在前序章节中(上一章地址),我们已经完成了基础的 RAG 功能实现,即基于组件库文档检索并回答用户问题。但目前的 Agent 助手仅具备核心的问答能力,如同只拥有 "大脑",仍有大量功能尚未完善。本章将继续为其补充交互与执行能力,为 Agent 装上 "手脚",让它拥有更完整、更实用的智能交互能力。
1. 记忆(Memory)
我们希望 Agent 助手在对话过程中具备记忆能力,能够记录用户历史提问与自身回复内容,并基于上下文进行思考、总结与规划,从而输出更精准可靠的结果。若无记忆机制,Agent 将无法理解对话上下文,难以推进复杂任务,无法形成连贯的智能交互行为,仅能完成孤立、单次的问答交互。
你问:"帮我查北京天气",再问:"那明天呢?"它会反问:"明天什么?"
1.1. 自定义ChatHistory
我们使用自定义ChatHistory把聊天记录储存到本地中。接下来用代码实现一下:
在根目录下新建utils/index.js文件:
js
import { BaseListChatMessageHistory } from "@langchain/core/chat_history";
/**
* 基于 JSON 文件的聊天历史记录类
* 继承自 LangChain 的 BaseListChatMessageHistory,用于持久化存储对话记录
*/
export class JSONChatHistory extends BaseListChatMessageHistory {
// LangChain 命名空间,用于序列化识别
lc_namespace = ["langchain", "store", "message"];
// 会话唯一标识
sessionId = '';
// 存储目录路径
dir = '';
/**
* 构造函数
* @param {Object} fields - 配置对象
* @param {string} fields.sessionId - 会话 ID
* @param {string} fields.dir - 存储目录路径
*/
constructor(fields) {
super(fields);
this.sessionId = fields.sessionId;
this.dir = fields.dir;
}
/**
* 获取所有历史消息
* @returns {Promise<BaseMessage[]>} 消息列表
*/
async getMessages() {}
/**
* 添加单条消息
* @param {BaseMessage} message - 消息对象
* @returns {Promise<void>}
*/
async addMessage(message) {}
/**
* 添加多条消息
* @param {BaseMessage[]} messages - 消息数组
* @returns {Promise<void>}
*/
async addMessages(messages) {}
/**
* 将消息保存到文件
* @param {BaseMessage[]} messages - 消息数组
* @returns {Promise<void>}
*/
async saveMessagesToFile(messages) {}
/**
* 清空历史记录
* @returns {Promise<void>}
*/
async clear() {}
/**
* 添加 AI 消息(兼容旧版本 BufferMemory 的废弃方法)
* @param {string} message - 消息内容
* @returns {Promise<void>}
* @deprecated 建议使用 addMessage 方法
*/
async addAIChatMessage(message) {
return this.addMessage(new AIMessage(message));
}
}这里声明了JSONChatHistory类,并继承自BaseListChatMessageHistory。
BaseListChatMessageHistory 是 LangChain 框架中用于管理聊天历史记录 的抽象基类。主要作用:
