文章目录
- [1. 栈的静态模拟实现](#1. 栈的静态模拟实现)
- [1.0 栈的概念(防止有些人忘记了~)](#1.0 栈的概念(防止有些人忘记了~))
- [1.1 创建](#1.1 创建)
- [1.2 进栈](#1.2 进栈)
- [1.3 出栈](#1.3 出栈)
- [1.4 查询栈顶元素](#1.4 查询栈顶元素)
- [1.5 判空](#1.5 判空)
- [1.6 有效元素的个数](#1.6 有效元素的个数)
- 2.队列的静态实现
- [2.0 队列的概念](#2.0 队列的概念)
- [2.1 创建](#2.1 创建)
- [2.2 入队](#2.2 入队)
- [2.3 出队](#2.3 出队)
- [2.4 队头](#2.4 队头)
- [2.5 队尾](#2.5 队尾)
- [2.6 判空](#2.6 判空)
- [2.7 元素个数](#2.7 元素个数)
- [3. 树(这里的树表示的是非特殊的树哈)](#3. 树(这里的树表示的是非特殊的树哈))
- [3.1 树的定义](#3.1 树的定义)
- [3.2 树的基本术语](#3.2 树的基本术语)
- [3.3 有序树和无序树](#3.3 有序树和无序树)
- [3.4 有根树和无根树](#3.4 有根树和无根树)
- [3.5 树的存储](#3.5 树的存储)
- [3.5.1 孩⼦表⽰法](#3.5.1 孩⼦表⽰法)
- [3.5.2 实现⽅式⼀:⽤ vector 数组实现](#3.5.2 实现⽅式⼀:⽤ vector 数组实现)
- [3.5.3 实现⽅式⼆:链式前向星](#3.5.3 实现⽅式⼆:链式前向星)
- [3.5.4 关于 vector 数组以及链式前向星:](#3.5.4 关于 vector 数组以及链式前向星:)
- [3.6 树的遍历](#3.6 树的遍历)
- [3.6.1 深度优先遍历 - DFS](#3.6.1 深度优先遍历 - DFS)
- [3.6.2 宽度优先遍历 - BFS](#3.6.2 宽度优先遍历 - BFS)
1. 栈的静态模拟实现
1.0 栈的概念(防止有些人忘记了~)
栈是一种只允许在一端进行数据插入和删除操作的线性表。
- 进行数据插入或删除的一端称为栈顶 ,另一端称为栈底 。不含元素的栈称为空栈。
- 进栈 就是往栈中放入元素,出栈就是将元素弹出栈顶。
