简介
在此记录的为langchain v1.x.
以下所有demo都是使用云端模型,我是买的阿里云百炼,自己实验demo完全不贵。
代码运行的时候我是定义了一个全局变量chatmodel。
python
chat_model = ChatTongyi(model="qwen3-max")为了美观,并且方便以后我自己回溯,所以均没有把import放入。如果想要执行实验,那么就去我的github:https://github.com/zpskt/SmartCS/tree/main/study
官方文档
https://langchain-doc.cn/v1/python/langchain/short-term-memory.html
概览
短期记忆能够记住单线程或者对话中之前的所有交互。
即你构建的prompt里面的所有数据,比如HumanMessage和A iMessage、systemMessage。
保存记忆
保存记忆是指将用户会话和AI回答都保存下来,至于是内存还是文档,数据库都由开发者自行抉择。
保存到内存中
python
def save_memory():
'''
保存历史记忆
:return:
'''
memory = InMemorySaver()
agent = create_agent(
chat_model,
tools=None,
checkpointer=memory,
)
config = {"configurable": {"thread_id": "1"}}
before_memory = memory.get(config)
print(before_memory)
res = agent.invoke(
{"messages": [{"role": "user", "content": "我叫张鹏"}]},
config, # [!code highlight]
)
after_memory = memory.get(config)
print(after_memory)
for msg in res["messages"]:
msg.pretty_print()这种方式是保存到内存中,langchain会自动帮我们进行维护,在调用agent.invoke里面的configurable是必填的,这块的内存也是根据thread_id存储。
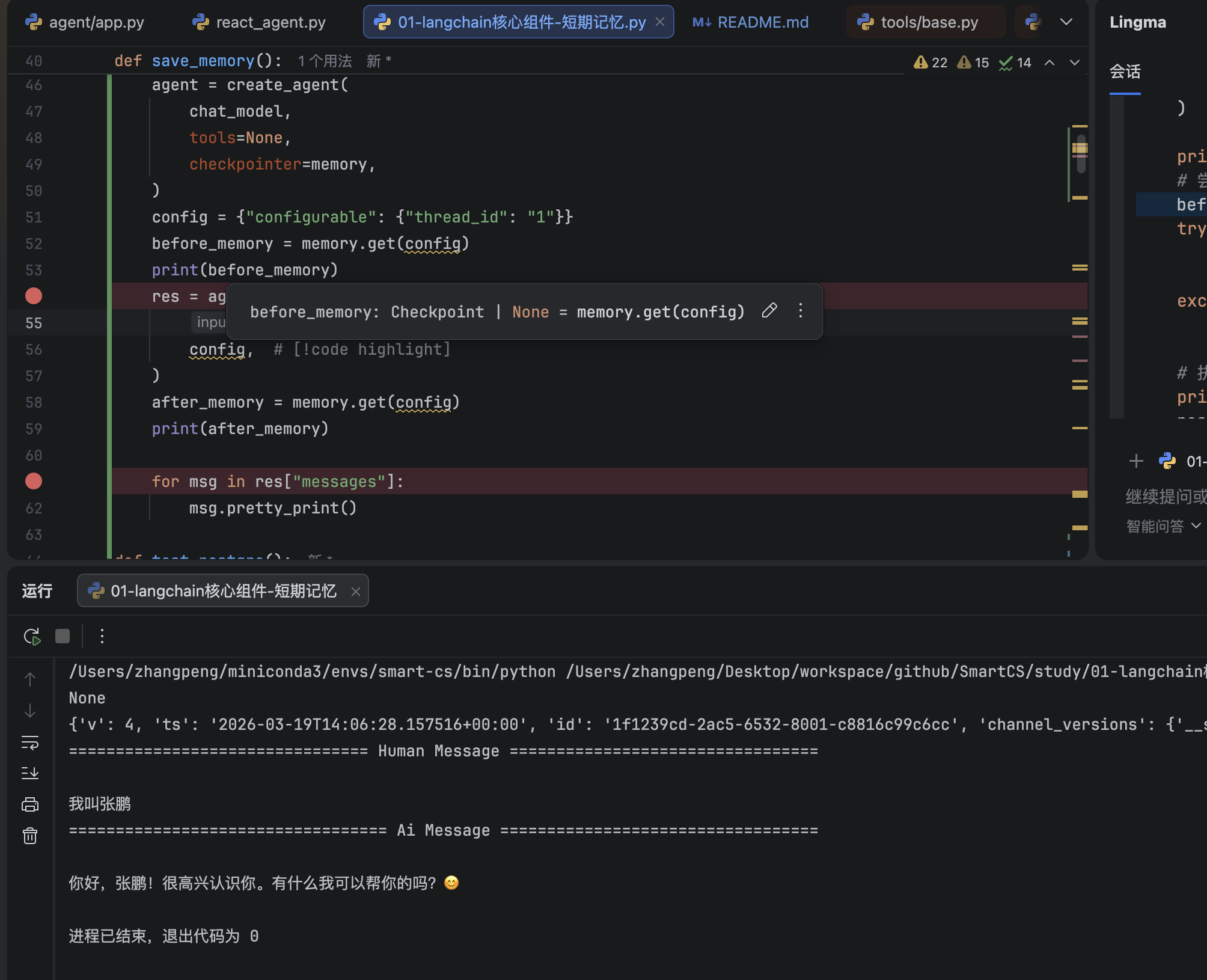
通过打断点也能看到前后值的对比
保存到数据库
一般默认使用postgre数据库,相比于mysql而言,可以支持向量存储。
曾经看到过有人不推荐生产使用,但是我感觉绝大部分场景都是企业内部自己的私有知识智能体,这个数据库完全满足。
python
def test_postgre():
import psycopg
# 测试 psycopg 能否正常连接
conn = psycopg.connect(
user="postgres",
password="zhangpeng",
dbname="maxkb",
host="localhost"
)
print("psycopg 连接 PostgreSQL 成功!")
conn.close()
def save_memory_to_postgresql():
'''
保存上下文记忆到数据库中
:return:
'''
from langgraph.checkpoint.postgres import PostgresSaver # [!code highlight]
DB_USER = "postgres"
DB_PASSWORD = "zhangpeng"
DB_URI = f"postgresql://{DB_USER}:{DB_PASSWORD}@localhost:5432/maxkb?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 会自动创建表 都是checkpoint开头的表
agent = create_agent(
chat_model,
tools = [get_user_info],
checkpointer=checkpointer, # [!code highlight]
)
res = agent.invoke(
{"messages": [{"role": "user","content": "你好,我叫张鹏"}]},
{"configurable": {"thread_id": "1"}}, # [!code highlight]
)
for msg in res["messages"]:
msg.pretty_print()这里是根据dburl创建一个数据库连接,在此基础上创建agent,然后所有的会话都会被持久到数据库中。
访问短期记忆
不仅要写,我们还要读记忆。
通过工具访问
python
@tool
def get_user_info(
runtime: ToolRuntime
) -> str:
"""查看用户信息"""
user_id = runtime.state["user_id"]
return "用户是张鹏" if user_id == "zhangpeng" else "不认识的 user"
class CustomState(AgentState):
"""
这里要提前定义好要存储的key,最终值会出现在runtime.state里面
"""
user_id: str
user_name: str
def read_memory_by_tool():
"""
通过工具访问记忆
这里state_schema里面传入一个自定义AgentState类,并且定义了里面的key值
通过get_user_info工具去查询用户信息
:return:
"""
agent = create_agent(
chat_model,
[get_user_info],
state_schema=CustomState, # [!code highlight]
)
result = agent.invoke({
"messages": "查看用户信息",
"user_id": "zhangpeng"
})
print(result["messages"][-1].content)这里我们自定义了一个方法get_user_info,并且告诉agent,可以用这个方法来查询用户信息。当用户提问时(传入了user_id),llm大脑会调用这个方法,这个方法提取到runtime中state中的user_id,返回。
可以在工具方法中打一个断点,如下图一样
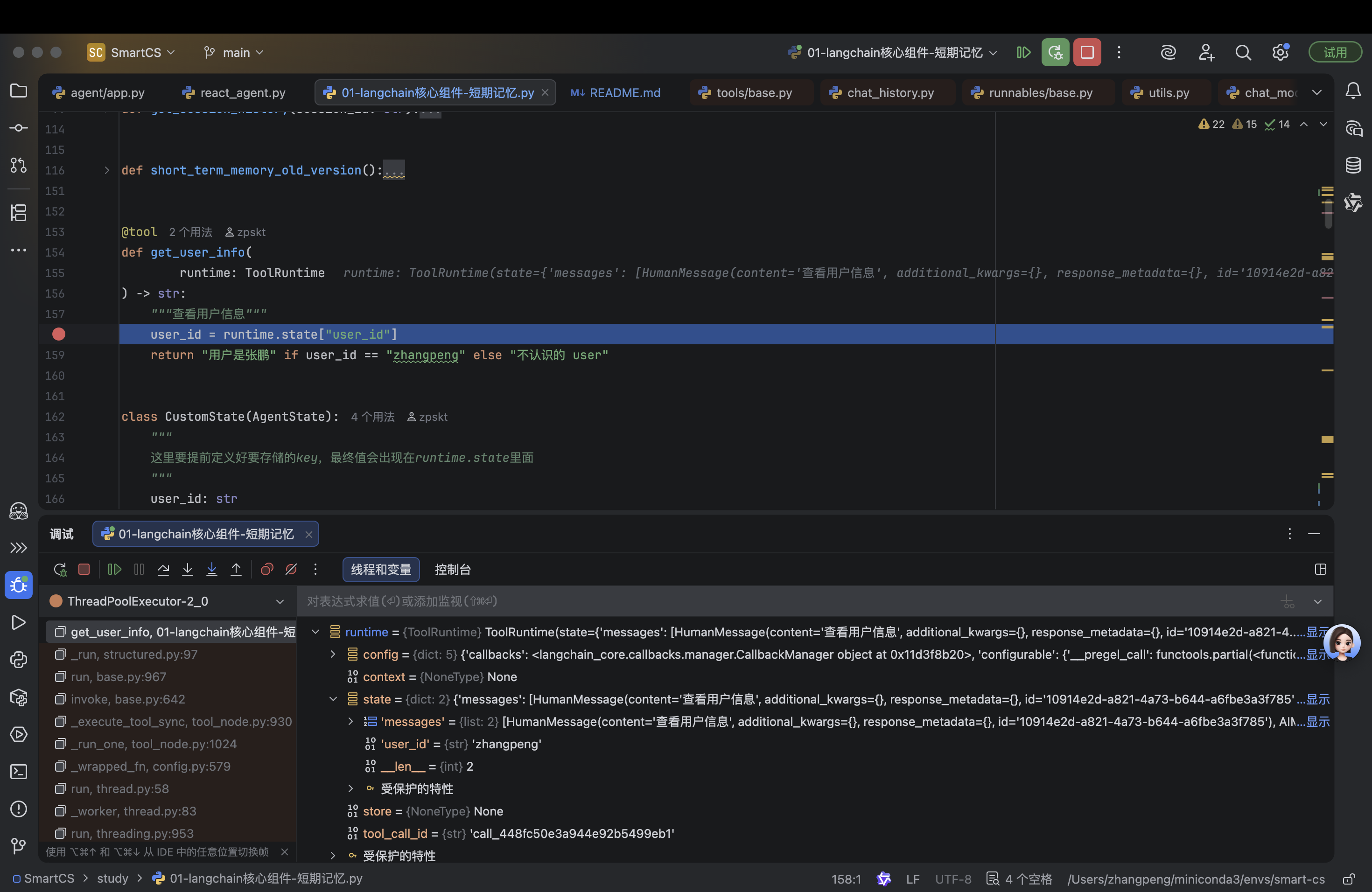
这里可以看到我们定义的CustomState(我们定义了user_id)里面的userId值已经在invoke的时候传值了。
从中间件读取值
基本上是一样的,没啥区别,感兴趣就看代码。
编辑记忆
python
@after_model
def validate_response(state: AgentState, runtime: Runtime) -> dict | None:
"""删除聊天信息里面的敏感词"""
STOP_WORDS = ["password", "secret"]
last_message = state["messages"][-1]
if any(word in last_message.content for word in STOP_WORDS):
return {"messages": [RemoveMessage(id=last_message.id)]}
return None
def read_memory_by_middleware_after_model():
agent = create_agent(
model=chat_model,
tools=[],
middleware=[validate_response],
checkpointer=InMemorySaver(),
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "你好,我的password是 123456,我的secret是zhangpeng"}, config)
final_response = agent.invoke({"messages": "设置 password 和 secret 的原则是什么?"}, config)
for msg in final_response["messages"]:
msg.pretty_print()
# 这里其实可以看到看不到最后一条的AI回答,因为已经被我们删除了这里是写了一个中间件,设置的aftermodel,即执行了模型以后就会执行一次函数,类似于aop
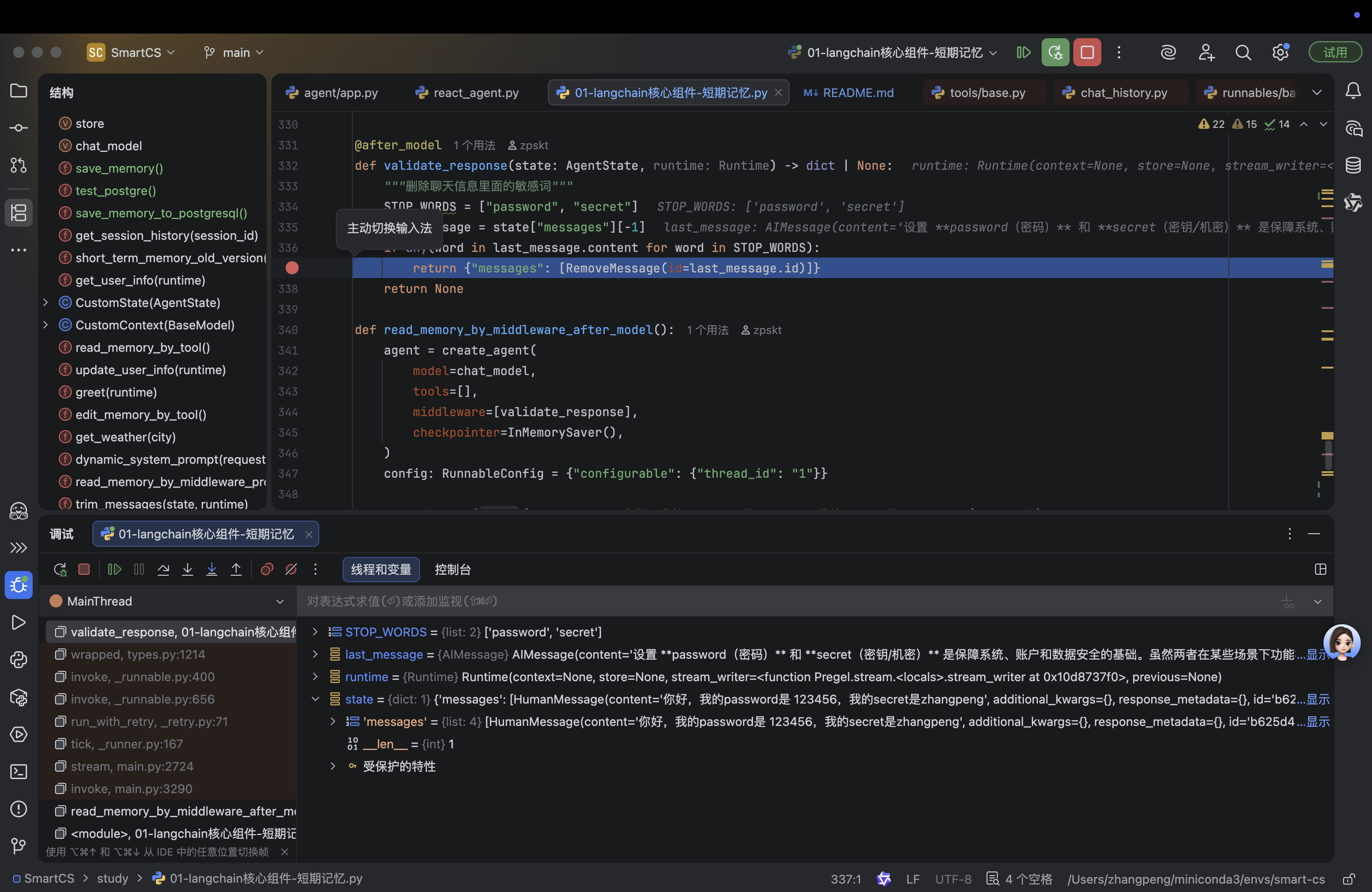
精简记忆
我个人觉得这个是实际使用频率最高的,就像豆包一样,我们都会只关注用户近几轮的对话,对于更早的对话,我们一般都是放弃、精简、总结、、等策略。
python
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
""" 仅保留最后几条消息以适应上下文窗口。"""
messages = state["messages"]
print(f"=== trim_messages 执行 ===")
print(f"当前消息数量:{len(messages)}")
for i, msg in enumerate(messages):
print(f" [{i}] {msg.__class__.__name__}: {str(msg)[:50]}...")
print(f"========================")
if len(messages) <= 3:
return None #返回none,即不做任何修改
first_msg = messages[0]
# 奇数保留三条,偶数保留四条
recent_messages = messages[-3:] if len(messages) % 2 == 0 else messages[-4:]
# 只保留第一条和最近几条消息
new_messages = [first_msg] + recent_messages
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES), # 删除所有旧消息
*new_messages # 插入精简后的新消息
]
}
def read_memory_by_middleware_before_model():
"""
在模型执行前获取短期记忆
:return:
"""
# 创建内存检查点保存器
memory = MemorySaver()
agent = create_agent(
chat_model,
tools=[get_weather],
middleware=[trim_messages],
checkpointer=memory, # [!code highlight] 添加检查点保存器
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "你好,我的姓名是张鹏"}, config)
agent.invoke({"messages": "你好,我的性别是男性"}, config)
agent.invoke({"messages": "写一个关于猫的短诗"}, config)
agent.invoke({"messages": "现在相同的事情弄个关于狗的"}, config)
final_response = agent.invoke({"messages": "我的名字是什么?我都让你干了什么事?我的性别是什么?"}, config)
final_response["messages"][-1].pretty_print()
看我的日志打印可以看到,有关于性别的humanMessage已经被删除了