文章标题:End-to-End Autonomous Driving: From Classic Paradigm to Large Model Empowerment---A Comprehensive Survey
**翻译:**端到端自动驾驶:从经典范式到大模型赋能------综合综述
文章发表于二区Top期刊IEEE INTERNET OF THINGS JOURNAL
Digital Object Identifier 10.1109/JIOT.2025.3635092
摘要:
近年来,自动驾驶技术在全球范围内迅速发展,为日益严重的交通拥堵和道路安全相关挑战提供了有效解决方案。在各种范式中,端到端自动驾驶由于其简化的架构、增强的决策一致性以及出色的泛化能力,已经成为传统模块化系统的一个有前景的替代方案。本综述全面回顾了端到端自动驾驶的发展历程和核心技术,强调了模仿学习(IL)、强化学习(RL)等范式的应用与发展。此外,本文还重点介绍了由基础模型赋能的新兴范式,例如大型语言模型(LLMs)和视觉-语言模型(VLMs),并系统地对规划、推理、数据生成和场景理解方面的最新进展进行了分类。在多模态融合复杂性、样本效率低和安全风险等持续挑战的背景下,本综述总结了代表性研究工作及其相应解决方案。最后,本文概述了未来方向,包括利用世界模型(WMs)实现数据生成与推理优化的统一、推动基础模型架构朝向模块化设计、稀疏激活机制和知识蒸馏的发展,以及实现可部署、可迁移和统一的多模态框架。本综述旨在为端到端自动驾驶领域的研究人员提供全面的理论和技术参考,促进其向更高性能、更强泛化能力和更高安全保障方向发展。
关键词:
端到端自动驾驶、大型语言模型(LLMs)、多模态融合、世界模型(WM)
一、引言
A. 自动驾驶发展的背景
自动驾驶技术已经引起了全球广泛关注,并正在推动智能交通和未来出行模式的变革。其中一个主要推动因素是全球机动车保有量的快速增长,这加剧了交通拥堵和道路事故等问题,其中许多事故是由人为错误造成的,而人为错误仍然是导致死亡的主要原因。为了解决这些问题,学术界和行业越来越认为自动驾驶是提高交通安全和改善交通效率的有前景的解决方案,通过替代或辅助人类驾驶员来实现。在这种需求的推动下,自动驾驶迅速成为国际研究和产业发展的焦点。许多国家已将其确定为战略性新兴产业,并出台支持性政策和法规,以加快其技术进步和商业化部署。
在技术方面,深度学习的突破为自动驾驶系统的发展提供了强劲的动力。深度神经网络在特征表示和复杂模式建模方面表现出强大的能力,在目标检测、场景理解和路径规划等任务中取得了显著的成功。这些发展为数据驱动的自动化系统奠定了坚实的基础,同时也推动了相关领域的广泛应用。
在架构方面,早期的自动驾驶系统通常采用模块化框架,将感知、预测、决策和控制分离为由明确定义的接口连接的独立组件11。虽然这种设计提供了可解释性和工程灵活性,但它往往在实时响应能力、跨模块一致性以及累积误差传播方面存在局限12。为克服这些限制,端到端自动驾驶范式近年来引起了越来越多的关注13。该方法采用统一的学习架构,将原始传感器输入直接映射到控制输出,消除了对人工设计中间模块的需求。它具有结构简化、计算效率高和强大的泛化能力,并正成为当前研究中愈发突出的焦点。
我们重点关注端到端自动驾驶的发展轨迹及最新进展,特别强调由大模型驱动的方法。如图1所示,本综述的结构安排如下:第I部分介绍模块化和端到端自动驾驶系统的基本框架;第II部分回顾经典的端到端方法,包括模仿学习(IL)、强化学习(RL)及其他代表性策略;第III部分作为本综述的核心,对主流大模型驱动的方法进行全面分类和总结,突显其技术趋势和核心特征;第IV部分深入分析当前研究面临的主要挑战,并基于现有文献讨论未来探索的潜在方向;第V部分总结评估方法和基准系统;第VI部分则为本文的结论。此外,图2描绘了端到端自动驾驶的主要演化轨迹,而图3按时间顺序交织关键技术突破、市场驱动因素及各发展阶段的杰出研究机构或企业,提供了详尽且结构连贯的叙述。按照这两条路线图,本综述系统地对现有文献和市场演变进行分类和全面分析,确保主题连续性和覆盖的完整性。
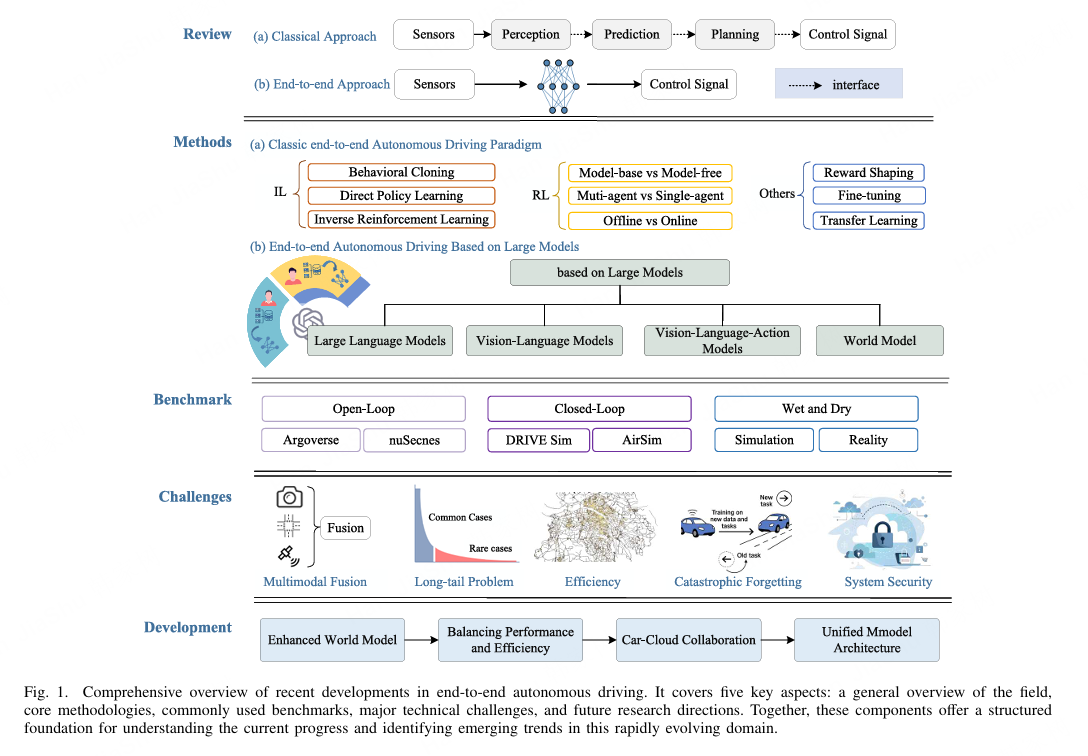
图1. 端到端自动驾驶最新进展的综合概述。它涵盖了五个关键方面:该领域的一般概述、核心方法、常用基准、主要技术挑战以及未来研究方向。这些组成部分共同为理解当前进展和识别这一快速发展的领域中新兴趋势提供了结构化的基础。
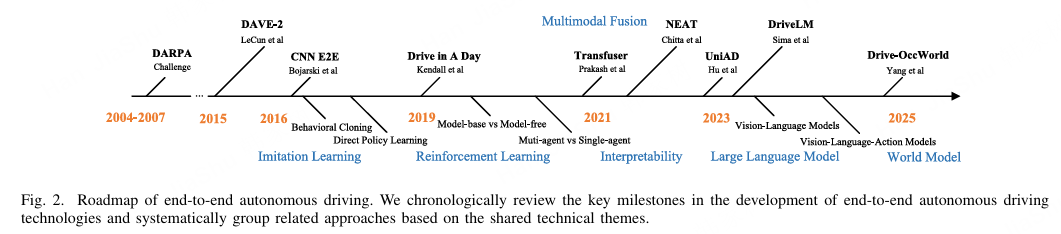
图 2. 端到端自动驾驶路线图。我们按时间顺序回顾了端到端自动驾驶技术发展的关键里程碑,并根据共享的技术主题系统地对相关方法进行分类。
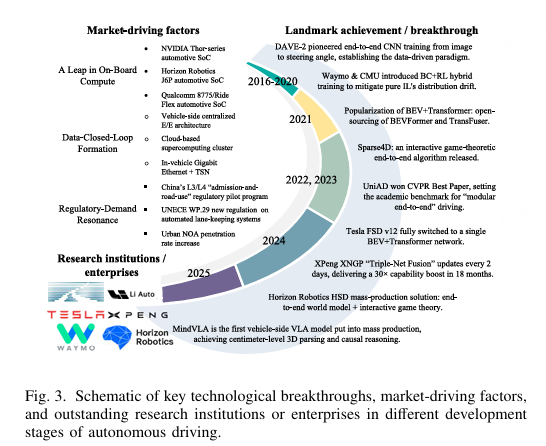
图 3. 自动驾驶不同发展阶段关键技术突破、市场驱动因素以及杰出科研机构或企业的示意图。
B. 模块化与端到端:自动驾驶架构的两种演进路径
**1)模块化自动驾驶系统:**模块化自动驾驶系统通常遵循感知--决策--控制的流程,其中整体任务根据工程设计被划分为独立的模块。这种分解通过将优化任务隔离在各个组件内,从而简化了系统的复杂性。如图4所示,感知模块融合多传感器和定位数据,检测和跟踪障碍物及交通标志等关键要素。随后,决策和路径规划模块分析交通环境和车辆状态,以生成安全且可行的行驶轨迹。最后,控制模块通过发出方向盘和加速指令来执行该轨迹,实现精准的横向和纵向运动控制。
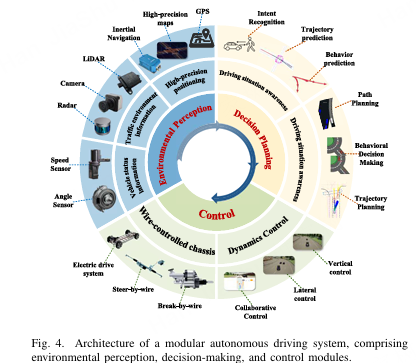
图4. 模块化自动驾驶系统的架构,包括环境感知、决策和控制模块。
**a)环境感知:**作为自动驾驶系统的核心组成部分,环境感知从多模态传感器中提取信息,以支持下游决策和控制。感知流程通常包括定位、物体检测、场景理解、行为预测和物体跟踪。定位方面,主流方法包括全球导航轨道卫星系统惯性测量单元(GNSS-IMU)集成、目视同步定位与测绘(SLAM)、光探测与测距(LiDAR)SLAM以及多传感器聚变。GNSS或全球定位,而SLAM方法则利用环境特征实现高精度的局部地图绘制。此外,近年来多频智能手机GNSS14、15的进展,加上气压计、三维地图和磁力计等辅助传感器的无缝集成,已实现近米级精度,凸显了提升端到端自动驾驶定位稳健性和多模态感知的前景。物体检测通过基于图像、激光雷达(LiDAR)或融合传感器的方法,识别静态和动态元素,如车道、轨道标志、可行驶区域和三维物体。融合策略或在复杂且恶劣条件下更强的鲁棒性16。场景理解通过语义、实例和全景分割,以及深度和光流估计来刻画驱动上下文17。近期利用老化的Transformer架构和多尺度特征的模型在公开基准测试中显著提升了性能。在行为预测方面,系统利用深度生成模型预测tra c代理的未来轨迹,这些模型考虑了过去的运动、场景语义和交互,为决策提供了可靠的输入。多对象跟踪维护动态代理的身份和状态更新。虽然Kalman的追踪器在简单情况下依然有效,但基于深度学习的追踪器更能处理复杂且互动的环境。当前研究越来越强调感知模块与追踪模块之间的联合建模和协作优化。
总之,感知发展正从等值特定任务的改进向统一的多任务建模和多模态融合发展。未来方向将优先提升实时电子科学、在多种条件下的稳健性,以及更紧密地与预测和规划的整合,以确保开放世界环境下的可靠运行。
**b)决策规划:**决策模块在自动驾驶系统中充当感知与控制之间的关键桥梁,负责在复杂和动态环境中选择合适的行为。传统方法依赖基于规则的逻辑,而深度学习方法由于其强大的表示能力和泛化能力,越来越受到关注,并且现在被广泛应用于高层策略学习。
在模块化架构中,决策通常分层结构,包括全局路径规划、行为决策和运动规划。这一三层框架可以追溯到2007年的DARPA城市挑战赛,并在今天仍有影响力。全局规划层利用高清地图在道路网络级别搜索最优路径,常用的算法有Dijkstra算法和A*算法,其中A*通过启发式引导提高效率,减少搜索空间,并增强实时性能。行为决策层将感知、交通规则和场景上下文结合起来,生成短期决策,例如保持车道、跟车、变道、超车或紧急制动。它预测交通的近期发展,并相应地选择行为。运动规划层,也称为局部规划,根据车辆状态、本地环境和全局路径参考,生成平滑且可行的短时间轨迹。这些轨迹优化安全性、舒适性和效率,并传递给控制模块执行。
**c)控制模块:**控制模块位于自动驾驶系统的执行层,将规划的轨迹转换为可执行的指令,如转向、油门和制动。这些指令是基于车辆当前的动态状态计算的,以确保轨迹跟踪的安全性和稳定性。在常见的控制算法中,比例-积分-微分(PID)和模型预测控制(MPC)被广泛使用。PID依赖于期望状态与实际状态之间的误差,结合比例、积分和微分项。其简单性和响应性使其适用于不确定或快速变化的环境,但缺乏前瞻性,在受约束条件下表现较差。相比之下,MPC利用预测系统模型在有限时间范围内优化控制输入,每步仅应用第一个输入,这是一种递推优化方式。这种闭环机制使MPC能够有效处理约束和干扰,非常适合高精度控制任务。作为最终执行器接口,控制模块必须在响应性、稳定性和约束处理能力之间取得平衡。随着线控系统和车载计算的不断进步,智能策略(如多MPC、数据驱动控制和自适应方法)变得日益重要。此外,为自动驾驶开发的控制技术在其他领域也具有潜在应用18、19、20、21、22。
总体而言,模块化规划架构提供了较强的可解释性和可部署性,仍然是当前工业自动驾驶系统的主流解决方案。然而,这种方法高度依赖预定义规则和人工工程。子模块间协同不足,以及对误差传播的敏感性,限制了其应对复杂动态真实交通场景的能力。因此,增强模块间交互机制并通过统一优化提高全局鲁棒性,已成为推进模块化规划方法的关键方向。
**2)端到端自动驾驶:**端到端的自动驾驶模式为传统模块化系统提供了一种有前景的替代方案,它通过完全可微分的框架,将原始传感器数据(如摄像头图像或雷达信号)直接映射到轨迹或控制指令。其主要目标是优化整体规划性能,确保每个决策都能促成一致且高效的驾驶行为。
在功能上,端到端方法可以分为传统端到端范式和模块化端到端范式 23,24。传统范式省略了中间任务的监督,学习从感知到控制的直接映射。这减少了误差积累并简化了部署,但缺乏结构化表示在复杂场景下限制了安全性和可解释性。相比之下,模块化端到端方法结合了辅助任务的监督,通常使用基于注意力的机制。这提高了训练优化效果,并在一定程度上增强了安全性。然而,仍然存在挑战,包括数据不平衡导致的长尾问题、有限的推理能力以及对协变量偏移和领域适应问题的敏感性。
近期,基础模型的出现,如 GPT 25、CLIP 26 和 PaLMCLIP 27,为自动驾驶带来了新的机遇。这些大规模多模态模型标志着从静态感知到控制流水线向通用智能体的转变,这些智能体具备语言理解、语义推理、上下文记忆和数据生成的能力。特别是大语言模型(LLMs)带来了常识推理、逻辑推理和持续学习的潜力,为构建更具可泛化性、可解释性和可靠性的自动驾驶系统提供了路径。在大语言模型的基础上,新兴架构如视觉--语言模型(VLMs)、视觉--语言--动作(VLA)系统和工作记忆(WMs)进一步推动了场景理解、推理、零样本泛化和可解释性。这些模型为解决当前端到端自动驾驶的局限性提供了新的技术路径。
