一、多头注意力
1. 直观理解 (What & Why)
-
什么是多头注意力?
它是 Transformer 模型(由 Google 在 Attention Is All You Need 中提出)的核心组件。简单来说,就是把"自注意力机制 (Self-Attention)"重复做多次(多个"头"),然后再把结果合并起来。
-
通俗比喻:
假设你在看一幅画。如果只有一个"头"(单头注意力),你可能只注意到了画的颜色 ;但如果你有多个"头",头1可以关注颜色 ,头2可以关注线条 ,头3关注构图 。多头机制让模型能够从不同的维度和视角去理解同一段信息。
2. 前置知识:单头自注意力 (Self-Attention)
在理解多头之前,先回顾单头注意力的核心公式:
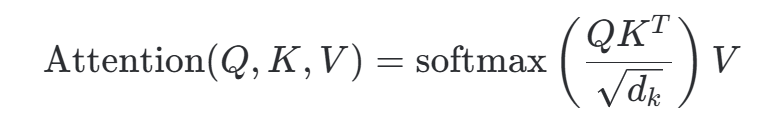
-
Q (Query): 寻问者(我要找什么?)
-
K (Key): 关键词(我有什么特征?)
-
V (Value): 实际内容(我的具体内容是什么?)
-
过程: Q和K点乘计算出相似度(注意力权重),经过 Softmax 归一化后,再乘以V得到最终的加权表示。
3. 多头注意力的计算流程
多头注意力并不是简单地把上面的公式算h次,而是将QKV映射到不同的低维子空间,再分别计算注意力,最后拼接。
步骤 1:线性映射 (Linear Projection)
对于每一个头 i,使用不同的权重矩阵对原始的QKV进行线性变换
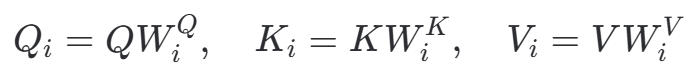
步骤 2:并行计算注意力 (Scaled Dot-Product Attention)
每个头独立计算自己的注意力结果
步骤 3:拼接 (Concatenation)
将所有h个头的结果拼接(Concat)在一起。拼接后的维度恢复到原来的模型维度
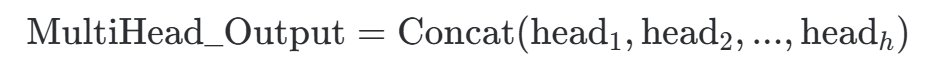
步骤 4:最终线性映射 (Final Projection)
通过一个输出权重矩阵 W0,将拼接后的特征再进行一次线性融合
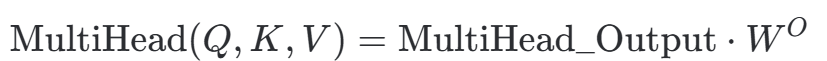
二、代码
import math
import torch
from torch import nn
import d2l
# import test_65attentionscore
def sequence_mask(X,valid_len,value=0):
masklen=X.size(1)
mask=torch.arange((masklen),dtype=torch.float32,device=X.device)[None,:]<valid_len[:,None]
X[~mask]=value
return X
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
class MultiHeadAttention(nn.Module):
def __init__(self,key_size,query_size,value_size,num_hiddens ,num_heads,dropout,bias=False,**kwargs):
super(MultiHeadAttention,self).__init__(**kwargs)
self.num_heads=num_heads
self.attention=DotProductAttention(dropout)
self.W_q=nn.Linear(query_size,num_hiddens,bias=bias)
self.W_k=nn.Linear(key_size,num_hiddens,bias=bias)
self.W_v=nn.Linear(value_size,num_hiddens,bias=bias)
self.W_o=nn.Linear(num_hiddens,num_hiddens,bias=bias)
def forward(self,queries,keys,values,valid_lens):
#q,k,v形状为(batch_size,q或者k-v个数,num_hiddens)
#valid_lens形状(batch_size,)或(batch_size,查询个数)
#经过变换,q,k,v形状为(batch_size*num_heads,q或者k-v个数,num_hiddens/num_heads)
queries=transpose_qkv(self.W_q(queries),self.num_heads)
keys=transpose_qkv(self.W_k(keys),self.num_heads)
values=transpose_qkv(self.W_v(values),self.num_heads)
if valid_lens is not None:
valid_lens=torch.repeat_interleave(valid_lens,self.num_heads,dim=0)
output=self.attention(queries,keys,values,valid_lens)
output_cancat=transpose_output(output,self.num_heads)
return self.W_o(output_cancat)
def transpose_qkv(X,num_heads):#让多头注意力并行计算,而不是用forloop
#输入x的形状:(batch_size,查询或k-v个数,num_hiddens)
#输出X的形状:(batch_size,查询或k-v个数,num_heads,num_hiddens/num_heads)
X=X.reshape(X.shape[0],X.shape[1],num_heads,-1)#输入x的形状:(batch_size,查询或k-v个数,num_heads,num_hiddens/num_heads),num_hiddens / num_heads 是每个头分配到的特征维度。
X=X.permute(0,2,1,3)#输出X的形状:(batch_size,num_heads,查询或k-v个数,num_hiddens/num_heads),为了让每个头的计算能够并行处理。
return X.reshape(-1,X.shape[2],X.shape[3]) #输出X的形状:(batch_size*num_heads,查询或k-v个数,num_hiddens/num_heads)#合并这样每个头的数据可以独立处理,并且每个头对应的特征维度变小,便于并行计算。
def transpose_output(X,num_heads):#逆转transpose_qkv操作
#X的形状(batch_size * num_heads, seq_len, num_hiddens / num_heads)
X=X.reshape(-1,num_heads,X.shape[1],X.shape[2])#X的形状(batch_size ,num_heads, seq_len, num_hiddens / num_heads)
X=X.permute(0,2,1,3)#X的形状(batch_size , seq_len, num_heads,num_hiddens / num_heads)
return X.reshape(X.shape[0],X.shape[1],-1)#X的形状(batch_size,seq_len,num_hiddens)
num_hiddens,num_heads=100,5
attention=MultiHeadAttention(num_hiddens,num_hiddens,num_hiddens,num_hiddens,num_heads,0.5)
attention.eval()
batch_size,num_queries=2,4
num_kvpairs,valid_lens=6,torch.tensor([3,2])
X=torch.ones((batch_size,num_queries,num_hiddens))
Y=torch.ones((batch_size,num_kvpairs,num_hiddens))
print(attention(X,Y,Y,valid_lens).shape)