1、Nginx作为反向代理服务器,可以实现哪些负载均衡策略?如果一台上游服务器(Upstream)宕机,Nginx如何处理?
● 负载均衡策略
四大负载均衡策略,Nginx提供了多种策略,就像不同的兵法,适用于不同的作战场景。
○ 轮询 (Round Robin)
默认策略,将请求按时间顺序逐一分配到不同的后端服务器。
http {
upstream geek_mall {
server 192.168.1.101:8080; # 服务器A
server 192.168.1.102:8080; # 服务器B
server 192.168.1.103:8080; # 服务器C
}
server {
listen 80;
location / {
proxy_pass http://geek_mall;
}
}
}-
请求流向:第1个请求 -> A,第2个请求 -> B,第3个请求 -> C,第4个请求 -> A,如此循环。
-
适用场景 :所有后端服务器硬件配置、性能几乎完全相同的情况。这是最单纯、最公平的策略。
○ 加权轮询 (Weighted Round Robin):
根据服务器配置和性能,为其分配不同的权重。权重越高,被分配到的请求越多。
upstream geek_mall {
server 192.168.1.101:8080 weight=3; # 高性能服务器,权重3
server 192.168.1.102:8080 weight=2; # 中等性能,权重2
server 192.168.1.103:8080 weight=1; # 旧机器,权重1
}-
请求流向:在多个请求周期内,请求会按3:2:1的比例分配。比如,前6个请求的分配可能是:A, A, A, B, B, C。
-
适用场景 :后端服务器性能不均。新采购的高配置服务器理应承担更多流量,充分发挥集群价值。
-
对比分析:与简单轮询相比,加权轮询考虑了服务器的异构性,避免了"大锅饭"式的平均主义,资源利用率更高。
○ IP哈希 (ip_hash):
根据客户端IP的哈希结果分配请求,同一个IP的客户端总会访问到同一个后端服务器,可解决会话(Session)保持问题。
upstream geek_mall {
ip_hash; # 启用IP哈希策略
server 192.168.1.101:8080;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
}-
请求流向 :Nginx会对客户端的IP地址进行哈希计算,得到一个数值,然后根据服务器数量取模,确保同一个IP的请求永远落到同一台后端服务器上。
-
解决核心问题 :Session保持(会话保持)。如果用户的登录状态(Session)只存储在服务器B的内存里,那么他下次请求如果被分配到服务器C,就会被提示"未登录",体验极差。IP哈希从根本上解决了这个问题。
-
潜在缺点:如果某个IP的用户特别活跃(比如爬虫或网红主播),会导致其对应的服务器压力过大,破坏了负载均衡的初衷。
○ 最少连接 (least_conn):
将请求优先分配给当前活跃连接数最少的后端服务器。
upstream geek_mall {
least_conn; # 启用最少连接策略
server 192.168.1.101:8080;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
}-
请求流向:Nginx会实时跟踪每个后端服务器当前的活跃连接数,新的请求会被发送给连接数最少的那台服务器。
-
适用场景 :请求处理时间长短不一的场景。比如,有些请求是简单的商品查询(快),有些是复杂的订单生成(慢)。最少连接数策略能动态地将新请求导向当前相对"清闲"的服务器,避免某些服务器因处理长任务而积压请求。
● 故障处理:
模式一:被动健康检查(默认熔断机制)
这是Nginx自带的、开箱即用的功能。就像电路中的"保险丝"。
upstream geek_mall {
server 192.168.1.101:8080 max_fails=2 fail_timeout=30s;