C. 贡献
我们方法的主要贡献可以总结如下。
-
我们对端到端自动驾驶系统的研究进展进行了全面回顾,并基于架构视角提出了经典范式的精细分类。这一重新分类弥补了现有分类方案的空白,为不同技术路线之间的对比分析和未来的整合奠定了理论基础。
-
我们开发了一个由大模型驱动的端到端方法的系统分类框架。该框架揭示了几个此前未被充分识别的主流技术范式,并对其核心特性和模型架构进行了详细分析,为基于大模型的自动驾驶的发展提供了新的见解。
-
我们对当前研究面临的关键挑战进行了深入分析,指出了若干重要问题。基于对文献的全面调查,我们进一步确定了一系列前瞻性和创新的研究方向,旨在通过可行的技术路径和理论指导支持未来发展。
-
在端到端自动驾驶评估框架的背景下,我们系统回顾了现有的开环评估、闭环仿真和真实车辆测试方法,强调了各自的优势和局限性。此外,我们介绍并讨论了最近提出的干湿结合测试评估方法,提供了一种更为实用和成本效益高的综合系统评估策略。
二、经典端到端自动驾驶范式
A. 模仿学习 (IL)
IL(模仿学习)是端到端自动驾驶中的一种基础方法,它旨在通过模仿专家演示,将原始传感器输入直接映射到控制指令。给定从专家驾驶中收集的状态--动作对数据集,IL 旨在学习一个能够在观察到的状态下复制专家行为的策略。该方法已广泛应用于各个领域 28、29、30、31,其优化目标通常定义为最小化所学策略与专家动作在驾驶状态分布上的差异。在基于 IL 的端到端自动驾驶中,现有方法通常可根据专家知识的利用方式分为三类:行为克隆(BC)、直接策略学习(DPL)和逆向强化学习(IRL)。
**1)行为克隆:**BC 由于其训练简单且高效,尤其在显式奖励设计不切实际时 23,仍然是端到端自动驾驶中占主导地位的 IL 范式。随着模型架构和输入模态的不断发展,BC 的研究逐渐分化出若干技术子范式。这些包括端到端控制预测、直接感知和不确定性量化。每个分支都探索在不同环境和建模条件下提高策略性能、鲁棒性和可解释性的不同策略。各子范式的代表性工作总结如表 I 所示。
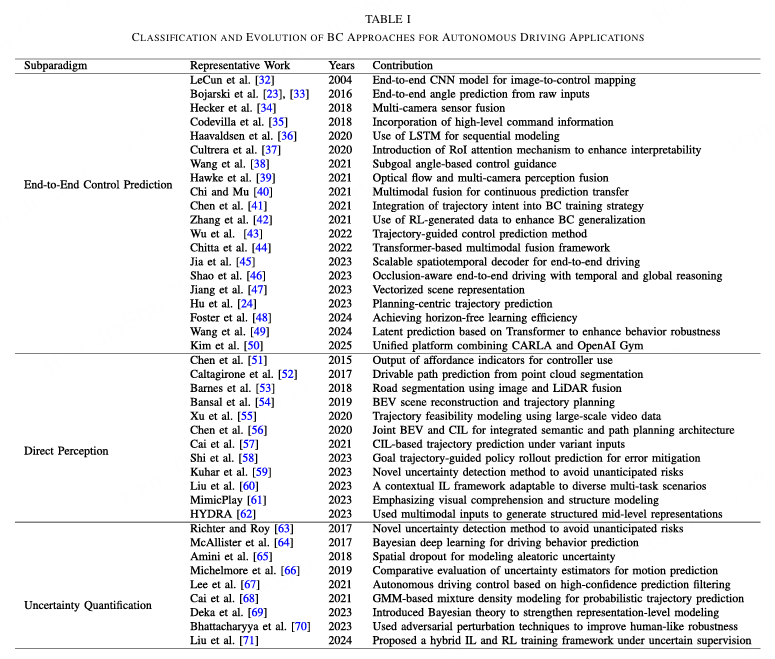
端到端控制预测旨在将原始观测直接映射到低级车辆指令。这一范式起源于 DAVE 32 和 DAVE-2 23,其中使用卷积神经网络(CNN)从前置摄像头图像预测转向角。随后,研究人员通过引入多摄像头输入并结合带有高级导航指令的条件模仿学习(IL)扩展了这一方法。为了更好地捕捉长时间依赖,研究中引入了时间建模模块,如 LSTM 和 Transformer。最近,研究重点转向通过多任务学习、感知-规划融合以及基于注意力机制的 RGB、LiDAR 和地图数据多模态整合来增强复杂驾驶场景下的鲁棒性和泛化能力 44, 45, 46。直接感知方法引入中间表示以提升可解释性、模块化和可迁移性。早期方法预测规则控制器的从属指标 51。随后的研究探索了鸟瞰视图(BEV)特征提取 54、LiDAR 点云整合 53 以及中级输出,如代价地图 55 或子目标轨迹 58。更新的方法通过基于偏好表示和多模态结构化场景编码来增强泛化能力。不确定性量化解决了行为克隆(BC)在面对新输入、模糊上下文和分布变化时的脆弱性。代表性方法包括贝叶斯神经网络、空间 dropout 以实现近似推断,以及高斯混合模型。一些研究引入主动安全策略,例如在高不确定性下的回退机制 67 或新颖性检测 63。近期的混合方法将 BC 与强化学习(RL)结合,使用辅助评判器 69 或策略融合 71,从而提高了可靠性和部署准备度。
**2)直接策略学习(Direct Policy Learning, DPL):**DPL 通过引入学习策略与专家之间的交互来扩展行为克隆(BC),以解决协变量偏移问题。其核心思想是允许策略生成自身的状态分布,然后通过专家反馈进行纠正。最具代表性的方法是 DAgger 72,它使用当前策略迭代生成轨迹,对访问的状态查询专家动作,并通过汇总的数据集更新策略,从而实现对策略漂移的动态纠正。随后出现的变体旨在减少专家监督并提高样本效率。SafeDAgger 73 使用安全策略,仅在学习策略明显偏离时才触发专家反馈。HG-DAgger 74 在关键状态下采用人工门控机制进行专家查询。其他扩展则关注泛化能力。OIL 75 从次优专家中选择信息丰富的示范以指导训练。Pan 等 76 利用 MPC 生成的示范作为高质量的初始数据,并通过 DAgger 风格的更新进行优化。近期进展将 DPL 推向长期部署。LLPL 77 引入终身适应机制,在操作过程中持续改进。PlanTF 78 提出一种基于 dropout 和扰动增强的轻量级规划器,在 nuPlan 中展示了强大的闭环性能,而无需依赖手工设计规则。
**3)逆向强化学习(Inverse Reinforcement Learning, IRL):**IRL 采用间接模仿的方法,假设专家的行为是由潜在奖励函数的最大化驱动的。它通过示范来恢复这一奖励,然后应用强化学习以导出最优策略。相比于行为克隆(BC)和直接策略学习(DPL),IRL 不仅能产生策略,还能揭示潜在的决策逻辑,提高可解释性和迁移能力。早期的 IRL 方法依赖手工设计的状态特征和线性奖励模型。基于特征的 IRL 79 将模仿问题框架化为已知动态下的奖励恢复,为该领域奠定了理论基础。为了解决奖励推断中的歧义,最大熵 IRL(Maximum Entropy IRL)80 引入了一种随机化的形式,鼓励高熵策略以匹配专家行为,从而避免过拟合。随着深度学习的兴起,深度最大熵 IRL(Deep MaxEnt IRL)81 使用卷积神经网络(CNN)从激光雷达(LiDAR)数据中学习非线性代价图,实现了城市场景中复杂奖励的建模。基于 IRL,生成对抗模仿学习(Generative Adversarial Imitation Learning, GAIL)82 将模仿问题重新定义为对抗训练,其中判别器区分专家与策略轨迹,并在不显式恢复奖励的情况下指导策略学习,从而提高效率和可扩展性。GAIL 及其扩展在自动驾驶中得到了广泛应用。Kuefler 等 83 将 GAIL 与循环神经网络(RNN)结合用于高速公路轨迹生成,表现优于 BC 基线。InfoGAIL 84 引入潜在变量以建模行为多样性,增强了多风格模仿。分层 GAIL(Hierarchical GAIL)85 通过条件生成对抗网络(GAN)生成鸟瞰图(BEV)表示进一步稳定训练,将感知与规划解耦,提高泛化能力。总体而言,IRL 及其对抗扩展方法支持基于奖励的策略学习、意图推断、多任务迁移和安全感知评估,使其在实际自动驾驶系统中具有高度适用性。
B. 强化学习 (RL)
与依赖专家示范的IL算法不同,RL通过与环境交互或使用预先收集的驾驶数据来学习自动驾驶策略。这使得自动驾驶代理能够在不同状态下采取最优行动,以最大化累积回报。
**1)基于模型与无模型的强化学习:**强化学习算法可以根据其学习方法分为基于模型和无模型两类。基于模型的强化学习假设智能体能够构建环境模型,以预测在当前状态下采取特定动作后的下一个状态及可能的奖励86。这种方法通过模拟与虚拟环境的交互来减少现实世界中的反复试验,提高样本效率87,88,并使其适用于风险敏感的场景。例如,在自动驾驶中,智能体可以利用环境模型生成大量长尾和边缘案例数据89。这使得智能体能够为极端路况下的决策挑战做好准备,从而在保证安全的同时加速策略迭代。
在早期强化学习研究中,基于模型的方法在状态和动作空间较小的简单环境中表现尤为有效。广泛使用的基于表的MDP框架90、91明确记录了过渡和奖励,实现了直观的策略优化。借助深度学习,基于模型的强化学习发展成两个方向:一方面着重于最小化预测损失92,使模型输出与真实环境反馈保持一致;另一方面强调更广泛的误差减少策略93以实现更稳健的建模。这些进步使自动驾驶的多样化应用成为可能。例如,何和李(94)引入了带有不确定性估计的集合模型,通过虚拟推广提升学习与科学能力。Wu等人95通过基于模型的正则化引入了专家知识以提升安全性。Wen 等人96设计了一个自我关注环境模型,以更好地处理高密度的 tra-c 交互。这些方法在样本和科学、风险控制和复杂场景理解方面取得了显著进展;然而,平衡模型准确性与可部署性仍是基于模型的强化学习在自动驾驶中的一大挑战。
与基于模型的强化学习不同,无模型的强化学习是通过交互直接学习策略,而无需构建环境模型。它根据状态、动作和奖励的经验样本更新策略,非常适合复杂、动态或难以建模的场景,如自动驾驶。无模型强化学习方法主要分为三类:基于价值、基于策略和行为者-批评者。基于价值的甲基苯丙胺ODS估算在特定状态下行为的预期回报97,改进型如双DQN 98和对抗DQN 99解决了高估问题,提升了tra c环境中的决策可靠性100。基于策略的方法101通过策略优化直接学习状态-动作映射。行为者-批评者框架102结合了两者,行为者学习政策,批评者评估政策。该结构在自动驾驶任务中表现出强劲表现,包括高级行为规划103、104、轨迹生成105、106和运动控制107。此外,无模型强化学习可以通过统一感知、决策、规划和控制在单一学习框架内,支持端到端自动驾驶108、109、110。例如,赵等人108使用近端策略优化(PPO)将图像和车辆状态输入直接映射到速度和转向指令。Li 等人 109 结合了 CNN 和 Transformer 架构,实现了安全的端到端通道切换。Wang 等人110引入了一种模态流水线,整合语义感知、层级决策和控制,通过层级强化学习和改进的动作采样实现端到端学习。这些研究表明,无模型强化学习已经逐渐发展成为一种有效的范式,能够在复杂和动态的环境中实现端到端的自动驾驶决策和控制,具有高度的灵活性、可扩展性和环境适应性。
**2)多智能体与单智能体强化学习:**与采用集中决策的单智能体强化学习自动驾驶系统相比,多智能体强化学习通过自主驾驶代理之间的协作,实现了更高效的任务完成和更优的整体性能。面对环境变化和不确定性,多智能体系统表现出更强的鲁棒性。即使个别代理出现故障或异常行为,其他代理仍能继续运行并调整策略,以维持整体系统的功能。此外,多智能体系统能够通过代理之间的互动和学习,更好地适应复杂的交通环境和多样的交通场景。它们可以实时优化策略,以应对不同的交通条件和动态变化。
现有的多智能体强化学习端到端架构可以分为完全去中心化架构、完全中心化架构以及集中训练、分散执行架构。在完全去中心化架构111中,每个自动驾驶智能体仅基于局部观测信息做出决策。这种架构的优势在于可以利用单智能体架构的设计和训练方法,将其他智能体视为环境动态的一部分。此外,每个智能体都维护自己的评价网络和驾驶策略,并根据其获得的经验样本进行更新。相比之下,完全中心化架构112涉及将所有自动驾驶智能体的状态、动作和奖励信息集中共享给中央控制器。该控制器统一做出决策,并向每个智能体分配动作指令,同时由控制器集中优化和更新智能体策略。这种架构能够实现高效协作和整体性能优化,适用于智能体数量少且通信条件良好的场景。然而,它存在依赖中央控制器和可扩展性差等局限性。集中训练、分散执行架构113允许智能体在训练期间共享全局信息以优化策略,但在执行阶段仅依赖局部信息进行决策。这种架构结合了集中优化与分散执行的优势,在协作性能与计算和通信成本之间取得平衡。
