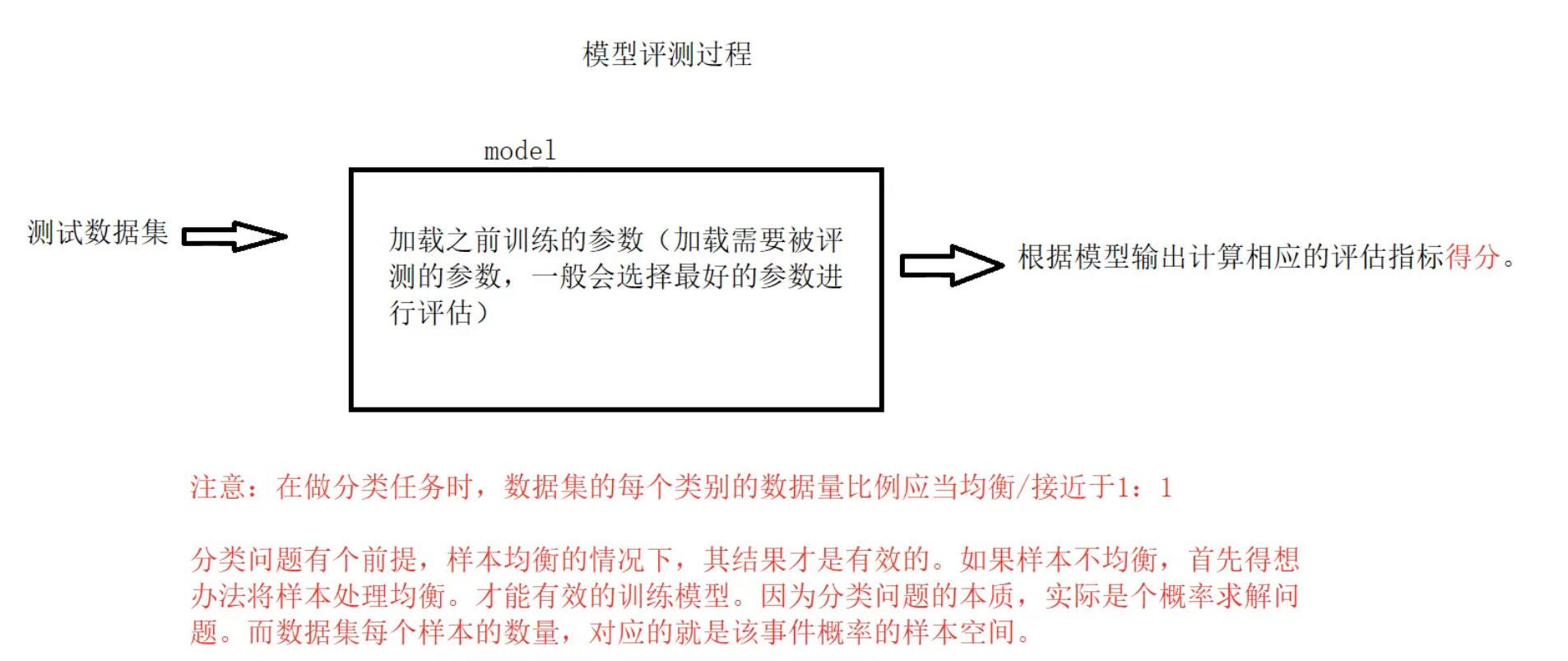
模型评估测试逻辑
且在训练的过程中
如果出现了 0 1 数据不均衡的情况下,,优先将少的数据补起来,如果不可行才去砍数据
微调模型的三种方式
1、增量微调(BERT本文采用的)
2、局部微调
3、全局微调
上述三种方式效果是自上到下,训练效果是越来约好的,,但是训练所需的成本是变高的
小问题
01:为什么要存储最后一次的参数?存最好的不就好了吗?
最后参数的保存是为了不丢失前面训练的数据(断电),并且并不知道当前最好是不是全局最好
**********************************
02:模型的参与
在训练的过程中,是屏蔽了 bert模型原有的,只让增量模型参与训练
但是,在测试的时候,两个模型是一起测试的

一、代码模块化说明
1. 数据处理模块
1.1 数据集类 (MyData.py)
python
class MyDataset(Dataset):
def __init__(self, mode='train'):
"""
初始化数据集
:param mode: 数据集模式 (train/test)
"""
self.data = [] # 存储(文本, 标签)元组
# 实现数据加载逻辑
# ...
def __getitem__(self, index):
return self.data[index] # 返回(文本, 标签)
def __len__(self):
return len(self.data)1.2 数据预处理函数 (collate_fn)
python
def collate_fn(data):
...
批量处理函数,将原始文本转换为BERT输入格式
:param data:批次数据[(text1, label1),(text2, label2),...]
:return:编码后的张量
...
texts = [item[0] for item in data]
labels = [item[1] for item in data]
# BERT编码
encodings = tokenizer(
texts,
truncation=True,
max_length=512,
padding='max_length',
return_tensors='pt'
)
return {
'input_ids': encodings['input_ids'],
'attention_mask': encodings['attention_mask'],
'labels': torch.tensor Labels)
}2. 模型架构模块 (net.py)
python
#加载预训练模型
pretrained = BertModel.from_pretrained(r"D:\PycharmProjects\demo_02\model\bertbase-chinese\models--bert-basechinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE)
print(pretrained)
#定义下游任务(增量模型)
class
Model(torch.nn.Module):
def __init__(self):
super().__init__()
#设计全连接网络,实现二分类任务
self.fc = torch.nn.Linear(768,2)
#使用模型处理数据(执行前向计算)
def forward(self,input_ids,attention_mask,token_type_ids):
#冻结Bert模型的参数,让其不参与训练
with torch.no_grad():
out =
pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=toke
n_type_ids)
#增量模型参与训练
out = self.fc(out.last_hidden_state[:,0])
return out3. 评估测试模块 (test.py)
python
def evaluate_model(model, testloader, device):
评估模型在测试集上的性能:
:param model: 待评估模型
:param testloader: 测试数据加载器
:param device: 计算设备
:return: 评估指标字典
""model.eval()
all_preds, all_labels = [], []
with torch.no_grad():
for batch in testloader:
# 数据转移到设备
batch = {k: v.to(device) for k, v in batch.items())
# 前向传播
outputs = model(
input_ids=batch['input_ids'],
attention_mask=batch['attention_mask']
)
# 收集预测结果
predicts = torch.argmax(outputs, dim=1)
all_preds.append(preds.cpu().numpy())
all_labels.append(batch['labels'].cpu().numpy())
# 计算评估指标
metrics = {
'accuracy': accuracy_score(all_labels, all_preds),
'precision': precision_score(all_labels, all_preds, average='macro'),
'recall': recall_score(all_labels, all_preds, average='macro'),
'f1': f1_score(all_labels, all_preds, average='macro')
} return metrics4. 交互式应用模块 (run.py)
python
#模型使用接口(主观评估)
#模型训练
import torch
from net import Model
from transformers import BertTokenizer
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#加载字典和分词器二、评估指标详解
token = BertTokenizer.from_pretrained(r"D:\PycharmProjects\demo_02\model\bertbase-chinese\models--bert-basechinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
model
= Model().to(DEVICE)
names = ["负向评价","正向评价"]
#将传入的字符串进行编码
def collate_fn(data):
sents = []
sents.append(data)
#编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
# 当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=512,
# 一律补0到max_length
padding="max_length",
# 可取值为tf,pt,np,默认为list
return_tensors="pt",
# 返回序列长度
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
return input_ids,attention_mask,token_type_ids
def test():
#加载模型训练参数
model.load_state_dict(torch.load("params/16_bert.pth"))
#开启测试模型
model.eval()
while True:
data = input("请输入测试数据(输入'q'退出):")
if data=='q':
print("测试结束")
break
input_ids,attention_mask,token_type_ids = collate_fn(data)
input_ids, attention_mask, token_type_ids =
input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE)
#将数据输入到模型,得到输出
with torch.no_grad():
out = model(input_ids,attention_mask,token_type_ids)
out = out.argmax(dim=1)
print("模型判定:",names[out],"\n")
if __name__ == '__main__':
test()二、评估指标详解
1. 基础评估指标
