主题9:DMA与零拷贝------让CPU从数据搬运中解放
- 核心问题:大量数据如何高效传输而不占用CPU?
- 串联领域:USB(内置DMA)→ 计算机体系结构(DMA控制器)→ 操作系统(零拷贝技术)→ 视觉SLAM(图像数据直接从相机到内存)
搬运与计算的分离
搬运与计算的分工
你或许会好奇:你的手机能同时拍照、导航、听音乐,CPU到底是怎么忙得过来的?其实,它并没有亲自做所有的事------就像一家餐厅的老板不会亲自端盘子,他负责炒菜,端盘子的事交给服务员。
计算机的本质是处理信息,但信息必须流动才能被处理------从磁盘到内存,从网卡到CPU,从摄像头到算法。在冯·诺依曼架构中,CPU既是计算的核心,也是数据流动的指挥者。然而,当数据量爆炸式增长,CPU如果还要亲自搬运每一个字节,它就会陷入一个尴尬的困境:越是忙于搬运,越无暇计算。
这个困境背后藏着一个深刻的矛盾:数据的移动与数据的处理,在资源上是竞争的。CPU的周期是有限的,每个用于加载/存储的周期,都意味着少执行一次算术或逻辑运算。那么,怎么办?
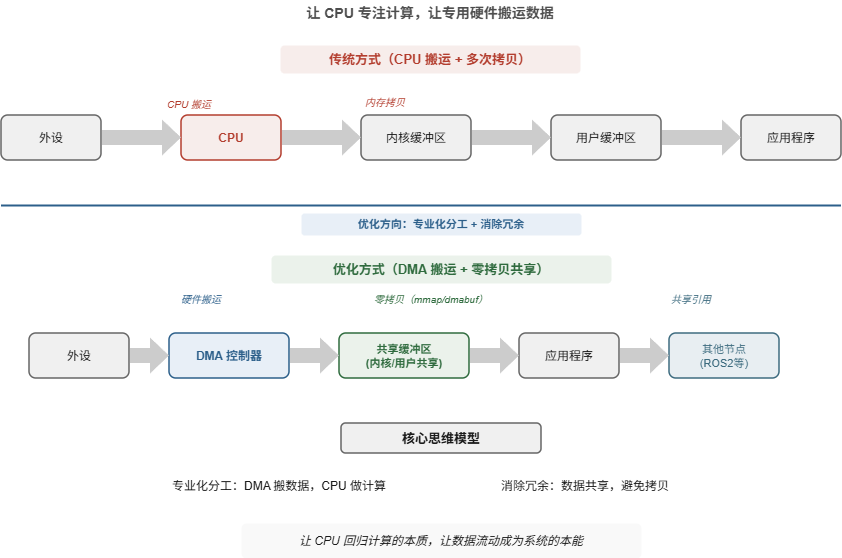
答案是:把"搬运"的活儿交给别人 。DMA(直接内存访问)与零拷贝技术,正是将"数据移动"这一职责从CPU剥离,交由专门的硬件和软件机制完成。让CPU专注于计算,让DMA专注于搬运------这就是关注点分离。
有意思的是,这个思想并非计算机独有。任何复杂系统都遵循类似的分工原则:物流系统中,快递员负责送货,商家负责生产和销售,两者分离才能高效运转。如果商家亲自送货,店面只能关门。同理,CPU的"店面"就是它的算力,一旦被数据搬运占据,计算任务就只能排队等待。
一、DMA:让数据流动成为"硬件级本能"
1.1 为什么CPU不适合做搬运工?