**3)离线强化学习(RL)与在线强化学习:**由于在线强化学习依赖试错训练方法,因此出于安全性和效率的考虑,自动驾驶的在线RL训练通常在模拟器中进行 42, 114。然而,训练环境与实际环境之间的差异使RL模型难以实现有效迁移,从而使其在实际车辆上的部署仍处于探索阶段 115。最近,一些研究 116 已开始使用离线RL 117 来解决这一迁移挑战。与在线RL不同,离线RL从历史数据中学习策略,使其适用于数据采集成本高或实时互动风险大的场景,如自动驾驶。需要注意的是,与依赖高质量专家演示的模仿学习(IL)不同,离线RL使用来自各种来源的历史数据,包括专家演示、随机策略或其他策略生成的数据。离线RL不假设数据是由专家生成的,也不假设数据的质量很高。
离线强化学习(Offline RL)消除了实时交互的需求,降低了反复试错的成本,并充分利用了已收集的数据。其研究重点是解决在部署过程中智能体遇到新状态时,由分布变化引起的性能下降问题。早期研究主要集中在机器人领域,但随着机器学习技术的发展,关于离线强化学习在自动驾驶中的研究逐渐兴起。Shi 等人 118 提出了一种改进的离线强化学习方法,通过参数噪声提升探索效率,并结合 Lyapunov 稳定性理论以确保安全。Lin 等人 119 进一步引入了感知安全的结构化场景表示(FUSION)方法,通过因果表示学习和安全意识,提升了自动驾驶在不同场景下的安全性和泛化能力。Diehl 等人 120 提出了 UMBRELLA 方法,该方法考虑了不确定性和部分可观测性,利用离线数据学习联合模型用于预测、规划和控制,从而增强了自动驾驶决策的安全性和可解释性。Li 等人 121 设计了一种基于层次潜在技能的离线强化学习框架,命名为用于车辆规划的层次技能离线强化学习(HsO-VP)。通过变分自编码器,它从离线示范中学习驾驶技能,并将这些技能作为长期车辆规划的动作,显著提升了离线强化学习在自动驾驶任务中的表现。为应对现实驾驶数据集中缺失奖励信号的问题,Asodia 等人 122 提出了一种用于自动驾驶的离线强化学习流程,生成与人类判断一致的奖励标签。最后,Fang 等人 123 基于真实驾驶数据开发了离线强化学习基准,包括数据集、基线方法和数据驱动仿真器,为评估和分析不同离线强化学习算法在自动驾驶任务中的表现提供了一个全面的平台。
总体而言,这些研究显著推进了离线强化学习在自动驾驶中的发展。然而,大多数现有方法仍然依赖于理想化的仿真数据或有限质量的离线样本,在跨领域泛化、长期决策一致性和现实世界迁移能力方面仍存在明显差距。未来的工作应致力于在数据分布建模和安全约束优化之间实现更稳健的平衡。
C. 具有端到端推理特性的多阶段方法
在机器学习领域,许多方法表现出独特的阶段特性:最初的训练过程并非端到端;但最终推理可以实现从输入到输出的直接映射。尽管这些方法在训练阶段不是端到端系统,但它们在最终推理应用阶段展示了端到端特性。基于此,我们将它们归类为具有端到端推理特性的多阶段方法,并将其划分为三个维度:奖励塑形、微调和迁移学习。
奖励塑形作为强化学习中的一个关键概念,旨在通过对奖励函数模型的精细设计和优化,为代理训练提供准确且全面的奖励信号。这引导代理快速学习高质量策略,同时确保安全,高效地实现性能提升目标。传统的手工设计奖励函数可能导致指标冲突和奖励漏洞。为有效应对这一挑战,研究人员引入了人类偏好124,并利用人类反馈数据进行奖励塑形125,以替代可能有缺陷的手工奖励函数。Huang 等人126提出了一个名为通过人类反馈的强化学习偏好引导(PE-RLHF)的框架,该框架通过结合人类反馈和物理知识的强化学习提升自动驾驶安全性,显著优于传统方法。Wang 等人127提出了一种基于人类反馈的强化学习方法,通过预训练和人类标注数据优化自动驾驶车辆的换道决策,从而提升安全性和自然性。Cao 等人128提出了一个名为TrafficRLHF 的三阶段框架,将强化学习与人类反馈相结合,有效提升自动驾驶模拟中交通模型的真实性,显著减少不真实的驾驶行为并提高轨迹的真实性。
微调是指在预训练模型的基础上进一步训练,使其适应新的特定任务或数据集。通常,预训练模型是在大规模数据集上训练的,并具备良好的通用特征表示能力。在微调过程中,模型的参数会进一步调整,以更好地适应目标任务。模仿强化学习(Imitation RL)是一种典型的微调算法,结合了模仿学习(IL)和强化学习(RL)。它通过模仿专家行为来学习策略,然后利用强化学习进一步优化策略,以提高模型的性能和泛化能力。Kaur 和 Sobti 129 将基于模仿强化学习的混合框架应用于高性能和高安全性的自动驾驶车辆运动规划。Choi 等 130 提出了一种将 IL 和 RL 结合的方法,通过使用 CARLA 模拟器的专家示例数据预训练 actor 模型,然后将其集成到基于 PPO 的强化学习中。实验表明,该方法在训练早期阶段的表现优于仅使用 RL 的模型。
在大模型时代,IL 与 RL 的协同效应进一步提升。以 Horizon Robotics 发布的 HSD 系统为例,它首先利用数百万公里的人工驾驶数据,通过 BEV Transformer 进行 IL 预训练,获得类人的基础策略。然后构建了车端快速系统与云端慢速系统的双层架构。车端策略实时运行,以保证低延迟和安全性,而云端则基于 WM 和 RL 算法在模拟环境中持续自我演练,生成高价值的长尾场景并优化策略。最终,云端进化的策略通过知识蒸馏回传到车端,实现类人的操作和持续学习。
迁移学习 131,132 是一个更广泛的概念,包括微调和其他利用源任务知识来辅助目标任务学习的方法。如图 5 所示,其目标是将从一个任务中学到的知识应用到另一个相关任务中,通常通过在目标任务上调整一些模型参数或使用预训练模型作为特征提取器。知识蒸馏可以被视为迁移学习的一种变体。它将知识从复杂模型(教师模型)传递到简单模型(学生模型),使学生模型能够继承教师模型的性能和泛化能力。Li 等人 133 提出了 Hydra-MDP,一种新颖的端到端自动驾驶框架,基于人类示范和基于规则的专家系统,使用多头解码器知识蒸馏,显著提升了驾驶安全性和效率。Pan 等人 134 提出了基于知识蒸馏的端到端车道检测方法,通过教学-测试模块利用辅助监督和知识蒸馏,直接预测车道的多项式参数,并提高复杂道路条件下的拟合精度。Agand 135 提出了一种基于 Transformer 的端到端自动驾驶算法,通过知识蒸馏整合 RGB-D 摄像头的多种特征表示,并结合强化学习和 PID 控制优化车辆操作。
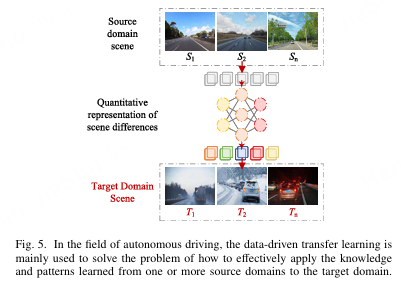
图5. 在自动驾驶领域,数据驱动的迁移学习主要用于解决如何将从一个或多个源域学到的知识和模式有效应用到目标域的问题。
总体来看,这些工作展示了多阶段学习方法在提升自动驾驶模型的可迁移性、可解释性和安全性方面的巨大潜力,在弥合端到端学习与现实约束之间的差距方面取得了显著进展。然而,如何在保持端到端推理优势的同时,进一步降低多阶段框架的训练复杂性和跨域不确定性,仍然是未来研究的关键方向。
三、大模型驱动的端到端自动驾驶
尽管诸如模仿学习(IL)、强化学习(RL)以及多阶段混合框架在弥合感知与控制之间取得了显著进展,但它们的性能和可扩展性仍然受到数据依赖、有限推理能力和较弱可解释性的基本限制。随着驾驶场景变得愈加复杂且安全性要求更高,这些方法在不同环境间泛化或处理长尾行为时表现困难。
近年来,大规模基础模型的出现为端到端自动驾驶带来了范式转变。诸如大型语言模型(LLMs)、视觉语言模型(VLMs)和视觉语言行动系统(VLAs)等模型引入了强大的推理能力、上下文理解能力和多模态对齐能力,为在认知基础框架内统一感知、规划与控制提供了新可能。在经典范式的基础原则之上,这些以大模型为驱动的方法旨在超越纯数据驱动的模仿或强化信号,迈向知识增强、可解释和可泛化的自动驾驶系统。在本节中,我们将全面回顾面向端到端自动驾驶的大模型驱动范式,重点探讨 LLMs、VLMs 和 VLAs 如何通过统一的多模态表示和基于知识的决策重塑感知、推理与控制。
A. 利用大型语言模型(LLM)的自动驾驶
近年来,随着在语言理解和生成方面强大的能力,LLM 在自然语言处理领域取得了显著进展。通过大规模预训练和指令调优,LLM 能够有效捕捉复杂的语言语义、推理逻辑和世界知识,展现出接近人类水平的推理和决策能力。具有代表性的模型如 GPT 系列 25、136、LLaMA 系列 137 及其多模态扩展,在对话系统、内容生成和基于推理的问答等任务中表现出了出色的效果。此外,这些模型在跨领域迁移和通用人工智能开发方面也显示出越来越大的潜力。
随着自动驾驶系统对环境理解、推理和安全保障能力的需求日益增加,研究人员开始探索将大型语言模型(LLM)整合到驾驶任务中的可能性。如图6所示,该方法包括将交通场景信息转换为基于语言的描述,并利用LLM的推理和生成能力产生具有可解释理由的行为决策。这使得自动驾驶车辆在感知、规划、决策甚至模拟数据生成等关键模块中展现出更高的智能性、可解释性和稳健性。因此,基于LLM的自动驾驶研究已经成为智能交通与人工智能交叉领域的一条有前景的方向,吸引了广泛关注和积极的研究。在本节中,我们从规划、决策与推理、数据生成及感知四个角度总结了现有方法,并重点介绍了规划与决策方面的最新进展。我们在表II中总结了这些方法。
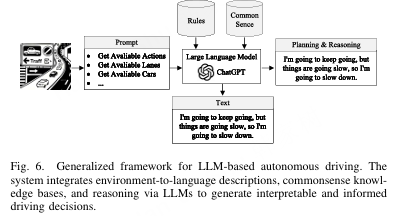
图6. 基于大语言模型(LLM)的自动驾驶通用框架。该系统整合了环境到语言的描述、常识知识库以及通过LLM的推理,以生成可解释且有依据的驾驶决策。
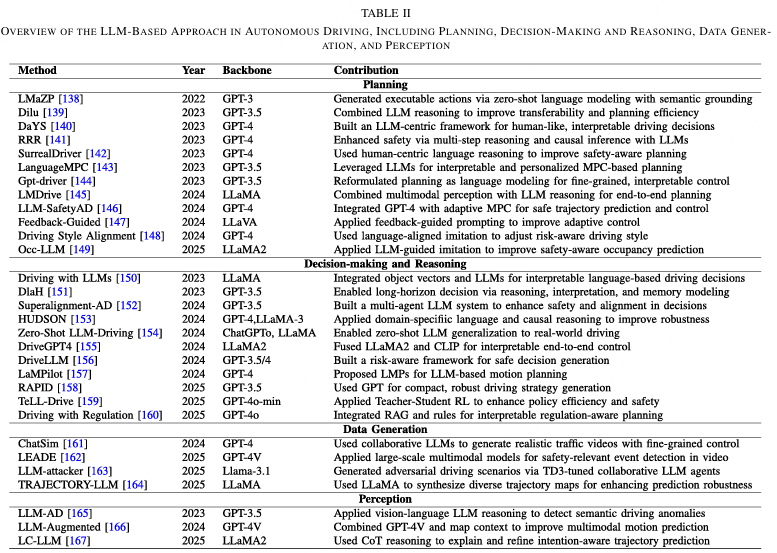
**1)规划:**在自动驾驶的规划模块中,早期研究探索了利用大型语言模型(LLM)直接生成轨迹或控制动作,揭示了其将语义推理与可执行决策结合的潜力。LMaZP 138 首次证明了 LLM 在零-shot 条件下能够将高级语言指令分解为中层可控动作,显示出语言表示可以为规划提供灵活且可解释的先验。然而,这种纯语义翻译框架往往难以在动态交通场景中保持时间一致性和上下文适应性。为了解决这一问题,Wen 等人 139 引入了一种推理-反思机制,将推理与基于记忆的适应结合起来,增强了对未知环境的泛化能力和自我纠正能力。同样,DaYS 140 和 RRR 141 融入了多模态感知和思维链(CoT)推理,以强化语言驱动规划的因果可解释性和鲁棒性,而 SurrealDriver 142 则采用人类驾驶反思作为提示,将行为认知和安全意识注入生成决策代理。这些工作共同展示了基于 LLM 的规划的早期演进,从遵循指令的模型向以推理为中心并与人类行为对齐的框架发展,更好地捕捉驾驶意图的语义。
随着闭环优化兴趣的增长,近期研究进一步将大语言模型(LLM)推理与控制理论规划结合起来,以实现自适应和安全意识的决策。LanguageMPC 143 通过文本条件调制引导模型预测控制(MPC),在离散推理和连续控制之间架起了桥梁,标志着向可解释混合控制器迈出了一步。Gpt-driver 144 通过提示工程和链式推理(CoT)将轨迹规划重新表述为语言建模任务,展示了自回归文本生成能够以明确的逻辑结构建模规划序列。LMDrive 145 将这一理念扩展到完整的闭环系统,将多模态感知与基于LLM的理解整合,以实现情境感知的轨迹生成。与此同时,LLM-SafetyAD 146 引入了结合主动风险推理的预测控制,以增强不确定性下的鲁棒性,而反馈引导驾驶 147 则实现了人机闭环优化,用于动态策略调整。此外,驾驶风格对齐 148 表明基于语言的调制可以根据人类驾驶偏好个性化规划行为,而Occ-LLM 149 提出了仿真反馈机制,可提升现实部署中的稳定性和安全性。