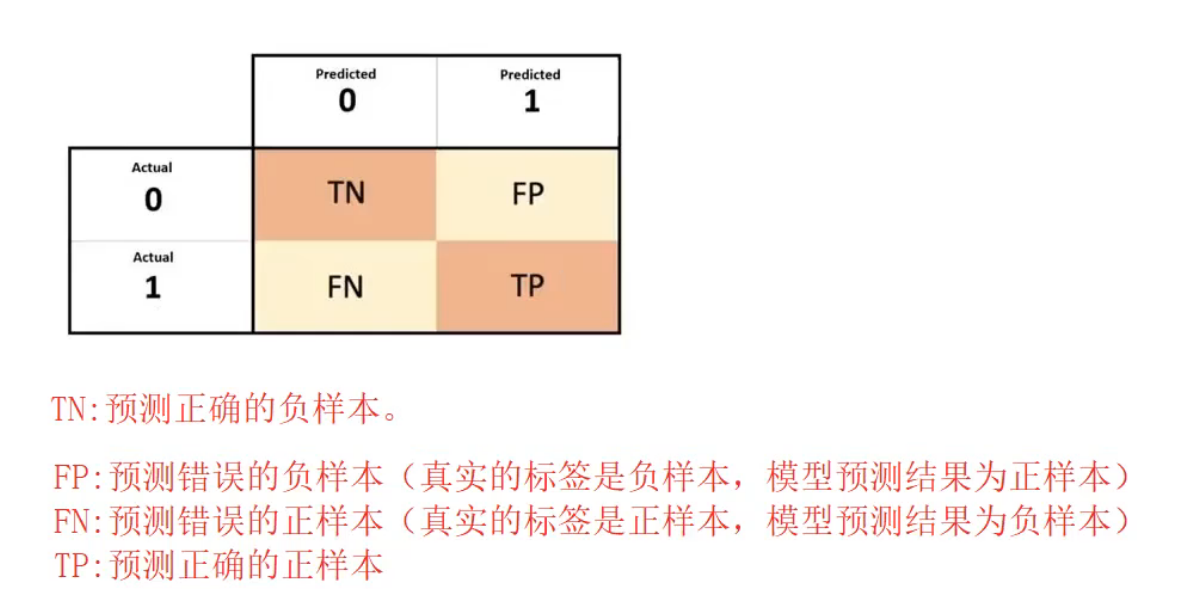
依赖于混淆矩阵
行是真实值,列是模型值
"T"和"F" 是模型的"真、假"(预测结果相对于真实值的对错)。
"N"和"P" 是样本的"负、正" (样本本身所属的类别标签)。++遇见F反过来++
|----------------|--------|-------------------------------------------------|----------------|
| 指标名称 | 别名 | 计算公式 | 解释说明 |
| 准确率(Accuracy) | 正确率 | (TP + TN) / (TP + TN + FP + FN) | 总体预测正确的比例 |
| 精确率(Precision) | 查准率 | TP / (TP + FP) | 预测为正例中实际为正的比例 |
| 召回率(Recall) | 查全率敏感度 | TP / (TP + FN) | 实际为正例中被正确预测的比例 |
| F1分数(F1 Score) | F值 | 2 × (Precision × Recall) / (Precision + Recall) | 精确率和召回率的调和平均数 |
其中(看上文,这里绕):
TP (True Positive):真正例(预测正确且为正)
TN (True Negative):真负例(预测正确且为负)
FP (False Positive):假正例(预测错误,实际为负但预测为正)
FN (False Negative):假负例(预测错误,实际为正但预测为负)
1.1 准确率 (Accuracy)
定义:正确预测的样本数占总样本数的比例
适用场景:各类别样本均衡时使用
局限性:在类别不平衡数据中可能产生误导
1.2 精确率 (Precision)
定义:预测为正例的样本中真正为正例的比例
适用场景:关注减少假正例(如垃圾邮件检测)
1.3 召回率 (Recall)
定义:实际为正例的样本中被正确预测的比例
适用场景:关注减少假负例(如疾病诊断)
1.4 F1 分数 (F1 Score)
定义:精确率和召回率的调和平均数
特点:综合衡量模型性能,在类别不平衡时更可靠
2. 多分类评估策略
|------------------------|----------------------------|--------------------------|-----------------------------------------------|---------|
| 平均策略 | 精确率公式 | 召回率公式 | F1分数公式 | 适用场景 |
| 宏平均(Macro-average) | (P1 + P2 + ... + Pn) / n | (R1 + R2 + ... + Rn) / n | (F11 + F12 + ... + F1n) / n | 各类别权重相同 |
| 加权平均(Weighted-average) | Σ(Pi × Wi)Wi = 类别i样本数/总样本数 | Σ(Ri × Wi) | Σ(F1i × Wi) | 考虑类别不平衡 |
| 微平均(Micro-average) | ΣTP / (ΣTP + ΣFP) | ΣTP / (ΣTP + ΣFN) | 2 × (Micro-P × Micro-R) / (Micro-P + Micro-R) | 整体性能评估 |
3. 混淆矩阵解读表
|--------|--------|--------|-----|--------|---------|
| 预测\实际 | 类别1 | 类别2 | ... | 类别N | 行统计 |
| 类别1 | TP1 | FP1→2 | ... | FP1→n | 预测为1的总数 |
| 类别2 | FP2→1 | TP2 | ... | FP2→n | 预测为2的总数 |
| ... | ... | ... | ... | ... | ... |
| 类别N | FPn→1 | FPn→2 | ... | TPn | 预测为N的总数 |
| 列统计 | 实际1的总数 | 实际2的总数 | ... | 实际N的总数 | 总样本数 |
关键分析点:
- 对角线元素:各类别的正确预测数
- 非对角线元素:类别间的混淆情况
- 行总和:各类别的预测数量
- 列总和:各类别的实际数量
4. 多分类指标计算示例
假设3分类问题的混淆矩阵:
|--------|-----|-----|-----|
| 预测\实际 | 类别A | 类别B | 类别C |
| 类别A | 80 | 5 | 2 |
| 类别B | 3 | 70 | 10 |
| 类别C | 1 | 8 | 65 |
各类别指标计算:
|----|---------------------|---------------------|------------------------------------------|-----|
| 类别 | 精确率 | 召回率 | F1分数 | 支持数 |
| A | 80/(80+3+1)=91.95% | 80/(80+5+2)=92.00% | 2×(0.9195×0.92)/(0.9195+0.92)=91.97% | 87 |
| B | 70/(70+5+8)=84.34% | 70/(70+3+10)=84.34% | 2×(0.8434×0.8434)/(0.8434+0.8434)=84.34% | 83 |
| C | 65/(65+2+10)=84.42% | 65/(65+1+8)=87.84% | 2×(0.8442×0.8784)/(0.8442+0.8784)=86.08% | 74 |
整体指标计算:
|------|---------------------------------------------------|--------------------------------------------|--------------------------------------------|
| 平均策略 | 精确率 | 召回率 | F1分数 |
| 宏平均 | (91.95%+84.34%+84.42%)/3=86.90% | (92.00%+84.34%+87.84%)/3=88.06% | (91.97%+84.34%+86.08%)/3=87.46% |
| 加权平均 | (91.95%×87+84.34%×83+84.42%×74)/244=87.03% | (92.00%×87+84.34%×83+87.84%×74)/244=88.10% | (91.97%×87+84.34%×83+86.08%×74)/244=87.54% |
| 微平均 | (80+70+65)/(80+70+65+3+1+5+8+2+10)=215/244=88.11% | 同精确率(微平均下相等) | 同精确率 |
5. 评估指标关系图
预测质量
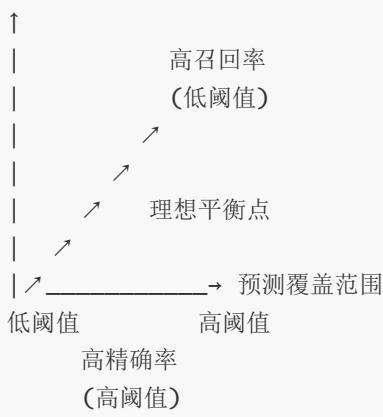
解读:
X轴:预测覆盖范围(降低阈值会增加预测为正例的数量)
Y轴:预测质量 (预测为正例的准确性)
曲线趋势:随着阈值降低,覆盖范围增加但预测质量下降
理想平衡点:精确率和召回率的最佳平衡位置
6. 指标选择指南
|-------|--------|-----------|
| 场景 | 推荐指标 | 原因 |
| 类别平衡 | 准确率 | 直观反映整体正确率 |
| 类别不平衡 | F1宏平均 | 平等对待各类别 |
| 假正例敏感 | 精确率 | 减少错误肯定 |
| 假负例敏感 | 召回率 | 减少错误否定 |
| 大类别主导 | F1加权平均 | 考虑样本分布 |
7. 混淆矩阵分析
from sklearn.metrics import confusion_matrix
import seaborn as sns
# 计算混淆矩阵
cm = confusion_matrix(true_labels, predictions)
# 可视化
plt.figure(figsize=(10, 8))
sns_heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('预测标签')
pltylabel('真实标签')
plt.title('混淆矩阵')
plt.show()混淆矩阵解读:
对角线:正确分类的样本数
非对角线:分类错误样本(行->列)
分析重点:
哪些类别容易被混淆
是否存在系统性误分类
类别间相似度对模型的影响
8. 综合评估报告
from sklearn.metrics import classification_report
#生成详细评估报告
report = classification_report( true_labels, predictions, target_names ≡ class_names, digits=4
)
print.report)
报告示例:
|--------------|-----------|--------|----------|---------|
| | precision | recall | f1-score | support |
| 类别0 | 0.9212 | 0.8943 | 0.9075 | 350 |
| 类别1 | 0.8765 | 0.9128 | 0.8943 | 420 |
| accuracy | | | 0.8990 | 770 |
| macro avg | 0.8989 | 0.9036 | 0.9009 | 770 |
| weighted avg | 0.8998 | 0.8990 | 0.8992 | 770 |
报告解读:
- 类别级指标:每个类别的精确率、召回率和F1分数
- 总体指标:整体准确率
- 宏平均:各类别指标的平均值
- 加权平均:按支持数加权的指标平均值
- 支持数:每个类别的真实样本数
三、代码以及评估结果
1、环境
pip install scikit-learn
pip install seaborn
2、导包解释
pythonfrom sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score from sklearn.metrics import confusion_matrix, classification_report
- precision_score(精确率/查准率)
功能:衡量模型预测为正类的样本中,有多少是真正的正类
通俗理解:当模型说"这是A类"时,它有多可靠
计算方式:正确预测的正类样本数 ÷ 模型预测的所有正类样本数
适用场景:在"误判成本高"时重点关注(如垃圾邮件检测,不想把正常邮件误判为垃圾邮件)
- recall_score(召回率/查全率)
功能:衡量实际为正类的样本中,有多少被模型正确识别出来
通俗理解:模型能找到多少真正的正类样本
计算方式:正确预测的正类样本数 ÷ 实际的所有正类样本数
适用场景:在"漏判成本高"时重点关注(如疾病诊断,不想漏掉真正的病人)
- f1_score(F1分数)
功能:精确率和召回率的调和平均数,综合评估模型性能
通俗理解:在精确率和召回率之间找一个平衡点
计算方式:2 × (精确率 × 召回率) ÷ (精确率 + 召回率)
适用场景:当需要同时考虑精确率和召回率,且数据类别不平衡时
- accuracy_score(准确率)
功能:模型预测正确的样本占总样本的比例
通俗理解:模型整体猜对了多少
计算方式:预测正确的样本数 ÷ 总样本数
适用场景:各类别样本数量均衡时的通用评估指标
- confusion_matrix(混淆矩阵)
功能:以表格形式展示模型预测结果与真实标签的对应关系
输出结构:
行:真实标签
列:预测标签
四个值:真正例(TP)、假正例(FP)、真反例(TN)、假反例(FN)
作用:直观展示模型在各类别上的表现,特别是错误类型
- classification_report(分类报告)
功能:生成包含多个评估指标的综合性文本报告
报告内容:
每个类别的精确率(precision)、召回率(recall)、F1分数
每个类别的支持度(样本数量)
宏观平均(各类别指标的简单平均)
加权平均(按各类别样本数量加权平均)
准确率(accuracy)
作用:一键获取全面的分类模型评估结果
总结对比
指标 关注点 适用场景 不适用场景 准确率 整体正确率 各类别均衡 数据不平衡 精确率 预测的可靠性 误判成本高 不关心漏检 召回率 样本的覆盖率 漏判成本高 不关心误报 F1分数 平衡精确和召回 需要综合评估 单独强调某一方面 一句话总结:这些函数共同构成了分类模型的评估工具箱,让你能多角度、全方位地评估模型性能,而不仅仅依赖单一的准确率。
3、加载训练好的参数
python
# 模型参数路径
model_path = r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\params\best_bert.pth"
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型参数文件不存在: {model_path}")
# 加载模型训练参数
model.load_state_dict(torch.load(model_path))4、完整评测代码
test.py
这里面有混淆矩阵的图片输出和报告格式
python
# test.py - 模型评估测试模块
import torch
from MyData import MyDataset
from torch.utils.data import DataLoader
from net import Model
from transformers import BertTokenizer
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score
from sklearn.metrics import confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import os
# 定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载字典和分词器
token = BertTokenizer.from_pretrained(
r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
# 将传入的字符串进行编码
def collate_fn(data):
sents = [i[0] for i in data]
label = [i[1] for i in data]
# 编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=sents,
# 当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=512,
# 一律补0到max_length
padding="max_length",
# 可取值为tf,pt,np,默认为list
return_tensors="pt",
# 返回序列长度
return_length=True
)
input_ids = data["input_ids"]
attention_mask = data["attention_mask"]
token_type_ids = data["token_type_ids"]
label = torch.LongTensor(label)
return input_ids, attention_mask, token_type_ids, label
def evaluate_model(model, test_loader, device):
"""
评估模型在测试集上的性能
:param model: 待评估模型
:param test_loader: 测试数据加载器
:param device: 计算设备
:return: 评估指标字典
"""
model.eval()
all_preds, all_labels = [], []
for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(test_loader):
# 将数据转移到设备
input_ids = input_ids.to(device)
attention_mask = attention_mask.to(device)
token_type_ids = token_type_ids.to(device)
labels = labels.to(device)
# 前向传播
with torch.no_grad():
outputs = model(input_ids, attention_mask, token_type_ids)
preds = torch.argmax(outputs, dim=1)
# 收集预测结果
all_preds.extend(preds.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 计算评估指标
metrics = {
'accuracy': accuracy_score(all_labels, all_preds),
'precision_macro': precision_score(all_labels, all_preds, average='macro'),
'recall_macro': recall_score(all_labels, all_preds, average='macro'),
'f1_macro': f1_score(all_labels, all_preds, average='macro'),
'precision_weighted': precision_score(all_labels, all_preds, average='weighted'),
'recall_weighted': recall_score(all_labels, all_preds, average='weighted'),