- 标准化接口:为不同的聊天历史存储方式(内存、文件、数据库等)提供统一的接口。
- 核心方法 :
getMessages()- 获取所有历史消息addMessage(message)- 添加单条消息addMessages(messages)- 添加多条消息clear()- 清空历史记录
- 使用场景 :
- 与
BufferMemory等内存组件配合,让 AI 模型能够"记住"对话上下文 - 实现自定义的持久化存储(如你的代码中用 JSON 文件存储)
- 与
接着完成类的具体实现,首先在constructor构造函数中,声明了lc_namespace=["langchain", "store", "message"]。
- 作用 :当 LangChain 需要序列化(保存/导出)这个聊天历史对象时,
lc_namespace帮助识别这个类的类型和来源。 - 格式 :
["langchain", "store", "messsage"]表示这个类属于langchain库的store模块下的message命名空间。 - 使用场景 :
- 当你将对话历史保存到文件或数据库时
- 当你需要反序列化(加载)对象时,LangChain 可以通过这个命名空间找到对应的类定义
第10-12行,11行声明了 sessionId 用于标识会话 ID,作为本地存储文件的唯一标识;12行dir 则指定本地存储文件夹的路径。然后实现了所有抽象方法,包括获取消息、添加消息、保存到文件和清空历史记录等功能。
然后我们先实现saveMessagesToFile,新增如下代码:
js
import { mapChatMessagesToStoredMessages } from "@langchain/core/messages";
export class JSONChatHistory extends BaseListChatMessageHistory {
//...省略部分代码
/**
* 将消息保存到文件
* @param {BaseMessage[]} messages - 消息数组
* @returns {Promise<void>}
*/
async saveMessagesToFile(messages) {
const filePath = path.join(this.dir, `${this.sessionId}.json`);
const serializedMessages = mapChatMessagesToStoredMessages(messages);
try {
fs.writeFileSync(filePath, JSON.stringify(serializedMessages, null, 2), {
encoding: 'utf8',
});
} catch(error) {
console.error(`Failed to save chat history to ${filePath}`, error);
}
}第12行代码将sessionId定为文件名称,然后通过path.join拼接dir目录。
第13行使用了 LangChain 的工具函数 mapChatMessagesToStoredMessages,它将聊天消息对象转换为可存储的 JSON 格式,便于持久化。
打印一下转化后的JSON格式看一下:
js
{
"type": "human",
"data": {
"content": "请你介绍下input组件的基本用法以及它支持哪些参数,回答尽量详细",
"additional_kwargs": {},
"response_metadata": {}
}
},
{
"type": "ai",
"data": {
