目录
- 1、openclaw必须的底层配置文件:
- 2、心跳(HEARTBEAT)机制
- 3、openclaw与LLM配合操作电脑完成任务的过程
- 4、openclaw调用工具(也生成工具)、sub-agent和skills等外援
- 5、openclaw的记忆:
- [6、openclaw应对危害信息(指令,如rm -rf)的防御策略:](#6、openclaw应对危害信息(指令,如rm -rf)的防御策略:)
- 7、openclaw防止上下文过长的方式
-
- [(1)context compression:](#(1)context compression:)
- (2)context过滤后嵌入prompt
- [(3)其他,soft trim、hard clear:](#(3)其他,soft trim、hard clear:)
- (3)context压缩后,效果变差的解决方式
- (4)何时压缩
- 8、clawHub:
1、openclaw必须的底层配置文件:
- ~/.openclaw/openclaw.json
- 系统的"大脑":定义模型、渠道、端口、安全策略等所有全局核心设置。
- ~/.openclaw/workspace/ 目录下的七个文件(用户可以更改,但是不建议,容易导致多个文件之间内容出现矛盾;agent也能自己修改):
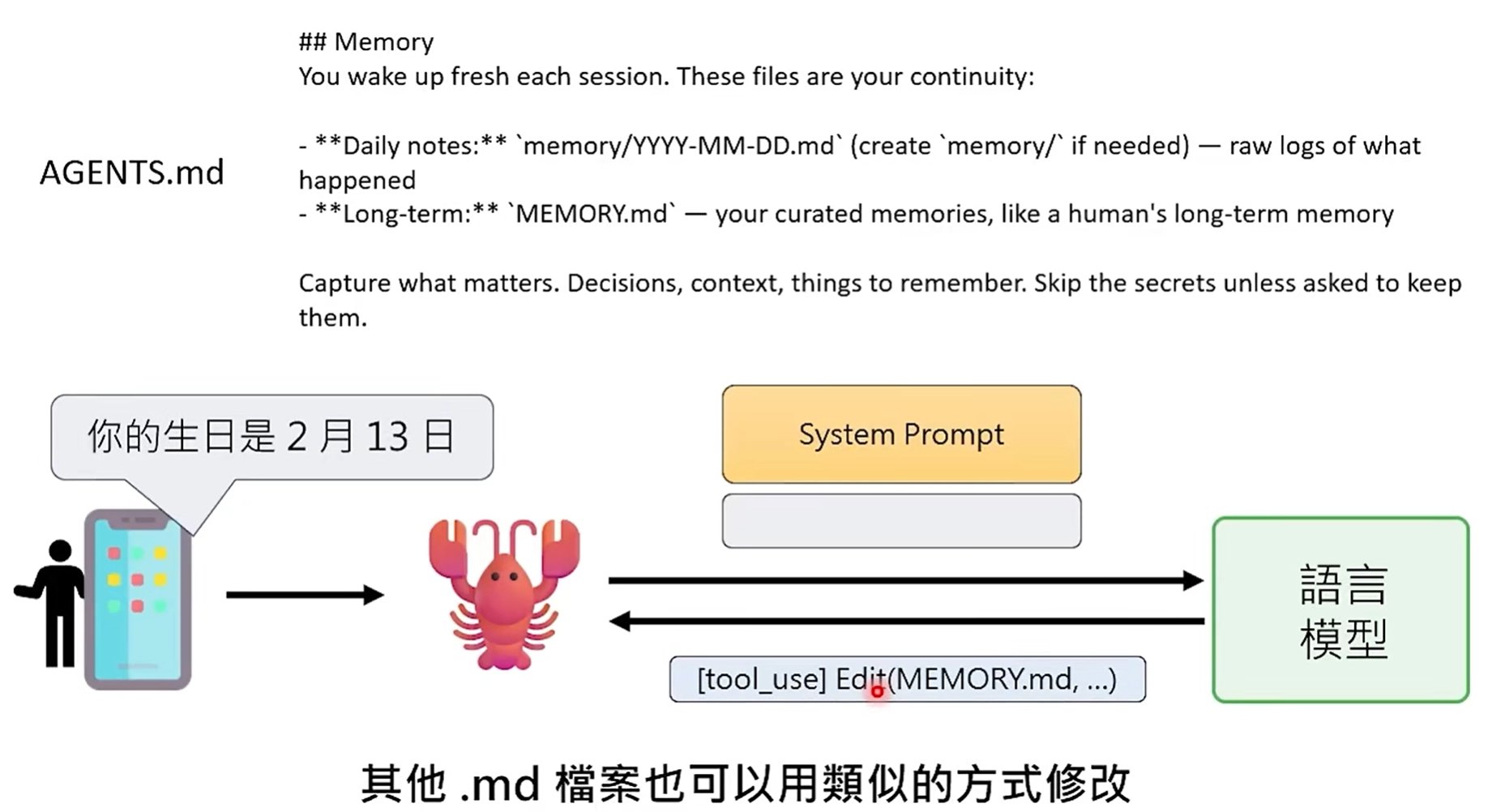
- SOUL.md:agent人格设定,定义AI的性格、核心价值观和沟通风格;
- AGENTS.md:工作指南,规定AI处理任务的流程和规则;
- USER.md:用户说明书,让AI了解你------你的偏好、习惯、雷区;
- MEMORY.md:长期记忆,AI手动可编辑的长期记忆库,记录重要事实、项目进展、你的喜好,实现跨会话(session)的"记住";
- IDENTITY.md:对外形象,区别于SOUL.md的内在,定义AI的"外在"样子------显示名称、主题色、问候语等;
- HEARTBEAT.md:自主意识,AI拥有"主动性",定义定时任务和主动触发条件;
- BOOTSTRAP.md:用于全新工作空间的一次性初始化向导。
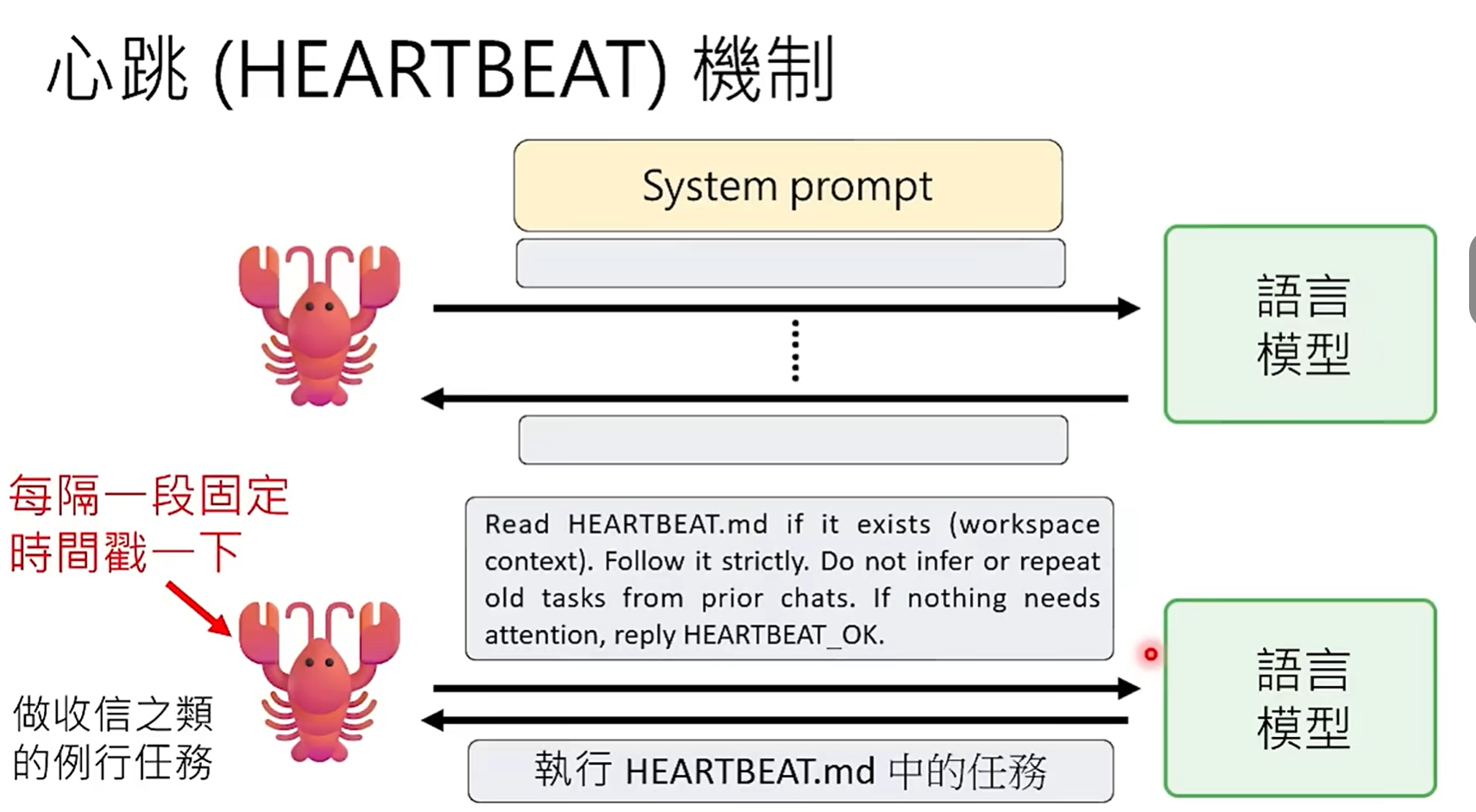
2、心跳(HEARTBEAT)机制
- 一些日常要定时等处理的任务可以放在HEARTBEAT.md中;
- 其中记录的任务不一定是很明确的,比如,可以指定任务"向目标前进",在SOUL.md中定义过它的目标是"成为世界顶级学者",那么它就会可能自己每隔一段时间去阅读某个paper,或者研究了某个模型写了篇笔记等等。
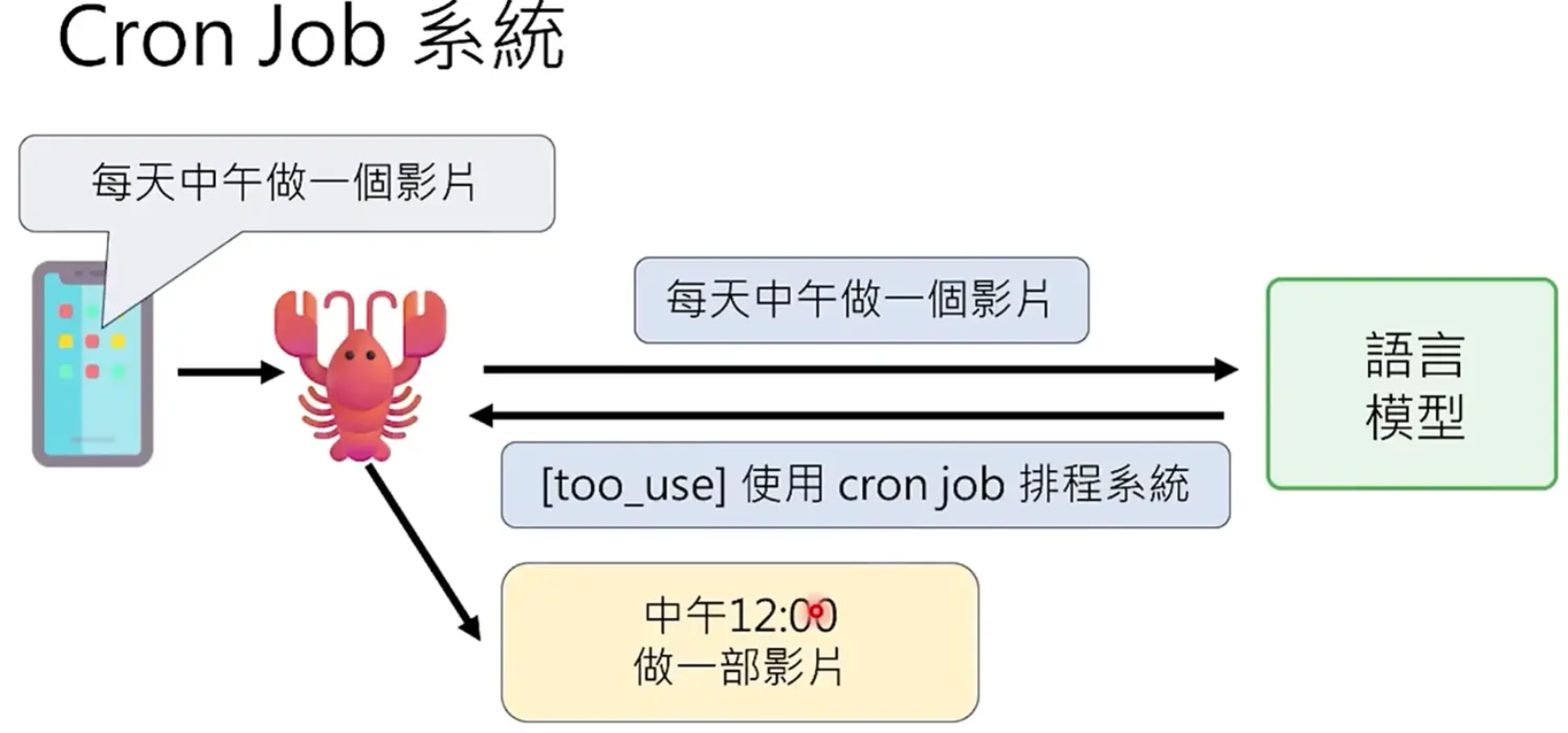
- 搭配心跳机制使用的系统------Cron job系统
-
一般工作逻辑:
-
一种妙用::让AI学会等待
AI并不是真的会等待,对于"龙虾"来说,每一次对话都是一个重启,它只是在指定时间之后执行LLM给的指令;
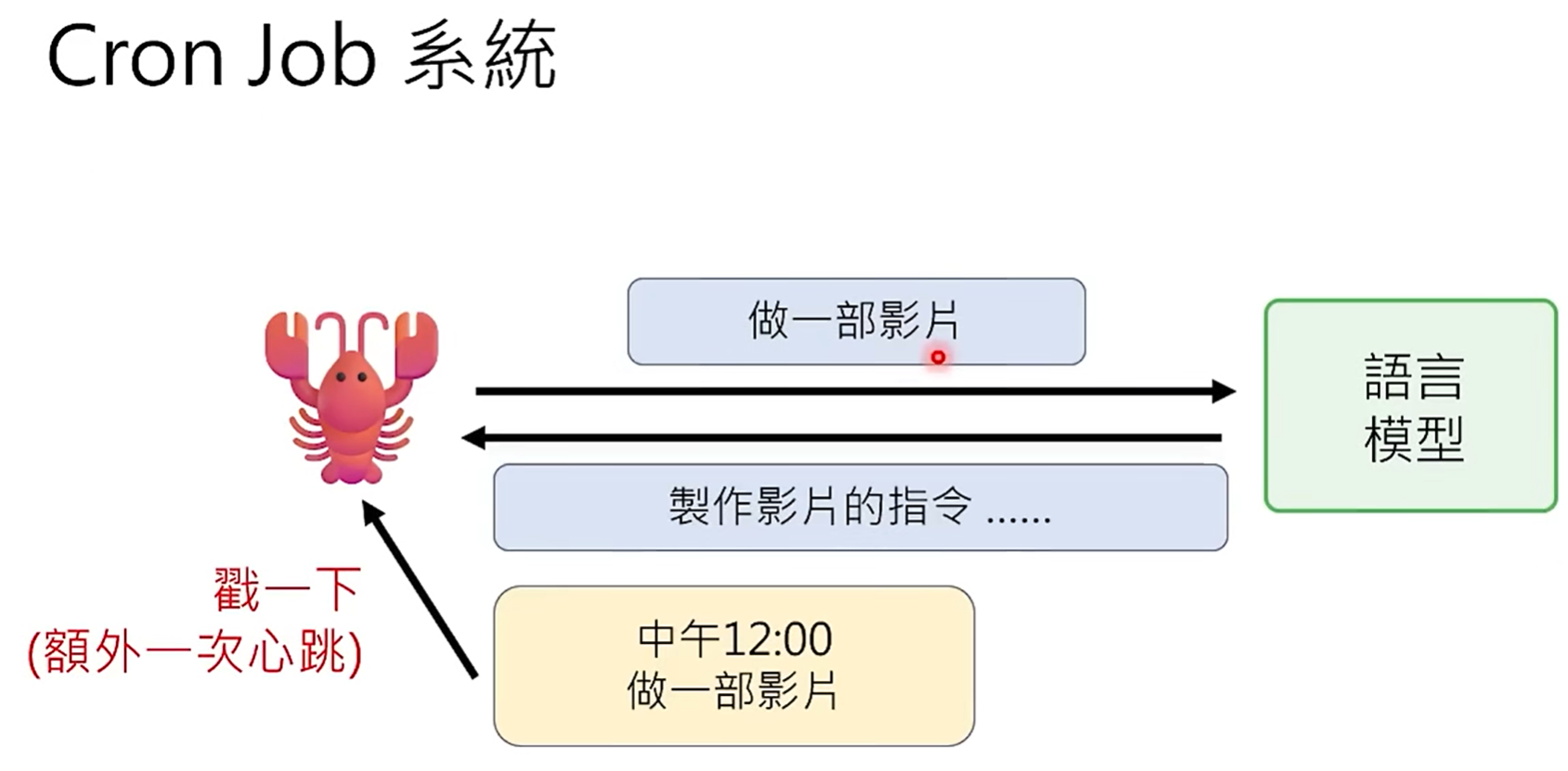
再好的模型,也可能不会每次都能成功,当前最彻底的解决方式是在memory.md中规定好,只要有"xxx生成中"这类表达,都需要在x分钟之后检查网页。
- 没有cron job的一般情况

- 加了cron job的情况:
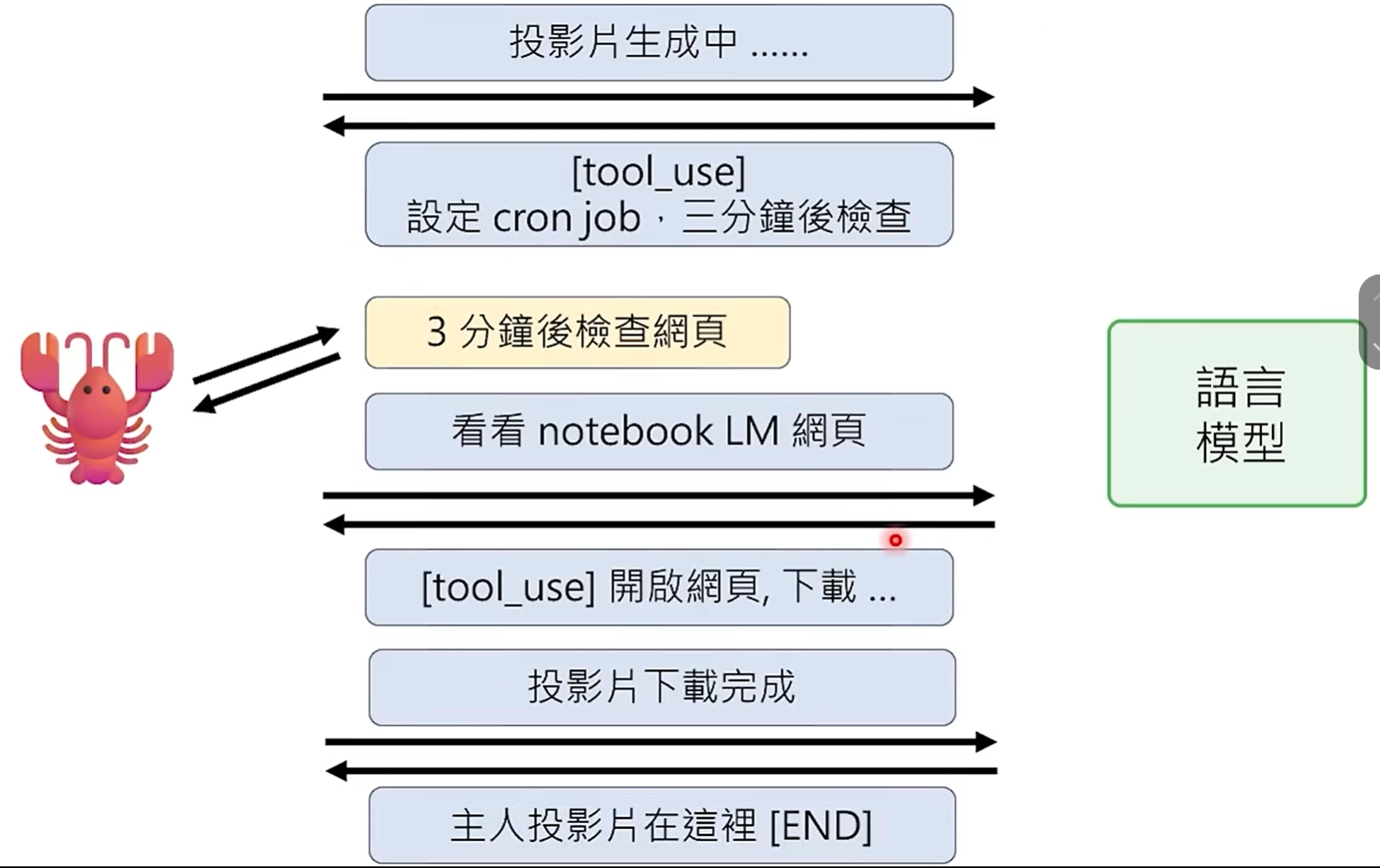
- 没有cron job的一般情况
-
3、openclaw与LLM配合操作电脑完成任务的过程
1、"龙虾"接收到任务,并将任务prompt发送给LLM,大模型识别到可以使用Read工具,返回Read工具调用指令;
大模型返回的是对Read工具调用的指令,有的LLM可能能力比较差,会光说不练,仅返回"我无法打开xxx文件......"。
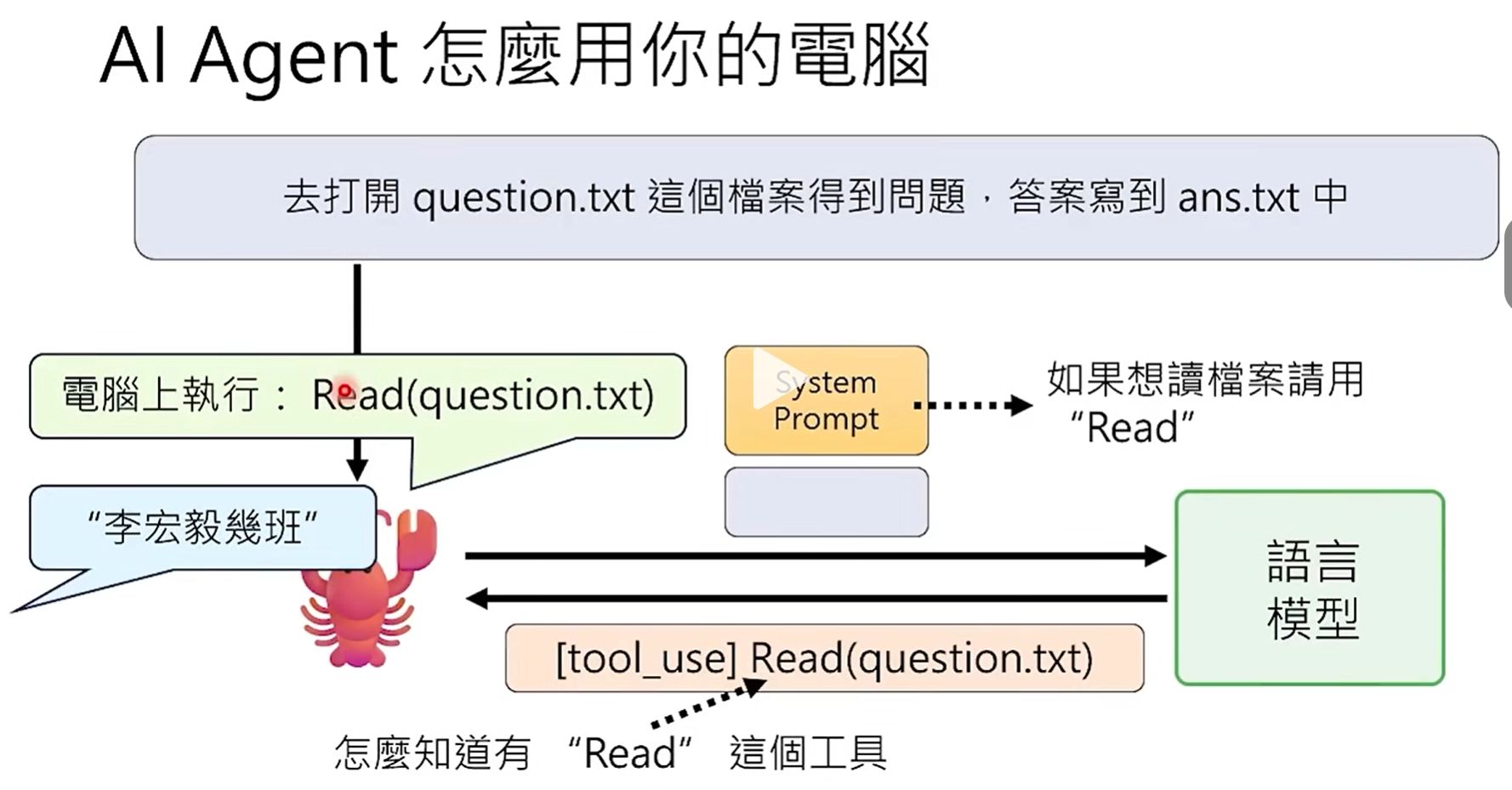
2、"龙虾"使用Read工具,读取到文件中的问题,并将问题传给LLM,LLM返回答案和调用Write工具的指令;
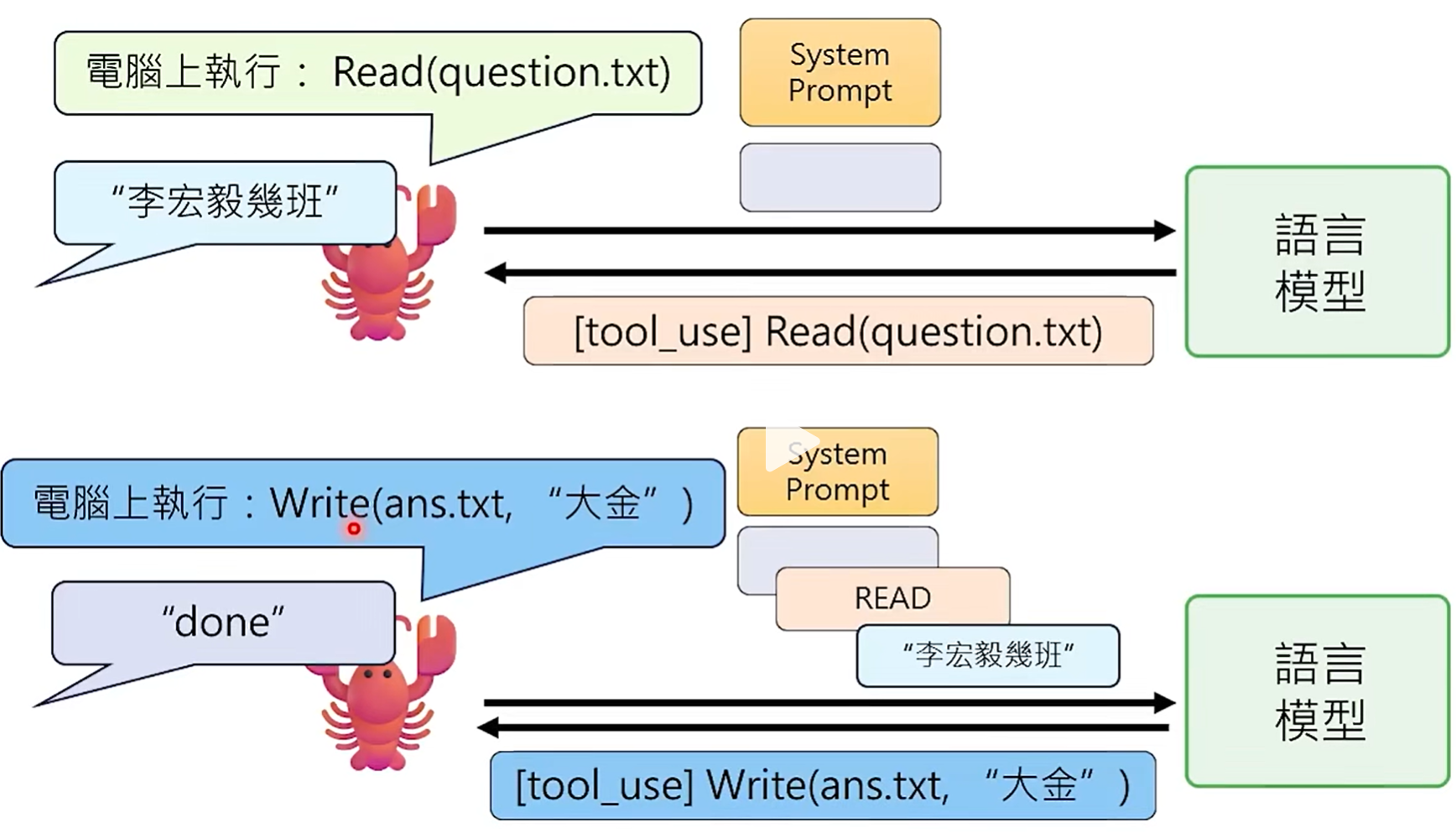
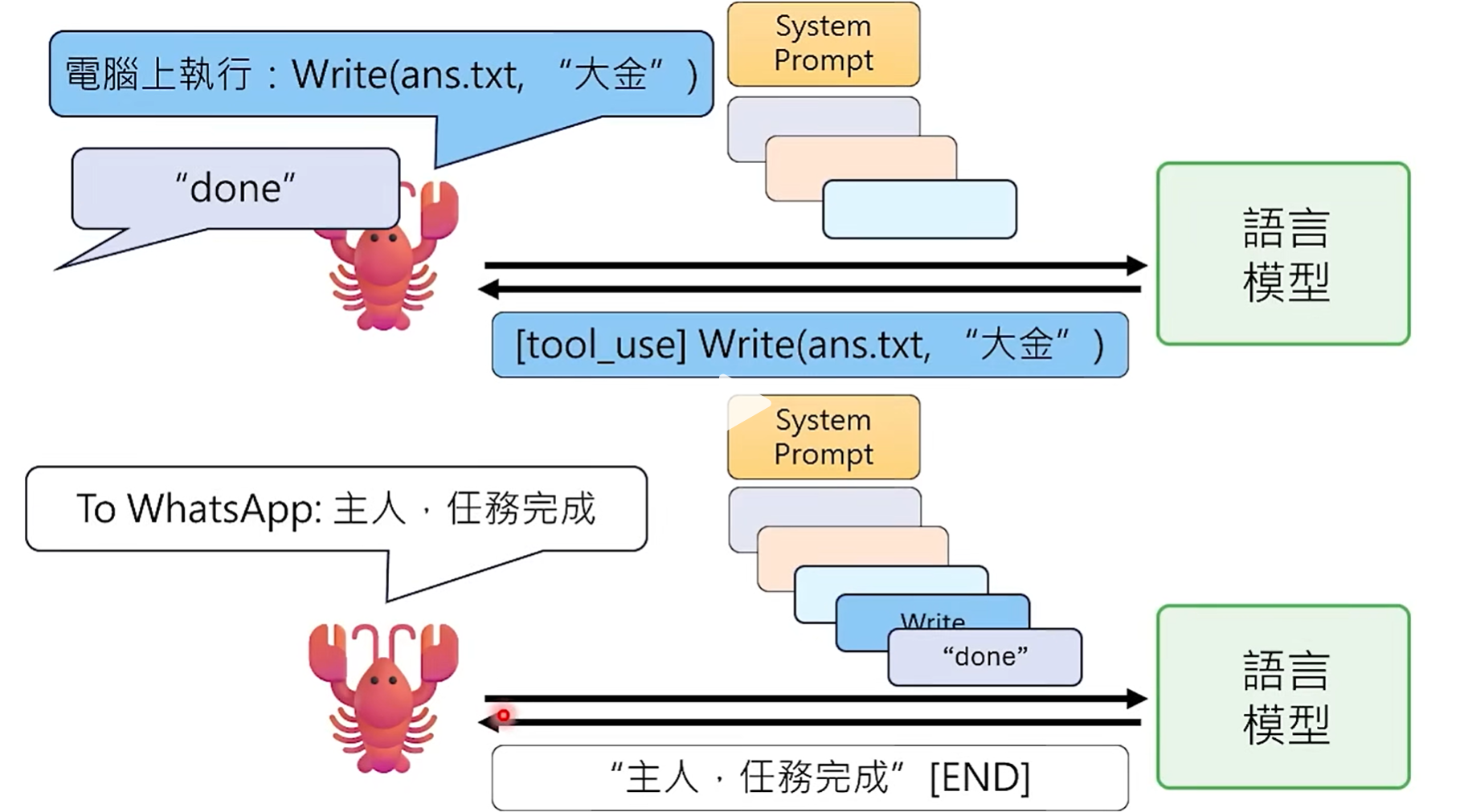
3、"龙虾"使用Write工具将答案写入文件中,并返回Done完成标识给LLM,LLM将"主任,任务完成 DONE"内容返回。
4、openclaw调用工具(也生成工具)、sub-agent和skills等外援
- 可以调用工具;
- 也可以自己生成工具并使用;
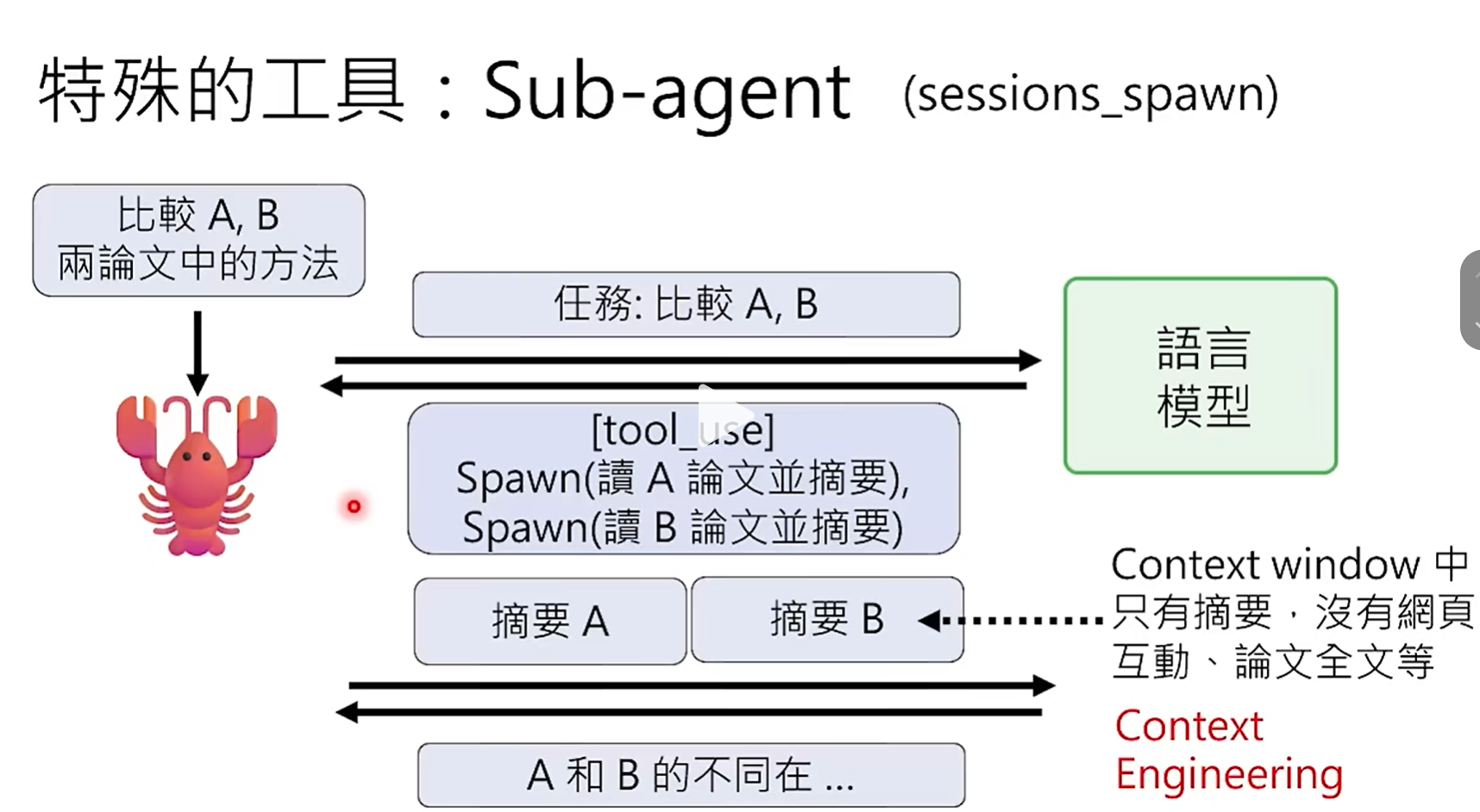
- 调用sub-agent(sessions-spawn):
其中,context engine指的是通过一定的策略,如"大龙虾"使用sub-agent分开处理长context(另外,加载skills时,初始仅加载他们的name、description等基本信息,也是一种context engine策略),从而使得自己的context window在可控范围内,本质上对于"大龙虾"来说就是进行了context compression。- 大龙虾"调用sub-agent这些"小龙虾"进行复杂任务处理(比如比较A、B两篇paper):
 - 调用skill:初始状态时加载所有的skill的name和description,按需确定真正使用某个skill时加载其所有的信息。
- 调用skill:初始状态时加载所有的skill的name和description,按需确定真正使用某个skill时加载其所有的信息。
- 大龙虾"调用sub-agent这些"小龙虾"进行复杂任务处理(比如比较A、B两篇paper):
5、openclaw的记忆:
对话页面"new session"按钮,一键清空当前记忆,但是不会完全清空,对于部分重要记忆会按照agent.md文档中的记录记忆的规则进行记录:
- AGENT.md中对长期记忆的记录规则:
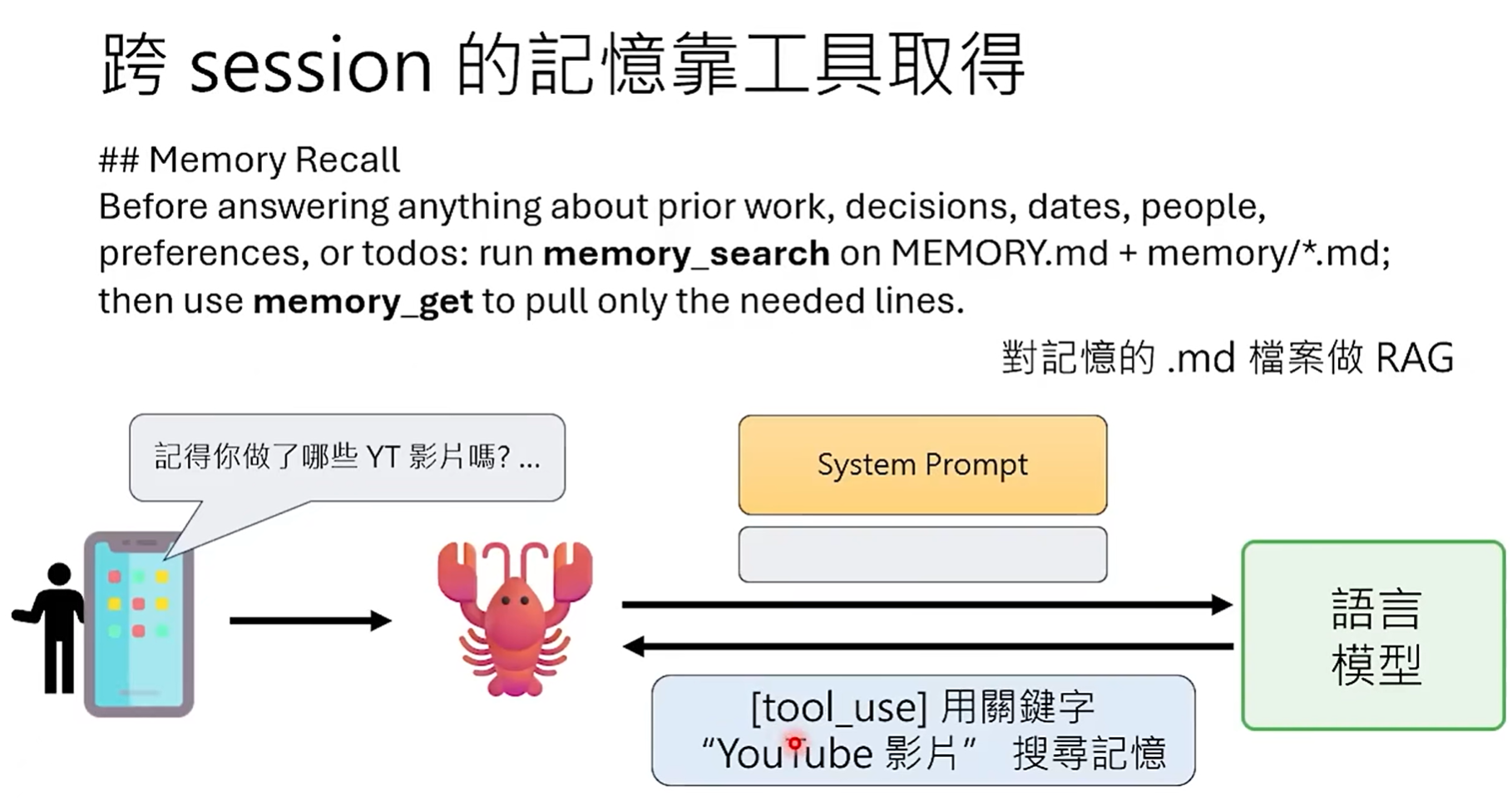
- 使用memory_search和memory_get工具跨session获取记忆:
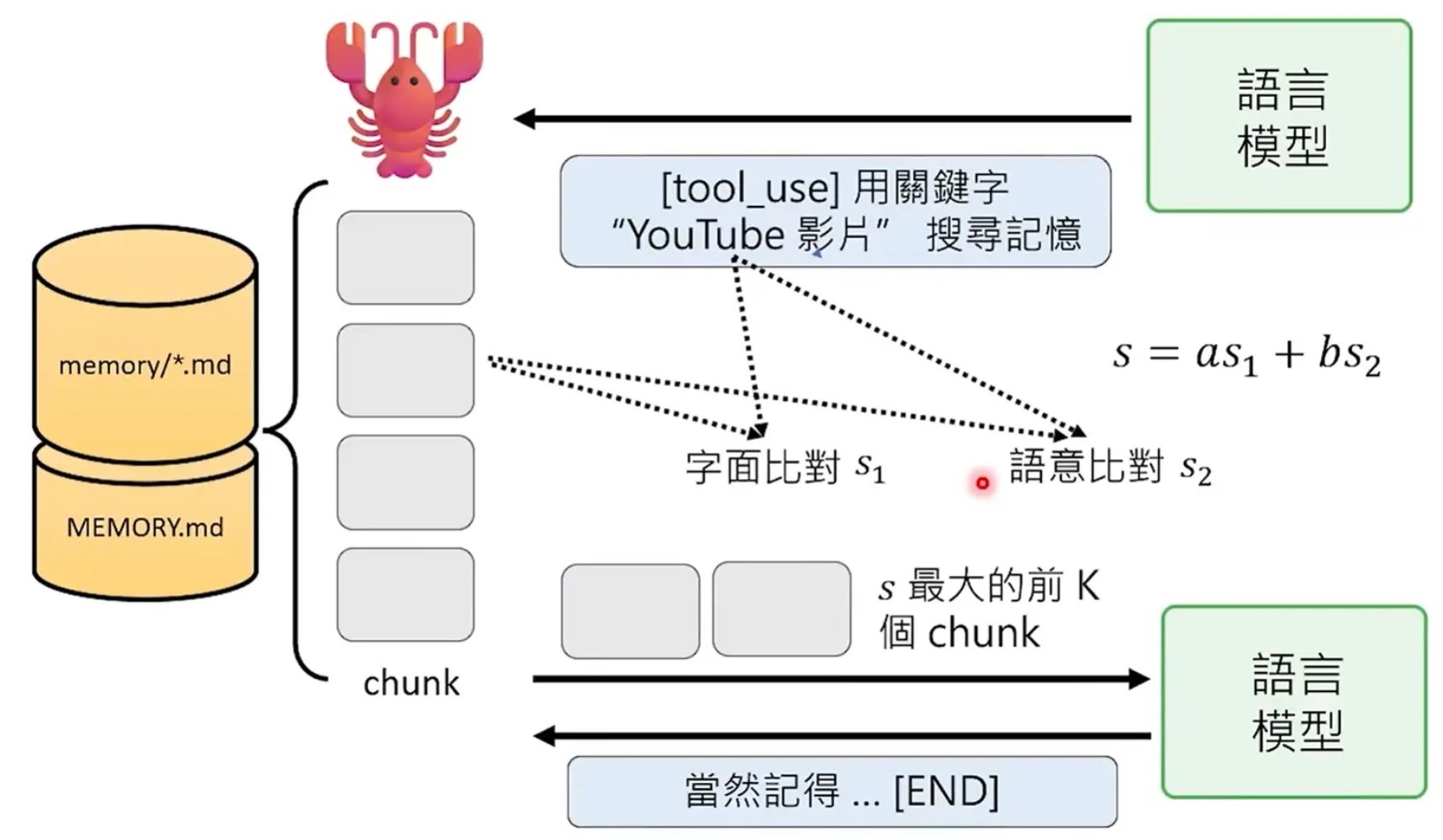
- 当前对话与历史记忆的RAG:
6、openclaw应对危害信息(指令,如rm -rf)的防御策略:
(使用内置规则)执行指令时,弹窗咨询用户意愿。
7、openclaw防止上下文过长的方式
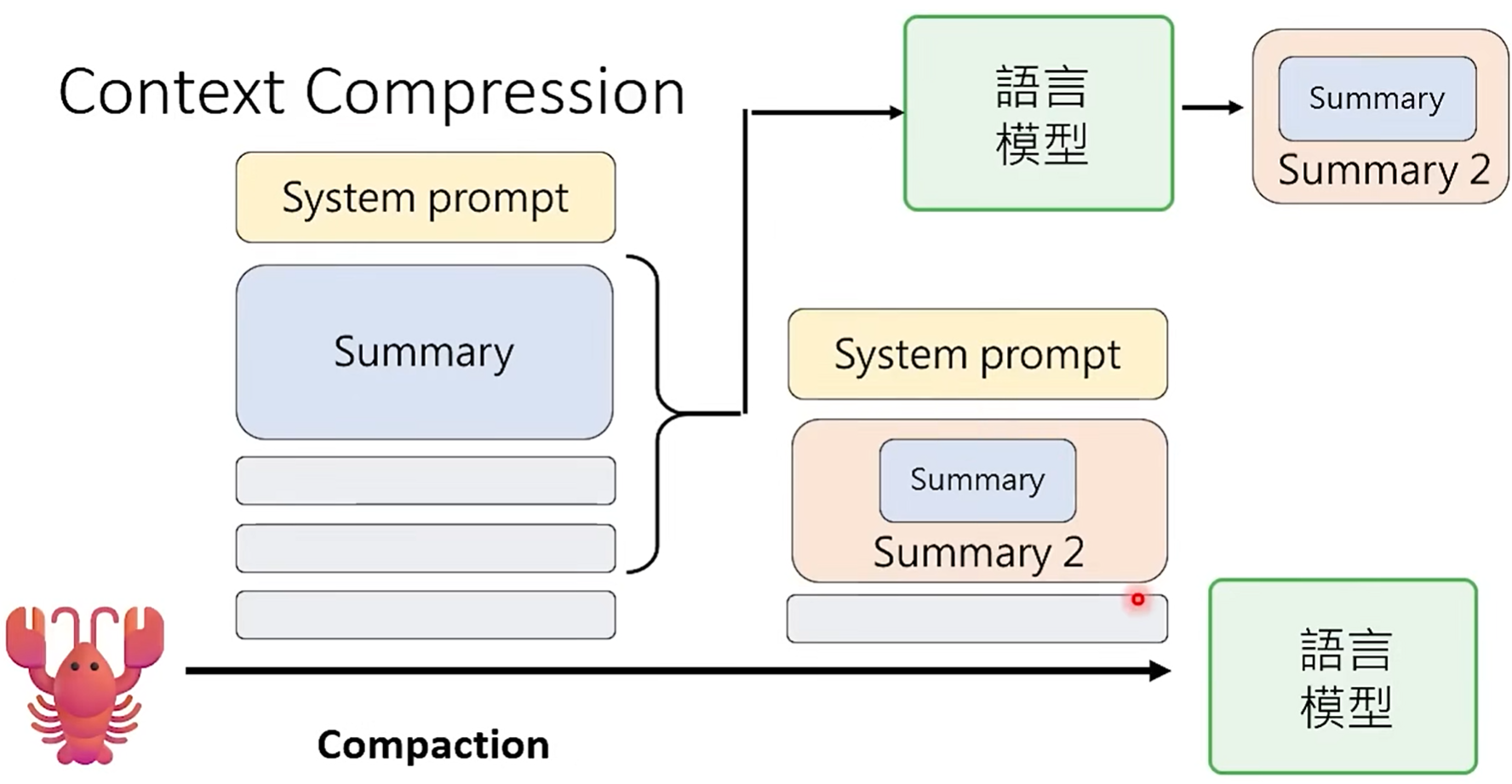
(1)context compression:
- 对历史context进行摘要(可多次摘要),然后仅记录摘要后的内容;
- 主agent调用sub-agent处理任务,也是一种context压缩策略。
(2)context过滤后嵌入prompt
- 读memory的时候,使用的memory_search和memory_get工具其中就使用了一定的过滤机制;
- 按需加载真正要使用的skill,也是一种过滤策略。
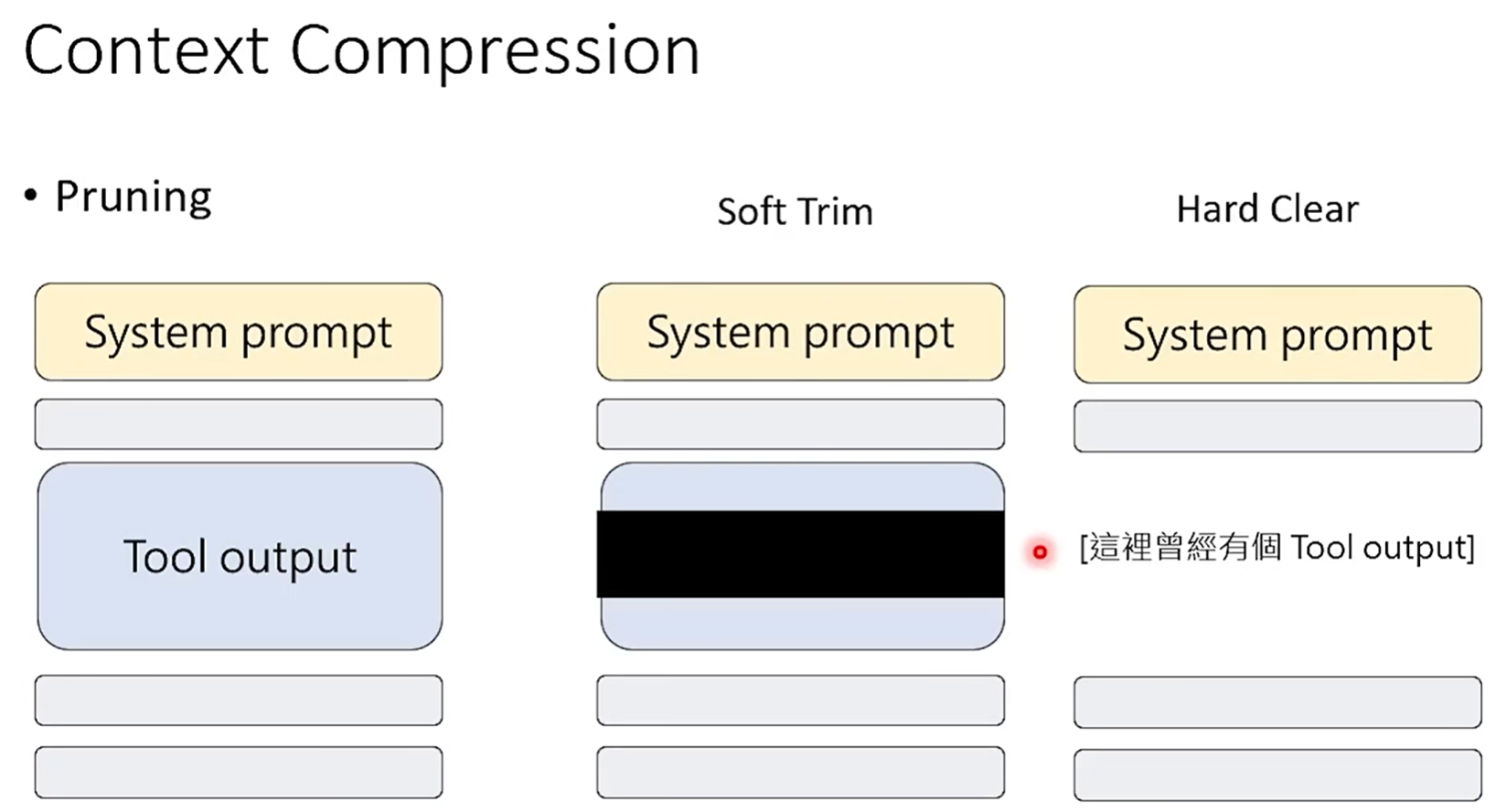
(3)其他,soft trim、hard clear:
- 将工具的调用记录给抹掉(删除),或者直接使用 这里曾经有个tool output 进行替换;
- 也可以使用 详见log1.txt 这么一个说明和附件替换 这里曾经有个tool output ,好处是后续如果确实需要查看这个tool output时能调用Read工具直接获取;
(3)context压缩后,效果变差的解决方式
- 使用另一个LLM,将压缩后,效果变差的例子给该LLM,并让它进行总结反省,得到feedback信息,下次回答问题时,将这些feedback信息一起放在prompt中给到LLM;
(4)何时压缩
- openclaw使用最简单粗暴的方式:设置一定的长度阈值,超过这个阈值则开始进行压缩;
- 通过指令强制模型自己进行压缩一般不可行,因为模型本身是不喜欢对context进行压缩的,模型可能不一定会去执行压缩,如果想让模型进行自主压缩,需要对模型进行额外的压缩场景训练;
8、clawHub:
- 可以把它理解为 OpenClaw AI 的"插件应用商店",可以找到、安装、分享skills;
- 官网:ClawHub
- 【国内腾讯skill社区:https://skillhub.tencent.com/】