'f1_weighted': f1_score(all_labels, all_preds, average='weighted'),
'confusion_matrix': confusion_matrix(all_labels, all_preds),
'classification_report': classification_report(all_labels, all_preds, digits=4)
}
return metrics
def plot_confusion_matrix(cm, class_names, save_path=None):
"""
绘制并保存混淆矩阵
:param cm: 混淆矩阵
:param class_names: 类别名称列表
:param save_path: 保存路径(可选)
"""
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=class_names, yticklabels=class_names)
plt.xlabel('yucebiaoqian')
plt.ylabel('zhenshibiaoqian')
plt.title('hunxiaojuzhen')
if save_path:
plt.savefig(save_path, bbox_inches='tight')
print(f"混淆矩阵已保存至: {save_path}")
plt.show()
def save_metrics_to_file(metrics, save_path):
"""
将评估指标保存到文本文件
:param metrics: 评估指标字典
:param save_path: 保存路径
"""
with open(save_path, 'w', encoding='utf-8') as f:
f.write("模型评估报告\n")
f.write("=" * 50 + "\n")
f.write(f"准确率 (Accuracy): {metrics['accuracy']:.4f}\n\n")
f.write("宏平均指标 (Macro-average):\n")
f.write(f" 精确率 (Precision): {metrics['precision_macro']:.4f}\n")
f.write(f" 召回率 (Recall): {metrics['recall_macro']:.4f}\n")
f.write(f" F1分数 (F1 Score): {metrics['f1_macro']:.4f}\n\n")
f.write("加权平均指标 (Weighted-average):\n")
f.write(f" 精确率 (Precision): {metrics['precision_weighted']:.4f}\n")
f.write(f" 召回率 (Recall): {metrics['recall_weighted']:.4f}\n")
f.write(f" F1分数 (F1 Score): {metrics['f1_weighted']:.4f}\n\n")
f.write("分类报告 (Classification Report):\n")
f.write(metrics['classification_report'])
f.write("\n\n混淆矩阵 (Confusion Matrix):\n")
np.savetxt(f, metrics['confusion_matrix'], fmt='%d')
print(f"评估报告已保存至: {save_path}")
if __name__ == '__main__':
# 创建数据集
test_dataset = MyDataset("test")
test_loader = DataLoader(
dataset=test_dataset,
batch_size=100,
shuffle=False, # 评估时不需要打乱
drop_last=False, # 保留所有样本
collate_fn=collate_fn
)
# 开始测试
print(f"使用设备: {DEVICE}")
model = Model().to(DEVICE)
# 模型参数路径
model_path = "L2/day04-基于BERT模型的自定义微调训练/demo_04/params/best_bert.pth"
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型参数文件不存在: {model_path}")
# 加载模型训练参数
model.load_state_dict(torch.load(model_path))
# 评估模型
metrics = evaluate_model(model, test_loader, DEVICE)
# 打印评估结果
print("\n" + "=" * 50)
print(f"准确率 (Accuracy): {metrics['accuracy']:.4f}")
print("\n宏平均指标 (Macro-average):")
print(f" 精确率 (Precision): {metrics['precision_macro']:.4f}")
print(f" 召回率 (Recall): {metrics['recall_macro']:.4f}")
print(f" F1分数 (F1 Score): {metrics['f1_macro']:.4f}")
print("\n加权平均指标 (Weighted-average):")
print(f" 精确率 (Precision): {metrics['precision_weighted']:.4f}")
print(f" 召回率 (Recall): {metrics['recall_weighted']:.4f}")
print(f" F1分数 (F1 Score): {metrics['f1_weighted']:.4f}")
print("\n分类报告 (Classification Report):")
print(metrics['classification_report'])
# 可视化混淆矩阵
# 注意:根据您的实际类别修改class_names
class_names = ["label0", "label1"] # 替换为您的实际类别名称
plot_confusion_matrix(metrics['confusion_matrix'], class_names, "confusion_matrix.png")
# 保存评估结果
save_metrics_to_file(metrics, "evaluation_report.txt")
print("评估完成!")net.py
python
#net.py - 模型定义模块
import torch
from transformers import BertModel
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
#加载预训练模型
pretrained = BertModel.from_pretrained(r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE)
print(pretrained)
#定义下游任务(增量模型)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#设计全连接网络,实现二分类任务
self.fc = torch.nn.Linear(768,2)
#使用模型处理数据(执行前向计算)
def forward(self,input_ids,attention_mask,token_type_ids):
#冻结Bert模型的参数,让其不参与训练
with torch.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#增量模型参与训练
out = self.fc(out.last_hidden_state[:,0])
return outMyData.py
python
# MyData.py - 数据集定义模块
from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
#初始化数据集
def __init__(self,split):
#从磁盘加载数据
self.dataset = load_from_disk(r"F:\26_01\第六期\python\L2_study\L2\day05-自定义微调训练BERT模型效果测试\demo_05\data\ChnSentiCorp")
if split == "train":
self.dataset = self.dataset["train"]
elif split == "test":
self.dataset = self.dataset["test"]