栈其实是一个比较简单的数据结构。学习的重点在于用栈去解决问题,这也是难点。
【注意】
如果定义了一个栈结构,那么添加和删除元素只能在栈顶进行。不能随意位置添加和删除元素,这是栈这个数据结构的特性,也是规定。
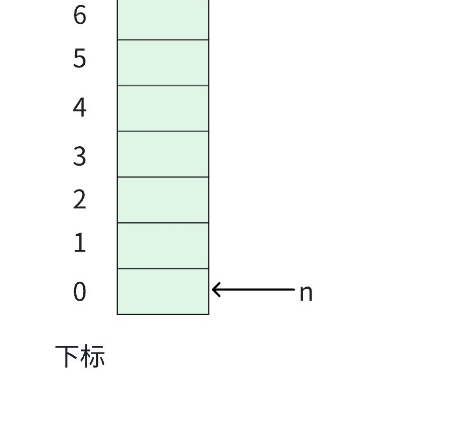
1.1 创建
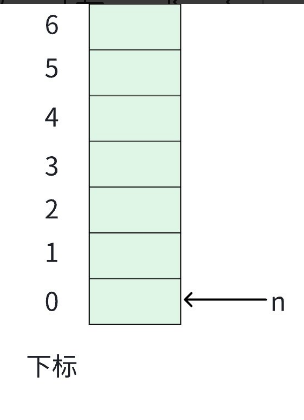
- 本质还是线性表,因此可以创建一个足够大的数组,充当栈结构
- 再定义一个变量
n,用来记录栈中元素的个数,同时还可以标记栈顶的位置。
cpp
const int N = 1e6 + 10;
int n;
int stk[N];1.2 进栈
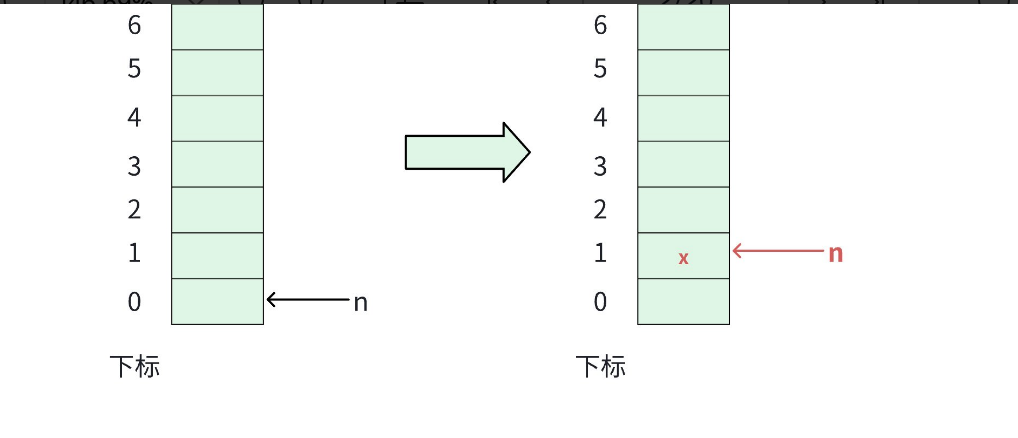
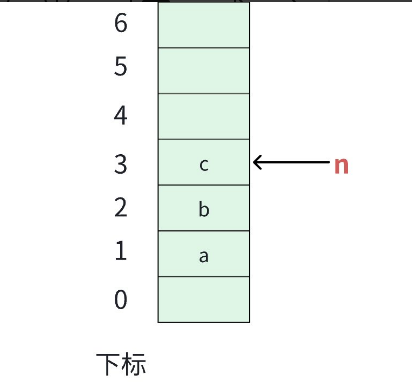
这里依旧舍弃下标为 0 的位置,有效元素从 1 开始记录。
进栈操作,那就把元素放在栈顶位置即可。
cpp
// 进栈
void push(int x)
{
stk[++n] = x;
}1.3 出栈
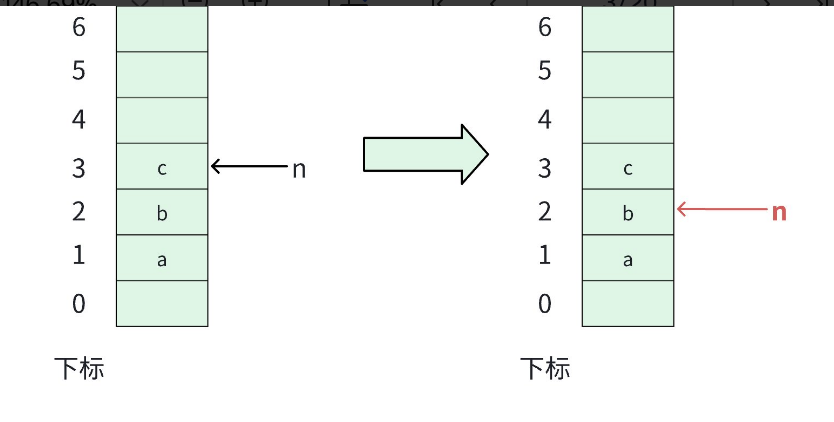
不⽤真的删除元素,只⽤将元素个数减 1 ,就相当于删除栈顶元素。本质就是个"障眼法"。栈只认栈顶指针,把指针下移1位,旧数据虽然还留着,但已经"看不见"了,等于被逻辑删除了。下次入栈直接覆盖,省时省力。
cpp
// 出栈
void pop()
{
n--;
}1.4 查询栈顶元素
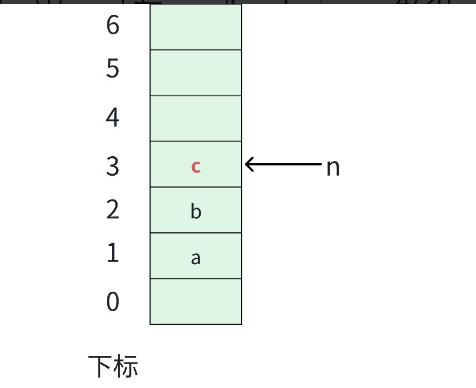
查询栈顶元素。
这里要注意,因为栈特殊的规定,不支持遍历整个栈中的元素。因此,需要查找栈中元素的时候,只能查找到栈顶元素。
cpp
// 栈顶元素
int top()
{
return stk[n];
}1.5 判空
cpp
// 判空
bool empty()
{
return n == 0;
}1.6 有效元素的个数
cpp
// 栈中元素个数
int size()
{
return n;
}2.队列的静态实现
2.0 队列的概念
队列也是一种访问受限的线性表,它只允许在表的一端进行插入操作,在另一端进行删除操作。
- 允许插入的一端称为队尾 ,允许删除的一端称为队头。
- 先进入队列的元素会先出队,故队列具有先进先出 (First In First Out) 的特性。
