一、解析 CSV 文件头
要在文本文件中存储数据,最简单的方式是将数据组织为一系列以逗号分隔的值(comma-separated values,CSV)并写入文件。这样的文件称为 CSV文件。例如,下面是一行 CSV 格式的天气数据:
python
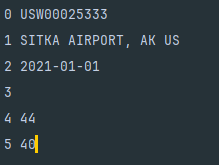
"USW00025333","SITKA AIRPORT, AK US","2021-01-01",,"44","40"1. 解析 CSV 文件头
csv 模块包含在 Python 标准库中,可用于解析 CSV 文件中的数据行,让我们能够快速提取感兴趣的值。先来查看这个文件的第一行,其中的一系列文件头(file header,CSV 文件的列标题行)指出了后续各行包含的是什么样的信息:
python
from pathlib import Path
import csv
# 读取文件
path = Path('test.csv')
lines = path.read_text().splitlines()
# 创建一个 reader 对象,用于解析文件的各行。为了创建 reader 对象,调用 csv.reader() 函数并将包含 CSV 文件中各行的列表传递给它。
reader = csv.reader(lines)
# 函数 next() 返回文件中的下一行(从文件开头开始)
header_row = next(reader)
print(header_row)运行结果如下:

2. 打印文件头及其位置
为了让文件头数据更容易理解,我们将列表中的每个文件头及其位置打印出来:
python
from pathlib import Path
import csv
# 读取文件
path = Path('test.csv')
lines = path.read_text().splitlines()
# 创建一个 reader 对象,用于解析文件的各行。为了创建 reader 对象,调用 csv.reader() 函数并将包含 CSV 文件中各行的列表传递给它。
reader = csv.reader(lines)
# 函数 next() 返回文件中的下一行(从文件开头开始)
header_row = next(reader)
# 对列表调用 enumerate() 来获取每个元素的索引及其值。
for index, row in enumerate(header_row):
print(index, row)运行结果如下:
3. 提取并读取数据
先创建一个名为 highs 的空列表,再遍历文件中余下的各行。reader 对象从刚才中断的地方继续往下读取 CSV 文件,每次都自动返回当前所处位置的下一行。由于已经读取了文件头行,这个循环将从第二行开始------从这行开始才是实际数据。每次执行循环时,都将索引为 4(TMAX列)的数据追加到 highs 的末尾
python
from pathlib import Path
import csv
# 读取文件
path = Path('test.csv')
lines = path.read_text().splitlines()
# 创建一个 reader 对象,用于解析文件的各行。为了创建 reader 对象,调用 csv.reader() 函数并将包含 CSV 文件中各行的列表传递给它。
reader = csv.reader(lines)
# 函数 next() 返回文件中的下一行(从文件开头开始)
header_row = next(reader)
# 对列表调用 enumerate() 来获取每个元素的索引及其值。
# for index, row in enumerate(header_row):
# print(index, row)
highs = []
for row in reader:
high = int(row[4])
highs.append(high)
print(highs)其中text.csv存储数据如下:
python
date,high,low
2026-01-01,61,50
2026-01-02,60,49
2026-01-03,66,52
2026-01-04,60,48
2026-01-05,65,50
2026-01-06,59,47
2026-01-07,58,46
2026-01-08,58,46
2026-01-09,57,45
2026-01-10,60,48
2026-01-11,60,48
2026-01-12,60,48
2026-01-13,57,45
2026-01-14,58,46
2026-01-15,60,48
2026-01-16,61,49
2026-01-17,63,50
2026-01-18,63,50
2026-01-19,70,55
2026-01-20,64,52
2026-01-21,59,48
2026-01-22,63,50
2026-01-23,61,49
2026-01-24,58,46
2026-01-25,59,47
2026-01-26,64,52
2026-01-27,62,51
2026-01-28,70,55
2026-01-29,70,55
2026-01-30,73,57
2026-01-31,66,534. 绘制温度图
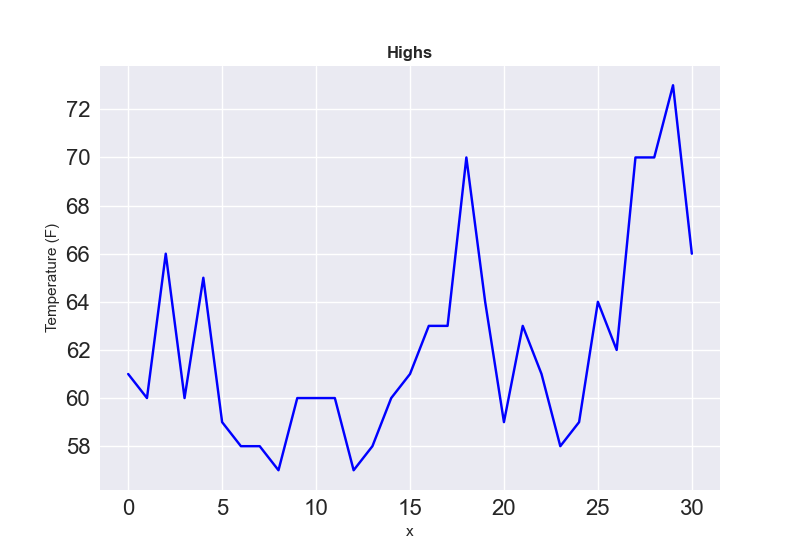
为了可视化这些温度数据,首先使用 Matplotlib 创建一个显示每日最高温度的简单绘图,如下所示:
python
from pathlib import Path
import csv
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
# 读取文件
path = Path('test.csv')
lines = path.read_text().splitlines()
# 创建 reader 对象
reader = csv.reader(lines)
# 读取 header
header_row = next(reader)
highs = []
for row in reader:
# 假设 highs 在倒数第二列
high_str = row[-2]
if high_str != '': # 避免空值
high = int(high_str)
highs.append(high)
print(highs)
# 绘图
plt.style.use('seaborn-v0_8')
fig, ax = plt.subplots()
ax.plot(highs, color='blue')
ax.set_title('Highs', fontweight='bold')
ax.set_xlabel('x', fontweight=16)
ax.set_ylabel('Temperature (F)', fontweight=16)
ax.tick_params(labelsize=16)
plt.show()运行结果如下:
5. datetime 模块
在读取该数据时,获得的是一个字符串,因此需要想办法将字符串"2026-01-01" 转换为一个表示相应日期的对象。为了创建一个表示 2021 年 7月 1 日的对象,可使用 datetime 模块中的 strptime() 方法。我们在终端会话中看看 strptime() 的工作原理:
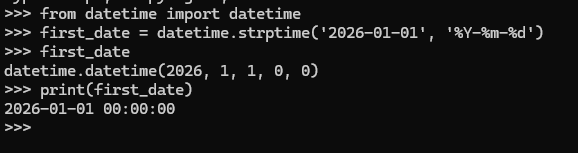
首先导入 datetime 模块中的 datetime 类,再调用 strptime() 方法,并将包含日期的字符串作为第一个实参。第二个实参告诉 Python 如何设置日期的格式。
6. 在图中添加日期
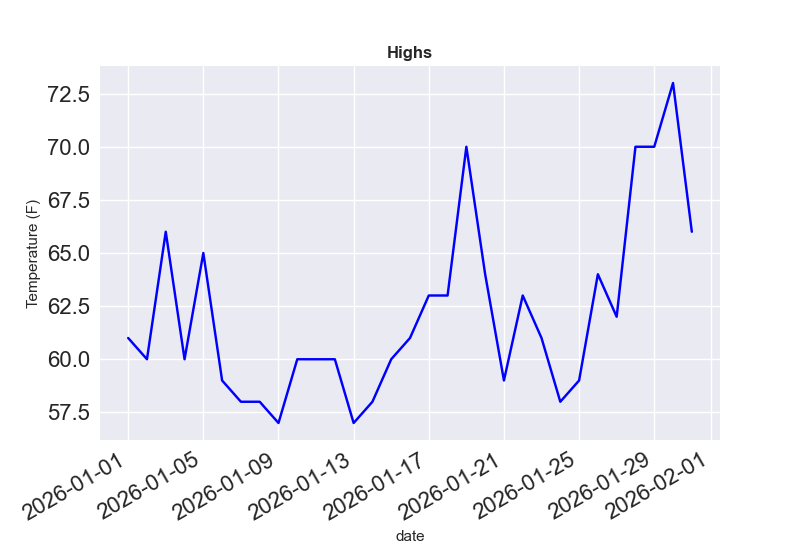
现在可对温度图进行改进了------提取日期和最高温度,并将日期作为 x 坐标值:
python
from pathlib import Path
import csv
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from datetime import datetime
# 读取文件
path = Path('test.csv')
lines = path.read_text().splitlines()
# 创建 reader 对象
reader = csv.reader(lines)
# 读取 header
header_row = next(reader)
dates, highs = [], []
# 提取日期和最高温度
for row in reader:
# 假设 highs 在倒数第二列
current_date = datetime.strptime(row[0], '%Y-%m-%d')
high_str = row[-2]
high = int(high_str)
dates.append(current_date)
highs.append(high)
print(highs)
# 绘图
plt.style.use('seaborn-v0_8')
fig, ax = plt.subplots()
ax.plot(dates, highs, color='blue')
ax.set_title('Highs', fontweight='bold')
ax.set_xlabel('date', fontweight=16)
# 日期倾斜
fig.autofmt_xdate()
ax.set_ylabel('Temperature (F)', fontweight=16)
ax.tick_params(labelsize=16)
plt.show()运行结果如下:
二、制作全球地震散点图:GeoJSON 格式
本节将首先下载一个数据集,其中记录了一个月内全球发生的所有地震,然后制作一幅散点图,展示这些地震的位置和震级。这些数据是以 GeoJSON 格式(基于 JSON 的地理空间信息数据交换格式)存储的,因此要使用 json 模块来处理。我们将使用 Plotly 来创建图形,清楚地指出全球的地震分布情况。
1. 地震数据
在用于存储本章程序的文件夹中,新建一个文件夹并将其命名为eq_data,再将文件 eq_1_day_m1.geojson 复制到这个新建的文件夹中。地震规模通常是以里氏震级度量的,而这个文件记录了在(截至写作本节时)过去24 小时内全球发生的所有不低于 1 级的地震。
2. 查看 GeoJSON 数据
打开文件 eq_1_day_m1.geojson,我们发现内容密密麻麻,难以阅读:
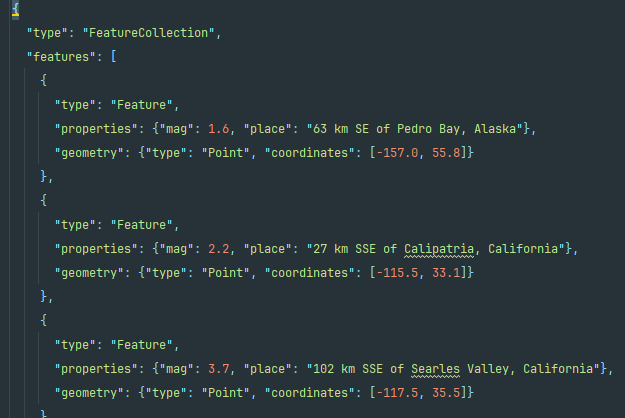
json 模块提供了探索和处理 JSON 数据的各种工具,其中一些有助于重新设置这个文件的格式,让我们能够更清楚地查看原始数据,继而决定如何以编程的方式处理它们。
python
from pathlib import Path
import json
# 将数据作为字符串读取并转换为 Python 对象
path = Path('eq_1_day_m1.geojson')
content = path.read_text()
all_eq_data = json.loads(content)
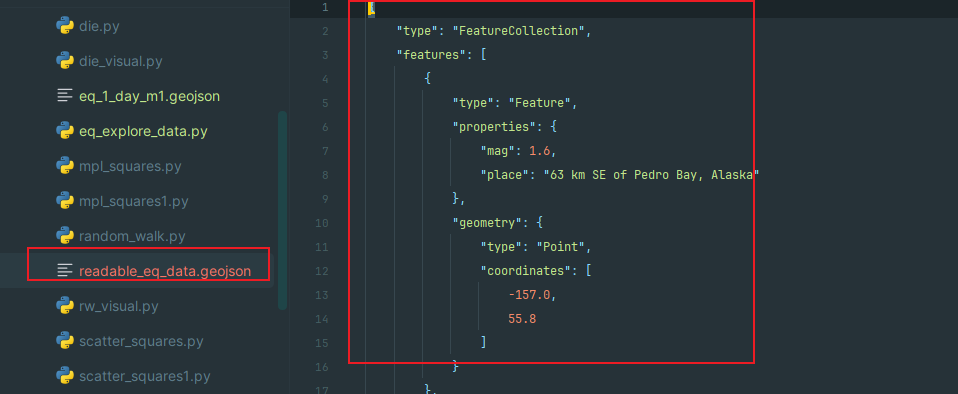
# 将数据文件转换为更易于阅读的版本
path = Path('readable_eq_data.geojson')
readable_contents = json.dumps(all_eq_data, indent=4)
path.write_text(readable_contents)readable_eq_data.geojson,将发现其开头部分像下面这样:
3. 创建地震列表
我们从字典 all_eq_data 中提取与键 'features' 相关联的数据,并将其赋给变量 all_eq_dicts。我们知道,这个文件记录了 160 次地震。下面的输出表明,我们提取了这个文件记录的所有地震:
python
from pathlib import Path
import json
# 将数据作为字符串读取并转换为 Python 对象
path = Path('eq_1_day_m1.geojson')
content = path.read_text()
all_eq_data = json.loads(content)
# 查看数据集中的所有地震
all_eq_dicts = all_eq_data['features']
print(len(all_eq_dicts))4. 提取震级
有了这个包含所有地震数据的列表,就可以遍历它,从中提取所需的数据了。下面来提取每次地震的震级:
python
from pathlib import Path
import json
# 将数据作为字符串读取并转换为 Python 对象
path = Path('eq_1_day_m1.geojson')