server 192.168.1.102:8080 max_fails=2 fail_timeout=30s;
server 192.168.1.103:8080 max_fails=2 fail_timeout=30s;
}-
核心参数:
-
max_fails:在fail_timeout时间内,连续失败多少次,才标记服务器不可用。默认是1次。 -
fail_timeout:有两个含义:1) 计算失败次数的时间窗口;2) 服务器被标记为不可用后,多久后再去尝试探测是否恢复。默认是10秒
-
故障发生时的流程:
-
用户请求到来:Nginx将请求转发给服务器B。
-
首次失败:连接超时或收到错误码(如502 Bad Gateway)。Nginx记下一次失败。
-
二次失败 :在接下来的30秒内,又一个请求被分给B,再次失败。失败次数达到
max_fails=2。 -
熔断 :Nginx立即将服务器B标记为"不可用",并启动一个30秒的"熔断计时器"。在接下来的30秒内,所有新请求都会跳过B,只发给A和C。系统实现了快速自保。
-
探活与自愈 :30秒的
fail_timeout过后,Nginx会"小心翼翼地"尝试将下一个新请求再次发给B。-
如果成功:B被重置为"健康"状态,重新加入集群,熔断结束。
-
如果依然失败:B继续被标记为不可用,再进入下一个30秒的熔断期。
-
模式二:主动健康检查
Nginx通过主动健康检查(需要集成nginx_upstream_check_module模块)或被动健康检查(默认)来探测上游服务器状态。
被动检查有个缺点:必须等到有真实用户请求失败时才会触发。这意味着总要有一个"倒霉"的用户去触发这个错误。
对于要求高可用的金融、支付等核心业务,我们需要更主动的机制。这通常需要集成第三方模块,如 nginx_upstream_check_module。
upstream geek_mall {
server 192.168.1.101:8080;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
check interval=3000 rise=2 fall=3 timeout=1000 type=http;
check_http_send "HEAD /health_check.html HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}-
工作机制:
-
interval=3000:每3秒检查一次。 -
type=http:发送HTTP请求进行检查。 -
check_http_send:定义发送的请求内容,比如请求一个特定的健康检查页面。 -
check_http_expect_alive:如果返回2xx或3xx状态码,则认为健康。 -
fall=3:连续失败3次,才标记为不健康。 -
rise=2:从不健康状态恢复,需要连续成功2次。
-
-
巨大优势 :在用户请求到达之前,Nginx就已经知道了服务器B宕机了。 当故障发生时,Nginx能瞬间 将B从可用列表中剔除,没有任何用户会感受到故障。实现了无缝故障转移。
HTTP状态码分类(解释 check_http_expect_alive:如果返回2xx或3xx状态码,则认为健康)
| 状态码范围 | 类别 | 含义 | 常见状态码示例 |
|---|---|---|---|
| 2xx | 成功 | 请求已被服务器成功处理 | 200 OK, 201 Created |
| 3xx | 重定向 | 需要客户端进一步操作 | 301 Moved Permanently |
| 4xx | 客户端错误 | 请求包含错误语法或无法完成 | 404 Not Found, 403 Forbidden |
| 5xx | 服务器错误 | 服务器处理请求失败 | 500 Internal Server Error |
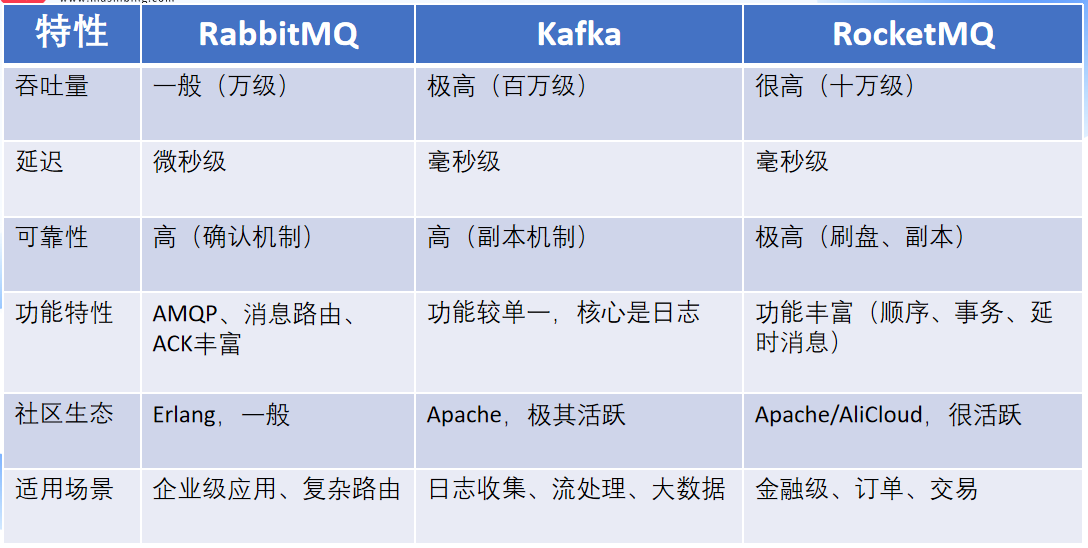
2、在Kafka、RocketMQ、RabbitMQ之间进行技术选型时,你会考虑哪些因素?