elif split == "validation":
self.dataset = self.dataset["validation"]
else:
print("数据名错误!")
#返回数据集长度
def __len__(self):
return len(self.dataset)
#对每条数据单独做处理
def __getitem__(self, item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text,label
if __name__ == '__main__':
dataset = MyDataset("test")
for data in dataset:
print(data)data_test.py
python
# data_test.py - 数据加载测试模块
from datasets import load_dataset,load_from_disk
#在线加载数据
# dataset = load_dataset(path="NousResearch/hermes-function-calling-v1",cache_dir="data/")
# print(dataset)
#转为csv格式
# dataset.to_csv(path_or_buf=r"D:\PycharmProjects\demo_02\data\ChnSentiCorp.csv")
# 加载缓存数据
datasets = load_from_disk(r"F:\26_01\第六期\python\L2_study\L2\day05-自定义微调训练BERT模型效果测试\demo_05\data\ChnSentiCorp")
print(datasets)
train_data = datasets["test"]
for data in train_data:
print(data)
# 扩展:加载CSV格式数据
# dataset = load_dataset(path="csv",data_files=r"D:\jukeai\demo_04\data\hermes-function-calling-v1.csv")
# print(dataset)5、评测结果
5.1 视频测试结果
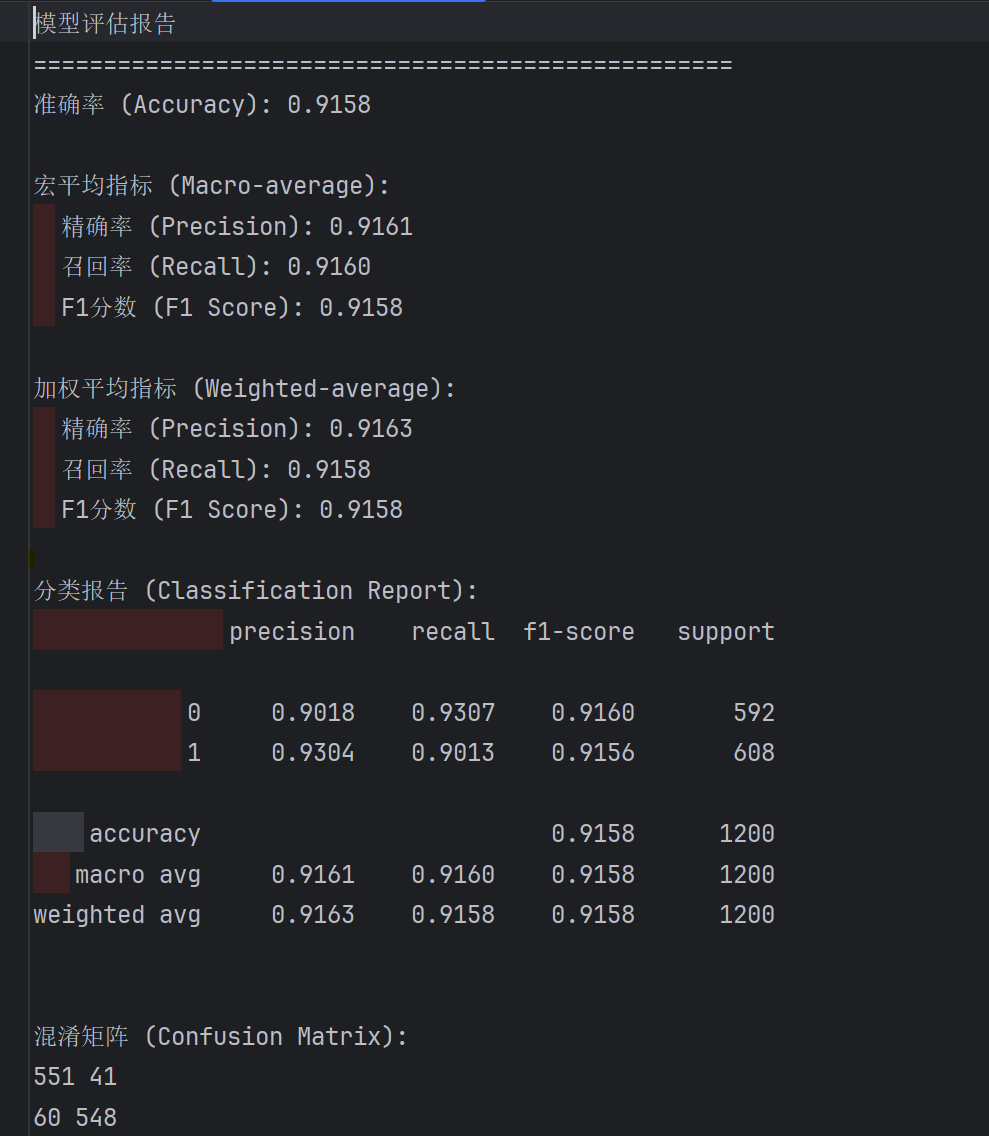
5.2 本地测试结果
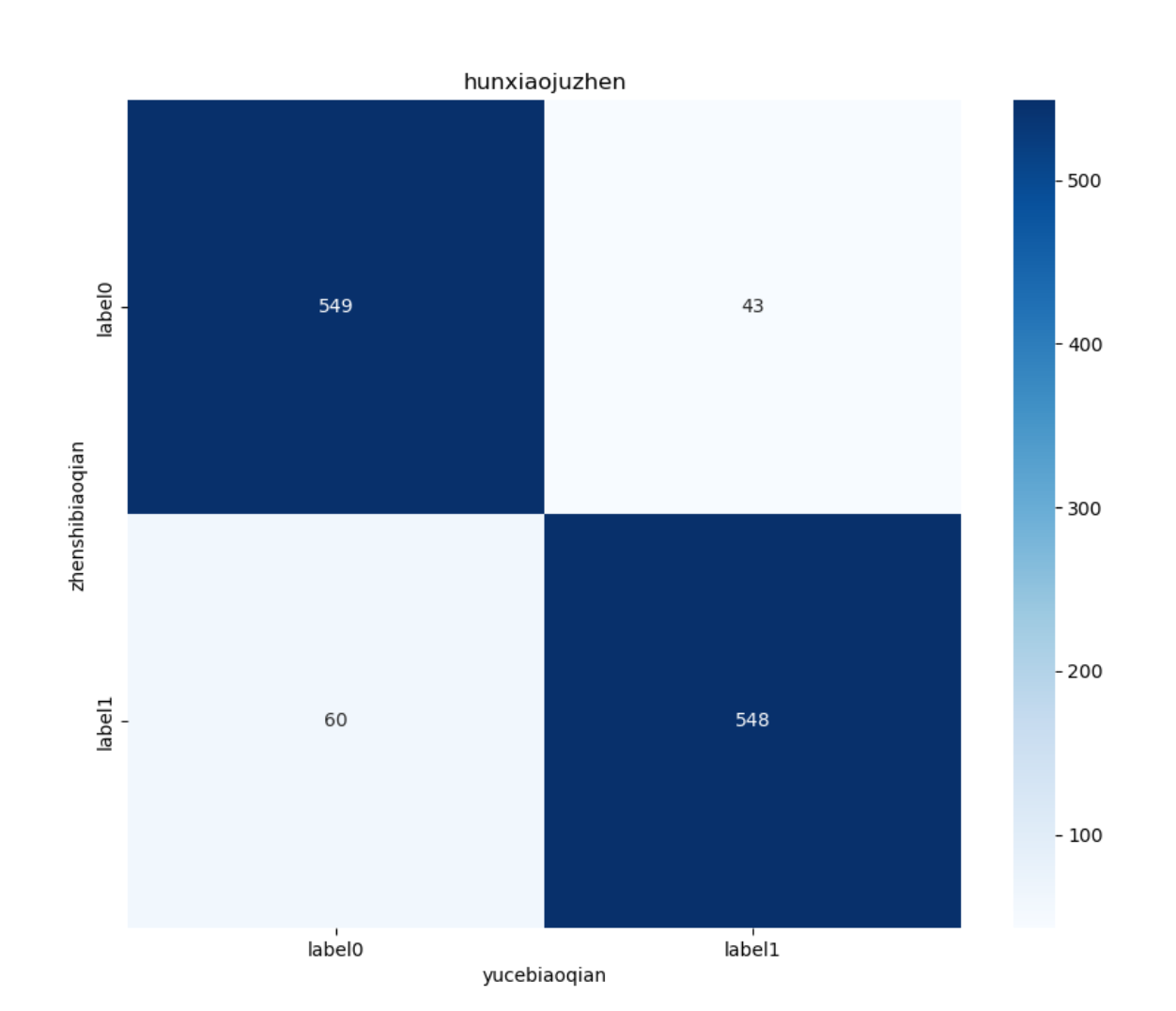
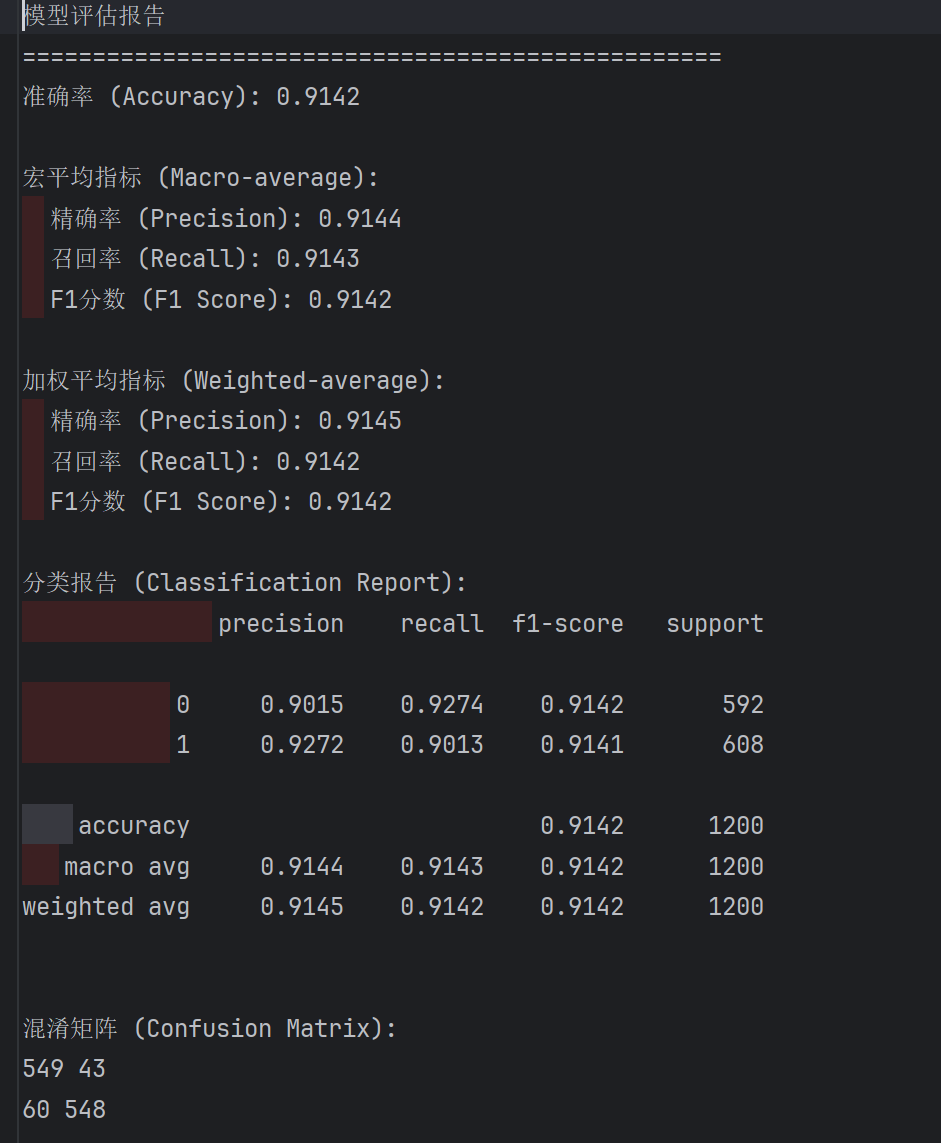
5.3 主观评估
采用输入,人为主观测试
代码
python#模型使用接口(主观评估) import torch from net import Model from transformers import BertTokenizer #定义设备信息 DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") #加载字典和分词器 token = BertTokenizer.from_pretrained(r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f") model = Model().to(DEVICE) names = ["负向评价","正向评价"] #将传入的字符串进行编码 def collate_fn(data): sents = [] sents.append(data) #编码 data = token.batch_encode_plus( batch_text_or_text_pairs=sents, # 当句子长度大于max_length(上限是model_max_length)时,截断 truncation=True, max_length=512, # 一律补0到max_length padding="max_length", # 可取值为tf,pt,np,默认为list return_tensors="pt", # 返回序列长度 return_length=True ) input_ids = data["input_ids"] attention_mask = data["attention_mask"] token_type_ids = data["token_type_ids"] return input_ids,attention_mask,token_type_ids def test(): #加载模型训练参数 model.load_state_dict(torch.load(r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\params\best_bert.pth")) #开启测试模型 model.eval() while True: data = input("请输入测试数据(输入'q'退出):") if data=='q': print("测试结束") break input_ids,attention_mask,token_type_ids = collate_fn(data) input_ids, attention_mask, token_type_ids = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE) #将数据输入到模型,得到输出 with torch.no_grad(): out = model(input_ids,attention_mask,token_type_ids) out = out.argmax(dim=1) print("模型判定:",names[out],"\n") if __name__ == '__main__': test()

四、八分类
1、修改部分
二分类模型改为八分类模型,只需要修改两个地方:
1.1. 修改模型输出层(net.py)
修改前(二分类):
pythonclass Model(torch.nn.Module): def __init__(self): super().__init__() # 二分类任务 self.fc = torch.nn.Linear(768, 2) # 768维输入,2维输出修改后(八分类):
pythonclass Model(torch.nn.Module): def __init__(self): super().__init__() # 八分类任务 self.fc = torch.nn.Linear(768, 8) # 768维输入,8维输出
1.2. 确保数据集(MyData.py)
修改加载数据的方式以及类
pythondef __init__(self,split): #从磁盘加载csv数据 self.dataset = load_dataset(path="csv",data_files=f"data/Weibo/{split}.csv",split="train")确定text和label的位置
pythondef __getitem__(self, item): text = self.dataset[item]["text"] label = self.dataset[item]["label"] return text,label如果修改text和label返回的顺序,直接低调顺序就好,再去train_val.py
确保接受的参数顺序对应
pythondef collate_fn(data): sents = [i[0]for i in data] label = [i[1] for i in data] #编码 ....这是隐式修改,你需要确保:
你的数据集中有8个不同的类别
标签是0到7的整数,而不是只有0和1
MyData.py中的
label字段已经是0-7的值如果标签不是0-7 ,需要在
__getitem__方法中修改:
pythondef __getitem__(self, item): text = self.dataset[item]["text"] # 假设原始标签是1-8,需要转换为0-7 label = self.dataset[item]["label"] - 1 return text, label

1.3 修改训练train_val.py
修改权重/参数的保存路径,,确保目录存在
python# print(epoch,"参数保存成功!") #根据验证准确率保存最优参数 if val_acc > best_val_acc: best_val_acc = val_acc torch.save(model.state_dict(),"params02/best_bert.pth") print(f"EPOCH:{epoch}:保存最优参数:acc{best_val_acc}") #保存最后一轮参数 torch.save(model.state_dict(), "params02/last_bert.pth") print(f"EPOCH:{epoch}:最后一轮参数保存成功!")
