本文章结合之前文章优化问题------局部最小值与鞍点-CSDN博客、自动调整学习率-CSDN博客的各种优化训练的方法,介绍实际工程中常用的优化器
Adam
Adam,全称Adaptive Moment Estimation(自适应矩估计),它实际上就是结合了 SGD with Momentum(SGDM) 和 RMSProp 思想的自适应学习率优化器,既带惯性,又自适应学习率,是目前深度学习最常用、默认首选的优化器(自适应学习率优化器)。
SGDM和RMSProp之前都已经学习过,这里将它们整合到一起,介绍一个完整的优化器Adam:
SGDM
SGDM 核心是累积历史梯度的一阶矩,核心公式是:
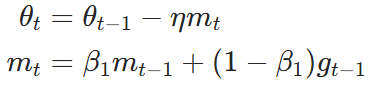
:第
动量项 会保留历史梯度方向,像物理中的 "动量" 一样保持运动惯性,从而加速收敛、抑制震荡、帮助跳出鞍点和平坦区。
指数移动平均(EMA)形式 兼顾历史信息与当前趋势。
指数移动平均(Exponential Moving Average, EMA) 是一种对时间序列数据做加权滑动平均的方法,核心特点是越新的数据权重越大,越旧的数据权重呈指数衰减。在优化器里EMA的公式形式为:
下面将EMA公式展开,看它的本质:
当
对第
最新数据权重最高(如
有效平滑窗口 ,我们定义有效窗口大小
当
当
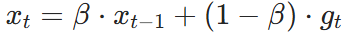
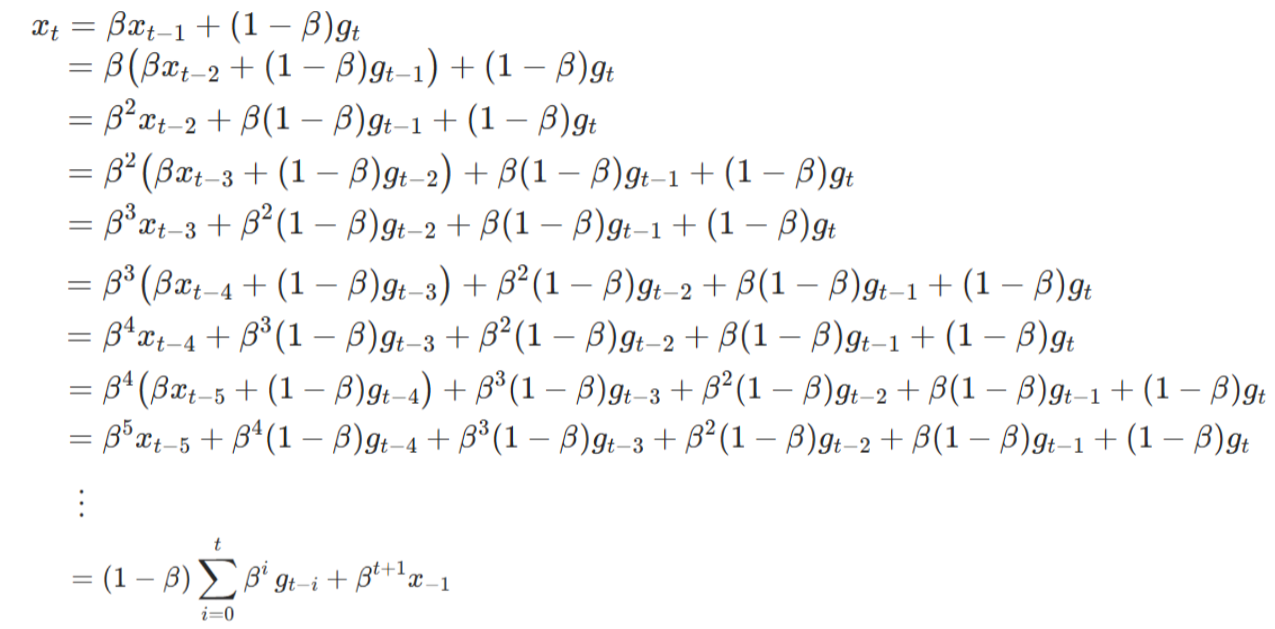
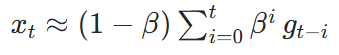
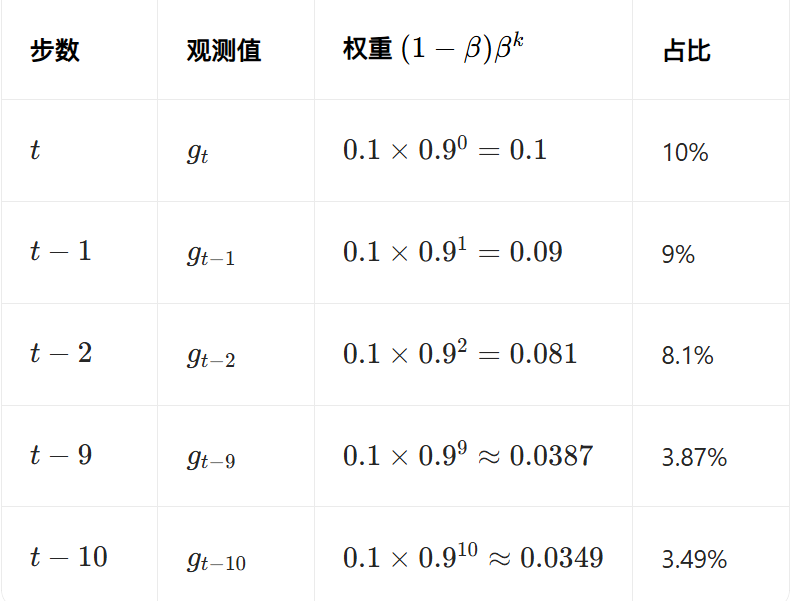
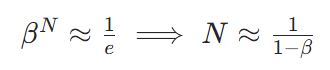
SGDM平滑系数设置为0.9,表示平均看最近 10 步的梯度方向,既保留趋势,又不会被单步噪声带偏。如果
太小(比如 0.5),动量几乎消失。
RMSProp
RMSProp 核心是累积历史梯度的二阶矩,实现自适应学习率,核心公式是:
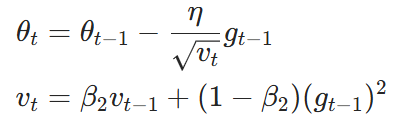
用 对学习率做归一化,对于梯度波动大的参数,学习率会自动缩小;梯度稳定的参数,学习率自动放大,实现自适应学习率。避免了固定学习率在不同参数维度上表现不均的问题。
若 太小(比如 0.9),平滑窗口只有 10 步,
会对单步噪声太敏感,自适应学习率震荡剧烈,甚至导致训练崩溃。
在概率论里,矩(moment) 是描述随机变量分布特征的统计量:
一阶矩则表示期望
在优化器里,梯度
整合公式
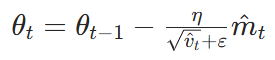
其中
Adam 将 SGDM 的一阶矩与 RMSProp 的二阶矩结合,并引入偏差校正(de-biasing)和数值稳定项:
- 偏差校正
以具体数据示例说明偏差的出现及校正过程(假设每一步梯度都为10,
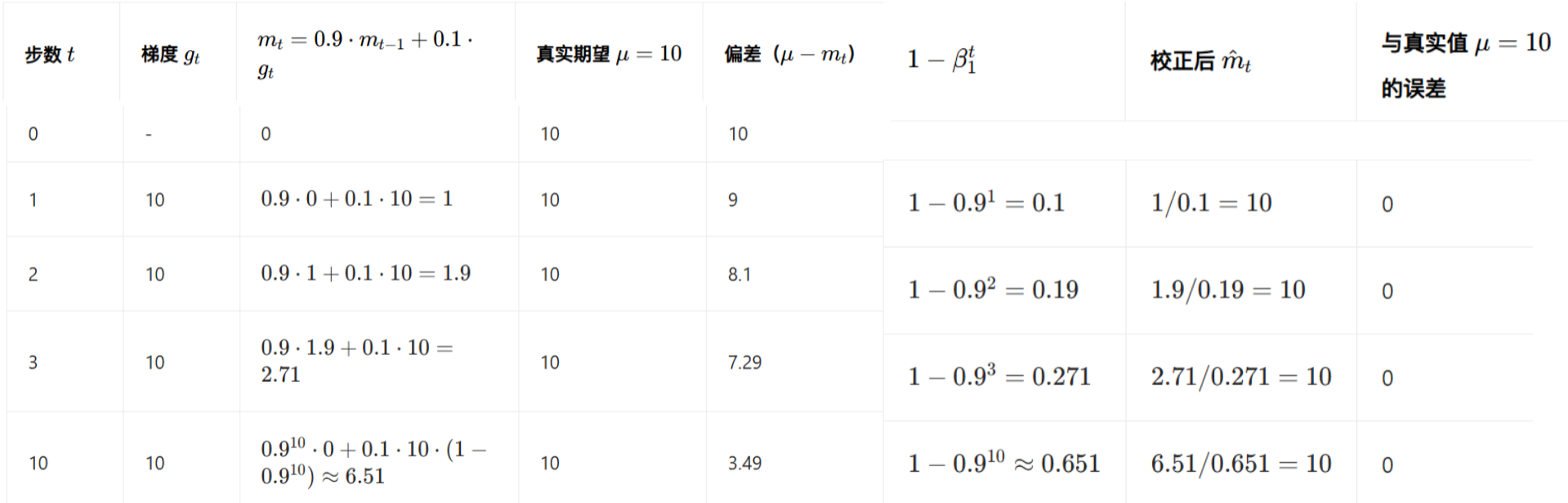
当 - 数值稳定项
SGDM
上面在介绍Adam优化器时说过,Adam包括SDGM,但这并不意味着它一定优于SGDM。Adam在 SGDM 基础上增加了自适应学习率(RMSProp 二阶矩) 和偏差校正,这两个核心改动让它和纯 SGDM 成为完全不同的优化器。实际在使用时,有的模型会使用Adam(如BERT、Transformer、GAN等),有的模型会使用SGDM(如ResNet、VGG、AlphaGo等)。
SGDM,全称Stochastic Gradient Descent with Momentum(带动量的随机梯度下降),核心公式:
与Adam相比:
- 学习率: SGDM全局固定学习率
- 梯度: SGDM仅用梯度的一阶矩(方向)
- **收敛特性:**SGDM收敛慢,但更容易收敛到更优的局部最优 / 全局最优;Adam收敛快,但可能提前收敛到次优解(后期步长过小)。SGDM 靠动量惯性可以 "冲过" 浅谷;而Adam 自适应步长会在后期自动缩小,容易提前停滞
我们可以通过具体的例子来看看Adam的问题所在:
其中:
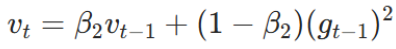
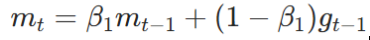
与SGMD相比,Adam使用了自适应学习率,我么可以让动量
的
(即
),只看自适应学习率所起的作用。我们知道当
