混合检索
定义
混合检索也叫多路召回或者融合检索,不仅限于向量检索和关键词检索的叠加。
比如同时从文档库和数据库检索,或者同时用多个不同的 Embedding 模型做向量检索,最后把结果融合起来,都算混合检索。
只不过在大模型 RAG 场景下,混合检索最常见的形态就是向量检索 + 关键词检索 。
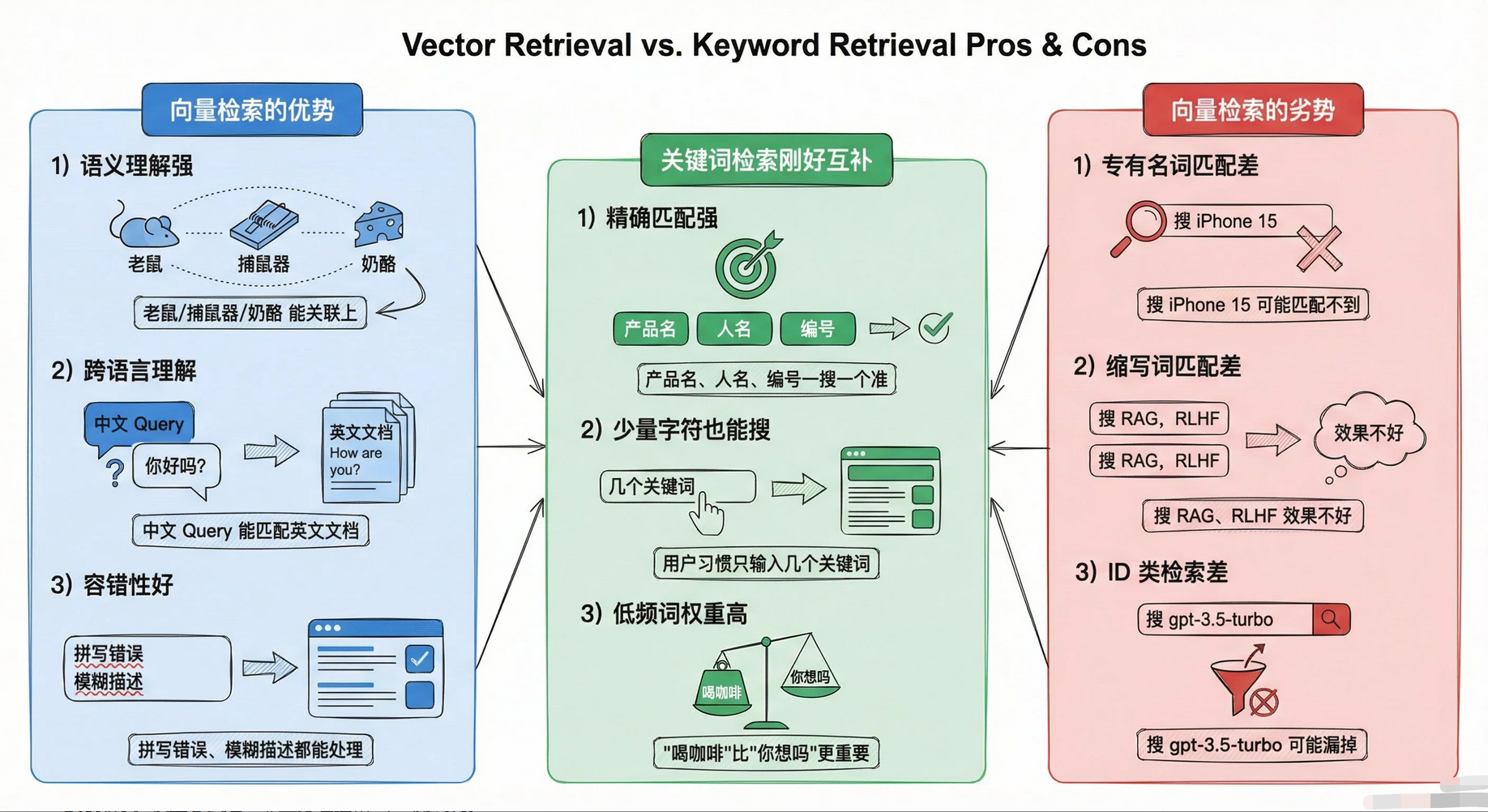
两种检索方式各有软肋:
● 向量检索:擅长语义理解,比如 "猫捕猎老鼠" 和 "猫追逐老鼠" 能匹配上;但难以精准匹配专有名词(如 "iPhone 15")。
● 关键词检索:精确匹配没问题,但理解不了语义,用户问 "怎么减肥",它匹配不到 "如何瘦身"。
混合检索就是两条路并行走:
- 分别执行向量检索和关键词检索
- 把两边的结果融合起来
- 用权重加权或者 RRF 算法重排序
- 取最优结果喂给大模型
实现方案
- Elasticsearch 8.0+ :原生支持
dense_vector字段和 knn 查询,可以在一个查询里同时做向量检索和关键词检索,用bool query组合结果。 - Milvus + 外部搜索引擎:Milvus 专门做向量检索,配合 Elasticsearch 做关键词检索,在应用层做结果融合。
- LlamaIndex / LangChain:这类框架封装了混合检索的能力,简单配置即可使用,适合快速搭建原型系统。
结果融合策略
两路检索的结果怎么合并是个技术活,常见做法有两种:
- 加权求和
给向量检索和关键词检索的分数分别乘以权重,加起来算总分。比如向量检索权重 0.7,关键词检索权重 0.3,最后按总分排序。
-
权重怎么定?没有万能的黄金比例,需要根据业务场景调:
-
- 文档里专有名词、ID 类查询多:关键词检索权重可调高到 0.4-0.5
-
- 主要是自然语言问答:向量检索权重可给到 0.7-0.8
