将得到的训练数据集和测试数据集通过8种算法来进行模型评估,对比结果得到最优的模型评估
1.LR逻辑回归算法
数据提取(本文以平均填充值为例子)
python
import pandas as pd
from sklearn import metrics
train_data=pd.read_excel(r'训练数据集[平均填充].xlsx]')
train_data_x=train_data.iloc[:,1:]#训练数据集的特征
train_data_y=train_daata.iloc[:,0]#训练数据集的测试标签label
test_data=pd.read_excel(r'测试数据集[平均值填充].xlsx')
test_data_x=test_data.iloc[:,1:]#测试数据集的特征
test_data_y=test_data.iloc[:,0]#测试数据集的测试标簽label
result_data={}逻辑回归LR算法实现代码
python
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV#网络搜索
param_grid={
'C':[0.01],
'penalty':['l2'],
'solver':['lbfgs'],
'max_iter':[3000],
'class_weight':['balanced']
}
logreg = LogisticRegression()
grid_search = GridSearchCV(logreg,param_grid,cv=5)#创建GridSearchCV对象
grid_search.fit(train_data_x,train_data_y)#在训练集上执行网格搜索
print("best parameters set found debelopment set:")#输出最佳参数
pritn(grid_search.best_params_)建立最优模型
python
LR_result={}#用来保存训练之后的结果
lr = LogistRegression(C=0.01,max_iter=1000,penalty=None,solver='lbfgs')
lr=.fit(train_data_x,train_data_y)测试结果含训练数据集的测试+测试数据集的测试
python
train_predicted=lr.predict(train_data_x)#训练数据集的预测结果
print('LR的train:\n',metric.classification_report(train_data_y,train_predicted)
test_predicted=lr.predict(test_data_x)#测试数据集的预测结果
print('LR的test:\n',metrics.classification_report(test_data_y,test_predicted)