时,
平均关注最近 1000 步的数据。而在模型训练过程中,训练到最后时大部分的梯度都特别小,只有某几个Batch的梯度会比较大(关键特征,很明确的告诉你往哪里走),如果使用这种自适应学习率,最近 1000 步的数据进行加权计算,会导致后期少数梯度比较大的Batch提供的更新方向被稀释。举一个比较极端的例子,如下图所示,假设100000~100998的梯度都为1(即更新步长均为
),到100999时梯度突然猛增到100000(出现了关键特征),但是由于要考虑前1000步的影响,所以最终巨大的梯度会迅速被稀释,这会让 Adam 错误地认为梯度很小,从而自适应放大学习率,导致参数更新幅度过大,最终偏离最优解,甚至训练发散(不收敛)。

AMSGrad
AMSGrad 是 Adam 的改进版本,核心目的是解决训练后期大梯度被小梯度稀释而导致Adam误以为梯度很小,从而导致更新步长过大而训练发散的问题。 它的核心思路很直接 **"只增不减,锁定历史最大值"。**核心公式如下:
一阶矩计算(与Adam完全相同):
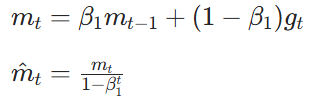
二阶矩计算(核心改进):
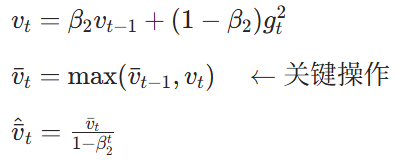
参数更新:
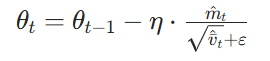
AMSGrad引入的核心公式,
长期记忆变量。它保证了二阶矩估计
是单调非递减的。无论当前梯度
多么小,
都不会下降,只会保持不变或上升。这就锁住了历史上出现过的最大梯度幅度。
但是AMSGrad存在很多缺陷:
- 学习率只会变小,不会 "回弹",导致后期走不动、收敛慢:一旦历史上出现过一个大梯度,有效学习率就被永远压小了,哪怕后面梯度方向很稳、很正确,也不敢大步走。
导致收敛比 Adam 慢很多,甚至卡在鞍点附近不动。 - 对 "正常噪声" 太敏感,一遇到大梯度就永久保守:一旦某一个 batch 噪声大,或者某一层梯度突然爆一下,AMSGrad 会把这次偶然的大梯度永久记住,而 Adam 会慢慢忘掉,恢复正常学习率。
- 泛化能力往往不如 Adam,更不如 SGDM:AMSGrad 因为学习率只降不升而过度稳定,这缺少适度震荡,更容易陷在critical point。
由于上述缺陷的限制,正常工程中都不会用 AMSGrad,它只是提出了自己的理论,但实际效果并不理想。
AdaBound
AdaBound 是为了解决 Adam 泛化差、SGDM 前期慢 的矛盾:
- Adam:前期收敛快,但泛化能力差(测试集精度常低于 SGD);后期易出现极端学习率(某些维度过大 / 过小),导致不稳定、不收敛。
- SGDM:泛化好、最终精度高,但前期收敛极慢,调参成本高。
它通过动态学习率边界让优化器从 Adam 平滑过渡到 SGD,兼得 Adam 的快速收敛与 SGD 的优秀泛化。
AdaBound的原理是在Adam 基础上,给自适应学习率加动态上下界,训练初期时上下界宽松(此时近似Adam,可以快速收敛),训练后期上下界收紧并收敛到同一个值 ,退化为固定学习率的 SGDM(带动量),保证泛化。其核心公式如下:
一阶/二阶矩估计沿用Adam:
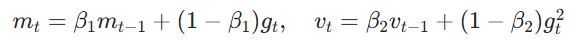
动态边界:
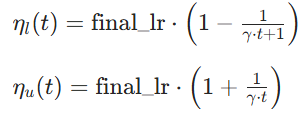
- final_lr:表示训练后期时 SGD 固定的学习率(如 0.1)
- 随训练步数
模型使用的裁剪学习率(使用"裁剪 / 钳位" 函数Clip ):
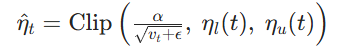
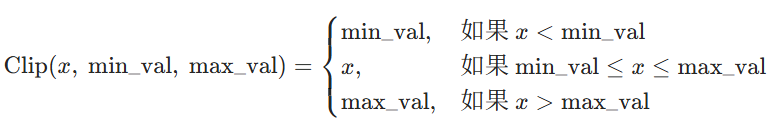
参数更新:
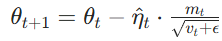
AdaBound 虽然思路巧妙(兼顾 Adam 速度和 SGDM 泛化),但在工程落地中暴露了多个核心缺陷,这也是它始终无法成为主流的关键原因:
final_lr难以调优:final_lr是 SGDM 的核心超参数,本身就需要针对不同任务 / 模型手动调(比如 ResNet 用 0.1,BERT 用 5e-5)。如果final_lr设错,AdaBound 后期要么学习率过大(震荡),要么过小(不动),反而不如直接用 SGDM 调参。- 自适应优势被削弱:Adam 的核心价值是不同参数用不同学习率,若某参数的梯度本就该用大 / 小学习率(比如稀疏特征),裁剪会强制 "矫正" 它,反而导致该参数更新不匹配,训练变慢。
- 超参数复杂度翻倍:AdaBound 除了要调 Adam 的基础超参数(
Cyclical LR
Cyclical LR(Cyclical Learning Rate,循环学习率)核心是让学习率在训练过程中周期性地在预设区间内上下波动 ,而非单调下降。一般在SGDM基础上使用Cyclical LR。
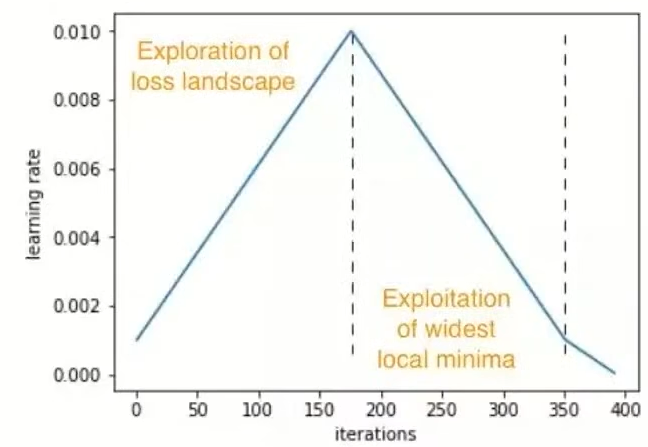
学习率过小参数更新步长不足,模型易卡在局部最优 / 鞍点,无法跳出,学习率过大前期收敛快,但后期震荡,无法收敛到最优解,那就干脆用 "周期性波动的学习率",让模型在 "探索(大学习率跳坑)" 和 "利用(小学习率收敛)" 之间平衡,既避免卡壳,又保证最终精度。
让学习率在一个最小值(base_lr) 和最大值(max_lr) 之间,按预设周期(stepsize)做 "上升 - 下降" 的周期性变化,上升阶段(大学习率)像 "用大步子跳坑",帮助模型跳出局部最优,探索更优的参数空间,下降阶段(小学习率)像 "用小步子微调",让模型在当前优质区域内收敛,保证精度。
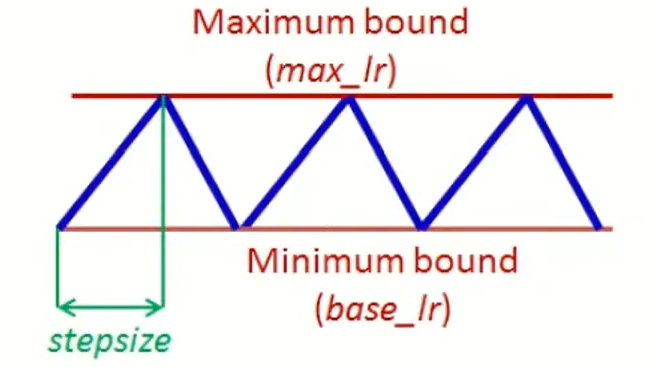
Cyclical LR最常用 "三角循环" 模式:
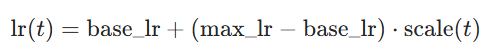
scale(t)是随训练步数t变化的缩放因子- 在上升阶段(半个周期):
scale(t)从 0 线性增长到 1,学习率从base_lr涨到max_lr - 在下降阶段(半个周期):
scale(t)从 1 线性下降到 0,学习率从max_lr降到base_lr - 周期长度
step_size通常设为2-10 * 训练一个 epoch 的步数(比如训练 1 个 epoch 要 1000 步,step_size=2000)。
Cyclical LR是是 "多周期波动",在实际训练中会出现问题:
- 多周期易导致后期震荡,反而影响精度: 对于一个模型训练而言,前期模型参数远离最优解,这时需要大学习率探索参数空间,波动是正常且有益的,后期模型参数已接近最优解,这时需要小学习率精细收敛,此时任何大的参数更新都会导致 "震荡"(偏离最优解后又往回走)
所以对于周期性的参数起伏,在后期时模型本应收敛,但每次 lr 升到max_lr时,参数更新幅度会突然变大,这把本已接近最优解的参数 "推出去",之后 lr 降到base_lr,参数又往回走形成 "推出去→拉回来" 的循环,也就是震荡。 - 缺少对 "训练初期" 的适配(初始大学习率易发散): 主要因为训练初期,模型参数随机初始化,梯度噪声极大、分布极不稳定(batch 间差异大),如果直接用大学习率会让梯度瞬间被极端值主导,分布被 "扭曲"。
所以zai优化器在训练初期必须做学习率 Warm-up(预热),否则会出现梯度分布畸变、二阶矩 EMA 被污染,最终导致学习率失效、训练震荡甚至发散。Warm-up的核心操作是在训练初期让学习率从极小值线性 / 平滑增长到目标学习率,下面的One-cycle LR就进行了前期的Warm-up。
相比之下SGDM只有一阶矩(动量),且学习率是全局固定的,初期梯度噪声对 EMA 的影响小,大学习率也不容易直接发散。
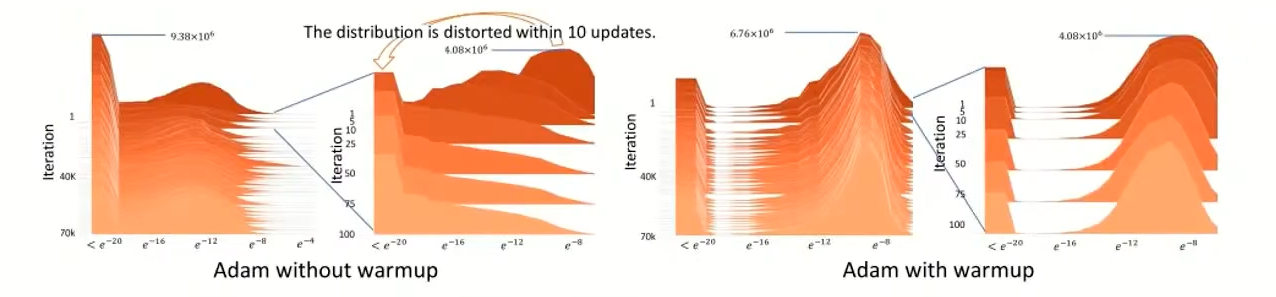
下图是Transformer 模型在德英翻译数据集上的梯度绝对值直方图(y 轴是训练迭代次数,x 轴是梯度绝对值的对数尺度,高度是频率):
左图(无Warm up),前 10 步内梯度分布出现明显畸变(The distribution is distorted within 10 updates),大量梯度集中在极小值区域,分布形态混乱,这种畸变会持续影响后续训练,导致参数更新不稳定。右图(有Warm up)梯度分布始终保持平滑、规整的形态,没有出现前期畸变。这说明 Warm-up 有效抑制了初期梯度噪声的影响,让梯度统计更稳定。
One-cycle LR
One-cycle LR 是 Cyclical LR 的升级版,核心是让学习率在整个训练过程中只完成一次 "升 - 降" 循环 ,且搭配 "学习率升温 + 动量反向波动",极致适配 SGDM,最大化其泛化能力和收敛效率。
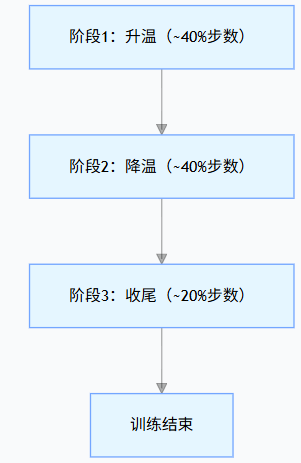
One-cycle LR仅用 一次完整的升 - 降循环 覆盖全训练周期,避免多周期震荡;前期 "缓慢升温" 学习率,后期 "快速降温",同时反向调整动量,兼顾稳定性和收敛速度。其把整个训练步数 total_steps 分成 3 部分:
对应核心公式1(学习率计算):
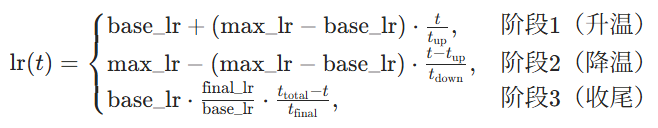
base_lr:初始低学习率(通常是max_lr/25)max_lr:峰值学习率(核心超参数,需通过 学习率扫描 确定)final_lr:收尾学习率(通常是base_lr/1000)total_steps)total_steps)total_steps)
对应核心公式2(动量反向波动):
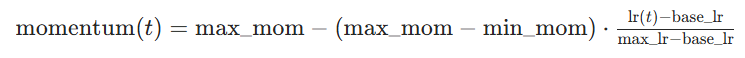
max_mom:最大动量(如 0.95)min_mom:最小动量(如 0.85)- 动量反向波动(lr 高→动量低,lr 低→动量高),本质是用动量的 "惯性" 一定程度上抵消不同 lr 阶段的风险,具体体现为当Ir处于峰值时并且在动量的影响下,参数更新幅度大,容易 "冲过头"(比如一步跨出最优解区域),所以减小动量(低动量)可以一定程度上防止"冲过头";在lr 处于低谷时,参数更新幅度小,容易 "卡壳"(比如陷在鞍点,梯度接近 0 就不动了),此时采用高动量,高动量保留历史梯度的方向,哪怕当前梯度小,也能靠惯性 "推着参数往前走",突破鞍点,继续收敛。
工作机制:
- 升温阶段(小 lr + 高 mom):训练初期模型参数是随机初始化的,直接用大 lr 会导致梯度爆炸 / 损失飞涨,而慢升温让模型在安全范围内,逐步扩大参数更新幅度,"探索"到优质的参数空间区域(比如远离初始随机值的 "低损失区")。
- 峰值阶段(大 lr + 低 mom):升温阶段已经找到 "优质参数区域",降温的核心是 "从探索转向收敛" 。通过逐步减小 lr,让参数在优质区域内 "精细调整",而非继续大范围探索。
- 降温 + 收尾阶段(小 lr + 高 mom):此时参数已非常接近最优解,哪怕 base_lr 也可能 "微调过头" ,所以采用极低的 final_lr 让参数做 "纳米级微调"。
RAdam
RAdam 是针对 Adam 优化器训练初期学习率震荡 / 不稳定问题的改进版本,核心是融合 SGDM 的稳定性和 Adam 的自适应优势:
- 训练前期使用SGDM,利用 SGDM 稳定性强、步长可控的优点,让模型 "稳起步",规避 Adam 初期因二阶矩估计不可靠导致的步长爆炸、震荡甚至发散。
- 训练中后期切换到Adam,利用 Adam 自适应学习率的优点,根据梯度方差调整步长(梯度大则步长小,梯度小则步长大),让模型 "快收敛、准收敛",规避 SGDM 学习率固定,易卡在局部最优、收敛慢的问题。
- RAdam通过 整流因子
在Cyclical LR的后面我们说过训练初期,模型参数随机初始化,梯度噪声极大、分布极不稳定(batch 间差异大),而Adam的有效学习率依赖二阶矩的偏差校正项**** ,在训练初期(比如 t<10),
,
接近1,
极小,
被放大,导致有效学习率剧烈波动。
我们在之前说过**
取
前几步的
副作用仅存在于
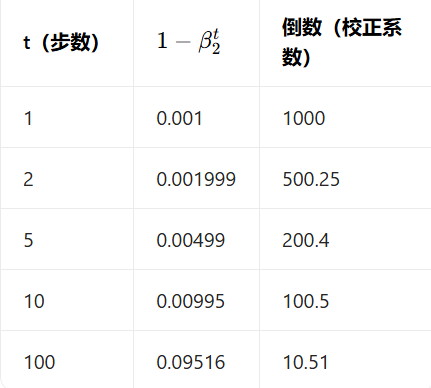
RAdam 的核心不是 "否定偏差校正",而是 "在保留校正的前提下,限制其副作用",它保留了 Adam 的偏差校正,保证估计值无偏,在此基础上新增整流因子,在
时动态缩小有效学习率,抵消 "校正后
过大" 导致的波动,后期
时,
,完全退化为 Adam,既保留无偏估计,又无波动问题。其核心公式如下:
计算"方差收敛系数":
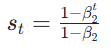
计算"学习率方差上限":
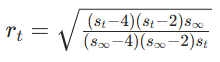
动态修正学习率:
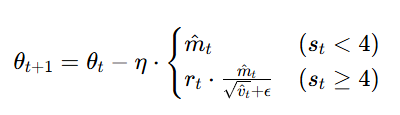
RAdam基于统计学的方差分析,计算出有效学习率的理论方差上限,用这个上限约束前期的学习率,让波动不超过合理范围。下面分别介绍这三个公式的原理及推导:
方差收敛系数
RAdam 要解决的根本问题是Adam 训练初期,二阶矩的 EMA 统计量还未收敛 ,导致自适应学习率的方差过大,参数更新震荡。而"方差收敛系数" 是量化**"二阶矩 EMA 收敛程度"**的关键指标。
要理解**
Adam 的二阶矩
当
当
当
所以总结来说,训练初期
针对上述出现的问题,Adam 用**
也就是说我们要知道 "二阶矩EMA的收敛程度" 只需要知道当前更新的步数,步数越多,历史梯度数据越多,权重和越接近于1,二阶矩收敛效果越好。
的公式就是这个思路,但它并不是简单的代指更新步数,而是代表 EMA 的有效样本数(Effective Sample Size)
统计上,有效样本数的定义是让 EMA 的方差等于某个普通平均的方差时,那个普通平均的样本数。我们先从最简单的平均开始,再过渡到 EMA来解释这个定义:
- 普通平均:用
这里的样本数- 指数移动平均(EMA): 对样本
普通平均的方差(假设样本独立同分布,方差为
对 EMA 做方差计算(假设
从公式的角度理解:每个样本的权重及其和为
如果表示收敛完成,只需要知道
的值就可以知道收敛程度,而
只是在此基础上除以
将其扩大
倍
例如,则
,
,则
,
当时,
,
,若此时
,则
表示无限步 EMA 的统计可靠性约等于10 个样本的等权平均;若此时
,则
表示无限步 EMA 的统计可靠性约等于1000 个样本的等权平均;
是把梯度权重和按
这个尺度归一后,得到的 "等效样本数量"------ 它的物理意义是 "这个 EMA 到底相当于用了多少个独立样本在平均"。
学习率方差上限
Adam 在训练前期,因为梯度样本太少,自适应学习率的方差会变得非常大,导致更新不稳定、震荡、发散。RAdam做的事情是把梯度近似成 正态分布,把Adam里的看作是一个统计量它在小样本时服从t 分布,然后用 t 分布的方差公式,算出这个统计量到底波动有多大,最后算出一个系数 **
** 把方差强行拉回正常水平。
正态分布:
自然界大量现象由独立小因素共同影响,最终符合正态分布(Normal Distribution)(中心极限定理),梯度、噪声、误差,均接近正态。正态分布概率密度公式如下:
- 标准正态分布写为
正态分布图像两侧对称,中间最高,往两边越来越低。下图为
t 分布:
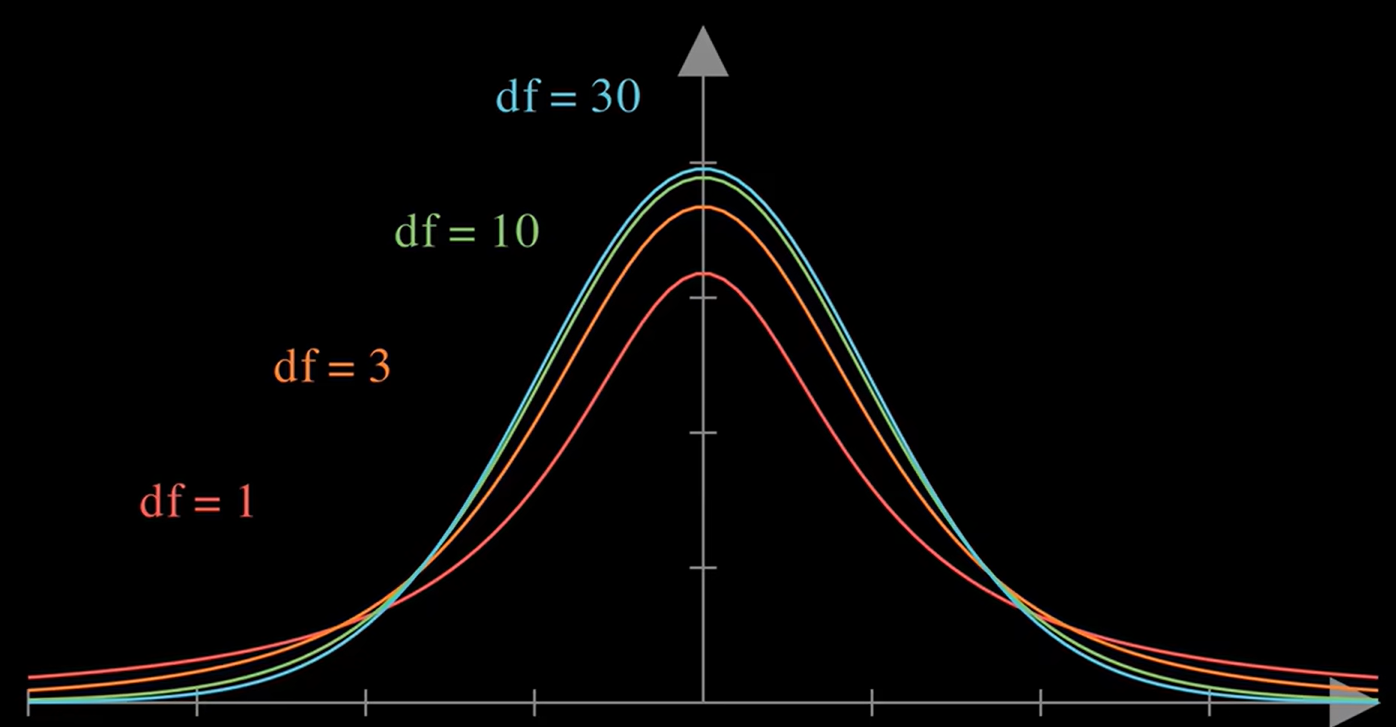
t 分布是样本很少时的 "正态分布",当你只有很少几个样本数据时,这时估计总体的均值、方差均不准,并且相较于从总体中抽样更容易出现极端值,它的图像尾巴比正态分布更厚(这表示更容易出现极端值),如下所示样本数从30、10、3到1图像尾巴越来越厚(样本越少,尾巴越厚)。样本越多,t 分布 越来越接近正态分布。
t 分布的概率密度函数如下:
自由度- 上式是t分布的标准形式(默认
标准正态分布为
标准正态分布的"形状公式"
当
当
所以
即 t 分布在自由度无穷大时,形状公式完全变成标准正态分布的形状公式。
对于不服从标准正态分布的正态分布,如果它的均值等于
来对每一个样本
同理,对于不服从标准 t 分布的 t 分布,如果它的样本均值 等于
来对每一个样本
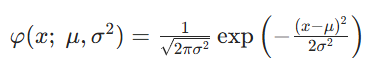
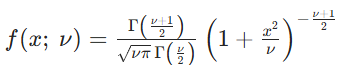
RAdam将Adam里的看成是一个服从 t 分布的统计量,原因如下:
- RAdam假设梯度
- 一阶矩
- 二阶矩
- t 统计量
RAdam将方差收敛系数(有效样本数)作为 t 分布的自由度,在训练前期
小,t 分布方差巨大Adam 的更新方向方差巨大,训练后期
大,t 分布接近正态分布,方差稳定。
RAdam的目标是让修正后的更新量的方差尽可能与后期稳定时的方差相等,即
我们知道,在后期稳定时(),t 分布的方差为
;而当前时刻方差为
。我们希望
,所以:
在实际训练时,作者发现 t 分布方差公式在
很小时(比如 < 4)误差很大,所以加了一个经验修正项来让方差更准,经验修正项为:
于是,重新推导得:
即
动态修正学习率
RAdam 的更新规则本质是 "条件分支",根据 的大小,决定用哪种方式更新参数,核心是 "初期稳、后期准"。
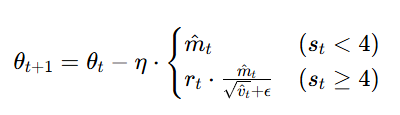
- 当
- 当
当
当
SWATS
SWATS(Switching from Adam to SGD)是另一类融合 Adam 和 SGDM 的优化器,核心思路与 RAdam 相反 ------先启用 Adam 快速探索参数空间,再根据训练状态自动切换到 SGDM 完成精细收敛 ,而非 RAdam 那样 "先 SGDM 稳起步,再 Adam 自适应"。SWATS 的过渡是 "一次性、平滑触发",而非 RAdam 使用做过渡。
SWATS 的设计思路依赖如下Adam和SGDM的优缺点:
- Adam 优势:训练初期收敛快(自适应学习率能快速找到优质参数区域);
- Adam 短板:训练后期易在最优值附近震荡,泛化能力不如 SGDM;
- SGDM 优势:后期收敛更稳定,泛化能力强;
- SGDM 短板:初期收敛慢,需手动调学习率。
核心公式如下:
Adam阶段更新(切换前),与标准 Adam 完全一致,先按 Adam 规则更新参数:
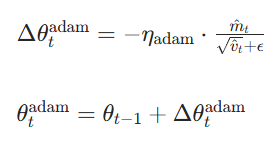
切换触发条件,定义一致性指标 用来衡量 Adam 更新方向与原始梯度方向的 "对齐程度",当
连续多步稳定时,触发切换:
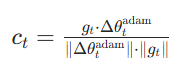
- 物理意义:当
- 触发规则:当
SGDM学习率初始化,切换时,SWATS 会从 Adam 的自适应步长中自动推导 SGDM 的最优学习率,避免手动调参:
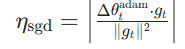
SGDM阶段更新(切换后),固定使用 SGDM 更新,动量系数复用 Adam 的 (保证一致性):
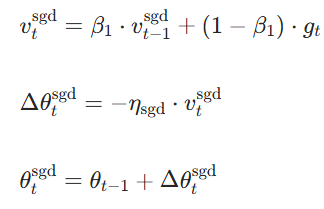
RAdam 和 SWATS 虽然都融合 Adam 和 SGDM,但它们的设计思路和适用场景截然不同:
- RAdam更在意稳定性(极强的鲁棒性),解决了 Adam 最致命的 "早期方差估计不可靠导致步长爆炸" 问题,但是后期Adam更新步长小,泛化能力可能不足。
如果你的任务容易震荡、崩掉(如大 Batch、小模型),选 RAdam。 - SWATS更在意泛化能力,训练后期完全等价于SGDM,SGDM 具有很好的收敛性和泛化能力,能跳出较差的局部最优,因此在 ImageNet 等分类任务中,SWATS 配合 SGDM 的最终精度往往很高。但一次性切换的机制不稳定,只在特定数据集(如分类任务)上效果拔群,在生成任务、NLP 细调等场景下,SWATS 的 "一刀切" 切换策略往往会破坏训练稳定性。
如果你的任务需要极高泛化能力、且 Adam 后期震荡严重,选 SWATS。
实际上,针对 "Adam 前期不稳 + 后期停滞"、"SGDM 前期慢 + 后期稳" 的全周期问题,提出了一系列更全面的融合方案,如 "AdamW + 学习率调度 + 权重衰减" 、"RAdam + Lookahead"等,而不是只使用RAdam或者SWATS。
Lookahead
Lookahead 是在 2019 年提出的通用优化器 wrapper(优化器包装器),它可以套在任意基础优化器(如 SGD、Adam、RAdam 等)外面,不修改原有优化器逻辑,仅通过 "快慢权重双轨道" 更新机制,提升训练稳定性与泛化能力。
它的核心行为可以概括为:k 步向前探索,1 步向后回退(k step forward, 1 step back),就像在优化路径上先 "探路",再谨慎地迈出一步。
Lookahead的设计思路源于两个核心问题:
- 避免危险探索:基础优化器(如 SGD)在训练中可能陷入剧烈震荡或尖锐局部极小值,导致泛化变差。Lookahead 先让 "快权重" 走 k 步探索梯度方向,再让 "慢权重" 向探索终点做小幅回退,避免过度激进的更新。
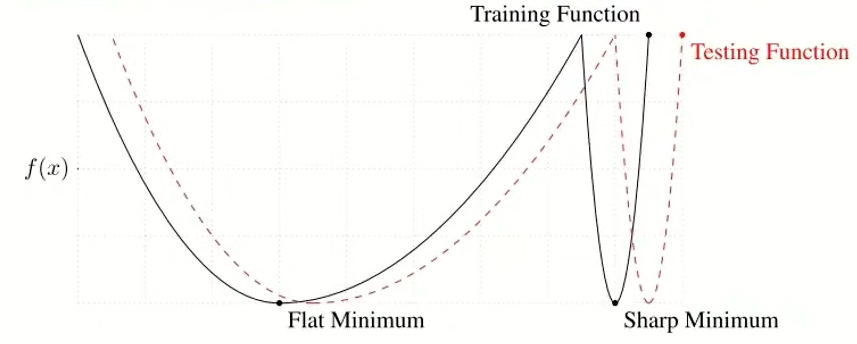
- 寻找更平坦的极小值:平坦的极小值通常对应更好的泛化性能。Lookahead 通过慢权重的插值更新,引导优化轨迹向更平缓的区域收敛,从而提升模型在测试集上的表现。
- 尖锐极小值:对参数扰动敏感,测试集表现差(泛化弱);
- 平坦极小值:对参数扰动鲁棒,测试集表现好(泛化强)。
Lookahead 维护两套权重:
- 快权重
- 慢权重
采用 "内外双循环" 更新结构:
外层循环(慢权重更新,第 轮): 将上一轮的慢权重
作为本轮快权重的初始值,保证探索起点与慢权重一致。此步为初始化步骤:
内层循环(快权重探索,共 步):
对:
- 公式含义:以
慢权重插值更新:
内层循环结束后,更新慢权重:
上述公式等价于:
- 公式含义:慢权重
从下图可以看出,快权重(蓝色虚线)在探索过程中精度会短暂下降(震荡),慢权重(绿色点)通过插值更新,始终保持更稳定、更高的测试精度,最终收敛到更优的平坦极小值。
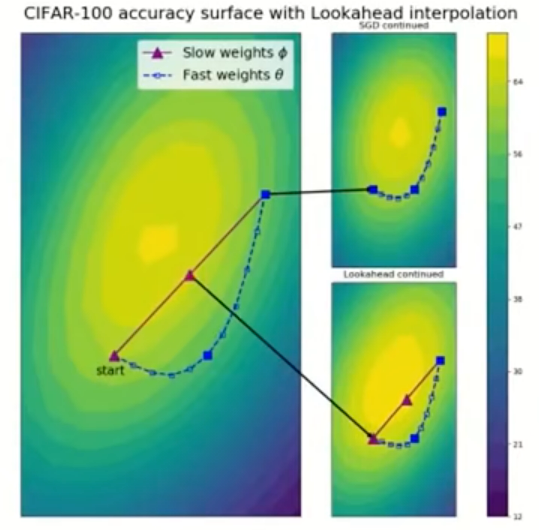
Lookahead的优势在于**「慢权重只跟探索后的终点做插值,而不是跟每一步快权重」以及「探索 k 步后再决定怎么迈一步」**这个设计里。
- 对于高频震荡会让收敛路径曲折,容易扎进尖锐极小值,而Lookahead通过快权重先跑 k 步,把短期震荡 "平均" 到一个探索终点,慢权重只跟这个 k 步后的平均方向做插值,相当于低通滤波(过滤掉单步梯度的高频噪声)
- Lookahead 在快权重探索时,会短暂进入尖锐极小值区域(表现为精度下降、震荡),而慢权重通过小步插值,不会直接扎进这些尖锐区域,而是沿着探索轨迹的 "平均方向",慢慢滑向更平坦的区域.。
NAG
NAG,全称Nesterov Accelerated Gradient,是改进版的 Momentum ,它在 Momentum 的基础上引入了**「前瞻性梯度计算」**,本质是对 Momentum 方法的更精细的动量控制,收敛更快、更稳定。
之前介绍过Momentum 的核心是累积历史梯度方向,公式,但Momentum 是基于当前位置计算梯度,容易在接近极小值时因动量过大而冲过最优解(overshooting)。NAG的设计思路是先看一步,再算梯度 ,即在更新前,先沿着历史动量方向 "迈出一小步" ,在这个前瞻位置 计算梯度,而不是在当前位置。这种设计可以使梯度提前感知到 前方地形 ,当接近极小值时,梯度会更早开始减小,从而抑制过度冲量,避免震荡,让收敛更精准。公式对比如下:
标准Momentum公式:
表示在当前参数
处的梯度
NAG公式:
先沿动量方向做前瞻:
在前瞻位置计算梯度:
参数更新:
公式含义:模拟 "如果我们继续沿上一步动量方向走,会到达哪里",提前感知前方的梯度地形。而标准 Momentum 只在当前位置算梯度,容易在接近极小值时因动量过大冲过最优解(overshooting);NAG 提前看一步,让梯度更早反映 "前方坡度变缓" 的信号。
公式含义:梯度不再基于当前位置
,而是基于前瞻位置
。当接近极小值时,前瞻位置的梯度会比当前位置更小,因此动量项
的增量会提前减小,自然削弱冲量,避免震荡。
NAG除了在后期收敛阶段可以防止 overshooting(冲过最优解),让参数精准收敛到极小值点。它在前期参数更新加速阶段还可以提前感知前方梯度,在方向切换时更早调整动量,让收敛路径更平滑,减少不必要的来回震荡,加速收敛。(标准 Momentum 会累积大量动量,容易在梯度方向变化时 "刹不住车",导致路径震荡)
NAG并不会因为前瞻性而更难跳出局部最优 / 鞍点,因为它并没有改变动量积累的本质,只要梯度不为零,动量就会持续累积,依然有足够的 "惯性" 冲出局部最优或鞍点。相反,它反而可能更容易跳出,当接近局部最优 / 鞍点时,前瞻位置的梯度会更早变为零或反向,这会让动量的增量提前减小甚至反向,避免过度 "扎进" 局部最优 / 鞍点,为后续跳出保留了动量空间;而 Momentum 可能因为动量过大,直接扎进局部最优,后续更难挣脱。
Nadam
Nadam就是将上述的NAG用到了Adam中,即Nadam = NAG + Adam。其公式如下:
一阶矩、二阶矩更新:
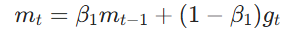
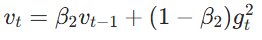
偏差修正(与Adam相同):
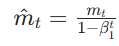
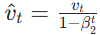
Nesterov前瞻性动量:
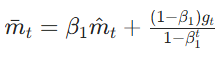
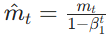 ,而
,而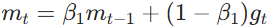
更新公式:
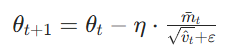
Nadam 没有显式计算前瞻位置,而是通过动量的加权组合,让最终的 等价于「已经在前瞻位置算过梯度后的动量」,结合NAG公式看:

- Nadam中的
- Nadam中的
AdamW
AdamW,全称Adam with Decoupled Weight Decay,是深度学习中主流的带解耦权重衰减的优化器,核心是把权重衰减从梯度计算中分离,解决传统 L2 正则与自适应优化器不兼容的问题。
在下面的文章中我们在优化模型时提到了正则化机器学习过程(线性回归)------ 模型构造与优化_从机器学习到深度学习的重要步骤-CSDN博客
正则化即在原损失函数上加上一个正则项,即:(关于正则化的详细说明参考上述文章正则化部分)