-
调参技巧:准备一批有标注的测试集,跑不同权重组合,观察召回率和准确率的变化,找到最优点;线上还可以做 A/B 测试持续优化。
- RRF 算法(Reciprocal Rank Fusion)
不看分数只看排名,对每个文档计算1/(k+rank)(k 一般取 60),然后把两路的分数加起来。
-
- 好处:不用关心两路检索分数的量纲差异,直接用排名计算,避免了分数归一化的问题。
一些追问
1. 向量检索和关键词检索的权重一般怎么定?有什么调参技巧?
没有万能的黄金比例,得根据业务场景调:
- 文档里专有名词、ID 类查询多:关键词检索权重可调高到 0.4-0.5。
- 主要是自然语言问答:向量检索权重可给到 0.7-0.8。
- 调参技巧:准备一批有标注的测试集,跑不同权重组合,看召回率和准确率的变化,找到最优点;线上还可以做 A/B 测试持续优化。
2. 混合检索和 Rerank 是什么关系?能一起用吗?
能一起用,而且建议一起用:
- 混合检索解决的是召回阶段的问题,让召回的候选文档更全面。
- Rerank 解决的是精排阶段的问题,让最终送给大模型的文档更精准。
- 典型流程:向量检索召回 Top 50,关键词检索召回 Top 50,RRF 融合后取 Top 100,然后用 Rerank 模型精排,最后取 Top 5 喂给大模型。两者是互补关系,不是替代关系。
3. 如果关键词检索和向量检索的结果完全没有交集,怎么处理?
这种情况说明两路检索的视角差异很大,需要分情况处理:
- 如果用户 Query 明显是搜专有名词或 ID:关键词检索的结果更可信,可以给关键词检索更高权重甚至只用关键词检索的结果。
- **如果用户 Query 是自然语言问题:**向量检索的结果更可信。
- 进阶方案:做个简单的 Query 分类器,判断 Query 类型后动态调整两路的权重。