2.1 创建
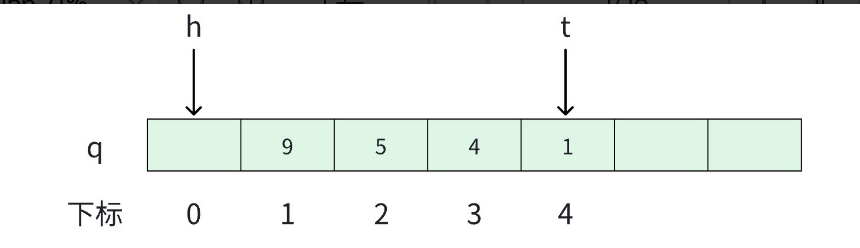
- 一个足够大的数组充当队列;
- 一个变量
h标记队头元素的前一个位置; - 一个变量
t标记队尾元素的位置。
两个变量(h, t]是一种左开右闭的形式,这样设定纯属个人喜好,因为后续的代码写着比较舒服。
当然,也可以h标记队头元素的位置。只要能控制住代码不出现bug,想怎么实现就怎么实现。
cpp
const int N = 1e6 + 10;
int h, t; // 队头指针,队尾指针
int q[N]; // 队列2.2 入队
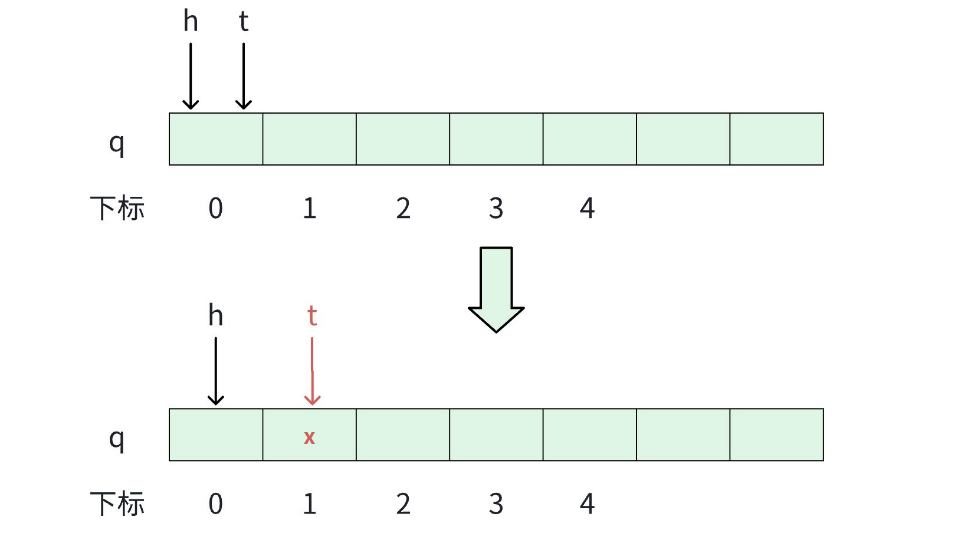
- 将 x 这个元素放入到队列中。
注意,我们这里依旧从下标为 1 的位置开始存储有效元素。
cpp
// ⼊队
void push(int x)
{
q[++t] = x;
}2.3 出队
- 删除队头元素。
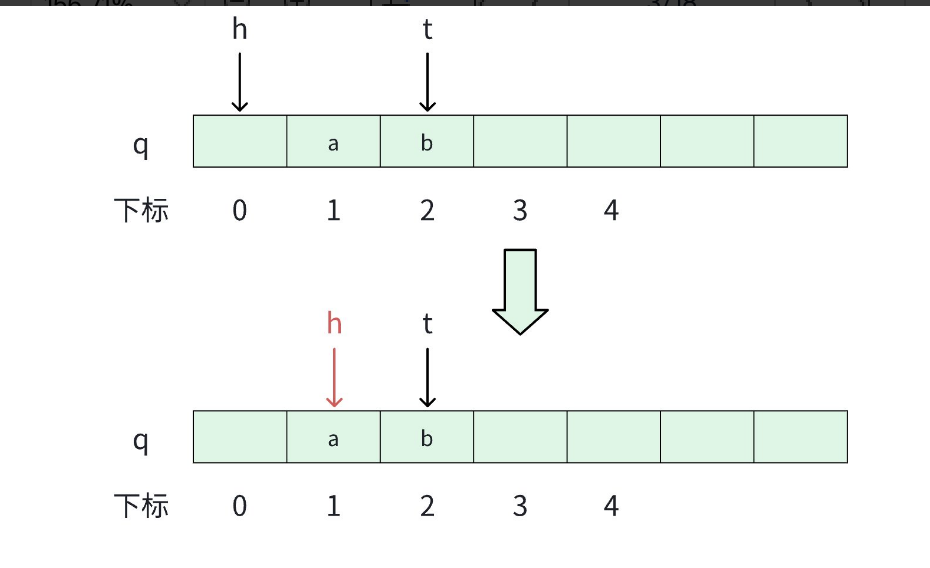
cpp
// 出队
void pop()
{
h++;
}2.4 队头
返回队列里面的第一个元素。
这里要注意,不是 h 所指的位置,而是 h 所指的下一个位置。
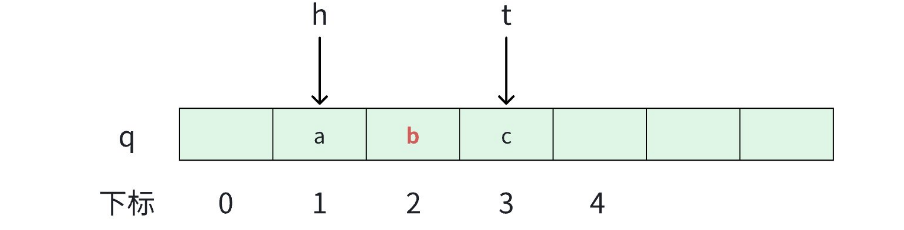
cpp
// 队头元素
int front()
{
return q[h + 1];
}2.5 队尾
返回队列⾥⾯的最后⼀个元素
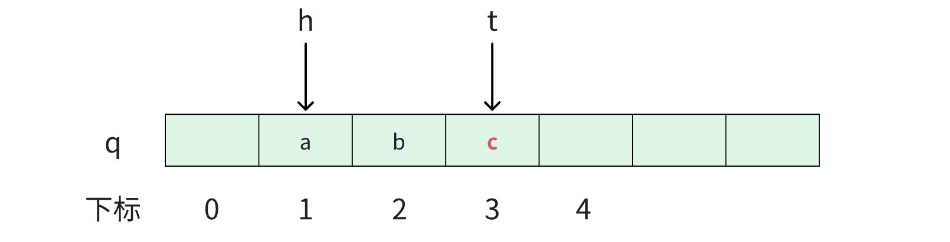
cpp
// 队尾元素
int back()
{
return q[t];
}2.6 判空
根据h和t是否相等来判断队列是否为空。
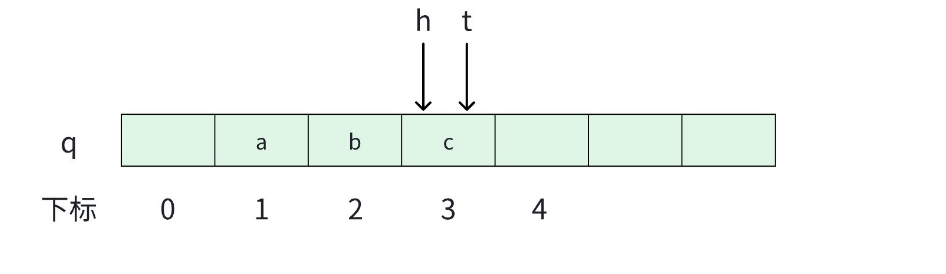
cpp
// 队列是否为空
bool empty()
{
return t == h;
}2.7 元素个数
直接t-h 即可!
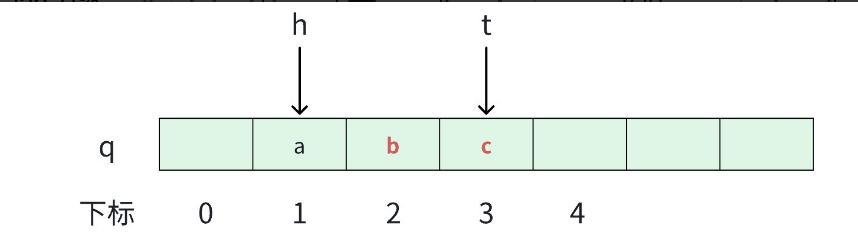
cpp
// 队列的⼤⼩
int size()
{
return t - h;
}3. 树(这里的树表示的是非特殊的树哈)
3.1 树的定义
树型结构是一类重要的非线性数据结构。
- 有一个特殊的结点,称为根结点,根结点没有前驱结点。
- 除根结点外,其余结点被分成 (M) 个互不相交的集合 (T_1、T_2、...、T_m),其中每一个集合 (T) 又是一棵树,称这棵树为根节点的子树。
因此,树是递归定义的。
3.2 树的基本术语
- 结点的度:树中一个结点孩子的个数称为该结点的度。
- 树的度:树中结点最大的度数称为树的度。
- 树的高度(深度):树中结点的最大层数称为树的高度(深度)。
- 路径:树中两个结点之间的路径是由这两个结点之间所经过的结点序列构成的,路径长度为序列中边的个数。
3.3 有序树和无序树
- 有序树:结点的子树按照从左往右的顺序排列,不能更改。
- 无序树:结点的子树之间没有顺序,随意更改。(算法竞赛基本都是这树)
这个认知会在后续学习二叉树时用到,因为二叉树需要区分左右孩子。
3.4 有根树和无根树
- 有根树:树的根节点已知,是固定的。
- 无根树:树的根节点未知,任何结点都可以作为根结点。
此认知主要影响树的存储,存储树结构的核心是保存逻辑关系。
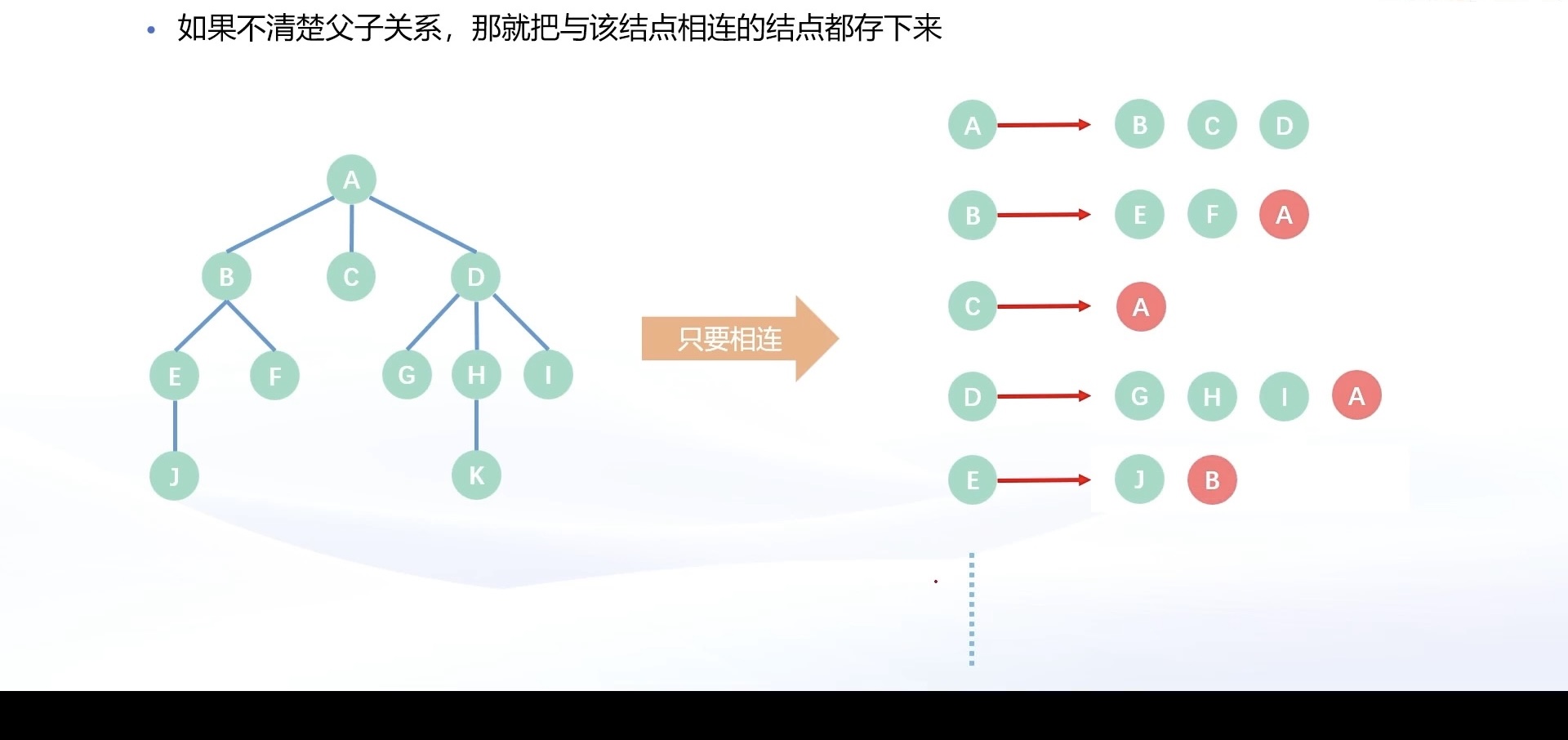
- 若是无根树,父子关系不明确,需保存所有可能的关联(例如 a 和 b 之间有一条边,不仅要存 a 有一个孩子 b,同时要存 b 有一个孩子 a)。
- 部分有根树的题目中,也需要采用这种存储方式。
3.5 树的存储
树结构相对线性结构比较复杂,存储时既要保存值域,也要保存结点与结点之间的关系。实际中树有多种存储方式:双亲表示法、孩子表示法、孩子双亲表示法以及孩子兄弟表示法等。
现阶段只需掌握孩子表示法 ,学会用它存储树并遍历整棵树;后续会在并查集中学习双亲表示法;其他存储形式在算法竞赛阶段不要求掌握。
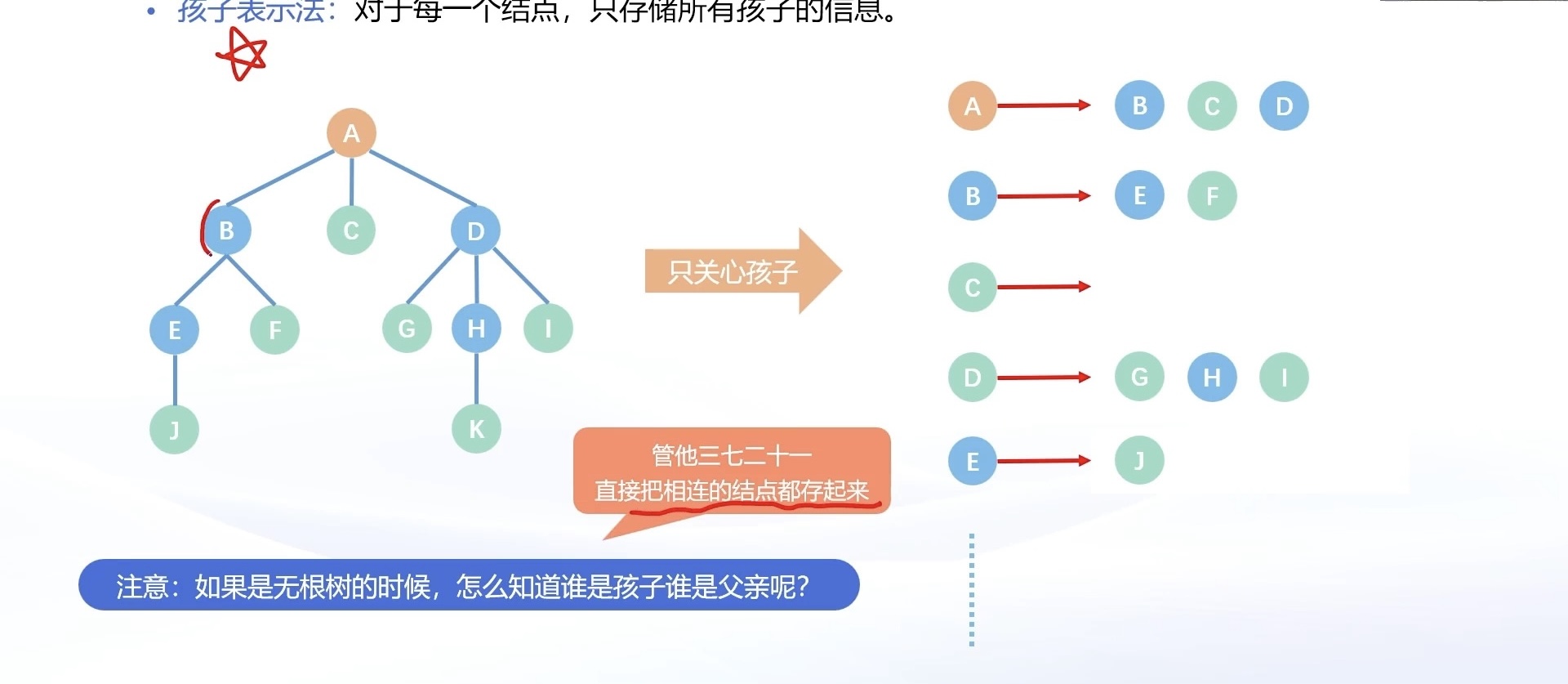
3.5.1 孩⼦表⽰法
孩子表示法是将每个结点的孩子信息存储下来。
如果是在无根树中,父子关系不明确,我们会将与该结点相连的所有的点都存储下来。
⬇️
3.5.2 实现⽅式⼀:⽤ vector 数组实现
⚠️:在算法竞赛中,一般给出的树结构都是有编号的,这样会简化我们之后存储树的操作
一般会给出以下两个信息:
- 结点的个数n;
- n-1 条x结点与y结点相连的边。
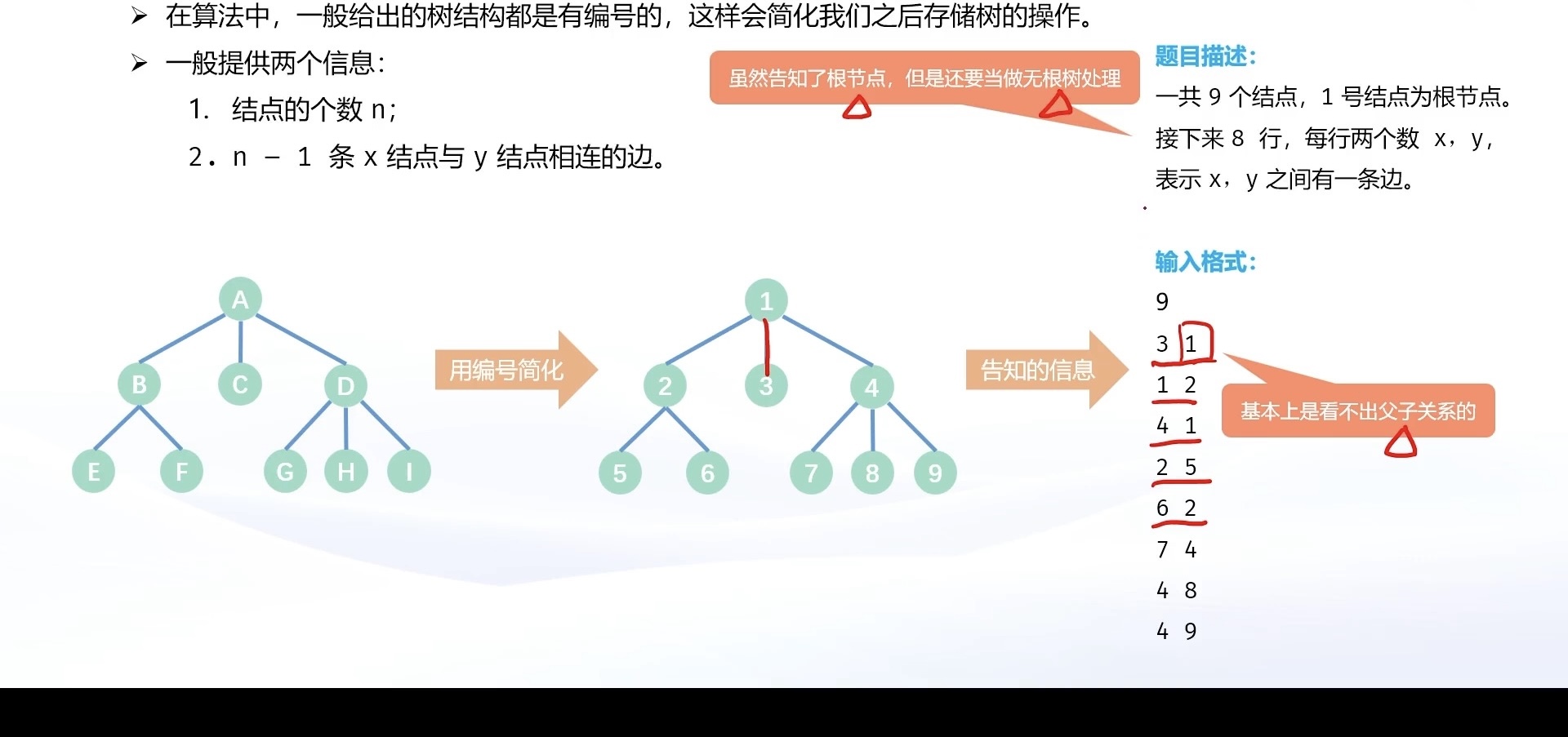
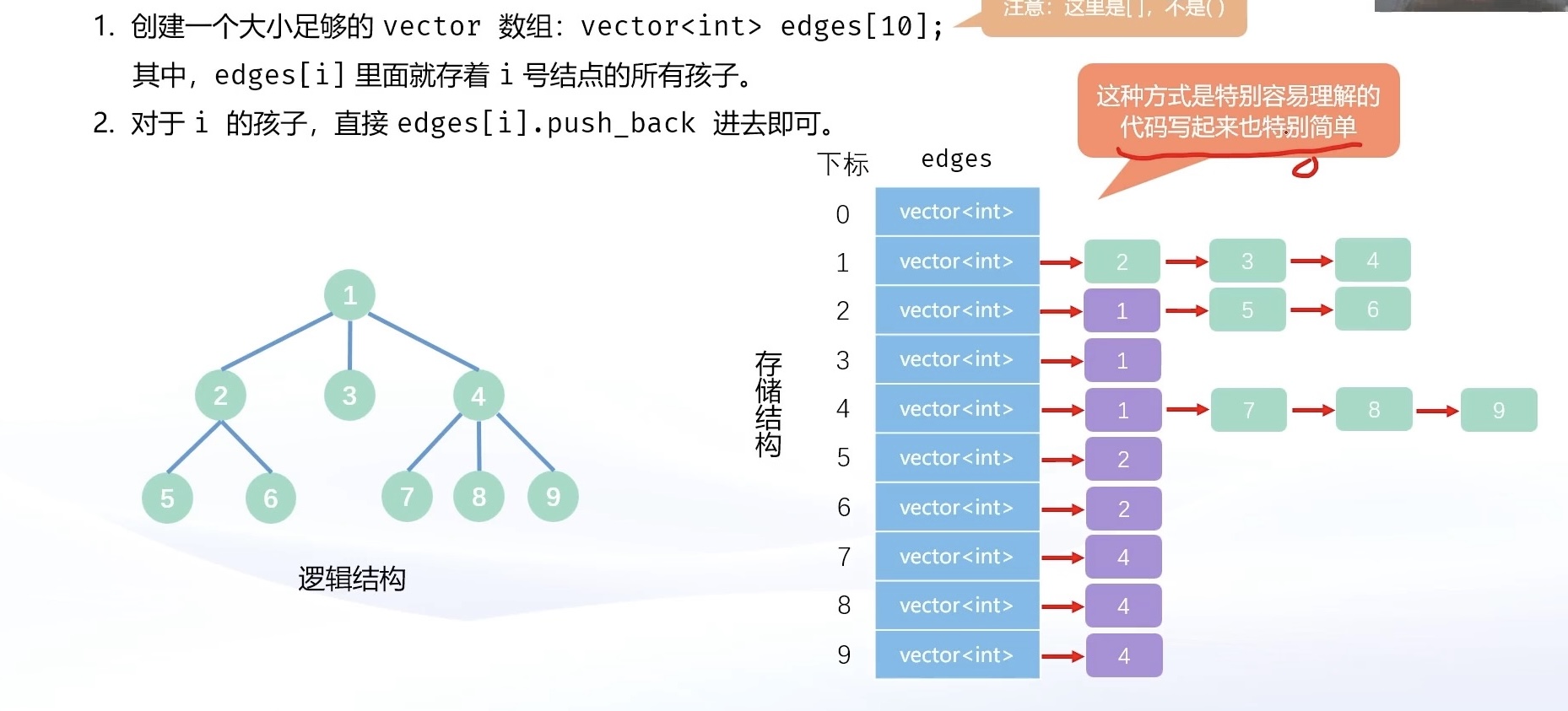
