博士论文聚焦FPGA-based 量子电路仿真 ,针对 CPU 和 GPU 在能耗与扩展性上的局限,设计了直接迭代处理、缓冲架构、门融合架构 等多种可定制化 FPGA 架构,提出了受控门调度优化 (使部分电路速度提升达 5 倍)和电路宽度缩减技术 (适配计算基编码与振幅基编码),实现了支持29 个量子比特的通用量子电路仿真,虽原始速度不及 GPU,但在受控门密集型电路中能耗比 GPU 低 2.6 倍,凸显了 FPGA 在能耗受限场景的显著优势,同时指出了高电平合成(HLS)局限等现存挑战及多 FPGA 集群等未来优化方向。
3. 详细总结
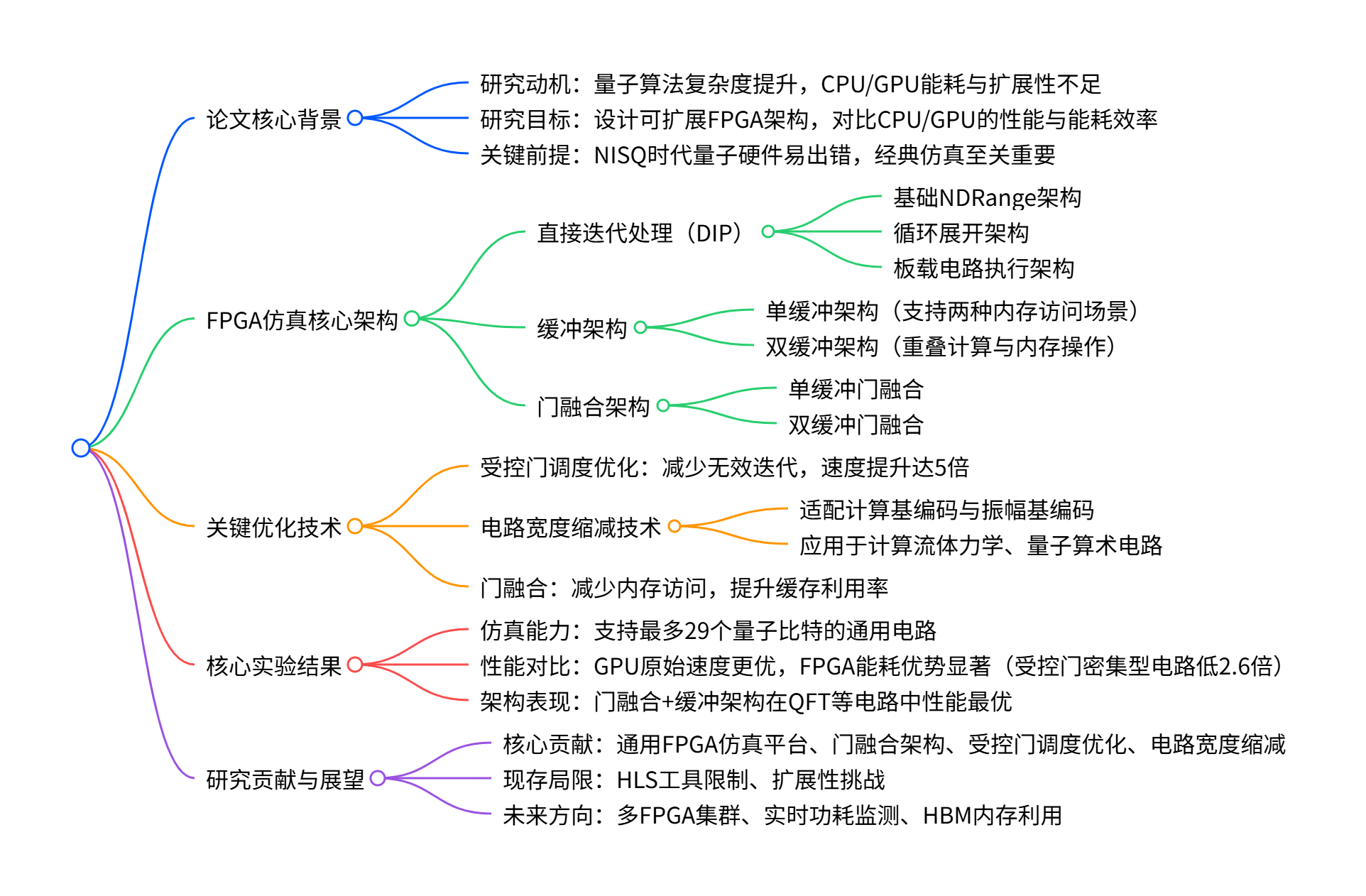
一、研究背景与目标
- 研究背景
- 量子算法复杂度与规模持续增长,但物理量子硬件存在易出错、相干时间短等局限,经典量子电路仿真成为必要工具。
- 传统 CPU/GPU 仿真存在能耗高、扩展性差的问题,FPGA 凭借可定制并行性、能耗效率和灵活硬件配置,成为潜在替代平台。
- 核心目标
- 设计适用于量子电路全状态向量仿真的可扩展 FPGA 架构。
- 对比 FPGA 与 CPU/GPU 在性能、扩展性和能耗效率上的表现。
- 探索 FPGA 仿真的最优应用场景及关键优化方向。
- 研究问题
- FPGA 架构能否针对量子电路仿真优化?
- FPGA 性能随硬件利用率如何扩展?
- 哪些类型的量子电路从 FPGA 仿真中获益最多?
- FPGA 相比 CPU/GPU 是否存在每瓦性能优势?
二、核心架构设计
表格
| 架构类型 | 关键子类 | 核心特点 | 适用场景 |
|---|---|---|---|
| 直接迭代处理(DIP) | 基础 NDRange 架构 | 基于 OpenCL NDRange 调度迭代,并行性由计算单元(CU)复制实现 | 通用量子电路,入门级仿真 |
| 循环展开架构 | 单任务内核 + 循环展开,细粒度并行,减少循环控制开销 | 对延迟敏感的中小型电路 | |
| 板载电路执行架构 | 一次性加载整个电路到 FPGA 内存,避免主机 - FPGA 频繁通信 | 无需动态修改的固定电路 | |
| 缓冲架构 | 单缓冲架构 | 利用板载 BRAM 缓存状态向量切片,支持单 / 双次突发内存访问 | 内存访问密集型电路 |
| 双缓冲架构 | 分离读写缓冲,重叠计算与内存操作,降低延迟 | 高吞吐量要求的大规模电路 | |
| 门融合架构 | 单 / 双缓冲门融合 | 融合连续满足条件的门,减少内存读写次数,提升缓存利用率 | 多连续门、高数据 locality 电路 |
三、关键优化技术
- 受控门调度优化
- 核心逻辑:受控门会使部分迭代无效,通过计算调整后的控制位和跳过间隔,仅调度有效迭代。
- 性能提升:对受控门密集型电路,速度较基准架构提升达5 倍。
- 电路宽度缩减技术
- 核心逻辑:识别并转换电路中可简化的部分,减少所需量子比特数,不影响整体计算结果。
- 适配范围:最初用于计算基编码电路,后扩展至更广泛的振幅基编码电路。
- 应用场景:计算流体力学(D1Q3 模型)、量子算术电路(Cuccaro 加法器),可将 D1Q3 电路缩减至 25 个量子比特。
- 门融合优化
- 核心逻辑:将连续满足
t<l(目标比特索引 < 缓冲量子比特大小)的门融合为块,在缓存中完成多门运算。 - 优势:减少全局内存访问次数,提升数据复用率,尤其适用于 QFT、Grover 扩散算子等电路。
- 核心逻辑:将连续满足
四、实验结果与对比
-
仿真能力
- 支持量子比特数:最多29 个通用量子比特,理论上可通过内存扩展支持更多。
- 测试电路:量子傅里叶变换(QFT)、Grover 搜索算法、计算流体力学(D1Q3)、量子算术电路等。
-
性能对比(FPGA vs CPU/GPU)
表格
对比维度 FPGA 表现 CPU/GPU 表现 关键结论 原始执行速度 低于 GPU GPU 最优,CPU 次之 FPGA 不追求绝对速度,聚焦能耗效率 能耗效率 受控门密集型电路能耗比 GPU 低2.6 倍 能耗较高,尤其是 GPU FPGA 在能耗受限场景优势显著 扩展性 随计算单元(CU)数量增加性能提升 受限于架构并行度上限 FPGA 支持细粒度并行扩展 -
最优架构组合
- 单缓冲门融合架构(3BQS)在 QFT 电路中表现最优。
- 受控门调度优化后的 OptContNDRange 架构在 streaming 电路中相对提升最大。
五、研究贡献与展望
- 核心贡献
- 开发了首个支持通用量子电路(非特定算法 / 门集)的 FPGA 仿真平台。
- 提出门融合 FPGA 架构,显著提升缓存利用率和内存访问效率。
- 设计受控门调度优化,解决受控门密集型电路的性能瓶颈。
- 提出通用电路宽度缩减技术,适配两种主流数据编码方式。
- 现存局限
- 高电平合成(HLS)工具限制,影响进一步性能提升。
- 单 FPGA 内存与计算资源有限,大规模电路仿真需集群支持。
- 未来工作
- 构建多 FPGA 集群与分布式架构,提升大规模电路仿真能力。
- 实现实时功耗监测,优化能耗 - 性能平衡。
- 改进 HLS 工具适配性,提升架构编译效率。
- 整合高带宽内存(HBM),优化内存访问延迟与带宽。
4. 关键问题
问题 1:FPGA 在量子电路仿真中相比 CPU/GPU 的核心优势与劣势分别是什么?
答案:优势:① 能耗效率显著,受控门密集型电路中能耗比 GPU 低 2.6 倍,适合能耗受限场景;② 可定制化并行架构,支持细粒度优化(如门融合、缓冲策略),适配量子电路的内存访问模式;③ 通用性强,可仿真任意结构的量子电路(最多 29 个量子比特),不局限于特定算法。劣势:① 原始执行速度低于 GPU,绝对性能无优势;② 受 HLS 工具限制,架构优化与编译效率存在瓶颈;③ 单 FPGA 资源有限,大规模电路仿真需依赖多 FPGA 集群扩展。
问题 2:论文提出的受控门调度优化和电路宽度缩减技术分别解决了什么核心问题?具体效果如何?
答案:① 受控门调度优化:解决了受控门导致的大量无效迭代问题,通过计算调整后的控制位和跳过间隔,仅调度有效迭代,避免 FPGA 静态调度下的时钟周期浪费,使部分受控门密集型电路速度较基准架构提升达 5 倍。② 电路宽度缩减技术:解决了量子电路所需量子比特数过多、占用内存过大的问题,通过识别电路中可简化部分并转换,在不影响计算结果的前提下减少 qubit 数量,适配计算基编码与振幅基编码,成功将 D1Q3 计算流体力学电路缩减至 25 个量子比特,提升 FPGA 内存与计算资源利用率。
问题 3:论文设计的多种 FPGA 架构(直接迭代、缓冲、门融合)中,哪种架构在什么场景下表现最优?其核心原因是什么?
答案 :单缓冲门融合架构(3BQS)在量子傅里叶变换(QFT)等包含连续满足t<l条件的电路中表现最优;受控门调度优化后的 OptContNDRange 架构在 streaming 等受控门密集型电路中表现最优。核心原因:① 门融合架构通过将连续门融合为块,减少了全局内存访问次数,充分利用 FPGA 板载 BRAM 的高带宽低延迟特性,提升数据复用率;② 缓冲策略解决了量子电路内存访问分散的问题,支持突发内存访问,降低延迟;③ 受控门调度优化针对性解决了受控门密集型电路的无效迭代问题,进一步提升并行效率,三者结合最大化发挥了 FPGA 的硬件定制优势。