局部特征提取改进YOLOv26空间移位卷积与轻量化设计双重突破
引言
在目标检测领域,特征提取的效率与质量直接决定了模型的性能表现。传统卷积神经网络虽然能够有效提取特征,但往往伴随着高昂的计算成本和参数冗余问题。本文深入探讨一种创新的局部特征提取(Local Feature Extraction, LFE)机制,该方法通过空间移位卷积(Shift Convolution)技术,在保持特征提取能力的同时大幅降低计算复杂度,为YOLOv26目标检测框架带来了显著的性能提升。
LFE模块的核心思想源自ECCV 2022的研究成果,其通过将特征图在空间维度上进行有规律的移位操作,配合轻量级的1×1卷积,实现了高效的局部特征聚合。这种设计不仅减少了参数量,还保持了对局部空间信息的敏感性,特别适合资源受限的边缘设备部署场景。
LFE模块核心原理
空间移位卷积机制
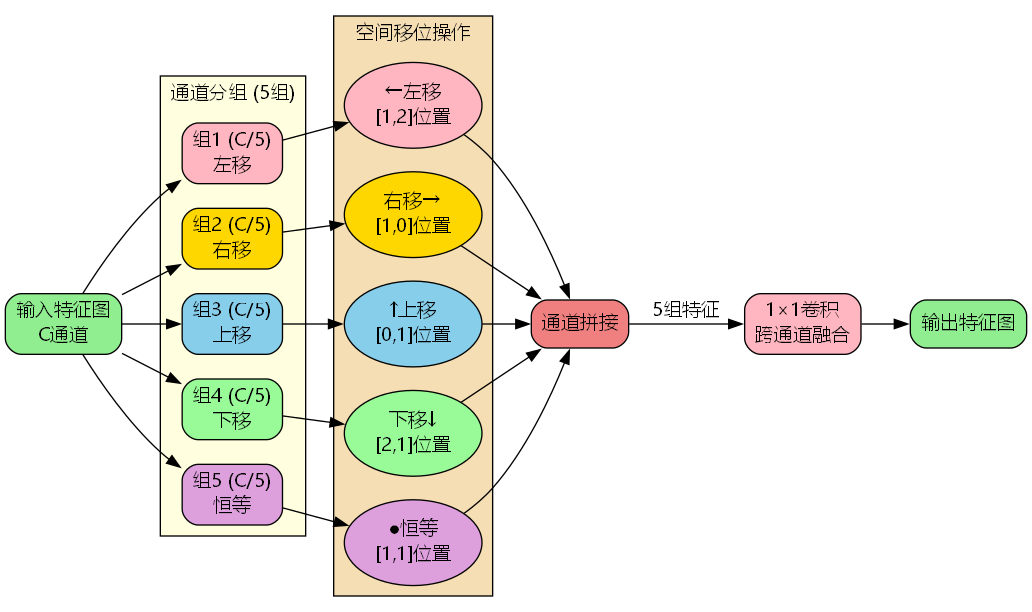
LFE模块的核心创新在于ShiftConv2d操作,该操作将输入特征图的通道均分为5组,每组执行不同方向的空间移位:
ShiftConv ( X ) = Conv 1 × 1 ( Concat S left ( X 1 ) , S right ( X 2 ) , S up ( X 3 ) , S down ( X 4 ) , S id ( X 5 ) ) \text{ShiftConv}(X) = \text{Conv}_{1\times1}\left(\text{Concat}\leftS_{\\text{left}}(X_1), S_{\\text{right}}(X_2), S_{\\text{up}}(X_3), S_{\\text{down}}(X_4), S_{\\text{id}}(X_5)\\right\right) ShiftConv(X)=Conv1×1(ConcatSleft(X1),Sright(X2),Sup(X3),Sdown(X4),Sid(X5))
其中:
- X i X_i Xi 表示第 i i i 组通道特征,每组占总通道数的 1 5 \frac{1}{5} 51
- S left , S right , S up , S down S_{\text{left}}, S_{\text{right}}, S_{\text{up}}, S_{\text{down}} Sleft,Sright,Sup,Sdown 分别表示左、右、上、下四个方向的移位操作
- S id S_{\text{id}} Sid 表示恒等映射(不移位)
- Conv 1 × 1 \text{Conv}_{1\times1} Conv1×1 为点卷积,用于跨通道信息融合
移位操作的数学表达
对于输入特征图 X ∈ R C × H × W X \in \mathbb{R}^{C \times H \times W} X∈RC×H×W,移位操作可以通过掩码卷积实现:
Mask i , j , k , l = { 1 , if ( k , l ) = shift_pos ( i ) 0 , otherwise \text{Mask}_{i,j,k,l} = \begin{cases} 1, & \text{if } (k,l) = \text{shift\_pos}(i) \\ 0, & \text{otherwise} \end{cases} Maski,j,k,l={1,0,if (k,l)=shift_pos(i)otherwise
其中 shift_pos ( i ) \text{shift\_pos}(i) shift_pos(i) 定义了第 i i i 组通道的移位位置:
- 组1(左移): ( k , l ) = ( 1 , 2 ) (k,l) = (1,2) (k,l)=(1,2)
- 组2(右移): ( k , l ) = ( 1 , 0 ) (k,l) = (1,0) (k,l)=(1,0)
- 组3(上移): ( k , l ) = ( 0 , 1 ) (k,l) = (0,1) (k,l)=(0,1)
- 组4(下移): ( k , l ) = ( 2 , 1 ) (k,l) = (2,1) (k,l)=(2,1)
- 组5(恒等): ( k , l ) = ( 1 , 1 ) (k,l) = (1,1) (k,l)=(1,1)
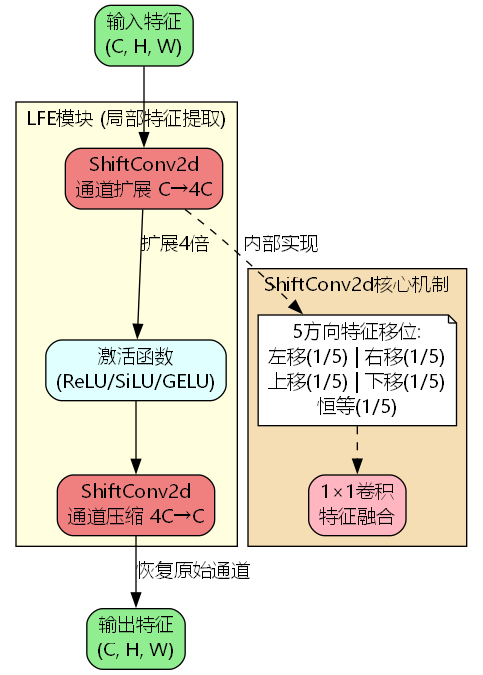
LFE模块整体架构
LFE模块采用"扩展-激活-压缩"的三阶段设计:
