一、什么是KNN
KNN(K-Nearest Neighbor)K邻近算法,是机器学习中常用的分类算法,思想基础是"物以类聚,人以群分",即要判断一个新数据的类别,就看它的邻居。
K值就是用离新数据样本p最近的K个样本来判断p的类别,这里的距离可以是欧氏距离、曼哈顿距离等。
KNN算法的核心流程:
①在已知类别中,计算样本集中的样本与当前测试数据(待分类数据)的距离;
②按照距离递增次序排序;
③选取与当前测试数据距离最小的k个样本;
④统计前k个样本属于各个类别的出现频率;
⑤将前k个样本中出现频率最高的类别作为当前点测试数据的分类结果。
所以,KNN的缺点是,数据越多计算量越大,效率就越低,故而很难运用到较大数据的训练中。
感兴趣的同学可以详细了解:KNN算法(k近邻算法)原理及总结
二、为什么要在OSI的物理层中引入KNN
2.1、背景
我们知道,下小雨时打伞就够用,下大雨时穿雨衣雨鞋是更妥善的方法;如果不知道今天外面下多大的雨,那只好考虑最坏的情况穿雨衣雨鞋;但是如果只是一直下小雨,穿雨衣雨鞋就会没有打伞轻便。随着技术的发展,我们有了天气预报,可以告诉人们外面是将要下大雨还是下小雨,让人们可以自行调整雨具的选择。
在无线通信的的传输过程中,传统的调制方式包括AM、FM、PM、ASK、FSK、PSK、PAM、QAM等。若采用固定的调制方式,调制阶数越低抗干扰和噪声的能力越强(归一化星座图上相邻星座点间的欧氏距离越大),但是实际信道中往往需要考虑最恶劣的情况(信道噪声波动大),因此通常选择地接调制;但若信道质量很好,则频谱利用率就会很低。
因此Cavrs在1972年提出根据接收信号电平自适应调整符号传输速率的方法来对抗信道衰落,这种方法自适应地选择不同的调制方式:当信道质量差时选择地接调制,保证可靠性,当信道质量好是选择高阶调制,在保证可靠性的前提下提高了有效性。
2.2、KNN的引入
传统的AMC技术基于信令来传输调制方式的信息 ,即接收机自适应地选择频谱调制方式并通过信令反馈给发射机,发射机确定调制方式并通过信令通知接收机,但是信令传输需要占用频谱/时隙/功率资源。
为了克服该缺点,我们引入了自动调制识别技术(例如KNN) ,即接收机根据接收数据的特征分析及算法判别其调制方式**(第一章:KNN的作用为将样本数据分类)**。通过这样的方式,我们就无需收发机之间传输调制方式相关的信令,节省了频谱资源。
KNN主要应用于支持AMC调制方式,以及不同调制信号的探测识别。
三、基于KNN算法的调制识别技术建模
3.1、调制信号的高阶累积量
3.3.1、KNN分类调制信号的依据
调制信号的特征有很多,包络基于频谱特性的特征、基于小波变换的特征、基于高阶统计特性的特征、基于时域特性的特征等等。机器学习中我们常用高阶统计量的特征来区分调制信号的调制类型。
3.1.2、广义高阶累积量的定义
广义高阶矩:对于一个具有零均值的复随机过程 X( t) , 其广义高阶矩定义为:
其中,E 表示求期望运算,* 表示函数的共轭。
广义高阶累积量:定义式:
其中,联合累积量cum:
L维随机矢量的特征函数为
3.1.3、常用高阶累积量计算公式
3.1.4、常用高阶累积量
|-----|----------|----------|-----------|-----------|------------|
| | BPSK | QPSK | 16QAM | 64QAM | 256QAM |
| C20 | 1 | 0 | 0 | 0 | 0 |
| C21 | 1 | 1 | 1 | 1 | 1 |
| C40 | 2 | 1 | 0.68 | 0.62 | 0.6 |
| C41 | 2 | 0 | 0 | 0 | 0 |
| C42 | 2 | 1 | 0.68 | 0.62 | 0.6 |
| C60 | 16 | 0.36 | 0.27 | 0.26 | 0.25 |
| C61 | 16 | 4 | 2.08 | 1.8 | 1.7 |
| C62 | 16 | 0.25 | 0.22 | 0.2 | 0.2 |
| C63 | 16 | 4 | 2.08 | 1.8 | 1.8 |
3.2、基于高阶累积量的调制信号样本集构造
3.2.1、特征向量建模
本案例算法以上述高阶累积量的部分之作为特征参量,设计特征向量,构造从原始信号空间想特征向量空间的映射。本案例中,选择二、三、四阶统计量构成特征向量,以BPSK信号为例,其特征向量表示为:
其余调制方式处理过程类似。还可以设计更为优秀的特征向量,例如引入更多的高阶累积量,或者各种累积量的计算组合,以增加不同调制方式特征向量的区分度。
3.2.2、训练样本集建模
假设对于每一种调制方式,分别生成M=10组数据,每组包含N=500个调制符号,所以原始训练集:
|-------|-----------|---------|------------------|
| BPSK | 10组×500符号 | 每符号1bit | 需生成 500 个随机 bit |
| QPSK | 10组×500符号 | 每符号2bit | 需生成 1000 个随机 bit |
| 16QAM | 10组×500符号 | 每符号4bit | 需生成 2000 个随机 bit |
| 64QAM | 10组×500符号 | 每符号6bit | 需生成 3000 个随机 bit |
训练样本集建模:
等价于:
3.2.3、训练样本的特征向量集建模
以BPSK信号为例,每组 N = 500 个符号经过调制后,计算出 L = 5 个归一化高阶累积量特征:
最终形成一组BPSK500个符号训练后得到 1 条特征向量:
因此每种调制方式贡献N = 10 行特征数据,训练集总计 4×10 = 40 行。
故高阶累积量训练集建模:
等价于:
3.2.4、待测数据集建模
对于待测试数据,可以分为P=1000组,每组N=500个符号,处理待测数据集的特征向量为:
3.2.5、待测向量集KNN流程建模
设定算法参数,可以通过多次测试确定,选择性能最好的参数,本案例选择n=10,计算距离变量,将每个待测数据特征向量与训练样本集特征向量空间中的每一个样本计算欧氏距离:
然后统计距离最小的k个样本,记录这k个样本的调制方式,统计各种调制方式的频次,将出现频次最高的调制方式作为最终的识别结果。将测试识别正确的次数与测试数据特征向量综述P的比值作为统计测试准确率。
3.2.6、项目整体仿真系统建模
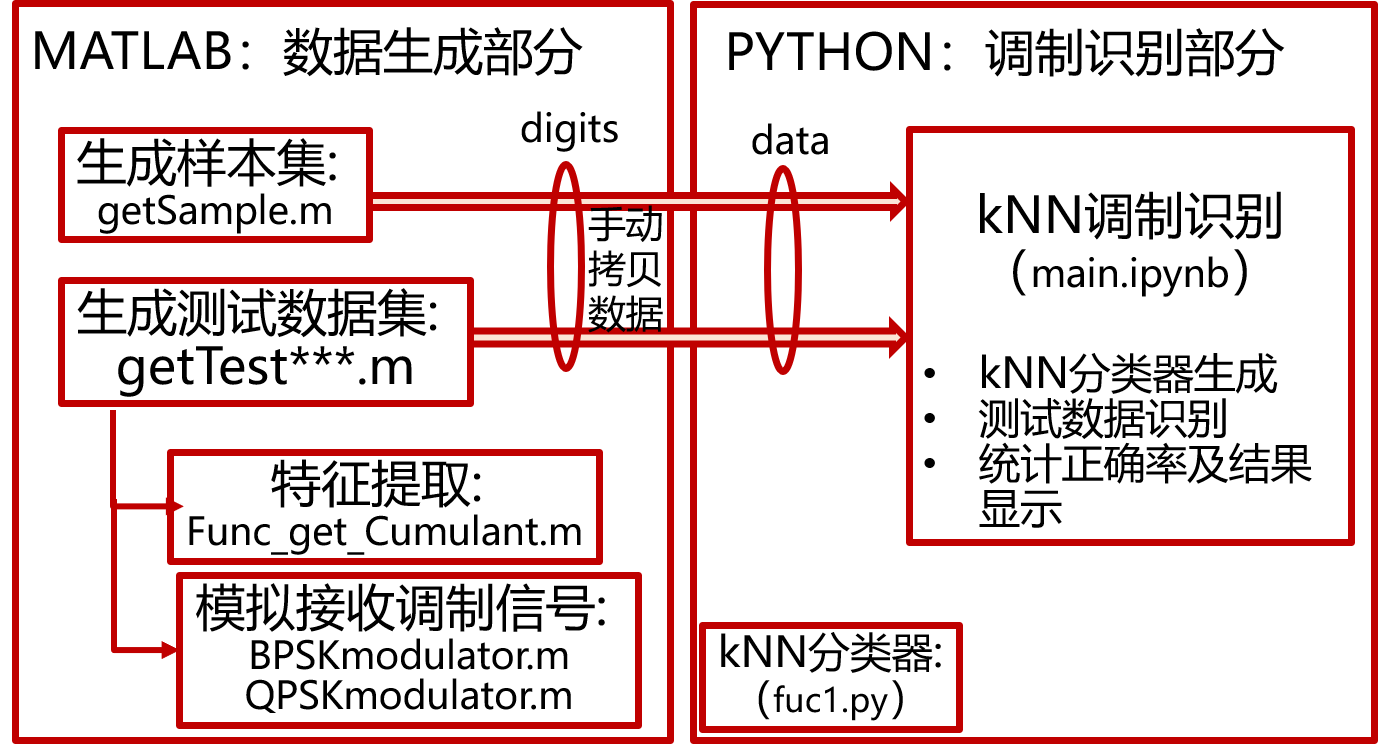
四、数据生成部分仿真设计
本模块采用MATLAB实现,数据生成部分包括BPSK、QPSK、16QAM信号的生成及提取他们的高阶累积量特征值。
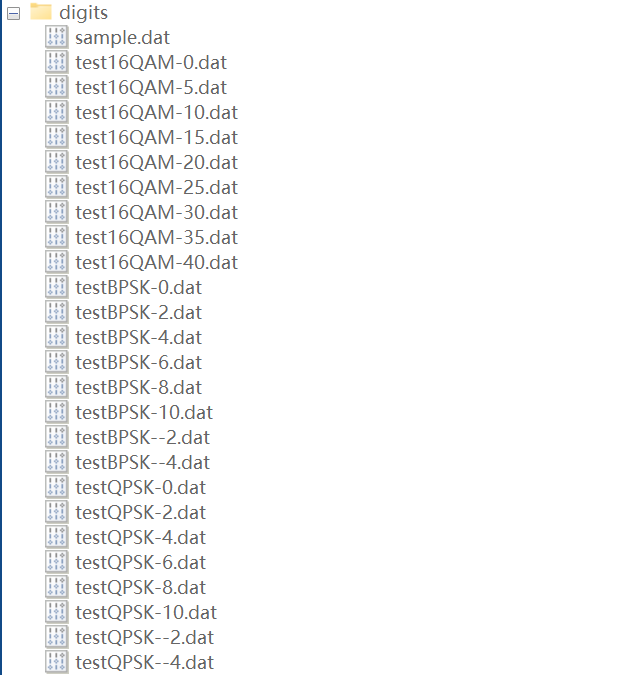
4.0、数据生成模块项目文件结构
bash
data_generation/
│
├── 📄 BPSKModulator.m # BPSK 调制器封装
├── 📄 QPSKModulator.m # QPSK 调制器封装
├── 📄 func_get_cumulants.m # 高阶累积量特征提取(核心)
├── 📄 getSample.m # 生成训练样本集
├── 📄 getTestBPSK.m # 生成 BPSK 测试样本
├── 📄 getTestQPSK.m # 生成 QPSK 测试样本
├── 📄 getTest16QAM.m # 生成 16QAM 测试样本
│
└── 📁 digits/ # 生成的数据文件(27个)
├── sample.dat # 训练集:4类 × 10条 = 40行
│
├── testBPSK--4.dat # BPSK 测试,SNR=-4dB
├── testBPSK--2.dat # BPSK 测试,SNR=-2dB
├── testBPSK-0.dat # BPSK 测试,SNR=0dB
├── testBPSK-2.dat # BPSK 测试,SNR=2dB
├── testBPSK-4.dat # BPSK 测试,SNR=4dB
├── testBPSK-6.dat # BPSK 测试,SNR=6dB
├── testBPSK-8.dat # BPSK 测试,SNR=8dB
├── testBPSK-10.dat # BPSK 测试,SNR=10dB
│
├── testQPSK--4.dat # QPSK 测试,SNR=-4dB
├── testQPSK--2.dat # QPSK 测试,SNR=-2dB
├── testQPSK-0.dat # QPSK 测试,SNR=0dB
├── testQPSK-2.dat # QPSK 测试,SNR=2dB
├── testQPSK-4.dat # QPSK 测试,SNR=4dB
├── testQPSK-6.dat # QPSK 测试,SNR=6dB
├── testQPSK-8.dat # QPSK 测试,SNR=8dB
├── testQPSK-10.dat # QPSK 测试,SNR=10dB
│
├── test16QAM-0.dat # 16QAM 测试,SNR=0dB
├── test16QAM-5.dat # 16QAM 测试,SNR=5dB
├── test16QAM-10.dat # 16QAM 测试,SNR=10dB
├── test16QAM-15.dat # 16QAM 测试,SNR=15dB
├── test16QAM-20.dat # 16QAM 测试,SNR=20dB
├── test16QAM-25.dat # 16QAM 测试,SNR=25dB
├── test16QAM-30.dat # 16QAM 测试,SNR=30dB
├── test16QAM-35.dat # 16QAM 测试,SNR=35dB
└── test16QAM-40.dat # 16QAM 测试,SNR=40dB4.1、各调制信号的调制器
4.1.1、BPSK调制器
file name : BPSKModulator.m
Matlab
function [out] = BPSKModulator(in)
persistent Modulator
if isempty(Modulator)
Modulator=comm.BPSKModulator;
%Modulator=comm.PSKModulator(2,'BitInput',true);
end
out = Modulator(in);
end4.1.2、QPSK调制器
file name : QPSKModulator.m
Matlab
function [out] = QPSKModulator(in)
persistent Modulator
if isempty(Modulator)
Modulator=comm.QPSKModulator('BitInput',true);
%demodLLR=comm.QPSKDemodulator('BitOutput',true,'DecisionMethod','Log-likelihood ratio','VarianceSource','Input port');
end
out = Modulator(in);
end4.1.3、MQAM调制器
16QAM 和 64QAM 没有单独的调制器.m文件,而是直接调用了 MATLAB 内置的 qammod 函数:
Matlab
qammod(x, 16, 'InputType', 'bit', 'UnitAveragePower', true) % 16QAM4.2、生成训练样本集
file name : getSample.m
具体流程如下:
①对每种调制方式(BPSK、QPSK、16QAM、64QAM),各生成 rows=10 组随机比特,每组 length=500 个符号;
②通过各自的调制器(BPSKModulator / QPSKModulator / qammod)将比特映射为复基带调制符号;
③调用 func_get_cumulants.m 对每组 500 个符号计算 5 维四阶累积量特征向量;
④最后一列附加调制类型标签(BPSK=2, QPSK=4, 16QAM=16, 64QAM=64,写入 digits\sample.dat,供后续 Python 端 KNN 的 fit() 训练使用。
最终生成的 sample.dat 是一个 40行 × 6列 的矩阵(4类 × 10组/类 = 40行),每行格式为:
|C20| |C21| |C40| |C41| |C42| 标签代码如下:
Matlab
%% Clean up
clear all;
clc;
rows = 10;
length = 500;
NFeatures = 5;
sample_data = zeros(rows, NFeatures + 1);
%% Simulation parameters
%% Simulate
%BPSK
% Generate random data
data = randi([0 1], rows, length);
% QAM mapping
[data1] = data';
data_cell = mat2cell(data1,length,ones(1,rows));
signalData = cellfun(@(x) BPSKModulator(x), data_cell, 'UniformOutput',false);
%signalData = cellfun(@(x) qammod(x, 2, 'InputType', 'bit', 'UnitAveragePower', true), data_cell, 'UniformOutput',false);
signalData1 = cell2mat(signalData);
signalData2 = mat2cell(signalData1',ones(1,rows),length);
% get cumulants
cumulants = cellfun(@(x) func_get_cumulants(x), signalData2, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
for row = 1: rows
for i = 1:NFeatures
sample_data(row, i) = cumulantsMat(row, i);
end
sample_data(row, NFeatures + 1) = 2;
end
%QPSK
% Generate random data
data = randi([0 1], rows, 2*length);
% QAM mapping
[data1] = data';
data_cell = mat2cell(data1,2*length,ones(1,rows));
signalData = cellfun(@(x) QPSKModulator(x), data_cell, 'UniformOutput',false);
%signalData = cellfun(@(x) qammod(x, 4, 'InputType', 'bit', 'UnitAveragePower', true), data_cell, 'UniformOutput',false);
signalData1 = cell2mat(signalData);
signalData2 = mat2cell(signalData1',ones(1,rows),length);
% get cumulants
cumulants = cellfun(@(x) func_get_cumulants(x), signalData2, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
for row = 1: rows
row_r = rows + row;
for i = 1:NFeatures
sample_data(row_r, i) = cumulantsMat(row, i);
end
sample_data(row_r, NFeatures + 1) = 4;
end
%16QAM
% Generate random data
data = randi([0 1], rows, 4*length);
% QAM mapping
[data1] = data';
data_cell = mat2cell(data1,4*length,ones(1,rows));
signalData = cellfun(@(x) qammod(x, 16, 'InputType', 'bit', 'UnitAveragePower', true), data_cell, 'UniformOutput',false);
signalData1 = cell2mat(signalData);
signalData2 = mat2cell(signalData1',ones(1,rows),length);
% get cumulants
cumulants = cellfun(@(x) func_get_cumulants(x), signalData2, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
for row = 1: rows
row_r = 2*rows + row;
for i = 1:NFeatures
sample_data(row_r, i) = cumulantsMat(row, i);
end
sample_data(row_r, NFeatures + 1) = 16;
end
%64QAM
% Generate random data
data = randi([0 1], rows, 6*length);
% QAM mapping
[data1] = data';
data_cell = mat2cell(data1,6*length,ones(1,rows));
signalData = cellfun(@(x) qammod(x, 64, 'InputType', 'bit', 'UnitAveragePower', true), data_cell, 'UniformOutput',false);
signalData1 = cell2mat(signalData);
signalData2 = mat2cell(signalData1',ones(1,rows),length);
% get cumulants
cumulants = cellfun(@(x) func_get_cumulants(x), signalData2, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
for row = 1: rows
row_r = 3*rows + row;
for i = 1:NFeatures
sample_data(row_r, i) = cumulantsMat(row, i);
end
sample_data(row_r, NFeatures + 1) = 64;
end
filename=['digits\sample.dat'];
dlmwrite(filename,sample_data,'delimiter','\t','newline','pc');
%csvwrite('sample.txt', sample_data);4.2、高阶累积量特征提取
file_name : func_get_cumulants.m
作用:生成了5个四阶及以下的累积量。
Matlab
function [cumulants] = func_get_cumulants(signalData)
shape = size(signalData);
H = shape(1);
L = shape(2);
cumulants = zeros(H, L);
for row = 1:H
M20 = sum(signalData(row,:).^2)/L;
M21 = sum(abs(signalData(row,:)).^2)/L;
M40 = sum(signalData(row,:).^4)/L;
M41 = sum(abs(signalData(row,:)).^2.*signalData(row,:).^2)/L;
M42 = sum(abs(signalData(row,:)).^4)/L;
C20 = M20;
C21 = M21;
C40 = M40 - 3*M20^2;
C41 = M41 - 3*M20*M21;
C42 = M42 - abs(M20)^2 - 2*M21^2;
C21_modify = C21;
C20_norm = C20/(C21_modify^2);
C21_norm = C21/(C21_modify^2);
C40_norm = C40/(C21_modify^2);
C41_norm = C41/(C21_modify^2);
C42_norm = C42/(C21_modify^2);
cumulants(row, 1) = abs(C20_norm);
cumulants(row, 2) = abs(C21_norm);
cumulants(row, 3) = abs(C40_norm);
cumulants(row, 4) = abs(C41_norm);
cumulants(row, 5) = abs(C42_norm);
end4.3、生成各调制方式的测试样本
4.3.1、生成 BPSK 测试样本
①生成1000路信号流,每一路500个符号,提取四阶累积量的5个特征,仿真噪声
Matlab
%% Clean up
clear all;
clc;
rows = 1000;
cols = 500;
NFeatures = 5;
test_data = zeros(rows, NFeatures);
SNR = [-4:2:10];②映射、加噪、获取高阶累积量
Matlab
for i = 1:length(SNR)
%% Simulation parameters
M = 2;
snr = SNR(i);
%% Simulate
%BPSK
% Generate random data
data = randi([0 1], rows, cols);
% PSK 映射
[data1] = data';
data_cell = mat2cell(data1,cols,ones(1,rows));
signalData = cellfun(@(x) BPSKModulator(x), data_cell, 'UniformOutput',false);
signalDataMat = cell2mat(signalData);
dataMod = mat2cell(signalDataMat',ones(1,rows),cols);
% AWGN 加噪
dataRx = cellfun(@(x) awgn(x, snr), dataMod, 'UniformOutput',false);
% 获取高阶累积量
cumulants = cellfun(@(x) func_get_cumulants(x), dataRx, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
test_data = cumulantsMat;③保存在digits文件夹里
Matlab
%% save
filename=['digits\testBPSK-',num2str(snr),'.dat'];
dlmwrite(filename,test_data,'delimiter','\t','newline','pc');
end④完整代码
Matlab
%% Clean up
clear all;
clc;
rows = 1000;
cols = 500;
NFeatures = 5;
test_data = zeros(rows, NFeatures);
SNR = [-4:2:10];
for i = 1:length(SNR)
%% Simulation parameters
M = 2;
snr = SNR(i);
%% Simulate
%BPSK
% Generate random data
data = randi([0 1], rows, cols);
% PSK 映射
[data1] = data';
data_cell = mat2cell(data1,cols,ones(1,rows));
signalData = cellfun(@(x) BPSKModulator(x), data_cell, 'UniformOutput',false);
signalDataMat = cell2mat(signalData);
dataMod = mat2cell(signalDataMat',ones(1,rows),cols);
% AWGN 加噪
dataRx = cellfun(@(x) awgn(x, snr), dataMod, 'UniformOutput',false);
% 获取高阶累积量
cumulants = cellfun(@(x) func_get_cumulants(x), dataRx, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
test_data = cumulantsMat;
%% save
filename=['digits\testBPSK-',num2str(snr),'.dat'];
dlmwrite(filename,test_data,'delimiter','\t','newline','pc');
end4.3.2、QPSK生成+提取高阶累积量
Matlab
%% Clean up
clear all;
clc;
rows = 1000;
cols = 500*2;
NFeatures = 5;
test_data = zeros(rows, NFeatures);
SNR = [-4:2:10];
for i = 1:length(SNR)
%% Simulation parameters
M = 4;
snr = SNR(i);
%% Simulate
%QPSK
% Generate random data
data = randi([0 1], rows, cols);
% PSK 映射
[data1] = data';
data_cell = mat2cell(data1,cols,ones(1,rows));
signalData = cellfun(@(x) QPSKModulator(x), data_cell, 'UniformOutput',false);
%signalData = cellfun(@(x) qammod(x, M, 'InputType', 'bit', 'UnitAveragePower', true), data_cell, 'UniformOutput',false);
signalDataMat = cell2mat(signalData);
dataMod = mat2cell(signalDataMat',ones(1,rows),cols/2);
% AWGN 加噪
dataRx = cellfun(@(x) awgn(x, snr), dataMod, 'UniformOutput',false);
% 获取高阶累积量
cumulants = cellfun(@(x) func_get_cumulants(x), dataRx, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
test_data = cumulantsMat;
%% save
filename=['digits\testQPSK-',num2str(snr),'.dat'];
dlmwrite(filename,test_data,'delimiter','\t','newline','pc');
end4.3.3、16QAM生成+提取高阶累积量
Matlab
%% Clean up
clear all;
clc;
rows = 1000;
cols = 500*4;
NFeatures = 5;
test_data = zeros(rows, NFeatures);
SNR = [0:5:40];
for i = 1:length(SNR)
%% Simulation parameters
M = 16;
snr = SNR(i);
%% Simulate
%16QAM
% Generate random data
data = randi([0 1], rows, cols);
% QAM 映射
[data1] = data';
data_cell = mat2cell(data1,cols,ones(1,rows));
signalData = cellfun(@(x) qammod(x, M, 'InputType', 'bit', 'UnitAveragePower', true), data_cell, 'UniformOutput',false);
signalDataMat = cell2mat(signalData);
dataMod = mat2cell(signalDataMat',ones(1,rows),cols/4);
% AWGN 加噪
dataRx = cellfun(@(x) awgn(x, snr), dataMod, 'UniformOutput',false);
% 获取高阶累积量
cumulants = cellfun(@(x) func_get_cumulants(x), dataRx, 'UniformOutput',false);
cumulantsMat = cell2mat(cumulants);
test_data = cumulantsMat;
%% save
filename=['digits\test16QAM-',num2str(snr),'.dat'];
dlmwrite(filename,test_data,'delimiter','\t','newline','pc');
end4.4、生成数据
运行getSample.m文件,生成原始训练数据,保存在digits文件夹中。运行getTestBPSK.m、getTestQPSK.m、getTest16QAM.m三个文件,其自动生成的高阶累积量会保存在digits文件夹中。
五、调制识别部分仿真设计
本模块采用Pycharm实现,对拿到的数据进行识别,分辨其调制类型,并绘制一个信噪比SINR与识别成功率的对应关系图。
5.0、调制识别模块项目文件结构
首先应将上述digits文件夹下新生成的所有数据文件拷贝到本模块的data文件夹中,故拷贝后本模块的文件结构如下:
bash
modulation_recognition/
│
├── 📄 fuc1.py # 核心:KNN 分类器实现 + 可视化
│
├── 📓 main.ipynb # Jupyter Notebook 主程序
│
│
├── 📁 data/ # 数据文件(与 data_generation/digits/ 内容相同)
│ ├── sample.dat # 训练集:4类 × 10条 = 40行
│ │
│ ├── testBPSK--4.dat ~ testBPSK-10.dat # BPSK 测试(8个SNR,-4~10dB)
│ ├── testQPSK--4.dat ~ testQPSK-10.dat # QPSK 测试(8个SNR,-4~10dB)
│ └── test16QAM-0.dat ~ test16QAM-40.dat # 16QAM 测试(9个SNR,0~40dB)
│
└── 📁 .ipynb_checkpoints/
└── main-checkpoint.ipynb # Notebook 自动检查点5.1、anaconda与jupyter-notebook
5.1.1、conda生态的发展史
15分钟彻底搞懂!Anaconda Miniconda conda-forge miniforge Mamba
历史上官方python包管理器pip曾对于跨语言依赖支持很不友好,很多常用的哭根本没法用一句简单的pip install 安装好。为了解决这个问题,Continuum Analytics公司将python和各种常见的数学库打包成了一个超大的安装包,这就是anaconda distribution的原型。
anaconda distribution的第一版只是一个把所有依赖打包在一起的大杂烩而已,而我们今天熟悉的conda命令在当时甚至还没有出现;随着第一版的使用,有关库更新、稀缺库安装、多余库删除的问题逐渐成为主要矛盾,故而anaconda公司不久后就新增了一个命令行工具用来专门解决这些问题,可以通过conda install/uninstall pkg_name来添加/删除包,这就是conda指令原型。为此,anaconda公司专门维护了一个自己的软件包仓库,收录了几千个软件包。
anaconda公司为每个支持的系统都提前编译好了对应的二进制版本,并且精心处理好了各种复杂的依赖,所以虽然conda和pip的功能类似,但通过conda下载下来的包往往是可以开箱即用的,少了很多对不同系统兼容的折腾。
当然了,无论怎么维护,能够做到包和包之间100%兼容还是很困难的,比如一个项目需要numpy2.3,另外一个项目需要numpy1.26,无论安装哪个版本都会影响另一个项目,python官方的解决方法是使用venv创建虚拟环境,每个项目都拥有自己一套独立的依赖,互不影响,conda也采用了类似的机制,可以用conda create -n venv_name来创建不同的conda环境,用conda activate/deactivate来激活/去激活,在虚拟环境激活状态下采用conda install 来安装包,就会安装在本虚拟环境中。如果在conda install之前没有执行conda activate的话,安装的包将会被安装在base环境(即conda自身运行环境)中,这是不推荐的。
anaconda随后贡献了他们的软件托管平台,但是为了保证其他用户不影响到他们原本已经维护好的仓库,故而推出了一个名为binstar的平台,后来改名为ANACONDA.ORG,用户可以在这个平台上创建自己的软件仓库,自己上传包、自己维护、自己负责兼容性的问题,在anaconda.org上这样的仓库被称为channels;而anaconda官方维护的仓库被命名为defaults(main+R+msys2三个channels),当我们执行conda install 时,默认下载源就是defaults。
由于anaconda.org的出现,人们更倾向于最小化自己的conda仓库,故而anaconda公司推出了miniconda,只包含conda命令和运行conda所需要的最基本的环境依赖,所以体积比anaconda distribution小得多。
当然现在的anaconda distribution也不仅仅是conda命令和各种包的集合了,它还内置了很多其他的工具,比如图形化的包管理界面anaconda navigator等,这些在miniconda中是完全没有的。
至此是conda的全部官方生态发展史,下面我们来介绍conda的开源社区。
【conda-forge】虽然conda的defaults已经收录了几千个常见的软件包,但归根结底是由一家公司进行维护的,精力有限。为了发展包罗万象的软件仓库,由于有了anaconda.org这个非常成熟的托管平台,开源社区在上面创造了一个叫做conda-forge的channel,conda-forge是完全由开源社区共同维护的,任何人都可以申请上传自己搭好的软件包,审核通过之后就可以共享给所有人了。发展到现在,conda-forge已经是anaconda.org上最大的channel了,它包含了3w多个软件包,如果算上不同操作系统的版本,总量或超10w。
conda-forge的内容完全由社区维护,anaconda公司只负责提供anaconda.org平台进行托管。conda-forge在兼容性上可能比anaconda官方的defaults略逊一筹,但是在大部分场景下是完全够用的,而且conda-forge最大的优点是软件包数量极多,更新非常快,最重要的一点anaconda提供的defaults渠道从2020年之后对商业用途就开始收费了,因此目前绝大多数开发者用的都是conda-forge,在conda中使用conda-forge的方法是:conda create -n nev_name -c conda-forge,其中-c是-channel的缩写。无论是创建环境还是后续安装包,-c conda-forge参数都要带上,否则conda会默认从defaults进行下载,可能引发一系列问题。
由于每次使用conda-forge下载依赖都必须加-c conda-forge,这一操作过于繁琐,所以conda-forge开源社区的开发者参考miniconda,自己打包了一个conda安装包,修改了配置文件把默认的channel改成了conda-forge,命名为miniforge。miniforge的安装效果和miniconda基本一样,但miniforge的默认配置指向免费的conda-forge channel,而miniconda则指向收费的defaults channel。
5.1.2、anaconda的安装
注意,如果要用pycharm运行,可选2024版本的anaconda,不然新版的anaconda可能会与pycharm不兼容;注意conda要配置系统环境变量的path,配置详见:
【保姆级】手把手教你下载专业版JetBrains Pycharm(基于Anaconda环境)
5.1.3、jupyter-notebook
python数据分析神器Jupyter notebook快速入门
如果你写过 Python 脚本,你一定熟悉这样的流程:写好一整段代码,点击运行,然后看着终端里打印出结果。如果中间某一步出了错,你得从头再来一遍。这种"写完全部再运行"的方式在面对数据分析、机器学习这类需要反复试探、不断调整的任务时,效率其实很低。而 Jupyter Notebook 要解决的,恰恰就是这个问题。
Jupyter Notebook 是一个基于浏览器的交互式编程工具,它的名字来源于 Julia、Python 和 R 三种编程语言的首字母组合。虽然现在它已经支持超过四十种语言,但 Python 仍然是它最常见的搭档。打开 Jupyter Notebook,你会看到一个网页界面,里面不是一整个代码文件,而是一个个"单元格"。每个单元格可以独立运行,你可以写完一行代码就立刻看到输出,确认没问题了再写下一行。
但 Jupyter Notebook 的功能远不止"能分段运行代码"这么简单。它真正强大的地方在于,你可以在代码中间穿插 Markdown 格式的说明文字、LaTeX 数学公式、图片甚至视频,最终生成一份集代码、注释、可视化图表和文字讲解于一体的完整文档。换句话说,你写的不是"代码文件",而是一本可以执行的计算笔记。你的思路、推导过程和最终结论全都在一个文件里,任何一个拿到这份笔记的人都可以从头到尾复现你的全部工作。
正因如此,Jupyter Notebook 在数据科学和机器学习领域几乎成了标配工具。数据科学家用它来读取数据、清洗异常值、绘制分布图、训练模型、评估效果,每一步的中间结果都直观地摆在眼前。如果发现某一步有问题,只需要修改那个单元格重新运行即可,不用把整个流程从头跑一遍。在教育教学领域,老师可以把理论讲解、公式推导和可运行的代码示例放在同一页面上,学生可以边学边动手修改参数观察结果变化,学习的沉浸感和反馈速度远超传统的"看书 + 单独开 IDE 写代码"的模式。科研人员也喜欢用 Jupyter Notebook 记录实验过程,因为它天然保证了研究的可复现性:论文里的每一个图表背后都有一段可以直接运行的代码,审稿人或同行可以直接验证,而不是对着模糊的文字描述猜测实验是怎么做的。
5.2、pycharm jetbrains 与jupyter-notebook
pycharm community是没法运行.ipynb文件的,只有pycharm jetbrains专业版才可以,而专业版软件要交钱,所以可以选用jupyter-notebook来免费操作。
想使用破解的pycharm jetbrains 2019 的朋友,可以参考我的文章:
【保姆级】手把手教你下载专业版JetBrains Pycharm(基于Anaconda环境)
其中需要的各种软件包可以私信和我要,配置过程比较繁琐,需要有一定基础的朋友耐心操作。
下面介绍jupyter-notebook的使用方法。
首先从电脑的搜索栏中搜索anaconda prompt,双击打开,先测试Jupyter notebook --version,如果显示出来了版本号则不用额外安装,如果没显示出来,则conda install jupyter。
启动jupyter-notebook的方式:首先在anaconda prompt这个终端cd到你要打开的项目文件夹路径上,然后在终端输入jupyter notebook回车就可以了,它会在浏览器打开一个localhost用来展示你的项目目录,这里你可以借助jupyter notebook运行。ipynb文件。
5.3、仿真设计
如果用jupyter-notebook,则本脚本文件可以直接使用anaconda的base环境;我用的是pycharm jetbrains,除了可以用base环境(不推荐)之外,还可以配置自己的虚拟环境,操作方式如下:
①打开powershell,输入conda env list,检查所有虚拟环境及路径;
②在powershell中输入conda create -n mdltion_rcgntion_env python=3.9;
③ 在powershell中输入conda activate mdltion_rcgntion_env,进入了该虚拟环境;
④ conda install需要的包,比如numpy、matplotlib、scikit-learn等。
⑤给pycharm配置这个已有的虚拟环境解释器,等待pycharm将环境更新完毕,即可使用。
仿真代码和讲解都在main.ipynb中,代码流程如下:
bash
┌─────────────────────────────────────────────────────┐
│ Cell 1: 导入包 + 定义 file2matrix()
│ 读取 .dat 文件 → 取前5列作特征, 最后一列作标签
└────────────────────┬────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Cell 3: 训练 KNN 分类器
│ sample.dat → KNeighborsClassifier(k=10) → fit()
│
│ 标签: 2=BPSK 4=QPSK 16=16QAM 64=64QAM
└────────────────────┬────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ Cell 5 / 7 / 9: 三类测试(BPSK / QPSK / 16QAM)
│
│ for each SNR:
│ 加载 test{调制}-{SNR}.dat
│ for each 样本 → kNN_classifier.predict()
│ 统计: 判对了几次?误判成什么?
│ accuracy = 判对数 / 总样本数
│
│ 画图: SNR(x) vs Accuracy(y) 折线图
│
│ BPSK/QPSK: SNR = -4 ~ 10 dB (步长2)
│ 16QAM: SNR = 0 ~ 40 dB (步长5)
└─────────────────────────────────────────────────────┘5.4、基于四阶累积量五个特征的仿真
5.4.1、cell1:导入包及数据部分
python
import numpy as np #导入numpy,用于科学计算,如,矩阵运算
from sklearn.neighbors import KNeighborsClassifier # 包装好的knn算法
from collections import defaultdict
import collections
import matplotlib.pyplot as plt
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = np.zeros((numberOfLines,5)) #prepare matrix to return the number of features
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:5] #chose features
classLabelVector.append(float(listFromLine[-1]))
#classLabelVector.append(float(0))
index += 1
return returnMat,classLabelVector5.4.2、cell2:生成KNN分类器
python
data_X,data_y = file2matrix('data/sample.dat')
data_y_name = ['BPSK','QPSK','16QAM','64QAM']#分类名称
X_train = data_X #numpy ndarray格式
y_train = data_y #numpy ndarray格式
kNN_classifier = KNeighborsClassifier(n_neighbors=10) # knn中k值
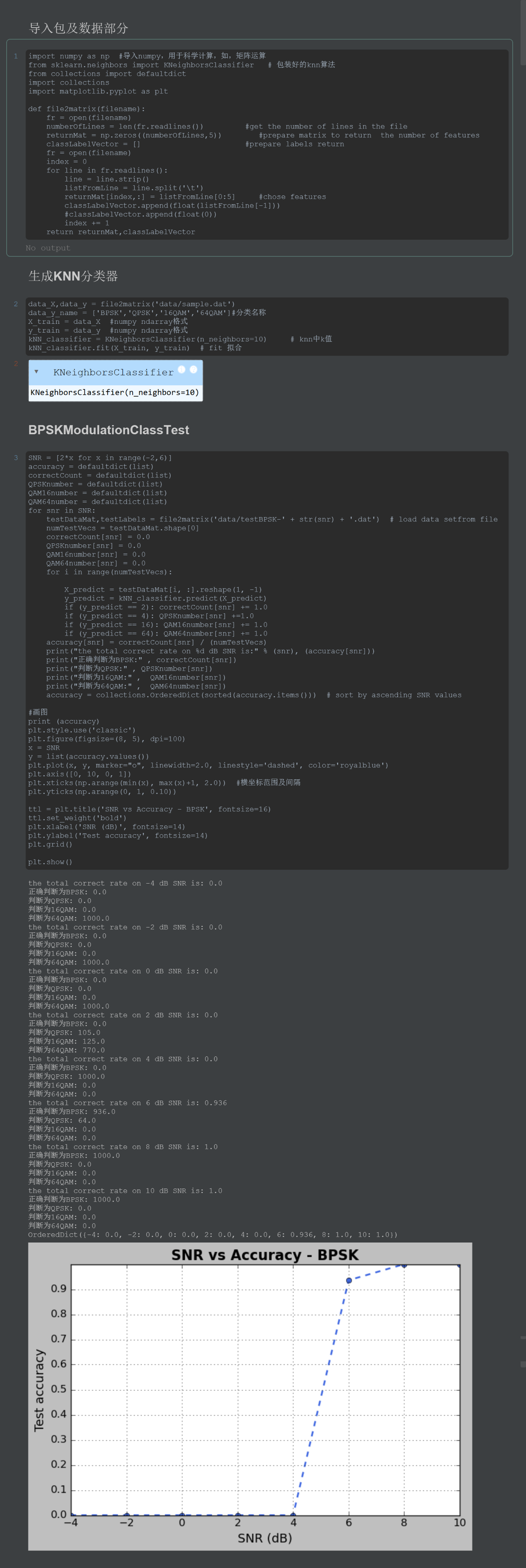
kNN_classifier.fit(X_train, y_train) # fit 拟合5.4.3、cell3:BPSKModulationClassTest
代码流程:
①将上一步生成好的待测试的BPSK信号导入;
②将生成的P=1000路BPSK信号每一路都调用KNN算法识别并贴上标签;
③统计这P=1000路BPSK的识别情况;
④正确率等于成功识别的数量/P。
python
SNR = [2*x for x in range(-2,6)]
accuracy = defaultdict(list)
correctCount = defaultdict(list)
QPSKnumber = defaultdict(list)
QAM16number = defaultdict(list)
QAM64number = defaultdict(list)
for snr in SNR:
testDataMat,testLabels = file2matrix('data/testBPSK-' + str(snr) + '.dat') # load data setfrom file
numTestVecs = testDataMat.shape[0]
correctCount[snr] = 0.0
QPSKnumber[snr] = 0.0
QAM16number[snr] = 0.0
QAM64number[snr] = 0.0
for i in range(numTestVecs):
X_predict = testDataMat[i, :].reshape(1, -1)
y_predict = kNN_classifier.predict(X_predict)
if (y_predict == 2): correctCount[snr] += 1.0
if (y_predict == 4): QPSKnumber[snr] +=1.0
if (y_predict == 16): QAM16number[snr] += 1.0
if (y_predict == 64): QAM64number[snr] += 1.0
accuracy[snr] = correctCount[snr] / (numTestVecs)
print("the total correct rate on %d dB SNR is:" % (snr), (accuracy[snr]))
print("正确判断为BPSK:" , correctCount[snr])
print("判断为QPSK:" , QPSKnumber[snr])
print("判断为16QAM:" , QAM16number[snr])
print("判断为64QAM:" , QAM64number[snr])
accuracy = collections.OrderedDict(sorted(accuracy.items())) # sort by ascending SNR values
#画图
print (accuracy)
plt.style.use('classic')
plt.figure(figsize=(8, 5), dpi=100)
x = SNR
y = list(accuracy.values())
plt.plot(x, y, marker="o", linewidth=2.0, linestyle='dashed', color='royalblue')
plt.axis([0, 10, 0, 1])
plt.xticks(np.arange(min(x), max(x)+1, 2.0)) #横坐标范围及间隔
plt.yticks(np.arange(0, 1, 0.10))
ttl = plt.title('SNR vs Accuracy - BPSK', fontsize=16)
ttl.set_weight('bold')
plt.xlabel('SNR (dB)', fontsize=14)
plt.ylabel('Test accuracy', fontsize=14)
plt.grid()
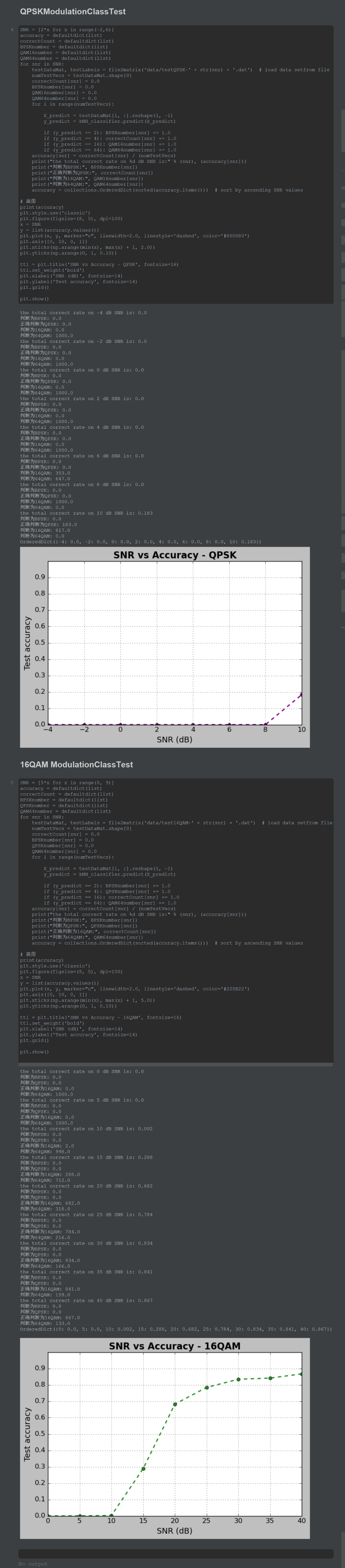
plt.show()5.4.4、cell4:QPSKModulationClassTest
python
SNR = [2*x for x in range(-2,6)]
accuracy = defaultdict(list)
correctCount = defaultdict(list)
BPSKnumber = defaultdict(list)
QAM16number = defaultdict(list)
QAM64number = defaultdict(list)
for snr in SNR:
testDataMat, testLabels = file2matrix('data/testQPSK-' + str(snr) + '.dat') # load data setfrom file
numTestVecs = testDataMat.shape[0]
correctCount[snr] = 0.0
BPSKnumber[snr] = 0.0
QAM16number[snr] = 0.0
QAM64number[snr] = 0.0
for i in range(numTestVecs):
X_predict = testDataMat[i, :].reshape(1, -1)
y_predict = kNN_classifier.predict(X_predict)
if (y_predict == 2): BPSKnumber[snr] += 1.0
if (y_predict == 4): correctCount[snr] += 1.0
if (y_predict == 16): QAM16number[snr] += 1.0
if (y_predict == 64): QAM64number[snr] += 1.0
accuracy[snr] = correctCount[snr] / (numTestVecs)
print("the total correct rate on %d dB SNR is:" % (snr), (accuracy[snr]))
print("判断为BPSK:", BPSKnumber[snr])
print("正确判断为QPSK:", correctCount[snr])
print("判断为16QAM:", QAM16number[snr])
print("判断为64QAM:", QAM64number[snr])
accuracy = collections.OrderedDict(sorted(accuracy.items())) # sort by ascending SNR values
# 画图
print(accuracy)
plt.style.use('classic')
plt.figure(figsize=(8, 5), dpi=100)
x = SNR
y = list(accuracy.values())
plt.plot(x, y, marker="o", linewidth=2.0, linestyle='dashed', color='#800080')
plt.axis([0, 10, 0, 1])
plt.xticks(np.arange(min(x), max(x) + 1, 2.0))
plt.yticks(np.arange(0, 1, 0.10))
ttl = plt.title('SNR vs Accuracy - QPSK', fontsize=16)
ttl.set_weight('bold')
plt.xlabel('SNR (dB)', fontsize=14)
plt.ylabel('Test accuracy', fontsize=14)
plt.grid()
plt.show()5.4.5、cell5:16QAM ModulationClassTest
python
SNR = [5*x for x in range(0, 9)]
accuracy = defaultdict(list)
correctCount = defaultdict(list)
BPSKnumber = defaultdict(list)
QPSKnumber = defaultdict(list)
QAM64number = defaultdict(list)
for snr in SNR:
testDataMat, testLabels = file2matrix('data/test16QAM-' + str(snr) + '.dat') # load data setfrom file
numTestVecs = testDataMat.shape[0]
correctCount[snr] = 0.0
BPSKnumber[snr] = 0.0
QPSKnumber[snr] = 0.0
QAM64number[snr] = 0.0
for i in range(numTestVecs):
X_predict = testDataMat[i, :].reshape(1, -1)
y_predict = kNN_classifier.predict(X_predict)
if (y_predict == 2): BPSKnumber[snr] += 1.0
if (y_predict == 4): QPSKnumber[snr] += 1.0
if (y_predict == 16): correctCount[snr] += 1.0
if (y_predict == 64): QAM64number[snr] += 1.0
accuracy[snr] = correctCount[snr] / (numTestVecs)
print("the total correct rate on %d dB SNR is:" % (snr), (accuracy[snr]))
print("判断为BPSK:", BPSKnumber[snr])
print("判断为QPSK:", QPSKnumber[snr])
print("正确判断为16QAM:", correctCount[snr])
print("判断为64QAM:", QAM64number[snr])
accuracy = collections.OrderedDict(sorted(accuracy.items())) # sort by ascending SNR values
# 画图
print(accuracy)
plt.style.use('classic')
plt.figure(figsize=(8, 5), dpi=100)
x = SNR
y = list(accuracy.values())
plt.plot(x, y, marker="o", linewidth=2.0, linestyle='dashed', color='#228B22')
plt.axis([0, 10, 0, 1])
plt.xticks(np.arange(min(x), max(x) + 1, 5.0))
plt.yticks(np.arange(0, 1, 0.10))
ttl = plt.title('SNR vs Accuracy - 16QAM', fontsize=16)
ttl.set_weight('bold')
plt.xlabel('SNR (dB)', fontsize=14)
plt.ylabel('Test accuracy', fontsize=14)
plt.grid()
plt.show()5.4.6运行结果
依次运行各个cell: