目录
[1. 业务背景](#1. 业务背景)
[2. 环境依赖](#2. 环境依赖)
[3. 原始数据概览](#3. 原始数据概览)
[1. 核心问题](#1. 核心问题)
[2. 处理方案与代码实现](#2. 处理方案与代码实现)
[三、缺失值深度分析与 6 种工业级填充方案](#三、缺失值深度分析与 6 种工业级填充方案)
[1. 缺失值统计分析](#1. 缺失值统计分析)
[2. 核心设计思路](#2. 核心设计思路)
[3. 六种缺失值填充方案全实现](#3. 六种缺失值填充方案全实现)
[① 类别内均值填充](#① 类别内均值填充)
[② 随机森林预测填充(本项目最优方案)](#② 随机森林预测填充(本项目最优方案))
[1. Z-Score 标准化](#1. Z-Score 标准化)
[2. 数据集划分](#2. 数据集划分)
[3. 缺失值填充执行](#3. 缺失值填充执行)
[五、类别不平衡优化(SMOTE 过采样)](#五、类别不平衡优化(SMOTE 过采样))
本文基于 1000 + 条矿物检测样本的实战项目,完整拆解工业级表格数据清洗全流程,覆盖异常值处理、多方案缺失值填充、标准化、类别不平衡优化等核心环节,所有代码开箱即用,可直接复用于各类结构化分类任务。
一、项目背景与环境准备
1. 业务背景
我们拿到了一份1044 条矿物检测数据,包含氯、钠、镁、硫等 13 项化学成分特征,目标是实现 A/B/C/D 四类矿物的智能分类。原始数据存在大量非数值异常值、不规则缺失值、类别分布不平衡等问题,直接建模会出现精度失真、模型泛化能力差等问题,因此数据清洗是本项目的核心基石。
正确流程(数据预处理黄金法则)
读取数据→删除 E 类→处理异常值(转数值)
切分训练 / 测试集(先切分!避免测试集信息泄露)
基于训练集填充测试集的缺失值(测试集不能用自身数据填充)
基于训练集做标准化(测试集仅用训练集的均值 / 方差)
训练集做 SMOTE 过采样(仅训练集!)
保存数据
2. 环境依赖
python
import pandas as pd
import matplotlib.pyplot as plt
from pathlib import Path
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import SMOTE
# 缺失值填充自定义模块(下文完整拆解)
import filldata3. 原始数据概览
原始数据为 Excel 格式,核心结构如下表所示,共 13 个数值型特征、1 个分类标签列,我们首先过滤掉业务中不需要的 E 类矿物样本。
| 特征列 | 含义 | 数据类型 | 业务说明 |
|---|---|---|---|
| 氯 / 钠 / 镁 / 硫 / 钙 / 钾 / 碳 / 溴 / 锶 /pH/ 硼 / 氟 / 硒 | 矿物化学成分含量 | 数值型 | 矿物分类核心特征,存在大量非数值异常值 |
| 矿物类型 | 分类标签 | 字符型 | 目标值,分为 A/B/C/D 四类,需做数值编码 |
数据加载与初步过滤代码
python
BASE_DIR = Path(__file__).resolve().parent
data_path = BASE_DIR / "矿物数据.xls"
output_dir = BASE_DIR / "temp_data"
output_dir.mkdir(parents=True, exist_ok=True)
# 导入数据并过滤E类矿物
data = pd.read_excel(data_path)
data = data[data['矿物类型'] != 'E']
# 拆分特征与标签
X_whole = data.drop('序号', axis=1).drop('矿物类型', axis=1)
Y_whole = data.矿物类型二、异常值与标签标准化处理
1. 核心问题
原始数据中存在大量字符串、特殊符号、空格、非法数值等异常数据,直接传入模型会触发类型报错,同时字符型标签无法被机器学习模型识别,需做标准化处理。
2. 处理方案与代码实现
(1)非数值异常值清洗
使用pd.to_numeric将所有特征列强制转换为数值型,无法转换的异常值统一设为NaN,为后续缺失值处理做准备。
python
# 数据中存在大量字符串数值、|、空格等异常数据。字符串数值直接转换为float,\和空格转换为nan
for column_name in X_whole.columns:
X_whole[column_name] = pd.to_numeric(X_whole[column_name], errors='coerce')
# pd.to_numeric()函数尝试将参数中的数据转换为数值类型。如果转换失败,它会引发一个异常,
# 设置errors='coerce',将会无法转换的值设置为nun(2)分类标签数值编码
将字符型标签 A/B/C/D 映射为数值 0/1/2/3,符合分类模型的输入要求。
python
# 标签数值编码
label_dict = {"A":0, "B":1, "C":2, "D":3}
enecoded_label = [label_dict[label] for label in Y_whole]
Y_whole = pd.Series(enecoded_label,name="矿物类型")三、缺失值深度分析与 6 种工业级填充方案
1. 缺失值统计分析
首先统计每列的缺失值数量,明确缺失分布:
python
