目录
一、注意力机制的由来以及解决的问题
- 早期在解决机器翻译这一类seq2seq问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题:
- 问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。
- 问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。
二、什么是注意力机制
- "注意力机制"实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。
三、自注意力机制
- Self Attention是Google在transformer模型中提出的,上面介绍的都是一般情况下Attention发生在Target元素Query和Source中所有元素之间。而Self Attention,指的是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。当然,具体的计算过程仍然是一样的,只是计算对象发生了变化而已。
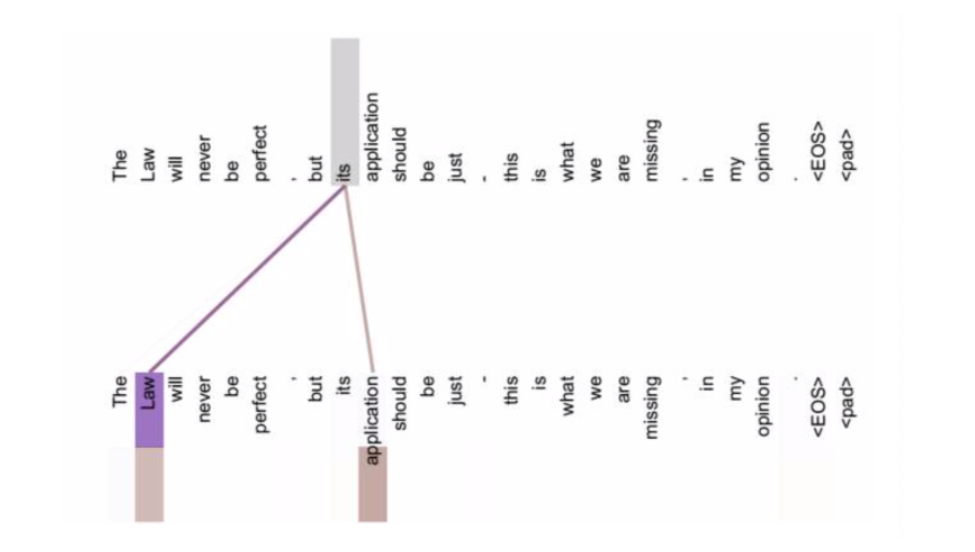
- 上面内容也有说到,一般情况下Attention本质上是Target和Source之间的一种单词对齐机制。那么如果是Self Attention机制,到底学的是哪些规律或者抽取了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?仍然以机器翻译为例来说明, 如下图所示:
- Attention的发展主要经历了两个阶段:
从上图中可以看到, self Attention可以远距离的捕捉到语义层面的特征(its的指代对象是Law).
应用传统的RNN, LSTM, 在获取长距离语义特征和结构特征的时候, 需要按照序列顺序依次计算, 距离越远的联系信息的损耗越大, 有效提取和捕获的可能性越小.
但是应用self-attention时, 计算过程中会直接将句子中任意两个token的联系通过一个计算步骤直接联系起来
四、注意力机制规则
-
它需要三个指定的输入Q(query), K(key), V(value), 然后通过计算公式得到注意力的结果, 这个结果代表query在key和value作用下的注意力表示. 当输入的Q=K=V时, 称作自注意力计算规则.
-
常见的注意力计算规则:
- 将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法.
- 将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法.
- 将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法.
计算公式:
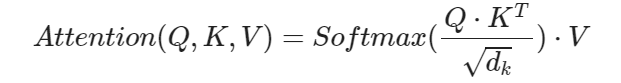
五、什么是深度学习注意力机制
- 注意力机制是注意力计算规则能够应用的深度学习网络的载体, 同时包括一些必要的全连接层以及相关张量处理, 使其与应用网络融为一体. 使自注意力计算规则的注意力机制称为自注意力机制.
六、注意力机制的作用
-
在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
- 在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).
七、注意力机制实现步骤
-
注意力机制实现步骤:
- 第一步: 根据注意力计算规则, 对Q,K,V进行相应的计算.
- 第二步: 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.
- 第三步: 最后为了使整个attention机制按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换, 得到最终对Q的注意力表示.
代码如下:
python
# 任务描述:
# 有QKV:v是内容比如32个单词,每个单词64个特征,k是32个单词的索引,q是查询张量
# 我们的任务:输入查询张量q,通过注意力机制来计算如下信息:
# 1、查询张量q的注意力权重分布:查询张量q和其他32个单词相关性(相识度)
# 2、查询张量q的结果表示:有一个普通的q升级成一个更强大q;用q和v做bmm运算
# 3 注意:查询张量q查询的目标是谁,就是谁的查询张量。
# eg:比如查询张量q是来查询单词"我",则q就是我的查询张量
import torch
import torch.nn as nn
import torch.nn.functional as F
# MyAtt类实现思路分析
# 1 init函数 (self, query_size, key_size, value_size1, value_size2, output_size)
# 准备2个线性层 注意力权重分布self.attn 注意力结果表示按照指定维度进行输出层 self.attn_combine
# 2 forward(self, Q, K, V):
# 求查询张量q的注意力权重分布, attn_weights[1,32]
# 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,64]
# q 与 attn_applied 融合,再按照指定维度输出 output[1,1,32]
# 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,32]
class MyAtt(nn.Module):
# 32 32 32 64 32
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super(MyAtt, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 线性层1 注意力权重分布
self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1)
# 线性层2 注意力结果表示按照指定维度输出层 self.attn_combine
self.attn_combine = nn.Linear(self.query_size+self.value_size2, output_size)
def forward(self, Q, K, V):
# 1 求查询张量q的注意力权重分布, attn_weights[1,32]
# [1,1,32],[1,1,32]--> [1,32],[1,32]->[1,64]
# [1,64] --> [1,32]
# tmp1 = torch.cat( (Q[0], K[0]), dim=1)
# tmp2 = self.attn(tmp1)
# tmp3 = F.softmax(tmp2, dim=1)
attn_weights = F.softmax( self.attn(torch.cat( (Q[0], K[0]), dim=-1)), dim=-1)
# 2 求查询张量q的结果表示 bmm运算, attn_applied[1,1,64]
# [1,1,32] * [1,32,64] ---> [1,1,64]
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)
# 3 q 与 attn_applied 融合,再按照指定维度输出 output[1,1,64]
# 3-1 q与结果表示拼接 [1,32],[1,64] ---> [1,96]
output = torch.cat((Q[0], attn_applied[0]), dim=-1)
# 3-2 shape [1,96] ---> [1,32]
output = self.attn_combine(output).unsqueeze(0)
# 4 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,32]
return output, attn_weights调用:
python
if __name__ == '__main__':
query_size = 32
key_size = 32
value_size1 = 32 # 32个单词
value_size2 = 64 # 64个特征
output_size = 32
Q = torch.randn(1, 1, 32)
K = torch.randn(1, 1, 32)
V = torch.randn(1, 32, 64)
# V = torch.randn(1, value_size1, value_size2)
# 1 实例化注意力类 对象
myattobj = MyAtt(query_size, key_size, value_size1, value_size2, output_size)
# 2 把QKV数据扔给注意机制,求查询张量q的注意力结果表示、注意力权重分布
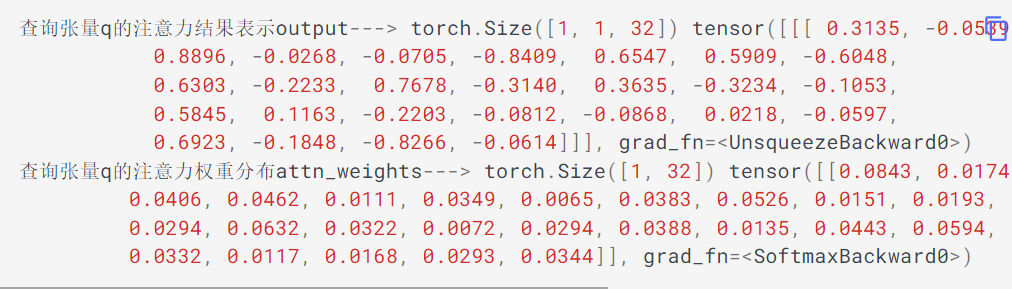
output, attn_weights = myattobj(Q, K, V)
print('查询张量q的注意力结果表示output--->', output.shape, output)
print('查询张量q的注意力权重分布attn_weights--->', attn_weights.shape, attn_weights)输出效果:
以上主要掌握注意力实现过程,在后续案例中不断加深理解。