场景1:电商平台订单系统
业务需求:
-
订单创建、支付、发货的状态流转必须严格有序
-
双11期间需要处理百万级订单消息
-
需要保证消息不丢失(资金相关)
-
可能需要延迟消息(如30分钟未支付自动取消)
RocketMQ 最优
-
严格的消息顺序保证
-
完整的事务消息支持
-
内置延迟消息功能
-
经过阿里双11验证的稳定性
场景2:日志收集与实时分析系统
业务需求:
-
收集上千个微服务的运行日志
-
每秒处理百万条日志消息
-
消息允许少量丢失(日志可重复)
-
需要支持多个消费者组(监控、分析、归档)
Kafka 最优
-
天然的高吞吐设计
-
完善的多消费者组机制
-
海量消息堆积能力
-
成熟的流处理生态(Kafka Streams)
场景3:企业级ERP系统集成
业务需求:
-
多个异构系统间消息路由(CRM、财务、仓储)
-
复杂的消息路由规则(基于header、Topic路由)
-
需要多种消息模式(点对点、发布订阅)
-
企业级管理界面和监控
RabbitMQ 最优
-
灵活的Exchange路由机制
-
多种协议支持(AMQP、MQTT等)
-
完善的Web管理界面
-
丰富的客户端支持
3、请简要描述Elasticsearch写入数据和全文检索的基本原理
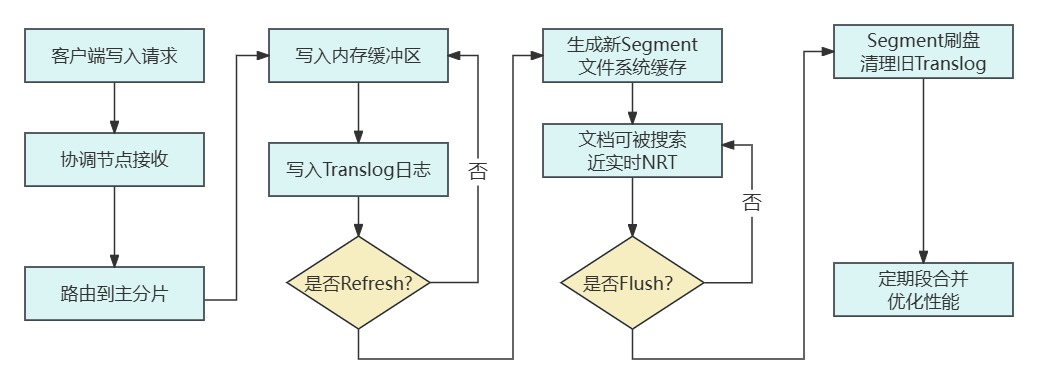
写入原理 (Write)
1、文档首先被写入内存缓冲区和事务日志 (Translog) 中(用于保证数据不丢失)。
2、默认每1秒,内存缓冲区中的文档会被刷新(refresh)到文件系统缓存中,形成一个新的不可变的段 (Segment)。此时文档才变得可被搜索(Near Real-Time)。
3、 随着段的数量增多,ES会定期进行段合并 (Segment Merge),将小段合并成大段,并物理删除标记为删除的文档。
4、 Translog会不断增长,ES会在段被刷盘 (Flush) 到磁盘后清空旧的Translog。
整体流程图如下:
1、内存缓冲区 + Translog(双保险机制)
如果没有Translog会怎样?