CPU擅长的,是复杂的控制流和算术逻辑。它的核心是ALU(算术逻辑单元)和控制单元,而数据搬运(内存与外设之间的传输)是一种极其简单却极其频繁的操作。用CPU做搬运,就像用超级计算机做打字员------大材小用,而且效率低下。
我们来看两种最原始的搬运方式:
- PIO(编程I/O)模式:CPU执行一个循环,每次从外设寄存器读一个字节,再存到内存里。一个字节可能需要多条指令,而外设的速率高达Gbps------这意味着CPU将完全被这个循环占据,别的事都干不了。
- 中断开销:每传输一个数据块(甚至每个字节)都可能触发一次中断,CPU需要保存和恢复上下文,这进一步加剧了开销。
你可能会说:那就把数据块变大一点,减少中断次数?但即使如此,CPU还是要亲自把数据从外设搬到内存,这个过程叫"内存拷贝"。拷贝一个字节,CPU要执行加载、存储指令;拷贝一百万个字节,就要执行两百万条指令------而这些指令,本来可以用来做更有价值的计算。
1.2 DMA的哲学:让"会者"专职其事
DMA控制器的设计极为精简:它只有几个寄存器(源地址、目的地址、长度),能发起总线事务,并在完成后发一个中断。它没有复杂的流水线、分支预测、缓存,因此功耗低、延迟小。它的全部工作就是:把一块数据从A搬到B,搬完了告诉我。
这就是计算机体系结构的第一条黄金法则:将简单重复的工作交给专用硬件。这条法则后来演变为GPU(图形处理)、NPU(神经网络)、DPU(数据处理)等各类专用加速器。
DMA的出现,使数据流动成为一种"本能":外设和内存之间有了直通的硬件通道,无需CPU的每一步指引。打个比方:人体的自主神经系统控制心跳和呼吸,不需要大脑意识介入;DMA就是让数据的"呼吸"(I/O)成为系统的本能反应。
1.3 从物理连接到逻辑抽象:IOMMU的升华
早期DMA直接操作物理地址,存在两个大问题:第一,安全性------设备可以访问任意内存,如果一个恶意设备故意写坏内核数据,后果不堪设想;第二,虚拟化困境------虚拟机中的操作系统看到的是虚拟地址,而DMA硬件只认物理地址,两者对不上。
IOMMU(输入输出内存管理单元)的引入,为DMA增加了一层地址转换,就像MMU为CPU提供虚拟内存一样。从此,DMA可以操作虚拟地址,设备被隔离在专属的I/O地址空间里,操作系统可以像管理虚拟内存一样灵活地管理DMA缓冲区。
IOMMU不仅是安全机制,它还是零拷贝的关键支撑:用户空间的虚拟地址可以直接映射给DMA硬件,实现真正的零拷贝数据传输。这是硬件与软件协同的典范------硬件提供能力,软件提供策略。
二、零拷贝:软件层面的"降本增效"
DMA解决了"外设→内存"的第一次搬运,但数据到达内核缓冲区后,还需要传递给应用程序。传统的read/write模型是这样的:
外设 → DMA → 内核缓冲区 → CPU拷贝 → 用户缓冲区 → 应用程序
你看,即使DMA帮我们省去了从外设到内核的CPU搬运,但从内核到用户空间的那一次拷贝,还是得CPU亲自来。而且,每次系统调用还会触发两次上下文切换(用户态↔内核态)。这些开销加起来,对于高频、大块的数据流来说,非常可观。
零拷贝技术的出现,源于一个深刻的反思:数据真的需要经过每一个中间层吗?能不能让它"抄近路"直接抵达目的地?
