在人形机器人从实验室走向产业化的赛道上,英伟达GR00T N系列作为面向人形机器人的开源VLA基础模型,已成为物理 AI 领域的重要技术底座。
从2025年3月首款模型GR00T N1发布,到 2026 年 4 月 N1.7 以 Apache 2.0 许可全面开放商用。GR00T N系列围绕感知与推理能力、动作控制精度与流畅度、数据利用效率、跨本体与场景适配性持续迭代,逐步实现从基础能力验证到工业级实用化的跨越。
本文将按迭代顺序,逐一解析N1、N1.5、N1.6、N1.7的核心细节,帮助读者清晰把握这一演进脉络。
一、GR00T N1(2025.3):开启开源VLA新时代
2025年3月GTC开发者大会,英伟达推出全球首个开源、可定制的通用人形机器人VLA模型------GR00T N1,为整个系列奠定了"双系统协同"的核心架构。
1. 模型架构
GR00T N1采用"视觉-语言模块(系统2)+ 扩散Transformer模块(系统1)"的双系统架构,两大模块均基于Transformer构建,分工明确、紧密协同:
-
系统2(思考中枢):以Eagle-2 VLM为视觉-语言骨干,运行频率10Hz,负责处理视觉图像和语言指令,完成深度推理与任务规划,相当于人类的"大脑思考";
-
系统1(运动中枢):扩散Transformer(DiT),运行频率120Hz,采用流匹配(Flow Matching)技术快速生成动作指令,相当于人类的"身体执行"。
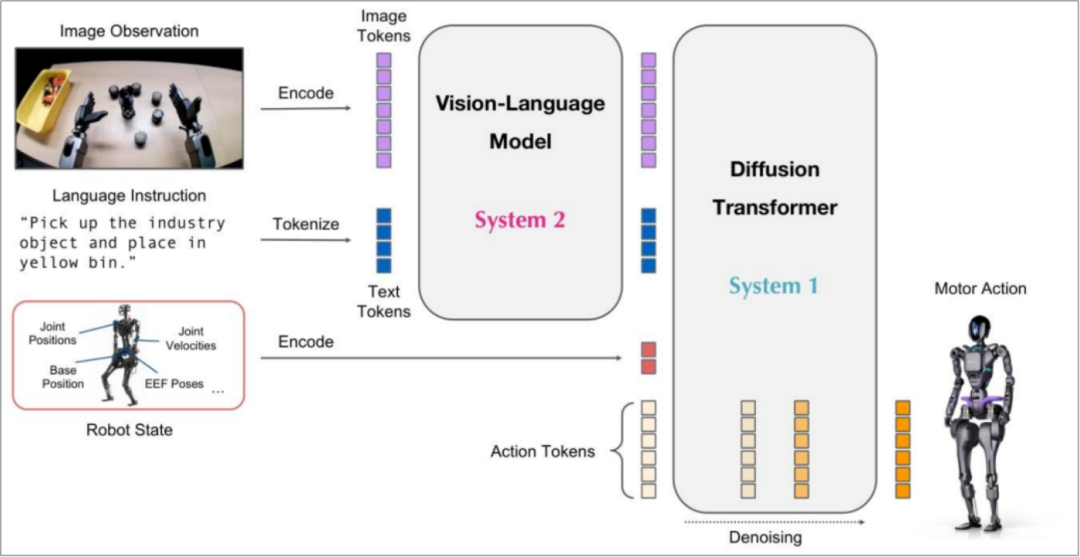
GR00T N1模型架构 简化版(来源:英伟达论文)
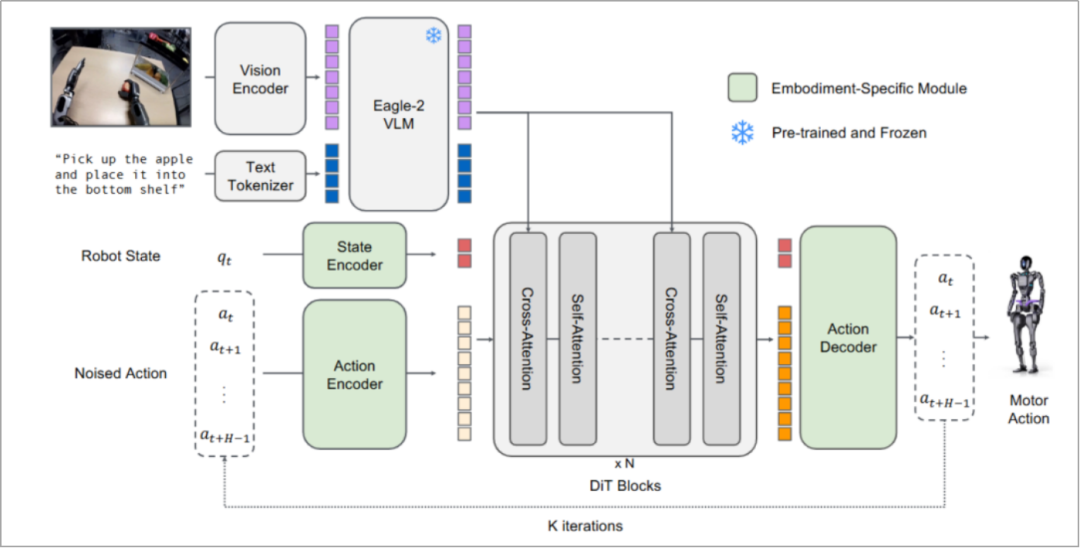
GR00T N1模型架构 详情版(来源:英伟达论文)
公开版本GR00T-N1-2B总参数达22亿,其中VLM占13.4亿参数,双模块端到端联合训练,实现推理与动作的高效协同。
模型的输入输出:
-
****输入:****RGB图像帧(固定分辨率)、机器人本体状态(关节位置、速度等)、自然语言指令。
-
****输出:****绝对关节角度或末端执行器位置为核心的连续动作向量。
2. 模型训练
