我们经常面临这样的需求:我不想知道每个员工的具体信息,而是想知道"每个部门总共有多少人"。这种情况下,你需要统计的是数据摘要 ,而不是数据本身 。实现这一目标的核心武器就是 聚合函数 与 分组。
文章目录
- [一、 聚合函数:单点汇总](#一、 聚合函数:单点汇总)
-
- [1.1 聚合函数](#1.1 聚合函数)
- [1.2 总数统计(count)](#1.2 总数统计(count))
- [1.2 最大、最小、平均、汇总值统计(max/min/avg/sum)](#1.2 最大、最小、平均、汇总值统计(max/min/avg/sum))
- [1.3 对唯一值进行聚合 (DISTINCT)](#1.3 对唯一值进行聚合 (DISTINCT))
- [二、 分组查询](#二、 分组查询)
-
- [2.1 创建分组](#2.1 创建分组)
- [2.2 多级分组](#2.2 多级分组)
- [2.3 过滤分组 (HAVING)](#2.3 过滤分组 (HAVING))
- [三、 SQL 执行顺序总结](#三、 SQL 执行顺序总结)
一、 聚合函数:单点汇总
聚合函数是对一组值执行计算并返回单一值的函数。
1.1 聚合函数
MySQL中常用的聚合函数如下:
| 函数 | 描述 |
|---|---|
COUNT(*)/count(column) |
返回行数/非空行数 |
SUM(column) |
返回总和 |
MAX(column) |
返回最大值 |
MIN(column) |
返回最小值 |
AVG(column) |
返回平均值 |
1.2 总数统计(count)
COUNT() 函数是进行数据审计和规模统计最常用的工具,虽然 COUNT(*) 和 COUNT(column) 看起来相似,但它们在统计逻辑 和性能上有着本质的区别。
| 用法 | 统计逻辑 | 是否过滤 NULL | 性能表现 |
|---|---|---|---|
COUNT(*) |
统计结果集中的总行数,所该行会被计入。 | 否(包含 NULL) | 统计总行数最快的方式。 |
COUNT(column) |
统计指定列中非 NULL 值的行数。 | 是(过滤 NULL) | 略慢,因为需要检查每一行的该列是否为 NULL。 |
案例:统计titles表记录总数及to_date列非空总数
sql
SELECT
count(*) 表的总行数,
count(to_date) to_date列非空行数
FROM titles;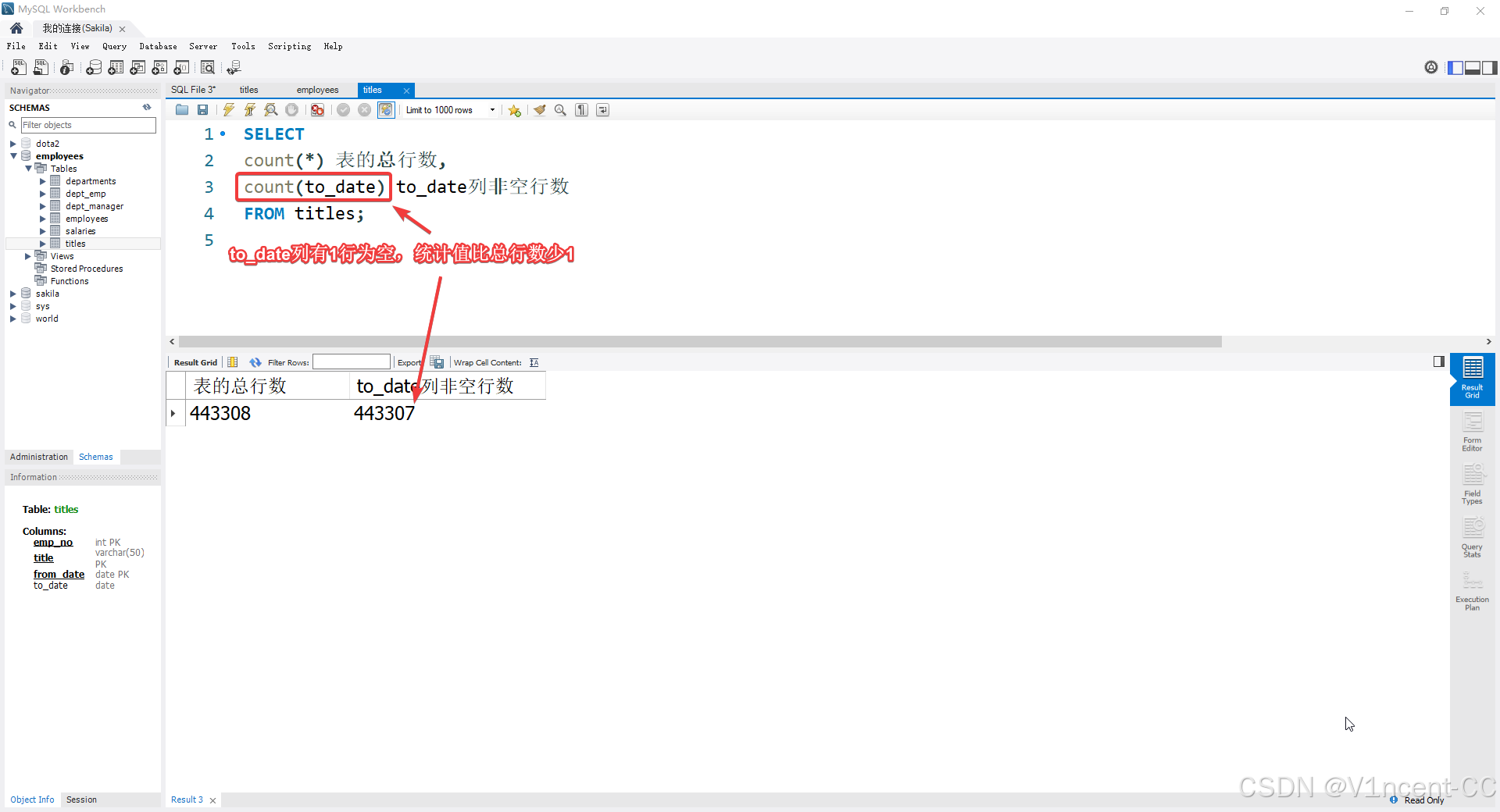
1.2 最大、最小、平均、汇总值统计(max/min/avg/sum)
这四个函数分别返回分组中的最大、最小、平均、汇总值。
我们以工资表salaries举例:
sql
SELECT
MAX(salary) 最高工资,
MIN(salary) 最最低工资,
ROUND(AVG(salary), 2) 平均工资,
SUM(salary) 工资总和
FROM salaries;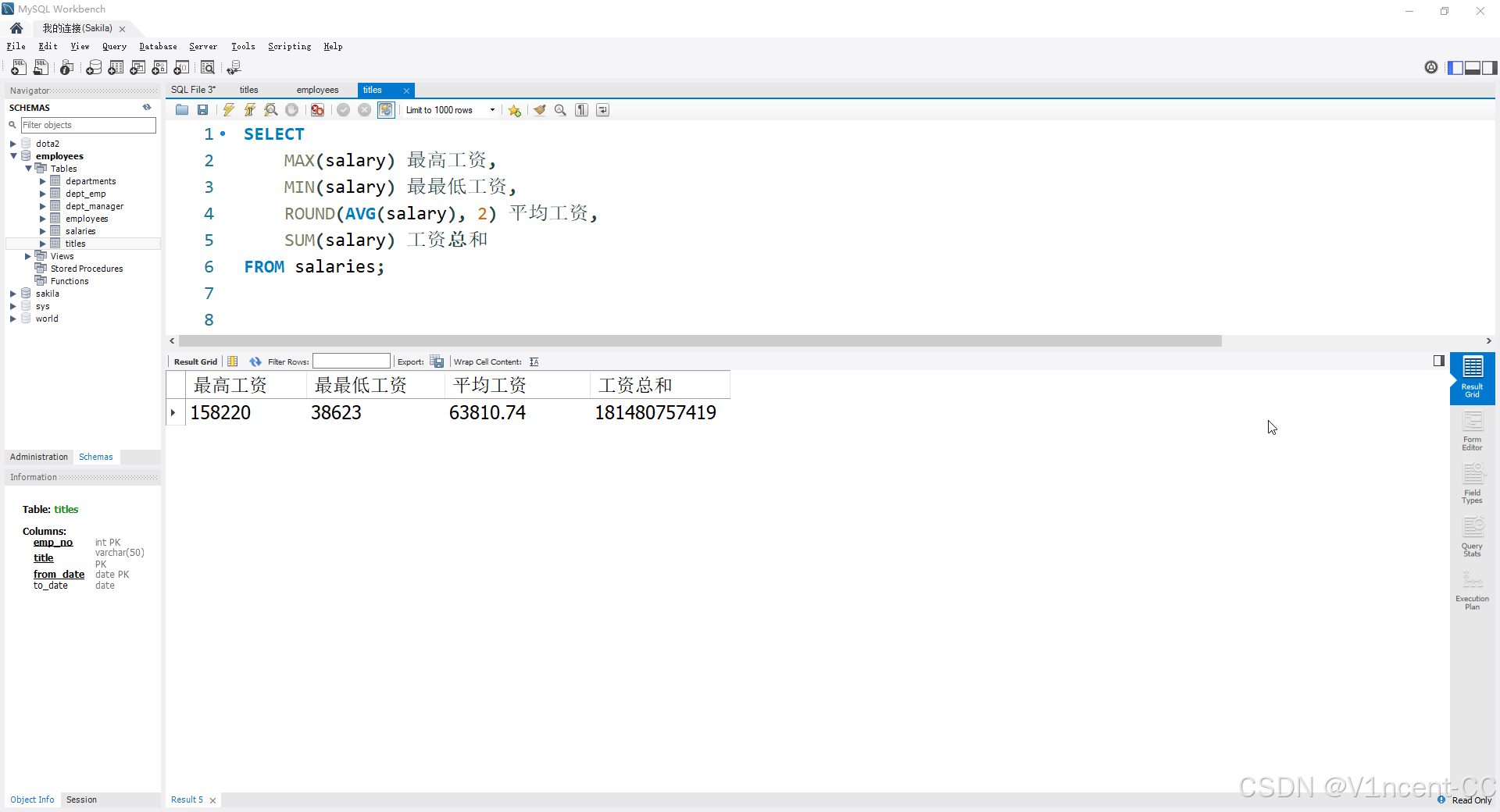
1.3 对唯一值进行聚合 (DISTINCT)
titles表中记录了每个员工的岗位,如果你想知道公司里有多少个不同 的岗位,而不是总共有多少条记录,需要配合 DISTINCT:
sql
select
count(*) 记录总数,
count(distinct title) 不同岗位数
from titles;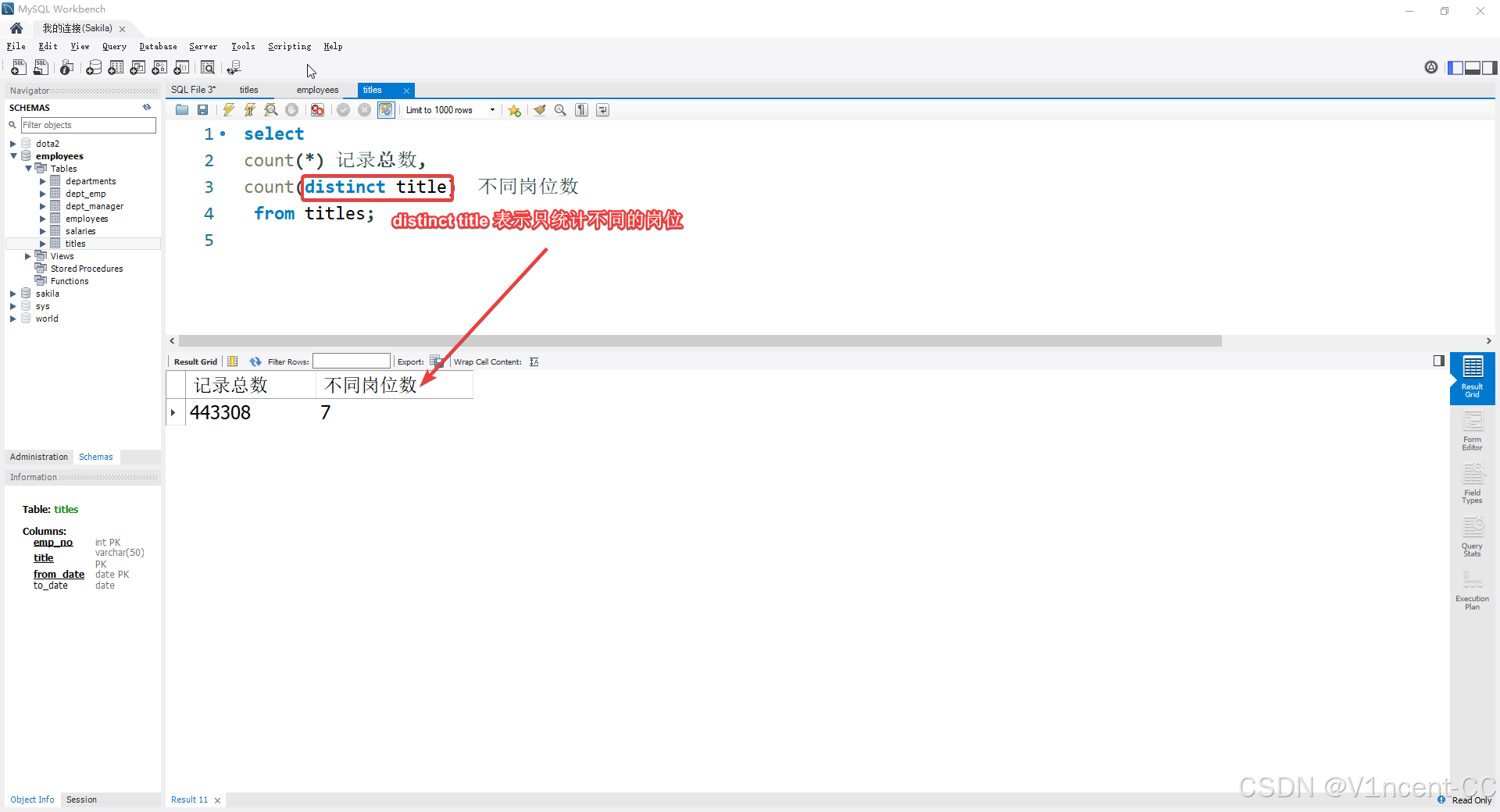
二、 分组查询
聚合函数默认是将全表看作一个大组,如果你想查看"每个部门"的平均薪资,或者"每个职级"的人数,就必须引入 GROUP BY 子句。
2.1 创建分组
GROUP BY 子句用于将数据划分为逻辑集合,以便对每个组执行单独的聚合计算。
案例:统计每个部门员工数
sql
SELECT dept_no 部门编号,
COUNT(emp_no) 员工数
FROM dept_emp
GROUP BY dept_no;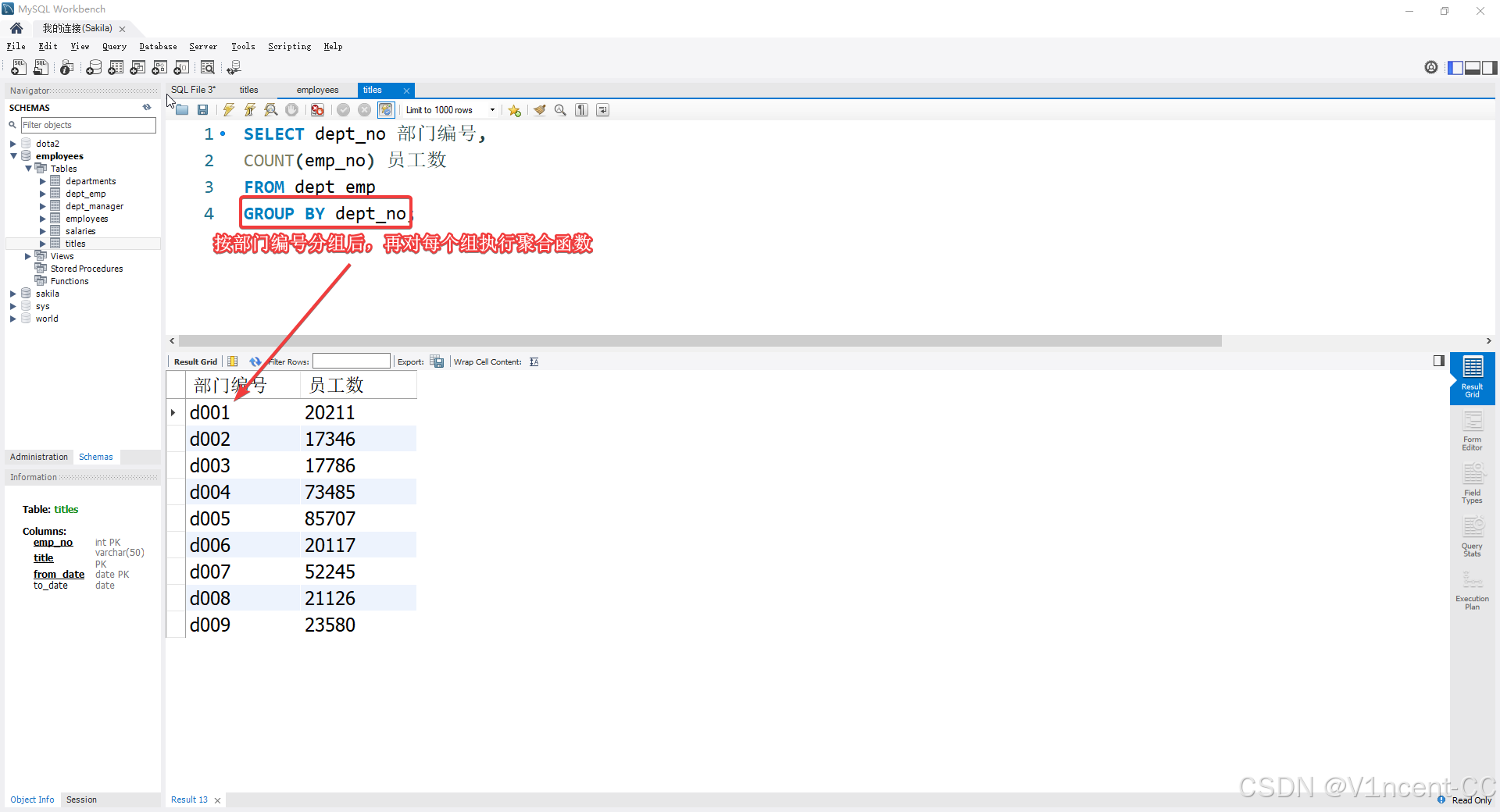
注意:除了聚合函数外,
SELECT中的每一列都必须 出现在GROUP BY子句中(由 only_full_group_by参数控制)。
2.2 多级分组
分组可以多次叠加,在group by 子句中用逗号分隔分组列。
按部门分组后,每个部门内再按性别分组 GROUP BY dept_no, gender。
sql
SELECT dept_no 部门编号,
gender 性别,
COUNT(e.emp_no) 员工数
FROM dept_emp d
JOIN employees e ON e.emp_no=d.emp_no
GROUP BY dept_no, gender
ORDER BY dept_no;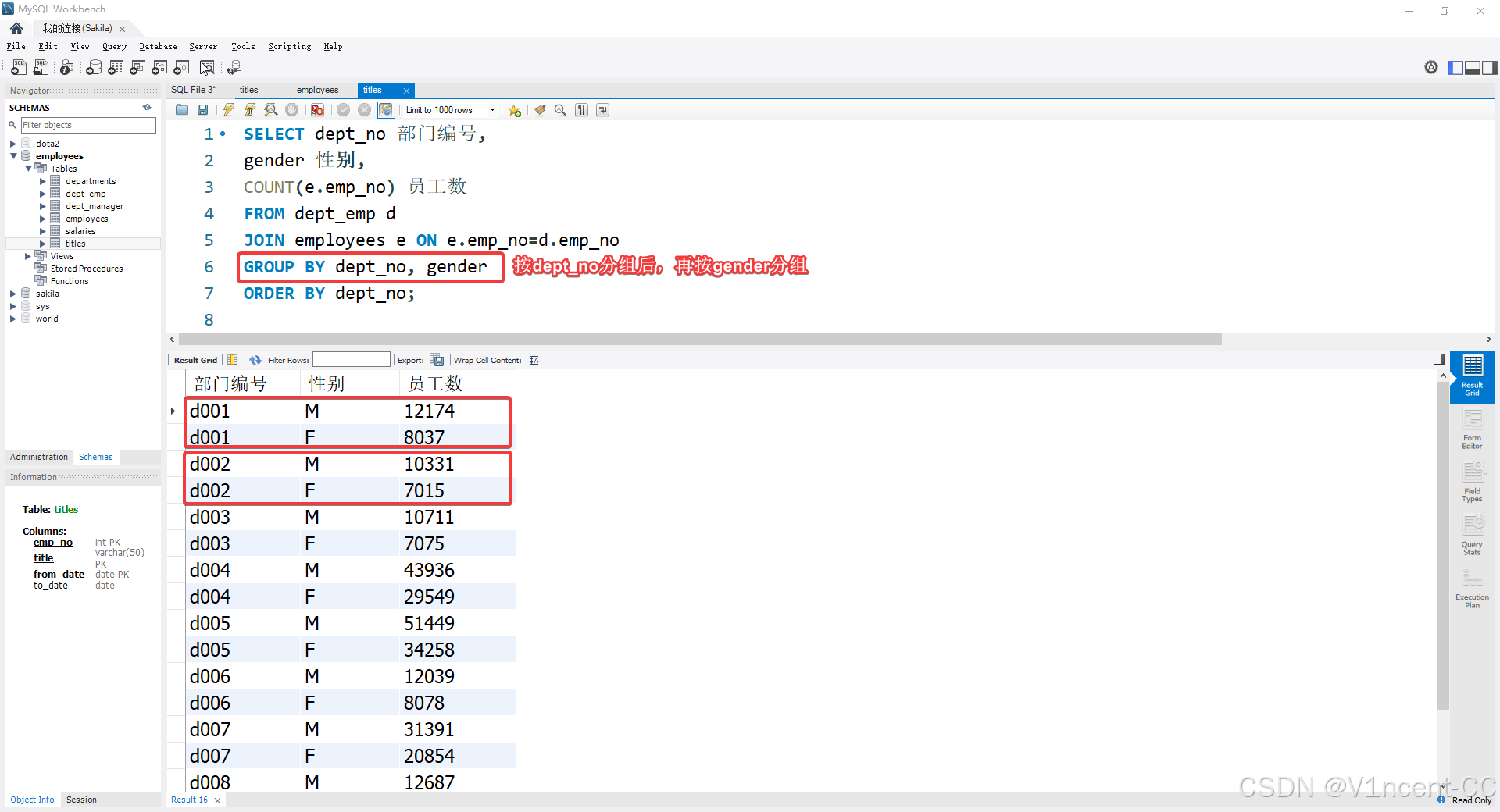
2.3 过滤分组 (HAVING)
这是比较容易混淆的地方:WHERE 过滤的是行,而 HAVING 过滤的是组。
WHERE:在数据分组前进行过滤,被排除的行不参与分组计算。HAVING:在数据分组后进行过滤,基于聚合后的结果筛选组。
案例:找出部门号大于d005,员工人数超过 20,000 的部门编号
sql
SELECT dept_no 部门编号,
COUNT(emp_no) 员工总数
FROM dept_emp
WHERE dept_no >='d005'
GROUP BY dept_no
HAVING COUNT(emp_no) > 20000;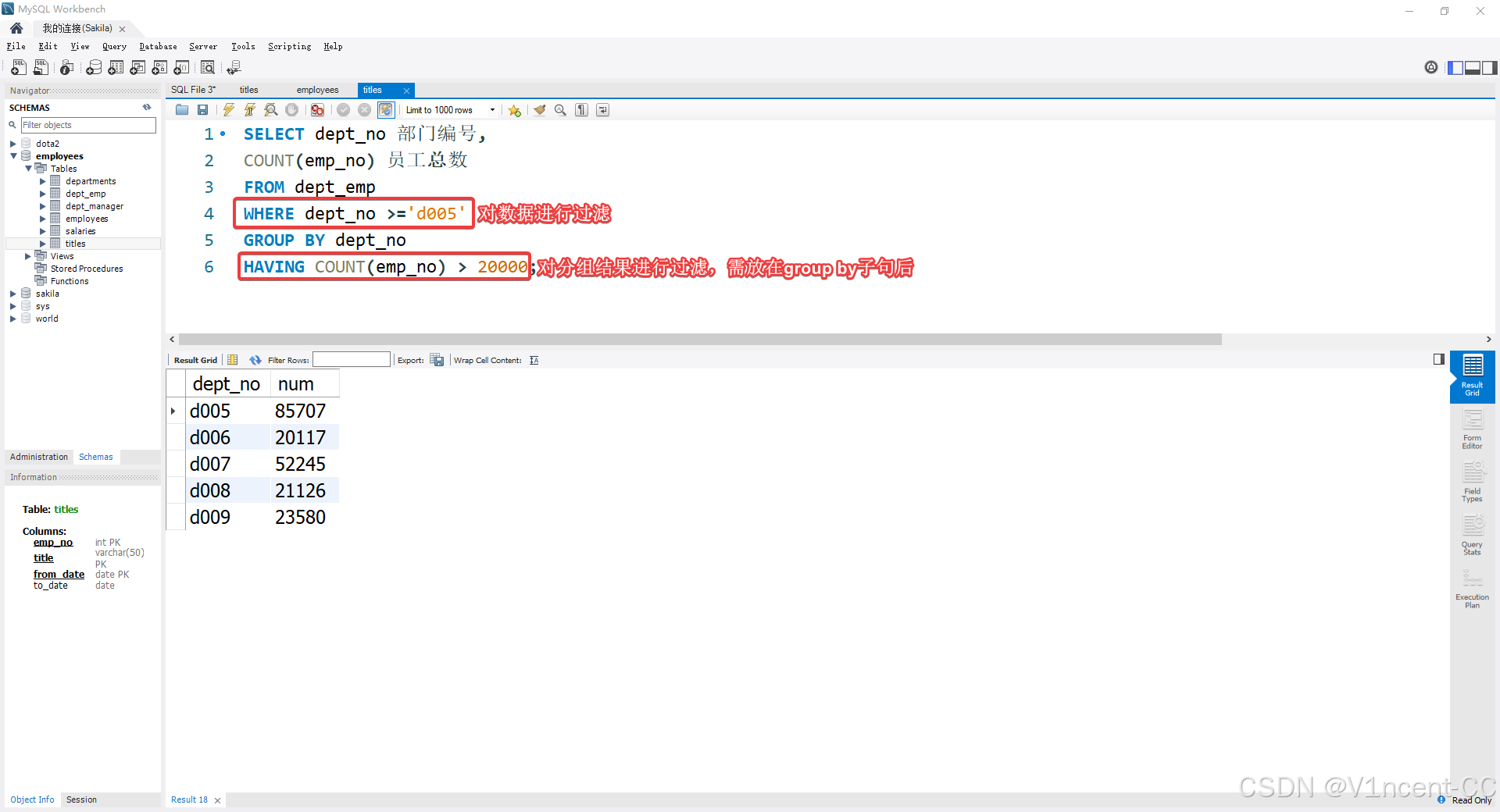
三、 SQL 执行顺序总结
聚合与分组查询的本质,是数据经过层层筛选、拆解再重新组合的过程。
以下是 MySQL 执行一条完整 SQL 的标准路径:
| 执行步骤 | 子句 | 逻辑行为 | 示例 |
|---|---|---|---|
| 1 | FROM |
锁定目标表(或多表联查) | 确定要查的表 salaries 。 |
| 2 | WHERE |
行级过滤 | 排除已经离职的员工(to_date < NOW()),这里不可以用别名 |
| 3 | GROUP BY |
数据分组 | 把剩下的员工按 dept_no(部门)拨到不同的"组"里。 |
| 4 | SELECT |
提取列与聚合计算 | 此时才开始计算 AVG()、COUNT() 并应用别名。 |
| 5 | HAVING |
组级过滤 | 只留下那些"平均薪资 > 60000"的部门(组),这里可以用别名。 |
| 6 | ORDER BY |
最终排序 | 把结果按薪资从高到低排列。 |
| 7 | LIMIT |
输出限制 | 只取出前 5 名展示在报表上。 |