2.1 引用传递 vs 数据复制
信息在系统中传递有两种方式:复制内容,或者传递引用。复制是昂贵的------它占用内存带宽和CPU周期;引用是廉价的------只需传递一个指针或描述符。
零拷贝的本质,就是把数据复制尽可能转化为引用传递。举几个常见的例子:
- mmap:把内核缓冲区映射到用户空间,传递的是虚拟地址的映射关系,而不是数据内容。应用程序可以直接访问内核缓冲区,就像访问自己的内存一样。
- sendfile:在两个文件描述符之间传递数据,内核直接在页缓存和socket缓冲区之间建立DMA传输通道,数据全程不经过用户空间。
- dmabuf:在不同的设备驱动之间共享DMA缓冲区,传递的是一个文件描述符,它指向同一块物理内存。
这种思想在分布式系统中演化为RDMA(远程直接内存访问),在网络中演化为"零拷贝网络栈"。无论形态如何变化,核心始终是:数据只在一处存在,所有需要它的人共享一个引用。
2.2 拷贝的隐性成本:不仅仅是CPU周期
数据拷贝的直接成本是CPU时间和内存带宽,但隐性成本更值得我们警惕:
- 缓存污染:拷贝数据会冲刷CPU缓存,导致后续计算的关键数据被逐出。你可能只是拷贝了一堆数据,却把即将要用的变量挤出了缓存,后续计算反而变慢了。
- TLB压力:大量拷贝涉及新页面的映射,可能引起TLB(转换后备缓冲器)颠簸。
- 能源消耗:你可能不知道,移动数据比计算消耗更多的能量。据估计,一次64位数据移动的能耗大约是64位整数运算的十倍。在移动设备和数据中心这种能耗敏感的场景下,零拷贝的价值尤为突出。
因此,零拷贝不仅是性能优化,更是能效优化。
三、融合:DMA与零拷贝构建的端到端数据高速公路
把DMA和零拷贝结合起来,我们得到一条从物理设备到应用程序的"数据高速公路":
- 入口匝道(设备→内存):DMA控制器把数据从外设直接搬入预分配的缓冲区,CPU完全不介入。
- 主线(内存内部):数据通过mmap或dmabuf在不同模块之间共享,不需要复制。
- 出口匝道(内存→设备):输出时,DMA控制器把数据从共享缓冲区直接发送给另一个外设(比如网卡、显示器)。
这条高速公路实现了数据移动的完全硬件化:数据从进入系统到离开系统,全程由DMA引擎驱动,CPU只在必要的控制点(比如中断、同步)短暂介入一下。
3.1 案例深度剖析:视觉SLAM中的数据流
让我们以一个视觉SLAM系统为例,看看这条高速公路的每一个细节。这个例子可能会让你对前面讲的内容有更直观的感受。
- 摄像头端:CMOS传感器生成图像,通过MIPI CSI-2接口发送出去。MIPI接收器内部的DMA引擎直接把图像数据写入通过CMA(连续内存分配器)分配的物理连续内存------这是第一次DMA搬运,CPU没参与。
- 内核驱动:V4L2驱动通过videobuf2框架管理这些缓冲区。应用程序通过mmap获得用户空间的虚拟地址,这个地址与DMA缓冲区建立了映射------零拷贝就此实现,没有发生任何数据复制。
- 算法处理:SLAM算法直接通过映射地址读取像素数据,提取特征点。特征点的数据量远小于原始图像,可以进一步通过DMA传递给硬件加速器(比如FPGA实现的特征提取单元)。
- 多节点共享:如果系统采用ROS2,可以通过dmabuf_transport把缓冲区的文件描述符传递给其他节点(比如可视化节点、建图节点)。所有节点共享同一份物理内存,没有拷贝。
整个过程,图像数据只在传感器和内存之间流动了一次,然后被多个模块"引用"。对比传统方式:read()把数据拷贝到用户空间,ROS序列化再拷贝一次,可视化节点又拷贝一次------数据被反复复制了很多次,CPU被大量memcpy占据,SLAM的实时性就没了。
四、零拷贝并非万能
任何工程技术都是权衡的结果。零拷贝虽然强大,但也有它的适用边界和潜在代价。
4.1 什么时候零拷贝不值得?