a=metrics.classification_report(test_data_y,test_predicted,digits=6)#digits表示保留有效位小数
b=a.split()
LR_result['recall_0']=float(b[8])#添加类别为0的召回率
LR_result['recall_1']=float(b[11])#添加类别为1的召回率
LR_result['recall_2']=float(b[16])#添加类别为2的召回半
LR_result['recall_3']=float(b[21])#添加类别为3的什问率
LR_result['acc']=float(b[25])#添加accuracy的结果
result_data['acc']=LR_result#result_data是总体的结果
print('lr结束')运行结果:
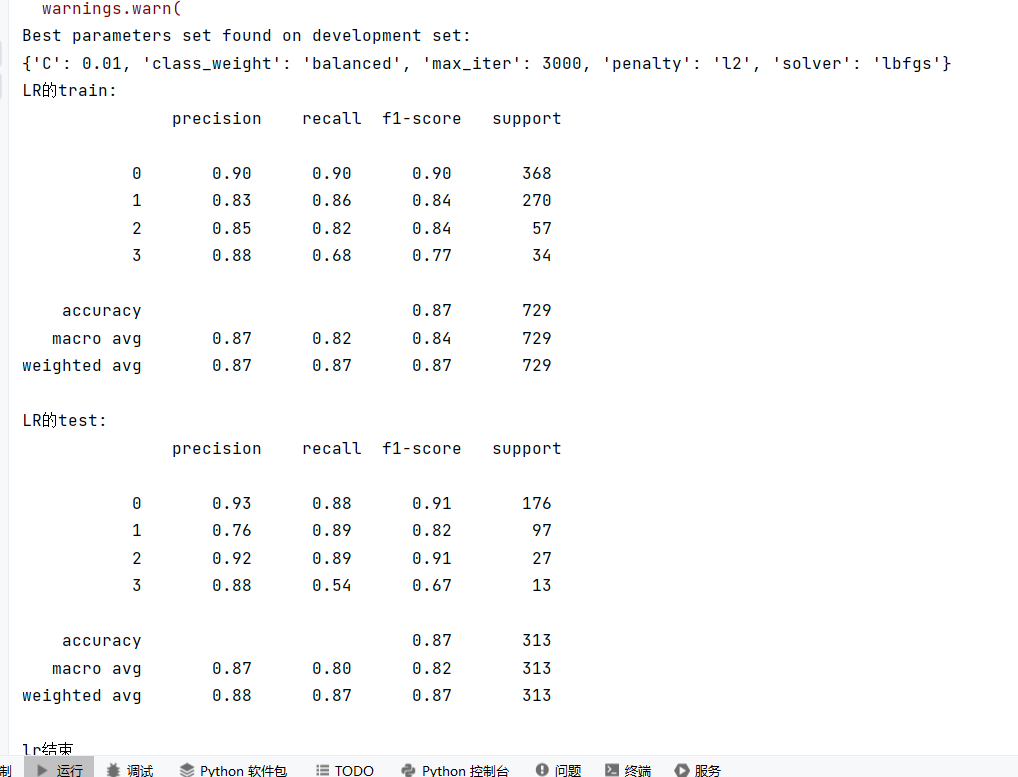
训练集准确率:0.87
测试集准确率:0.87
训练集和测试集准确率几乎一致,说明模型没有过拟合 / 欠拟合,泛化能力稳定。
2.随机森林算法
数据提取
python
import pandas as pd
from sklearn import metrics
'''数据提取'''
train_data=pd.read_excel(r'训练数据集[平均值填充].xlsx')
train_data_x=train_data.iloc[:,1:]#训练数据集的特征
train_data_y=train_data.iloc[:,0]#训练数据集的测试标签label
test_data = pd.read_excel(r'测试数据集[平均值填充].xlsx')
test_data_x=test_data.iloc[:,1:]#测试数据集的特征
test_data_y=test_data.iloc[:,0]#测试数据集的测试标簽label
result_data={}#用来保存后面6种算法的结果。随机森林RF算法实现代码
python
'''----------------------RF算法实现代码------------------------------'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV#网络搜索
param_grid ={
'n_estimators':[50,100,200],# 树的数量
'max_depth':[None,10,20,30],#树的深度
'min_samples_split':[2,5,10], #节点分裂所需的最小样本数
'min_samples_leaf':[1,2,5], # 叶子节点所需的最小样本数
'max_features':['auto','sqrt','log2'],#最大特征数
'bootstrap':[True,False] #是否使用自举样本
}
rf = RandomForestClassifier()
grid_search = GridSearchCV(rf,param_grid,cv=5)# 创建GridSearchCV对象