content = path.read_text()
all_eq_data = json.loads(content)
# 查看数据集中的所有地震
all_eq_dicts = all_eq_data['features']
mags = []
for eq_dict in all_eq_dicts:
mag = eq_dict['properties']['mag']
mags.append(mag)
print(mags[:10])运行结果截屏:

5. 提取位置数据
地震的位置数据存储在 "geometry" 键下。在 "geometry" 键关联的字典中,有一个 "coordinates" 键,它关联到一个列表,其中的前两个值为经度和纬度。下面演示了如何提取位置数据:
python
from pathlib import Path
import json
# 将数据作为字符串读取并转换为 Python 对象
path = Path('eq_1_day_m1.geojson')
content = path.read_text()
all_eq_data = json.loads(content)
# 查看数据集中的所有地震
all_eq_dicts = all_eq_data['features']
mags, titles, lons, lats = [], [], [], []
for eq_dict in all_eq_dicts:
mag = eq_dict['properties']['mag']
title = eq_dict['properties']['place']
lon = eq_dict['geometry']['coordinates'][0]
lat = eq_dict['geometry']['coordinates'][1]
mags.append(mag)
titles.append(title)
lons.append(lon)
lats.append(lat)
print(mags[:10])
print(titles[:2])
print(lons[:5])
print(lats[:5])运行结果如下:

6. 绘制地震散点图
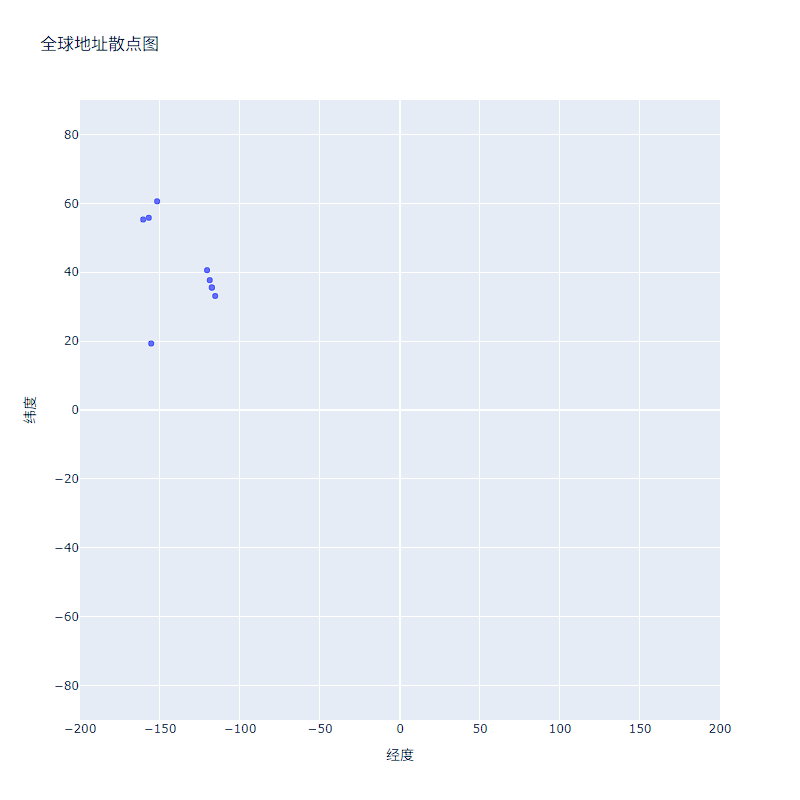
有了前面提取的数据,就可以绘制简单的散点图了。这个散点图谈不上美观,但这里只确保显示的信息正确无误就好,之后再专注于调整样式和外观。
python
from pathlib import Path
import json
import plotly.express as px
# 将数据作为字符串读取并转换为 Python 对象
path = Path('eq_1_day_m1.geojson')
content = path.read_text()
all_eq_data = json.loads(content)
# 查看数据集中的所有地震
all_eq_dicts = all_eq_data['features']
mags, titles, lons, lats = [], [], [], []
for eq_dict in all_eq_dicts:
mag = eq_dict['properties']['mag']
title = eq_dict['properties']['place']
lon = eq_dict['geometry']['coordinates'][0]
lat = eq_dict['geometry']['coordinates'][1]
mags.append(mag)
titles.append(title)
lons.append(lon)
lats.append(lat)
print(mags[:10])
print(titles[:2])
print(lons[:5])
print(lats[:5])
fig = px.scatter(
x=lons,
y=lats,
labels={'x': '经度', 'y': '纬度'},
range_x=[-200, 200],
range_y=[-90, 90],
width=800,
height=800,
title='全球地址散点图'
)
fig.write_html('eq_world_map.html')
fig.show()运行结果如下: