为 Linux 主机添加自定义监控项,最成熟、最灵活的方法是利用 Node Exporter 的 textfile collector 功能。
它的核心原理是:你通过脚本生成监控数据,Node Exporter 负责读取并暴露给 Prometheus。
🎯 解决方案:使用 textfile collector
这个方案主要分三步:开启功能、创建指标、编写脚本自动化。下面是详细的操作流程。
📝 第一步:开启 textfile collector
创建数据目录:在主机上创建一个专用目录,用来存放自定义指标文件。
bash
sudo mkdir -p /var/lib/node_exporter/textfile_collector
配置并重启 Node Exporter:需要编辑 Node Exporter 的启动配置,让它知道这个目录的存在。
编辑服务文件 (/etc/default/node_exporter 或 /etc/systemd/system/node_exporter.service):
bash
sudo nano /etc/default/node_exporter
在 OPTIONS 中添加 --collector.textfile.directory 参数。如果文件是空的,修改后应类似于:
text
OPTIONS='--collector.textfile.directory=/var/lib/node_exporter/textfile_collector'
以下注意反斜杠,丢了不生效
bash
[root@localhost node_exporter]# cat start.sh
#!/bin/bash
cd /data/node_exporter
nohup ./node_exporter \
--web.listen-address="0.0.0.0:9100" \
--collector.disable-defaults \
--collector.cpu \
--collector.meminfo \
--collector.filesystem \
--collector.diskstats \
--collector.netdev \
--collector.loadavg \
--collector.time \
--collector.uname \
--collector.textfile \
--collector.textfile.directory=/var/lib/node_exporter/textfile_collector \
> logs/node_exporter.log 2>&1 &
echo $! > node_exporter.pid
echo "Node Exporter started with PID: $(cat node_exporter.pid)"
[root@localhost node_exporter]# 重启服务:
bash
sudo systemctl daemon-reload # 如果修改了 service 文件,需要执行这一步
sudo systemctl restart node_exporter
检查状态:确保 Node Exporter 重启成功,且没有报错。
bash
sudo systemctl status node_exporter
📝 第二步:创建你的第一个自定义指标
创建一个 .prom 文件:在刚才创建的目录下新建一个文件。文件名可以自定义,但后缀必须是 .prom。例如,创建一个测试文件:
bash
sudo nano /var/lib/node_exporter/textfile_collector/test_metric.prom
写入指标数据:文件内容格式很简单,每行一个指标。它的格式是:
指标名称{标签1="值1", 标签2="值2"} 指标值
请将下面的示例复制到文件中。
text
这是帮助信息,可选,用于解释这个指标的含义
HELP my_custom_metric A metric from my own script
TYPE my_custom_metric gauge
my_custom_metric{source="textfile",type="demo"} 42
补充说明:gauge 是可增可减的数值(如温度);如果是累计值(如请求总数),可以用 counter。
bash
[root@localhost node_exporter]# cat /var/lib/node_exporter/textfile_collector/test_metric.prom
# HELP my_custom_metric This is my custom metric
# TYPE my_custom_metric gauge
my_custom_metric{source="textfile",type="demo"} 666
[root@localhost node_exporter]# 验证指标是否生效:等待几秒钟,让 Node Exporter 读取新文件。然后通过 curl 命令来验证。
bash
curl -s http://localhost:9100/metrics | grep my_custom_metric
如果看到类似下面的输出,就说明配置成功了!
text
HELP my_custom_metric A metric from my own script
TYPE my_custom_metric gauge
my_custom_metric{source="textfile",type="demo"} 42
bash
[root@localhost node_exporter]# curl -s http://localhost:9100/metrics | grep my_custom_metric
# HELP my_custom_metric This is my custom metric
# TYPE my_custom_metric gauge
my_custom_metric{source="textfile",type="demo"} 666
[root@localhost node_exporter]# 📝 第三步:编写脚本采集真实数据
手动创建文件并不能实现自动化。实际使用中,你需要编写一个脚本(比如 Bash、Python 等),让它周期性运行,并把结果输出到 .prom 文件中。
社区维护了很多现成的脚本,可以去 node-exporter-textfile-collector-scripts 这个仓库找找灵感。
下面是一个简单的 Bash 脚本示例,用于监控失败的 SSH 登录尝试次数:
bash
#!/bin/bash
脚本名称: ssh_failures.sh
功能: 统计 /var/log/auth.log 中失败的 SSH 登录次数
1. 定义输出文件的路径
OUTPUT_FILE="/var/lib/node_exporter/textfile_collector/ssh_failures.prom"
2. 采集数据:使用 grep 统计日志中 "Failed password" 的行数
如果有多个日志文件,请根据实际情况调整
FAILURE_COUNT=$(grep -c 'Failed password' /var/log/auth.log)
3. 将结果写入临时文件,再 mv 到最终文件,这是一个保证写入"原子性"的好习惯。
bash
echo "# HELP ssh_failed_logins_total Total number of failed SSH login attempts" > ${OUTPUT_FILE}.$$
echo "# TYPE ssh_failed_logins_total counter" >> ${OUTPUT_FILE}.$$
echo "ssh_failed_logins_total ${FAILURE_COUNT}" >> ${OUTPUT_FILE}.$$4. 移动临时文件到最终位置,Node Exporter 会读取这个文件
mv OUTPUTFILE.{OUTPUT_FILE}.OUTPUTFILE. {OUTPUT_FILE}
如何让脚本周期执行?
使用 cron 任务即可。通过 crontab -e 命令添加下面的配置,让脚本每分钟运行一次:
bash
* * * * * root /path/to/your/scripts/ssh_failures.sh
测试脚本:在创建 cron 任务前,先手动运行一次脚本,确保它按预期工作。
bash
sudo chmod +x /path/to/your/scripts/ssh_failures.sh
sudo /path/to/your/scripts/ssh_failures.sh
curl -s http://localhost:9100/metrics | grep ssh_failed
🚨 重要提醒:注意指标基数
这是新手最容易踩的坑,需要特别注意一下。
不要在标签值里使用变化频繁或无限制的值,比如:
user_id="12345" (用户ID)
request_id="abc-123"
ip_address="192.168.1.1"
timestamp="2023-10-27 10:00:00"
这样做会导致指标数量爆炸式增长,严重消耗 Prometheus 服务器的内存和磁盘,甚至导致服务崩溃。
一个正确做法的例子:
http_requests_total{method="GET", status="200"}
一个需要避免的坏例子:
http_requests_total{user_id="12345", status="200"}
Grafana出图
第1步:创建 Dashboard 并添加图表
方式一:从零创建
鼠标悬停到左侧 + 号图标,点击 New Dashboard
点击 + Add visualization
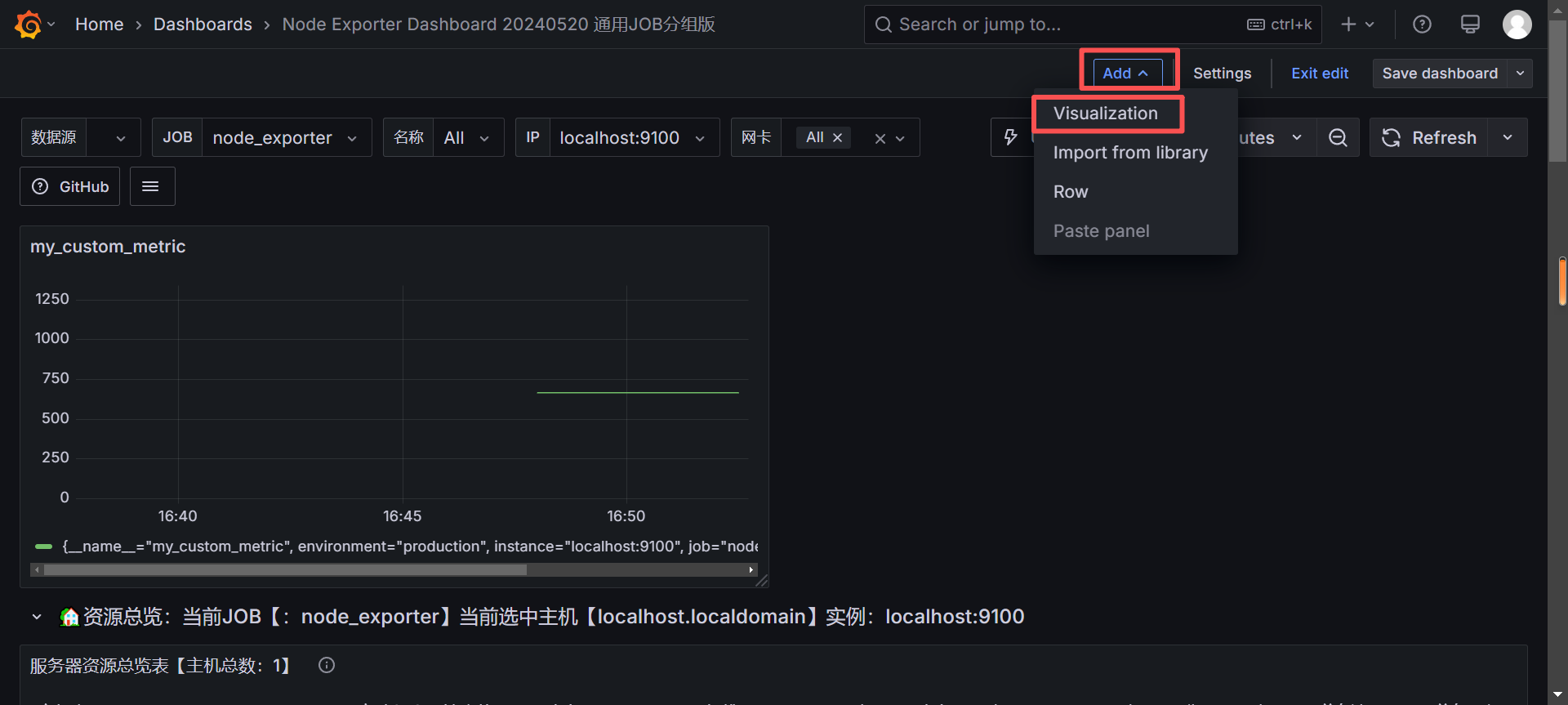
选择刚才创建的 Prometheus 数据源
在查询编辑器中输入你的自定义指标名:
promql
my_custom_metric
如果指标带有标签(labels),可以进一步筛选:
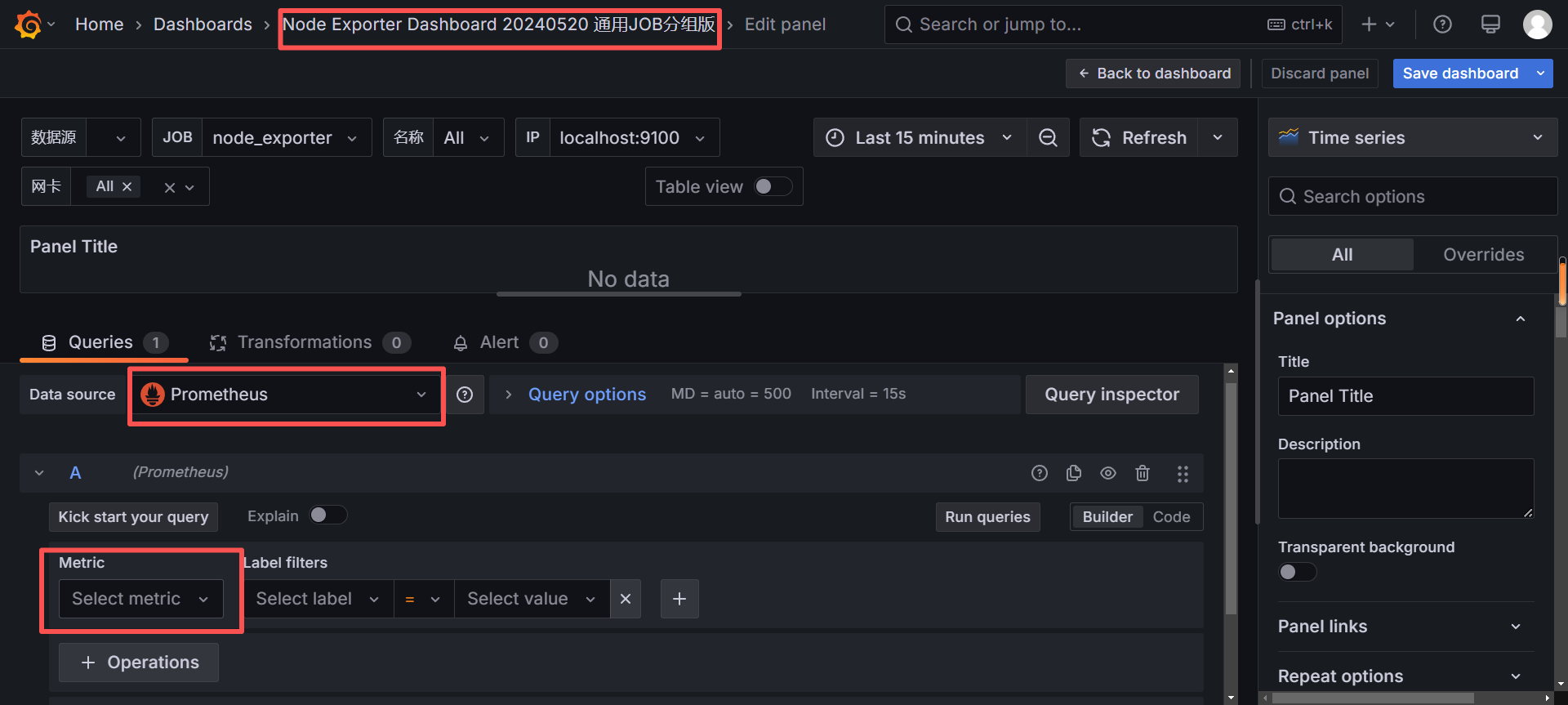
promql
my_custom_metric{source="textfile"}
或者查看该指标的所有时间序列:
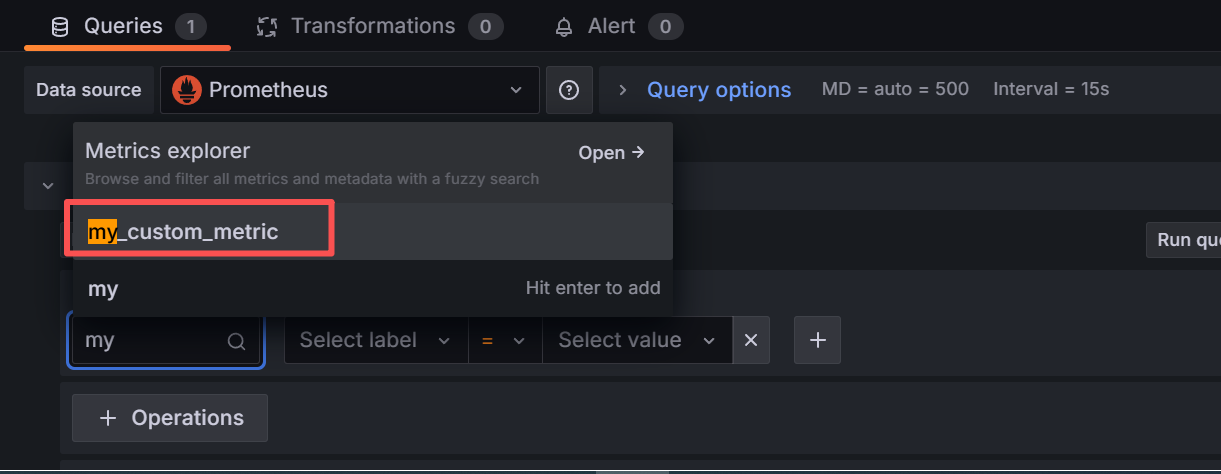
promql
my_custom_metric{source="textfile", type="demo"}
右上角选择时间范围(可以选 Last 15 minutes 或 Last 30 minutes),确认图表有数据显示
点击右上角 Save 按钮,给仪表盘起个名字(比如 "My Custom Metrics")
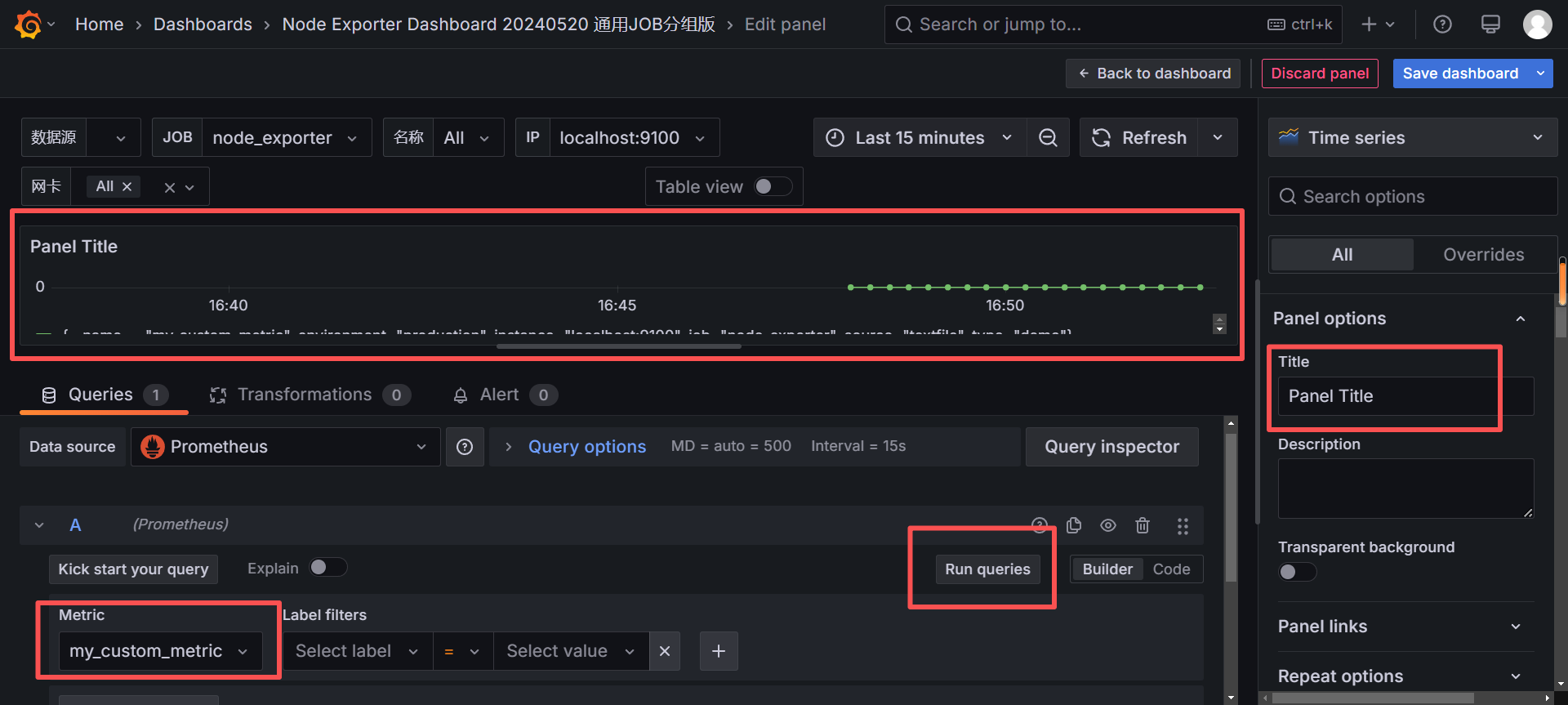
方式二:在已有 Dashboard 中新增 Panel
打开已有的 Dashboard
点击顶部 Add → Panel
按同样方式配置 PromQL 查询并保存
第4步:图表展示优化建议
选择合适的图表类型
在右侧面板的 Visualization 选项中:
图表类型 适用场景 建议
Stat 显示当前值(最新的 666) 适合展示单个最新数值
Time series / Graph 展示指标随时间变化的趋势 适合观察变化趋势
Gauge 显示当前值占总范围的百分比 适合水位类指标
配置图表参数
Legend:可以改成 {{source}} 或 {{type}} 来动态显示标签值
Unit:如果数值是百分比,在 Standard options > Unit 中选择 Percent (0-100)
Thresholds:可以设置告警阈值(如 80 黄色警告,90 红色严重)
💎 常用 PromQL 查询示例
你想看的 查询语句
最新值 my_custom_metric
最近1小时变化趋势 my_custom_metric1h
平均值 avg(my_custom_metric)
过滤特定标签 my_custom_metric{source="textfile"}
❓ 如果图表显示"无数据"
按以下顺序排查:
检查时间范围:确保右上角时间范围覆盖了数据的时间点(如果指标是刚采集的,选 Last 15 minutes 即可)