1.4 如果需要更换模型和分词器
train_val.py
pythontoken = BertTokenizer.from_pretrained( r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
2、数据
2.1 获取数据
取的数据必须是1:1:1:1...的,不然效果不好
前往,魔搭社区获取数据集,,https://www.modelscope.cn/my/overview
python#数据集下载 from modelscope.msdatasets import MsDataset cache_dir = r"/reproduce/day05/data" ds = MsDataset.load('zhangzhihao/Simplified_Chinese_Multi-Emotion_Dialogue_Dataset', subset_name='default', split='train', cache_dir=cache_dir) #您可按需配置 subset_name、split,参照"快速使用"示例代码 #输出下载好的数据路径 print(f"数据已经下载到",ds.data_path) # for i in ds: # print(i)
2.2 整理数据
查看标签以及对应的数量
确保每个标签是1/1/1..
pythonimport os from collections import Counter file_path = "data/Weibo/train.csv" # 直接使用文件路径 if not os.path.exists(file_path): raise FileNotFoundError(f"文件不存在: {file_path}") labels = [] with open(file_path, 'r', encoding='utf-8') as f: # 跳过第一行列名 header = f.readline().strip() # 可验证 header 是否为 "label,text" 或类似 for line in f: line = line.strip() if not line: continue # 跳过空行 # 按第一个英文逗号分割 parts = line.split(',', 1) if len(parts) == 2: label, text = parts labels.append(label.strip()) else: # 处理格式异常的行(如缺少逗号、全为文本) # 可根据实际需求:跳过、记录或尝试猜测 print(f"警告:跳过无法解析的行: {line}") # 若需要统计,可自行添加逻辑,例如假设整行是text,label缺失 # 统计标签 label_counter = Counter(labels) print("标签统计结果:") for label, count in label_counter.items(): print(f"标签 '{label}': {count} 个") print(f"\n总标签类型数: {len(label_counter)} 种") print(f"总样本数量: {len(labels)} 条")很明显当前是脏数据
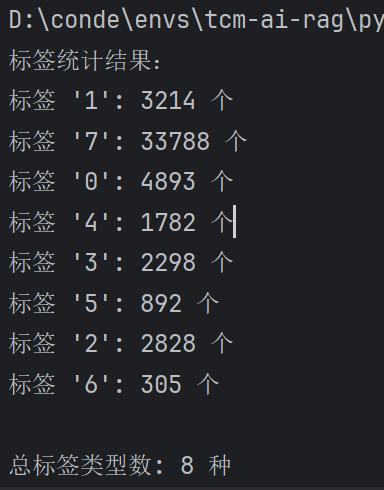
3、❌️训练
这里为了方便,并没有对数据进行清洗,这样肯定是错的
4、测试
主观测试
代码测试
很明显错误训练的,测试结果很差劲
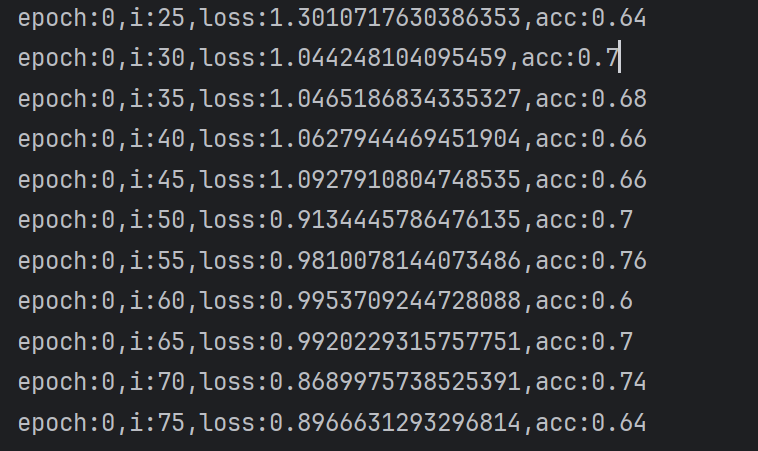
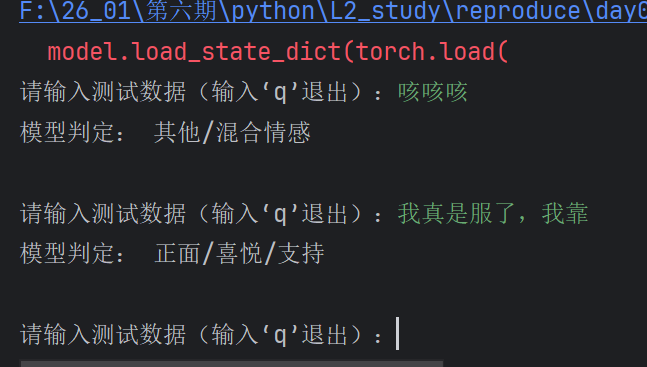
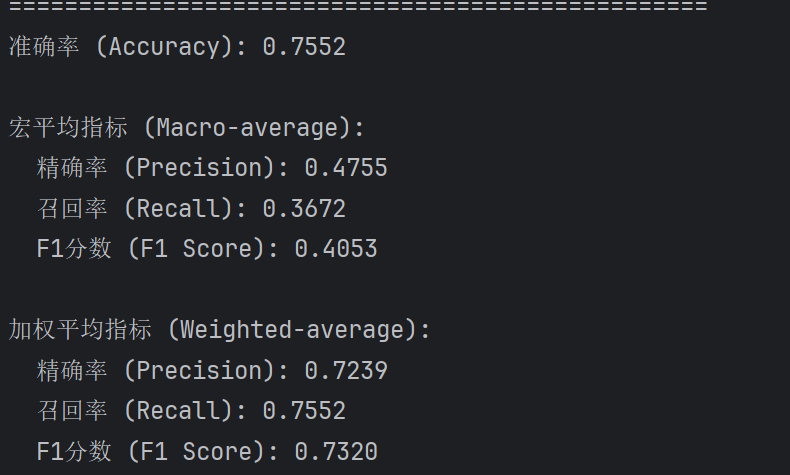
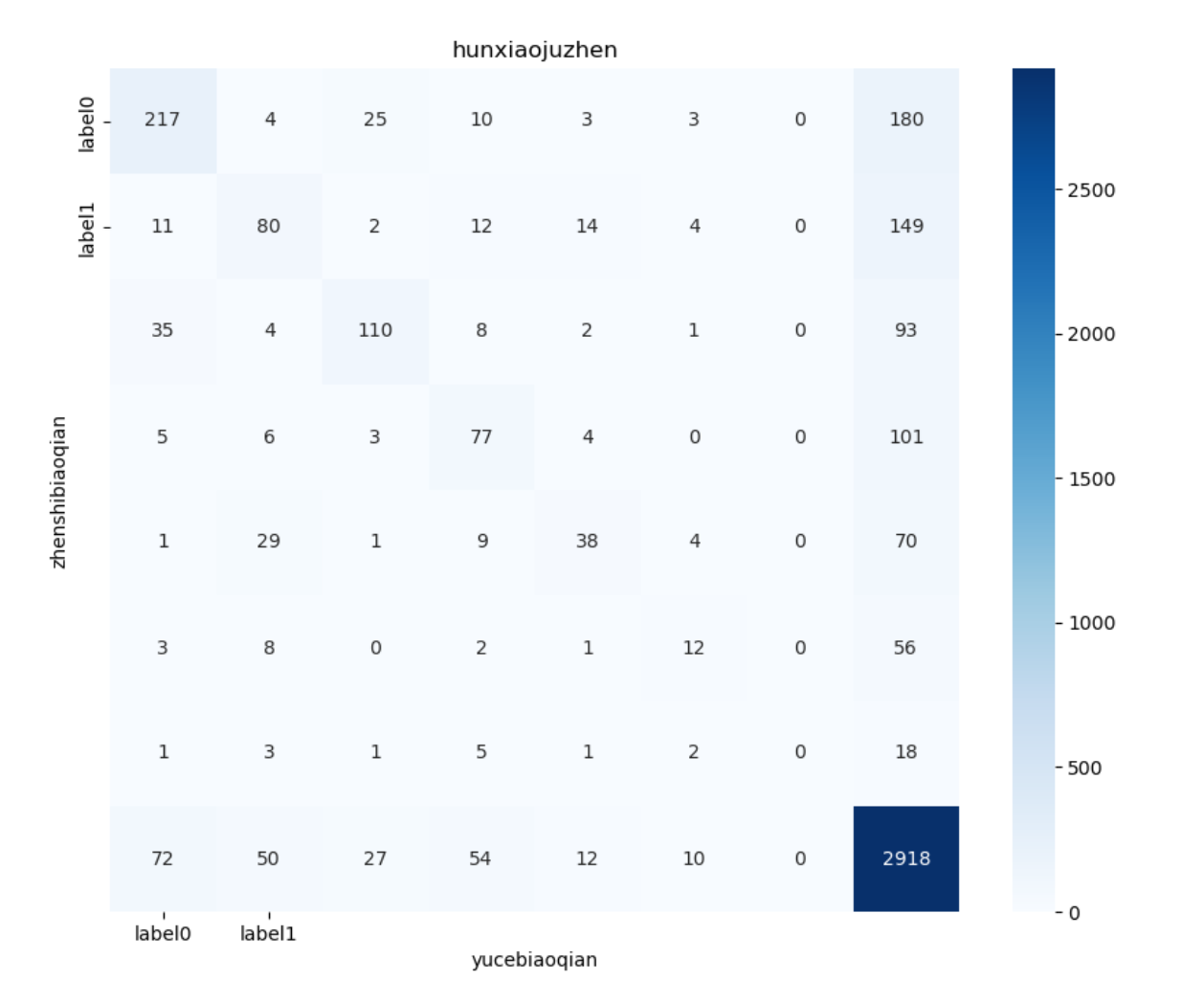
完整代码
train_val.py模型训练
python#模型训练,train_val.py import torch from torch.optim import AdamW from MyData import MyDataset from torch.utils.data import DataLoader from net import Model from transformers import BertTokenizer #定义设备信息 DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") #定义训练的轮次(将整个数据集训练完一次为一轮) EPOCH = 30000 #加载字典和分词器 token = BertTokenizer.from_pretrained(r"F:\26_01\第六期\python\L2_study\L2\day05-自定义微调训练BERT模型效果测试\demo_05\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f") #将传入的字符串进行编码 def collate_fn(data): sents = [i[0]for i in data] label = [i[1] for i in data] #编码 data = token.batch_encode_plus( batch_text_or_text_pairs=sents, # 当句子长度大于max_length(上限是model_max_length)时,截断 truncation=True, max_length=512, # 一律补0到max_length padding="max_length", # 可取值为tf,pt,np,默认为list return_tensors="pt", # 返回序列长度 return_length=True ) input_ids = data["input_ids"] attention_mask = data["attention_mask"] token_type_ids = data["token_type_ids"] label = torch.LongTensor(label) return input_ids,attention_mask,token_type_ids,label #创建数据集 train_dataset = MyDataset("train") train_loader = DataLoader( dataset=train_dataset, #训练批次 batch_size=50, #打乱数据集 shuffle=True, #舍弃最后一个批次的数据,防止形状出错 drop_last=True, #对加载的数据进行编码 collate_fn=collate_fn ) #创建验证数据集 val_dataset = MyDataset("validation") val_loader = DataLoader( dataset=val_dataset, #训练批次 batch_size=40, #打乱数据集 shuffle=True, #舍弃最后一个批次的数据,防止形状出错 drop_last=True, #对加载的数据进行编码 collate_fn=collate_fn ) if __name__ == '__main__': #开始训练 print(DEVICE) model = Model().to(DEVICE) #定义优化器 optimizer = AdamW(model.parameters()) #定义损失函数 loss_func = torch.nn.CrossEntropyLoss() #初始化验证最佳准确率 best_val_acc = 0.0 for epoch in range(EPOCH): for i,(input_ids,attention_mask,token_type_ids,label) in enumerate(train_loader): #将数据放到DVEVICE上面 input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),label.to(DEVICE) #前向计算(将数据输入模型得到输出) out = model(input_ids,attention_mask,token_type_ids) #根据输出计算损失 loss = loss_func(out,label) #根据误差优化参数 optimizer.zero_grad() loss.backward() optimizer.step() #每隔5个批次输出训练信息 if i%5 ==0: out = out.argmax(dim=1) #计算训练精度 acc = (out==label).sum().item()/len(label) print(f"epoch:{epoch},i:{i},loss:{loss.item()},acc:{acc}") #验证模型(判断模型是否过拟合) #设置为评估模型 model.eval() total_correct = 0 total_samples = 0 val_loss = 0.0 with torch.no_grad(): for i, (input_ids, attention_mask, token_type_ids, label) in enumerate(val_loader): input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE), attention_mask.to( DEVICE), token_type_ids.to(DEVICE), label.to(DEVICE) out = model(input_ids, attention_mask, token_type_ids) # 计算批次损失(已取平均) loss_batch = loss_func(out, label) val_loss += loss_batch.item() # 