1.机器学习:就是让机器具备找函式(寻找规律)的能力。
2.不同类型的函式:
回归:函数输出一个数值,输入可能是多种能够判断输出结果的指标,预测连续数值。
分类:给定选项类,函式输出正确的选项,预测离散类型。
如何找到函式:a.假设函数y(y就是模型,可带有未知参数);b.根据训练数据定义损失L(判断模型的好坏,实际也是一个函数);c.优化(Optimiztion),找最佳的y中的未知参数,使得损失最小。
MAE:均值绝对误差,e=|y-y'|(y'为预测值,y为真实值)
MSE:均方差,e=(y-y')²(y'为预测值,y为真实值)
:学习率,寻找未知参数的最佳值时用到
3.模型分为:线性模型、非线性模型
liner function:(会具有模型偏差)
Sigmoid function:(w改变斜率、b改变左右位置、c改变上下高度)
Rectified Liner Unit(RLU)
4.深度学习:由多个神经元组成神经层,从而构成深度神经网络的机器学习。
神经元 (Neuron):基本计算单元,接收输入,加权求和,通过激活函数输出(相当于过滤器)。
层:输入出、隐藏层(进行特征提取和变换)、输出层。
激活函数:让网络拟合出复杂的曲线。(ReLU、Sigmoid)
5.常见的网络架构:
CNN(卷积神经网络):处理网络状数据。(图像)
RNN(循环神经网络):处理序列数据,具有"记忆"特点。(文本)
GAN(生成对抗网络):生成内容。
6.(AI生成)
| 术语 | 解释 | 通俗理解 |
|---|---|---|
| 特征 (Feature) | 输入数据的属性 | 比如预测房价,特征就是"面积"、"地段"、"房龄"。 |
| 标签 (Label) | 想要预测的目标值 | 比如预测房价,标签就是具体的"价格"。 |
| 模型 (Model) | 经过训练后的算法文件 | 就像学生学完知识后的大脑,可以用来做题。 |
| 训练集/测试集 | 用于训练和验证的数据划分 | 训练集是"课本",测试集是"期末考试题"。 |
| 损失函数 (Loss) | 衡量预测值与真实值差距的公式 | 考试扣了多少分,分数越低越好。 |
| 优化器 (Optimizer) | 用于更新模型参数的算法 | 老师根据错题指导学生如何改进学习方法(如 SGD, Adam)。 |
| 梯度下降 (Gradient Descent) | 寻找损失函数最小值的方法 | 下山的过程,一步步往坡度最陡的地方走,直到谷底。 |
| 过拟合 (Overfitting) | 模型在训练集表现好,测试集表现差 | "死记硬背",课本题都会,考试换个题就不会了。 |
| 欠拟合 (Underfitting) | 模型在训练集和测试集表现都差 | "没学懂",课本题都不会。 |
| 超参数 (Hyperparameter) | 训练前人工设定的参数 | 如学习率、网络层数(类似于"每天学几小时")。 |
7.训练损失
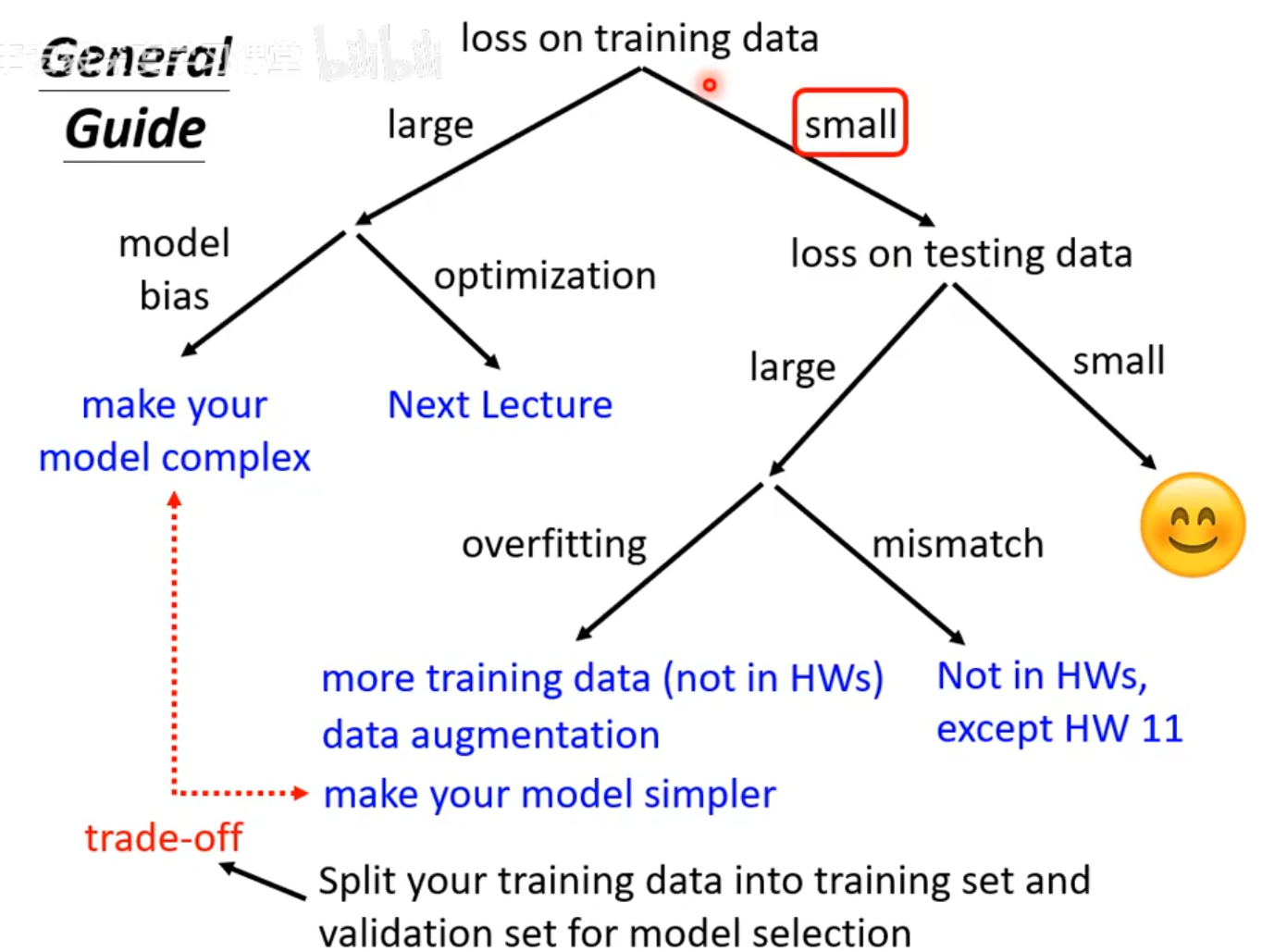
8.过拟合
表现:训练集准确率很高,但测试集/验证集准确率很低)。
本质:模型太复杂,记住了数据中的"噪声"而不是"规律"。
解决方法:
增加训练数据
数据增强(没有足够的数据,需要对原数据进行变换)
给模型进行限制:减少参数、使用共享参数、去掉不相关或冗余的特征、早停法(early stopping)、正则化技术(Regularization)、Dropout。
9.欠拟合
表现:训练集准确率低,测试集/验证集准确率很低。
本质:模型太简单。
解决方法:
增加模型复杂度
减少正则化
增加新特征
增加训练时间(epoch)