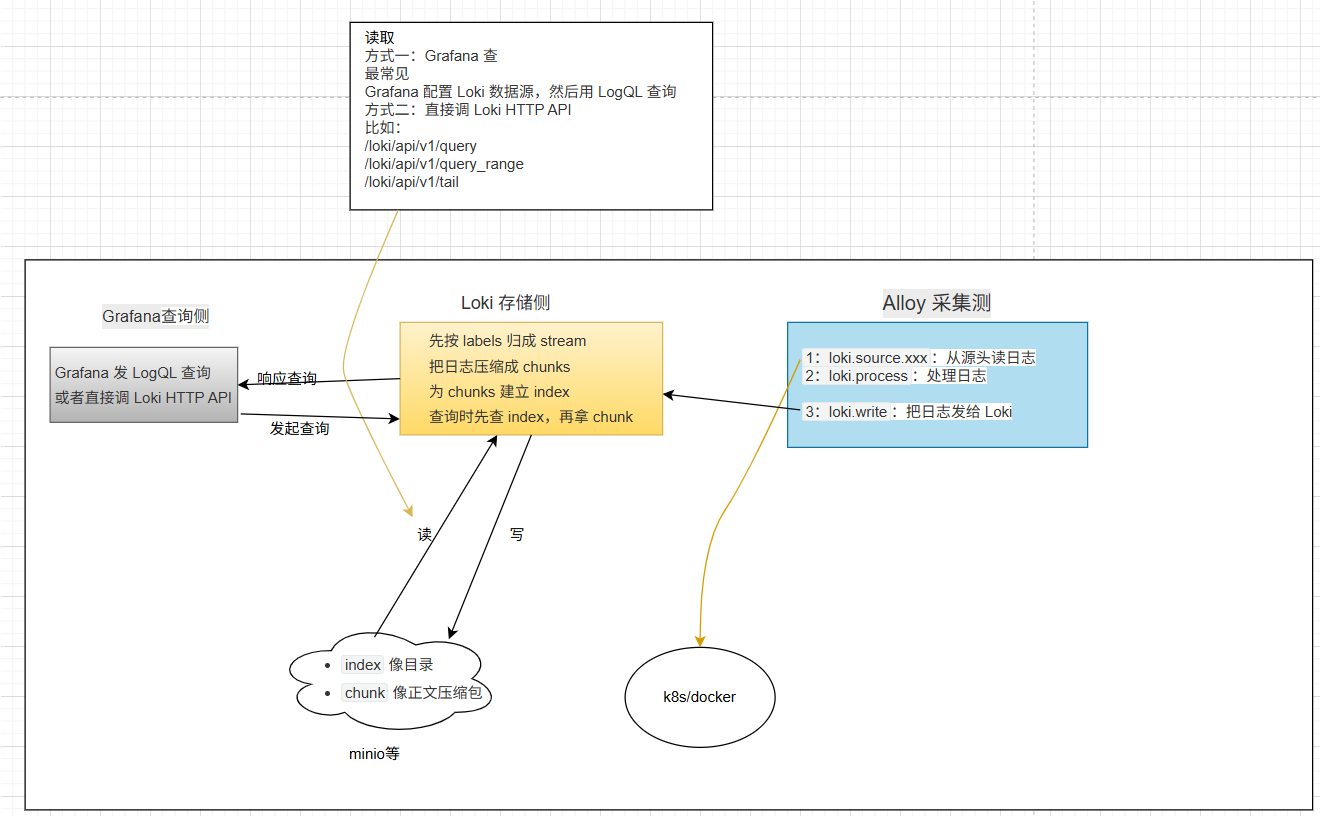
可以把 Grafana + Loki + Alloy 理解成一套"轻量级、云原生友好"的日志平台:
- Alloy:负责采集、加工、转发日志
- Loki:负责存储和检索日志
- Grafana:负责查询、展示、分析和告警
一、这套日志系统的优势
1)比传统 ELK 更轻,成本通常更低
Loki 和很多全文检索型日志系统最大的区别是:它不对日志正文做全文索引,而是只索引标签(labels)元数据。日志内容本身会被压缩后按 chunk 存储。这样索引更小,存储和运维成本通常更低,尤其适合容器环境下大量应用日志收集
bash
system-server
business-server
data-process-server
alarm-server
gateway
infra-server
report-server 这类多服务日志场景,如果按 namespace / pod / container / app / service 做标签,查询会非常自然,不需要一开始就走"重索引"路线。这个是 Loki 的核心优势
2)天然适配 Kubernetes
Grafana 官方对 K8s 日志采集给了明确方案:Alloy 负责采集 Kubernetes Pod 日志,再写入 Loki。Alloy 既能采集 Pod 日志,也能采集系统日志、集群事件等。
- 每个节点一个 Alloy(DaemonSet)
- 自动发现这个节点上的 Pod 日志
- 给日志打上 K8s 元数据标签
- 统一推送到 Loki
这比在每个 Spring Boot 服务里单独装日志 agent 简单很多,也更符合运维习惯
3)和 Grafana 结合紧密,查询体验好
Grafana 本身就是可视化层,接入 Loki 后可以:
- 按标签快速过滤日志
- 按时间范围检索
- 实时 tail 日志
- 做关键字检索、错误聚合、异常排查
- 基于日志做告警
Loki 官方文档说明,它支持通过 HTTP API 推送、查询和 tail 日志;Grafana 则是最常见的查询与展示入口
4)Alloy 不只是日志采集器,后续还能统一接管观测数据
Alloy 不是一个"只会收日志"的工具,它是 Grafana 发行版的 OpenTelemetry Collector ,支持 metrics、logs、traces、profiles。这意味着你后面如果想把:
- Spring Boot 指标
- 应用链路追踪
- JVM 指标
- 主机指标
一起纳入统一观测体系,Alloy 可以继续复用,不需要再换一套采集架构
对运维来说,这一点很重要:先做日志,后面做监控、链路追踪时不推倒重来
5)更适合云原生场景下"按标签找日志"
Loki 的核心检索方式不是传统"先全文建索引再查",而是:
- 先根据 labels 找到目标日志流
- 再读取对应 chunk
- 再做过滤、关键字匹配、展示
所以它特别适合查询这类问题:
- 某个 namespace 下的日志
- 某个服务 app 的日志
- 某个 pod 的日志
- 某个实例在某时间段的报错
- 某个网关服务 5xx 相关日志
这和 K8s 的运维排障思路高度一致
二、它的工作原理
你可以把整套链路理解成下面这条数据流:
容器标准输出 / 日志文件 → Alloy 采集 → 打标签 / 清洗 / 转发 → Loki 存储索引 → Grafana 查询展示
官方文档里已经明确了 Alloy 到 Loki 的典型链路:配置 loki.write 写入 Loki,再配置对应的日志采集组件去收集 Pod 日志或系统日志
1)日志从哪里来
在 Kubernetes 里,Spring Boot 应用最推荐的做法通常是:
- 应用日志输出到 stdout/stderr
- 由容器运行时写入节点上的容器日志
- Alloy 再从 K8s/节点侧统一采集
如果你的 Spring Boot 还在写本地文件日志,也能采,但 K8s 场景优先推荐标准输出,因为这样最符合容器化日志收集模式。Grafana 官方的 K8s 采集文档也是围绕 Pod 日志来设计的。
2)Alloy 做什么
Alloy 的职责相当于"日志入口网关",主要干四件事:
- 发现目标:找到哪些 Pod、容器、节点日志要采
- 采集日志:持续读取日志流
- 加工日志:加标签、解析字段、过滤噪音、重写结构
- 发送日志 :通过
loki.write发给 Loki
Alloy 是一个遥测采集器,原生支持 Loki 等后端;它的设计本质上继承了 OpenTelemetry Collector 的 pipeline 思想
3)Loki 怎么存
Loki 收到日志后,不会像 Elasticsearch 那样把每一行正文都做全文索引。它会:
- 按标签组合把日志划分成不同的 stream
- 把日志批量压缩成 chunks
- 为这些 chunk 建立一个"目录式"的索引
- 查询时先查索引,再取 chunk 内容
官方文档对这一点描述得很明确:每组唯一 label 组合定义一个 stream,日志会被批量压缩为 chunk;labels 是 Loki 的索引。
4)Grafana 怎么查
Grafana 连接 Loki 后,用户发起查询时通常会:
- 先指定标签条件,比如
app="pems-gateway" - Loki 根据标签索引找到对应 chunks
- 再从这些 chunks 中取出日志内容
- 在 Grafana 界面显示,并支持继续筛选、聚合、统计
所以 Loki 的查询效率很大程度上取决于:你的标签设计是否合理。 标签打得太少,查询范围太大;标签打得太细、太离散,又会造成高基数问题。官方也明确强调:labels 要谨慎设计。
三、这三者之间的分工
Grafana
相当于"前台控制台"
- 配置数据源
- 查日志
- 做 Dashboard
- 配置告警
- 做排障分析
Loki
相当于"日志数据库"
- 接收日志
- 按标签组织日志流
- 存储 chunks
- 提供查询接口
Alloy
相当于"采集代理 + 数据管道"
- 在 K8s 节点或 Pod 侧采集日志
- 给日志补充 Kubernetes 元数据
- 清洗、重写、过滤
- 发送到 Loki
这个职责分离很清晰,也方便后期扩展。
四、凭什么这套适合你的项目
- Spring Cloud 微服务
- 服务数量较多
- K8s 部署
- 需要统一查看多个服务日志
- 未来大概率还想做监控、告警、链路分析
这时用 Grafana + Loki + Alloy 的好处是:
部署模型和 K8s 很契合 ,通常节点级采集即可。
多服务日志统一检索方便 ,按 namespace / app / pod / container 查询就行。
日志成本相对友好 ,尤其适合持续增长的容器日志量。
后续可以平滑扩展到指标和链路追踪,不用重建采集体系。
五、需要建立的正确认知
1)Loki 不是 Elasticsearch
它不是"重全文索引搜索引擎",而是"按标签组织日志流的日志系统"。所以设计重点不在"把每个字段都索引",而在"先把标签体系设计好"
2)K8s 日志采集最好围绕容器 stdout
不要延续传统物理机时代"每个应用各写一个文件、每个文件再单独采集"的思路。容器场景最好让 Spring Boot 把日志打到标准输出,再让 Alloy 统一采集。Grafana 官方的 K8s 日志采集路径也是围绕 Pod/container logs
3)标签比正文更重要
以后你查日志时,最常用的不是"全文搜一句话",而是先按这些条件缩小范围:
- 集群 / namespace
- 服务名
- pod 名
- 容器名
- 节点名
- 环境(dev/test/prod)
然后再在结果里过滤关键字。
4)Alloy 是整套方案的入口
Alloy 配置写得好不好,直接决定:
- 日志是否能采到
- 标签是否齐全
- 是否有噪音日志
- 查询是否方便
- Loki 压力是否合理
所以实操里,采集配置和标签规划 是成败关键。
六、总结
这套系统本质上是:
用 Alloy 在 K8s 里统一采集日志,用 Loki 以"标签索引 + 压缩存储"的方式低成本保存日志,再用 Grafana 做检索、分析和告警。
大概结构如下: