在语音领域,自回归(AR)与非自回归(NAR)模型的博弈构成了技术演进的核心主线。这两条路线在语音识别(ASR) 和语音合成(TTS) 这两个子领域中,呈现出了不同的技术格局。
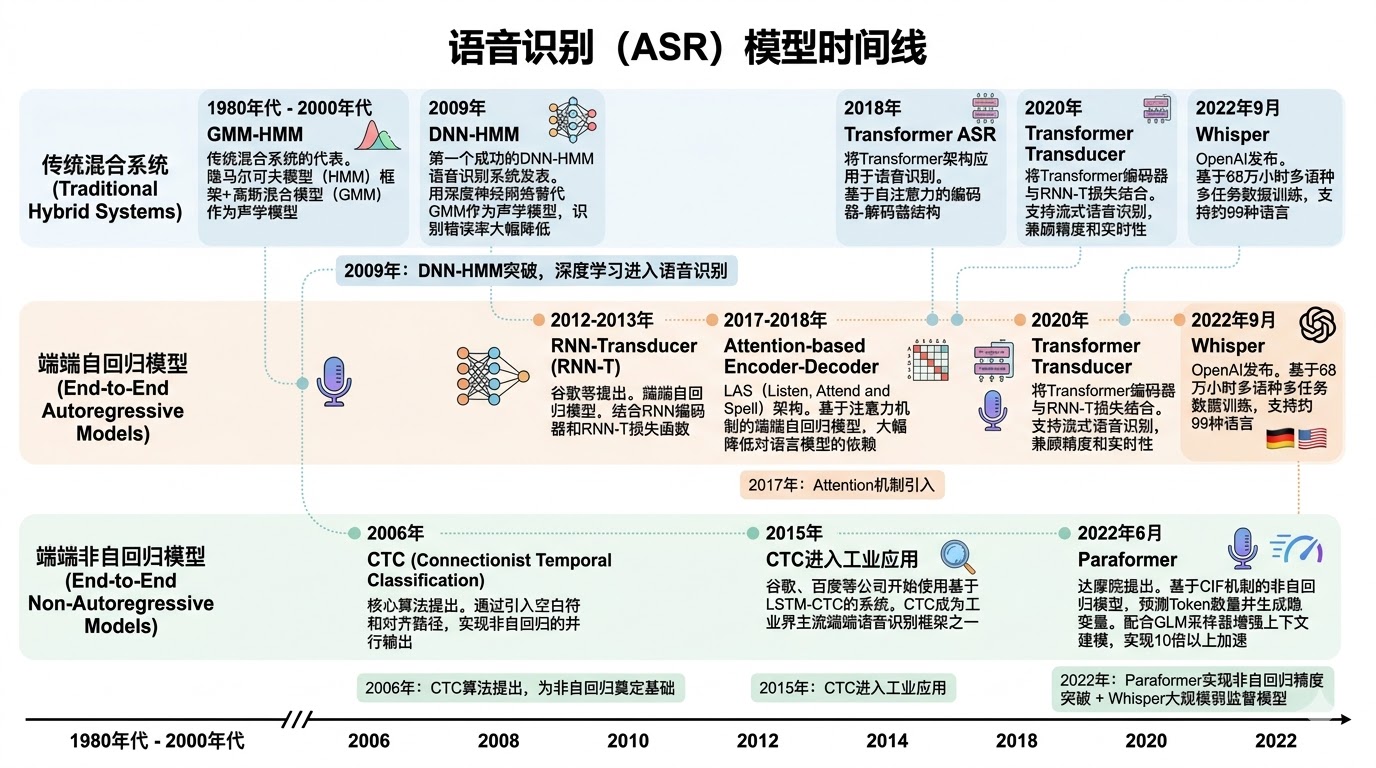
一、语音识别(ASR):从混合系统到端到端,再到非自回归的突破
语音识别的目标是让机器"听得准",核心挑战在于如何处理变长的音频序列 并将其映射到定长的文本序列,其技术路线经历了从传统混合系统到现代端到端模型的深刻变革。
1. 技术路线全景
| 技术路线 | 代表模型/框架 | 核心技术 | 优点 | 缺点 |
|---|---|---|---|---|
| 传统混合系统 | GMM-HMM, DNN-HMM | 隐马尔可夫模型(HMM)框架,高斯混合模型(GMM)或深度神经网络(DNN)作为声学模型,配合语言模型和解码器(如WFST)。 | 模块化,工程成熟度高,在特定领域(如Kaldi)精度依然优秀。 | 流程复杂,各模块独立优化困难,对专家经验依赖强。 |
| 端到端自回归模型 | RNN-Transducer (RNN-T) , Attention-based Encoder-Decoder (如最初的 Transformer ASR ),Whisper | 用一个神经网络直接将语音映射到文本。自回归解码,即逐个预测文字,每一步依赖上一步的输出。 | 天然支持流式,流程简化,性能强大,成为现代语音识别的主流。 | 推理速度慢,并行度低,无法充分利用GPU的并行计算能力,且在长音频中易产生"幻听"。 |
| 端到端非自回归模型 | CTC , Paraformer (CIF机制) | 同样端到端,但解码方式不同。CTC 通过引入空白符和对齐路径,实现并行输出。Paraformer 中的**CIF **核心在于"集成与补充"。通过对声学编码器输出的权累重加,当达到阈值1时,判定为一个Token的边界。这解决了NAR无法对齐的致命伤。 | 推理速度极快(数倍至十倍提升),计算效率高。 | 早期模型(如CTC)性能弱于自回归。独立假设导致语义建模困难,准确率是主要挑战。实现流式识别需要复杂的切削策略,实时响应略慢于RNN-T。 |
2. 自回归模型的技术细节
