引言
调度器(Schedulers)在 Hugging Face Diffusers 库中发挥着至关重要的作用,并且会显著影响机器学习工作流的效率与性能。它们会在训练和推理过程中动态调整诸如学习率之类的参数,帮助模型收敛到更优的取值,同时降低过拟合与欠拟合等风险。本章将探讨调度器的功能、类型及其实际应用场景,为读者提供一套关于如何在真实世界的 NLP 流水线中实现并集成调度器的系统性指导。
本章结构
本章涵盖以下主题:
- 调度器简介
- 离散调度器与连续调度器
- 在训练中使用调度器
- 在推理中使用调度器
- 调度器实际应用案例研究
学习目标
读完本章后,读者将对调度器的功能及其重要性形成全面理解,能够把握它们在机器学习(ML)工作流中的作用,以及它们对于构建高性能模型的重要意义。读者将能够运用不同策略实现多种调度技术,以增强训练过程、提升模型效率并提高准确率。
读者还将学习如何通过高级调度方法提升模型性能,例如利用调度器实现噪声添加与样本更新等技术,从而增强模型的鲁棒性与泛化能力。此外,读者还将能够面向特定任务定制调度器,通过调整调度器设置来满足特定自然语言处理(NLP)任务的需求,从而确保其在多样化应用中的最优表现。最后,读者将能够评估并比较不同的调度策略,针对不同建模场景批判性地判断并选择最有效的方法。本章将帮助读者掌握实现和优化调度器的技能,从而支持更高级的模型训练,并提升 NLP 项目的整体性能。
调度器简介
调度器通过在学习过程中动态调整训练参数,在引导机器学习模型走向收敛方面发挥关键作用。在 ML 工作流中,最优性能往往取决于学习率与其他超参数之间的平衡。调度器提供了一种自适应修改这些参数的手段,使模型能够克服收敛缓慢、过拟合和欠拟合等问题。12
调度器的作用
调度器在 ML 工作流中具有双重作用。
在训练阶段,它们会根据训练进展调整学习率或其他参数,帮助模型找到通往收敛的最高效路径。
在推理阶段,调度器则用于稳定预测结果,尤其是在涉及噪声数据或动态数据的场景中。³ 这种适应性使模型在保持计算效率的同时,仍能输出可靠结果。举例来说,循环学习率调度器(cyclical learning rate schedulers)已被证明在那些要求快速收敛而又不能过度训练的任务中非常有效。⁴ 如下图所示:
图 7.1:机器学习工作流中调度器的规则与收益
关键收益
调度器通过增强收敛效果、优化资源利用以及适配多样化任务,在 ML 工作流的成功中发挥关键作用。具体如下:
改进收敛:
调度器可根据训练进度调整学习率,从而帮助模型更快收敛。例如,指数衰减调度器(exponential decay schedulers)会随着 epoch 的推进逐步降低学习率,使模型在逼近最优解时能够更细致地微调参数。研究表明,这种方式通过减少模型在极小值附近的振荡,加快了神经网络的收敛速度。⁵ 在实践中,余弦退火调度器(cosine annealing scheduler)常被应用于图像识别任务,在不增加额外计算成本的前提下提升模型精度。
资源管理:
高效的调度器能够通过智能调整训练参数来减少计算浪费。例如,线性预热调度器(linear warm-up schedulers)以较低的学习率开始,并在初始若干个 epoch 中逐步提高学习率,从而帮助模型在训练早期避免梯度不稳定。这种做法减少了大规模超参数调优的需求,既节省了计算资源,又维持了训练效率。⁶
通用性:
调度器具有极强的适应能力,使其能够在多种任务与数据结构中发挥价值。例如,在翻译和摘要等 NLP 任务中,调度器可以为预训练 Transformer 模型动态调整学习率,以便将其更好地微调到特定数据集上。像 AdamW 这样的自适应调度器在这些任务中的成功,充分体现了其在处理多样化语言结构并生成高质量输出方面的广泛适用性。⁷
调度器类型概览
调度器在训练过程中通过动态调整模型参数发挥关键作用,为优化学习过程和增强泛化能力提供了结构化手段。它们构成了 ML 工作流中的关键基础设施,尤其是在 NLP 和计算机视觉等复杂任务中,收敛性与效率至关重要。通过系统性地管理学习率及其他优化器参数,调度器使模型能够随着训练进展不断适应,从而实现更快的收敛与更稳健的性能。136
学习率调度器