"content": "根据原文,Input 组件的基本用法如下:\n\n**基本用法**:使用 `v-model` 进行双向数据绑定,并通过 `placeholder` 属性设置占位文本。\n```html\n<el-input v-model=\"input\" placeholder=\"请输入内容\"></el-input>\n```\n\nInput 组件支持以下参数(Attributes):\n* `placeholder`:输入框占位文本,类型为 `string`。\n* `disabled`:禁用输入框,类型为 `boolean`,默认值为 `false`。\n* `value-key`:输入建议对象中用于显示的键名,类型为 `string`。\n* `value`:必填值,输入绑定值,类型为 `string`。\n* `debounce`:获取输入建议的去抖延时,类型为 `number`,默认值为 `300`。\n* `size`:尺寸,类型为 `string`,可选值为 `medium` / `small` / `mini`。\n* `type`:类型,类型为 `string`,可选值为 `primary` / `success` / `warning` / `danger` / `info` / `text`。\n* `plain`:是否朴素按钮,类型为 `boolean`,默认值为 `false`。\n* `round`:是否圆角按钮,类型为 `boolean`,默认值为 `false`。\n* `circle`:是否圆形按钮,类型为 `boolean`,默认值为 `false`。\n* `suffix-icon`:输入框尾部图标,类型为 `string`。\n* `rows`:输入框行数,只对 `type=\"textarea\"` 有效,类型为 `number`,默认值为 `2`。\n* `autosize`:自适应内容高度,只对 `type=\"textarea\"` 有效,可传入对象,如 `{ minRows: 2, maxRows: 6 }`,类型为 `boolean / object`,默认值为 `false`。\n* `autocomplete`:原生属性,自动补全,类型为 `string`,可选值为 `on, off`,默认值为 `off`。\n* `label`:输入框关联的label文字,类型为 `string`。\n* `prefix-icon`:输入框头部图标,类型为 `string`。\n* `hide-loading`:是否隐藏远程加载时的加载图标,类型为 `boolean`,默认值为 `false`。\n* `popper-append-to-body`:是否将下拉列表插入至 body 元素。在下拉列表的定位出现问题时,可将该属性设置为 false,类型为 `boolean`,默认值为 `true`。\n* `highlight-first-item`:是否默认突出显示远程搜索建议中的第一项,类型为 `boolean`,默认值为 `false`。\n* `maxlength`:原生属性,最大输入长度,类型为 `number`。",
"tool_calls": [],
"invalid_tool_calls": [],
"additional_kwargs": {},
"response_metadata": {}
}
},type表示是ai回答还是用户提问,data里是提问或回答的具体内容,这是一个BaseMessage类。
第4行将JSON化后的字符串写入filePath目录。
接着我们完成获取本地目录所有聊天信息,也就是getMessages方法:
js
import { mapStoredMessagesToChatMessages } from "@langchain/core/messages";
async getMessages() {
const filePath = path.join(this.dir, `${this.sessionId}.json`);
try {
if (!fs.existsSync(filePath)) {
this.saveMessagesToFile([]);
return [];
}
const data = fs.readFileSync(filePath, { encoding: 'utf8' });
const storedMessages = JSON.parse(data);
return mapStoredMessagesToChatMessages(storedMessages);