在Paraformer这类模型出现前,顶尖的端到端ASR系统大多采用自回归架构,例如基于 Transformer 或 Conformer (结合了Transformer和CNN的优势)的编码器-解码器模型。这些模型在解码时,生成第 i 个词 y_i 的概率为 P(y_i | y_<i, X),即必须依赖之前生成的所有词 y_<i。这种方式虽然准确,但过程是串行的,好比一个字一个字地写文章,无法加快速度。
3. 非自回归模型的里程碑:Paraformer
Paraformer 的里程碑意义在于,它首次在工业级应用中证明,非自回归模型可以在保证甚至超越自回归模型识别准确率的同时,实现5-10倍的推理速度提升。它精准地解决了非自回归模型在工业落地中的两大核心痛点。
它的核心创新技术细节如下:
- Predictor(预测器)模块:解决"长度预测"难题
- 问题:非自回归模型首先要确定"这句话有多少个字"。在语速、口音、噪声影响下,准确预测文字个数非常困难。
- Paraformer的解法 :采用基于 Continuous Integrate-and-Fire (CIF) 机制的Predictor。CIF机制可以自动、准确地从语音中预测并抽取每个目标文字对应的声学特征向量,同时确定了文字个数。这比学术界此前用CTC预测个数的方式更精准。
- Sampler(采样器)模块:解决"语义缺失"难题
- 问题:由于条件独立假设,非自回归模型在预测时忽略了文字间的上下文依赖,导致替换错误显著增加,语义丢失。
- Paraformer的解法 :受机器翻译中的Glancing Language Model (GLM)启发,设计了一个 Sampler 。它通过巧妙的采样策略,将声学特征向量与目标文字向量融合,生成带有丰富上下文语义的特征,再送入一个双向的Decoder进行建模。这极大地增强了模型对上下文语义的理解能力,有效减少了替换错误。
- MWER区分性训练
- 为了进一步提升性能,Paraformer引入了基于负样本采样的MWER(Minimum Word Error Rate)训练准则。它不只是让模型预测正确,还通过对比错误样本来优化,直接降低最终的字错误率(WER)。
最终效果:在AISHELL-1、AISHELL-2、WenetSpeech等权威中文测试集上,Paraformer-large均取得了最优结果,在SpeechIO的公开评测中准确率超过98%。配合6倍下采样等优化,大幅降低了计算量。
4. 其他重要ASR模型简述
除了上述路线,还有一些模型在特定领域影响深远:
- Kaldi:传统混合架构的集大成者,至今仍在高精度要求的场景(如医疗、金融)有广泛应用。
- wav2vec 2.0 / HuBERT:自监督学习的代表,通过海量无标注语音预训练,再微调,极大地降低了对标注数据的依赖。
- Whisper:弱监督学习的典范,通过海量多样化的数据训练,展现出极强的泛化能力和多语言支持。
- Vosk:轻量化部署的佼佼者,专为嵌入式设备优化。
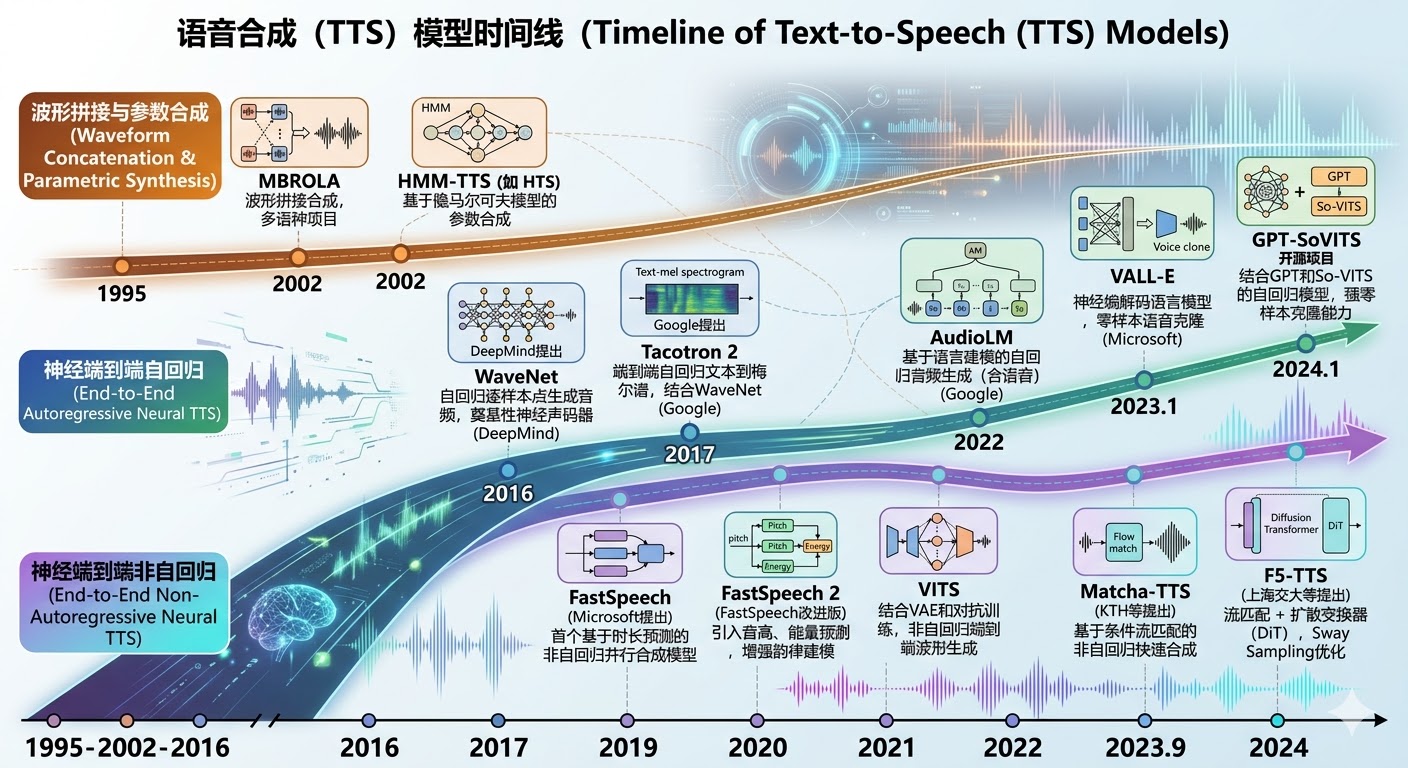
二、语音合成(TTS):从拼接合成到自回归,再到非自回归的效率革命
语音合成的目标是让机器"说得像",AR与NAR的争夺点在于声学建模的连贯性 与速度推理,其演进同样深刻,从早期的波形拼接走到了如今的神经端到端模型。
1. 技术路线全景
| 技术路线 | 代表模型 | 核心技术 | 优点 | 缺点 |
|---|---|---|---|---|
| 波形拼接与参数合成 | MBROLA, HMM-TTS | 拼接预录单元或通过统计模型生成参数。 | 技术成熟,计算量小。 | 自然度差,机械感强,无法处理新词或情感。 |
| 神经端到端自回归模型 | Tacotron 2 、WaveNet、VALL-E、GPT-SoVITS、AudioLM | 用神经网络(如seq2seq with attention)将文本映射到声学特征(如Mel谱),再由自回归声码器(如WaveNet)逐点生成波形。 | 自然度极高 ,情感表现力强。极强的零样本(Zero-shot)能力。由于它的学习是序列间的关系因果关系,只需3秒参考就能获得音频模板音色、语调甚至环境音。 | 合成速度慢 ,自回归声码器是瓶颈,难以实时应用。不稳定 (易出现复读、丢字)且延迟高。 |
| 神经端到端非自回归模型 | FastSpeech系列 , VITS、F5-TTS、Matcha-TTS | 采用非自回归架构,一次生成整个声学特征序列。通过时长预测器 、音高预测器等模块来建模韵律。 | 极速推理 (支持百倍速生成)且稳定性极高(绝无复读)。流量匹配架构在2024年后几乎抹平了与AR模型的音质差距。 | 韵律控制复杂,对时长预测器依赖强,情感表达有时不如自回归模型细腻。 |
2. 自回归模型的技术细节
以 Tacotron 2 + WaveNet 为代表的模型是自回归TTS的巅峰。
- Tacotron 2 :作为声学模型,它采用编码器-注意力-自回归解码器的架构,根据文本逐帧预测梅尔谱。这里的"自回归"体现在解码器生成第
t帧的梅尔谱m_t时,依赖于之前生成的所有帧m_<t。 - WaveNet:作为声码器,它同样采用自回归的扩张卷积网络,逐样本点地生成16kHz的音频波形。这种逐点生成的方式虽然保证了极高的音质,但计算量巨大,是速度的主要瓶颈。
3. 非自回归模型的技术细节
以 FastSpeech 2 为代表1。
- 核心思想 :将梅尔谱的生成完全并行化。它不再依赖注意力机制来对齐文本和语音,而是引入了一个时长预测器(Duration Predictor),用于显式地预测每个音素(或字)应该对应多少帧的语音。
- 韵律建模 :为了弥补非自回归丢失的韵律信息,FastSpeech 2 引入了音高(Pitch) 和能量(Energy) 的预测器,作为额外的条件输入,让模型可以学习更丰富的韵律变化。
- 推理过程:给定文本,先通过时长预测器将文本序列扩展到目标帧长度的序列,然后并行地通过非自回归解码器,一次性生成完整的梅尔谱,最后配合并行的神经声码器(如MelGAN、HiFi-GAN)快速生成波形。这使得实时语音合成成为可能。
4. 新近模型
- Fish Speech V1.5:采用了创新的双自回归Transformer(DualAR)设计,在多语言、多说话人合成上表现出色。
- CosyVoice2:基于LLM架构的流式合成模型,实现了极低延迟(流式模式150ms内)和高质量。
四、看完这些,我们收获了什么?(核心技术总结)
- 不再单打独斗,强强联合是主流:现在的语音黑科技,不再是AR或NAR的单人表演,而是他们的"组合拳"。GPT-SoVITS就很聪明,先用能看懂逆转的AR机制写好歌词本(保证语义),再用能一气呵成的NAR机制唱出来(保证声学快速)要素。
- 精准对准(CIF)让非自回归也能当主角: 超能者 的成功告诉我们:只要解决了**"字数预测不准"和"字和音对不齐"**这两个天坑,知道速度就快的NAR就能彻底翻身做主人。这证明了精准的对准机制能够回归非自回归彻底自回复。
- 算力下沉,端侧应用更爱非自回归:以后手机和耳机上的语音助手会越来越聪明。但AR逐字逐句生成太慢、太费电。所以,省电、生成快的小型NAR模型(比如基于流匹配技术)才是智能可穿戴设备的未来点技术。