-
如果只有内存缓冲区,当服务器突然断电时,所有在内存中未持久化的数据都会丢失
-
Translog的作用:类似于MySQL的Redlog日志,可以有安全性
// 索引设置,控制刷新频率
PUT /blog_articles
{
"settings": {
"index": {
"refresh_interval": "1s", // 每秒刷新一次
"translog": {
"sync_interval": "5s", // Translog刷盘间隔
"durability": "request" // 每次请求都写Translog(最安全)
}
}
}
}2、Refresh操作:近实时搜索的关键
ES是写入数据后搜索延迟的,大概延迟在1秒内,数据先到文件系统缓存,再异步刷盘(不同于传统型数据库:数据直接写入磁盘,可立即查询)
3. 段合并(Segment Merge):空间与性能的权衡
假设连续写入5篇文章:
文档1 → 生成Segment A
文档2 → 生成Segment B
文档3 → 生成Segment C
文档4 → 生成Segment D
文档5 → 生成Segment E合并过程
时间点T1: Segment A + Segment B → 合并为 Segment AB
时间点T2: Segment C + Segment D → 合并为 Segment CD
时间点T3: Segment AB + Segment CD + Segment E → 合并为最终段合并的好处:
-
减少文件句柄数
-
提升搜索性能(减少要搜索的段数)
-
物理删除标记为删除的文档
检索原理 (Search)
分词
查询语句会被分词器 (Analyzer) 拆分成一系列的词条(Token),如"Hello World" -> "hello", "world"。
不同分词器的效果
// 标准分词器(默认)
"Elasticsearch搜索原理" → ["elasticsearch", "搜", "索", "原", "理"]
// IK智能分词器(中文优化)
"Elasticsearch搜索原理" → ["elasticsearch", "搜索", "原理"]
// 关键字分词器(不分词)
"Elasticsearch搜索原理" → ["elasticsearch搜索原理"]倒排索引 (Inverted Index)
正排索引 vs 倒排索引对比:
| 索引类型 | 类比 | 数据结构 | 查询方式 |
|---|---|---|---|
| 正排索引 | 书的内容 | 文档ID → 文档内容 | 按文档ID查找内容 |
| 倒排索引 | 书的索引 | 关键词 → 文档ID列表 | 按关键词查找文档 |
# 文档数据
doc1 = {"id": 1, "title": "Elasticsearch原理", "content": "学习ES基本原理"}
doc2 = {"id": 2, "title": "搜索技术", "content": "Elasticsearch是优秀搜索引擎"}
doc3 = {"id": 3, "title": "大数据原理", "content": "ES在大数据中的应用"}
# 倒排索引构建
倒排索引 = {
"elasticsearch": [1, 2], # 出现在文档1和2中
"原理": [1, 3], # 出现在文档1和3中
"搜索": [2, 3], # 出现在文档2和3中
"技术": [2],
"学习": [1],
"基本": [1],
"优秀": [2],
"大数据": [3],
"应用": [3]
}相关性算分
根据TF-IDF或BM25等算法,计算查询词条与每个文档的相关性分数。
返回结果
按分数排序后,返回最相关的文档列表。
简单案例
GET /blog_articles/_search
{
"query": {
"match": {
"title": "Elasticsearch搜索原理"
}
}
}ES大致的执行过程
1、查询解析:识别为match查询,针对title字段
2、分词处理:将查询词分为["elasticsearch", "搜索", "原理"]
3、倒排索引查找:
3.1"elasticsearch" → [文档1, 文档5, 文档8]
3.2"搜索" → [文档1, 文档3, 文档5]
3.2"原理" → [文档1, 文档8, 文档10]
4、文档集合操作:求交集得到[文档1]
5、相关性评分:计算每个匹配文档的BM25分数
6、结果返回:按分数排序返回4、ShardingSphere有哪些分片算法?以及适合的分片业务场景!
简介ShardingSphere及其分片概念
-
ShardingSphere是一个开源的分布式数据库中间件生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar组成。
-
分片(Sharding)指的是将数据库中的数据按照某种规则分散存储到多个数据节点上,以达到分散负载、提升性能的目的。
分片算法分类
-
根据分片键的数量,分片算法可以分为单分片键算法和复合分片键算法。
-
根据分片算法的特性,可以分为精确分片算法、范围分片算法、复合分片算法等。
1、 取模分片算法(MOD)
-
描述:根据分片键的哈希值或直接值对分片数取模,得到分片位置。
-
配置示例:算法名称:MOD,属性:sharding-count(分片数量)
-
场景:适用于分片键为整数类型,且数据分布均匀的场景。例如,用户ID按4取模,分成4个表。
配置信息:
maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>application.properties
#--分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count=2适用场景:
-
用户表按user_id分片(用户ID通常是自增数字)
-
订单表按order_id分片(订单ID为数值类型)
-
需要数据均匀分布的业务场景
-
分片键为整数类型且分布均匀的情况
优势:
-
数据分布均匀,避免热点问题
-
简单高效,计算开销小
-
易于理解和维护
局限性:
-
分片键必须是整数类型
-
扩容困难,需要数据迁移
-
不支持非数值类型分片键
2、哈希分片算法(HASH)
-
描述:对分片键进行哈希运算,然后根据哈希值分布到不同的分片。
-
配置示例:算法名称:HASH,属性:sharding-count(分片数量)
-
场景:适用于分片键为非整数类型,或者希望将数据均匀分布的场景。例如,用用户名分片,先对用户名进行哈希,再取模。
application.properties
#--分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.type=MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-mod.props.sharding-count=2
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.type=HASH_MOD
spring.shardingsphere.rules.sharding.sharding-algorithms.table-hash-mod.props.sharding-count=2适用场景:
-
用户名、手机号、邮箱等字符串类型分片键
-
需要将非数值数据均匀分布的场景
-
分布式会话存储(按session_id分片)
-
商品SKU分片(按sku_code哈希)
优势:
-
支持任意数据类型分片键
-
数据分布相对均匀
-
适用于高基数字段
局限性:
-
哈希冲突可能导致数据分布不均
-
范围查询效率低
-
扩容需要数据重分布
3、 范围分片算法(RANGE)
-
描述:根据分片键的值范围进行分片。例如,0-1000在分片1,1001-2000在分片2。
-
配置示例:算法名称:RANGE,属性:ranges(范围定义,如"0-1000,1001-2000")
-
场景:适用于分片键是连续数值,且需要按范围查询的场景。例如,按订单金额分片,可以方便地进行范围查询,但可能导致数据倾斜。
application.properties
# 按金额范围分片
spring.shardingsphere.rules.sharding.sharding-algorithms.amount_range.type=BOUNDARY_RANGE
spring.shardingsphere.rules.sharding.sharding-algorithms.amount_range.props.sharding-ranges=1000,5000,10000,50000,100000
# 分片解释:
# amount < 1000 → 分片0(小额订单)
# 1000 <= amount < 5000 → 分片1(中等订单)
# 5000 <= amount < 10000 → 分片2(大额订单)
# 10000 <= amount < 50000 → 分片3(超大额订单)
# amount >= 50000 → 分片4(特殊订单)适用场景:
-
按订单金额分片(小额、中额、大额订单分离)
-
会员等级分片(普通会员、VIP会员、SVIP会员)
-
地区编码分片(按行政区划范围)
-
产品价格区间分片
优势:
-
支持范围查询优化
-
便于按业务特性分区管理
-
适合有明确数值区间的业务
局限性:
-
容易产生数据倾斜(热点问题)
-
需要预估数据分布
-
边界值调整复杂
4、时间分片算法(根据日期分片)
-
描述:根据分片键的日期进行分片,可以按年、月、日等。
-
配置示例:算法名称:INTERVAL,属性:datetime-pattern(日期格式),datetime-lower(开始时间),datetime-upper(结束时间),sharding-suffix-pattern(分片后缀模式,如yyyyMM)
-
场景:适用于按时间增长的数据,如日志、订单等。例如,可以按月分片,每个月一张表。
application.properties
#--分片算法:monthly_interval
spring.shardingsphere.rules.sharding.sharding-algorithms.monthly_interval.type=INTERVAL
spring.shardingsphere.rules.sharding.sharding-algorithms.monthly_interval.props.datetime-pattern=yyyy-MM-dd HH:mm:ss
spring.shardingsphere.rules.sharding.sharding-algorithms.monthly_interval.props.datetime-lower=2023-01-01 00:00:00
spring.shardingsphere.rules.sharding.sharding-algorithms.monthly_interval.props.datetime-upper=2025-12-31 23:59:59
spring.shardingsphere.rules.sharding.sharding-algorithms.monthly_interval.props.sharding-suffix-pattern=yyyyMM
spring.shardingsphere.rules.sharding.sharding-algorithms.monthly_interval.props.datetime-interval-amount=1
spring.shardingsphere.rules.sharding.sharding-algorithms.monthly_interval.props.datetime-interval-unit=MONTHS适用场景:
-
日志表按月/按周分片(访问日志、操作日志)
-
订单表按创建时间分片(支持时间范围查询)
-
监控数据按时序分片(指标数据、性能数据)
-
财务流水按会计期间分片
优势:
-
天然支持时间范围查询
-
便于历史数据归档和清理
-
自动分片,无需手动干预
-
适合时序数据场景
局限性:
-
时间戳字段必须有索引
-
早期分片可能数据量小,后期分片数据量大
-
需要合理设置时间上下限
5、行表达式分片算法(INLINE)
-
描述:使用Groovy表达式在配置中直接编写分片规则,简单灵活。
-
配置示例:算法类型:INLINE,属性:algorithm-expression(表达式,如ds_${order_id % 4})
-
场景:适用于简单的分片规则,且不想编写代码的场景。例如,根据分片键取模分片。
application.properties
# 行表达式分片
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-mod.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.inline-mod.props.algorithm-expression=db${order_id % 4}适用场景:
-
简单的取模分片逻辑
-
快速原型开发和测试环境
-
分片规则固定的简单业务
-
不希望编写Java代码的场景
优势:
-
配置简单,无需编码
-
灵活性强,支持Groovy表达式
-
适合规则固定的简单分片
局限性:
-
复杂逻辑表达能力有限
-
调试和排查问题困难
-
性能可能不如自定义算法
6、标准分片算法(STANDARD)
-
描述:允许用户通过实现PreciseShardingAlgorithm和RangeShardingAlgorithm接口来自定义精确分片和范围分片行为。
-
配置示例:算法类型:STANDARD,属性:algorithm-class(自定义算法类)
-
场景:适用于需要自定义分片逻辑的场景。例如,根据分片键的前缀或后缀进行分片。
application.properties
java
## 标准分片算法(STANDARD)
# 分片算法配置
spring.shardingsphere.rules.sharding.sharding-algorithms.order-precise.type=CUSTOM
spring.shardingsphere.rules.sharding.sharding-algorithms.order-precise.props.sharding-algorithm-class-name=com.mashibing.shardingjdbc.OrderPreciseSharding
# 表分片规则配置
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds_${0..9}.t_order_${0..9}
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=snowflake
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=order-precise
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class OrderPreciseSharding implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames,
PreciseShardingValue<Long> shardingValue) {
// 获取分片值(订单ID)
Long orderId = shardingValue.getValue();
// 计算分片后缀(订单ID最后一位)
int suffix = (int) (orderId % 10);
// 返回目标数据源名称(db0 ~ db9),实际可能没这么多
return "db" + suffix;
}
}关键配置解析
-
分片算法类型
type: CUSTOM表示使用自定义分片算法 -
算法类路径
sharding-algorithm-class-name需指定实现类的全限定名 -
分片规则绑定 在
tables配置中通过sharding-algorithm-name关联算法 -
分片值处理
doSharding方法参数说明:-
availableTargetNames:可用分片名集合(如ds_0,ds_1) -
shardingValue:包含分片键值和分片列信息