统计正确预测数和总样本数 preds = out.argmax(dim=1) total_correct += (preds == label).sum().item() total_samples += label.size(0) # 当前批次样本数 # 计算整个验证集的平均损失和准确率 val_loss /= len(val_loader) val_acc = total_correct / total_samples # 使用总样本数 print(f"验证集:loss:{val_loss},acc:{val_acc}") # #每训练完一轮,保存一次参数 # torch.save(model.state_dict(),f"params/{epoch}_bert.pth") # print(epoch,"参数保存成功!") #根据验证准确率保存最优参数 if val_acc > best_val_acc: best_val_acc = val_acc torch.save(model.state_dict(),"params/best_bert.pth") print(f"EPOCH:{epoch}:保存最优参数:acc{best_val_acc}") #保存最后一轮参数 torch.save(model.state_dict(), "params/last_bert.pth") print(f"EPOCH:{epoch}:最后一轮参数保存成功!")MyData.py - 数据集定义模块
python# MyData.py - 数据集定义模块 from torch.utils.data import Dataset from datasets import load_dataset class MyDataset(Dataset): #初始化数据集 def __init__(self, split): # 从磁盘加载csv数据 self.dataset = load_dataset(path="csv", data_files=f"data/Weibo/{split}.csv", split="train") #返回数据集长度 def __len__(self): return len(self.dataset) #对每条数据单独做处理 def __getitem__(self, item): text = self.dataset[item]["text"] label = self.dataset[item]["label"] return text,label if __name__ == '__main__': dataset = MyDataset("test") for data in dataset: print(data)net.py - 模型定义模块
python#net.py - 模型定义模块 import torch from transformers import BertModel #定义设备信息 DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(DEVICE) #加载预训练模型 pretrained = BertModel.from_pretrained(r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE) print(pretrained) #定义下游任务(增量模型) class Model(torch.nn.Module): def __init__(self): super().__init__() #设计全连接网络,实现八分类任务 self.fc = torch.nn.Linear(768,8) #使用模型处理数据(执行前向计算) def forward(self,input_ids,attention_mask,token_type_ids): #冻结Bert模型的参数,让其不参与训练 with torch.no_grad(): out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids) #增量模型参与训练 out = self.fc(out.last_hidden_state[:,0]) return outrun.py 模型使用接口(主观评估)- 八分类版本
python# run.py 模型使用接口(主观评估)- 八分类版本 import torch from net import Model from transformers import BertTokenizer # 定义设备信息 DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 加载字典和分词器 token = BertTokenizer.from_pretrained( r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f" ) model = Model().to(DEVICE) # 八分类标签名称(对应标签0~7) names = [ "正面/喜悦/支持", # 标签0 "负面/悲伤/崩溃", # 标签1 "中性/客观陈述", # 标签2 "愤怒/批评", # 标签3 "疑惑/提问", # 标签4 "讽刺/调侃", # 标签5 "恐惧/担忧", # 标签6 "其他/混合情感" # 标签7 ] # 将传入的字符串进行编码 def collate_fn(data): sents = [data] # 单条数据包装为列表 # 编码 data = token.batch_encode_plus( batch_text_or_text_pairs=sents, truncation=True, max_length=512, padding="max_length", return_tensors="pt", return_length=True ) input_ids = data["input_ids"] attention_mask = data["attention_mask"] token_type_ids = data["token_type_ids"] return input_ids, attention_mask, token_type_ids def test(): # 加载模型训练参数(请根据实际路径修改) model.load_state_dict(torch.load( r"F:\26_01\第六期\python\L2_study\reproduce\day05\params\best_bert.pth" )) model.eval() while True: data = input("请输入测试数据(输入'q'退出):") if data == 'q': print("测试结束") break input_ids, attention_mask, token_type_ids = collate_fn(data) input_ids, attention_mask, token_type_ids = input_ids.to(DEVICE), attention_mask.to(DEVICE), token_type_ids.to(DEVICE) with torch.no_grad(): out = model(input_ids, attention_mask, token_type_ids) pred = out.argmax(dim=1).item() print("模型判定:", names[pred], "\n") if __name__ == '__main__': test()test.py - 模型评估测试模块
python# test.py - 模型评估测试模块 import torch from MyData import MyDataset from torch.utils.data import DataLoader from net import Model from transformers import BertTokenizer from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score from sklearn.metrics import confusion_matrix, classification_report import matplotlib.pyplot as plt import seaborn as sns import numpy as np import os # 定义设备信息 DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 加载字典和分词器 token = BertTokenizer.from_pretrained( r"F:\26_01\第六期\python\L2_study\L2\day04-基于BERT模型的自定义微调训练\demo_04\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f") # 将传入的字符串进行编码 def collate_fn(data): sents = [i[0] for i in data] label = [i[1] for i in data] # 编码 data = token.batch_encode_plus( batch_text_or_text_pairs=sents, # 当句子长度大于max_length(上限是model_max_length)时,截断 truncation=True, max_length=512, # 一律补0到max_length padding="max_length", # 可取值为tf,pt,np,默认为list return_tensors="pt", # 返回序列长度 return_length=True ) input_ids = data["input_ids"] attention_mask = data["attention_mask"] token_type_ids = data["token_type_ids"] label = torch.LongTensor(label) return input_ids, attention_mask, token_type_ids, label def evaluate_model(model, test_loader, device): """ 评估模型在测试集上的性能 :param model: 待评估模型 :param test_loader: 测试数据加载器 :param device: 计算设备 :return: 评估指标字典 """ model.eval() all_preds, all_labels = [], [] for i, (input_ids, attention_mask, token_type_ids, labels) in enumerate(test_loader): # 将数据转移到设备 input_ids = input_ids.to(device) attention_mask = attention_mask.to(device) token_type_ids = token_type_ids.to(device) labels = labels.to(device) # 前向传播 with torch.no_grad(): outputs = model(input_ids, attention_mask, token_type_ids) preds = torch.argmax(outputs, dim=1) # 收集预测结果 all_preds.extend(preds.cpu().numpy()) all_labels.extend(labels.cpu().numpy()) # 计算评估指标 metrics = { 'accuracy': accuracy_score(all_labels, all_preds), 'precision_macro': precision_score(all_labels, all_preds, average='macro'), 'recall_macro': recall_score(all_labels, all_preds, average='macro'), 'f1_macro': f1_score(all_labels, all_preds, average='macro'), 'precision_weighted': precision_score(all_labels, all_preds, average='weighted'), 'recall_weighted': recall_score(all_labels, all_preds, average='weighted'), 'f1_weighted': f1_score(all_labels, all_preds, average='weighted'), 'confusion_matrix': confusion_matrix(all_labels, all_preds), 'classification_report': classification_report(all_labels, all_preds, digits=4) } return metrics def plot_confusion_matrix(cm, class_names, save_path=None): """ 绘制并保存混淆矩阵 :param cm: 混淆矩阵 :param class_names: 类别名称列表 :param save_path: 保存路径(可选) """ plt.figure(figsize=(10, 8)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=class_names, yticklabels=class_names) plt.xlabel('yucebiaoqian') plt.ylabel('zhenshibiaoqian') plt.title('hunxiaojuzhen') if save_path: plt.savefig(save_path, bbox_inches='tight') print(f"混淆矩阵已保存至: {save_path}") # plt.show() plt.savefig("my_confusion_matrix.png") plt.close() def save_metrics_to_file(metrics, save_path): """ 将评估指标保存到文本文件 :param metrics: 评估指标字典 :param save_path: 保存路径 """ with open(save_path, 'w', encoding='utf-8') as f: f.write("模型评估报告\n") f.write("=" * 50 + "\n") f.write(f"准确率 (Accuracy): {metrics['accuracy']:.4f}\n\n") f.write("宏平均指标 (Macro-average):\n") f.write(f" 精确率 (Precision): {metrics['precision_macro']:.4f}\n") f.write(f" 召回率 (Recall): {metrics['recall_macro']:.4f}\n") f.write(f" F1分数 (F1 Score): {metrics['f1_macro']:.4f}\n\n") f.write("加权平均指标 (Weighted-average):\n") f.write(f" 精确率 (Precision): {metrics['precision_weighted']:.4f}\n") f.write(f" 召回率 (Recall): {metrics['recall_weighted']:.4f}\n") f.write(f" F1分数 (F1 Score): {metrics['f1_weighted']:.4f}\n\n") f.write("分类报告 (Classification Report):\n") f.write(metrics['classification_report']) f.write("\n\n混淆矩阵 (Confusion Matrix):\n") np.savetxt(f, metrics['confusion_matrix'], fmt='%d') print(f"评估报告已保存至: {save_path}") if __name__ == '__main__': # 创建数据集 test_dataset = MyDataset("test") test_loader = DataLoader( dataset=test_dataset, batch_size=100, shuffle=False, # 评估时不需要打乱 drop_last=False, # 保留所有样本 collate_fn=collate_fn ) # 开始测试 print(f"使用设备: {DEVICE}") model = Model().to(DEVICE) # 模型参数路径 model_path = r"F:\26_01\第六期\python\L2_study\reproduce\day05\params\best_bert.pth" if not os.path.exists(model_path): raise FileNotFoundError(f"模型参数文件不存在: {model_path}") # 加载模型训练参数 model.load_state_dict(torch.load(model_path)) # 评估模型 metrics = evaluate_model(model, test_loader, DEVICE) # 打印评估结果 print("\n" + "=" * 50) print(f"准确率 (Accuracy): {metrics['accuracy']:.4f}") print("\n宏平均指标 (Macro-average):") print(f" 精确率 (Precision): {metrics['precision_macro']:.4f}") print(f" 召回率 (Recall): {metrics['recall_macro']:.4f}") print(f" F1分数 (F1 Score): {metrics['f1_macro']:.4f}") print("\n加权平均指标 (Weighted-average):") print(f" 精确率 (Precision): {metrics['precision_weighted']:.4f}") print(f" 召回率 (Recall): {metrics['recall_weighted']:.4f}") print(f" F1分数 (F1 Score): {metrics['f1_weighted']:.4f}") print("\n分类报告 (Classification Report):") print(metrics['classification_report']) # 可视化混淆矩阵 # 注意:根据您的实际类别修改class_names class_names = ["label0", "label1"] # 替换为您的实际类别名称 plot_confusion_matrix(metrics['confusion_matrix'], class_names, "confusion_matrix.png") # 保存评估结果 save_metrics_to_file(metrics, "my_evaluation_report.txt") print("评估完成!")