grid_search.fit(train_data_x,train_data_y)# 在训练集上执行网格搜索
print("Best parameters set found on development set:")#输出最佳参数
print(grid_search.best_params_)建立模型
python
# """建立最优模型"""
RF_result={}#用来保存训练之后的结果
rf = RandomForestClassifier(
bootstrap=False,
max_depth=20,
max_features='log2',
min_samples_leaf=1,
n_estimators=50,
random_state=487)
rf.fit(train_data_x, train_data_y)测试结果含训练数据集的测试+测试数据集的测试
python
# '''测试结果[含训练数据集的测试+测试数据集的测试]'''
train_predicted=rf.predict(train_data_x)#训练数据集的预测结果
print('RF的train:\n',metrics.classification_report(train_data_y,train_predicted))
test_predicted=rf.predict(test_data_x)#训练数据集的预测结果
print('RF的test:\n',metrics.classification_report(test_data_y,test_predicted))
a=metrics.classification_report(test_data_y,test_predicted,digits=6)#digits表示保倒有效位数
b=a.split()
RF_result['recall_0']=float(b[8])#添加类别为0的召回率
RF_result['recall_1']=float(b[11])#添加类别2的付四率
RF_result['recall_2']=float(b[16])#添加类别为2的召回半
RF_result['recall_3']=float(b[21])#添加类别为3的什问率
RF_result['acc']=float(b[25])#添加accuracy的结果
result_data['acc']=RF_result#result datg是总体的结果,
print('rf结束')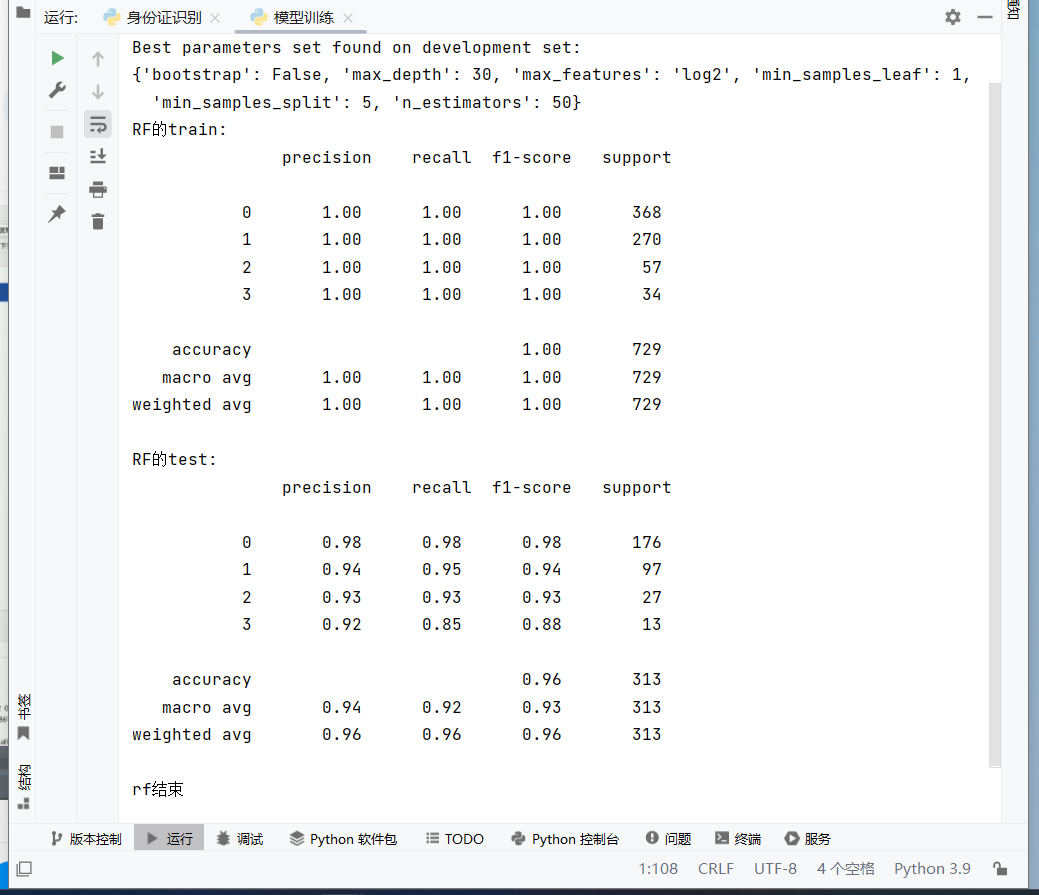
训练集准确率:1
测试集准确率:0.96
随机森林准确率更高,泛化能力极强,几乎没有过拟合。
3.支持向量机算法
数据提取
python
import pandas as pd
from sklearn import metrics
'''数据提取'''
train_data=pd.read_excel(r'训练数据集[平均值填充].xlsx')
train_data_x=train_data.iloc[:,1:]#训练数据集的特征
train_data_y=train_data.iloc[:,0]#训练数据集的测试标签label
test_data = pd.read_excel(r'测试数据集[平均值填充].xlsx')
test_data_x=test_data.iloc[:,1:]#测试数据集的特征
test_data_y=test_data.iloc[:,0]#测试数据集的测试标簽label
result_data={}#用来保存后面6种算法的结果。支持向量积SVM代码实现
python
#'''--------------------支持向量机----------------------------------'''
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
#定义参数网络
param_grid = {
'C':[0.01,0.1,1,2],
'kernel':['linear','poly','rbf','sigmoid'],#核函数类型
'degree':[2,3,4,5],#多项式核函数的阶数,仅在'ploy'核函数下有效
'gamma':['scale','auto']+[1],#RBF,poly和sigmoid的核函数参数
'coef0':[0.1],#和函数中的独立项,仅在'poly'和'sigmoid'核函数下有效
}
svc = SVC()#创建SVC分类器实例
#创建GridSearchCV对象
grid_search=GridSearchCV(svc,param_grid,cv=5)#五折交叉验证
#在训练集上执行网络搜索
grid_search.fit(train_data_x,train_data_y)
#输出最佳参数
print("Best parameters set found on development set:")
print()
print(grid_search.best_params_)建立模型,测试结果
python
#下面的参数均已通过网格搜索算法调优
SVM_result ={}
svm = SVC (C=1,coef0=0.1,degree=4,gamma=1,kernel='poly',probability=True,random_state=100)
svm.fit(train_data_x,train_data_y)
test_predicted=svm.predict(test_data_x)#训练数据集的预测结果
print('SVM的test:\n',metrics.classification_report(test_data_y,test_predicted))
a=metrics.classification_report(test_data_y,test_predicted,digits=6)
b=a.split()
print(a)
SVM_result['recall_0']=float(b[6])#添加类别为0的召回率
SVM_result['recall_1']=float(b[11])#添加类别为1的召回率
SVM_result['recall_2']=float(b[16])#添加类别为2的召回率
SVM_result['recall_3']=float(b[25])#添加类别为3的召回率
SVM_result['acc']=float(b[25])#添加accutancy的结果
result_data['SVM']=SVM_result运行结果: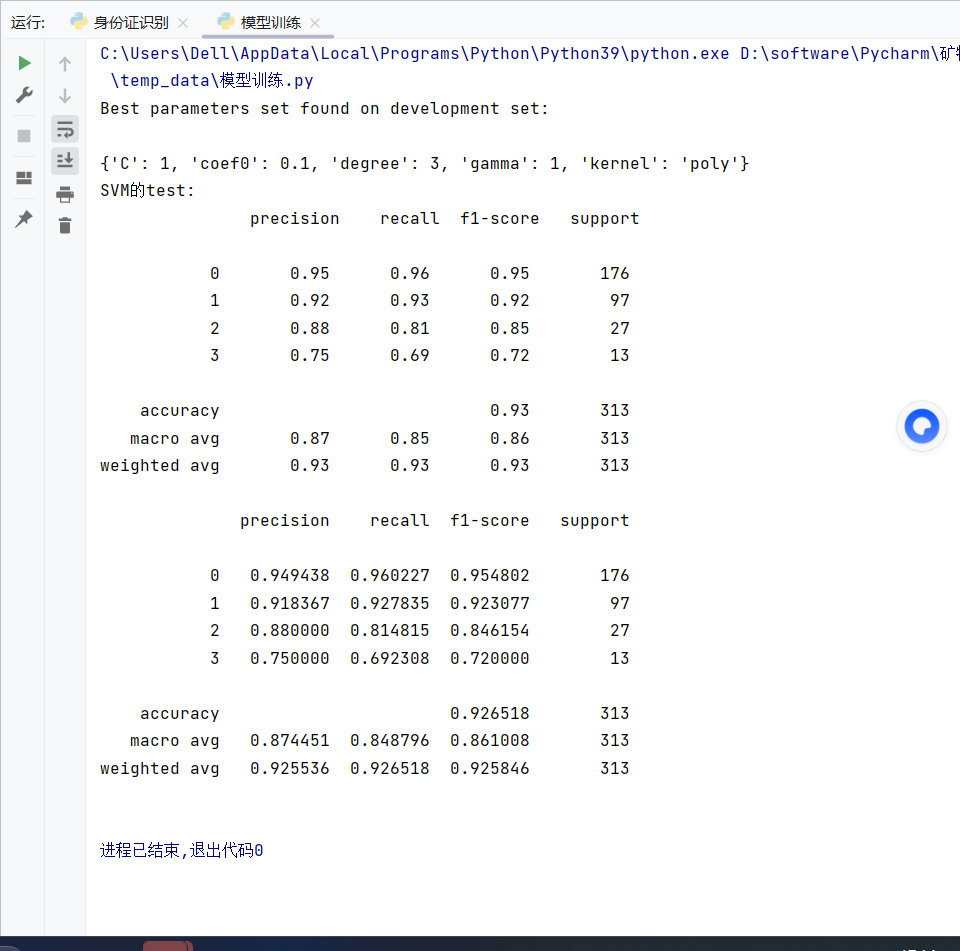
4.AdaBoost算法:
AdaBoost算法是集成学习算法中的stacking方法

随机森林和XGBoost使用的基学习器都是决策树,而AdaBoost可以使用其他各种弱学习器,集成学习。
数据提取
python
import pandas as pd
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore', category=FutureWarning) # 屏蔽FutureWarning
'''数据提取'''
train_data=pd.read_excel(r'训练数据集[平均值填充].xlsx').dropna(how='any')
train_data_x=train_data.iloc[:,1:]#训练数据集的特征
train_data_y=train_data.iloc[:,0]#训练数据集的测试标签label
test_data = pd.read_excel(r'测试数据集[平均值填充].xlsx').dropna(how='any')
test_data_x=test_data.iloc[:,1:]#测试数据集的特征
test_data_y=test_data.iloc[:,0]#测试数据集的测试标簽label
result_data={}#用来保存后面6种算法的结果。AdaBoost算法代码实现:
python
#--------------------AdaBoost算法-------------------------
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
ada = AdaBoostClassifier(algorithm='SAMME',random_state=0)
param_grid={
'n_estimators':[50,100,200],#弱分类器的数量
'learning_rate':[0.01,0.1,0.5,1.0],#学习率
'algorithm':['SAMME','SAMME.R'],#提升算法的类型
'estimator':[DecisionTreeClassifier(max_depth=1),DecisionTreeClassifier(max_depth=2)]
}
abf = AdaBoostClassifier(n_estimators=100,random_state=0)#创建AdaBoost分类器
grid_search = GridSearchCV(abf,param_grid,cv=5)#创建GridSearchCV对象
#在训练集上执行网格搜索
grid_search.fit(train_data_x,train_data_y)
#输出最佳参数
print("Best parameters set found on development set :\n ")
print(grid_search.best_params_)
AdaBoostClassifier_result={}
abf = AdaBoostClassifier(algorithm='SAMME',
estimator=DecisionTreeClassifier(max_depth=2),
n_estimators=200,
learning_rate=1.0,
random_state=0)#创建AdaBoost分类器
abf.fit(train_data_x,train_data_y)
train_predicted=abf.predict(train_data_x)#训练数据集的预测结果
print("AdaBoost的train:\n",metrics.classification_report(train_data_y,train_predicted))
test_predicted = abf.predict(test_data_x)#训练数据集的预测结果
print("AdaBoost的test:\n",metrics.classification_report(test_data_y,test_predicted))
a=metrics.classification_report(test_data_y,test_predicted,digits=6)
b=a.split()
AdaBoostClassifier_result['recall_0']=float(b[6])
AdaBoostClassifier_result['recall_1']=float(b[11])
AdaBoostClassifier_result['recall_2']=float(b[16])
AdaBoostClassifier_result['recall_3']=float(b[21])
AdaBoostClassifier_result['acc']=float(b[25])
result_data['AdaBoost']=AdaBoostClassifier_result运行结果: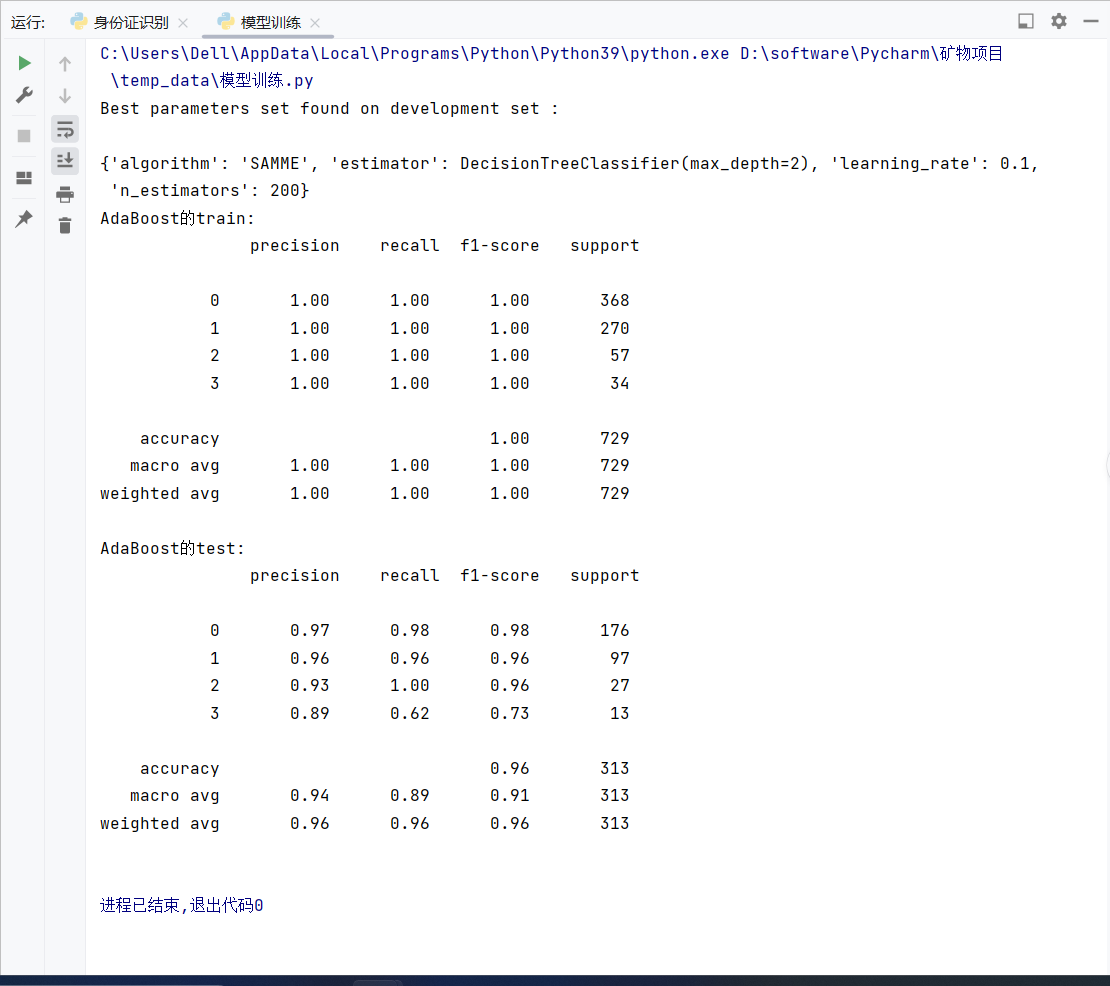
训练集准确率:1
测试集准确率:0.96
5.高斯贝叶斯(GNB)算法:要求是连续性的变量
本项目矿物数据文件中的数据矿物的含量就是连续的变量
代码显示:
python
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore', category=FutureWarning) # 屏蔽FutureWarning