} catch(error) {
console.error(`Failed to read chat history from ${filePath}`, error);
return [];
}
}第6-9行,判断filePath目录是否存在,不存在则调用saveMessagesToFile创建聊天记录目录。
第11-13行,读取聊天记录目录下的json文件,然后通过JSON.parse将JSON字符串转为js字符串,接着通过mapStoredMessagesToChatMessages将js字符串转为真正的Messages对象。
同样打印一下转化为chat message后的对象:
js
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"AIMessage"
],
"kwargs": {
"content": "根据原文,**el-input组件的基本用法**是:\n\n**使用 `v-model` 进行双向数据绑定,并通过 `placeholder` 属性设置占位文本。**\n\n**示例代码:**\n```html\n<el-input v-model=\"input\" placeholder=\"请输入内容\"></el-input>\n\n<script>\nexport default {\n data() {\n return {\n input: ''\n }\n }\n}\n</script>\n```\n\n**重要说明:**\n1. **Input 是受控组件**:它**总会显示 Vue 绑定值**,因此必须处理 `input` 事件并更新绑定值(或使用 `v-model`)。\n2. **不支持 `v-model` 修饰符**:如 `.trim`、`.number` 等修饰符不被支持。\n3. **基础用法核心**:通过 `v-model` 实现数据的双向绑定,`placeholder` 提供输入提示。",
"tool_calls": [],
"invalid_tool_calls": [],
"additional_kwargs": {},
"response_metadata": {}
}
},
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"HumanMessage"
],
"kwargs": {
"content": "请你介绍下input组件的基本用法以及它支持哪些参数,回答尽量详细。",
"additional_kwargs": {},
"response_metadata": {}
}
},这里是BaseMessage对象包含的属性,主要是在id里标识是AIMessage还是HumanMessage,并且在kwargs的content里是具体的回答和提问内容。
接下去继续实现addMessage和addMessages方法:
js
/**
* 添加单条消息
* @param {BaseMessage} message - 消息对象
* @returns {Promise<void>}
*/
async addMessage(message) {
const messages = await this.getMessages();
messages.push(message);
await this.saveMessagesToFile(messages);
}
/**
* 添加多条消息
* @param {BaseMessage[]} messages - 消息数组
* @returns {Promise<void>}
*/
async addMessages(messages) {
const existingMessages = await this.getMessages();
const allMessages = existingMessages.concat(messages);
await this.saveMessagesToFile(allMessages);
}这两个方法比较类似,先读取在目录中历史消息,然后通过push或者concat连接新的消息,再存入本地目录中。至此ChatHistory自定义类已经全部完成,我们要接入到Agent中。
1.2. Agent接入Memory
回到agent/index.js目录,我们增加如下代码:
js
import { readFromMDFiles, JSONChatHistory } from '../utils/index.js';
import { RunnableWithMessageHistory } from "@langchain/core/runnables";
export async function getRagChain() {
//...省略部分代码
// 创建一个聊天提示模板,用于生成问题回答的提示
const prompt = ChatPromptTemplate.fromMessages([
['system', SYSTEM_TEMPLATE],
new MessagesPlaceholder('history'),
['human', '现在,你需要基于原文,回答以下问题:\n{standalone_question}`'],
]);
const ragChain = RunnableSequence.from([
RunnablePassthrough.assign({
context: contextRetrieverChain,
}),
prompt,
model,
new StringOutputParser(),
]);
// 定义chat-history目录
const chatHistoryDir = process.cwd() + '/chat-history';
// 创建一个 RunnableWithMessageHistory 对象,用于将聊天历史记录与检索链结合起来
const ragChainWithHistory = new RunnableWithMessageHistory({
runnable: ragChain, // 被包装的 RAG 链
getMessageHistory: (sessionId) =>
new JSONChatHistory({ sessionId, dir: chatHistoryDir }), // 获取历史记录的方式
historyMessagesKey: 'history', // 历史消息在 prompt 中的变量名
inputMessagesKey: 'question', // 用户输入的变量名
});
return ragChainWithHistory;
}第7-11行,新增了MessagePlaceHolder('history')这里新增了一个history的占位符,用来放置Memory相关的记忆记录。
第21行定义了chat-history本地目录地址。
第23-30行,这里使用了RunnableWithMessageHistory,这是 LangChain 提供的一个包装类,用于将聊天历史记录功能集成到任意的 Runnable 链中 。它让 RAG 链具备了多轮对话记忆能力,能够记住之前的对话上下文,使 AI 能够理解连续的问题。
工作流程
- 用户提问 → 自动从
JSONChatHistory加载该会话的历史消息 - 构建 Prompt → 将历史消息 + 当前问题一起传入
- 模型回答 → 将 AI 回复保存回
JSONChatHistory - 下次对话 → 重复上述过程,保持上下文连贯
chat history部分基本已经完成,我们在调用的地方增加一些参数,代码如下:
js
apiRouter.post('/chat', async (req, res) => {
const { question, sessionId = 'default' } = req.body;
if (!question) {
return res.status(400).json({ error: 'Question is required' });
}
try {
// 获取请求体
const result = await chain.invoke(
{ question },
{ configurable: { sessionId }
});
res.json({ content: result });
} catch (error) {
console.error('Error during chat:', error);
res.status(500).json({ error: 'Internal server error' });
}
});我们来试试看,问它一下刚刚问了什么问题:
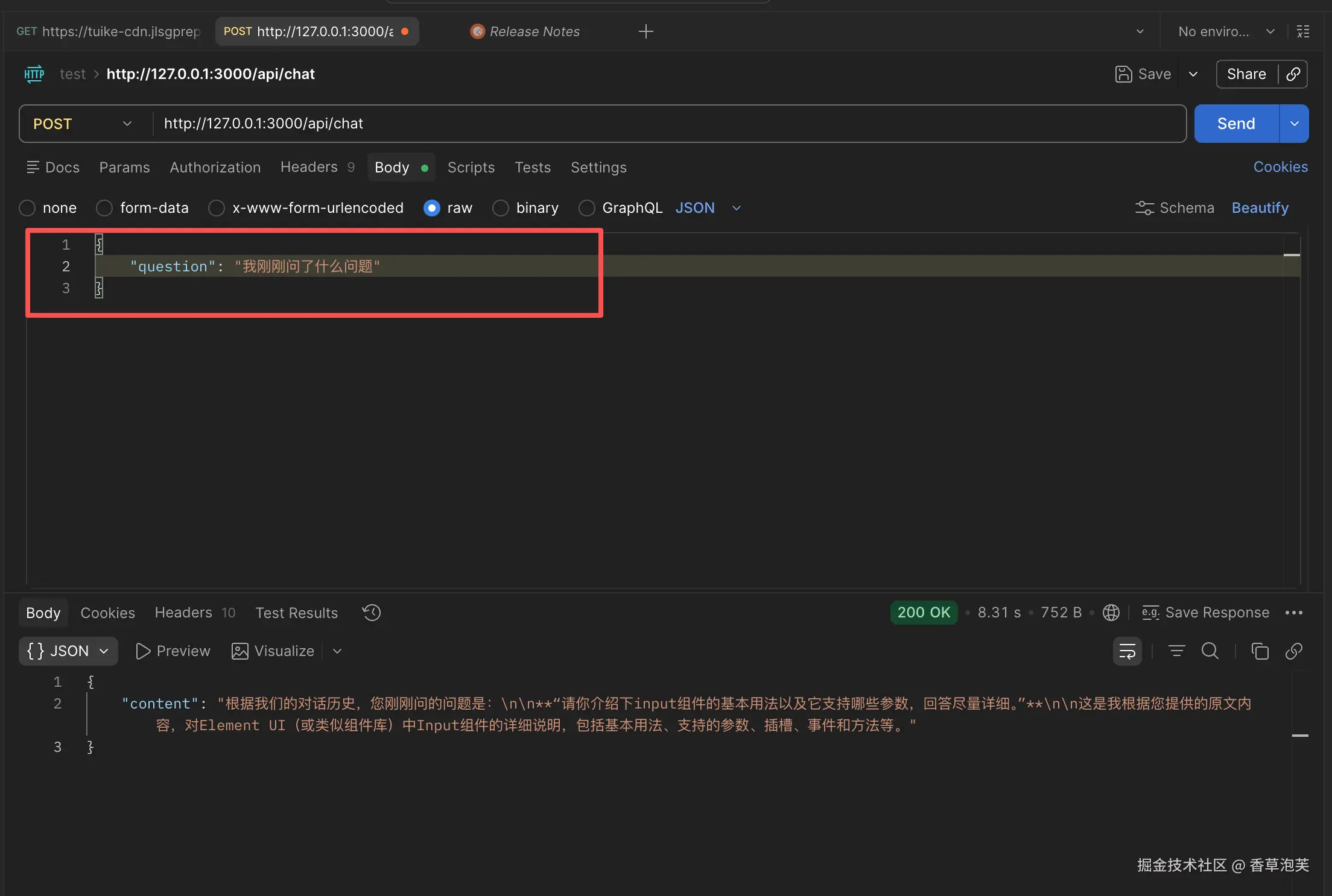
确实是历史记录中刚刚的提问,说明我们的历史记录已经生效了。这样它就能结合之前的回答来总结出最新的答案。
好了后端部分基本已经完成,接下去完成前端部分。
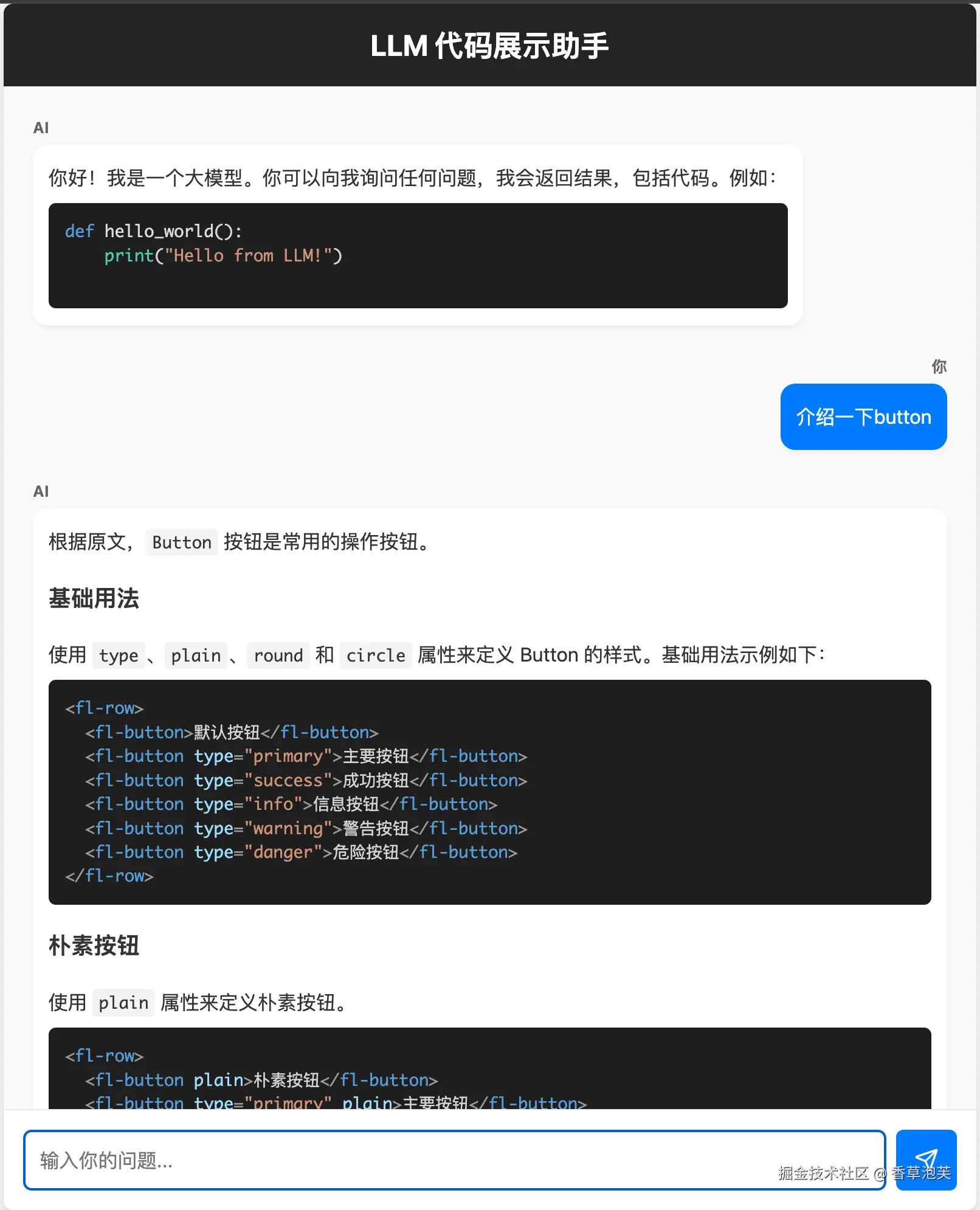
2. 前端代码
这里要搭建一个聊天界面,整体代码直接给出,我们挑几个重点讲一下如何实现。代码地址
2.1. Markdown转换
由于大模型返回的是Markdown格式的字符串,因此需要使用Markdown转换器将其转为HTML进行渲染。我使用了MarkdownIt库以及highlightjs来做代码的高亮提示。具体代码如下:
js
import MarkdownIt from 'markdown-it';
import hljs from 'highlight.js';
import 'highlight.js/styles/vs2015.css';
interface MarkdownRendererProps {
content: string;
}
// 初始化 markdown-it 实例,配置 highlight.js 进行语法高亮
const md: MarkdownIt = new MarkdownIt({
html: true,
linkify: true,
typographer: true,
highlight: function (str: string, lang: string): string {
if (lang && hljs.getLanguage(lang)) {
try {
return hljs.highlight(str, { language: lang }).value;
} catch (e) {
console.warn('Highlight error', e);
}
}
// 如果语言不支持或出错,使用自动高亮
try {
return hljs.highlightAuto(str).value;
} catch (e) {
console.warn('Auto highlight error', e);
}
// 如果都失败,直接返回文本并转义 HTML
return md.utils.escapeHtml(str);
},
});
const MarkdownRenderer: React.FC<MarkdownRendererProps> = ({ content }) => {
// 使用 markdown-it 将 Markdown 转换为 HTML
const htmlContent = md.render(content);
return (
<div
className='markdown-body'
dangerouslySetInnerHTML={{ __html: htmlContent }}
/>
);
};过程还是比较简单的,借助MarkdownIt就能轻松转换,最后通过dangerouslySetInnerHTML进行渲染。
2.2. 打字机效果
在上节中实现的RAG Chain是一次性将结果返回的,这样如果返回的内容非常大,等待结果会非常长,这样的体验会非常差。因此我们需要将chain返回改成流式,让它能够一段一段的返回,优先展示已经生成的结果。
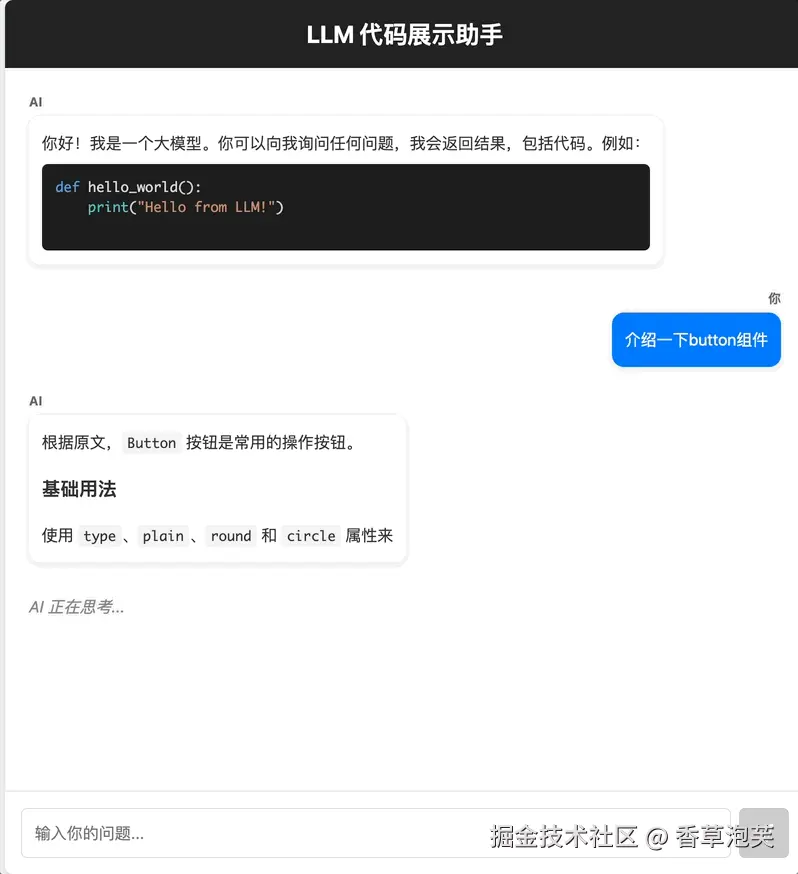
首先需要对agent服务器进行改造,改造如下:
js
apiRouter.get('/chat', async (req, res) => {
const { question, sessionId = 'default' } = req.query;
if (!question) {