标准 Adam 中把 L2 正则项加入损失函数,在一阶 / 二阶矩的更新过程中也加上了正则项:
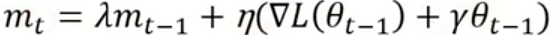
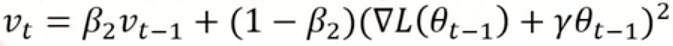
实验表明,如果在一阶 / 二阶矩中加入正则项,会导致权重衰减失效、泛化变差。所以AdamW的设计思路是解耦权重衰减,在参数更新步骤单独施加权重衰减,不参与梯度与矩的计算,让正则效果等价于 SGD 中的权重衰减。公式如下:
一阶/二阶矩的计算(与Adam相同):
偏差修正(与Adam相同):
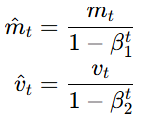
参数更新(解耦权重衰减,与 Adam 核心区别):先做 Adam 自适应更新,再单独施加权重衰减 ,不影响
计算。
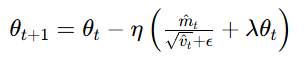
SGDW
SGDW,全称SGD with Momentum & Decoupled Weight Decay。设计思路与AdamW完全相同,只是是在SGDM之上做的解耦权重衰减。公式如下:
动量累积(同SGDM):
参数更新(解耦权重衰减,与 SGDM 核心区别)先做动量更新,再单独施加权重衰减 ,不影响动量累积。:
Something may help optimization
下面介绍几种优化常用的小方法,可能对优化有帮助:
- Shuffling(数据打乱): 这个用在Mini-Batch SGD,之前介绍过。
主要方法是在每轮(epoch)训练前,对整个训练集进行随机重排,再按批次(batch)输入模型。 - Dropout(随机失活): 防止神经网络过拟合,同时让模型学习更鲁棒的特征表示。
主要方法是在训练时以概率 - Gradient Noise(梯度噪声注入): 公式
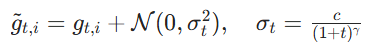
在梯度计算后,向梯度中注入随时间衰减的高斯噪声,噪声强度随训练步数增加而降低,前期鼓励探索,后期稳定收敛。主要作用是为梯度添加可控噪声,帮助模型跳出局部最优,增强探索性,提升泛化能力(尤其在高维非凸优化中)。 - Warm-up(预热): 之前介绍过。在训练初期使用较小的学习率,避免模型参数因梯度爆炸而发散,稳定前期训练过程。训练前若干步(如前 1000 步),学习率从 0 线性 / 分段增长至目标学习率,之后恢复为正常学习率调度。例如Transformer模型常用的线性Warm-up:
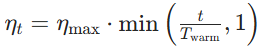 ,
, - Curriculum Learning(课程学习): 模仿人类学习顺序,从简单样本到复杂样本逐步训练,帮助模型更快收敛、提升泛化能力。
具体做法是先训练简单样本(如干净语音、低噪声图像、易分类样本),让模型学习基础模式,再逐步引入复杂样本(如带噪语音、难分类样本),让模型学习更精细的特征。 - **Fine-tuning(微调):**在预训练模型基础上,针对下游任务进行小样本训练,复用预训练学到的通用特征,提升下游任务性能。
- Normalization(归一化方法): 可参考文章PyTorch_conda-CSDN博客中Normalization Layers部分
- **Regularization(正则化):**已介绍过。
总结
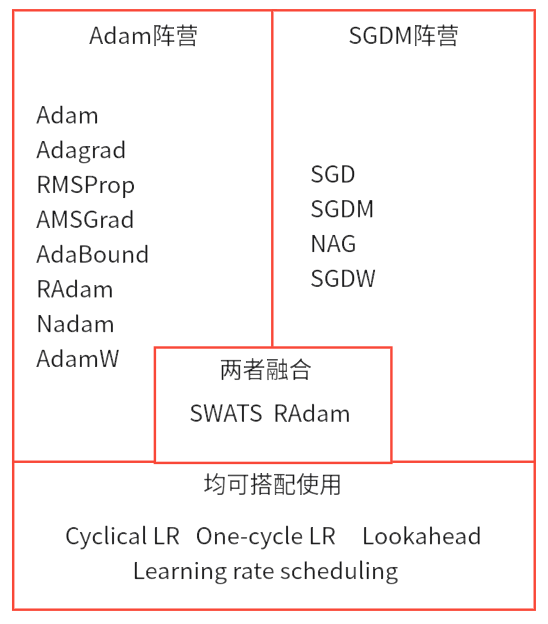
- Adam阵营:
核心优势:自适应学习率、收敛快、对超参数不敏感,适合复杂、高维、数据量大的场景。
优势领域:自然语言处理(NLP,大模型参数量级大、训练数据海量,Adam/AdamW 能快速收敛,且 AdamW 正确的权重衰减机制完美适配 Transformer 正则化需求)、生成式模型(如GAN、Diffusion,自适应学习率能稳定对抗训练中的梯度波动,RAdam/AMSGrad 可缓解 Adam 的梯度估计偏差,避免模式崩溃)、强化学习 - SGDM阵营:
核心优势:泛化性能更强、噪声引入更利于跳出局部最优,适合追求极致精度、模型结构相对简单的场景。
优势领域:计算机视觉(CV)(如图像分类(ResNet、EfficientNet)、目标检测(YOLO、Faster R-CNN)、语义分割等任务)、传统深度学习模型(CNN 为主,如轻量级 CNN、经典视觉 backbone等任务,模型结构相对简单,SGDM 的动量机制能有效平滑梯度噪声,避免过拟合,泛化能力更稳定)