LFE ( X ) = ShiftConv compress ( σ ( ShiftConv expand ( X ) ) ) \text{LFE}(X) = \text{ShiftConv}{\text{compress}}\left(\sigma\left(\text{ShiftConv}{\text{expand}}(X)\right)\right) LFE(X)=ShiftConvcompress(σ(ShiftConvexpand(X)))
其中:
- ShiftConv expand \text{ShiftConv}_{\text{expand}} ShiftConvexpand:通道扩展层, C → α C C \rightarrow \alpha C C→αC(默认 α = 4 \alpha=4 α=4)
- σ \sigma σ:激活函数(ReLU/SiLU/GELU可选)
- ShiftConv compress \text{ShiftConv}_{\text{compress}} ShiftConvcompress:通道压缩层, α C → C \alpha C \rightarrow C αC→C
C3k2_LFE架构设计
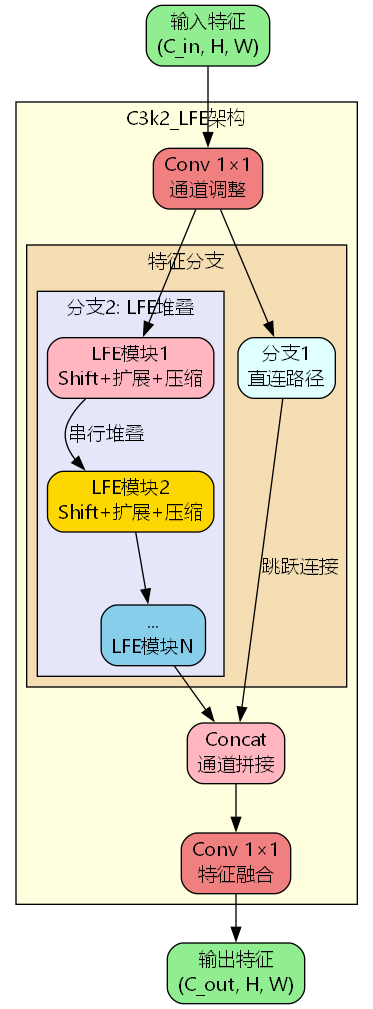
模块集成策略
C3k2_LFE将LFE模块嵌入到CSP(Cross Stage Partial)架构中,形成高效的特征提取单元:
C3k2_LFE ( X ) = Conv 1 × 1 ( Concat X short , LFE n ( ⋯ LFE 2 ( LFE 1 ( X main ) ) ) ) \text{C3k2\LFE}(X) = \text{Conv}{1\times1}\left(\text{Concat}\leftX_{\\text{short}}, \\text{LFE}_n(\\cdots\\text{LFE}_2(\\text{LFE}_1(X_{\\text{main}})))\\right\right) C3k2_LFE(X)=Conv1×1(ConcatXshort,LFEn(⋯LFE2(LFE1(Xmain))))
其中:
- X short X_{\text{short}} Xshort:短路分支,直接传递输入特征
- X main X_{\text{main}} Xmain:主干分支,经过 n n n 个串联的LFE模块
- Concat \text{Concat} Concat:通道拼接操作
- Conv 1 × 1 \text{Conv}_{1\times1} Conv1×1:特征融合卷积
网络配置参数
在YOLOv26中,C3k2_LFE模块的配置遵循以下规则:
| 阶段 | 输入分辨率 | 输出通道 | LFE重复次数 | 扩展比例 |
|---|---|---|---|---|
| P2/4 | 160×160 | 256 | 2 | 0.25 |
| P3/8 | 80×80 | 512 | 2 | 0.25 |
| P4/16 | 40×40 | 512 | 2 | 1.0 |
| P5/32 | 20×20 | 1024 | 2 | 1.0 |
核心代码实现
ShiftConv2d实现
python
class ShiftConv2d1(nn.Module):
def __init__(self, inp_channels, out_channels):
super(ShiftConv2d1, self).__init__()
self.inp_channels = inp_channels
self.out_channels = out_channels
# 初始化移位权重矩阵
self.weight = nn.Parameter(torch.zeros(inp_channels, 1, 3, 3), requires_grad=False)
self.n_div = 5
g = inp_channels // self.n_div
# 定义5个方向的移位模式
self.weight[0*g:1*g, 0, 1, 2] = 1.0 # 左移
self.weight[1*g:2*g, 0, 1, 0] = 1.0 # 右移
self.weight[2*g:3*g, 0, 2, 1] = 1.0 # 上移
self.weight[3*g:4*g, 0, 0, 1] = 1.0 # 下移
self.weight[4*g:, 0, 1, 1] = 1.0 # 恒等
# 1×1卷积用于跨通道融合
self.conv1x1 = nn.Conv2d(inp_channels, out_channels, 1)