return res.status(400).json({ error: 'Question is required' });
}
try {
// 设置 SSE 响应头
res.setHeader('Content-Type', 'text/event-stream');
res.setHeader('Cache-Control', 'no-cache');
res.setHeader('Connection', 'keep-alive');
// 使用 stream 模式调用 chain
const stream = await chain.stream(
{ question },
{ configurable: { sessionId } }
);
// 逐块返回数据
for await (const chunk of stream) {
res.write(`data: ${JSON.stringify({ content: chunk })}\n\n`);
}
// 发送结束标记
res.write(`data: ${JSON.stringify({ done: true })}\n\n`);
res.end();
} catch (error) {
console.error('Error during chat:', error);
res.write(`data: ${JSON.stringify({ error: 'Internal server error' })}\n\n`);
res.end();
}
});这里使用 SSE(Server-Sent Events)实现流式返回,因此需要在响应头中设置 Content-Type: text/event-stream,标识返回格式为流式数据(第 10 行)。
第 15-18 行,将 chain.invoke() 改为 chain.stream(),使 LLM 的返回变为流式格式。
第 21-27 行,遍历流式数据,逐块提取内容并通过 res.write() 实时返回给客户端。
然后前端这边进行改造:
ts
/**
* 使用 SSE 方式接收流式聊天响应
* @param {string} prompt - 用户输入的提示词
* @param {Function} onChunk - 接收到数据块时的回调函数
* @param {Function} onComplete - 接收完成时的回调函数
* @param {Function} onError - 发生错误时的回调函数
*/
export const fetchChatStream = (
prompt: string,
onChunk: (chunk: string) => void,
onComplete: () => void,
onError: (error: Error) => void
) => {
const baseURL = import.meta.env.VITE_API_BASE_URL || 'http://127.0.0.1:3000/api';
const eventSource = new EventSource(`${baseURL}/chat?question=${encodeURIComponent(prompt)}`);
eventSource.onmessage = (event) => {
const data = JSON.parse(event?.data || '{}');
if (data.done === true) {
eventSource.close();
onComplete();
} else {
onChunk(data.content);
}
};
eventSource.onerror = () => {
eventSource.close();
onError(new Error('SSE 连接错误'));
};
// 返回关闭连接的方法
return () => eventSource.close();
};重点在15-25行,前端这边使用EventSource创建连接,然后在onmessage回调函数中不断接收服务器推送的内容,在onChunk中进行内容拼接,我们看一下onChunk:
js