总体而言,这些工作显示了LLM驱动规划在范式上的明显转变------从静态语义理解转向交互式、推理引导及反馈自适应控制。尽管在可解释性和适应性方面取得了进展,现有方法仍面临提示不一致、闭环响应延迟以及对大规模环境扩展有限等挑战。因此,未来研究应探索分层提示、轻量级推理模块及领域感知微调,以平衡LLM的认知灵活性与实时自动驾驶所需的效率。
**2)决策与推理:**基于大语言模型(LLM)的自动驾驶决策旨在通过直接从原始场景输入生成操作来简化传统流程,提高可解释性并减少中间不确定性。早期研究150将对象级特征与预训练的LLM结合,构建从感知到行动的推理管道,表明自然语言可以有效编码驾驶意图和情境逻辑。DlaH 151 在此框架基础上引入了推理和记忆机制,提高了长远一致性和零样本泛化能力。随着模型能力的提升,研究逐渐转向安全性和鲁棒性。Superalignment AD 152 引入多智能体协作以增强协调性,HUDSON 153 则利用因果推理来抵抗感知扰动。零样本LLM驾驶154 验证了在未见场景下的闭环控制。为提高可靠性,DriveGPT4 155 和 DriveLLM 156 将视觉编码器与安全评估结合,实现风险感知控制,而 LaMPilot 157、RAPID 158 和 TeLL Drive 159 则通过语言程序和蒸馏方法增强可控性和效率。Driving with regulation 160 进一步引入规则感知推理,实现可解释且符合法规的决策。总体来看,这些研究标志着从描述性推理向有基础的、安全感知及自适应决策的过渡。然而,将语言推理与连续控制对齐,并在开放世界场景中确保鲁棒性,仍是未来研究面临的挑战。
**3)数据生成:**在数据生成领域,研究人员积极探索使用大型语言模型(LLM)来增强自动驾驶交通仿真和轨迹数据的多样性与真实性。ChatSim 161 引入了一种协作型LLM代理架构,能够生成可编辑的交通仿真视频,并对个体交通参与者和道路布局等元素进行精细控制。这种方法显著丰富了自动驾驶系统可用的测试和交互场景。LEADE 162 提出了一种从普通交通视频中合成安全关键事件的新方法,为罕见事件建模和安全评估提供了宝贵的数据来源。为了评估和增强模型的鲁棒性,LLM攻击者 163 将LLM与TD3强化学习算法结合,用于生成对抗性交通场景。这些极端案例为鲁棒性测试和策略改进提供了挑战性条件,提高了系统应对非理想环境的能力。在轨迹生成方面,TRAJECTORY-LLM 164 专注于多智能体交互感知的合成,使得能够生成多样且语义对齐的轨迹样本。生成的数据集为运动预测和决策模型提供了可控且社会一致的训练信号,对提升交互感知规划性能具有较大潜力。总体而言,LLM提高了交通和轨迹数据的多样性和真实性,丰富了自动驾驶的训练和测试。然而,目前的方法缺乏物理和因果一致性。未来的研究应将语义生成与物理及因果感知建模相结合,以实现更高的真实性和可靠性。
**4)感知与场景理解:**近年来,研究人员越来越多地探索将大语言模型(LLMs)整合到感知中,以克服传统模型在语义理解和高阶推理方面的局限性。这类研究体现了从低层特征提取向以认知为导向的感知的转变,结合了推理、抽象和上下文感知。LLM-AD 165 提出了一种语义一致性检测框架,将感知特征转换为结构化语言描述,从而实现因果推理和异常检测。这种方法有效增强了可解释性,但高度依赖语言表示的准确性,在动态场景中可能引入语义漂移。LLM增强的运动预测 166 将GPT-4V与上下文交通图融合,以改善交互环境中的多主体轨迹预测。虽然它在语义推理和交互建模方面表现出强大能力,但对多模态预训练数据的高度依赖限制了其在开放世界环境中的可扩展性。LC-LLM 167 采用了CoT微调策略,以增强换道意图识别和轨迹预测中的逻辑一致性。与以往方法相比,其在时间一致性和跨模块对齐方面表现更好;然而,额外的推理层增加了推理延迟,阻碍了实时部署。近期的基于LLM的感知框架在语义可解释性和认知整合方面取得了进展,但在抽象能力、物理基础和效率之间保持平衡仍面临困难。未来的研究方向应强调轻量化和物理一致性的设计,将推理、感知和预测在实时、安全关键环境中有效整合。
B. 使用视觉--语言模型的自动驾驶
与主要处理和推理文本信息的LLM相比,VLM将这种能力扩展到视觉领域,通过联合建模图像和语言表示来实现。LLM侧重于符号推理和语言抽象,而VLM强调跨模态的关联,通过对比或融合训练将语义概念与视觉证据对齐。这使得它们能够以更可解释且与人类认知一致的方式理解场景和指令。在自动驾驶中,VLM越来越多地被采用来桥接感知、推理和控制。通过将视觉理解与语言驱动的推理统一,它们使端到端系统能够理解复杂的交通场景、遵循自然语言指令,并生成语义一致的驾驶行为。不同类型VLM的代表性工作在表III中进行了总结。
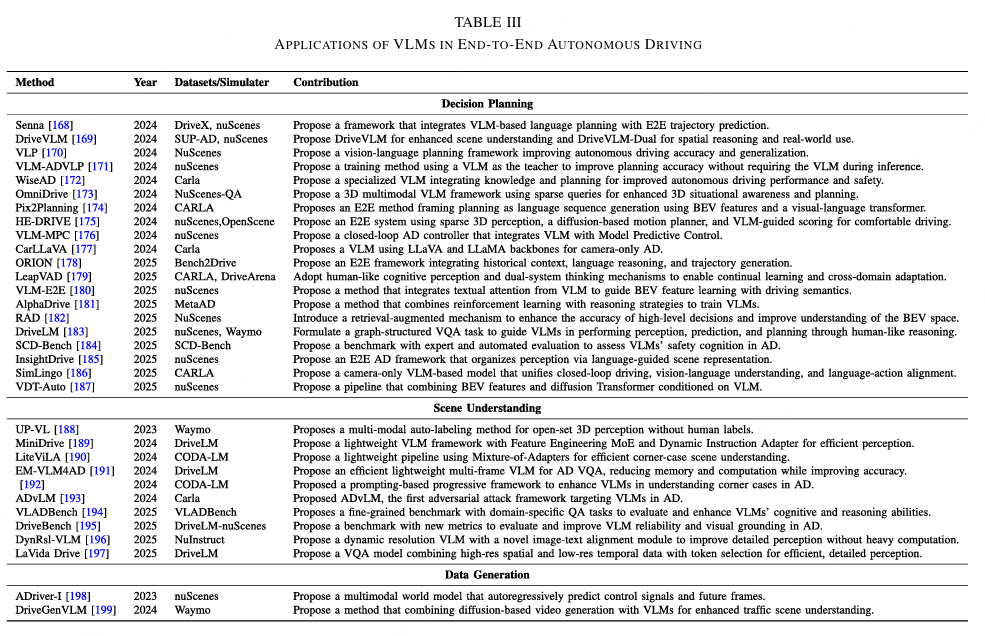
**1)决策规划:**关于用于决策规划的视觉语言模型(VLMs)的最新研究显示,从直接感知到控制映射的方式,逐渐转向语义驱动的推理和分层控制。一种典型趋势是使用混合认知结构,将快速响应和深思熟虑的推理相结合,以提高适应性和安全性。DriveVLM 169 就是这一方向的典型代表,强调多层次规划,结合了反应式和反思式决策模式,显示出从端到端回归方法向结构化认知控制的转变。其他工作,如 Senna 168 和 VLP 170,探索了分离的意图推理,将高层语义意图与低层轨迹预测分开。这提高了可解释性和迁移性,但也引入了额外依赖,可能削弱端到端设计的简洁性。同样,VLM-AD 171 和 RAD 182 将 VLMs 作为监督或引导模型,通过结构化语言约束对感知和控制进行对齐。虽然这增强了在未见场景下的可靠性,但仍受限于数据规模和仿真偏差。最近的基准测试,如 DriveLM 183 和 SCD-Bench 184,进一步将这一工作拓展到基于推理的评估,不仅强调性能,还强调安全认知和因果合理性。同时,诸如 SimLingo 186 和 VDT-Auto 187 等模型突显了语言引导推理与多模态规划日益融合,取得了具有良好泛化能力的闭环性能。总体而言,基于 VLM 的决策规划正向以认知为驱动的框架发展,结合感知、记忆和推理。这些方法提高了可解释性和适应性,但在语义抽象、实时效率和开放世界鲁棒性之间取得平衡仍是未来部署的一大挑战。
**2)场景理解:**近期基于视觉-语言模型(VLM)的场景理解研究反映出从低级感知向语义抽象和上下文感知推理的明显转变。这些方法不再依赖固定的视觉分类体系,而是利用跨模态表示来更灵活、更具解释力地理解交通场景。一个主要趋势是向开放词汇和无注释感知发展,例如 UP VL 188 等工作展示了语言引导的蒸馏如何使模型超越预定义类别进行泛化。这一方向不仅减少了对高成本标注数据集的依赖,同时也引发了在领域迁移下语言驱动语义的稳定性和准确性问题。第二个趋势聚焦于轻量化和可部署的感知框架,如 MiniDrive 189 和 LiteViLA 190,它们通过集成自适应分词和模块化适配器来实现实时推理。这些设计体现了对语义丰富性与计算效率之间权衡认识的提升。然而,这种模块化简化可能会限制全局推理能力,尤其是在复杂的多智能体环境中。
**3)数据生成:**在数据生成方面,视觉语言模型(VLMs)为构建具有最少人工标注的多模态自动驾驶数据集提供了一条有前景的路径。通过将视觉生成与语言引导的语义对齐,它们能够可扩展地合成图像--文本和视频--语言对,从而提高下游感知和决策任务的效率和可解释性。最近的研究越来越多地将VLMs与扩散或生成模型结合,以创建现实且行为一致的驾驶场景。诸如ADriver-I 198 和 DriveGenVLM 199 的工作就是这一趋势的例证,展示了如何通过将视觉--动作表示与语言推理相结合,提升合成数据的多样性和语义一致性。DriveLM 183 通过将结构化问答推理融入生成任务,进一步扩展了这一理念,通过语言监督丰富场景级理解。同样,InsightDrive 185 利用文本指导重建语义可解释的场景,强调生成感知与推理之间的对齐。除了视觉合成,SimLingo 186 探索了从自然语言指令到驾驶轨迹生成的端到端一致性,凸显了统一多模态仿真的潜力。总之,基于VLM的数据生成推动了语义丰富且认知基础扎实的驾驶环境的创建,支持仿真、数据增强和推理。然而,在实现物理真实性、时间稳定性以及可控场景多样性方面仍存在挑战,而这些对于在安全关键和真实世界的自动驾驶系统中部署这些方法至关重要。
C. 使用视觉--语言--动作模型的自动驾驶
VLA模型通过引入一种将感知和推理与控制连接的显式动作模态,扩展了LLM和VLM的能力。LLM强调语言推理,VLM则关注视觉-语义对齐,而VLA旨在将这些模态落地到行为生成中,使模型能够在真实环境中解释场景并执行决策。一个具有代表性的里程碑是RT-2 208,它展示了预训练的VLM可以通过在视觉、语言和轨迹数据上的联合训练来适应具身控制。在自动驾驶中,VLA范式越来越被视为端到端框架的演进,将感知、语义推理和轨迹预测统一在单一模型中。这种整合提升了理解与控制之间的可解释性和认知一致性,并激发了一系列探讨统一多模态决策的最新研究。代表性工作汇总于表IV。

**1)决策与规划:**基于VLA的决策与规划框架引入了一个明确的动作基础机制,将语义理解与可执行控制连接起来。这标志着从语言引导的解释向行为生成的转变,使模型在生成可实际执行的驾驶动作的同时,能够推理意图。近期的系统,如EMMA 200、OpenEMMA 201和OpenDriveVLA 202,体现了这种向认知驱动控制转变的趋势,将多模态推理与轨迹预测整合在一起。这些方法不仅提升了对感知、意图和运动的统一建模及可解释性,同时也面临诸如高计算需求、推理延迟,以及在符号推理与动态车辆行为之间保持一致性的困难等挑战。诸如CoVLA 203的努力进一步凸显了构建大规模多模态数据集以桥接感知、语言与动作的必要性。基于VLA的决策与规划代表了超越感知驱动推理、迈向真正具身智能的一步,但在实际约束下确保因果基础、高效性和安全性仍然是一个未解决的挑战。
**2)其他任务:**除了自动驾驶之外,VLA 模型由于其多模态对齐和泛化能力,在更广泛的具身智能系统中也展现出了强大的潜力。近期研究,如 OpenVLA 204、MoLe-VLA 205、CoT-VLA 207 和 HybridVLA 206,通过动态和混合建模策略提高了推理效率和自适应控制,为构建更高效、更可解释的 VLA 架构以应用于自动驾驶提供了参考。在更广泛的机器人领域,VLA 正越来越多地应用于跨工业、服务和农业场景的感知-语言-行动任务。在农业机器人中,诸如检测与识别 209--217、抓取与采摘 101,218--220、种植与施肥 221,222 以及田间导航 223--226 等任务,验证了基于 VLA 的感知-行动学习的适应能力。然而,与这些低速且特定任务的操作相比,自动驾驶的复杂性远高,需要模型能够在多样化的交通场景中实现泛化,并保持实时性能 227--229。总体而言,从机器人到自动驾驶的 VLA 应用仍处于早期阶段。实际车辆部署既需要高效的推理能力,也需要稳健的环境推理能力,这对模型设计、优化以及硬件适配提出了重大挑战。机器人应用中的经验,如基于语言的行动落地和模块化感知-控制耦合,可能有助于未来自动驾驶系统实现更强的泛化性和可解释性,这将在第 V 节进一步讨论。
D. 使用世界模型(WMs)的自动驾驶
与依赖语义推理和多模态对齐的LLM、VLM和VLA不同,WM旨在模拟环境的物理和因果动态,通过学习状态转换来构建可预测的认知世界,从而支持自主规划和控制。
**1)数据生成:**作为一种强大的工具,WMs 可以通过学习和模拟驾驶环境的动态特性生成丰富的虚拟驾驶场景数据。这些数据不仅可以扩展训练集的多样性,还能有效增强自动驾驶系统应对罕见或极端场景的能力,从而提升系统的鲁棒性和安全性。基于不同的状态空间表示方法,基于 WM 的数据生成可以分为基于图像、基于 BEV、基于占据栅格以及基于点云的数据生成。
**a) 基于图像的数据生成:**基于图像的 WM(世界模型)直接在像素空间中模拟驾驶环境,捕捉细粒度的纹理和光照。HoloDrive 230 是这一研究方向的典型代表,它通过 BEV-摄像机对齐联合生成多视角摄像机图像和 LiDAR 点云。这种多模态一致性提升了视觉逼真度,但仍受限于跨帧保持时间一致性的难度。Vista 231 将基于图像的生成扩展到动态理解,整合多种控制模式和潜在替换策略以增强泛化能力。尽管它为大规模训练提供了统一接口,但生成的模型在表示长期物理依赖关系方面仍存在挑战。SimGen 232 通过级联扩散生成弥合了真实数据和模拟数据之间的差距。其模拟器条件合成提高了多样性,但继承了扩散建模的计算开销,并在复杂驾驶条件下部分失去场景逼真性。总体而言,基于图像的方法贡献了丰富纹理的多模态数据集,但在实现照片级真实感和物理一致动态方面仍是构建鲁棒 WM 的一大挑战。
**b)基于BEV的数据生成:**基于BEV的WM(世界模型)从像素级真实感转向结构化空间推理,提供更清晰的场景布局和可解释的表示。UNO233在此方向上取得进展,通过自监督学习从LiDAR历史数据预测连续的4D占用场,实现隐式几何建模,提升了空间一致性,但在稀疏环境中仍难以解决语义模糊问题。GenAD 234将驾驶问题表述为潜在BEV空间中的生成式问题,结合实例级标记和变分推理进行运动预测。该设计增强了轨迹多样性,但在捕捉真实世界约束方面引入了不确定性。CarFormer 235进一步探索以对象为中心的BEV表示,通过slot attention对动态主体进行分组,以学习交互感知的动态。尽管其模块化设计提高了可解释性,但牺牲了对于感知-规划对齐至关重要的细粒度外观信息。总体而言,基于BEV的生成提供了结构化和可推广的抽象,但在语义完整性与物理真实性之间的平衡仍是关键研究方向。
**c)基于占用格的数据生成:**基于占用格的WM将环境表示为概率3D网格,为建模空间结构和对象交互提供了统一框架。MUVO 236利用几何体素表示进行多模态生成,显示基于Transformer的融合能够显著提升相机预测和占用细节学习。GaussianWorld 237提出了一种基于高斯的方法,将场景动态分解为静态对齐、对象运动和新区域补全,在不增加计算成本的情况下提升效率。RenderWorld 238进一步证明,纯视觉框架可以通过高斯渲染和注意力机制-变分自编码器(AMVAE)学习,从二维标签重建三维占用,在nuScenes数据集上取得了良好表现。总体来看,这些工作显示了基于占用格的生成在以紧凑形式统一几何、语义和动态方面的潜力。
**d) 基于点云的数据生成:**基于点云的世界模型(WM)通过密集的几何坐标表示三维环境,保留了对精确感知和重建至关重要的详细空间结构。一个 4 维占用预测框架 239 将传感器和场景运动分离,从而在未标注的 LiDAR 序列上实现自监督学习,提高时间预测的准确性。Copilot4D 240 将 VQ-VAE 编码与离散扩散建模相结合,有效减少跨数据集预测误差。NeuralVol 241 通过引入基于体积表示的方法进一步扩展了这一方向,该方法利用自监督图像重建和神经渲染捕捉精细几何结构,同时运动流和时间注意模块增强了动态场景理解。ViDAR 242 通过潜在的三维渲染机制,直接从视觉输入预测未来点云,实现视觉与几何的桥接,改善下游感知和规划性能。尽管基于点云的生成在几何保真性和时间推理方面表现出色,但其计算强度大,并且依赖密集的 LiDAR 或渲染管线,使大规模部署变得困难。
**2)端到端集成:**近期进展显示,人们越来越关注将窗口管理器整合进端到端自动驾驶框架,在该框架中感知、预测和规划在统一的潜在空间中共同建模。这一范式使得科学的环境理解和行为预测成为可能,开辟了一条通往更具解释性和因果依据的决策的有前景道路。多项代表性研究展示了将世界建模与端到端学习结合的不同策略。基于语义掩蔽的 WM 243 通过对语义特征的选择性过滤和多源数据采样,提升了鲁棒性和样本科学性,凸显了数据抽象对稳定规划的重要性。Drive-WM 244 将这一理念扩展到多视角场景建模,结合空间和时间推理与视图分解,生成一致且高保真的驾驶场景用于控制学习。从多智能体视角看,Tra cBots 245 侧重于交互动力学,整合运动预测和策略学习以模拟真实的 tra c 行为,而 BEV World 246 则统一潜在 BEV 空间中的异质感官输入,提升空间推理和场景重构。PowerBEV 247 进一步探讨了建筑与科学,采用轻量级多尺度模块以平衡任务复杂性和实时稳定性。综合来看,这些框架不仅提升了自动驾驶在感知、预测和规划方面的能力,也促进了其在复杂环境中的实际应用,为自动驾驶的未来发展奠定了基础。
E. 总结与讨论
以大模型为驱动的范式,包括基于 LLM、VLM、VLA 和 WM 的框架,已经从根本上改变了端到端自动驾驶的格局。通过在统一的多模态表示中整合感知、推理和控制,这些模型相比传统的基于 IL/RL 的系统,能够实现更丰富的语义理解、更强的泛化能力以及更高的可解释性。然而,在真实自动驾驶车辆中部署此类大模型驱动的框架仍受到硬件和能源限制的严重约束。大规模多模态模型带来的显著推理延迟和内存开销阻碍了其实时响应能力,尤其是在动态交通场景中,毫秒级决策至关重要。此外,车辆上的计算还带来了能效和热管理方面的额外挑战,因为持续的多模态推理可能导致过度的能量消耗和过热。
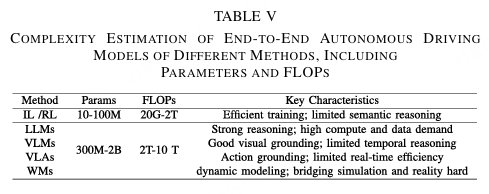
为了更清晰地展示这一权衡,表V总结了代表性范式的大致参数规模和计算复杂度。如图所示,IL/RL模型仍然轻量且数据高效,而大型语言模型和多模态模型则需要更高的计算量,通常从万亿级到千万亿级不等。尽管计算成本高昂,大型模型始终表现出卓越的推理能力、跨模态定位能力和认知对齐性,为实现更可解释和可靠的自动驾驶系统提供了有前景的方向。
大型模型范式标志着向统一、认知启发的自动驾驶系统迈出的重要一步。然而,它们对大量计算和数据的高度依赖凸显了以效率为导向的研究的紧迫性,例如模型压缩、基于适配器的微调以及云-边协同部署。未来的工作应聚焦于在模型容量与计算可行性之间取得平衡,确保大型模型驱动的自动驾驶能够从实验验证发展到安全、高能效且可扩展的实际部署。
四、评估方法与基准系统
在自动驾驶系统的整个生命周期中,从开发到部署,全面评估其性能、安全性和可靠性是至关重要的。对于端到端系统来说,由于其封闭的特性和缺乏可解释的中间输出,这一过程尤其具有挑战性。与支持单元级测试的模块化架构不同,端到端模型直接将原始输入映射到控制指令上,因此评估重点转向系统级行为、适应性以及真实环境下的交互能力。因此,需要稳健的评估框架来评估整体驾驶能力、稳健性和安全性。本节回顾了主流评估方法,包括开环测试、闭环测试、干湿结合的综合测试以及新兴的语言增强评估框架,这些方法对于迭代改进和安全部署都是必不可少的。
A. 开环评估
开环评估或离线评估是一种广泛用于评估端到端自动驾驶模型的方法,尤其在早期开发阶段。如图7(a)所示,该方法将预先录制的传感器数据------如图像或LiDAR点云------输入模型,模型随后输出驾驶决策,例如控制指令或预测轨迹23。其一个关键特征是非交互性:模型输出不会影响环境或未来输入,从而能够进行快速、可重复的测试,但限制了对实时反应行为的评估。开环评估高效且风险低,非常适合验证通过IL训练的模型。它提供可解释的指标,用于比较模型输出与专家行为的差异248。此外,它利用大规模公共数据集,如nuScenes 249、Waymo 250、Argoverse 251和BDD-X 252,支持在多样化真实场景中进行泛化测试。标准化的开环评估协议还便于在不同架构和训练方法之间进行公平比较,加快迭代开发,同时避免实时部署的风险。
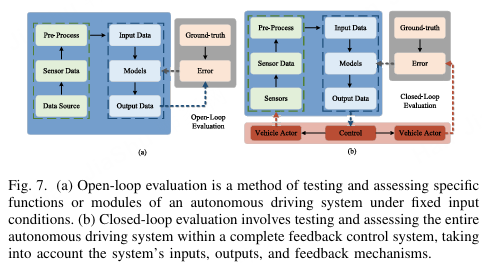
图7. (a) 开环评估是一种在固定输入条件下测试和评估自动驾驶系统特定功能或模块的方法。(b) 闭环评估涉及在完整的反馈控制系统中测试和评估整个自动驾驶系统,考虑系统的输入、输出和反馈机制。
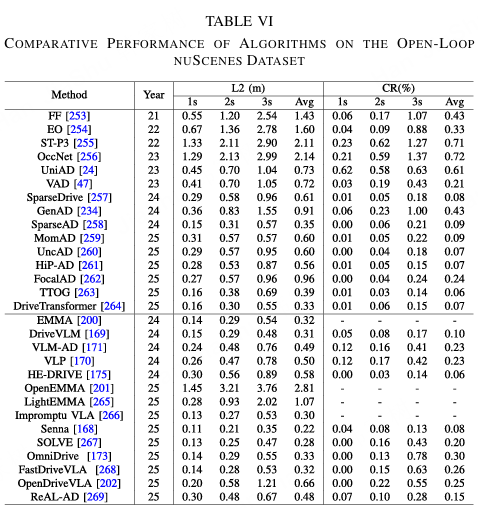
在开环评估中,指标的选择取决于模型的输出类型。对于连续控制任务,通常使用均方根误差(RMSE)和平均绝对误差(MAE)来评估预测的准确性,分别反映模型对大偏差的敏感性及整体的稳健性。对于轨迹预测,会使用平均位移误差(ADE)、最终位移误差(FDE)以及欧几里得距离误差(L2,以米为单位)等指标来评估轨迹偏差。当输出涉及诸如变道或转弯决策等离散驾驶行为时,会采用准确率、精确率、召回率和F1分数等分类指标来评估行为预测的正确性和一致性。此外,完成率(CR)也常用于衡量成功完成驾驶场景(无碰撞或偏离)的百分比。几种最先进端到端算法在开环nuScenes数据集上的性能对比总结如表VI所示。
尽管开放循环评估在成本、安全性和可重复性方面具有优势,并能够利用大规模真实世界数据集进行高效验证,但它在反映实际驾驶性能方面仍然有限。由于缺乏反馈机制,这种评估无法捕捉误差累积,因为早期预测偏差不会影响后续输入,这可能导致轨迹漂移和连锁故障 72。此外,开放循环测试难以揭示诸如因果混淆、惯性偏差和分布偏移等问题,因为模型可能依赖表面相关性而非真正的因果推理,使其在动态或对抗性场景中脆弱 35。总体而言,虽然开放循环评估作为早期验证和算法比较的有价值工具,但全面评估驾驶能力仍需结合闭环仿真和真实世界测试,在逐步逼近实际部署的多阶段框架中进行。
B. 闭环仿真评估
鉴于开环评估在捕捉累积误差和动态交互方面的局限性,闭环仿真作为评估端到端自动驾驶系统的重要中间步骤显得尤为关键 270。如图 7(b) 所示,闭环评估将模型置于虚拟环境中,其决策基于模拟传感器输入,并直接影响车辆状态。随后更新的状态会改变后续的传感器输入,形成完整的感知--决策--执行--环境反馈循环。这种交互使得可以更真实地、在时间上延长地评估模型对自身行为和不断变化环境的响应表现。
闭环仿真解决了开放环评估的若干关键局限性。它可以揭示驾驶过程中长期误差的累积,支持对交通参与者之间动态交互的评估,并提供一个安全且可控的环境来测试稀有或危险的情景。此外,对于强化学习(RL)模型,闭环仿真不仅可用于训练,还可在反应一致的环境中用于策略评估。闭环评估依赖高保真模拟器,这些模拟器能够再现真实的传感器数据、车辆动力学、可配置环境及随机代理行为。常用的平台包括 CARLA 270、AirSim 271 和 SUMO 272,它们支持从真实世界日志或程序生成的多样交通场景。与开放环方法相比,闭环评估更强调任务级性能和安全性。典型指标包括任务成功率(SR)、路线完成率(RC)、碰撞与违规率、最短碰撞时间、车辆间距、平均速度、完成时间、加速度及瞬时加速度(jerk)。部分研究还采用驾驶员介入率作为部署准备情况和运营安全的指标。
闭环仿真通过捕捉动态交互和长期行为显著提升了评估效果;然而,其有效性仍受制于仿真与现实的差距。模拟器无法完全再现现实环境的复杂性,因为传感器模型通常忽略光照、天气、噪声及硬件故障的变化。车辆动力学和交通行为通常被简化,缺乏人类行为的多样性和不确定性。情景库的覆盖范围也有限,可能未包含罕见但安全关键的边缘案例,导致模型部署到现实中时性能下降。尽管如此,闭环仿真仍是离线训练与真实世界测试之间的重要桥梁,为规划、交互及安全机制的验证提供了安全且可控的环境,但其结果最终仍需通过真实世界实验进行验证。多个最先进端到端算法在闭环 CARLA Leaderboard 1.0 和 Bench2drive 基准上的性能比较总结如表 VII 和表 VIII 所示。
表7. 算法在闭环 CARLA 排行榜 1.0 上的表现。DS、RC 和 IS 分别表示驾驶分数、路线完成度和违规分数
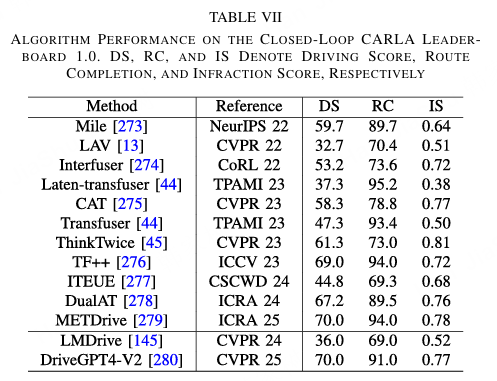
表8. 算法在闭环 Bench2Drive 基准测试中的性能。DS、SR、EFF. 和 COMF. 分别表示 DS、成功率、效率和舒适度。
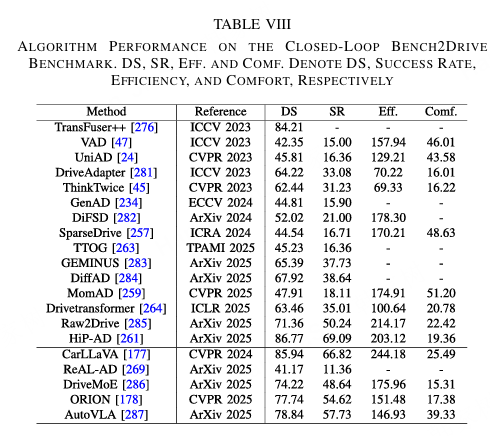
在 nuScenes L2 误差上,VLM/VLA 算法(DriveVLM 0.31,Senna 0.22)已经优于纯 IL 方法 VAD(0.72)和早期 RL 方法 GenAD(0.91),这表明多模态预训练能够实现场景语义迁移,在罕见长尾条件下保持较低的轨迹偏差。然而,大模型推理延迟通常比传统 IL 方法高出 2--3 倍,并且参数量大 1--2 个数量级。例如,在 Bench2Drive 效率指标上,VLA 模型的平均得分为 146--175,低于纯 CNN/Transformer 方法获得的 200 分,这表明实时性能和资源消耗仍然是主要瓶颈。总之,大模型在安全性、泛化能力和复杂语义理解方面相对于传统数据驱动方法具有明显优势;然而,实时性能和计算成本仍然是短期部署的主要障碍。
C. 综合干湿测试评估
集成干法与湿法测试已成为自动驾驶系统评估的一个有前景的范式,它将理论建模、仿真和实际验证结合到一个统一的框架中。它涵盖了从算法设计、基于仿真的训练到道路车辆测试的完整开发周期,通过数据增强和跨域迁移等技术,连接虚拟环境和物理环境。仿真使得在可控环境中进行高效迭代成为可能,而实际车辆测试则将模型暴露于复杂和长尾场景中,为提高系统的鲁棒性和可靠性提供关键反馈。
最近,基于 WM 的综合干湿检测评估方法不断取得突破。例如,OccSora 289 通过整合模拟数据和真实世界数据构建物理上合理的四维占用场景,提供了一个稳健的基于 WM 的评估系统。SimGen 232 通过结合模拟器和真实世界的数据生成,提高了场景的多样性和感知的泛化能力。这些以 WM 为驱动的方法提升了自主系统的真实性、适应性和整体可靠性。
在干湿测试中,评估指标涵盖多个维度,包括安全性、鲁棒性、泛化能力和数据效率。在仿真阶段,模型的准确性和鲁棒性主要反映系统识别多样化场景的能力,以及在噪声和天气变化等干扰下保持稳定的能力。在实际道路测试中,重点转向模型在复杂动态交通环境中的适应性和泛化能力。该框架的一个关键方面是仿真与真实车辆性能之间的一致性,包括车辆动力学和感知质量的一致性,确保系统在不同领域中表现出类似的行为模式。数据增强的有效性通过其增加场景多样性和提升模型性能的能力来衡量,尤其是通过对比使用和未使用合成数据训练的模型。最后,跨域迁移性能评估模型在仿真环境中训练后适应真实世界条件的能力,以及迁移技术在部署过程中对性能提升的贡献。
尽管集成干湿测试评估具有许多优势,但也面临一些挑战。一个关键问题是数据的一致性和准确性。仿真数据与实际数据之间存在差异。如何有效整合这些数据并确保其可靠性,需要进行深入研究。此外,反馈优化机制的效率同样至关重要。如何将真实车辆测试中的反馈信息快速且准确地转化为算法优化方向,需要建立更智能、高效的优化算法和流程。
总体而言,集成干湿测试通过将理论建模与实际测试相结合,为评估和优化自动驾驶系统提供了全面的方法。通过仿真、道路测试、数据增强以及跨域迁移,它能够有效支持系统的改进。尽管在数据融合和反馈优化方面存在挑战,但该方法有望在提升自动驾驶的安全性、可靠性和效率方面发挥越来越重要的作用。
D. 面向语言增强多模态驾驶系统的新兴评估框架
VLMs 和 LLMs 在自动驾驶系统中的快速整合正在从根本上重塑性能评估的范围和目标。现有的基准,如 nuScenes、CARLA 和 Waymo-Sim,提供了标准化的环境和物理指标;然而,它们在评估增强语言模型的认知和交互能力方面仍然不足。诸如 ADE 和 RMSE 等指标可以量化几何偏差,但无法捕捉模型是否能够解释为何采取特定动作或以人类可理解的方式表达其决策逻辑。此外,这些框架既无法评估多模态推理链的逻辑一致性,也无法评估模型在驾驶过程中执行基于语言的提问或语义解释的能力。
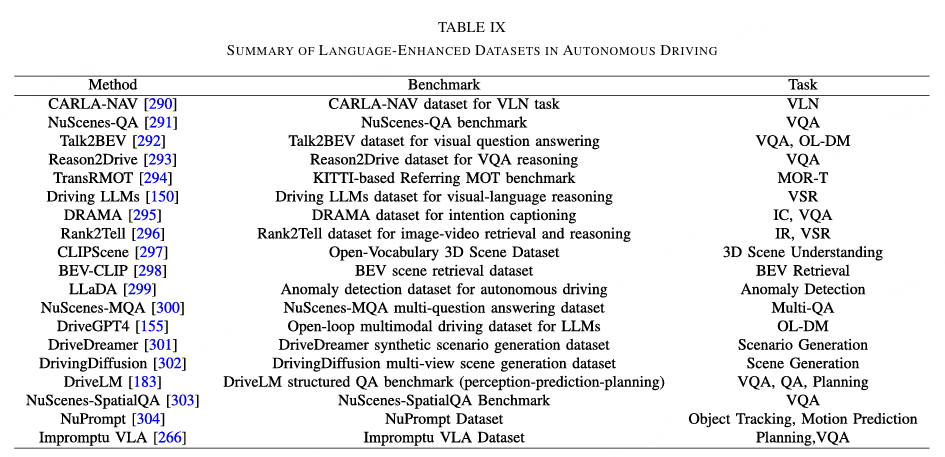
为了解决这些局限性,近期研究提出了各种语言增强的评估基准,将感知、推理和解读统一到单一框架中。如表9所示,NuScenes-QA 和 NuScenes-MQA 将传统的感知基准扩展为结构化问答格式,从而实现对推理和关系理解的量化评估。DriveLM 进一步将感知、预测和规划整合到基于多轮对话的评估中,而 Talk2BEV 和 Reason2Drive 则侧重于 BEV 或动态驾驶场景下的语义问答和因果推理。最近提出的 NuScenes-SpatialQA 构建了一个用于空间理解和推理的大规模基准。总体而言,这些努力展示了评估模式的转变,从传统的性能指标转向语言对齐的认知评估。
语言增强评估框架通常从三个互补的维度对模型进行评估。首先,它们检查文本查询是否能够准确地与视觉或空间实体对齐。其次,通过结构化问答或多轮对话,它们衡量模型在复杂场景中进行多步骤推理和意图预测的能力。第三,它们评估语言解释的事实准确性、因果一致性和可读性,以确定模型是否能够清楚地阐述其决策理由。除了传统指标,如准确率和FDE之外,这些框架还使用问答准确率、语义相似度(如BLEU和BERTScore)、因果有效性和对话一致性。
这些新型评估范式的出现标志着自动驾驶领域从性能导向向认知导向评估的转变。未来的研究预计将开发交互式评估环境,使模型能够在闭环模拟中以自然语言传达其感知、推理和规划决策。此外,将定量安全指标与定性可解释性测量相结合的混合评估系统,可能成为下一代自动驾驶基准的基础。总体而言,语言增强评估代表了迈向可信、可解释且与人类一致的自动驾驶系统的关键步骤。
五、自动驾驶的挑战与前景
A. 挑战
**1)面向端到端自动驾驶的多模态融合:**现代自动驾驶系统整合了来自异构传感器的数据,如摄像头、激光雷达、雷达和惯性测量单元(IMU),每种传感器提供互补信息。RGB图像提供语义上下文,激光雷达和立体摄像头提供精确的三维结构,而IMU和车辆传感器提供动态运动数据。这种多模态设置不仅增强了环境感知,同时也带来了如何高效融合多源数据的关键挑战。开发稳健的融合策略,将这些输入统一为连贯表示以实现可靠决策,仍然是端到端自动驾驶的核心问题。
自动驾驶早期的多模态融合技术主要集中在感知任务,如目标检测和分割305。近年来,端到端框架越来越多地引入这些策略45,46。例如,多模态端到端自动驾驶306表明,融合RGB和深度数据可同时提升感知和控制性能。融合方法通常分为早期融合、中级融合和后期融合。早期融合将原始输入直接拼接,但存在高维度和不稳定的风险;后期融合将不同网络的输出结合,计算成本较低,但信息量较少。中级融合则通过在中间层整合编码特征来平衡两者优势,但在数据同步、坐标系对齐和特征归一化方面仍面临挑战。基于Transformer的架构在跨模态建模方面显示了潜力44,但其高计算成本限制了实际部署。
近来,自然语言被引入作为额外模态,以融入高级语义和人类意图139,140,143。与视觉或几何输入不同,语言提供可解释的指导,但由于其模糊性、结构缺失以及对高延迟大语言模型(LLM)的依赖,带来了挑战。部署还受到运行时稳定性有限以及缺乏面向现实驾驶场景的大规模、结构化和多语言数据集的限制,从而制约了验证和可扩展性。
值得注意的是,就融合策略而言,固定权重融合方法已不足以应对随着场景复杂性和天气条件变化而产生的各模态信噪比的动态变化。因此,近期研究引入了基于质量感知和注意力机制的动态融合方法,使模型能够根据感知信号的可靠性自适应地调整视觉、LiDAR 和雷达输入的融合权重,从而在低能见度或传感器退化条件下保持稳健的感知和决策。然而,在融合过程中,准确估计各模态的置信度以及实现稳定、高效的动态权重调整仍然是当前多模态整合研究中的重大挑战。
总之,端到端自动驾驶中的多模态融合仍然是一个不断发展的领域,面临着模态异质性、计算效率、特征对齐和任务级协调等持续挑战。将语言作为补充模态引入框架,为系统带来了语义层面的先验知识,从而扩展了传统感知-决策流程的认知边界。这种整合具有显著潜力,能够推动端到端自动驾驶代理实现更高的可解释性和通用性,为自动驾驶系统的未来指明了一个有前景的方向。