vector是可变长数组,如果只涉及尾插,效率还是可以的。而树结构这种一对多的关系,正好可以利用尾插,把所有的关系全部存起来。
- 因此,可以创建一个大小为
n + 1的vector数组edges[n + 1]。- 其中
edges[i]里面就保存着i号结点所连接的结点。
cpp
#include <iostream>
#include <vector>
using namespace std;
const int N = 1e5 + 10;
int n;
vector<int> edges[N]; // 存储树
int main()
{
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
// a 和 b 之间有⼀条边
edges[a].push_back(b);
edges[b].push_back(a);
}
return 0;
}3.5.3 实现⽅式⼆:链式前向星
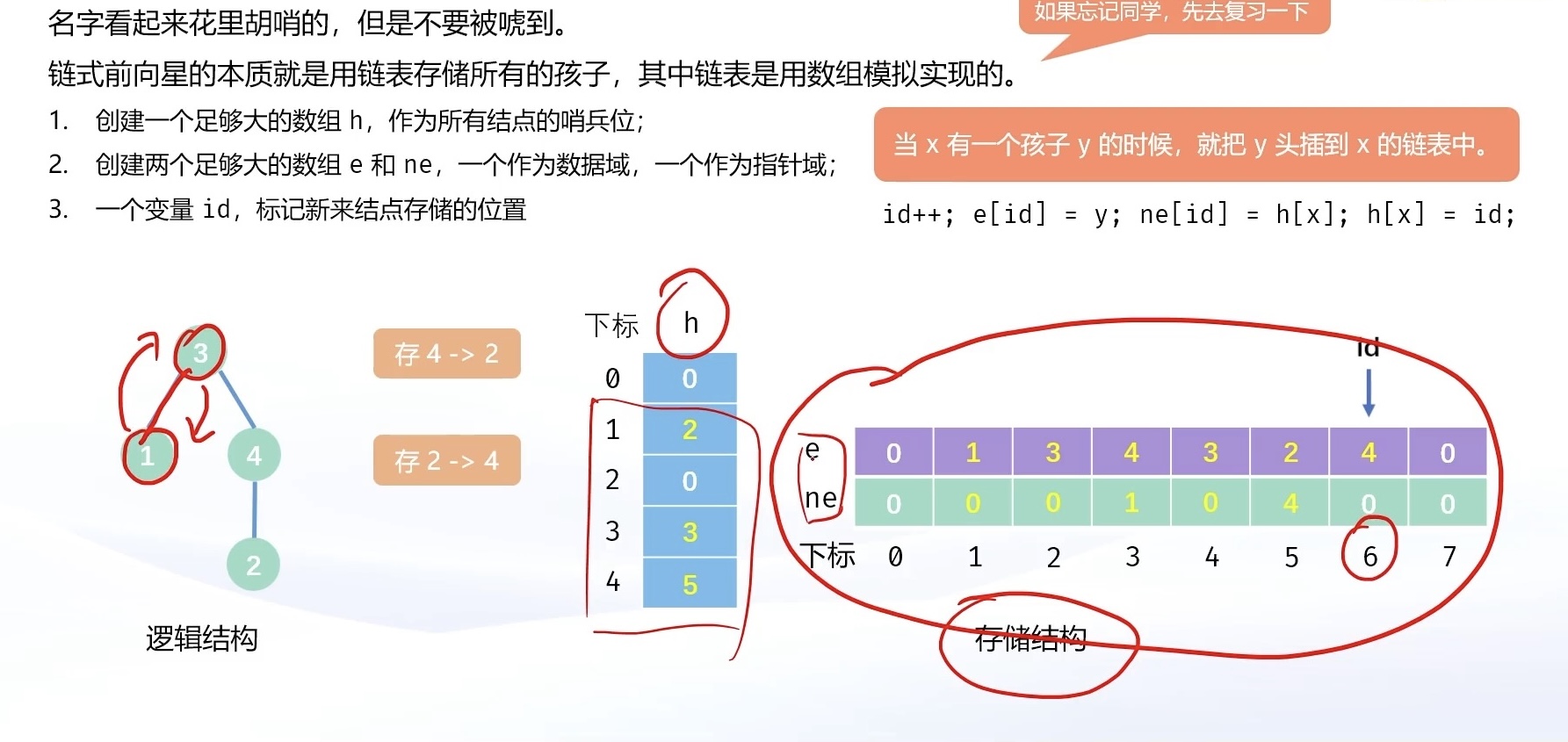
链式前向星的本质就是⽤数组来模拟链表
cpp
#include <iostream>
using namespace std;
const int N = 1e5 + 10;
// 链式前向星
int h[N], e[N * 2], ne[N * 2], id;
int n;
// 其实就是把 b 头插到 a 所在的链表后⾯
void add(int a, int b)
{
id++;
e[id] = b;
ne[id] = h[a];
h[a] = id;
}
int main()
{
cin >> n;
for(int i = 1; i < n; i++)
{
int a, b; cin >> a >> b;
// a 和 b 之间有⼀条边
add(a, b); add(b, a);
}
return 0;
}3.5.4 关于 vector 数组以及链式前向星:
- 前者由于用到了容器 vector,实际运行起来相比较于后者更耗时,因为 vector 是动态实现的。
- 但是在如今的算法竞赛中,一般不会无聊到卡这种常数时间。也就是 vector 虽然慢,但不会因此而超时。
那么,在做题的时候,选择一种自己喜欢的方式即可。
因为两种实现方式都挺简单,搞清楚原理之后也都很容易理解。
3.6 树的遍历
树的遍历就是不重不漏地将树中所有的点都扫描一遍。
在之前学过的线性结构中,遍历就很容易,直接从前往后扫描一遍即可。但是在树形结构中,如果不按照一定的规则遍历,就会漏掉或者重复遍历一些结点。因此,在树形结构中,要按照一定规则去遍历。
常用的遍历方式有两种,一种是深度优先遍历 ,另一种是宽度优先遍历。
3.6.1 深度优先遍历 - DFS
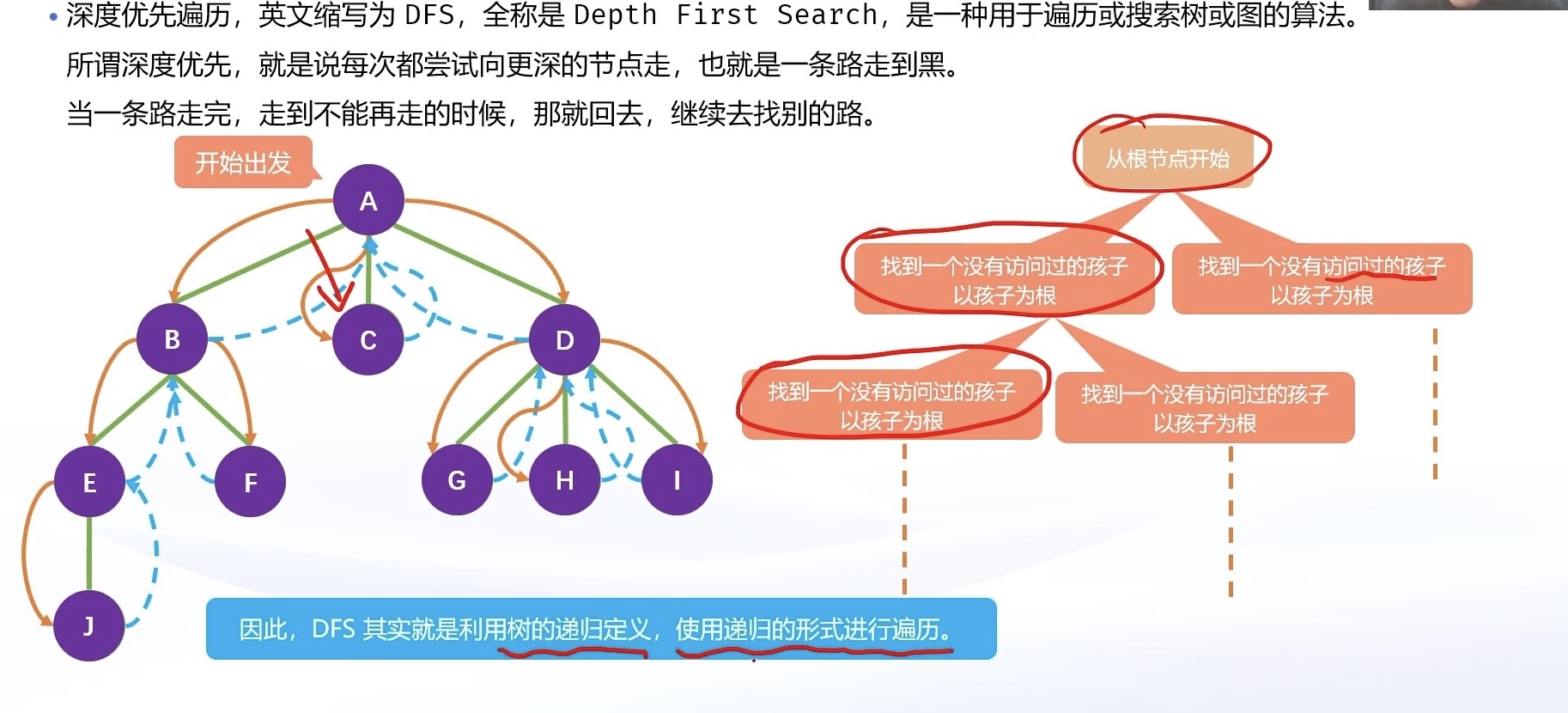
深度优先遍历,英文缩写为 DFS,全称是 Depth First Search,中文名是深度优先搜索,是一种用于遍历或搜索树或图的算法。所谓深度优先,就是说每次都尝试向更深的节点走,也就是一条路走到黑。
具体流程:
- 从根节点出发,依次遍历每一棵子树;
- 遍历子树的时候,重复第一步。
因此,深度优先遍历是一种递归形式的遍历,可以用递归来实现。
⬇️
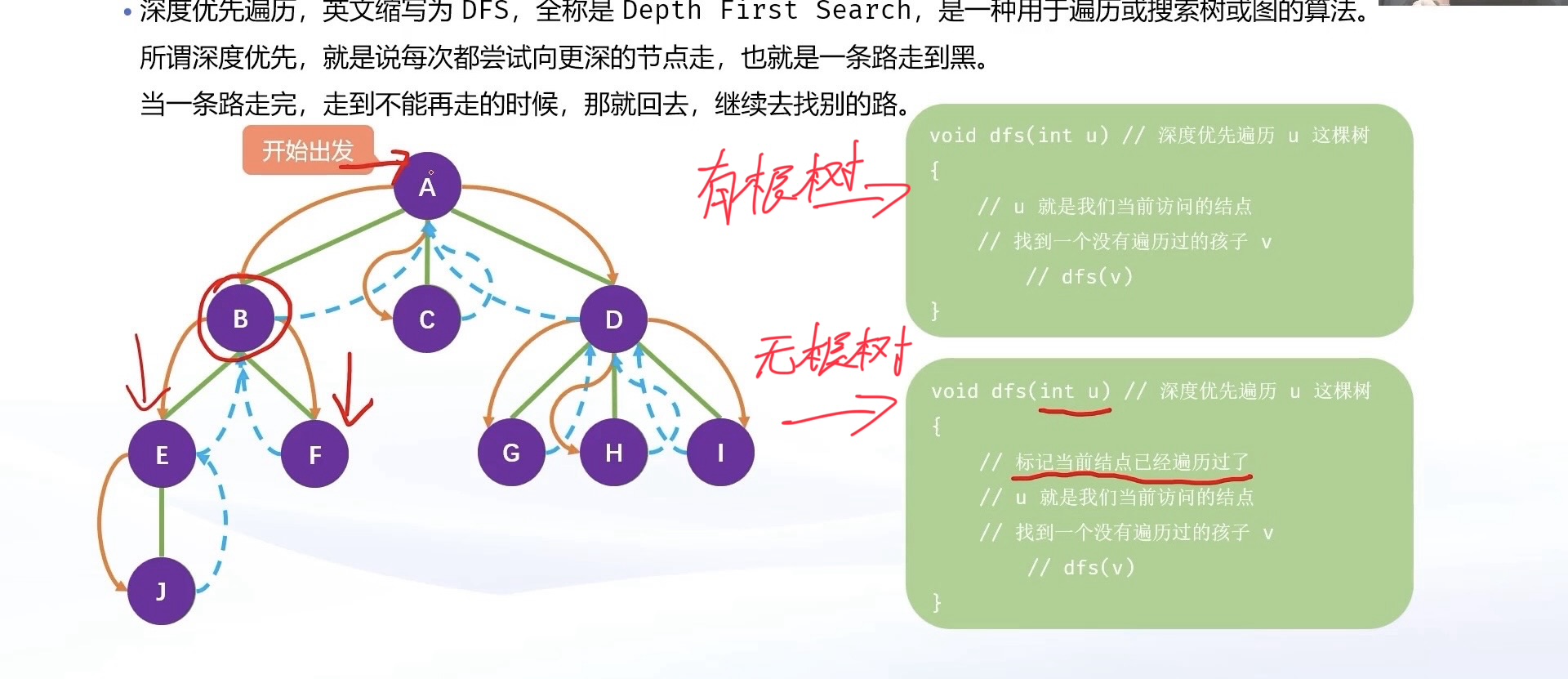
vector数组实现:注:存储树结构的时候,会把相邻的所有结点都存下来,这样在扫描子树的时候会直接扫描到上一层,这不是我们想要的结果。
因此,需要一个
st数组来标记,哪些结点已经访问过,接下来 dfs 的时候,就不去遍历那些点。
cpp
int n;
vector<int> edges[N]; // edges[i] 保存着 i 号结点相连的所有点
bool st[N]; // 标记当前结点是否已经被遍历过
// 当前遍历到 u 这棵⼦树
void dfs1(int u)
{
// 先访问该点
cout << u << " ";
st[u] = true; // 标记该点已经被访问过
// 访问它的⼦树
for(auto v : edges[u])
{
if(!st[v]) dfs1(v); // 如果没有遍历过,再去遍历
}
}
// ⽤ vector 数组
void test1()
{
cin >> n;
for(int i = 1; i <= n - 1; i++)
{
int a, b; cin >> a >> b; // 读⼊⼀条边
edges[a].push_back(b); // 保存 a -> b 的⼀条边
edges[b].push_back(a); // 保存 b -> a 的⼀条边
}
dfs1(1);
}链式前向星存储:
cpp
int n;
int h[N], e[N * 2], ne[N * 2], id;
bool st[N]; // 标记当前结点是否已经被遍历过
void add(int a, int b)
{
id++;
e[id] = b; // 搞⼀个格⼦,存 b
// 把 b 头插在 a 这个链表的后⾯
ne[id] = h[a];
h[a] = id;
}
// 当前遍历到 u 这棵⼦树
void dfs2(int u)
{
cout << u << " ";
st[u] = true;
for(int i = h[u]; i; i = ne[i])
{
int v = e[i];
if(!st[v]) dfs2(v);
}
}
// ⽤数组模拟链表
void test2()
{
cin >> n;
for(int i = 1; i <= n - 1; i++)
{
int a, b; cin >> a >> b;
add(a, b); add(b, a);
}
dfs2(1);
}⚠️:
- 时间复杂度:
简单估计一下,在 dfs 的整个过程中,会把树中所有的边扫描两遍。边的数量为 (n-1),因此时间复杂度为 (O(N))。- 空间复杂度:
最差情况下,结点个数为 (n) 的树,高度也是 (n),也就是变成一个链表。此时递归的深度也是 (n),此时的空间复杂度为 (O(N))。
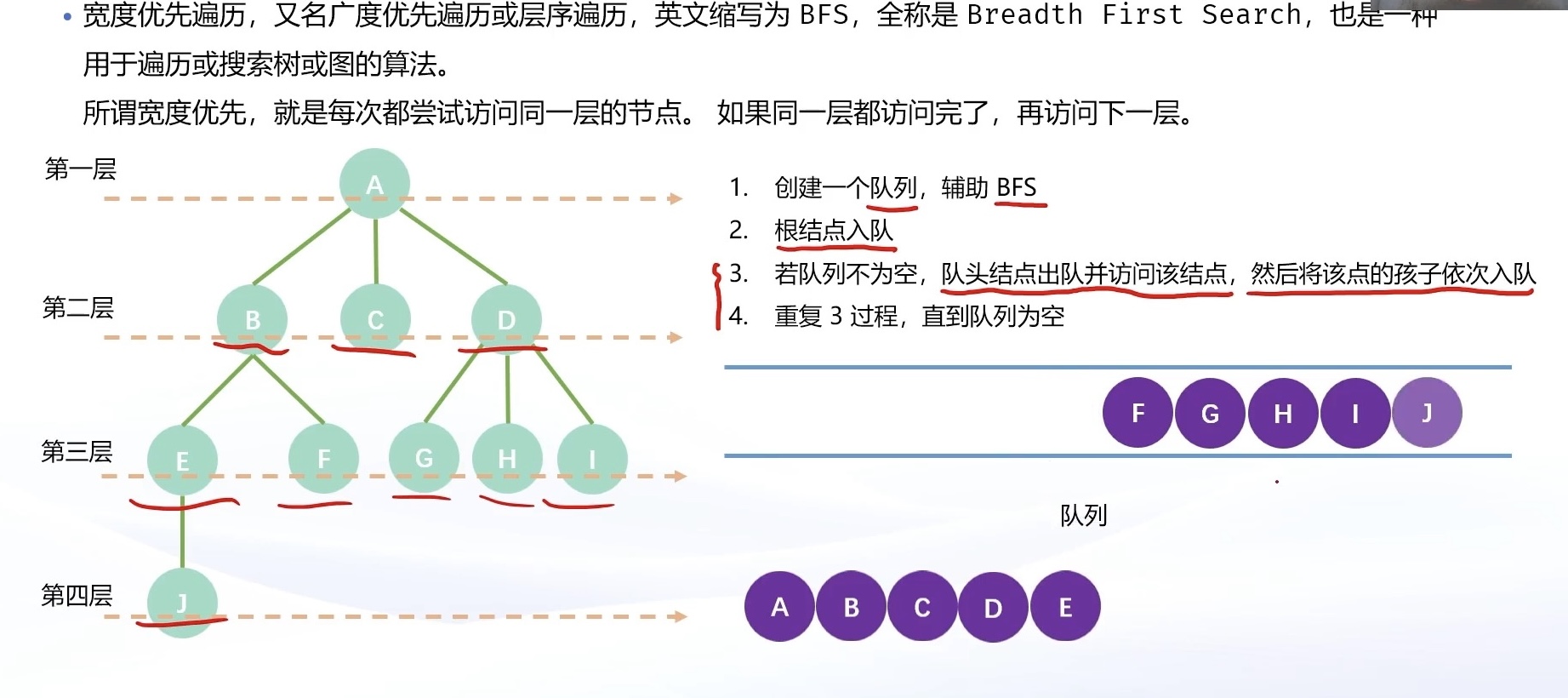
3.6.2 宽度优先遍历 - BFS
宽度优先遍历,英文缩写为 BFS,全称是 Breadth First Search,也叫广度优先遍历。也是一种用于遍历或搜索树或图的算法。所谓宽度优先,就是每次都尝试访问同一层的节点。如果同一层都访问完了,再访问下一层。
算法过程可以看做是在树和图中,在起点放上一个细菌,每秒向周围的那些干净的位置扩散一层,直到把所有位置都感染。
具体实现方式:借助队列。
- 初始化一个队列;
- 根节点入队,同时标记该节点已经入队;
- 当队列不为空时,拿出队头元素,访问,然后将队头元素的所有孩子入队,同时打上标记;
- 重复 3 过程,直到队列为空。
⽤ vector 数组存储:
cpp
int n;
vector<int> edges[N]; // edges[i] 保存着 i 号结点相连的所有点
bool st[N]; // 标记哪些点已经⼊过队了
void bfs1()
{
queue<int> q;
q.push(1);
st[1] = true;
while(q.size())
{
auto u = q.front(); q.pop();
cout << u << " ";
// 让孩⼦⼊队
for(auto v : edges[u])
{
if(!st[v])
{
q.push(v);
st[v] = true;
}
}
}
}
// ⽤ vector 数组
void test1()
{
cin >> n;
for(int i = 1; i <= n - 1; i++)
{
int a, b; cin >> a >> b; // 读⼊⼀条边
edges[a].push_back(b); // 保存 a -> b 的⼀条边
edges[b].push_back(a); // 保存 b -> a 的⼀条边
}
bfs1();
}链式向前星存储:
cpp
int n;
int h[N], e[N * 2], ne[N * 2], id;
bool st[N]; // 标记哪些点已经⼊过队了
void add(int a, int b)
{
id++;
e[id] = b; // 搞⼀个格⼦,存 b
// 把 b 头插在 a 这个链表的后⾯
ne[id] = h[a];
h[a] = id;
}
void bfs2()
{
queue<int> q;
q.push(1);
st[1] = true;
while(q.size())
{
auto u = q.front(); q.pop();
cout << u << " ";
for(int i = h[u]; i; i = ne[i])
{
int v = e[i];
if(!st[v])
{
q.push(v);
st[v] = true;
}
}
}
}
// ⽤数组模拟链表
void test2()
{
cin >> n;
for(int i = 1; i <= n - 1; i++)
{
int a, b; cin >> a >> b;
add(a, b);
add(b, a);
}
bfs2();
}⚠️:
- 时间复杂度: 所有结点只会入队一次,然后出队一次,因此时间复杂度为 O ( N ) O(N) O(N)。
- 空间复杂度: 最坏情况下,所有的非根结点都在同一层,此时队列里面最多有 n − 1 n - 1 n−1 个元素,空间复杂度为 O ( N ) O(N) O(N)。