****1)训练配置与方法:****N1 采用双系统端到端联合训练,以 Flow Matching 流匹配 为核心训练目标,使用 BF16 混合精度 完成训练。模型基于 Eagle-2 VLM + DiT 架构联合优化,实现感知、推理与动作生成的一体化学习,奠定系列基础训练范式。
2) 训练数据: N1 采用英伟达官方数据金字塔异构混合数据体系:以互联网人类视频、网页图文数据为底座,以 Omniverse 生成的仿真合成数据为中层扩充,辅以少量真实机器人遥操作数据做顶层对齐,整体以通用数据为主、真实数据为辅,用于验证基础感知--动作能力。
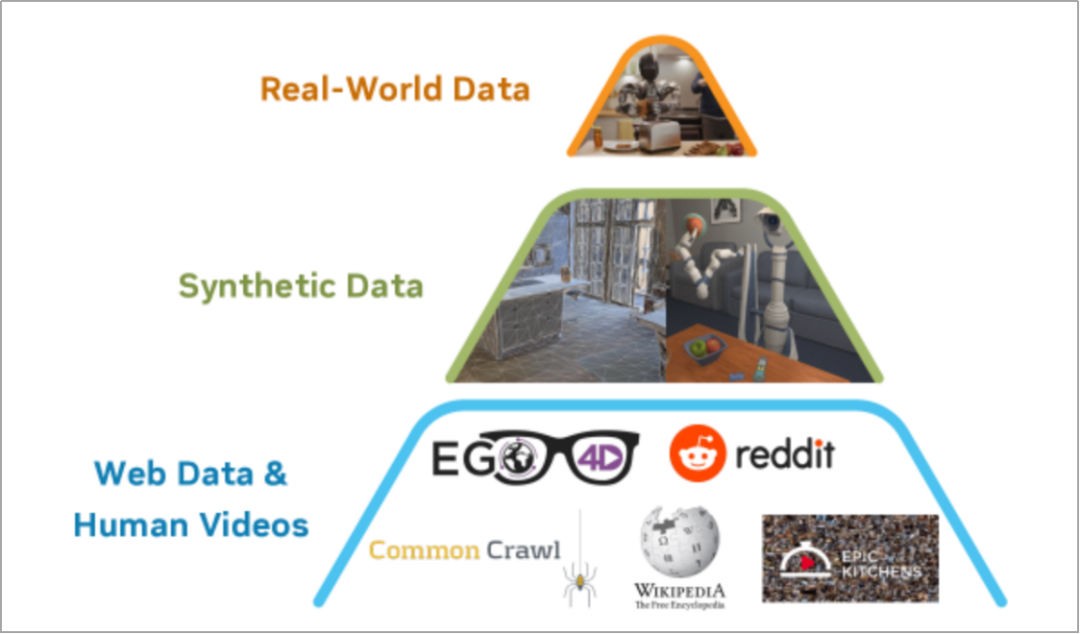
数据金字塔****(来源:英伟达论文)****
3. 核心特点
-
****开创性:****英伟达全球首个开源、通用、完全可定制的人形机器人VLA 基础模型,奠定双系统架构与跨机器人泛化能力。
-
****生态初建:****1X Technologies、Agility Robotics、傅利叶等已率先接入。
-
****局限性:****语言指令跟随准确率仅约46.6%,泛化能力弱,对新物体、新场景适配性不足。
二、GR00T N1.5(2025.6):泛化与效率双提升
继N1之后,英伟达于2025年5月在台北电脑展正式发布GR00T N1.5,6月11日完成开源并上线技术博客。作为初代迭代版,N1.5并未改变双系统核心架构,而是聚焦"优化细节、提升泛化",解决N1在语言跟随、数据利用效率上的不足。
1. 架构优化
N1.5延续双系统设计,但在细节上做了关键改进:
****1)VLM升级:****将Eagle-2升级为Eagle 2.5,视觉定位能力和物理理解能力提升,在GR-1定位任务中IoU达40.4,优于Qwen2.5VL的35.5;
****2)冻结VLM:****预训练和微调阶段均冻结VLM,防止动作训练破坏语言理解能力,提升模型泛化性;
****3)适配器简化:****简化视觉编码器与LLM之间的MLP适配器;同时为输入 LLM 的视觉、文本两路 token 嵌入统一添加层归一化,解决了多模态特征分布不一致导致的训练不稳定问题。
4)新技术集成:
-
FLARE(未来潜在表示对齐):从动作去噪网络的隐藏状态中预测机器人未来观测的紧凑表示,解锁了从人类视频中学习的能力。
-
DreamGen:通过视频世界模型生成合成神经轨迹数据,提升数据效率。
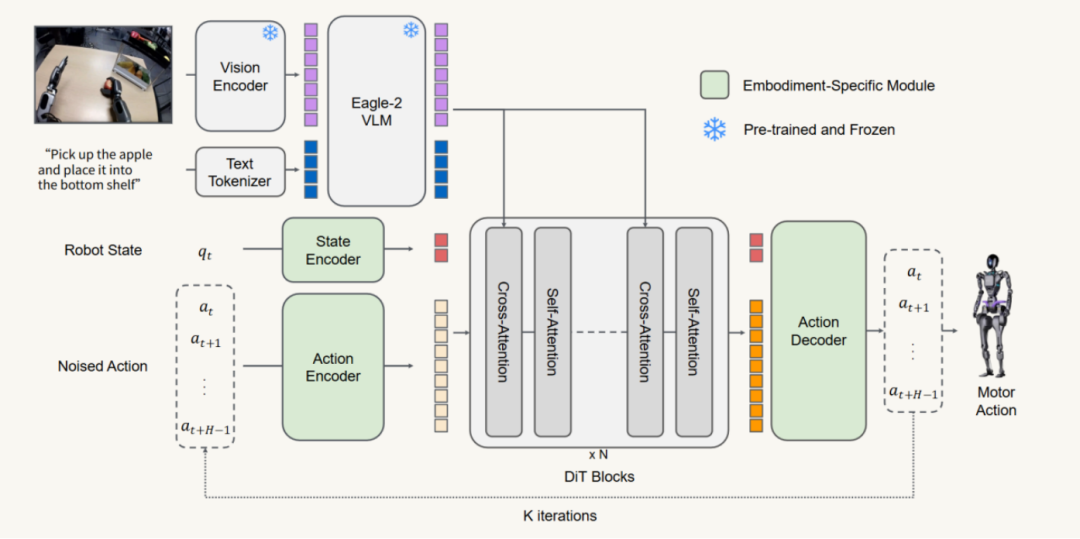
GR00T N1.5模型架构 (来源:英伟达)
模型输入输出:
-
**输入:**支持可变数量的224×224图像帧(uint8),本体状态可通过padding适配不同维度。
-
**输出:**120Hz端到端连续动作,支持零样本/小样本微调。
2. 模型训练
****1) 训练配置与方法:****N1.5 在 1000 块 H100 GPU 上完成 250K 步预训练,全局批次大小 16384,采用 AdamW 优化器与余弦学习率调度。训练新增 FLARE(未来潜在表示对齐) 目标,与流匹配损失联合训练,使模型能够从无动作标签的人类视频中学习,显著提升数据利用效率。
****2)训练数据:****N1.5 延续 N1 的异构数据混合体系,预训练数据采用精确五分类分布:真实 GR-1 遥操作数据 27.3%、OpenXE 公开机械臂数据 27.3%、Sim GR-1 仿真数据 27.3%、AgiBot-Beta 数据 9.1%、DreamGen 合成神经轨迹数据 9.1%。
其中核心新增:
-
DreamGen 合成数据:通过四步流水线自动生成合成机器人轨迹,突破真实遥操作数据的边界,使模型能够泛化到预训练中从未见过的新动词与新任务(在12个全新动词任务上成功率达 38.3%,远超 N1 的 13.1%);
-
AgiBot-Beta 多本体数据:补充了不同人形机器人的动作数据,为跨本体迁移能力奠定基础。
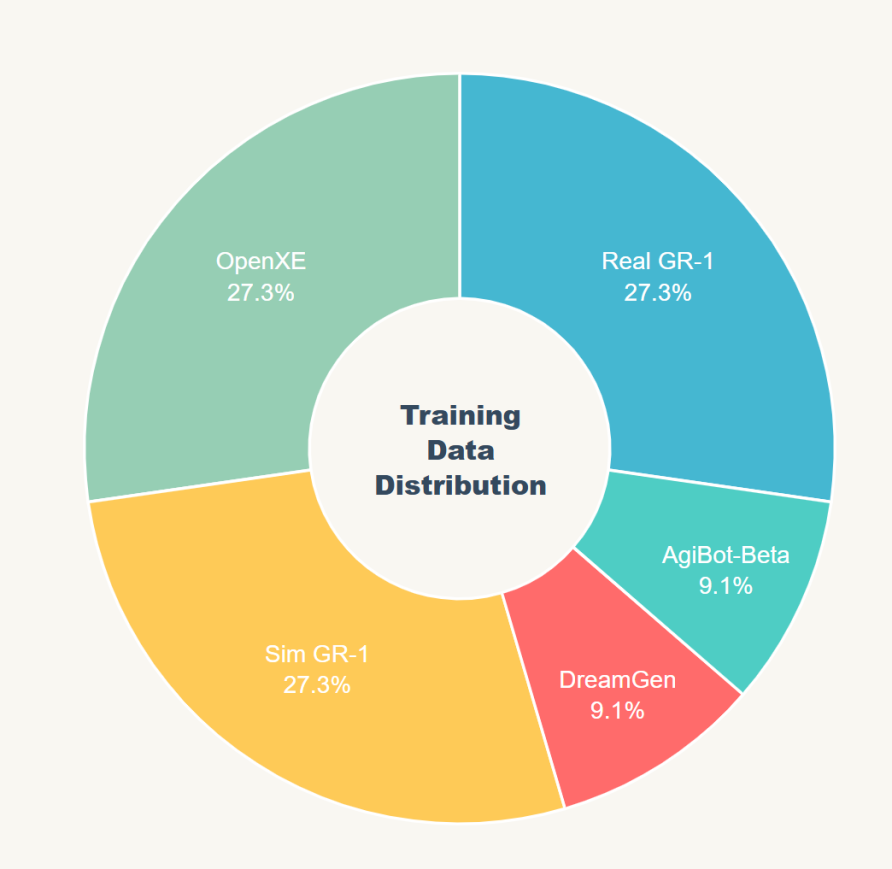
GR00T N1.5预训练所使用数据分布(来源:英伟达)********
3. 核心特点
N1.5是N1 的迭代升级版本,在开源、通用、可定制基础上,实现语言跟随、泛化性、数据效率、部署能力全面提升。
-
****语言跟随能力增强:****语言跟随准确率从N1的46.6%提升至93.3%;
-
****泛化能力增强:****支持从人类第一视角视频学习,新物体零样本泛化成功率结合FLARE后达55%;
-
****跨机器人迁移能力显著:****在宇树G1上微调后成功率达98.8%;
-
部署灵活:提供PyTorch与TensorRT推理脚本,支持Ampere至Blackwell全系列GPU及Jetson边缘端部署;
-
****局限性:****DiT仅16层,复杂动作建模能力有限,仍以绝对动作输出为主。
三、GR00T N1.6(2025.12):精度与流畅度双突破
2025年12月15日,英伟达正式发布GR00T N1.6。通过VLM升级、DiT扩容、动作范式调整,实现了性能的提升,在双手YAM、Agibot Genie-1、Unitree G1等特定真实机器人场景中表现优于N1.5。
1. 架构革新
N1.6实现了"感知+动作"双重升级 ,关键改进包括:
1)VLM升级:采用英伟达内部Cosmos-Reason-2B VLM变体(Eagle-Block2A-2B-v2),支持原生宽高比编码图像,无需填充(Padding),避免视觉信息扭曲,同时在通用视觉语言任务与具身推理任务(如下一步动作预测)上联合训练,感知能力显著提升;
2)DiT扩容:DiT层数从16层翻倍至32层,提升复杂动作轨迹建模能力,可应对叠衣服、插拔GPU导轨等高精度任务;
3)取消适配器:移除N1.5 中VLM 与DiT 间的 4 层 Transformer 适配器,改为预训练阶段解冻 VLM 顶部 4 层参数协同训练,弱化转接模块、降低跨模态特征损耗,强化视觉 - 动作原生联动。
4)动作范式调整 :引入状态相对动作块预测,替代绝对关节角度或末端执行器位置,减少电机突兀震动,提升动作平滑度,同时引入闭环反馈机制,每步动作生成都基于当前机器人真实状态修正,解决相对动作的误差累积问题。
模型输入输出:
-
****输入:****图像帧最短边缩放至256,支持原生宽高比,无需padding;Sin-Cos状态编码增强,优化本体感知,支持多视角图像联合输入。
-
****输出:****状态相对动作块,动作轨迹更平滑,减少电机突兀震动,可适配不同本体的机器人(如智元Genie-1、宇树G1)。
2. 模型训练
1)训练配置与方法:GR00T N1.6 预训练共计 300K 步 ,全局批次大小为16384 ,采用BF16 + 可训练 FP32 混合精度 训练。训练策略上解冻VLM 顶部 4 层 与动作模块联合训练,动作空间默认使用状态相对动作块 。下游任务后训练通常为10K--30K 步 ,全局批次大小控制在1K 及以下 ,并通过状态正则、数据增强、DAgger、RTC 实时控制等工程技巧提升模型收敛速度、动作平滑度与泛化稳定性。
2)训练数据:在 N1.5 数据混合基础上,GR00T N1.6 预训练新增数千小时真实机器人遥操作数据 ,涵盖YAM 双臂、Agibot Genie1、Unitree G1 全身移动操作 以及BEHAVIOR 仿真环境(Galaxea R1 Pro) 数据。官方数据分布中,仿真BEHAVIOR、真实智元机器人、真实 YAM 双臂 各占约 22.0%,为核心训练来源;其余数据包括仿真GR1(11.0%)、RoboCasa、真实 GR1、真实 Unitree G1、Language Table 与 DROID 等,整体数据真实度与场景多样性显著提升。
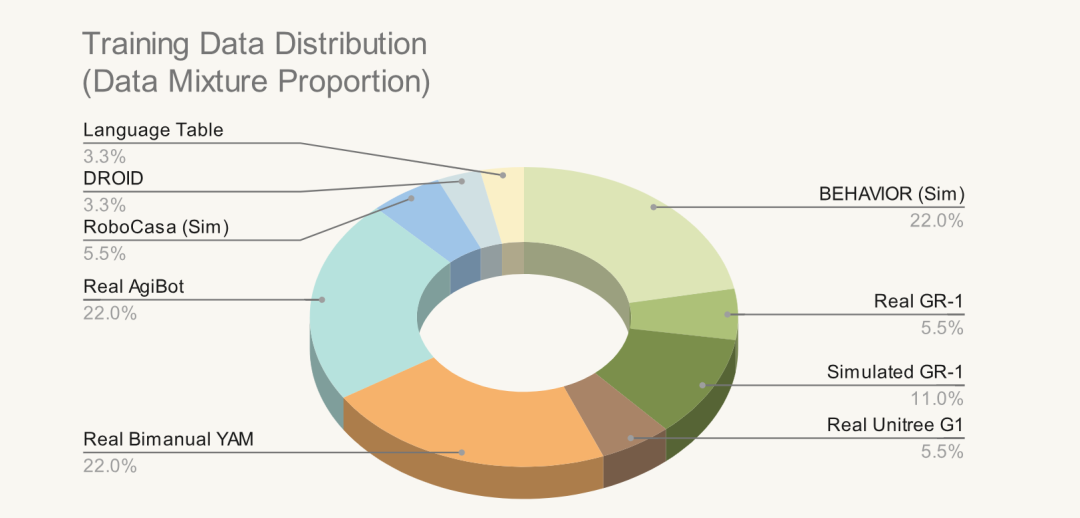
GR00T N1.6预训练所使用数据分布(来源:英伟达)****
3. 核心特点
GR00T N1.6 依托架构革新与工程化优化,在真实机器人场景实现全面性能突破,核心优势集中体现为更强的感知能力、更精准流畅的动作控制与更友好的落地适配性。
-
感知升级:原生宽高比图像输入,具身推理能力增强,可应对高精度操作任务。
-
动作优化:32层DiT可建模复杂动作轨迹;相对动作输出提升流畅度与机器人适配性,支持双手协作、全身移动操作。
-
工程友好:提供完善的微调、推理脚本,支持多种学术仿真基准测试。
四、GR00T N1.7(2026.4):商业就绪,开启灵巧操作新时代
2026年4月,英伟达发布GR00T N1.7(EA)------首个全面开放商业授权的人形机器人VLA模型,采用Apache 2.0许可证,源代码和模型权重均可商用,核心突破是"灵巧性提升"与"商业落地适配",标志着GR00T N系列从"开源可用"正式走向"产业实用"。
1. 架构升级
N1.7采用"动作级联双系统"(Action Cascade)设计,延续VLA定位,但将高级推理与低级运动控制进行分离,协同效率大幅提升:
-
系统2(推理层):采用Cosmos-Reason2-2B骨干网络(基于Qwen3-VL定制),负责任务分解与多步骤推理,截取至第12层输出以减少计算量,具备更强的物理世界理解和时空推理能力,支持256K token长上下文窗口;
-
系统1(控制层):保持32 层 DiT 结构,采用Flow Matching+DiT架构,负责生成精准实时运动指令并通过去噪优化动作准确性;依托流匹配优势,仅需 4 步去噪即可输出高质量动作,远快于传统 DDPM 所需的 50--1000 步,推理效率与实时性大幅提升。
特色设计:
-
AlternateVLDiT:默认启用图像/语言分离交叉注意力机制,让模型交替关注图像token和文本token,避免信息稀释。
-
多本体适配:通过CategorySpecificMLP为最多32种不同机器人本体维护独立编码/解码器权重,共享DiT核心和VLM Backbone。
模型输入输出:
-
****输入:****RGB图像帧(任意分辨率)、自然语言指令、机器人本体感受状态(关节位置、速度、末端执行器位姿)。
-
输出:映射到机器人自由度的连续动作向量,支持手指级控制,可直接对接工业机器人控制系统,支持RTC实时控制推理。
2. 模型训练
N1.7引入EgoScale数据集------20854小时人类第一视角视频,涵盖9869个场景、6015项任务、43237种物体,规模较前代扩大20倍以上。采集方式包括头戴Ego相机、腕部相机、22-DoF手部关节标注、6-DoF腕部位姿。
训练采用"预训练-中间训练-后训练"三阶策略:++++预训练基于EgoScale数据,中间训练使用人类-机器人配对数据适配机器人空间,后训练针对具体任务微调,大幅降低对大规模真机遥操作数据的依赖。++++
英伟达通过研究发现首个机器人灵巧性缩放定律:人类第一视角视频数据量与机器人灵巧操作性能呈对数线性关系(R²=0.9983),数据量越多,模型性能可预测提升。
3. 核心特点
N1.7的核心价值的是"商业落地"与"灵巧突破":
-
商业就绪:采用Apache 2.0商业许可,源代码和模型权重可自由用于商业产品、训练衍生模型及修改分发,扫清企业部署的法律障碍;
-
灵巧性突破:支持手指级精细操作,可完成可完成注射器抽液、拧开瓶盖、折叠衬衫等接触密集型任务;
-
泛化性提升 :依托EgoScale数据,新环境、新物体适应能力显著增强,语言跟随精度进一步优化;
-
部署便捷:兼容LeRobot数据集格式,支持从N1.6即插即用升级,适配Ampere至Blackwell系列GPU及Jetson边缘平台。
结语
从N1的开创性奠基,到N1.5的冻结VLM策略让语言跟随准确率翻倍,再到N1.6的DiT翻倍与相对动作范式革新,最终N1.7以2万小时人类视频数据+Apache 2.0商业许可实现工业级落地------英伟达GR00T N系列用不到一年半的时间,将人形机器人的"大脑"从实验室原型推向了工业级商用落地阶段。
随着开源与商业授权的全面开放,GR00T系列有望成为机器人时代的"安卓",构建起从模型、工具链到芯片的完整开发生态。人形机器人的未来,正在加速到来。