现在使用AI帮我们找一些资料帮我们分析问题的场景多的数不胜数,但是在AI找资料的过程中,我们对AI抓取的内容是不知道,也不可以明确指定范围的,主要是靠模型本身能力去收集,当然也可以增加提示词,加以控制。
当然目前解决方案也有很多:
- 增加更详细的提示词,描述更细致,控制更精细,过程更明确
- 同时也有Tavily Search、SearXNG等搜索智能体,可以更好指定搜索参数,如何处理搜索结果等
- 引用Skills、MCP等丰富大模型能力
了解到这些的时候,想着练习写一个Skills,实现网页内容抓取(其实很多东西都已经实现了,本文就是学习和分享),也了解一下Skills的开发
Skills的项目结构
skill-name/
├── SKILL.md (唯一必需)
│ ├── YAML 格式 (name, description 必须)
│ └── Markdown instructions (介绍使用Markdown)
└── Bundled Resources (可选的其他内容,和SKILL.md同级)
├── scripts/ - 存放可执行脚本(例如 Python 等)
├── references/ - 存放文档、API说明、领域知识
├── examples/ - 存放示例文件
├── evals/ - 存放测试说明
└── assets/ - 准备模板、图标、样板代码。确保格式正确(PPT、Word、图片等)SKILL.md元数据介绍
元数据字段:
| 字段 | 必填 | 说明 |
|---|---|---|
| name | 是 | Skill 显示名称,默认使用目录名,仅支持小写字母、数字和短横线(最长 64 字符) |
| description | 是 | 技能用途及使用场景,Claude 根据它判断是否自动应用 |
| argument-hint | 否 | 自动补全时显示的参数提示,如 issue-number、filename format |
| disable-model-invocation | 否 | 设为 true 禁止 Claude 自动触发,仅能手动 /name 调用(默认 false) |
| user-invocable | 否 | 设为 false 从 / 菜单隐藏,作为后台增强能力使用(默认 true) |
| allowed-tools | 否 | Skill 激活时 Claude 可无授权使用的工具 |
| model | 否 | Skill 激活时使用的模型 |
| context | 否 | 设为 fork 时在子代理上下文中运行 |
| agent | 否 | 子代理类型(配合 context: fork 使用) |
| hooks | 否 | 技能生命周期钩子配置 |
scripts
Skills采用Prompt + Scripts架构,Scripts必须绑定特定运行时环境
- Skills的实现多采用
Python脚本,也是大模型运行的主要环境 - Node.js Skills:需配置node_modules及package.json
- Bash Scripts:仅需基础Shell环境(但可能依赖系统工具包)
开发案例
Python还不太熟悉,用Node写了一个
主要实现的是:获取网页中所有的文本内容,如果有可以识别的媒体文件,将媒体资源的URL获取下来
整体项目目录结构,skills中website-content-fetch是本次的skill主目录,我们可以在一个项目中开发多个skill统一放在skills中,在一起维护也可以随时使用和优化其他skill
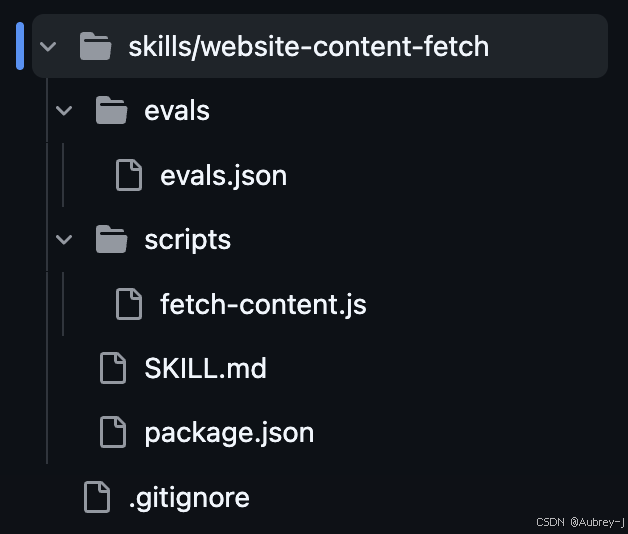
SKILL.md
markup
---
name: website-content-fetch
description: Fetch and extract content from websites. Use this skill whenever the user mentions fetching website content, extracting text from web pages, or needing to get content from a URL, even if they don't explicitly ask for a 'website content fetch' skill.
---package.json
json
{
"name": "website-content-fetch",
"version": "1.0.0",
"description": "fetching website content",
"main": "scripts/fetch-content.js",
"scripts": {
"test": "node scripts/fetch-content.js"
},
"keywords": [
"openclaw",
"skill",
"website",
"content",
"fetch"
],
"author": "",
"license": "MIT",
"dependencies": {
"axios": "^1.6.2",
"cheerio": "^1.0.0-rc.12"
}
}scripts
fetch-content.js
javascript
const axios = require("axios");
const cheerio = require("cheerio");
const path = require("path");
const fs = require("fs");
/**
* Fetch website content
* @param {string} url - The URL to fetch
* @param {object} options - Optional parameters
* @param {string} options.saveDir - Directory to save media files (optional)
* @returns {Promise<object>} - The fetched content and metadata
*/
async function fetchWebsiteContent(url, options = {}) {
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
// Extract text content
let content = $("body").text().trim();
// Clean up content
content = content.replace(/\s+/g, " ");
// Extract media resources
const media = {
images: [],
videos: [],
audios: [],
};
// Extract images
$("img").each((i, elem) => {
const src = $(elem).attr("src");
const alt = $(elem).attr("alt") || "";
if (src) {
const absoluteUrl = new URL(src, url).href;
media.images.push({
url: absoluteUrl,
alt: alt,
});
}
});
// Extract videos
$("video, iframe").each((i, elem) => {
let src = $(elem).attr("src");
if (!src && $(elem).attr("data-src")) {
src = $(elem).attr("data-src");
}
if (src) {
const absoluteUrl = new URL(src, url).href;
media.videos.push({
url: absoluteUrl,
});
}
});
// Extract audios
$("audio").each((i, elem) => {
const src = $(elem).attr("src");
if (src) {
const absoluteUrl = new URL(src, url).href;
media.audios.push({
url: absoluteUrl,
});
}
});
// Save media files if saveDir is provided
if (options.saveDir) {
// Create save directory if it doesn't exist
if (!fs.existsSync(options.saveDir)) {
fs.mkdirSync(options.saveDir, { recursive: true });
}
// Save images
for (let i = 0; i < media.images.length; i++) {
const image = media.images[i];
try {
const imageResponse = await axios.get(image.url, {
responseType: "stream",
});
const imageName = `image_${i}_${path.basename(new URL(image.url).pathname)}`;
const imagePath = path.join(options.saveDir, imageName);
const writer = fs.createWriteStream(imagePath);
imageResponse.data.pipe(writer);
await new Promise((resolve, reject) => {
writer.on("finish", () => resolve());
writer.on("error", reject);
});
image.localPath = imagePath;
} catch (error) {
console.error(`Error saving image ${image.url}:`, error.message);
}
}
// Save videos
for (let i = 0; i < media.videos.length; i++) {
const video = media.videos[i];
try {
const videoResponse = await axios.get(video.url, {
responseType: "stream",
});
const videoName = `video_${i}_${path.basename(new URL(video.url).pathname)}`;
const videoPath = path.join(options.saveDir, videoName);
const writer = fs.createWriteStream(videoPath);
videoResponse.data.pipe(writer);
await new Promise((resolve, reject) => {
writer.on("finish", () => resolve());
writer.on("error", reject);
});
video.localPath = videoPath;
} catch (error) {
console.error(`Error saving video ${video.url}:`, error.message);
}
}
// Save audios
for (let i = 0; i < media.audios.length; i++) {
const audio = media.audios[i];
try {
const audioResponse = await axios.get(audio.url, {
responseType: "stream",
});
const audioName = `audio_${i}_${path.basename(new URL(audio.url).pathname)}`;
const audioPath = path.join(options.saveDir, audioName);
const writer = fs.createWriteStream(audioPath);
audioResponse.data.pipe(writer);
await new Promise((resolve, reject) => {
writer.on("finish", () => resolve());
writer.on("error", reject);
});
audio.localPath = audioPath;
} catch (error) {
console.error(`Error saving audio ${audio.url}:`, error.message);
}
}
}
return {
content,
length: content.length,
url,
media,
};
} catch (error) {
console.error("Error fetching website content:", error);
throw new Error(`Failed to fetch content from ${url}: ${error.message}`);
}
}
// If run directly, test the function
if (require.main === module) {
const url = process.argv[2] || "https://example.com";
const saveDir = process.argv[3];
const options = {};
if (saveDir) {
options.saveDir = saveDir;
}
fetchWebsiteContent(url, options)
.then((result) => {
console.log("Fetched content:");
console.log(`URL: ${result.url}`);
console.log(`Length: ${result.length} characters`);
console.log("Content:");
console.log(result.content);
// Display media resources
console.log("\nMedia resources:");
if (result.media.images.length > 0) {
console.log("Images:");
result.media.images.forEach((image, index) => {
console.log(`${index + 1}. ${image.url} (alt: ${image.alt})`);
if (image.localPath) {
console.log(` Saved to: ${image.localPath}`);
}
});
}
if (result.media.videos.length > 0) {
console.log("\nVideos:");
result.media.videos.forEach((video, index) => {
console.log(`${index + 1}. ${video.url}`);
if (video.localPath) {
console.log(` Saved to: ${video.localPath}`);
}
});
}
if (result.media.audios.length > 0) {
console.log("\nAudios:");
result.media.audios.forEach((audio, index) => {
console.log(`${index + 1}. ${audio.url}`);
if (audio.localPath) {
console.log(` Saved to: ${audio.localPath}`);
}
});
}
})
.catch((error) => {
console.error("Error:", error.message);
});
}
module.exports = { fetchWebsiteContent };evals
evals.json
json
{
"skill_name": "website-content-fetch",
"evals": [
{
"id": 1,
"prompt": "Fetch content from https://example.com",
"expected_output": "Should return the text content of example.com",
"files": []
},
{
"id": 2,
"prompt": "Fetch content from a nonexistent domain",
"expected_output": "Should throw an error about failed to fetch content",
"files": []
},
{
"id": 3,
"prompt": "Fetch content without providing a URL",
"expected_output": "Should throw an error about URL being required",
"files": []
}
]
}测试
将开发的skill目录website-content-fetch引入支持skill的AI助手或者开发IDE,此处不赘述,只要website-content-fetch放入对应的skills目录,助手或者IDE都可以识别到。
开发的时候,只需要在项目中,和AI工具说使用website-content-fetch skill为我抓取https://www.baidu.com中的内容即可,比如我使用Trae对话,AI会自动发现该工具,并识别scripts的语言 ,识别到node环境会开始install依赖 ,再用skill执行任务

install成功之后,环境准备就绪,就会按照skill开发的功能执行任务了
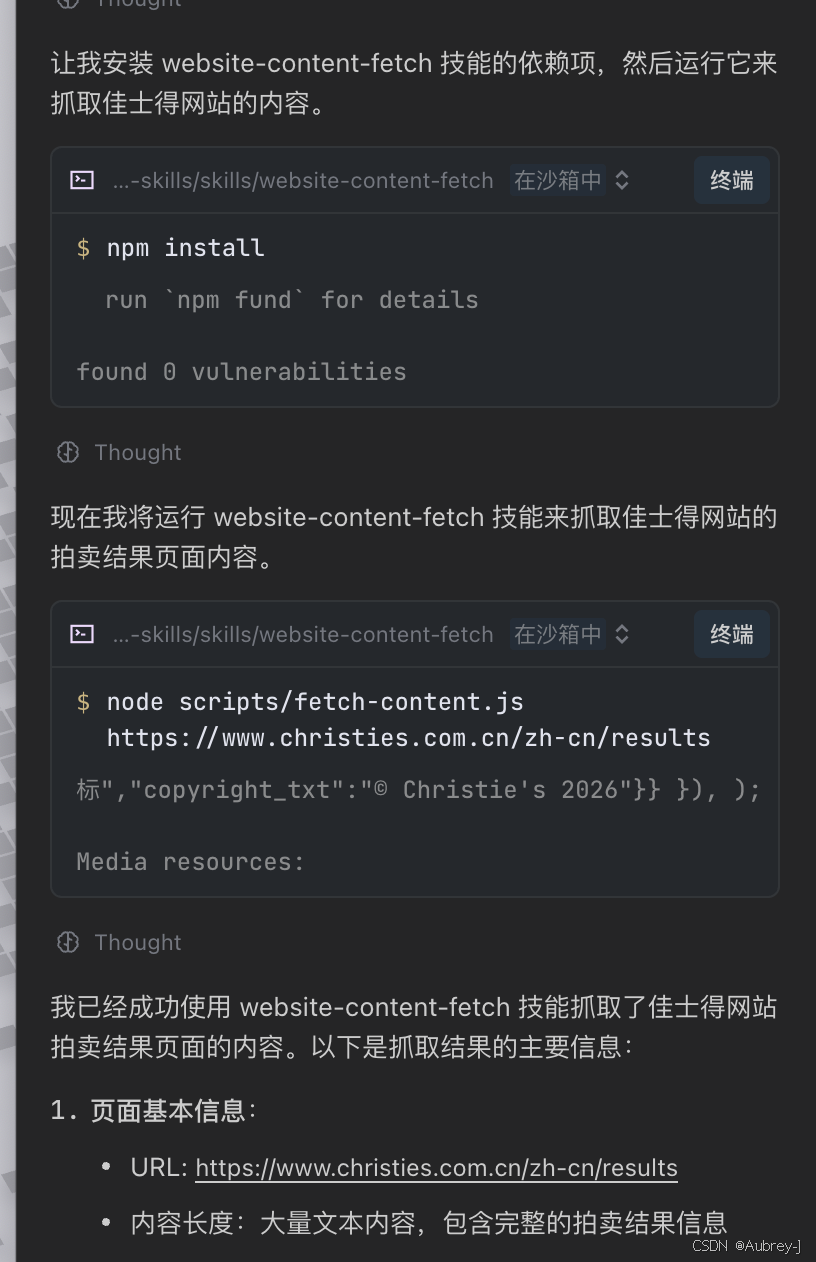
- 最后再反复测试结果,调试scripts功能,优化逻辑
- 丰富SKILL内容,为AI下次识别工具,对skill的功能和逻辑有更好的理解,更精确的执行任务
最后附上Github地址
aubrey-skills