**2)端到端自动驾驶中的泛化:**在自动驾驶中,长尾问题源于关键场景的罕见性,例如极端天气、异常的交通参与者行为以及复杂的道路布局。尽管这些高风险情景不常发生,但它们对实际部署构成了严重挑战。训练数据中对它们的有限表现会阻碍感知、预测和决策模型的泛化能力,从而在安全关键场景中导致更高的失败率。这个问题在端到端系统中尤为突出,因为训练主要以常规驾驶为主,而由于安全性和可复现性的限制,罕见事件很难收集。
为应对上述挑战,研究人员进行了广泛的研究。许多公司采取了尽可能多部署车辆在不同路线行驶的策略,旨在覆盖各种罕见交通情况,并通过积累定量数据实现自动驾驶能力的质的飞跃。虽然这种方法能够获得真实世界的驾驶场景,但它需要大量的人力、物力和财力,时间成本高,改进效果有限。在计算资源和模型参数受限的情况下,一些方法272,308依赖人工定义规则构建场景,从而在仿真环境中合成生成更多样的数据。例如,在极端情况下会触发应急干预,如系统回退或强制制动。然而,这些基于规则的系统通常导致决策僵硬且过于保守,从而泛化能力差,用户体验不佳。王等309和丁等310探索了将对抗攻击策略与贝叶斯优化和策略梯度强化学习等技术结合,数据驱动生成安全关键场景的方法。D2RL311提出一种密集深度强化学习方法,通过引入涉及背景车辆的各种碰撞,提高长尾场景的多样性。尽管这些方法在生成模拟长尾场景和加速自动驾驶安全验证迭代过程中表现出有效性,但它们在应对现实世界中未知的不可预见场景方面仍然存在局限。
上述大多数研究从数据生成角度解决长尾问题,旨在增加罕见场景的数量。近年来,大型语言模型(LLM)、VLMs(大型语言模型)和虚拟语言应用(VLA)展示了通过预训练获得的强大世界知识。当针对自动驾驶领域进行微调时,这些模型展现出专家级驾驶行为,采用了强大的模型中心方法来应对长尾挑战。然而,目前此类基础模型在端到端自动驾驶中的应用主要集中在可解释性任务,如场景描述和问答。此外,缺乏可靠且真实的长尾数据用于训练和评估,导致该领域的进展仅有表面。此外,虚拟数据与现实世界之间的差距也需要特别关注。将Bench2Drive排名第一的HiP-AD车型移植到真实城市道路后,其舒适度评分相对较低,且出现了突然的制动/转向事件。随后,增强传感器噪声和路面摩擦随机化显著减轻了急减速,提升了舒适度指标。虽然这一实例表明硬件在环噪声注入加上渐进域随机化可以缩小模拟与真实之间的差距,但这种差距的出现提醒社区,细微的场景差异会降低性能并削弱用户信任,这种无形影响值得定性关注。
总之,提升模型对长尾样本的泛化性和适应性,以及提升其应对现实极端情况的能力,仍是自动驾驶领域面临的关键挑战之一。
**3)端到端自动驾驶的效率:**由于车载计算资源有限,端到端自动驾驶模型的实时部署仍然具有挑战性。当前的数据驱动方法 24, 256 在训练和推理阶段都需要大量计算。虽然最近在大语言模型(LLMs)、视觉语言模型(VLMs)和视觉语言代理(VLAs)方面的进展已使统一驾驶代理成为可能 168, 169, 179, 202,但它们庞大的参数规模导致高内存和处理需求,使其难以在车载环境中实际部署。相比之下,端到端驾驶的轻量化解决方案仍未得到充分探索 189。因此,在模型性能和计算效率之间取得平衡已成为现实世界自动驾驶应用中一个关键且紧迫的挑战。
设计用于自动驾驶的轻量化基础模型面临若干关键挑战。首先,VLMs 和 VLAs 中的跨模态表示对齐涉及高维视觉和语言数据,导致复杂的架构和冗余计算,阻碍了实时和能效部署。其次,压缩或蒸馏大型模型往往会降低其在罕见场景、多样化输入或多语言指令上的泛化能力,从而在安全关键条件下影响鲁棒性。
尽管在第 III-B 节中回顾的轻量化方案,即 MiniDrive 189 和 LiteViLA 190,通过专家混合(MoEs)适配器或动态分辨率机制将延迟降低到 50 毫秒以下,但已发布的消融研究揭示了两个限制。首先,当稀疏激活比超过 30% 时,相较于密集版本,GPU 内存仅降低不到 40%,仍超出 NVIDIA Thor-U 数据表中规定的 8 GB 汽车安全预算。其次,在知识蒸馏后,罕见的 nuScenes 分类构建车辆的平均精度从 42.1 降至 23.4,下降了 18.7%,如 LiteViLA 报告所示,显示了轻量化与长尾性能之间的根本权衡。
第三,车载部署受限于汽车级硬件的计算能力、内存和功耗,而大多数基础模型依赖高性能 GPU 或 TPU,这使得硬件适配和流程重构变得困难。第四,现有的轻量化方法通常针对单任务模型进行优化,难以在多任务感知-预测-规划流程中保持一致性。最后,对大规模多模态预训练数据的依赖限制了其迁移能力;将此类模型适配到自动驾驶领域需要高质量、带标注的驾驶数据,而这些数据获取成本高且受隐私限制。MindVLA 首先训练了一个 320 亿参数的云端视觉-语言基础模型,然后将其蒸馏为 36-40 亿参数的汽车级 MoE。然而,维持功能安全仍然需要持续获取高精度的真实数据,这表明"超大模型-轻量标注"的范式尚未完全解决成本瓶颈。
总之,尽管从数据驱动方法向 LLM、VLM 和 VLA 的范式转变为构建通用智能驾驶代理提供了有前景的路径,但在车载系统的轻量化、效率和稳定性需求之间仍未实现平衡。展望未来,迫切需要开发适用于自动驾驶场景的轻量级多模态大模型解决方案,这些方案应具备结构可适应性、知识迁移能力和任务特定的模块化设计。在任务性能和部署效率之间实现平衡,将是大模型在真实自动驾驶系统中应用的关键突破口。
**4)灾难性遗忘挑战:**在端到端自动驾驶系统的持续训练和学习过程中,由于新旧知识的重叠,模型面临灾难性遗忘的挑战。具体而言,灾难性遗忘指的是模型在学习新数据和任务时,容易丧失之前获取的知识,导致在旧任务上的性能显著下降。传统的机器学习方法通常假设训练数据是一次性提供的 312,313,314,并且模型在训练后不会更新 315。然而,在现实的自动驾驶场景中,车辆不断遇到新的道路状况、交通模式和驾驶场景,这就要求模型能够持续学习和适应。例如,一个在城市环境中学会了特定交通规则和驾驶策略的模型,在部署到农村或高速公路环境时,在适应新环境的同时,可能会遗忘之前学到的知识。为了实现自动驾驶智能体的可持续学习和智能演化,确保模型在持续学习和适应新环境的同时,依旧能够高效处理旧任务至关重要。因此,解决灾难性遗忘的挑战对于提升自动驾驶系统的可靠性和适应性非常关键。
为了应对灾难性遗忘,研究人员提出了多种方法。一种常见策略是弹性权重巩固(EWC)316,它在优化过程中保留对旧任务重要的参数,防止新学习造成过度干扰 317。此外,经验回放方法 318 会存储部分旧数据,并在学习新数据时重新播放,使模型能够在旧数据和新数据上同时训练,从而保留旧知识。然而,这些方法在实际应用中面临挑战:数据回放可能引发存储和隐私问题,关键参数的识别仍然困难,且任务数量增加会导致模型复杂度提高,影响部署效率。克服灾难性遗忘对于提升自动驾驶系统的适应性和可靠性至关重要。
与传统的 CNN 骨干网络相比,第三节 III-C 中的 VLA 模型,即 DriveVLM 169 和 Senna 168,参数量增加了两个数量级,将遗忘问题从权重覆盖升级为知识记忆耦合失败。以代表性的大模型 DriveVLM(LLaMA 7B 骨干)为例,在从城市到高速公路领域的持续微调后,nuScenes 稀有物体召回率从 68.1 降至 51.7(下降 16.4%,HiP-AD 并行实验),显示旧领域 token 的深度前馈网络(FFN)层激活率下降超过 40%;秩为 16 的低秩适配(LoRA)仅恢复了 3.2%,表明小型插件适配器的梯度隔离不足。MLLM-CL 基准上的 MR-LoRA 319 使旧领域准确率仅下降 2.1%,优于标准 LoRA 的 9.7%,证明稀疏重放加低秩校正更适合十亿参数的 VLA。然而,经验重放通常需要大量内存来存储历史 BEV 特征,这不仅与有限的车载内存相冲突,也与 WP.29 数据匿名条款相抵触。
近期,一些研究开始探索使用元学习 320,321 来增强模型的持续学习能力,使其在学习新任务的同时保留旧知识。尽管这些方法在理论上具有潜力,但在实际自动驾驶场景中的应用仍处于初期阶段。总之,灾难性遗忘是端到端自动驾驶必须克服的重大挑战,以实现真正的智能和适应性。这需要在模型设计、训练策略以及计算资源管理方面进行深入研究和创新。
**5)系统安全挑战:**在端到端自动驾驶系统的部署过程中,安全风险------尤其是在通信和数据安全方面------构成了严重威胁。通信安全保证车辆、基础设施与云服务之间控制和感知信息的可靠交换。数据安全则着重于在处理、传输和存储过程中保护敏感信息,如用户身份、驾驶行为和环境感知数据。在实际交通中,自动驾驶车辆必须实时持续交换数据。然而,通信链路容易受到网络攻击,包括黑客攻击、数据篡改和拒绝服务(DoS)攻击,这可能导致命令延迟或错误,从而危及驾驶安全。同样,数据安全的漏洞可能导致私人信息泄露或通过恶意数据操作扭曲决策,进而可能引发不安全或错误的车辆行为。解决这些漏洞对于确保强大且可信赖的自动驾驶系统至关重要。
为应对这些系统安全挑战,研究人员和工程师提出了多种解决方案,如图8所示。在通信安全方面,采用了加密技术、身份认证与授权机制以及安全协议。例如,端到端加密可以确保数据在传输过程中的机密性和完整性,而数字证书用于认证通信双方,以防止未经授权的访问322。在数据安全方面,除了加密技术之外,还实施了隐私保护策略323,如访问控制和数据匿名化,以降低泄露风险。尽管采取了这些措施,实际应用中仍面临挑战。随着攻击手段的发展,安全技术必须不断更新。安全机制也可能增加系统的复杂性和计算负担,从而影响实时性能。确保整体系统安全需要从硬件、软件和网络等多个角度进行全面考虑,因为任何薄弱环节都可能危及整体安全。
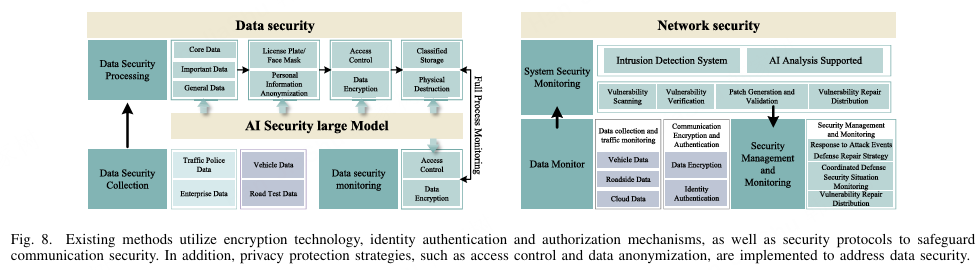
图 8. 现有的方法利用加密技术、身份认证和授权机制以及安全协议来保障通信安全。此外,还实施了隐私保护策略,如访问控制和数据匿名化,以应对数据安全问题。
总之,端到端自动驾驶系统的安全性对于自动驾驶技术的可靠性和用户信任至关重要。未来的研究与开发必须在通信和数据安全技术上不断创新,同时加强安全标准和法规的制定。这将确保自动驾驶系统在各种真实驾驶场景下的安全性和隐私保护。
**6)监管不匹配挑战:**向端到端大模型驱动的自动驾驶过渡正在将功能安全范式从固定需求和静态验证转向持续学习和动态治理。尽管 ISO 26262、UL 4600 和 WP.29 CSMS 对 ASIL 等级、剩余风险上限和 OTA 可追溯性提出了严格要求,但其方法论仍假设需求可以固定并且故障模式可枚举。然而,拥有数百亿参数的大型语言模型(LLM)展现出突现行为和幻觉,这使得事先完成需求闭环和对故障空间的全面描述变得不可能。这个规范性差距,即如何为既能对话又会产生幻觉的生成模型提供可量化、可审计且可回滚的合规证据链,已成为其工业部署的主要瓶颈。
结合已发表的研究和企业白皮书,我们总结了三种与监管对齐的应对措施及其当前成熟度。
将幻觉引发的错误轨迹的风险分解为两个指标:语义一致性和分布外检测覆盖率。Biswas 等人 324 引入了生成源事实重叠指标,并报告了一致性区间为 98.7%--99.8%,与提出的 99.5% 阈值一致。Kulkarni 等人 325 在一个语义相似的合成数据集上实现了 95.3% 的操作设计域(OOD)召回,确认了覆盖目标的可实现性。
根据 UL 4600 构建三步证据链:基于云的对抗生成、剩余风险的统计外推和车内影子模式验证。约克大学在 2023 年的一份技术报告首次提出使用对抗生成加统计外推来证明剩余风险低于 10^-7 h^-1,但该报告未提供实际生成的轨迹数量、外推细节或车内验证里程,因此不能构成可审计的证据链。目前,像小鹏和华为这样的公司公开提到 3×10^4 公里无干预驾驶作为影子模式的进入标准,但实验设计、场景分布或剩余风险计算程序均未公布。
创建一个包含模型 di-hash、训练数据版本和安全回归报告的变更包,并配备一个预部署监控器,如果幻觉率超过 0.1%,则自动回滚。GitHub 社区中存在开源实现,但针对自动驾驶大语言模型的研究仍处于早期阶段。
总之,这三种对策都在学术界或工业界实现了点验证;然而,一个端到端可审计的循环尚未建立。语义一致性和 OOD 覆盖率指标已在公开实验中得到支持,可以直接作为关键绩效指标(KPI)采用。UL 4600 的三步证据链仍缺乏完整的数据和第三方复现,因此需要一个开放的基准。0.1% 幻觉回滚阈值仍是企业声明,在驾驶领域的大语言模型中没有公开可用的模板或实验数据。未来的工作应通过标准化数据集、统一评估协议和监管批准的安全回归格式,将这些碎片整合成可量化、可重复和可提交的合规包,从而实现整个车辆生命周期内的大模型持续迭代和监管认证。
B. 发展趋势
**1)用于增强端到端自动驾驶的 WMs:**从数据角度来看,高效且真实地生成反映长尾分布的安全关键场景仍然是一个重大挑战。从建模角度来看,目前利用大语言模型(LLMs)应对自动驾驶中长尾场景的研究仍处于初期阶段。近期,基于 LLMs 构建的 WMs 展现出强大的泛化能力和未来状态预测能力,在数据生成和模型适应性方面具有优势。这一新兴范式为解决自动驾驶系统中数据稀缺和泛化能力有限的双重挑战提供了有前景的解决方案。通过学习环境的潜在动态并构建模拟真实世界条件的抽象表示,WMs 使智能体能够在虚拟环境中有效训练。与依赖大规模监督数据集的传统感知和决策模型相比,WMs 提供了一种通过想象和生成推理系统化建模罕见场景的方法。这些优势体现在以下几个方面。
通过学习潜在动力学和因果结构,WMs 可以生成多样且语义一致的长尾情景,用于训练和评估,从而减少对稀缺现实数据的依赖。在这些虚拟环境中,智能体能够在罕见条件下练习行为,提高其反应能力和策略稳健性。WMs 的共享抽象空间还支持元学习,使系统能够在有限数据情况下快速适应新场景。此外,引入不确定性估计能够让系统关注不确定或低代表性区域,通过有针对性的采样和自监督策略提升学习效率。
总之,WMs 不仅为克服样本稀缺瓶颈提供了一条新路径,还为提高自动驾驶系统在应对真实世界、不可预见、分布外和高风险场景下的适应性和稳健性奠定了基础,如图 9 所示。展望未来,将 WMs 的结构化建模能力与自动驾驶的端到端学习需求相结合,可能为有效应对长尾挑战提供关键方向。
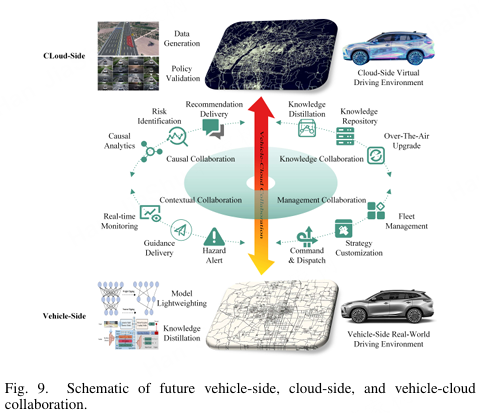
图9. 未来车端、云端及车-云协作示意图
根据当前研究和市场趋势,本综述预计 WMs 与端到端自动驾驶的融合将经历三个阶段。
**近期(1--2 年):**WMs 作为数据生成工具成熟。基于 4D 占空或图像激光雷达潜在空间的生成模型,如 OccSora、SimGen 和 Vista,已经能够在仿真中低成本合成长尾场景。预计在 1--2 年内,它们将成为主流的数据增强工具,可节约 30%--40% 的昂贵真实世界标注里程。
**中期(2--3年):**WMs 与 RL 在闭环管道中紧密集成。车载上运行一个轻量级感知-控制网络,而云端的 WM 则作为互动数字孪生,支持自我对弈策略演化和快速迭代。云到车的蒸馏定期更新车载模型,目标是在城市驾驶中将接管率降低一个量级。地平线机器人(Horizon Robotics)的 HSD 系统已展示了这一阶段的核心能力。HSD 建立在端到端 WM 和互动博弈算法基础上,在极端场景中验证了性能,包括突发车道潮汐变化和无高清地图的碎石路。预计将在 2025 年第三季度实现首次量产车发布,这一部署表明 WMs 已由离线数据生成器转变为关键的在线推理和决策组件,为中期阶段建立了早期基准。
**长期(3--5年):**WMs、LLMs、VLMs 及车辆动力学模型将统一为"一个大型驾驶 WM"。在共享潜在空间中,感知、预测、规划和控制将同步执行,实现对新城市或天气条件的零样本迁移,并实现"即插即用"的通用自动驾驶。由于传感器简化和计算共享,硬件成本预计将下降 20%--30%。
**2)性能与效率:**当前的基础模型通常规模较大,推理延迟高,计算开销大,这限制了在资源受限的车载环境中的训练效率和部署可行性。因此,实现轻量化设计同时保持性能已成为自动驾驶的关键研究方向。
一个有前景的方法是面向任务的模型设计。鉴于自动驾驶任务的层次化和结构化特性,未来的模型可能会被分解为可复用和可裁剪的组件,以支持动态按需组合。例如,VLM中的视觉-语言对齐模块可以与低级感知模块解耦,同时稀疏激活机制(如专家混合机制)可以选择性地激活特定子任务相关的子模块,从而减少不必要的计算。另一个方向是通过知识蒸馏实现多模态压缩。师生框架可以将大规模VLM或VLA的跨模态知识转移到更小、更高效的模型中。强化学习和对比目标进一步提升了知识迁移的质量和泛化能力,尤其是在边缘部署场景中。为了加快结构复杂模型的推理速度,可以探索剪枝和量化技术的联合优化。将神经网络结构搜索与硬件感知剪枝、缓存压缩、通道剪枝和稀疏注意力结合,能够在不影响模型稳定性的情况下降低延迟,如图9所示。此外,通过结构化预训练和高效微调技术(如参数高效调优)进行领域特定适配,可以在有限数据下提升性能,支持模型专业化和尺寸缩减。
总之,基础模型的轻量化不仅仅是压缩问题,而是关于重新思考模型架构、计算策略和任务协调。从模块化设计到高效部署,从通用能力到实用价值,构建可扩展、具备推理能力且具备安全保障的驾驶系统,将成为人工智能与自动驾驶交汇处的核心挑战。
**3) 车辆--云协作:**车云协作是一种前瞻性的方法,通过云端强大的计算和数据处理能力来赋能自动驾驶。云端可以实时接收和处理大量驾驶数据,包括道路状况、车辆状态以及环境感知信息。利用这些数据,云端可以进行因果序列推理,以揭示复杂交通场景中的潜在风险和因果关系。例如,在交通拥堵或事故的情况下,云端能够快速分析事件的原因、发展过程及可能的结果。这为车辆提供精确的决策建议,使自动驾驶车辆能够及时采取规避措施,从而显著提升驾驶安全性。
云端还作为驾驶知识的中央管理枢纽,可以统一管理来自不同地区和不同道路条件的驾驶数据。通过使用机器学习和数据挖掘技术,云端能够提炼通用的驾驶规则、策略和经验。这种知识系统的持续优化不仅支持自动驾驶系统的软件更新和策略改进,还使车辆能够适应更广泛的驾驶场景,从而全面提升驾驶性能。
未来,云端将基于驾驶记录、用户偏好和实时交通状况,为车辆提供个性化的驾驶知识支持和推送服务。当车辆进入不熟悉或复杂的驾驶环境时,云端可以及时推送相关的驾驶指南、注意事项和当地交通规则,帮助车辆快速适应新情况。在车队管理场景中,云端可以依据车队的整体任务和目标,为每辆车定制最优驾驶路线和策略,从而提升车队的运营效率和协调性。
总之,未来车-云协作的发展将聚焦于深入挖掘和高效利用云端智能,如图9所示。通过在因果推理、知识管理和个性化服务方面的进步,这种协作旨在构建一个更安全、更智能、更高效的自动驾驶系统。这不仅将显著提升自动驾驶车辆的性能和可靠性,还将为用户提供更加便捷和个性化的驾驶体验,从而加速自动驾驶技术的广泛应用。
**4)统一模型架构:**一个突破性的视角是开发一个统一的自动驾驶模型,该模型整合了大型语言模型(LLMs)、视觉语言模型(VLMs)、视觉语言代理(VLAs)、工作存储(WMs)和车辆模型。这个集成架构将增强自动驾驶系统的感知、理解和决策能力,为技术带来质的飞跃。
语言模型作为智能核心,提供先进的语义理解和指令解析能力。它能够准确解读司机或乘客的自然语言指令,例如复杂的导航请求或突发的驾驶意图变化,并将其转化为具体的驾驶策略。此外,它可以实时处理交通标志和道路指示的文本信息,结合上下文理解,为驾驶决策提供全面的语义支持。视觉语言模型(VLM)整合了语言与视觉感知,使车辆能够直观地理解视觉场景中的语义信息。这种跨模态的理解使车辆能够在复杂的交通场景中做出符合人类认知逻辑的决策。工作记忆(WM)作为环境预测与模拟的核心,动态预测和模拟驾驶环境的变化。它分析历史和实时传感器数据,同时结合语言模型提供的语义信息以及VLM的场景理解,从而实现对其他道路使用者行为和潜在风险的更准确预测。车辆模型作为执行层的核心,将高层决策转化为精确的控制指令。它与工作记忆保持反馈回路,根据实时环境预测调整控制策略,以确保车辆平稳、安全地运行。
这一集成模型架构将显著提升系统性能和适应性。在语言模型的语义指导下,VLM 的场景理解、WM 的环境预测以及车辆模型的精确控制,使自动驾驶系统能够在复杂环境中实现更精准的感知、更智能的决策以及更可靠的控制。研究将从优化单一模型转向协调多模型,以实现统一模型架构的实际应用,提高系统效率和稳定性。
图10展示了当前MindVLA和HSD框架的概览,详细说明了模块级映射和关键技术特性。两种解决方案的架构差异源于产品定位上的根本性不一致。MindVLA利用大规模参数、高计算预算和深度定制,实现旗舰级、豪华车般的驾驶体验,而HSD则依赖低功耗、可扩展和标准化的接口。这在目标价格区间、功能深度和商业模式上形成了明显的分层。总之,图10不仅突出了它们各自的技术路线,还展示了高端旗舰与经济型平台解决方案的市场分割,为未来架构选择和产业合作提供了清晰的参考。
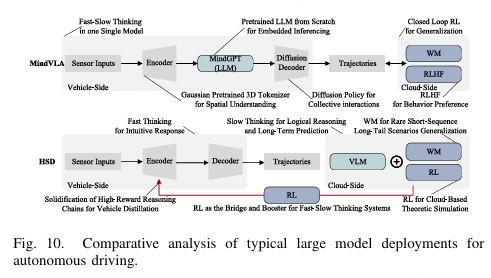
图10. 自动驾驶典型大模型部署的比较分析
六、结论
近年来,端到端自动驾驶技术经历了快速发展,从基于模仿学习(IL)和强化学习(RL)的经典范式,发展到由大规模基础模型驱动的多模态统一框架。这一演进不仅促进了感知、决策与规划的深度融合,也在可解释性、泛化能力和人机交互方面展现了新的潜力。同时,随着智能交通需求的日益多样化,端到端框架在特定场景下显示出广阔的应用前景。例如,在城市物流中,端到端方法有望通过简化的感知-决策流程提升复杂交通条件下的配送效率;在乡村道路上,这一范式可通过轻量化部署和云-边协作缓解基础设施薄弱的限制;在极端天气、低功耗或低带宽环境中,其统一的架构和知识迁移能力能够提高安全性和适应性。这些探索有助于端到端自动驾驶的实际应用,并为大规模现实场景提供宝贵经验。
然而,仍然存在若干关键挑战。大规模模型在训练和推理过程中都会带来显著的计算和能源成本。在复杂环境中,多模态特征融合往往受到噪声和时间错位的影响。目前的系统在长尾和极端场景下仍表现出不足的鲁棒性,同时安全验证和标准化框架尚未完全发展。这些限制对端到端自动驾驶系统在真实车辆上的部署以及大规模商业化构成了重大障碍。
展望未来,端到端自动驾驶的研究将越来越注重性能与效率的平衡,以及安全性和可靠性的保障。一方面,基于WM的统一认知框架有望在数据生成和推理优化中发挥关键作用;另一方面,稀疏激活机制、知识蒸馏和参数高效微调将为轻量化和可部署的大模型提供可行路径。同时,可解释性、透明性和安全标准的建立将成为推进端到端方法走向大规模工业应用的必要前提。总之,端到端自动驾驶正在从可行性验证阶段向实用可靠性阶段转变,其持续发展将深刻影响智能交通系统的发展,并为未来智能出行提供重要支撑。