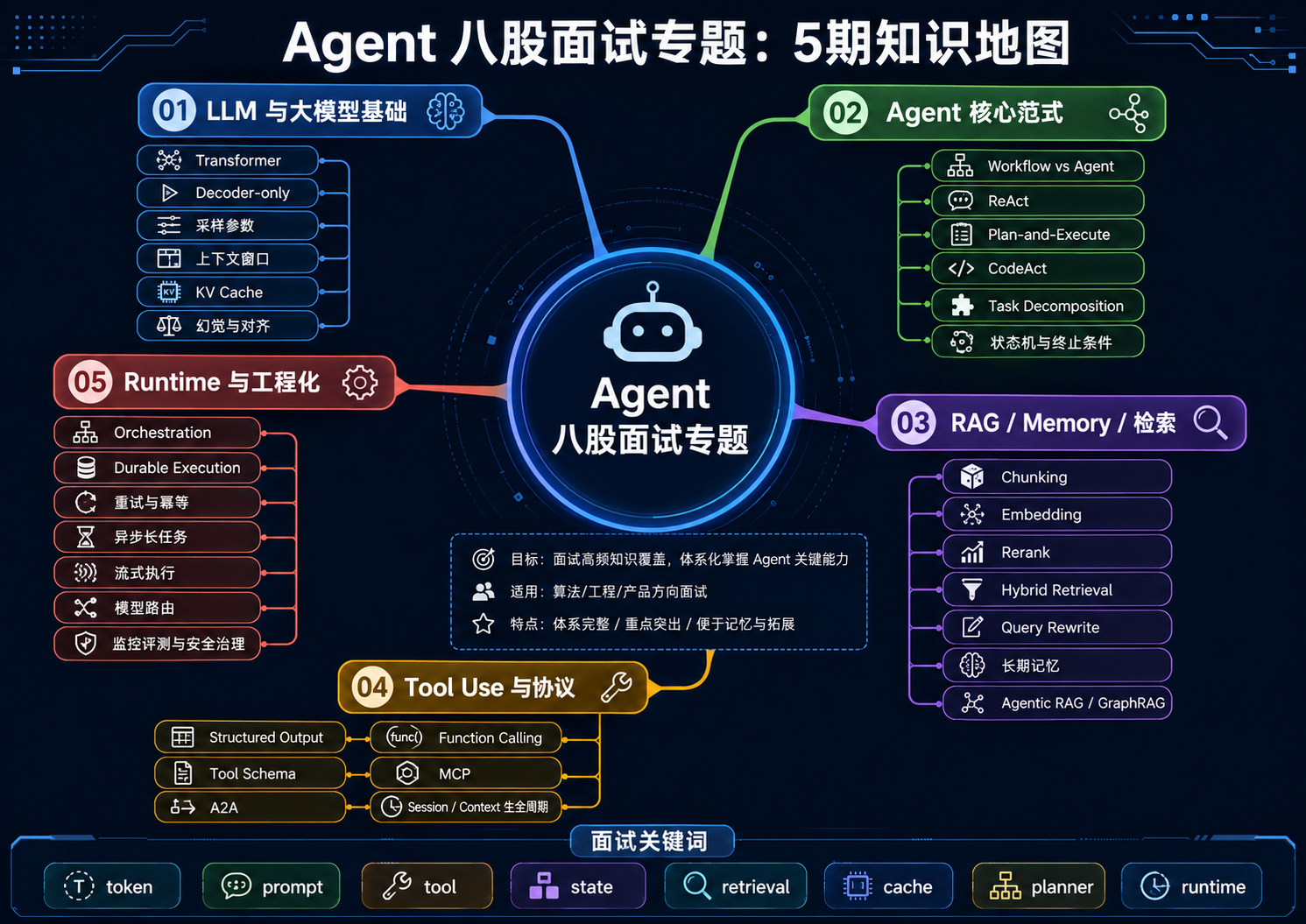
Agent 八股专题第三期:RAG / Memory / Agentic RAG 面试 10 连问
面向:大模型应用开发、RAG 工程师、Agent 工程师、AI 平台岗位
核心目标:把 RAG 从"向量库 demo"讲到"企业级知识系统"
目录
- RAG 是什么?为什么不是简单向量搜索?
- RAG 和微调有什么区别?
- Chunking 为什么决定 RAG 系统上限?
- Chunk size 和 overlap 应该怎么定?
- Embedding 和 Rerank 分别解决什么问题?
- 为什么生产系统常用 Hybrid Retrieval?
- Query Rewrite 有什么用?风险是什么?
- RAG 和 Memory 的本质区别是什么?
- 什么是 Agentic RAG?不是套个 Agent 壳
- GraphRAG 适合什么场景?一定比普通 RAG 强吗?
1. RAG 是什么?为什么不是简单向量搜索?
一句话定义
RAG,全称是 Retrieval-Augmented Generation,也就是:
在模型生成答案之前,先从外部知识源中检索相关证据,再把证据放进上下文,让模型基于证据回答。
低级回答:
text
RAG = 向量数据库 + 大模型这个回答非常危险。
因为它只说到了最浅的一层。
更准确的理解是:
text
RAG = 知识解析 + 切块 + 索引 + 检索 + 重排 + 上下文组装 + 生成 + 引用 + 权限 + 评测 + 监控材料里也明确强调,面试官会关注知识从哪里来、怎么进系统、怎么取出来、模型如何被证据约束、系统如何上线,而不是只问会不会调一个向量库。
RAG 的完整链路
text
原始文档 / 数据库 / 网页 / 代码仓库
↓
文档解析 Parsing
↓
切块 Chunking
↓
向量化 Embedding
↓
索引构建 Indexing
↓
用户 Query 理解
↓
检索 Retrieval
↓
重排 Rerank
↓
上下文组装 Context Construction
↓
LLM 生成答案
↓
引用 / 拒答 / 置信度 / trace工程化版本
python
def rag_pipeline(query: str):
# 1. 查询理解
rewritten_query = query_rewrite(query)
# 2. 多路召回
dense_docs = dense_retrieve(rewritten_query, top_k=30)
sparse_docs = bm25_retrieve(rewritten_query, top_k=30)
# 3. 合并候选
candidates = merge_and_deduplicate(dense_docs, sparse_docs)
# 4. 重排
reranked_docs = rerank(query, candidates, top_k=8)
# 5. 上下文压缩
context = build_context(reranked_docs)
# 6. 基于证据回答
answer = llm_generate(
query=query,
context=context,
instruction="只基于给定资料回答;资料不足时明确说明。"
)
return answer面试回答模板
可以这样说:
RAG 不是一个向量库项目,而是一条推理时访问外部知识并约束生成的工程链路。它的核心价值是让模型不要只依赖参数中的压缩知识,而是在回答前读取可更新、可追溯、可权限控制的外部证据。真正的 RAG 系统要考虑解析、切块、索引、召回、重排、上下文组装、引用、权限、评测和监控。
这就是能拿分的回答。
2. RAG 和微调有什么区别?
核心区别
RAG 解决的是:
text
知识怎么查出来微调解决的是:
text
模型怎么更会按照某种方式回答不要把二者混成一个东西。
对比表
| 维度 | RAG | 微调 |
|---|---|---|
| 主要目标 | 注入外部知识 | 改变模型行为/风格/格式 |
| 知识更新 | 容易,更新知识库即可 | 难,需要重新训练或继续训练 |
| 可追溯性 | 强,可以引用来源 | 弱,知识在参数里 |
| 适合场景 | 企业知识问答、文档问答、政策查询 | 输出格式、领域表达、任务风格 |
| 成本 | 主要是检索和推理成本 | 训练成本 + 数据成本 |
| 风险 | 检索错、权限错、上下文污染 | 遗忘、过拟合、幻觉仍存在 |
典型误区
很多人会说:
我们把公司知识微调进模型就好了。
这句话非常外行。
企业知识通常有几个特点:
text
更新频繁
权限复杂
版本很多
需要引用来源
需要删除和审计这些东西不适合全部塞进模型参数。
项目里的合理组合
更好的方案是:
text
高频稳定行为 -> SFT / Prompt / Output Schema
动态企业知识 -> RAG
用户偏好和长期状态 -> Memory
实时数据 -> Tool / API面试回答模板
RAG 更适合解决外部知识访问、更新和引用问题;微调更适合解决模型行为、表达风格、领域术语、输出格式和任务模式问题。企业知识库问答通常优先用 RAG,而不是把所有知识微调进参数。两者不是替代关系,而是互补关系。
3. Chunking 为什么决定 RAG 系统上限?
直接说结论
Chunking 是 RAG 的地基。
你切错了,后面 embedding、rerank、LLM 再强都救不回来。
材料里对这一点说得很狠:很多候选人能讲 RAG 流程,但一被问为什么 chunk size 设 512 而不是 1024,为什么加 rerank,embedding 为什么换代,就暴露没有做过系统优化。
Chunking 到底在切什么?
低级理解:
text
把长文档切成一段一段高级理解:
text
为检索系统定义可索引、可召回、可引用、可拼装的最小语义单元一个好的 chunk 至少要满足:
text
语义相对完整
长度适合 embedding
能被 query 命中
能挂载元数据
不会混入太多无关内容
能回溯原文位置错误切块示例
原文:
text
第六条:本保险承保因意外伤害导致的医疗费用。
但以下情况除外:
1. 战争、暴乱;
2. 核辐射;
3. 被保险人故意行为。如果切成两个 chunk:
text
chunk_1:
第六条:本保险承保因意外伤害导致的医疗费用。
chunk_2:
但以下情况除外:核辐射......用户问:
text
核辐射导致的医疗费用赔吗?系统可能只召回 chunk_1,然后回答:
text
赔。这就是典型 RAG 事故。
不是模型蠢,是你切块蠢。
更好的 chunk
json
{
"chunk_id": "insurance_clause_006",
"title": "第六条:承保范围与除外责任",
"text": "本保险承保因意外伤害导致的医疗费用。但以下情况除外:战争、暴乱、核辐射、被保险人故意行为。",
"metadata": {
"doc_id": "insurance_policy_2026",
"section": "第六条",
"type": "coverage_and_exclusion",
"page": 12
}
}这才像一个可用的知识单元。
4. Chunk size 和 overlap 应该怎么定?
面试官真正想听什么
不是想听:
text
一般设 512 token。这属于背参数。
真正要讲的是:
text
chunk size 取决于文档结构、问题粒度、embedding 模型、上下文预算和引用需求常见范围
| 场景 | 推荐切块策略 |
|---|---|
| FAQ / 短知识条 | 按 QA 对切 |
| 政策 / 合同 | 按条款、标题、章节切 |
| 技术文档 | 按标题层级 + 代码块保护 |
| 论文 / 报告 | 按章节 + 段落语义切 |
| 日志 | 按时间窗口 / error block 切 |
| 表格 | 按行组、业务实体或结构化字段切 |
overlap 的作用
overlap 是为了解决边界信息丢失。
例如:
text
chunk_1: A B C D
chunk_2: D E F GD 被重叠保留,可以减少上下文断裂。
overlap 不能太大
overlap 太大会带来:
text
索引体积膨胀
重复召回
上下文浪费
rerank 噪声增加
答案重复一个简单的结构化切块器
python
from typing import List, Dict
def chunk_by_heading(markdown_text: str) -> List[Dict]:
chunks = []
current_title = None
current_lines = []
for line in markdown_text.splitlines():
if line.startswith("#"):
if current_lines:
chunks.append({
"title": current_title,
"text": "\n".join(current_lines)
})
current_lines = []
current_title = line.strip("# ").strip()
else:
current_lines.append(line)
if current_lines:
chunks.append({
"title": current_title,
"text": "\n".join(current_lines)
})
return chunks这个只是最小示例。真实系统还要处理:
text
PDF 页眉页脚
表格
图片 OCR
代码块
标题层级
跨页段落
脚注
多栏排版面试回答模板
chunk size 不是固定值,而是由文档类型和查询粒度决定。合同政策类文档应优先保留条款完整性,技术文档要保护标题、代码块和表格,FAQ 则按问答对切。overlap 用来缓解边界断裂,但太大会造成重复召回和上下文浪费。工程上应该通过 recall@k、answer groundedness、引用准确率和人工 badcase 来调参,而不是拍脑袋设 512。
5. Embedding 和 Rerank 分别解决什么问题?
两者角色不同
Embedding 解决:
text
从海量文档里快速召回一批可能相关的候选Rerank 解决:
text
在候选里重新精排,挑出真正最相关的证据为什么不能只靠 Embedding?
因为向量召回是近似语义匹配,它容易出现:
text
语义看起来像,但不是答案
关键词没对上
领域术语表达不准
长文本被平均稀释
否定条件识别差
数字、时间、版本不敏感例如用户问:
text
2026 版员工手册中,试用期请假是否影响转正?Embedding 可能召回:
text
员工手册
试用期
请假制度
转正规则但真正答案可能只在一个非常具体的条款里。
Rerank 的作用
Rerank 通常使用 Cross-Encoder 或更强的排序模型,直接看:
text
query + document判断二者相关性。
简化理解:
text
Embedding:先粗筛
Rerank:再精排简化代码
python
def retrieve_then_rerank(query: str):
# 第一阶段:快,但粗
candidates = vector_db.search(query, top_k=50)
# 第二阶段:慢,但准
scored = []
for doc in candidates:
score = rerank_model.score(query, doc["text"])
scored.append((score, doc))
scored.sort(key=lambda x: x[0], reverse=True)
return [doc for score, doc in scored[:8]]面试回答模板
Embedding 适合做大规模候选召回,追求速度和覆盖率;Rerank 适合在候选集上做精排,追求相关性和证据质量。真实 RAG 系统里,通常不是二选一,而是先用 embedding/BM25/hybrid 召回 TopN,再用 rerank 选 TopK 进入上下文。
6. 为什么生产系统常用 Hybrid Retrieval?
Dense Retrieval 不够吗?
不够。
Dense Retrieval,也就是向量检索,擅长语义相似。
例如:
text
"离职补偿" ≈ "解除劳动合同经济补偿"但它对一些东西不敏感:
text
精确编号
人名
订单号
错误码
法律条款号
产品型号
函数名
日志关键词Sparse Retrieval 的价值
BM25 / 关键词检索擅长精确匹配。
例如用户问:
text
错误码 E1027 是什么原因?向量模型可能觉得很多"错误原因"都相关。
但 BM25 可以精准命中:
text
E1027Hybrid Retrieval
Hybrid Retrieval 就是把 dense 和 sparse 结合:
text
Dense:语义召回
Sparse:关键词召回
Rerank:最终精排简化融合策略
python
def hybrid_retrieve(query: str):
dense_results = dense_search(query, top_k=30)
sparse_results = bm25_search(query, top_k=30)
merged = {}
for rank, doc in enumerate(dense_results):
merged.setdefault(doc["id"], {"doc": doc, "score": 0})
merged[doc["id"]]["score"] += 1.0 / (rank + 1)
for rank, doc in enumerate(sparse_results):
merged.setdefault(doc["id"], {"doc": doc, "score": 0})
merged[doc["id"]]["score"] += 1.0 / (rank + 1)
results = sorted(
merged.values(),
key=lambda x: x["score"],
reverse=True
)
return [item["doc"] for item in results]面试回答模板
生产系统常用 Hybrid Retrieval,是因为 dense retrieval 擅长语义泛化,但对精确词、编号、实体、错误码、函数名不稳定;sparse retrieval 擅长关键词精确匹配,但泛化能力弱。两者结合能提高召回覆盖,再通过 rerank 控制最终证据质量。
材料里也把 dense retrieval、sparse、Hybrid Retrieval、rerank、Query Rewrite 放在检索优化高频题里,这就是面试重点。
7. Query Rewrite 有什么用?风险是什么?
Query Rewrite 解决什么问题?
用户原始 query 经常不适合直接检索。
例如:
text
这个能报销吗?系统不知道"这个"是什么。
或者:
text
上次那个政策现在还算吗?query 太依赖上下文。
Query Rewrite 的目标是把用户问题改写成更适合检索的问题。
示例
多轮上下文:
text
用户:我想查一下杭州 E 类人才补贴。
助手:你主要关心购房补贴还是租房补贴?
用户:博士毕业一年后还能申请吗?原始 query:
text
博士毕业一年后还能申请吗?改写后:
text
杭州 E 类人才补贴 博士 毕业一年后 是否还能申请 申请时限Query Rewrite 代码示例
python
def rewrite_query(chat_history: list, current_query: str) -> str:
prompt = f"""
你是检索查询改写器。
任务:把用户当前问题改写成适合知识库检索的独立问题。
要求:
1. 补全上下文指代
2. 保留关键实体、时间、地点、政策名
3. 不要添加用户没有表达的新意图
历史对话:
{chat_history}
当前问题:
{current_query}
输出改写后的检索 query:
"""
return llm(prompt)风险是什么?
Query Rewrite 最大风险是:
text
改写过度
引入错误实体
改变用户原意
丢失限制条件
把开放问题改成封闭问题例如用户问:
text
这个政策有没有风险?模型改写成:
text
这个政策有哪些申请材料?方向完全错了。
工程防护
text
保留原 query 一起检索
rewrite query 和 original query 多路召回
对改写结果做实体一致性检查
记录 rewrite trace
badcase 回放面试回答模板
Query Rewrite 的作用是把省略、指代、多轮上下文依赖的问题改写成更适合检索的独立查询。它能提升召回率,但风险是改写过度和语义漂移。工程上通常不会只用 rewrite query,而是 original query + rewrite query 多路召回,并记录 trace 方便排查。
8. RAG 和 Memory 的本质区别是什么?
一句话区别
RAG 解决:
text
外部知识怎么查Memory 解决:
text
用户和任务状态怎么长期保存并在未来复用对比表
| 维度 | RAG | Memory |
|---|---|---|
| 主要对象 | 文档、知识库、网页、数据库 | 用户偏好、历史任务、长期状态 |
| 来源 | 外部知识源 | 用户交互和系统运行过程 |
| 更新方式 | 文档更新、索引更新 | 写入、合并、遗忘、纠错 |
| 目标 | 提供事实证据 | 支持连续性和个性化 |
| 典型问题 | "公司报销政策是什么?" | "用户上次选择了哪种输出风格?" |
| 关键风险 | 越权、检索错、知识过期 | 误记、脏记忆、隐私、过度个性化 |
会话历史不是 Memory
这是面试大坑。
错误理解:
text
Memory = 把所有聊天记录塞回 prompt正确理解:
text
Memory = 从历史交互中提取对未来有稳定价值的信息,并结构化保存、按需召回、可更新、可删除Memory 写入策略
不是所有东西都应该写入长期记忆。
应该写入:
text
稳定偏好
长期项目背景
持续任务目标
常用技术栈
明确的用户约束不应该写入:
text
临时情绪
一次性问题
错误信息
敏感无关信息
短期上下文Memory 示例结构
json
{
"memory_id": "mem_001",
"type": "user_preference",
"content": "用户偏好 CSDN 技术帖使用 Markdown 格式,包含代码示例和面试回答模板。",
"confidence": 0.92,
"source": "conversation",
"created_at": "2026-05-20",
"last_updated_at": "2026-05-20"
}Memory 检索示例
python
def retrieve_memories(query: str, user_id: str):
memories = memory_store.search(
user_id=user_id,
query=query,
top_k=5
)
filtered = [
m for m in memories
if m["confidence"] > 0.7 and not m.get("expired")
]
return filtered面试回答模板
RAG 面向外部知识检索,Memory 面向用户和任务的长期状态管理。会话历史不等于 Memory,真正的 Memory 需要写入策略、更新策略、遗忘机制、置信度和权限控制。否则 memory 会变成上下文污染源。
材料里也把 RAG vs Memory、长期记忆、session state、working memory、cache、semantic/episodic/procedural memory 都列为高频题,说明这不是边角料,而是 Agent 系统设计重点。
9. 什么是 Agentic RAG?不是套个 Agent 壳
先打掉错误理解
错误回答:
text
Agentic RAG 就是让 Agent 调用 retriever 工具。太浅。
Agentic RAG 的关键不是"多了一个 Agent 名字",而是:
text
检索过程本身变成可规划、可迭代、可反思、可路由的决策过程材料里也明确批评了这种浅层说法:Agentic RAG 不是简单调用一次检索工具,而是根据中间结果动态调整,例如分解子问题、路由不同数据源、验证证据是否足够。
普通 RAG
text
用户问题
-> 检索一次
-> 拼上下文
-> 生成答案Agentic RAG
text
用户问题
-> 判断问题类型
-> 拆分子问题
-> 路由知识源
-> 多轮检索
-> 检查证据是否足够
-> 必要时改写 query 再检索
-> 汇总证据
-> 生成答案例子
用户问:
text
我们公司去年因为售后投诉增加,是否和某次产品版本升级有关?普通 RAG 很难一次检索解决。
Agentic RAG 可能拆成:
text
1. 查询去年售后投诉趋势
2. 查询产品版本发布时间线
3. 检索投诉文本中的高频问题
4. 对齐时间窗口
5. 判断版本升级前后投诉类型是否变化
6. 给出证据链Agentic RAG 简化代码
python
def agentic_rag(query: str):
state = {
"query": query,
"evidence": [],
"sub_questions": [],
"completed": False
}
sub_questions = planner_decompose(query)
state["sub_questions"] = sub_questions
for sub_q in sub_questions:
route = route_data_source(sub_q)
docs = retrieve(
query=sub_q,
source=route,
top_k=20
)
reranked = rerank(sub_q, docs, top_k=5)
state["evidence"].extend(reranked)
if not evidence_sufficient(sub_q, reranked):
rewritten = query_rewrite(sub_q)
more_docs = retrieve(rewritten, source=route, top_k=20)
state["evidence"].extend(rerank(rewritten, more_docs, top_k=3))
return generate_grounded_answer(query, state["evidence"])怎么证明不是"套壳"?
面试里要讲出这些能力:
text
是否会拆子问题
是否会路由不同知识源
是否会多轮检索
是否会检查证据充分性
是否会根据 observation 调整 query
是否有 trace 记录
是否有失败退出策略面试回答模板
Agentic RAG 的核心是让检索成为 Agent 推理循环的一部分。普通 RAG 通常是一次 query 到一次检索再生成,而 Agentic RAG 会根据任务动态拆分问题、选择知识源、改写查询、多轮取证、验证证据充分性,并在证据不足时继续检索或拒答。它不是简单给 retriever 包一层 Agent 名字。
10. GraphRAG 适合什么场景?一定比普通 RAG 强吗?
GraphRAG 是什么?
GraphRAG 不是简单的:
text
RAG + 知识图谱更准确地说,它通常会把非结构化文本转成:
text
实体
关系
社区
摘要报告
图结构索引然后基于图结构做检索和总结。
材料中对 GraphRAG 的要求也更具体:要知道实体/关系抽取、图构建、社区层次、社区报告,以及 local/global/DRIFT search 等不同搜索模式。
Vanilla RAG 不擅长什么?
普通 RAG 擅长:
text
单点事实查询
局部文档问答
明确问题定位但不擅长:
text
跨文档关系
多跳推理
全局主题总结
实体网络分析
复杂组织关系GraphRAG 适合场景
1. 多跳关系问题
text
A 公司和 B 公司之间通过哪些供应商产生关联?2. 全局主题总结
text
这批投诉文档整体反映了哪些系统性问题?3. 实体关系分析
text
某个产品缺陷涉及哪些模块、供应商、工厂和客户群?4. 跨文档聚合
text
过去一年所有项目复盘里反复出现的管理问题是什么?GraphRAG 不适合什么?
不要神化 GraphRAG。
它不适合:
text
简单 FAQ
明确条款查询
实时性要求很高的数据
图构建质量差的语料
实体关系不明显的内容
成本敏感的小系统GraphRAG 简化流程
text
文档解析
↓
实体抽取
↓
关系抽取
↓
图构建
↓
社区发现
↓
社区摘要
↓
local / global / drift search
↓
答案生成简化代码结构
python
class GraphRAGPipeline:
def __init__(self, entity_extractor, relation_extractor, graph_store):
self.entity_extractor = entity_extractor
self.relation_extractor = relation_extractor
self.graph_store = graph_store
def build_graph(self, documents):
for doc in documents:
entities = self.entity_extractor.extract(doc.text)
relations = self.relation_extractor.extract(doc.text, entities)
self.graph_store.upsert_entities(entities)
self.graph_store.upsert_relations(relations)
def query(self, question):
intent = classify_query_intent(question)
if intent == "local_entity":
subgraph = self.graph_store.local_search(question)
elif intent == "global_summary":
subgraph = self.graph_store.global_search(question)
else:
subgraph = self.graph_store.hybrid_search(question)
return generate_answer(question, subgraph)面试回答模板
GraphRAG 更适合多跳关系、跨文档聚合、实体网络分析和全局主题总结。但它不一定比普通 RAG 强,因为它依赖实体关系抽取质量,构图和维护成本高,更新复杂,简单事实查询反而可能更慢。生产上更合理的做法是路由:简单问题走 vanilla RAG,复杂关系和全局分析问题走 GraphRAG。
这句话非常关键。
面试里谁把 GraphRAG 吹成万能,谁就是没吃过工程的苦。
第三期总结:RAG 不是向量库,Memory 不是聊天记录
这 10 题的主线是:
text
RAG
-> Chunking
-> Embedding
-> Rerank
-> Hybrid Retrieval
-> Query Rewrite
-> Memory
-> Agentic RAG
-> GraphRAG
-> 失败模式治理真正要形成的认知是:
RAG 的核心不是"能不能搜到东西",而是能不能把正确、最新、可权限访问、可引用、可验证的证据,在正确时间放进模型上下文里。
再狠一点说:
text
RAG demo 的门槛很低。
企业级 RAG 的门槛很高。因为上线后真正的问题不是"能不能回答",而是:
text
为什么答错?
为什么没召回?
为什么召回了但没用?
为什么引用错?
为什么越权了?
为什么知识过期了?
为什么同一个问题今天对明天错?
为什么改了 chunk 后旧问题退化了?材料里也强调,RAG 常见失败模式不能都甩锅给"幻觉",要能定位到底是解析坏、切块错、召回漏、重排歪、上下文拼坏、权限过滤裁掉,还是知识本身过期。
面试速记版
text
1. RAG 不是向量库,而是外部知识约束生成的完整工程链路。
2. RAG 解决知识访问,微调解决模型行为。
3. Chunking 决定检索上限,切错后面基本救不回来。
4. chunk size 没有万能值,要看文档结构、查询粒度和上下文预算。
5. Embedding 负责粗召回,Rerank 负责精排序。
6. Hybrid Retrieval 结合语义召回和关键词召回,更适合生产。
7. Query Rewrite 能补全上下文,但有语义漂移风险。
8. RAG 是外部知识,Memory 是用户/任务长期状态。
9. Agentic RAG 是迭代式、有决策的检索,不是套 Agent 壳。
10. GraphRAG 适合关系、多跳、全局总结,但不是万能银弹。面试项目表达模板
可以直接改成自己的项目话术:
text
我们做企业知识库问答时,没有把 RAG 简单做成向量库检索。整个链路包括文档解析、结构化切块、embedding 索引、BM25 + dense hybrid retrieval、rerank 精排、上下文压缩和基于证据生成。
在检索优化上,我们发现很多 badcase 不是模型能力问题,而是 chunk 粒度破坏了语义边界,或者 query 中存在省略和指代。所以我们加入了 query rewrite、多路召回和 rerank,并通过 recall@k、引用准确率、答案 groundedness 和人工 badcase 集做回归测试。
对于复杂问题,普通 RAG 一次检索不够,我们设计了 Agentic RAG:planner 会拆分子问题,router 会选择不同数据源,retriever 多轮取证,最后由 LLM 基于证据链生成答案。对于跨文档实体关系和全局主题总结,我们尝试 GraphRAG,但没有一刀切使用,而是通过问题类型路由控制成本和延迟。这段比"我用了 LangChain 搭了个 RAG"强太多。
第四期题目:Tool Use / Function Calling / MCP / 协议层
第四期的内容是(给各位爱学习的宝子们作揖了,希望你点一个关注,谢谢!):
text
1. Function Calling 和 Structured Output 有什么区别?
2. Tool Schema 应该怎么设计?
3. 工具参数缺失时 Agent 应该怎么办?
4. Tool Use 的完整执行链路是什么?
5. Tool Executor 和 LLM 的边界是什么?
6. MCP 是什么?解决什么问题?
7. MCP 和普通 Function Calling 有什么区别?
8. A2A 是什么?为什么说是 Agent 互操作?
9. Session / Context 生命周期怎么管理?
10. Tool Use 里权限、审计和安全怎么做?