学习率调度器是深度学习模型训练中的基础组成部分,它会在整个训练过程中系统性地调整学习率,以实现最佳的权重更新效果。
学习率调度器的基本思想是:训练的不同阶段,在调整权重时所需的敏感程度并不相同。在训练早期,较高的学习率通过让模型探索更广泛的参数空间,促进更快收敛。随着训练持续进行,逐步降低学习率则能够实现更精细的更新,尽管这也可能使模型陷入局部极小值或鞍点。⁴
例如,指数衰减调度器会在每个 epoch 按固定比例降低学习率,从而逐步细化模型的权重更新。这种方法已被广泛应用于图像分类等任务,在这类任务中,ResNet 等模型通过渐进式衰减学习率实现了最先进的性能。⁵ 在 NLP 中,循环学习率调度器会在设定区间内振荡学习率,以维持优化动量并跳出次优极小值。这一策略已被证明在文本分类和机器翻译等任务中非常有效,因为对较高学习率的周期性探索有助于增强模型的泛化能力。⁴
学习率调度器的实际实现包括 TensorFlow 的 ExponentialDecay 和 PyTorch 的 StepLR,它们都可以无缝集成进现代训练流水线。
在 ML 中,调度器并不只是"方便使用的功能";它们更像是塑造模型如何学习、如何收敛以及如何适应的精密仪器。无论是微调学习率,还是管理优化器状态,调度器都像动态调节器一样工作,在整个 NLP 工作流中确保稳定性、速度和可扩展性,如下图所示:
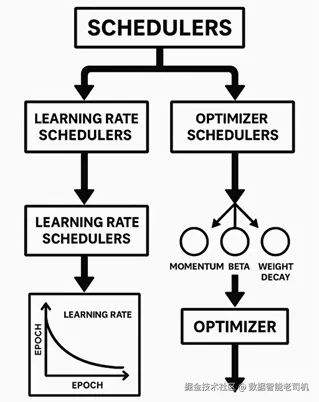
图 7.2:学习率调度器与优化器调度器
优化器调度器
优化器调度器通过修改优化算法中的关键参数(如动量、beta 值或权重衰减)来提升训练效率。这些调整能够确保优化器在训练过程中持续自适应,从而同时提升收敛速度与模型稳定性。
例如,AdamW 调度器将学习率调整与权重衰减正则化结合起来,在保持高效梯度更新的同时抑制过拟合。这种方法在对大语言模型(如 BERT)进行下游 NLP 任务微调时发挥了重要作用,在情感分析、命名实体识别和摘要生成等任务中均取得了优异表现。⁷
另一个典型例子是基于动量的调度器(momentum-based schedulers),它会动态调整随机梯度下降(SGD)等优化器中的动量参数。通过微调动量,这类调度器能够在梯度方差较高的场景中稳定训练,例如强化学习或对抗训练中常见的情形。⁸
像 Hugging Face Diffusers 这样的工具已集成优化器调度器,可简化训练工作流在不同模型架构和数据集之间的适配过程。例如,Hugging Face 的训练参数允许用户同时设置权重衰减、beta 值和学习率调整,从而提供统一的优化框架。
通过结合学习率调度器与优化器调度器的原理,现代 ML 流水线获得了前所未有的灵活性,使实践者能够高效而有效地处理各种任务。
离散调度器与连续调度器
调度器在训练与推理过程中对模型参数的调整都至关重要,它会影响收敛性、资源利用率以及整体性能。本节将调度器划分为离散型与连续型两类,并讨论它们的应用及其对不同 NLP 与 ML 任务的影响。这两类方法体现了参数调优中的不同思想,其适用性通常取决于任务复杂度与资源约束。79
调度器的差异不仅体现在它们如何调整参数,也体现在它们影响学习过程的时间模式上。离散方法与连续方法之间的对比,可以通过它们的更新动态来可视化:每种方法都以不同方式控制训练过程中参数变化的节奏与平滑程度,如图 7.3 所示:

图 7.3:离散调度器与连续调度器的对比
调度器并不仅仅是在调整参数;它们实际上是在编排学习本身。通过在离散与连续方法之间切换,调度器决定了模型优化的节奏与响应性,从而定义了模型是以更快还是更平滑的方式逼近有效认知。
图 7.3 以并列示意图的方式,对比了离散调度器基于区间的刚性更新方式与连续调度方法平滑、响应式的演进过程,突出展示了二者在训练期间管理学习率动态方面各自的作用。
离散调度器
离散调度器会在设定的时间间隔内,以离散步进的方式修改参数。由于其简单性和可预测性,这类调度器被广泛应用于通用训练场景。借助清晰明确的更新计划,它们为训练过程提供了稳定性,因此特别适合结构化任务以及拥有充足计算资源的大规模数据集。其固定幅度的调整有助于避免过早收敛,并使模型能够逐步微调参数,通常能够在探索(exploration)与利用(exploitation)之间取得平衡。
下面列出了离散调度器的核心运行特征:
按固定间隔或 epoch 修改参数:
离散调度器采取逐步更新的方式,在训练中的特定时间点修改参数。例如,某个学习率计划可能会每 10 个 epoch 将学习率降低一次。该方法可以防止模型过早收敛,并支持对权重进行渐进式细化。典型例子是阶梯衰减调度器(step-decay scheduler),它会在固定数量的 epoch 之后,将学习率按固定比例降低。¹
常用于 step decay 和 multi-step 学习率计划:
Step decay 调度器在那些需要缓慢收敛的任务中非常有效,例如大规模数据集上的图像分类或语言建模。Multi-step 计划则在此基础上扩展,在多个预定义时间点调整参数,从而为模型微调提供更高灵活性。
示例:每 10 个 epoch 将学习率减半
这是一种常见的调度技术,即以固定时间间隔按固定比例降低学习率,从而帮助模型随着训练推进逐步稳定优化过程。以下是该策略的 Python 实现:
ini
from tensorflow.keras.callbacks import LearningRateScheduler
def step_decay(epoch, lr):
drop_rate = 0.5
drop_interval = 10
if epoch % drop_interval == 0 and epoch > 0:
return lr * drop_rate
return lr
lr_scheduler = LearningRateScheduler(step_decay)
model.fit(x_train, y_train, callbacks=[lr_scheduler])在这个示例中,LearningRateScheduler 回调用 step_decay 函数来调整学习率。该函数会在每经过 10 个 epoch(drop_interval = 10)之后,将学习率减半(drop_rate = 0.5)。这种方法确保学习率在训练初期保持较高水平,使模型能够有效探索参数空间;而随着模型逐步收敛,学习率会不断降低,从而支持更精细的权重更新。这种方法尤其适用于图像分类或语言建模等任务,因为大规模数据集通常会从这种"阶梯式细化"策略中受益。¹
连续调度器
连续调度器提供了一种更精细、更灵活的参数更新方式,它会在每一次迭代中调整参数。与只在特定时间点发生变化的离散调度器不同,连续调度器能够在训练过程中实时动态响应。这种灵活性带来了更平滑的学习率过渡,有助于避免过冲(overshooting)或突变,从而降低训练过程失稳的风险。连续调度器尤其适用于那些需要精确控制的场景,例如小数据集微调,或训练面对敏感数据分布的模型。
下面概括了连续调度器的主要特征,以及它与离散调度器的区别:
在每次迭代时调整参数,以实现更平滑的过渡:
不同于离散调度器,连续调度器会贯穿整个训练过程动态调整参数,使模型能够响应数据中的细微模式。这种实时自适应能力可减少过冲或调整不足的问题,从而确保更好的收敛效果。⁴
适用于需要精确控制训练动态的任务:
涉及敏感数据集的任务,如低资源语言任务或专业医疗领域任务,往往更适合使用连续调度器。这类调度器能够对学习率及其他设置提供细粒度控制,从而在小型或不断变化的数据集上提升训练稳定性并减少误差。
示例:余弦退火与指数衰减
余弦退火(cosine annealing)是一种通过余弦曲线逐步降低学习率的调度方式。相比之下,指数衰减(exponential decay)则是在每一个时间步将学习率按因子 2 进行下降。这些方法对于需要平滑过渡与稳定收敛的任务都很有帮助。
下面的代码展示了在 PyTorch 中实现余弦退火调度器的方法,说明连续式学习率调整如何促进平滑收敛与稳定优化:
scss
import torch.optim.lr_scheduler as lr_scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)
for epoch in range(100):
train(model, train_loader, optimizer)
scheduler.step()该示例使用 PyTorch 的 CosineAnnealingLR 调度器来调整学习率。参数 T_max 定义了余弦曲线一个周期的长度(这里为 50 个 epoch)。学习率会以类似"冷却过程"的方式平滑下降。这种渐进式下降有助于模型在收敛过程中更专注于参数微调,避免会打断学习过程的突发性变化。像余弦退火这样的连续调度器非常适合迁移学习或低资源数据集场景,因为精细调整往往能显著提升模型表现。⁷
实践对比
调度器可针对不同任务和资源限制提供不同优势,具体取决于所选择的方法。下表展示了离散调度器与连续调度器的关键差异:
| 特性 | 离散调度器 | 连续调度器 |
|---|---|---|
| 调整频率 | 固定间隔 | 每次迭代 |
| 复杂度 | 更易实现 | 需要更多计算 |
| 适用场景 | 大数据集上的稳定任务 | 动态或敏感任务 |
表 7.1:不同调度器类型的关键差异
选择合适的调度器,取决于任务的具体需求、数据集特征以及可用计算资源。离散调度器实现简单,在大型数据集和稳定环境中表现良好,其逐步更新机制能够确保一致性与可靠性。相比之下,连续调度器提供了更细腻的控制方式,通过更平滑的过渡与自适应调整,成为动态或敏感训练场景中的关键工具。理解这两类调度器之间的差异,有助于实践者更精准地微调训练工作流,从而在各种 NLP 与 ML 任务中提升性能与效率。通过合理组合这些策略,模型便能够发挥其全部潜力,构建更稳健、更可扩展的解决方案。
在训练中使用调度器
高质量的 ML 模型训练依赖于对学习率的精细管理,因为学习率决定了在梯度下降过程中权重如何更新。调度器通过在训练期间动态调整学习率,在实现高效收敛的同时防止过拟合与欠拟合,发挥着关键作用。通过对这一关键参数的精细控制,调度器使模型能够在多种 NLP 任务中达到最优性能。本节将讨论在训练期间实现调度器的方法,并结合理论分析与实际示例,说明如何在不同场景中最大化其收益。¹
实现策略
调度器可以集成到训练工作流中,以动态管理学习率并提升模型收敛效果。根据任务和数据集的不同,可以采用多种策略来适应训练动态的复杂性。本节将介绍若干关键策略,并展示如何借助 PyTorch 等主流库进行实现。通过使用调度器来调整学习率,模型能够更精确地控制权重更新,在优化过程中获得更高稳定性,并实现跨任务的更好泛化。
Step decay 调度器
Step decay 调度器会在预定义的时间间隔内按固定比例降低学习率。对于那些在训练初期需要较大学习率以充分探索参数空间、而在后期又需要较小学习率进行精细化调整的任务而言,这种策略尤其有助于稳定训练过程。
下面的代码展示了如何在 PyTorch 中实现一个 step decay 调度器,通过在固定间隔降低学习率,在训练早期平衡探索、在后期实现微调:
scss
from torch.optim.lr_scheduler import StepLR
scheduler = StepLR(optimizer, step_size=10, gamma=0.1)
for epoch in range(epochs):
train(...)
scheduler.step()该示例演示了如何使用 PyTorch 实现 step-decay 调度器。StepLR 调度器会在每经过 step_size 个 epoch(此处为 10)之后,将学习率按 gamma(此处为 0.1)的比例缩小。scheduler.step() 函数会在每个 epoch 结束时调用,以应用预定的学习率调整。通过逐步降低学习率,这种方法确保模型在训练早期进行较大幅度更新以充分探索参数空间,而在后期则通过更小幅度更新来精细优化参数,从而提升整体收敛质量。
余弦退火调度器
余弦退火调度器通过遵循余弦曲线来平滑调整学习率。这种方法可避免学习率发生突变,特别适用于那些需要渐进式细化的任务,因为学习率的突然变化可能会打断训练过程。
下面的代码演示了如何使用余弦退火调度器,使学习率按余弦函数逐步下降,从而促进平滑收敛并增强训练稳定性:
scss
from torch.optim.lr_scheduler import CosineAnnealingLR
scheduler = CosineAnnealingLR(optimizer, T_max=50)
for epoch in range(epochs):
train(...)
scheduler.step()在这段代码中,CosineAnnealingLR 调度器会在由 T_max 定义的周期内平滑降低学习率,其中 T_max 表示最大迭代次数(此处为 50 个 epoch)。该调度器沿余弦曲线下降学习率,模拟一种渐进式"冷却"过程。这种平滑过渡能最大限度减少权重更新中的突发性干扰,从而确保训练稳定性。随着学习率按余弦曲线逐渐降低,模型可以在训练后期更精准地微调参数。对于小数据集微调或需要严格控制过拟合的任务而言,这种方法尤其有价值。
在推理中使用调度器
尽管调度器通常与训练阶段联系更紧密,但它们在推理阶段同样发挥着关键作用,尤其是在基于扩散器(diffuser-based)框架的高级模型中。推理调度器会实时调整参数,以维持稳定性、提升预测精度并优化资源使用。通过对噪声水平和采样方法等因素进行精细管理,调度器能够提升模型输出质量,确保即便在具有挑战性或高噪声的环境中,也能获得可靠且高质量的预测。本节将探讨调度器在推理期间的主要功能,重点关注噪声调度与样本更新,并通过详细示例说明它们对模型性能的影响。
噪声调度
在扩散模型中,噪声调度在推理过程中具有核心作用。这类模型需要反复将随机噪声转化为准确预测,因此必须精确控制噪声水平。噪声调度会在推理期间逐步降低噪声,从而帮助稳定模型输出并避免不可预测的结果。这种方法对于图像生成等应用尤为关键,因为输出必须清晰且一致;在 text-to-text generation 等 NLP 任务中,语义准确性也同样依赖这种机制。
噪声调度通常遵循预先设定的计划,例如线性计划或余弦退火计划,以逐步调整噪声水平。比如,线性噪声计划会在每一步按固定幅度降低噪声,从而形成平滑、可预测的精炼过程。相比之下,余弦退火提供了更具适应性的方式,使模型能够在推理不同阶段以不同速率降低噪声。
示例:在扩散模型中管理噪声
在这个示例中,噪声会在 100 个步骤中逐步下降。这样缓慢的降低过程能确保模型从初始高噪声状态平滑过渡到精炼后的输出状态。
下面的代码给出了一个线性噪声计划的简单实现,展示如何在多个推理步骤中逐步降低噪声水平,以确保平滑且稳定的模型精炼过程:
python
import numpy as np
def linear_noise_schedule(t, max_noise=1.0, min_noise=0.01):
return max_noise - (max_noise - min_noise) * t
# Simulating noise levels across 100 inference steps
steps = 100
noise_levels = [linear_noise_schedule(t/steps) for t in range(steps)]
print("Noise levels:", noise_levels)这类调度对于某些任务至关重要:若噪声降低得过于激进,可能会导致预测不完整或不准确;若噪声降低过于保守,则可能会把计算资源浪费在没有必要的额外精炼上。⁵
样本更新
调度器在推理阶段还会主动管理样本更新,使模型能够将计算资源优先分配给高价值预测。通过优先处理那些对结果影响更大的样本,同时减少在高噪声或低价值样本上的计算投入,调度器能在不损害输出质量的前提下提升推理效率。这种机制在资源受限环境或要求快速可靠预测的实时应用中尤为有用。
动态样本更新通常通过重要性采样(importance sampling)等技术实现,这些技术会给更可能带来有意义预测的样本赋予更高权重。例如,在文本生成任务中,调度器可以识别那些具有高不确定性或低概率的 token,并在后续迭代中重点优化它们。这样一来,模型的注意力就能集中在最关键的区域,从而提升整体输出的一致性与相关性。
示例:动态样本优先级排序
在这个示例中,token 会根据其重要性分数进行排序:
ini
import torch
# Simulating importance sampling for text tokens
tokens = ["The", "model", "is", "generating", "outputs"]
importance_scores = torch.tensor([0.2, 0.4, 0.1, 0.7, 0.6]) # Simulated importance values
# Prioritize tokens with higher importance scores
priority_indices = torch.argsort(importance_scores, descending=True)
prioritized_tokens = [tokens[i] for i in priority_indices]
print("Prioritized tokens:", prioritized_tokens)调度器会将计算资源优先用于精炼那些高优先级 token,例如 generating 和 outputs,因为它们在句子中承载了更重要的语义信息。这种方法不仅提高了效率,也增强了输出的语义深度,使结果更具意义、也更符合上下文。¹⁰
进一步深入探索
推理阶段的调度器并不局限于噪声管理和样本更新。它们在资源优化与自适应推理策略方面同样扮演重要角色。例如,渐进式采样方法(progressive sampling methods)会根据模型复杂度动态调整推理步数,在保持输出质量的同时显著降低计算成本。此外,像随机调度(stochastic scheduling)这样的高级技术,会在推理过程中引入受控随机性,从而为文本或图像生成等创造性任务带来更高的输出多样性。
通过理解并使用这些高级调度技术,实践者可以根据具体需求定制推理工作流,确保模型在广泛的 NLP 和 ML 任务中都能输出稳健、高效且高质量的结果。
调度器实际应用案例研究
调度器在解决真实世界 ML 挑战时具有变革性作用,它连接了理论进展与实践结果。通过动态管理学习率和噪声水平等参数,调度器能够改善收敛过程、减少过拟合,并提升模型输出质量。本节将通过详细案例和练习,展示调度器在解决特定 NLP 问题时的多样性,以及其在定制化与创新方面的潜力。
案例研究 1:文本摘要
问题:
在大规模数据集上训练文本摘要模型时,尤其是在收敛方面面临挑战。即便拥有充足的计算资源,模型仍难以在欠拟合与过拟合之间取得平衡,最终导致 BLEU(Bilingual Evaluation Understudy)分数表现不佳。
解决方案:
引入余弦退火调度器后,模型的收敛速度提升了 15%,训练动态也更为稳定。通过按照余弦模式逐步降低学习率,该调度器使模型能够在训练后期更有效地微调权重,从而在保持较高 BLEU 分数的同时提升摘要质量。
下面的代码展示了在文本摘要模型中实现余弦退火调度器的方法,说明了渐进式学习率调整如何改善训练过程中的收敛与稳定性:
scss
import torch
from torch.optim import Adam
from torch.optim.lr_scheduler import CosineAnnealingLR
# Define model, optimizer, and data loader
model = SummarizationModel()
optimizer = Adam(model.parameters(), lr=0.01)
scheduler = CosineAnnealingLR(optimizer, T_max=50)
# Training loop with scheduler
for epoch in range(100):
for batch in data_loader:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
scheduler.step()
# Evaluate model performance
bleu_score = evaluate_model(model, test_data)
print(f"BLEU Score: {bleu_score:.2f}")结果:
该调度器使权重调整更加平滑,减少了可能扰乱训练过程的学习率突变。最终,该方法在将 BLEU 分数维持在 30 以上的同时,实现了 15% 更快的收敛速度,证明了它在处理大规模数据集时的有效性。¹¹
案例研究 2:情感分析
问题:
在带有噪声且类别不平衡的数据上微调情感分析模型时,容易出现过拟合和预测不一致的问题。传统训练方法由于学习率波动,无法很好地泛化到未见数据。
解决方案:
通过在固定时间间隔降低学习率,step decay 调度器有效缓解了过拟合问题,促进了更稳定、更渐进的优化过程。该方法使模型准确率提高了 8%,同时保持了在不同数据样本上的鲁棒性。
下面的实现展示了如何将 step decay 调度器应用于情感分析模型,通过在固定间隔系统性降低学习率来提升泛化能力与准确率:
ini
from torch.optim import SGD
from torch.optim.lr_scheduler import StepLR
# Define model and optimizer
model = SentimentAnalysisModel()
optimizer = SGD(model.parameters(), lr=0.1)
scheduler = StepLR(optimizer, step_size=10, gamma=0.5)
# Training loop with scheduler
for epoch in range(50):
train_loss = 0.0
for batch in data_loader:
optimizer.zero_grad()
loss = model(batch)
loss.backward()
optimizer.step()
train_loss += loss.item()
scheduler.step()
# Evaluate model
accuracy = evaluate_model(model, test_data)
print(f"Model Accuracy: {accuracy:.2f}")结果:
通过每 10 个 epoch 系统性降低一次学习率,step-decay 调度器有效减轻了噪声与类别不平衡带来的影响,从而持续改善了预测准确率。¹
结论
本章探讨了调度器在 ML 模型训练与推理阶段中的关键作用。通过分析离散与连续两类调度策略、实际实现方式以及真实案例研究,本章展示了这些机制如何改善收敛、优化资源分配并提升整体模型性能。读者由此获得了更细致的理解:如何根据具体任务选择并定制调度器,以在各种 NLP 工作流中实现鲁棒性、适应性与效率。文中提供的系统化见解和示例,也为将高级调度技术集成到复杂 ML 流水线中奠定了基础。
在进入第 8 章"高级推理技术(Advanced Inference Techniques)"之后,关注点将从训练优化转向推理阶段的性能增强。Hugging Face Diffusers 库中的高级推理技术,包括主动采样(active sampling)、多阶段推理(multi-stage inference)以及提示工程(prompt engineering),为提升输出质量与增强可扩展性提供了新的方法。通过将调度器的核心原理与这些创新策略结合起来,下一章将帮助读者掌握在复杂环境中充分释放 NLP 应用潜力所需的关键工具。