# 缺失值统计
null_num = data.isnull()
null_total = null_num.sum()
print("各特征缺失值数量:\n", null_total)缺失值分布可视化代码
python
# 绘制缺失值分布柱状图
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(12, 6))
null_total.sort_values(ascending=False).plot(kind='bar', color='#1f77b4')
plt.title('各特征缺失值数量分布', fontsize=14)
plt.xlabel('特征名称', fontsize=12)
plt.ylabel('缺失值数量', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()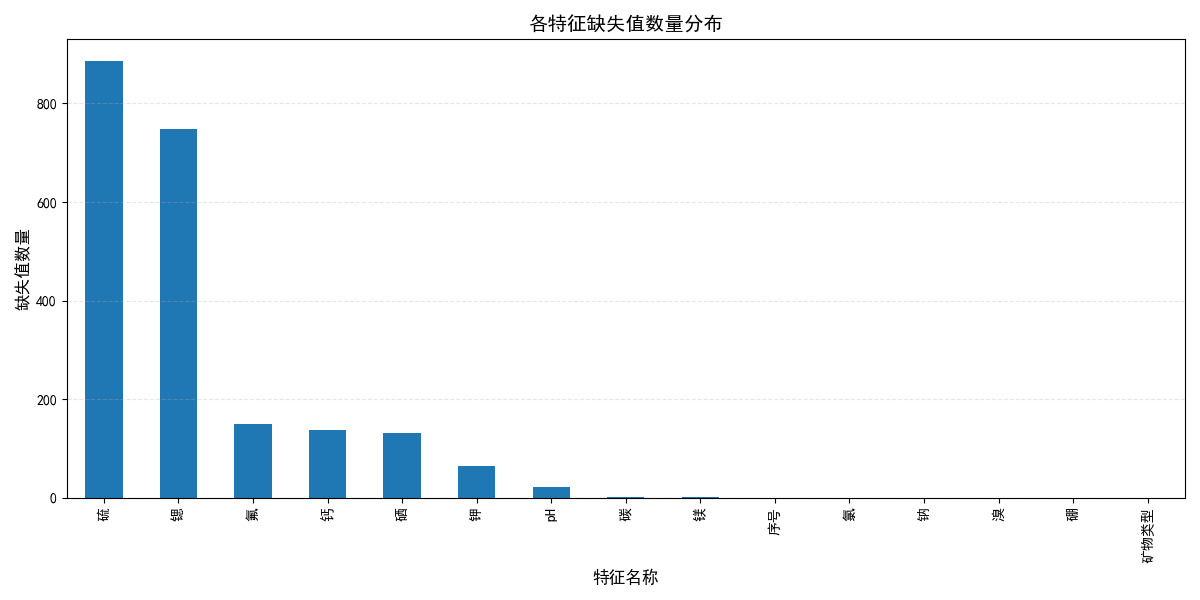
2. 核心设计思路
不使用全局填充,而是按矿物类型分组填充:不同矿物的化学成分分布存在本质差异,全局均值 / 中位数填充会引入严重的业务偏差,按标签分组填充更符合矿物检测的业务逻辑。
3. 六种缺失值填充方案全实现
我们实现了从简单统计填充到机器学习预测填充的 6 种方案,覆盖不同业务场景,所有代码均为原项目可运行版本。
填充方案对比总表
| 填充方案 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 完整案例删除法 | 删除含缺失值的整行样本 | 实现简单,不引入虚假数据 | 丢失大量样本,加剧类别不平衡 | 缺失率极低 (<5%)、样本量极大的场景 |
| 类别内均值填充 | 按矿物类型分组,用组内均值填充缺失值 | 实现简单,保留类别分布特征 | 对异常值敏感,缩小特征方差 | 数据分布正态、无极端异常值的场景 |
| 类别内中位数填充 | 按矿物类型分组,用组内中位数填充缺失值 | 抗异常值能力强,鲁棒性高 | 对离散特征适配性差 | 存在极端异常值、数据分布偏态的场景 |
| 类别内众数填充 | 按矿物类型分组,用组内众数填充缺失值 | 适配离散型特征,不改变数据分布 | 连续特征填充效果差,易出现偏差 | 离散特征、分类特征的缺失值填充 |
| 线性回归预测填充 | 用无缺失特征构建线性回归模型,预测缺失值 | 利用特征间相关性,填充精度高 | 对非线性关系拟合差,易过拟合 | 特征间线性相关性强的场景 |
| 随机森林预测填充 | 用无缺失特征构建随机森林回归模型,预测缺失值 | 拟合非线性关系,抗过拟合,填充精度最高 | 计算成本略高 | 结构化表格数据的高精度填充需求(本项目首选) |
(1)核心填充方法代码拆解
以下为 6 种方案的核心实现,完整代码可参考项目filldata.py,核心逻辑分块如下:
① 类别内均值填充
python
"""均值填充"""
def mean_train_method(data):
fill_value = data.mean()
return data.fillna(fill_value)
def mean_train_fill(train_data,train_label):
data = pd.concat([train_data,train_label],axis=1)
data = data.reset_index(drop=True)
# 按矿物类型分组填充
A = data[data['矿物类型'] == 0 ]
B = data[data['矿物类型'] == 1 ]
C = data[data['矿物类型'] == 2 ]
D = data[data['矿物类型'] == 3 ]
A = mean_train_method(A)
B = mean_train_method(B)
C = mean_train_method(C)
D = mean_train_method(D)
df_filled = pd.concat([A,B,C,D],axis=0)
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型
# 测试集填充(仅用训练集统计值,避免数据泄露)
def mean_test_method(train_data,test_data):
fill_value = train_data.mean()
return test_data.fillna(fill_value)
def mean_test_fill(train_data,train_label,test_data,test_label):
data_test = pd.concat([test_data,test_label],axis=1)
data_test = data_test.reset_index(drop=True)
data_train = pd.concat([train_data,train_label],axis=1)
data_train = data_train.reset_index(drop=True)
# 按矿物类型分组,用训练集统计值填充测试集
A = data_test[data_test['矿物类型'] == 0 ]
B = data_test[data_test['矿物类型'] == 1 ]
C = data_test[data_test['矿物类型'] == 2 ]
D = data_test[data_test['矿物类型'] == 3 ]
A_t = data_train[data_train['矿物类型'] == 0]
B_t = data_train[data_train['矿物类型'] == 1]
C_t = data_train[data_train['矿物类型'] == 2]
D_t = data_train[data_train['矿物类型'] == 3]
A = mean_test_method(A_t,A)
B = mean_test_method(B_t,B)
C = mean_test_method(C_t,C)
D = mean_test_method(D_t,D)
df_filled = pd.concat([A,B,C,D],axis=0)
df_filled = df_filled.reset_index(drop=True)
return df_filled.drop('矿物类型',axis=1),df_filled.矿物类型关键说明:测试集填充仅使用训练集的统计值,严格避免数据泄露,保证模型泛化能力。中位数、众数填充的代码结构与均值填充完全一致,仅替换统计方法。
② 随机森林预测填充(本项目最优方案)
python
"""随机森林填充"""
from sklearn.ensemble import RandomForestRegressor
def rf_train_fill(train_data,train_label):
data = pd.concat([train_data, train_label], axis=1)
data = data.reset_index(drop=True)
train_data = data.drop('矿物类型', axis=1)
# 按缺失值数量从小到大排序,优先填充缺失少的特征
null_num = train_data.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature = [] # 保存缺失值名
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i] != 0:
# 构建特征与标签,无缺失值为训练集,有缺失值为预测集
X = train_data[filling_feature].drop(i, axis=1)
y = train_data[i]
row_numbers = train_data[train_data[i].isnull()].index.tolist()
x_train = X.drop(row_numbers)
y_train = y.drop(row_numbers)
x_test = X.iloc[row_numbers]
# 训练随机森林回归模型预测缺失值
rf = RandomForestRegressor(n_estimators=100, max_depth=20, random_state=0)
rf.fit(x_train, y_train)
y_pred = rf.predict(x_test)
train_data.loc[row_numbers, i] = y_pred
print("完成训练数据集中'{}'列的数据填充".format(i))
return train_data, data.矿物类型
# 测试集预测填充(无数据泄露)
def rf_test_fill(train_data,train_label,test_data,test_label):
data_train = pd.concat([train_data,train_label],axis=1)
data_train = data_train.reset_index(drop=True)
train_data = data_train.drop('矿物类型',axis=1)
data_test = pd.concat([test_data,test_label],axis=1)
data_test = data_test.reset_index(drop=True)
test_data = data_test.drop('矿物类型',axis=1)
null_num = test_data.isnull().sum()
null_num_sorted = null_num.sort_values(ascending=True)
filling_feature = []
for i in null_num_sorted.index:
filling_feature.append(i)
if null_num_sorted[i] !=0 :
X = train_data[filling_feature].drop(i,axis=1)
y = train_data[i]
x_test = test_data[filling_feature].drop(i, axis=1)
row_numbers = test_data[test_data[i].isnull()].index.to_list()
x_test = x_test.iloc[row_numbers]
# 无特征可训练时,用均值兜底
if X.shape[1] == 0:
fill_val = y.mean()
test_data.loc[row_numbers, i] = fill_val
print(f"无特征可训练,测试集[{i}]列用均值{fill_val:.2f}填充")
continue
non_null_idx = y.notna()
X_train_clean = X[non_null_idx]
y_train_clean = y[non_null_idx]
# 仅用训练集训练模型,预测测试集缺失值
rf = RandomForestRegressor(n_estimators=100, max_depth=20, random_state=0)
rf.fit(X_train_clean,y_train_clean)
y_pred = rf.predict(x_test)
test_data.loc[row_numbers,i] = y_pred
print("完成测试集中'{}'的填充".format(i))
return test_data,data_test.矿物类型四、数据标准化与数据集划分
1. Z-Score 标准化
不同化学成分的量纲差异极大(如氯含量最高达 37 万,pH 值仅为个位数),基于距离的模型(SVM、逻辑回归)对量纲高度敏感,因此使用 Z-Score 标准化将数据缩放到均值为 0、方差为 1 的分布。
python
'''z标准化'''
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 训练集:fit+transform(拟合+转换)
x_train_scaled = scaler.fit_transform(x_train_fill)
# 测试集:仅transform(复用训练集的均值/标准差,避免数据泄露)
x_test_scaled = scaler.transform(x_test_fill)
# 转回DataFrame(方便后续保存)
x_train_scaled = pd.DataFrame(x_train_scaled, columns=x_train_fill.columns)
x_test_scaled = pd.DataFrame(x_test_scaled, columns=x_test_fill.columns)2. 数据集划分
采用 7:3 比例划分训练集与测试集,固定随机种子保证结果可复现,重置索引避免后续填充出现索引错位。
python
'''数据集切分'''
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = \
train_test_split(X_whole,Y_whole,random_state=7)
x_train = x_train.reset_index(drop=True)
y_train = y_train.reset_index(drop=True)
x_test = x_test.reset_index(drop=True)
y_test = y_test.reset_index(drop=True)3. 缺失值填充执行
以随机森林填充为例,执行填充流程,其他方案仅需替换函数名即可。
python
"""数据填充6种方法"""
#6随机森林填充
x_train_fill,y_train_fill = filldata.rf_train_fill(x_train,y_train)
x_test_fill,y_test_fill = filldata.rf_test_fill(x_train_fill,y_train_fill,x_test,y_test)五、类别不平衡优化(SMOTE 过采样)
矿物样本存在天然的类别分布不平衡,小类别样本量少会导致模型偏向大类别,因此使用 SMOTE 算法对训练集做过采样,生成合成样本平衡类别分布,测试集不做任何采样处理,保证评估结果真实。
python
'''smote拟合(仅训练集!测试集绝不过采样)'''
from imblearn.over_sampling import SMOTE
oversample = SMOTE(k_neighbors=1,random_state=0)
os_x_train,os_y_train = oversample.fit_resample(x_train_scaled,y_train_fill)六、清洗结果落地与输出
将最终处理好的训练集和测试集保存为 Excel 文件,方便后续模型训练调用,同时打乱训练集顺序避免模型学习到顺序特征。
python
'''数据保存为excel'''
# 训练集:合并标签+特征,打乱顺序(提升训练鲁棒性
data_train = pd.concat([os_y_train,os_x_train],axis=1).sample(frac=1,random_state=0)
# 测试集:合并标签+特征,不打乱(方便后续评估)
data_test = pd.concat([y_test_fill, x_test_scaled], axis=1) #测试集不用传入模型训练,无须打乱顺序
data_train.to_excel(output_dir / '训练数据集[随机森林填充].xlsx',index=False)
data_test.to_excel(output_dir / '测试数据集[随机森林填充].xlsx',index=False)七、清洗结果总结
经过上述全流程处理,我们得到了无缺失值、无异常值、无量纲差异、类别平衡的高质量数据集:
- 所有特征列无缺失值,填充过程严格避免数据泄露;
- 异常值全部完成标准化处理,符合模型输入要求;
- 特征完成标准化,消除量纲影响;
- 训练集类别完全平衡,解决了样本分布不均的问题。