-
注意事项
-
类扫描路径 确保自定义算法类在Spring Boot主应用类或配置类的包路径下,或通过
@ComponentScan扫描 -
分片值范围 示例中按订单ID最后一位分片(0-9),需确保分片后缀与
actual-data-nodes配置匹配 -
分布式ID生成 示例中配置了Snowflake生成器,需确保分片键与主键生成策略一致
-
多分片维度 如需同时按用户ID分片,需在
shardingValue中获取用户ID值,并组合分片逻辑
适用场景:
-
复杂的分片业务逻辑
-
需要多字段组合分片
-
特殊的分片规则需求
-
性能优化要求高的场景
优势:
-
完全自定义分片逻辑
-
支持复杂业务规则
-
性能优化空间大
-
灵活应对特殊需求
局限性:
-
需要编写和维护代码
-
部署和测试相对复杂
-
对开发人员要求较高
7、 复合分片算法(COMPLEX)
-
描述:支持多个分片键,用户可以通过实现ComplexKeysShardingAlgorithm接口来自定义多分片键的逻辑。
-
配置示例:算法类型:COMPLEX,属性:algorithm-class(自定义算法类)
-
场景:适用于多个分片键共同决定分片位置的场景。例如,同时根据用户ID和订单ID分片。
application.properties
# 复合分片算法配置
spring.shardingsphere.rules.sharding.sharding-algorithms.user-order-complex.type=CLASS_BASED
spring.shardingsphere.rules.sharding.sharding-algorithms.user-order-complex.props.strategy=COMPLEX
spring.shardingsphere.rules.sharding.sharding-algorithms.user-order-complex.props.algorithmClassName=com.mashibing.shardingjdbc.UserOrderComplexSharding
# 分表策略
spring.shardingsphere.rules.sharding.tables.orders.actual-data-nodes=db${0..9}.t_order_${0..9}
spring.shardingsphere.rules.sharding.tables.orders.table-strategy.complex.sharding-columns=user_id, order_id
spring.shardingsphere.rules.sharding.tables.orders.table-strategy.complex.sharding-algorithm-name=user-order-complex
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.util.Collection;
import java.util.HashSet;
import java.util.Set;
public class UserOrderComplexSharding implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames,
ComplexKeysShardingValue<Long> shardingValue) {
Set<String> result = new HashSet<>();
// 获取用户ID分片值
Collection<Long> userIds = shardingValue.getColumnNameAndShardingValuesMap().get("user_id");
// 获取订单ID分片值
Collection<Long> orderIds = shardingValue.getColumnNameAndShardingValuesMap().get("order_id");
// 组合分片逻辑
for (Long userId : userIds) {
int userSuffix = (int) (userId % 10);
for (Long orderId : orderIds) {
int orderSuffix = (int) (orderId % 10);
// 组合分片键:用户ID取模 + 订单ID取模
String target = "db" + (userSuffix * 10 + orderSuffix);
if (availableTargetNames.contains(target)) {
result.add(target);
}
}
}
return result;
}
}适用场景:
-
多维度分片需求(用户+时间)
-
关联查询优化(主子表同库分片)
-
复杂业务规则分片
-
需要避免跨分片关联的场景
优势:
-
支持多分片键组合
-
优化关联查询性能
-
灵活应对复杂业务
-
减少跨分片操作
局限性:
-
算法复杂度高
-
调试和维护困难
-
需要深入理解业务
业务场景匹配
| 业务场景 | 推荐算法 | 理由 | 示例 |
|---|---|---|---|
| 用户系统 | MOD | 用户ID为数值,分布均匀 | user_id % 16 |
| 订单系统 | COMPLEX | 多维度查询(用户+时间) | 用户分片+时间分片 |
| 日志系统 | INTERVAL | 按时间序列自动分片 | 按月分片 |
| 商品目录 | HASH_MOD | SKU编码为字符串 | sku_code哈希分片 |
| 财务系统 | RANGE | 按金额区间管理 | 小额、中额、大额分片 |
| 监控数据 | INTERVAL | 时序数据特性 | 按天/按时分片 |
| 会话存储 | HASH_MOD | session_id均匀分布 | session_id哈希分片 |