(chunk) => {
// 接收到数据块时更新消息内容
setMessages(prev => {
const newMessages = [...prev];
// 如果返回消息存在,则不断地增加content内容
if (newMessages[assistantIndex]) {
newMessages[assistantIndex] = {
...newMessages[assistantIndex],
content: newMessages[assistantIndex].content + chunk
};
}
return newMessages;
});
},2.3. 返回历史记录
现在每次刷新都会清空历史记录,因为我们未实现读取历史记录。
这里来实现一下这个功能,首先在后端服务器新增读取历史记录接口:
js
import { JSONChatHistory } from '../utils/index.js';
// 新增读取agent历史记录的接口
apiRouter.get('/history', async (req, res) => {
const { sessionId = 'default' } = req.query;
const chatHistoryDir = process.cwd() + '/chat-history';
try {
const chatHistory = new JSONChatHistory({ sessionId, dir: chatHistoryDir });
const messages = await chatHistory.getMessages();
// 将消息转换为前端友好的格式
const formattedMessages = messages.map(msg => ({
type: msg._getType(), // 'human' 或 'ai'
content: msg.content,
timestamp: msg.additional_kwargs?.timestamp || null
}));
res.json({
sessionId,
messages: formattedMessages,
});
} catch (error) {
console.error('Error fetching history:', error);
res.status(500).json({ error: 'Failed to fetch chat history' });
}
});这里使用之前实现的JSONChatHistory类来读取历史的聊天记录,然后转换为特定的格式返回给前端。
前端这边只需要在初始化时调用该接口,并渲染里面的内容即可:
js
// 初始化时加载历史记录
useEffect(() => {
const loadHistory = async () => {
try {
const history = await fetchChatHistory();
if (history && history.length > 0) {
// 将历史记录转换为 Message 格式
const historyMessages: Message[] = history.map((msg) => ({
role: msg.type === 'human' ? 'user' : 'assistant',
content: msg.content
}));
setMessages(historyMessages);
}
} catch (error) {
console.error('加载历史记录失败:', error);
}
};
loadHistory();
}, []);前端这边直接调用fetchChatHistory接口,再通过msgType来辨别是human信息还是ai信息,再进行role变量赋值。来试一下结果:
3. 总结
我们在两章内容中实现了基于LangChain的组件库RAG问答系统。该系统支持多轮对话,后端基于Express服务器提供流式返回内容;前端则实现了Markdown渲染、SSE流式响应以及历史记录展示。后续有机会再讨论如何接入MCP的流程。