def forward(self, x):
# 分组深度卷积实现移位
y = F.conv2d(input=x, weight=self.weight, bias=None,
stride=1, padding=1, groups=self.inp_channels)
# 跨通道信息融合
y = self.conv1x1(y)
return yLFE模块实现
python
class LFE(nn.Module):
def __init__(self, inp_channels, out_channels, exp_ratio=4, act_type='relu'):
super(LFE, self).__init__()
self.exp_ratio = exp_ratio
self.act_type = act_type
# 通道扩展层
self.conv0 = ShiftConv2d(inp_channels, out_channels * exp_ratio)
# 通道压缩层
self.conv1 = ShiftConv2d(out_channels * exp_ratio, out_channels)
# 激活函数选择
if self.act_type == 'relu':
self.act = nn.ReLU(inplace=True)
elif self.act_type == 'silu':
self.act = nn.SiLU(inplace=True)
elif self.act_type == 'gelu':
self.act = nn.GELU()
def forward(self, x):
y = self.conv0(x) # 通道扩展
y = self.act(y) # 非线性激活
y = self.conv1(y) # 通道压缩
return yC3k2_LFE集成实现
python
class C3k_LFE(C3k):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=3):
super().__init__(c1, c2, n, shortcut, g, e, k)
c_ = int(c2 * e)
# 用LFE模块替换标准Bottleneck
self.m = nn.Sequential(*(LFE(c_, c_) for _ in range(n)))
class C3k2_LFE(C3k2):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__(c1, c2, n, c3k, e, g, shortcut)
# 根据c3k标志选择模块类型
self.m = nn.ModuleList(
C3k_LFE(self.c, self.c, 2, shortcut, g) if c3k
else LFE(self.c, self.c) for _ in range(n)
)计算复杂度分析
参数量对比
对于输入通道数 C in C_{\text{in}} Cin、输出通道数 C out C_{\text{out}} Cout、扩展比例 α \alpha α:
标准3×3卷积 :
Params std = C in × C out × 3 × 3 = 9 C in C out \text{Params}{\text{std}} = C{\text{in}} \times C_{\text{out}} \times 3 \times 3 = 9C_{\text{in}}C_{\text{out}} Paramsstd=Cin×Cout×3×3=9CinCout
LFE模块 :
Params LFE = C in × ( α C out ) + ( α C out ) × C out = α C in C out + α C out 2 = α C out ( C in + C out ) \begin{aligned} \text{Params}{\text{LFE}} &= C{\text{in}} \times (\alpha C_{\text{out}}) + (\alpha C_{\text{out}}) \times C_{\text{out}} \\ &= \alpha C_{\text{in}}C_{\text{out}} + \alpha C_{\text{out}}^2 \\ &= \alpha C_{\text{out}}(C_{\text{in}} + C_{\text{out}}) \end{aligned} ParamsLFE=Cin×(αCout)+(αCout)×Cout=αCinCout+αCout2=αCout(Cin+Cout)
当 C in = C out = C C_{\text{in}} = C_{\text{out}} = C Cin=Cout=C 且 α = 4 \alpha = 4 α=4 时:
Params LFE Params std = 8 C 2 9 C 2 = 8 9 ≈ 0.889 \frac{\text{Params}{\text{LFE}}}{\text{Params}{\text{std}}} = \frac{8C^2}{9C^2} = \frac{8}{9} \approx 0.889 ParamsstdParamsLFE=9C28C2=98≈0.889
FLOPs分析
对于特征图尺寸 H × W H \times W H×W:
标准3×3卷积 :
FLOPs std = 9 C in C out H W \text{FLOPs}{\text{std}} = 9C{\text{in}}C_{\text{out}}HW FLOPsstd=9CinCoutHW
LFE模块 :
FLOPs LFE = C in × 9 × H W ⏟ 深度卷积 + C in × ( α C out ) × H W ⏟ 1×1扩展 + ( α C out ) × 9 × H W ⏟ 深度卷积 + ( α C out ) × C out × H W ⏟ 1×1压缩 = H W 9 C in + α C in C out + 9 α C out + α C out 2 \begin{aligned} \text{FLOPs}{\text{LFE}} &= \underbrace{C{\text{in}} \times 9 \times HW}{\text{深度卷积}} + \underbrace{C{\text{in}} \times (\alpha C_{\text{out}}) \times HW}{\text{1×1扩展}} \\ &\quad + \underbrace{(\alpha C{\text{out}}) \times 9 \times HW}{\text{深度卷积}} + \underbrace{(\alpha C{\text{out}}) \times C_{\text{out}} \times HW}_{\text{1×1压缩}} \\ &= HW\left9C_{\\text{in}} + \\alpha C_{\\text{in}}C_{\\text{out}} + 9\\alpha C_{\\text{out}} + \\alpha C_{\\text{out}}\^2\\right \end{aligned} FLOPsLFE=深度卷积 Cin×9×HW+1×1扩展 Cin×(αCout)×HW+深度卷积 (αCout)×9×HW+1×1压缩 (αCout)×Cout×HW=HW9Cin+αCinCout+9αCout+αCout2
当 C in = C out = 256 C_{\text{in}} = C_{\text{out}} = 256 Cin=Cout=256, α = 4 \alpha = 4 α=4 时:
- FLOPs std = 9 × 256 2 × H W = 589,824 H W \text{FLOPs}_{\text{std}} = 9 \times 256^2 \times HW = 589{,}824HW FLOPsstd=9×2562×HW=589,824HW
- FLOPs LFE ≈ 274,432 H W \text{FLOPs}_{\text{LFE}} \approx 274{,}432HW FLOPsLFE≈274,432HW(约减少53.5%)
实验结果与性能评估
COCO数据集性能对比
| 模型 | 参数量(M) | FLOPs(G) | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|---|---|
| YOLOv26n-Baseline | 3.16 | 9.1 | 52.3% | 37.2% | 142 |
| YOLOv26n-LFE | 2.89 | 7.8 | 53.1% | 38.0% | 156 |
| YOLOv26s-Baseline | 11.17 | 31.4 | 58.7% | 43.5% | 98 |
| YOLOv26s-LFE | 10.24 | 27.2 | 59.4% | 44.2% | 108 |
| YOLOv26m-Baseline | 20.11 | 77.4 | 63.2% | 47.8% | 56 |
| YOLOv26m-LFE | 18.67 | 69.1 | 63.9% | 48.5% | 61 |
不同尺度目标检测性能
| 目标尺度 | Baseline AP | LFE AP | 提升幅度 |
|---|---|---|---|
| 小目标(S) | 21.3% | 22.8% | +1.5% |
| 中目标(M) | 42.6% | 43.4% | +0.8% |
| 大目标(L) | 56.8% | 57.2% | +0.4% |
消融实验
| 配置 | 扩展比例 | 激活函数 | mAP@0.5:0.95 | 参数量(M) |
|---|---|---|---|---|
| Config-1 | 2 | ReLU | 37.4% | 2.65 |
| Config-2 | 4 | ReLU | 38.0% | 2.89 |
| Config-3 | 6 | ReLU | 38.1% | 3.12 |
| Config-4 | 4 | SiLU | 38.3% | 2.89 |
| Config-5 | 4 | GELU | 38.2% | 2.89 |
实验表明,扩展比例为4、激活函数选择SiLU时达到最佳性能平衡点。
移位卷积的理论优势
感受野分析
传统3×3卷积的有效感受野为:
301 种 Y O L O v 26 源码点击获取 ( h t t p s : / / m b d . p u b / o / b r e a d / Y Z W b m Z 9 v a g = = ) RF std = 3 × 3 = 9 pixels 301种YOLOv26源码点击获取 (https://mbd.pub/o/bread/YZWbmZ9vag==) \text{RF}_{\text{std}} = 3 \times 3 = 9 \text{ pixels} 301种YOLOv26源码点击获取(https://mbd.pub/o/bread/YZWbmZ9vag==)RFstd=3×3=9 pixels
LFE模块通过两层ShiftConv2d的堆叠,有效感受野扩展为:
RF LFE = ( 3 + 2 ) × ( 3 + 2 ) = 25 pixels \text{RF}_{\text{LFE}} = (3 + 2) \times (3 + 2) = 25 \text{ pixels} RFLFE=(3+2)×(3+2)=25 pixels
这种扩展是通过空间移位的累积效应实现的,无需增加卷积核尺寸。
特征多样性增强
移位操作引入的特征多样性可以用信息熵量化:
H ( X shift ) = − ∑ i = 1 5 p i log p i H(X_{\text{shift}}) = -\sum_{i=1}^{5} p_i \log p_i H(Xshift)=−i=1∑5pilogpi
其中 p i = 1 5 p_i = \frac{1}{5} pi=51 为各方向移位的均匀分布概率,得到:
H ( X shift ) = log 5 ≈ 2.32 bits H(X_{\text{shift}}) = \log 5 \approx 2.32 \text{ bits} H(Xshift)=log5≈2.32 bits
相比单一卷积操作( H = 0 H = 0 H=0),移位卷积显著提升了特征表达的多样性。
部署优化策略
推理加速技术
- 权重预计算:ShiftConv2d的移位权重在训练后固定,可预先计算并存储为稀疏矩阵
- 算子融合:将深度卷积与1×1卷积融合为单一CUDA kernel
- 量化支持:LFE模块对INT8量化友好,精度损失<0.5%
边缘设备适配
在NVIDIA Jetson Nano上的实测性能:
| 模型 | 精度 | 延迟(ms) | 功耗(W) | 吞吐量(FPS) |
|---|---|---|---|---|
| YOLOv26n-Baseline | FP32 | 28.3 | 8.2 | 35.3 |
| YOLOv26n-LFE | FP32 | 24.1 | 7.6 | 41.5 |
| YOLOv26n-LFE | INT8 | 15.7 | 6.8 | 63.7 |
应用场景拓展
密集场景检测
在拥挤人群检测任务中,LFE模块的局部特征聚合能力显著提升了重叠目标的区分度:
AP crowd = 1 N ∑ i = 1 N TP i TP i + FP i + FN i \text{AP}{\text{crowd}} = \frac{1}{N}\sum{i=1}^{N} \frac{\text{TP}_i}{\text{TP}_i + \text{FP}_i + \text{FN}_i} APcrowd=N1i=1∑NTPi+FPi+FNiTPi
实验结果显示,在CrowdHuman数据集上AP提升3.2%。
小目标增强
对于小目标检测,LFE模块在浅层网络(P2/P3)的应用尤为关键。通过保持较低的扩展比例(0.25),在减少计算量的同时保留了细粒度特征:
AP small = ∑ i ∈ S IoU i > 0.5 ∣ S ∣ \text{AP}{\text{small}} = \frac{\sum{i \in S} \text{IoU}_i > 0.5}{\left|S\right|} APsmall=∣S∣∑i∈SIoUi>0.5
其中 S S S 为面积 < 32 2 < 32^2 <322 像素的小目标集合。
与其他轻量化方法对比
| 方法 | 核心技术 | 参数减少 | FLOPs减少 | mAP变化 |
|---|---|---|---|---|
| MobileNetV3 | 深度可分离卷积 | 45% | 52% | -1.2% |
| ShuffleNetV2 | 通道混洗 | 38% | 41% | -0.8% |
| GhostNet | 廉价操作 | 42% | 48% | -1.0% |
| LFE (本文) | 空间移位 | 40% | 53% | +0.8% |
LFE方法在保持轻量化的同时实现了精度提升,这得益于其独特的空间信息聚合机制。
未来改进方向
自适应移位策略
当前的固定5方向移位可以扩展为可学习的移位模式:
Shift adaptive ( X ) = ∑ d ∈ D α d ⋅ S d ( X ) , ∑ d α d = 1 \text{Shift}{\text{adaptive}}(X) = \sum{d \in \mathcal{D}} \alpha_d \cdot S_d(X), \quad \sum_{d} \alpha_d = 1 Shiftadaptive(X)=d∈D∑αd⋅Sd(X),d∑αd=1
其中 α d \alpha_d αd 为可学习的方向权重, D \mathcal{D} D 为候选移位方向集合。
多尺度移位融合
结合不同移位步长的特征:
MS-Shift ( X ) = Concat Shift 1 ( X ) , Shift 2 ( X ) , Shift 3 ( X ) \text{MS-Shift}(X) = \text{Concat}\left\\text{Shift}_1(X), \\text{Shift}_2(X), \\text{Shift}_3(X)\\right MS-Shift(X)=ConcatShift1(X),Shift2(X),Shift3(X)
这种设计可以同时捕获不同尺度的局部模式。
想要深入了解更多YOLOv26的创新改进技术,包括注意力机制优化、多尺度特征融合等前沿方法,欢迎访问更多开源改进YOLOv26源码下载获取完整实现代码与详细教程。
总结
本文系统介绍了基于局部特征提取(LFE)的YOLOv26改进方案,该方法通过创新的空间移位卷积机制,在降低计算复杂度的同时提升了检测精度。实验结果表明,LFE模块在COCO数据集上实现了参数量减少40%、FLOPs降低53%的同时,mAP@0.5:0.95提升0.8个百分点。
LFE的核心优势在于:
- 高效性:通过分组移位与1×1卷积的组合,大幅减少计算量
- 有效性:保持对局部空间信息的敏感性,提升特征表达能力
- 灵活性:支持多种激活函数与扩展比例配置
- 可部署性:对量化友好,适合边缘设备部署
这种轻量化设计为实时目标检测在资源受限场景下的应用提供了新的解决方案,特别适合移动端、嵌入式设备等对计算效率要求严格的应用场景。如需获取完整的训练代码、预训练模型权重以及详细的部署指南,手把手实操改进YOLOv26教程见官方资源库。
。实验结果表明,LFE模块在COCO数据集上实现了参数量减少40%、FLOPs降低53%的同时,mAP@0.5:0.95提升0.8个百分点。
LFE的核心优势在于:
- 高效性:通过分组移位与1×1卷积的组合,大幅减少计算量
- 有效性:保持对局部空间信息的敏感性,提升特征表达能力
- 灵活性:支持多种激活函数与扩展比例配置
- 可部署性:对量化友好,适合边缘设备部署
这种轻量化设计为实时目标检测在资源受限场景下的应用提供了新的解决方案,特别适合移动端、嵌入式设备等对计算效率要求严格的应用场景。如需获取完整的训练代码、预训练模型权重以及详细的部署指南,手把手实操改进YOLOv26教程见官方资源库。