一、背景介绍
某客户生产环境部署了一套海山数据库PostgreSQl版一主两备高可用集群,硬件配置为:
- CPU:Intel Xeon Silver 4210R(32 核)
- 内存:128 GB
- 存储:1.6 TB HDD
- shared_buffers 配置为1/4(32 GB)
业务系统中存在一张核心日志表 warn_msg_tab_test,用于存储消息审计记录。该表采用 按时间范围分区(RANGE on mo_time) ,总数据量已超过 10 亿行,单日数据量约 5000 万行。
业务侧需对近 20 天的数据进行轮询式分页查询,典型查询并发为 10。压测发现:平均响应时间高达 16 秒,严重影响用户体验和系统吞吐能力。
二、问题分析
1. 表结构与索引概况
CREATE TABLE warn_msg_tab_test (
msg_idx varchar(40) NOT NULL,
src_addr varchar(20) NOT NULL,
dst_addr varchar(20) NOT NULL,
mo_time varchar(14) NOT NULL, -- 格式:YYYYMMDDHH24MISS
mt_time varchar(14) NOT NULL,
sm_content varchar(1600) NULL,
inspect_id varchar(128) NOT NULL,
-- ... 其他字段略 ...
if_show int4 DEFAULT 1 NULL
) PARTITION BY RANGE (mo_time);
-- 关键索引
CREATE INDEX idx_warn_msg_src_mo_test
ON ONLY warn_msg_tab_test
USING btree (src_addr, mo_time DESC);
注:实际每个分区表会继承并创建对应索引。
2. 典型慢查询语句
SELECT
MSG_IDX, SRC_ADDR, DST_ADDR, ..., LINK_FRAUD_CONTENT
FROM WARN_MSG_TAB_TEST t
WHERE
t.MO_TIME >= '20260103000000'
AND t.MO_TIME < '20260104000000'
AND t.SRC_ADDR = '13800000002'
ORDER BY t.MO_TIME DESC
OFFSET 4669
LIMIT 10;
3. 执行计划与瓶颈定位
执行计划如下(简化):
Limit (cost=18828.53...18868.85 rows=10 width=350)
-> Index Scan using idx_warn_msg_src_mo_test on partition_20260103
Index Cond: (src_addr = '13800000002' AND mo_time in range)
关键问题:
- 虽然使用了 (src_addr, mo_time DESC) 索引,但 OFFSET 4669 导致数据库必须扫描前 4679 行;
- 每行需回表读取完整数据(含大字段如 sm_content, inspect_info 等),I/O 和 CPU 开销巨大;
- 表数据远超内存容量(10 亿行 vs 32GB shared_buffers),无法缓存,大量随机 I/O;
- 10 并发下,磁盘和 CPU 成为瓶颈,平均耗时 16 秒。
只需 10 行结果,却要扫描近 5000 行数据。
三、优化思路与方案
优化目标
将"扫描 N+10 行"变为"只扫描 10 行" ,避免无效回表。
技术策略:延迟回表(Deferred Lookup)
- 第一步 :仅通过索引获取所需行的关键字段(msg_idx, mo_time**)** ------ 利用覆盖索引,避免回表;
- 第二步:通过 msg_idx 主键(唯一标识)精确回表,仅取 10 行完整数据。
前提:msg_idx 是业务主键,具有唯一性,可作为回表依据。
优化后 SQL(使用 CTE + JOIN)
WITH page_keys AS (
SELECT mo_time, msg_idx
FROM warn_msg_tab_test
WHERE
mo_time >= '20260103000000'
AND mo_time < '20260104000000'
AND src_addr = '13800000002'
ORDER BY mo_time DESC
OFFSET 4669
LIMIT 10
)
SELECT
t.MSG_IDX,
-- ... 其他字段略 ...
FROM page_keys k
JOIN warn_msg_tab_test t ON t.msg_idx = k.msg_idx
ORDER BY k.mo_time DESC;
为什么有效?
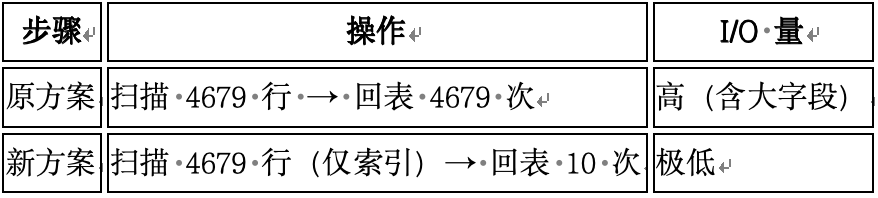
第一步的 CTE 只访问索引(Index-Only Scan),不触碰表数据。
四、效果验证

压测 10 分钟,10 并发稳定在 5ms 内,系统资源占用大幅降低。
五、经验总结
1.深分页是性能杀手
OFFSET N 在大数据量下必然导致性能劣化,应尽量避免。
2.延迟回表是通用优化手段
适用于所有"只需少量结果但需跳过大量数据"的场景,尤其在宽表(含大字段)中效果显著。
3.索引设计需配合查询模式
本例中 (src_addr, mo_time DESC) 索引支持了高效过滤和排序,是优化成功的前提。
4.CTE(WITH 子句)提升可读性与执行效率
海山PG对 CTE 的物化(Materialization)行为在此场景下恰好符合预期。
六、建议
1.长期方案:改用游标分页(Cursor-based Pagination),如 WHERE mo_time < last_seen_time,彻底规避 OFFSET;
2.索引增强:若 msg_idx 不在索引中,可考虑创建 包含索引(Covering Index):
CREATE INDEX CONCURRENTLY idx_covering ON warn_msg_tab_test (src_addr, mo_time DESC) INCLUDE (msg_idx);
3.分区裁剪:确保查询条件能精准命中单个分区,避免跨分区扫描。
4.海山PG将在后续内核层面考虑将offset下推至Index Only Scan中执行,内核层面优化SQL执行性能。
结语:性能优化的本质,是在理解数据访问模式的基础上,让数据库做最少的必要工作。本次优化通过"先找钥匙,再开门"的思路,将无效劳动降至最低,实现了数量级的性能飞跃。
移动云数据库团队历经十余年技术深耕磨砺,专注于云原生数据库领域,成功打造自有品牌---海山数据库。自主研发成果获国家科技进步奖等40余项权威认证。海山数据库在高扩展性和高可用性方面表现突出,支持1主15备架构,百TB级存储,秒级库容扩展,性能较原生PostgreSQL提升3倍,存储资源节约50%以上,实现了高性能与低成本的完美平衡。