'''数据提取'''
train_data=pd.read_excel(r'训练数据集[平均值填充].xlsx').dropna(how='any')
train_data_x=train_data.iloc[:,1:]#训练数据集的特征
train_data_y=train_data.iloc[:,0]#训练数据集的测试标签label
test_data = pd.read_excel(r'测试数据集[平均值填充].xlsx').dropna(how='any')
test_data_x=test_data.iloc[:,1:]#测试数据集的特征
test_data_y=test_data.iloc[:,0]#测试数据集的测试标簽label
result_data={}#用来保存后面6种算法的结果。
#---------------------GNB高斯贝叶斯算法------------------------------
from sklearn.naive_bayes import GaussianNB
GNB_result={}
gnb = GaussianNB()#创建高斯朴素贝叶斯分类器
gnb.fit(train_data_x,train_data_y)
train_predicted=gnb.predict(train_data_x)#训练数据的预测结果
print('GNB的train:\n',metrics.classification_report(train_data_y,train_predicted))
test_predicted = gnb.predict(test_data_x)#训练数据集的预测结果
print('GNB的test:\n',metrics.classification_report(test_data_y,test_predicted))
a=metrics.classification_report(test_data_y,test_predicted,digits=6)
b=a.split()运行结果: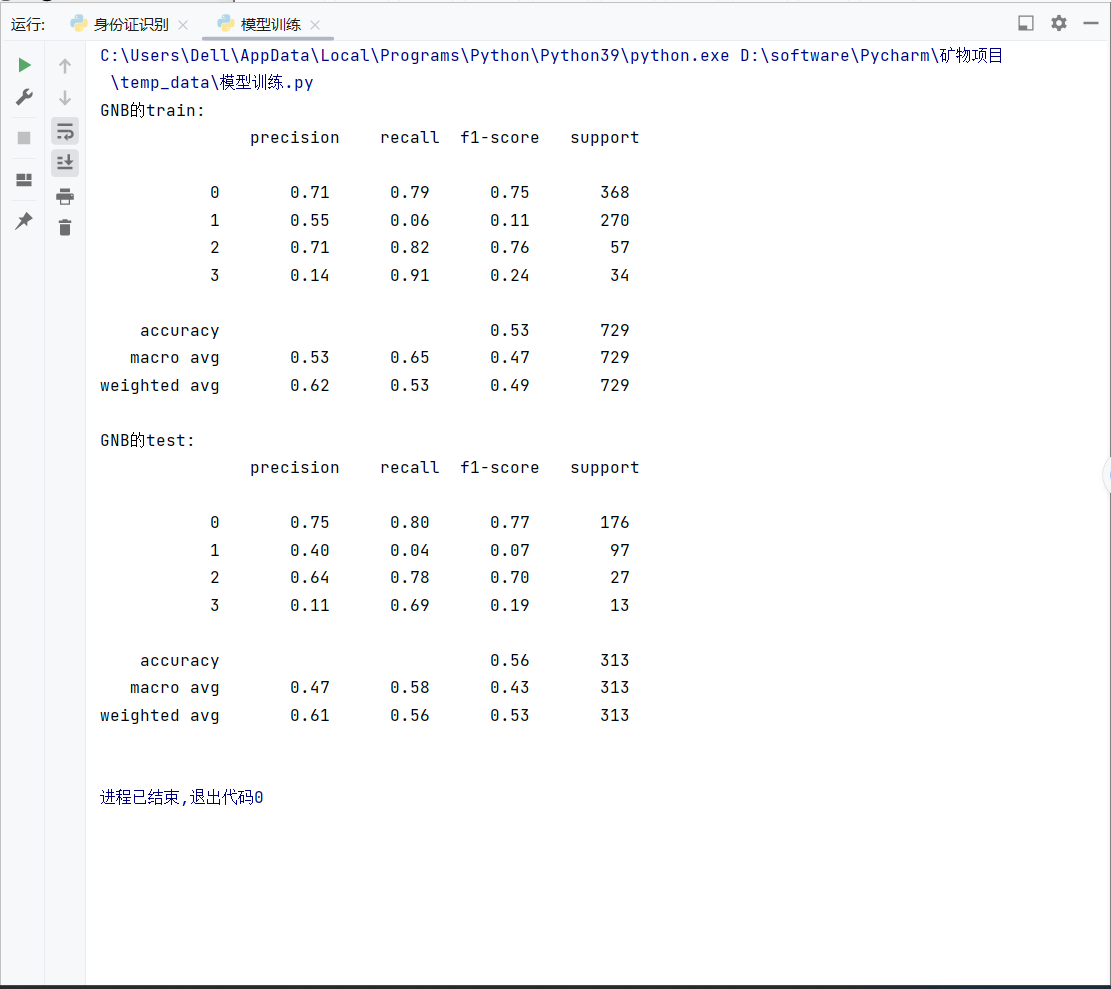
高斯贝叶斯算法准确率太低,已经过时。
6.XGBoost算法
Xgboost算法也是集成算法之一
示例代码如下:读取数据
python
import pandas as pd
from sklearn import metrics
import warnings
warnings.filterwarnings('ignore', category=FutureWarning) # 屏蔽FutureWarning
'''数据提取'''
train_data=pd.read_excel(r'训练数据集[平均值填充].xlsx').dropna(how='any')
train_data_x=train_data.iloc[:,1:]#训练数据集的特征
train_data_y=train_data.iloc[:,0]#训练数据集的测试标签label
