件(Markdown、JSON、图片等)都将保存在此目录下。 --device gpu 指定计算设备,使用 GPU 提速。 --format markdown 指定文本输出格式。此处为 Markdown 格式。 -
指令执行的注意事项:
- 首次运行会自动下载所需的模型文件(还不小),请耐心等待(我这边差不多10min有)。处理过程中,终端会显示进度条。
- 完成后,--save_path 指定的目录下将生成多个文件(每个 PDF 对应一个 .md 文件、一个 .docx 文件、一个 .json 文件及多张可视化图片)。
2.5 执行 Python 脚本:分门别类整理结果
-
如果只是直接跑完模型,由于模型是一页一页的处理PDF的,每一页的处理结果都是多份文件(包括docx、markdown、图片等),而每个PDF可能都是多页,所以输出结果的文件夹下会有一大堆文件。这时候,我们可以借助Python脚本 来将每个 PDF 相关的所有文件(Markdown、docs、JSON、图片等)自动归类到以该 PDF 命名的独立子文件夹中。这样一来,不论是后续统一查看,还是编写新脚本合并文档,都会很丝滑!
-
up 已经将写好的脚本放在了该仓库,大家估计已经看到了,就在上面的
organize_ocr_results.py,大家可以直接下载,当然,可以的话建议大家 fork 下本仓库,后续还可以提交 PR 噢。 -
脚本需要进行轻微的修改:主要是 存放PDF的路径 和 存放OCR结果 的路径,我在脚本中已经进行了标注。
-
organize_ocr_results.py脚本的执行命令如下:powershellpython organize_ocr_results.py -
这里再来简单说一下这个脚本的原理:
- 首先 ,脚本会扫描存放 PDF 的源文件夹,获取所有 PDF 文件的"基础名"(不含扩展名)。
- 接着 ,它会遍历输出目录下的所有文件,找出扩展名为 .md, .json, .jpg, .docx 等目标文件。
- 然后 , 它会利用文件名前缀进行匹配。PaddleOCR 生成的文件名通常以 PDF 基础名开头(例如 我的文档.pdf 会生成 我的文档.md、我的文档_layout.jpg 等)。脚本通过检查文件名是否以某个 PDF 基础名开头,将文件归入对应的组。
- 最后 ,脚本为每个 PDF 基础名创建 一个子文件夹,并将属于该组的所有文件移动进去。无法匹配的文件会被放入一个 _unclassified 文件夹,方便我们手动检查。
3.常见问题
-
安装 PaddlePaddle GPU 版时出现 SSL 错误 :
- 现象:Anaconda Prompt 中出现提示
SSLError或Could not fetch URL...。 - 原因:网络代理(如 VPN 或梯子)干扰了 pip 的 SSL 证书验证。
- 解决方案:关闭代理软件后重试安装命令(如果开了梯子的, 试试把梯子关了重新执行安装命令)。
- 现象:Anaconda Prompt 中出现提示
-
执行 paddleocr pp_structurev3 时报错 DependencyError:
-
现象:模型下载好后报错
RuntimeError: A dependency error occurred... requires additional dependencies. -
原因:未安装 PP-StructureV3 所需的额外组件。
-
解决方案:执行命令安装缺失的附加包:
powershellpip install "paddlex[ocr]"
-
-
执行命令后中断,报错 ModuleNotFoundError: No module named 'docx' :
-
现象:程序在处理完部分内容后崩溃,提示缺少 docx 模块。
-
原因:PaddleOCR 内部默认尝试保存一份 Word 文档,但环境中缺少 python-docx 库。
-
解决方案:执行命令安装该库,然后重新运行相同的 PaddleOCR 命令。程序会智能地跳过已处理的 PDF,从断点继续。
powershellpip install python-docx
-
4.讨论 (DISCUSSION)
为何选择"逐页处理"而非"整本输出"的处理逻辑?
- PaddleOCR 目前的默认行为是为 PDF 的每一页生成独立的文件(如图片、Markdown),而非输出一个单一的完整文档。这并非技术限制,而是一种面向生产环境的稳健设计。因为在处理大量的PDF时, 难免会遇到扫描模糊、页面损坏或特殊排版的"问题页"。逐页处理确保了某一页的失败不会导致整个 PDF 的解析任务崩溃。用户只需单独重新处理出错页面,然后用脚本替换旧文件即可,极大降低了维护成本。
- 而且, 独立的图片和文本文件让我们可以轻松定位并抽查任何一页的识别效果。发现错误时,能够进行精准修复。
- 虽然本教程使用单命令串行处理,但这种分页输出的架构为未来编写多线程/多进程脚本、实现多页同时解析提供了天然的基础。
- 后续优化:合并文档的路径------------当所有 PDF 都成功解析并通过质量抽检后,我们后续可能会希望将每个 PDF 的零散 Markdown 文件合并为一个完整的文档。这其实非常简单:对于 Markdown 文件:我们可以使用简单的命令行工具(如 Windows 的 type *.md > merged.md 或 Linux 的 cat *.md > merged.md)按页顺序拼接。PaddleOCR 生成的 Markdown 已经带有正确的阅读顺序,合并后无需二次排版。如果需要合并 Word 文档或进行更复杂的文本清洗,编写一个简短的 Python 脚本调用 python-docx 库即可轻松实现,通常不超过 20 行代码。
为何运行paddleocr模型时,提示大量的"Model files already exist. Using cached files"?
- 这些以 Model files already exist. Using cached files. 开头的信息是 PaddleOCR 的正常工作日志,并非错误。它的作用是报告模型加载状态,告诉我们所有必需的模型文件都已在本地缓存中找到了,无需再次下载。
- PaddleOCR 会在 C:\Users<你的用户名>.paddlex 路径下创建一个独立的模型缓存文件夹。这是因为PaddleOCR的内置工具 PP-StructureV3 需要加载一系列模型来处理版面分析、文字检测、表格识别等任务。这些模型文件加起来体积可观,每次运行加载后,都会存储在 C:\Users\Five.paddlex 目录下,这就是C盘空间减少的直接原因。
- PP-StructureV3 所需的全套模型文件总大小约为 2.5GB - 3.5GB,而且这些文件都会在我们首次运行成功之后,下载完毕并保存在 C:\Users\Five.paddlex 目录下。一般来说,模型缓存所占用的空间是基本不会增长的,除非后续我们主动对 PaddleOCR 进行了重大的版本升级,比如主动执行了
pip install --upgrade paddleocr命令,或者我们主动使用了新的流水线功能。所以,只要不是我们C盘空间特别吃紧,我们都可以保持现状,这样可以保证PaddleOCR 的高效运行😘。