- 小数据量:对于几十字节的控制消息,建立共享缓冲区的开销(比如页表映射、同步)可能比拷贝本身还大。
- 数据需要修改:如果多个消费者需要对数据做私有的修改,共享反而会带来复杂性(这时需要写时复制)。
- 硬件不支持:不是所有的DMA引擎都支持Scatter-Gather,也不是所有的设备驱动都实现了dmabuf导出。你要用的平台可能根本没法做零拷贝。
4.2 隐形成本清单
- 缓存一致性:DMA写内存之后,CPU缓存里可能还保留着旧数据,需要显式地无效化;反过来,CPU写内存之后,DMA读取之前需要冲刷缓存。这些操作都有开销,而且需要程序员正确地使用DMA API。
- 内存锁定:用于DMA的页面不能换出,这可能会减少可用的内存,增加内存压力。
- 同步复杂性:共享数据需要同步机制(比如fence、信号量),否则可能导致数据竞争。
- 调试难度:数据流经过多个模块而且没有拷贝,一旦出错,很难定位问题出在哪个环节。
所以,零拷贝是一种优化手段 ,而不是默认选项。它适用于高频、大块、只读或只写的数据流------而这正是摄像头、网络、雷达等外设的典型特征。
五、思维模型:从数据流动到系统设计
5.1 两个核心思维模型
- 数据流图与瓶颈识别 :在系统设计初期,先画一张数据流图,标记每一步是否发生了拷贝。然后问自己三个问题:
- 这次拷贝是必要的吗?
- 能不能让多个消费者共享同一份数据?
- 共享的代价(同步、生命周期管理)是否可以接受?
- 硬件-软件协同设计:考虑数据流动时,不能只盯着软件算法,也要思考硬件能力:DMA引擎支持哪些传输模式?IOMMU开了吗?缓存一致性协议会不会影响性能?只有在软硬件协同的视角下,才能设计出最优的数据路径。
5.2 从DMA到更广义的"数据移动优化"
DMA和零拷贝只是数据移动优化的一个起点。更广义的优化还包括:
- 近数据处理(Near-Data Processing):把计算推送到数据所在的位置,而不是移动数据到CPU。例如,在SSD内部直接执行过滤操作,只把结果返回给CPU。
- 内存计算(In-Memory Computing):在内存中直接执行计算,彻底消除数据移动。
- 可组合数据系统(Composable Data Systems):通过CXL等互联技术,构建资源池化的数据中心,数据可以在内存池、计算池、存储池之间高效流动。
这些前沿技术都遵循同一个原则:最小化数据移动,让计算尽可能靠近数据。
写在最后:让CPU回归计算的本质
DMA与零拷贝共同回答了计算机系统设计中的一个核心问题:如何让数据流动的效率最大化,同时让CPU的算力专注于创造价值?
答案不是简单地增加带宽或频率,而是通过两条路径:
- 专业化分工:DMA控制器负责数据移动,CPU负责计算------这是硬件级别的关注点分离。
- 消除冗余:零拷贝技术消除不必要的数据复制------这是软件级别的精益求精。
从更深层次看,这反映了系统设计的一条普遍原则:任何资源都不应被浪费,尤其是最宝贵的资源------人的时间(等待计算完成)和电的能耗(移动数据)。在数据爆炸的时代,我们无法制造出无限快的CPU,但可以通过更聪明的数据移动策略,让现有的硬件发挥出远超其规格的性能。
作为"物理世界与信号基础"系列的一部分,理解DMA与零拷贝,不仅仅是掌握一项技术,更是建立一种系统观:在抽象与具体之间、在硬件与软件之间、在性能与简洁之间,找到那个微妙的平衡点。
让CPU从数据搬运中解放
数据搬运的困境与解耦之道
如果你观察过现代计算机系统的工作方式,可能会发现一个有趣的现象:4K视频流、千兆网络、高帧率雷达点云、实时SLAM算法------这些应用产生的数据量正在以指数级增长。但如果每一次数据进出内存都需要CPU亲力亲为,那么再强大的处理器也会沦为一个"搬运工",整天忙着把数据从这儿搬到那儿,反而没时间做真正的计算。
这就是计算机系统性能优化的核心命题:如何让CPU从繁琐的数据搬运中解放出来?
答案有两个:DMA(直接内存访问) 和 零拷贝(Zero-Copy)。DMA从硬件层面让外设直接与内存交换数据,零拷贝从软件层面消除冗余的数据复制。两者协同,构建了一条从物理世界到应用程序的"数据高速公路"。
这篇文章不仅要讲清楚它们的原理,还会带你遍历USB、Wi-Fi、MIPI、毫米波雷达、视觉SLAM等多个技术领域,看看它们是如何以不同方式践行同一套核心思想的。读完之后,你将建立起一个关于"数据流动"的通用思维模型------这个模型可以帮你快速理解任何一个新系统的I/O设计,也能在你自己的项目中找到优化的突破口。
第一部分:DMA ------ 硬件级的数据移动
1.1 计算机体系结构中的DMA通用原理
DMA的核心思想其实很直接:让外设绕过CPU,直接访问系统内存。系统中有一个专门的DMA控制器(DMAC),它作为总线主控设备,能够自己发起总线事务。
整个流程是这样的:当外设需要传输数据时,CPU只需配置DMA控制器------告诉它源地址在哪、目的地址在哪、要传多长------然后启动传输。DMA控制器接手后,就在内存和外设之间批量搬运数据。等传输完成,它发一个中断通知CPU:"活干完了,你来收个尾吧。"
这个机制把CPU从逐字节的PIO(编程I/O)模式中彻底解放了出来。举个例子,USB 2.0高速模式有480 Mbps的带宽。如果采用PIO,CPU会被完全占据,什么事都干不了;而用DMA方式,CPU只在初始化和中断处理时介入一下,耗时不过几微秒。
但DMA并不是"一刀切"的实现。不同的外设,因为数据特性不同,其DMA引擎的设计也千差万别。理解这些差异,是融会贯通的关键。
1.2 各技术领域的DMA实现与特性
| 技术领域 | DMA实现特点 | 为何如此设计 |
|---|---|---|
| USB 2.0/3.0/OTG | 主机控制器(xHCI)内置DMA引擎,使用描述符环管理传输任务。USB 3.0支持Scatter-Gather,可处理非连续物理内存。OTG双角色模式下,DMA需在Host和Device模式间切换。 | USB是通用总线,连接设备多样,描述符环可灵活管理多个端点,Scatter-Gather适应内存碎片,提高大块传输效率。 |
| Wi-Fi | 无线网卡通过PCIe/SDIO接口连接,内置DMA引擎,使用描述符环管理收发包。现代Wi-Fi芯片甚至集成硬件安全加速器的DMA,实现加密卸载。 | Wi-Fi数据流突发性强,描述符环可高效管理多队列,硬件卸载能进一步释放CPU。 |
| MIPI CSI-2 | 接收器内置DMA引擎,要求缓冲区物理连续(常通过CMA分配),并支持缓存重映射(uncached→cached)。 | 移动摄像头产生连续流式数据,物理连续可简化地址计算,缓存重映射平衡CPU访问效率与DMA一致性。 |
| 毫米波雷达 | 雷达芯片内部集成专用DMA,如英飞凌TC3xx SPU的输入DMA支持三维寻址(自动转置距离-多普勒数据立方体),实现硬件加速器与内存间高效数据交换。 | 雷达信号处理需要频繁访问三维数据,专用DMA可减少软件重排开销,实现实时处理。 |
| 计算机体系结构 | 现代SoC集成多通道DMA控制器,支持优先级、链表传输。PCIe总线本身具备DMA能力,NVMe SSD通过提交队列/完成队列直接与内存交换数据。IOMMU提供地址转换与隔离。 | 为各种外设提供统一DMA服务,同时通过IOMMU支持虚拟化和零拷贝。 |
你可能已经发现了:尽管外设形态各异,但DMA的核心角色始终是"数据搬运"。设计上的差异,源于数据流的特征------是流式(摄像头)还是块式(存储),是二维(图像)还是三维(雷达),是否需要硬件加速(加密、FFT)。掌握了这个思路,以后遇到任何新外设,你都能快速理解其DMA设计的初衷。
第二部分:零拷贝 ------ 软件层面的数据复用
DMA解决了"外设→内存"的第一次搬运。但数据到达内存后,还需要从内核空间传递到用户空间,或者在多个模块之间共享。如果每次传递都伴随一次内存拷贝,CPU依然会陷入大量的数据复制中。零拷贝技术的目标,就是消除这些冗余拷贝。
2.1 操作系统提供的零拷贝通用机制
操作系统提供了多种零拷贝系统调用和框架:
- mmap:把内核缓冲区映射到用户空间,应用程序可以直接访问DMA写入的数据,不需要再拷贝一次。
- sendfile/splice:在两个文件描述符之间直接传输数据,数据全程不经过用户空间。
- io_uring:新一代异步I/O接口,支持缓冲区注册和共享,配合DMA实现真正的零拷贝。
- dmabuf:Linux内核的缓冲区共享机制,允许不同设备驱动共享同一个DMA缓冲区。
这些机制的核心思想其实是一样的:传递引用(指针或文件描述符),而不是传递数据副本。
2.2 各技术领域的零拷贝实践
| 技术领域 | 零拷贝实现方式 | 作用 |
|---|---|---|
| USB摄像头(V4L2) | mmap模式:用户空间通过mmap访问驱动分配的DMA缓冲区。 | 避免read方式的内核→用户拷贝,直接处理图像。 |
| Wi-Fi网络服务器 | sendfile:从磁盘文件直接传输到网卡,数据从页缓存DMA到网卡。 | 文件下载场景下,CPU占用降低50%以上。 |
| MIPI摄像头→AI处理 | dmabuf:V4L2导出dmabuf_fd,传递给RGA/NPU/DRM,实现采集→处理→显示全流程零拷贝。 | 多硬件模块共享同一物理内存,避免多次搬移。 |
| 毫米波雷达(DSP+硬件加速器) | 硬件加速器与DSP通过共享内存和DMA直接交换数据,软件只传递指针。 | 实现实时信号处理链,无需CPU参与数据移动。 |
| 视觉SLAM(ROS2) | dmabuf_transport:相机节点导出dmabuf_fd,SLAM节点和可视化节点共享同一缓冲区。 | 消除ROS2节点间的大图像数据拷贝,降低延迟。 |
| USB OTG设备模式 | FunctionFS mmap:用户空间预分配DMA缓冲区,配合libaio实现异步零拷贝传输。 | 手机作为USB摄像头时,视频数据直接进入应用缓冲区。 |
这里有一个要点:零拷贝的适用场景往往是高频、大块、只读或只写的数据流。不同的软件栈(V4L2、网络、ROS2)都在自己的领域内实现了零拷贝,但本质都是"共享物理内存,传递所有权或使用权"。理解这一点,你就能在任何需要高效数据传输的软件系统中主动应用这一思想。
第三部分:端到端数据流实战 ------ 以视觉SLAM为例
现在,让我们通过一个典型的视觉SLAM系统,完整地串起DMA与零拷贝在各个技术环节的应用。这个例子可能会让你对前面讲的内容有更直观的感受。
系统组成
- 传感器:MIPI摄像头(嵌入式平台)或USB 3.0摄像头(桌面平台)
- 计算单元:ARM SoC(如RK3588)或x86主机,集成ISP、GPU、NPU
- 通信:Wi-Fi/以太网(用于分布式SLAM或云端备份)
- 存储:NVMe SSD(记录数据集)
数据流全程解析
- 图像采集(MIPI/USB)
- 硬件DMA:MIPI CSI-2接收器的DMA把原始图像数据写入CMA分配的物理连续内存;或者USB xHCI控制器的DMA把数据写入预分配的用户空间缓冲区(通过V4L2 mmap)。
- 零拷贝1:SLAM主程序通过mmap直接访问这个缓冲区,开始特征提取。此时,图像数据还没有发生过一次软件拷贝。
- 预处理加速(ISP/GPU)
- 如果需要格式转换或降噪,SLAM程序把图像缓冲区的dmabuf_fd传递给ISP或GPU驱动。硬件直接读取同一物理内存进行处理,结果仍然存在原缓冲区或另一个共享缓冲区里。零拷贝2实现了跨硬件共享。
- 分布式协作(Wi-Fi/以太网)
- 如果需要把图像或特征点发给其他机器人,可以使用零拷贝网络传输 :通过sendfile或io_uring把数据直接从内核缓冲区(或已映射的用户缓冲区)发出,网卡的DMA引擎直接读取。如果网络支持RDMA(如RoCE),还可以实现远程直接内存访问,CPU完全无感。
- 数据记录(NVMe SSD)
- 记录数据集时,可以通过mmap把图像缓冲区映射到文件,或者使用io_uring直接提交DMA请求。数据从内存由NVMe控制器DMA到SSD介质。零拷贝3避免了文件系统缓冲区的额外复制。
- 整个过程中的CPU角色
- CPU只参与了:初始化配置、中断响应(比如帧完成中断)、特征提取与后端优化算法。数据搬运完全由各级DMA和零拷贝机制完成。
如果没有DMA和零拷贝
你不妨想象一下没有这些技术会怎样:CPU需要逐字节地从摄像头I/O端口读取数据(PIO)。1080p@30fps的视频流大约124MB/s,这足以把CPU完全耗尽。每帧图像在V4L2、ROS2、GPU、网络栈之间反复拷贝6到8次,内存带宽浪费数GB/s,延迟增加几十毫秒------SLAM的实时性根本无从谈起。
第四部分:性能权衡与通用设计原则
4.1 共同挑战:缓存一致性
DMA直接读写内存,而CPU通过缓存访问同一块内存,两者可能看到不一致的数据。怎么解决?
- 硬件一致性:部分SoC支持硬件缓存一致性(如CXL),但成本较高。
- 软件维护:驱动需要在DMA操作前后调用cache flush/invalidate函数(比如dma_map_single)。在零拷贝共享中,用户空间需要使用DMA_BUF_IOCTL_SYNC来同步。
4.2 内存锁定(Pinning)
用于DMA的用户内存必须锁定在物理内存中,不能被换出。如果大量锁定,可能导致内存压力,所以需要合理设计缓冲区的大小和数量。
4.3 中断开销与轮询模式
高吞吐的设备(比如10GbE网卡、4K摄像头)如果每帧都触发中断,可能引发"中断风暴"。解决方案有两个:
- 中断合并:把多个数据块合并成一个中断。
- 轮询模式驱动(NAPI):在中断后切换为轮询,减少中断次数。
4.4 设计原则总结
从这些讨论中,我们可以提炼出几条通用的设计原则:
- 最小化数据移动:数据每复制一次,就多一份CPU开销和延迟。画出数据流图,识别出冗余拷贝。
- 让数据尽可能靠近计算:利用dmabuf共享,把数据保留在硬件加速器附近。
- 硬件能做的绝不交给软件:DMA、硬件卸载(比如TCP校验和)能大幅减轻CPU的负担。
- 权衡零拷贝的适用场景:小数据量或者需要频繁修改的数据,零拷贝可能得不偿失。
数据流动的通用思维模型
通过上面的剖析,我们可以提炼出一个关于"数据流动"的通用模型:
生产者\] → \[搬运工1\] → \[存储/共享区\] → \[搬运工2\] → \[消费者
- 生产者:外设(摄像头、网卡、雷达传感器)
- 搬运工1:DMA控制器(硬件)
- 存储/共享区:物理内存,可能被多个消费者共享
- 搬运工2:零拷贝机制(软件)或其他DMA
- 消费者:CPU核心、硬件加速器(GPU/NPU)、网络、存储
这个模型可以映射到任何具体场景:
| 场景 | 生产者 | 搬运工1 | 共享区 | 搬运工2 | 消费者 |
|---|---|---|---|---|---|
| USB摄像头 → SLAM | USB摄像头 | xHCI DMA | V4L2缓冲区 | mmap | SLAM算法 |
| Wi-Fi → Web服务器 | 网卡 | 网卡DMA | 套接字缓冲区 | sendfile | 网卡(发送) |
| MIPI → AI推理 | MIPI传感器 | CSI接收器DMA | dmabuf | 驱动共享 | NPU |
| 雷达 → ADAS | ADC | 专用DMA | 片内SRAM | 指针传递 | DSP/HWA |
| 分布式SLAM | 本地相机 | 多级DMA | 共享内存 | RDMA | 远程节点 |
这个模型的价值在于:当你遇到一个新领域(比如CXL内存池、智能网卡),只需要识别出生产者和消费者,以及它们之间的搬运工是如何实现的,就能快速理解其数据流动的效率瓶颈和优化空间。它把你之前学到的所有技术点串联成了一个有机的整体。
写在最后:让CPU回归计算的本质
DMA与零拷贝共同回答了计算机系统设计中的一个核心问题:如何让数据流动的效率最大化,同时让CPU的算力专注于创造价值?
答案不是简单地增加带宽或频率,而是通过两条路径:
- 专业化分工:硬件DMA负责搬运,CPU负责计算。
- 消除冗余:软件零拷贝避免不必要的数据复制。
从USB到Wi-Fi,从MIPI到雷达,从操作系统到ROS2,我们看到同一套思想在不同领域以不同形式反复出现。理解这些原理,既能帮你做好当前项目的优化,也能让你在技术不断变化时抓住那些不变的核心。
数据流动的优化,本质上是在告诉系统:不要让CPU做它不擅长的事。
预习·自测清单
-
DMA(直接内存访问)的核心工作原理是什么?它与PIO(编程I/O)模式在CPU占用和传输效率上有何本质区别?
提示:DMA控制器作为总线主控设备,在CPU配置源/目的地址和长度后自主完成批量传输,结束时发中断;PIO需CPU逐字节搬运。DMA使CPU占用率从接近100%降至个位数。 -
什么是零拷贝?列举至少三种操作系统层面实现零拷贝的系统调用或机制,并简述各自适用场景。
提示:mmap(内核缓冲区映射到用户空间)、sendfile(文件描述符间直接传输)、splice(基于管道的零拷贝)、io_uring(支持缓冲区注册)、dmabuf(跨设备共享)。 -
USB 2.0、USB 3.0 和 USB OTG 在 DMA 实现上有哪些关键差异?为什么 USB 3.0 必须支持 Scatter-Gather?
提示:USB 3.0带宽5Gbps,需处理物理不连续内存;xHCI控制器增强描述符环;OTG需在Host/Device模式切换DMA方向。 -
MIPI CSI-2 摄像头为什么通常要求 DMA 缓冲区物理连续?什么是 CMA 和缓存重映射?
提示:MIPI是流式数据,物理连续简化地址计算;CMA(连续内存分配器)预留大块物理内存;缓存重映射将uncached内存转为cached提升CPU访问效率。 -
毫米波雷达信号处理中,DMA 如何实现三维数据立方体的自动转置(距离-多普勒-天线)?这带来了什么好处?
提示:英飞凌TC3xx SPU的输入DMA支持三层嵌套循环寻址,可配置地址转置模式,避免软件重排,实现实时FFT处理。 -
在视觉SLAM系统中,从摄像头采集到算法处理再到多节点共享,如何通过 DMA 和零拷贝实现端到端的数据不落地?
提示:V4L2 mmap直接访问DMA缓冲区;全程无软件拷贝。 -
零拷贝技术并非没有代价。列举至少两个隐形成本,并解释在什么情况下零拷贝反而得不偿失。
提示:缓存一致性开销(cache flush/invalidate)、内存锁定(pinning)导致可用内存减少;小数据量时建立共享映射的开销超过拷贝本身。 -
从 DMA 和零拷贝的发展(IOMMU、PCIe P2P、CXL、RDMA)中,你能总结出数据移动优化的通用趋势是什么?
提示:硬件加速(专用DMA引擎)、消除中间层拷贝(直接设备间通信)、地址隔离与虚拟化支持(IOMMU)、缓存一致性扩展(CXL)、跨机远程直接访问(RDMA)。