PEFT,全称是 参数高效微调 (Parameter-Efficient Fine-Tuning),是一套用于调整大型预训练模型(如大语言模型LLM)以适应特定下游任务的方法论,其核心思想是在 极小化计算和存储资源 的前提下,实现与全量微调(Full Fine-tuning)相媲美的模型性能。
一、 重参数化方法(Reparameterization-based)
1. LoRA (Low-Rank Adaptation)
-
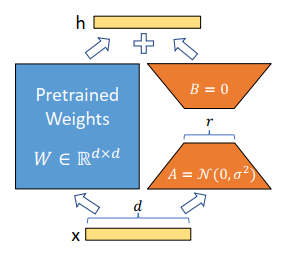
工作原理 :大模型虽然参数量巨大,但在学习特定的下游任务时,真正需要改变的参数空间其实非常小(即低秩的)。基于这个思想,LoRA 不去碰(冻结)原来那个庞大的权重矩阵 W0W_0W0,而是用两个很小的矩阵 AAA 和 BBB 相乘,来模拟原本需要更新的参数变化量 ΔW\Delta WΔW。
-
原来的前向传播: h=W0xh = W_0xh=W0x
-
全量微调: h=(W0+ΔW)xh = (W_0 + \Delta W)xh=(W0+ΔW)x (此时你要训练完整的庞大矩阵 ΔW\Delta WΔW)
-
LoRA 微调: h=W0x+BAxh = W_0x + BAxh=W0x+BAx
其中,xxx 的维度是 k×1k \times 1k×1,矩阵 AAA 的维度是 r×kr \times kr×k,矩阵 BBB 的维度是 d×rd \times rd×r。这里的 rrr 就是"秩"(Rank),它是一个远小于 ddd 和 kkk 的值(即 r≪min(d,k)r \ll \min(d,k)r≪min(d,k))。
通过这种"降维 (Ax=r×1Ax=r \times 1Ax=r×1) 再升维 (BAx=d×1BAx=d \times 1BAx=d×1) "的操作,需要训练的参数量直接呈指数级下降,极大地节省了显存和算力。
-
-
额外增加的网络结构 (BA) 加在哪里? 这个额外的网络结构(即矩阵 AAA 和 BBB 组成的旁路分支),是 并联(旁路添加) 在原模型的特定层上的。在实际操作中,大语言模型(如 LLaMA、ChatGLM 等)主要由 Transformer 结构组成。LoRA 的旁路通常会加在 Transformer 块中的 线性投影层(Wq,Wk,Wv,WoW_q, W_k, W_v, W_oWq,Wk,Wv,Wo 以及 前馈神经网络(MLP)层) 上。
-
LoRA 微调的重要参数及其设置建议:
| 参数名称 | 含义说明 | 设置建议 |
|---|---|---|
r (Rank) |
秩的大小。 决定了矩阵 AAA 和 BBB 的维度,直接影响训练参数量和模型的表达能力。 | 一般从 8 或 16 开始尝试。如果任务非常复杂(比如注入大量新知识),可以增大到 32 或 64;如果只是简单的格式对齐或风格微调,r=4 或 r=8 足矣。过大会增加过拟合风险。 |
lora_alpha |
缩放系数。 LoRA 实际作用于原输出时,会乘上一个缩放因子 αr\frac{\alpha}{r}rα。它决定了 LoRA 权重对最终结果的影响力度。 | 一个经典的经验法则是:lora_alpha 设置为 r 的 1 倍或 2 倍 (例如 r=8r=8r=8 时,α=16\alpha=16α=16)。这样可以在改变 rrr 时保持权重的尺度相对稳定。过大会导致BA影响过大,甚至导致训练时梯度爆炸。过小则会导致效果不明显,训练时loss无法下降。 |
target_modules |
目标模块。 指定将 LoRA 旁路添加到原模型的哪些网络层。 | 最基础的设置是 ["q_proj", "v_proj"]。但目前的最佳实践表明,应用到所有的线性层(Linear/Dense)(如 q, k, v, o, gate, up, down)通常能取得最好的微调效果。 |
lora_dropout |
丢弃率。 用于防止过拟合的正则化手段,在训练时随机使部分神经元失活。 | 通常设置为 0.05 到 0.1。如果是数据量极小且很容易过拟合的任务,可以稍微调高到 0.1。 |
- 局限性 :
- 超参敏感 :需要手动调节秩(Rank rrr)和缩放系数(Alpha α\alphaα),调参不当会导致不收敛或效果差。
- 复杂逻辑任务天花板:在极其复杂的推理任务或严重的领域偏移(Domain Shift)场景下,极低秩的 LoRA 效果有时仍略逊于全量微调(Full Tuning)。
2. QLoRA
- 工作原理:将预训练模型的高精度权重(如 FP16)量化为极低精度的 4-bit NormalFloat (NF4) 格式以大幅缩减显存占用。同时引入"双重量化"和"分页优化器"技术防止内存溢出。在这个 4-bit 的冻结底座上,依然使用 FP16/BF16 训练常规的 LoRA 矩阵。
- 局限性 :
- 训练速度慢:因为在前向和反向传播时,必须将 4-bit 权重反量化(Dequantize)回 16-bit 参与计算,这增加了大量的计算开销,导致训练时间通常比常规 LoRA 长。
- 精度损耗:由于极度压缩,对于某些对数值敏感的任务(如数学计算、代码生成),可能会出现极其轻微的性能下降。
3. AdaLoRA
-
工作原理 :不同网络层对任务的"重要性"是不同的。AdaLoRA 通过模拟奇异值分解(SVD),在训练过程中动态评估各层的权重矩阵重要性。重要的层分配更高的秩(分配更多参数),不重要的层分配极低的秩甚至裁剪掉。
传统的 LoRA 通过两个矩阵相乘来模拟权重变化:ΔW=BA\Delta W = B AΔW=BA。而 AdaLoRA 将这个增量矩阵参数化为奇异值分解(SVD)的形式:ΔW=PΛQ\Delta W = P \Lambda QΔW=PΛQPPP 和 QQQ:分别代表左奇异向量和右奇异向量,在训练中受到正交性约束。Λ\LambdaΛ:一个对角矩阵,对角线上的元素即为"奇异值"。在这个结构中,Λ\LambdaΛ 中的奇异值大小直接决定了对应秩(Rank)的重要性。
初始高秩 :训练初期,AdaLoRA 会给所有目标模块分配一个较高的初始秩(init_r)。
逐步剪枝 :随着训练的进行,模型会根据计算出的"重要性分数",逐步将 Λ\LambdaΛ 中得分最低的奇异值置为 0(即剪枝)。
达到目标:这个剪枝过程会在指定的训练步数内持续进行,直到整个模型中非零奇异值的总数(即平均秩)下降到我们预设的最终目标秩(target_r)。 -
AdaLoRA 的训练超参数:
| 参数名称 | 类别 | 含义与作用 | 典型值 / 补充说明 |
|---|---|---|---|
init_r |
核心预算 | 初始秩。训练初期分配给所有目标模块的较高 Rank 值,为模型提供足够的探索和剪枝空间。 | 通常设为 12, 16 或略高于你的目标秩 |
target_r |
核心预算 | 目标平均秩。训练结束时期望达到的模型整体平均 Rank 值。模型会自适应地将参数集中分配到重要模块。 | 比如 8(根据你的显存预算和模型规模决定) |
tinit |
剪枝调度 | 初始预热步数。训练开始后,前多少步只更新参数而不进行剪枝(Warmup 阶段)。 | 视总训练步数而定,如 200 步 |
tfinal |
剪枝调度 | 最终停止步数。训练进行到多少步时停止剪枝,固定当前的 Rank 结构继续微调。 | 通常设为总训练步数的 70%~80% |
deltaT |
剪枝调度 | 剪枝间隔步数。每隔多少个训练 Step 执行一次重要性打分和奇异值剪枝操作。 | 如 10 步,太小会增加计算开销,太大会影响剪枝平滑度 |
beta1 |
重要性评估 | 滑动平均系数 1。用于平滑处理当前步的权重和梯度,计算重要性分数的动量参数。 | 默认通常为 0.85 |
beta2 |
重要性评估 | 滑动平均系数 2 。同上,通常配合 beta1 使用,类似于 Adam 优化器中的机制。 |
默认通常为 0.85 |
ortha |
正则化 | 正交惩罚系数 。损失函数中正交性正则化项的权重,确保 PPP 和 QQQ 矩阵保持正交。 | 默认通常为 0.1 |
lora_alpha |
基础 LoRA | 缩放因子 。控制增量矩阵 ΔW\Delta WΔW 对原始模型权重的缩放比例。 | 通常设为 target_r 的 1 到 2 倍(如 16 或 32) |
lora_dropout |
基础 LoRA | Dropout 概率。在应用 LoRA 层之前对输入使用的 Dropout,用于防止过拟合。 | 一般为 0.05 到 0.1 |
target_modules |
基础 LoRA | 目标模块。指定要插入 AdaLoRA 结构的层名称。 | 如 ["q_proj", "v_proj"] 或 ["query", "value"] |
- 局限性 :
- 计算开销大:在训练过程中频繁计算重要性分数并动态调整参数预算,使得底层代码实现复杂,且略微拖慢训练速度。
4. DoRA (Weight-Decomposed LoRA)
-
工作原理:DoRA 的提出是为了解决标准 LoRA 的一个痛点:LoRA 在更新权重时,幅度和方向的更新是高度正相关的,而研究发现,全量微调(FT)中幅度和方向的更新呈现出一定程度的负相关(即幅度变小通常伴随方向的剧烈变化,反之亦然)。为了打破 LoRA 的这种限制,DoRA 引入了权重分解机制。将预训练权重矩阵分解为两部分:"幅度向量(Magnitude)"和"方向矩阵(Direction)"。微调时,幅度向量作为一个参数量极小的 1D 向量被全量微调,而方向矩阵则使用 LoRA 进行微调。
任何一个预训练权重矩阵 W∈Rd×kW \in \mathbb{R}^{d \times k}W∈Rd×k 都可以被分解为一个幅度向量 m∈R1×km \in \mathbb{R}^{1 \times k}m∈R1×k 和一个方向矩阵 V∈Rd×kV \in \mathbb{R}^{d \times k}V∈Rd×k:W=mV∣∣V∣∣cW = m \frac{V}{||V||_c}W=m∣∣V∣∣cV其中,∣∣V∣∣c||V||_c∣∣V∣∣c 是矩阵 VVV 每列的向量范数。通过这种分解,权重的大小(mmm)和权重的方向(V∣∣V∣∣c\frac{V}{||V||_c}∣∣V∣∣cV)被完全解耦。
-
DoRA的训练超参数:
| 参数名 | 含义说明 | 常用建议值 / 注意事项 |
|---|---|---|
use_dora |
DoRA 核心开关:是否启用权重分解。 | True (在 PEFT 库中只需这一行配置即可从 LoRA 切换到 DoRA)。 |
r (Rank) |
低秩矩阵的秩,决定了方向矩阵更新的参数规模和表达能力。 | 通常为 8, 16, 32, 64 。任务越复杂,r 值应适当增大,但显存占用也会随之增加。 |
lora_alpha |
缩放系数,决定方向更新矩阵对原始预训练权重的影响权重。 | 经验法则是设为 r 的 1倍或2倍(例如:r=16 时,alpha 设为 16 或 32)。 |
target_modules |
指定应用 DoRA 的模型组件(通常是各类线性层)。 | 建议覆盖所有线性层 (如 q_proj, v_proj, k_proj, o_proj, gate_proj, up_proj, down_proj)。DoRA 覆盖越全,性能越逼近全量微调。 |
lora_dropout |
为了防止低秩矩阵过拟合而设置的 Dropout 概率。 | 通常设置为 0.05 或 0.1。 |
- 局限性 :
- 虽然效果往往优于 LoRA,但由于需要进行权重分解的范数计算,它的训练时间、反向传播的内存占用均略高于原生 LoRA。
5. PiSSA (Principal Singular values and Singular vectors Adaptation)
- 工作原理 :普通 LoRA 的 AAA 和 BBB 矩阵是随机初始化的。PiSSA 则在微调前,对预训练权重进行一次真实的主成分奇异值分解(SVD),用最重要的主成分来初始化 AAA 和 BBB 矩阵,冻结剩下的残差部分。
- PiSSA训练超参数 : 与LoRA一致,但是一般会有一个
--init_weights=pissa(ms-swift框架)或--init_lora_weights=pissa(PEFT框架)参数可以指定初始化权重方式为PiSSA。 - 局限性 :
- 初始化成本高:对几百亿参数的大模型权重做 SVD 分解极其耗费显存和时间,初始化的预备阶段成本偏高。
6. 不同LoRA框架的对比
| 技术名称 | 核心亮点 | 适用场景与总结 | 推荐指数 |
|---|---|---|---|
| LoRA | 经典低秩微调,冻结原模型,只训练极少参数。 | 万金油。如果不受显存限制,且不想折腾超参数,直接用 LoRA 最稳妥。 | ⭐⭐⭐⭐⭐ (最稳) |
| QLoRA | 模型 4-bit 量化 + LoRA。 | 硬件资源受限时的唯一神。适合在单卡或消费级显卡(如 RTX 3090/4090)上微调 7B~70B 大模型。 | ⭐⭐⭐⭐⭐ (最火) |
| AdaLoRA | 动态分配秩(Rank)。有的层需要多学,有的层不需要。 | 追求极致参数效率。在给定的极低参数预算下,AdaLoRA 效果比固定 Rank 的 LoRA 好,但实现复杂,训练可能稍慢。 | ⭐⭐⭐ |
| DoRA | 权重分解为"方向"和"幅度"。高度逼近全参数微调。 | 追求极致模型性能 。几乎是 LoRA 的免费升级版,同等参数下效果更好,目前在各大框架中(如 PEFT)已经支持只需加一个参数 use_dora=True。 |
⭐⭐⭐⭐ (性能佳) |
| PiSSA | SVD 主成分初始化。收敛极快,误差小。 | 追求更快的收敛和更好的量化效果 。目前 HuggingFace PEFT 也已原生支持(init_lora_weights="pissa"),是取代传统 LoRA 初始化的极佳方案。 |
⭐⭐⭐⭐ (潜力大) |
二、 添加式方法(Additive Methods)
1. Adapter Tuning
- 工作原理:在 Transformer Block 的核心组件(如 Self-Attention 和 FFN)之后,串联插入一个小型的神经网络模块(通常是两层 MLP,先降维再升维)。冻结原模型,只训练这些新插入的 MLP。
- 局限性 :
- 推理延迟(Latency):由于 Adapter 是"串行"插入的,数据必须先经过原模型网络,再经过 Adapter。这改变了模型结构,增加了真实的推理耗时(通常增加 10%~20% 延迟)。
2. Prompt Tuning
- 工作原理:不改动模型内部,只在输入的 Token 序列最前面,拼接(Concat)上几个到几十个虚拟的"软提示(Soft Prompts)"向量。模型反向传播时只更新这几个虚拟 Token 的 Embedding 向量。
- 局限性 :
- 极难优化:非常依赖初始化的质量,训练容易陷入局部最优,收敛极慢。
- 吃模型规模:通常只在参数量达到百亿或千亿级(如 100B)的超大模型上,表现才能媲美全量微调;在小模型上效果很差。
- 占用上下文:虚拟 Token 会占用模型宝贵的输入上下文长度。
3. Prefix Tuning / P-Tuning v2
- 工作原理 :不仅在输入层加,而是在 Transformer 每一层 的 Multi-Head Attention 中的 Key(键)和 Value(值)矩阵前面,拼接上一段可训练的虚拟"前缀(Prefix)"。
- 局限性 :
- 吞噬 KV Cache:这些虚拟的前缀需要永久驻留在每一层注意力的 KV Cache 中。这意味着它挤占了原本属于用户输入数据的 KV Cache 空间,导致模型实际可处理的序列长度缩短,也会轻微降低推理吞吐量。
4. IA³ (Infused Adapter)
- 工作原理 :在 Transformer 中引入三个可学习的向量,分别与 Attention 的 Key、Value 以及 FFN 的中间激活值进行逐元素相乘(Element-wise Scaling),以此缩放特征的激活强度。
- 局限性 :
- 表达能力受限:逐元素缩放的数学表达能力远不及矩阵乘法(LoRA)。对于需要注入大量新领域知识的任务,IA³ 往往显得"力不从心"。
三、 选择式方法(Selective Methods)
1. BitFit
- 工作原理 :神经网络的线性层由 y=Wx+by = Wx + by=Wx+b 组成。BitFit 直接冻结所有庞大的权重矩阵 WWW,只解冻并更新所有的偏置项 bbb(Bias)。
- 局限性 :
- 天花板极低:Bias 的参数量不到万分之一。如果微调任务与预训练任务差异巨大,或者需要模型学习全新语言/复杂逻辑,仅靠修改偏置项根本无法做到,很容易欠拟合。
2. Diff Pruning
- 工作原理:为全量参数学习一个极度稀疏的"差异掩码(Sparse Mask)"。通过正则化手段,强迫网络在微调时只有极少数(如 0.5%)对当前任务最关键的权重发生改变,其余保持为 0。
- 局限性 :
- 非结构化稀疏难以加速:虽然理论上更新的参数极少,但在实际的 GPU 硬件底层,计算非结构化的稀疏矩阵效率很低。通常需要定制的 CUDA 算子才能真正省下显存和加速,工程落地难。
四、 表示微调(Representation-based)
1. ReFT / LoReFT
- 工作原理:跳出了"修改权重参数"的思维定势,转而"干预神经元的激活值"。它在前向传播经过特定层时,将模型的隐状态(Hidden States)投射到一个低秩的正交子空间中,对其进行修改,然后再合并回去。
- 局限性 :
- 生态不成熟:由于是非常前沿的方法,目前 HuggingFace 等主流框架的原生支持度不如 LoRA 完善。
- 干预位置难确定:需要实验决定干预哪些层、干预哪些 Token(例如仅干预 Prompt 的最后一个 Token 还是全部),比 LoRA 直接全局铺设要费心。
五、 统一与混合框架
1. UniPELT
- 工作原理:一个缝合怪。将 LoRA(负责矩阵表达)、Prefix Tuning(负责注意力干预)和 Adapter(负责特征非线性变换)塞到一起,并设计一个"门控机制(Gating)"。模型在训练时自己决定对当前输入哪种方法更有效,门控权重会偏向那个方法。
- 局限性 :
- 训练极其笨重:哪怕每种 PEFT 单独都很小,把它们全实例化并加上门控网络,不仅导致微调时的显存消耗大幅增加,也丧失了 PEFT 原本"极致轻量优雅"的初衷。
总结一张图理解如何避坑:
- 怕推理变慢? -> 绝对不要用 Adapter Tuning。选 LoRA 族。
- 显存实在太小? -> 选 QLoRA 或 BitFit。
- 要搞长文本且怕吃内存? -> 慎用 Prefix-Tuning / P-Tuning v2(吃 KV Cache),用 LoRA 或 LongLoRA。
- 不懂底层的炼丹小白? -> 无脑闭眼选原生 LoRA 或 QLoRA,社区现成的代码直接 Run。
常见QA
Q1 : 以Qwen2.5-7B为例,使用梯度检查点后,fp16精度启动全参SFT需要多少显存?至少需要84.37 G。fp16占用2bytes,因此参数权重占用的显存为:27B=14G,记为 base
优化器需要存储 m,v(一阶动量,二阶记忆),精度一般为fp32。因此需要存储4 base
存储梯度值,一般与训练精度一致是bf16,因此需要存储 1base
激活值中间值,存储大约是 Batch_Size * Seq_Length * Hidden_Size * 层数数据精度,假设batch=1, 数据长度是2K,那么就是 12k358428 2Bytes=382M 。
总共占用 6*base + 382M = 84.37 G
相同情况下,LoRA与QLoRa训练时分别占用多少显存?
A1:
- LoRA (16-bit) 训练显存计算:在常规 LoRA 中,底座模型依然以 FP16/BF16 加载。
-
原模型权重 (Base Weights): 精度为 FP16(2 Bytes)。全部冻结。
占用:7B×2 Bytes=14 GB7\text{B} \times 2\text{ Bytes} = \mathbf{14\text{ GB}}7B×2 Bytes=14 GB
-
LoRA 权重 (Trainable Weights):精度为 FP16(2 Bytes)。
占用:35M×2 Bytes≈70 MB35\text{M} \times 2\text{ Bytes} \approx \mathbf{70\text{ MB}}35M×2 Bytes≈70 MB (几乎可以忽略)
-
优化器状态 (Optimizer States):精度一般为 FP32。因为 AdamW 需要存一阶动量(m)、二阶动量(v)和 FP32 的主权重(Master Weights),共计 12 Bytes。(注意:这 12 Bytes 只乘在 35M 上,而不是 7B 上!)
占用:35M×12 Bytes≈420 MB35\text{M} \times 12\text{ Bytes} \approx \mathbf{420\text{ MB}}35M×12 Bytes≈420 MB
-
梯度 (Gradients): 与训练精度一致,为 FP16/BF16(2 Bytes)。同样只有 35M 参数有梯度。
占用:35M×2 Bytes≈70 MB35\text{M} \times 2\text{ Bytes} \approx \mathbf{70\text{ MB}}35M×2 Bytes≈70 MB
-
激活值 (Activations):开启梯度检查点(Gradient Checkpointing)后,虽然不用存前向传播的完整计算图,但仍需保留一定量的中间激活值用于计算 LoRA 分支的梯度。这部分开销基本和全参 SFT 类似,甚至略大一点点(因为多了并联分支)。
占用:预估约 0.5 GB∼1 GB\mathbf{0.5\text{ GB} \sim 1\text{ GB}}0.5 GB∼1 GB(取 1GB 计算)
总共占用 (LoRA): 14 GB + 70 MB + 420 MB + 70 MB + 1 GB ≈ 15.56 GB
- QLoRA (4-bit) 训练显存计算: 在 QLoRA 中,所有的变量开销与上述 LoRA 完全一致,唯一的区别在于底座模型权重的存放格式。
-
原模型权重 (Base Weights):精度被极度压缩为 4-bit (NF4格式,0.5 Bytes)。
占用:7B×0.5 Bytes=3.5 GB7\text{B} \times 0.5\text{ Bytes} = \mathbf{3.5\text{ GB}}7B×0.5 Bytes=3.5 GB (实际框架中往往有一些量化块的额外索引开销,算作 4 GB)
-
LoRA 权重、优化器、梯度、激活值:这些全部保持 16-bit 或 32-bit 参与运算,占用大小与上面的常规 LoRA 完全一模一样!因为你要保证微调的精度。
合计占用:70 MB + 420 MB + 70 MB + 1 GB ≈ 1.56 GB
总共占用 (QLoRA): 3.5 GB (算作 4 GB) + 1.56 GB ≈ 5.56 GB
总结对比表
| 训练模式 | 底座精度 | 底座显存占用 | 优化器/梯度等开销 (针对 7B) | 总显存需求 (不考虑其他开销,仅从理论上计算的最小值) | 能跑的最低显卡 |
|---|---|---|---|---|---|
| 全参SFT | FP16 | 14 GB | ∼70\sim 70∼70 GB (作用于 7B) | ∼85\sim 85∼85 GB | 2 × A6000 或 A100 |
| LoRA | FP16 | 14 GB | ∼1.5\sim 1.5∼1.5 GB (仅作用于 35M) | ∼16\sim 16∼16 GB | 1 × RTX 4080 (16G) |
| QLoRA | 4-bit | ∼4\sim 4∼4 GB | ∼1.5\sim 1.5∼1.5 GB (仅作用于 35M) | ∼6−8\sim 6-8∼6−8 GB | 1 × RTX 3060 (12G) |