test_data = pd.read_excel(r'测试数据集[平均值填充].xlsx').dropna(how='any')
test_data_x=test_data.iloc[:,1:]#测试数据集的特征
test_data_y=test_data.iloc[:,0]#测试数据集的测试标簽label
result_data={}#用来保存后面6种算法的结果。建立模型,测试结果
python
import xgboost as xgb
#
#---------------------------XGBoost算法----------------
XGBoost_result={}
xgb_model = xgb.XGBClassifier(learning_rate=0.05,#学习率(越小越稳定)
n_estimators=200,#树的数量
num_class=5,
max_depth=7,
min_child_weight=1,
gamma=0,
subsample=0.6,
colsample_bytree=0.8,
objective='multi:softmax',
seed=0)#学习率
xgb_model.fit(train_data_x,train_data_y)
train_predicted=xgb_model.predict(train_data_x)#训练数据集的预测结果
print("XGBoost的train:\n",metrics.classification_report(train_data_y,train_predicted))
test_predicted = xgb_model.predict(test_data_x)#训练数据集的预测结果
print("XGBoost的test:\n",metrics.classification_report(test_data_y,test_predicted))
a=metrics.classification_report(test_data_y,test_predicted,digits=6)
b=a.split()
XGBoost_result['recall_0']=float(b[6])
XGBoost_result['recall_1']=float(b[11])
XGBoost_result['recall_2']=float(b[16])
XGBoost_result['recall_3']=float(b[21])
XGBoost_result['acc']=float(b[25])运行结果: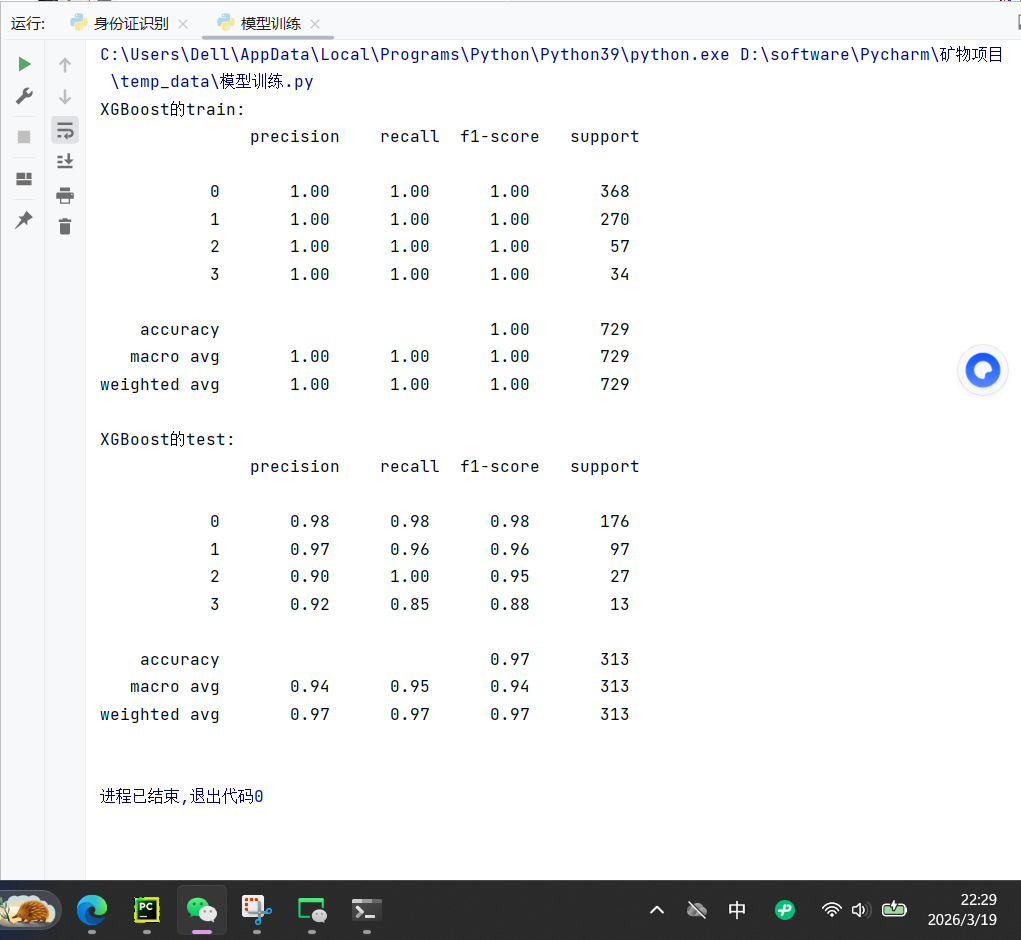
XGBoost 是你目前所有模型中效果最好的:
-
测试集准确率 97%,比 RF 高 1%,比 LR 高 10%;
-
类别 2 召回率 100%,对小样本类别的识别能力极强;
-
训练集全对、测试集 97% 准确率,几乎无过拟合,泛化能力拉满。
XGBoost 模型在你的矿物分类数据集上表现极佳,训练集完全拟合,测试集准确率高达 97%,是目前最优的分类模型