确认指标名拼写:在 PromQL 编辑器中输入 { 或按 Ctrl+Space,看看自动补全里有没有你的指标
验证 Prometheus 有数据:在 Promotion 的 Graph 页面直接查询 my_custom_metric,确认能返回结果
检查数据源配置:Save & Test 确认连接成功
配置告警媒介-邮件
将邮件信息配置到Grafana的ini文件,重启grafana
以下password是邮件的授权码,需要在邮箱设置里开启,生成授权码
bash
[root@localhost grafana]# cat /data/grafana/conf/custom.ini
[paths]
data = /data/grafana/data
logs = /data/grafana/logs
[server]
http_port = 3000
[smtp]
enabled = true
host = smtp.163.com:465
user = 1111111@163.com
password = KSsdsdsdsdsdsd
from_address = 111111@163.com
from_name = Grafana
skip_verify = true
[root@localhost grafana]#
bash
[root@localhost grafana]# cat start.sh
#!/bin/bash
sudo nohup ./bin/grafana-server --config=/data/grafana/conf/custom.ini --homepath=/data/grafana
[root@localhost grafana]# Grafana配置测试发邮件
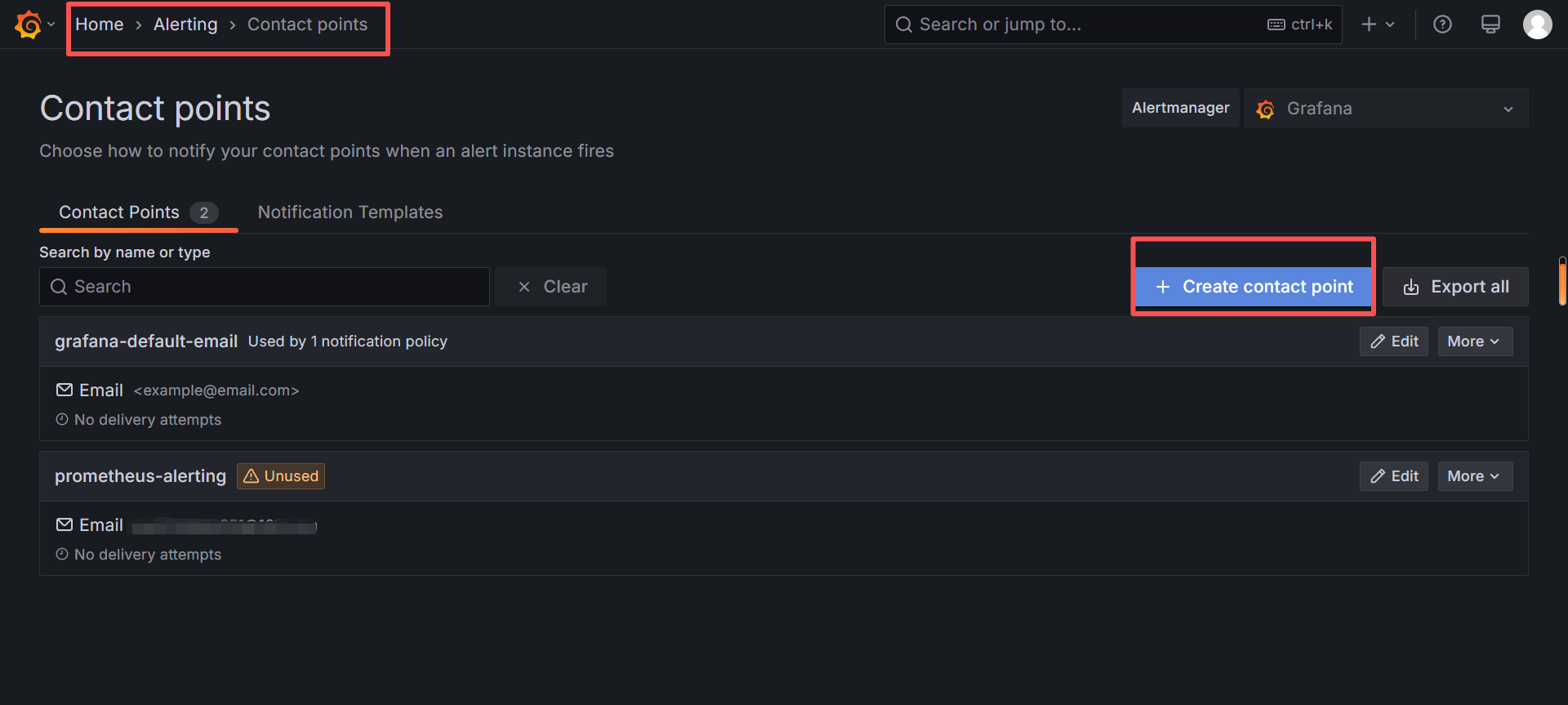
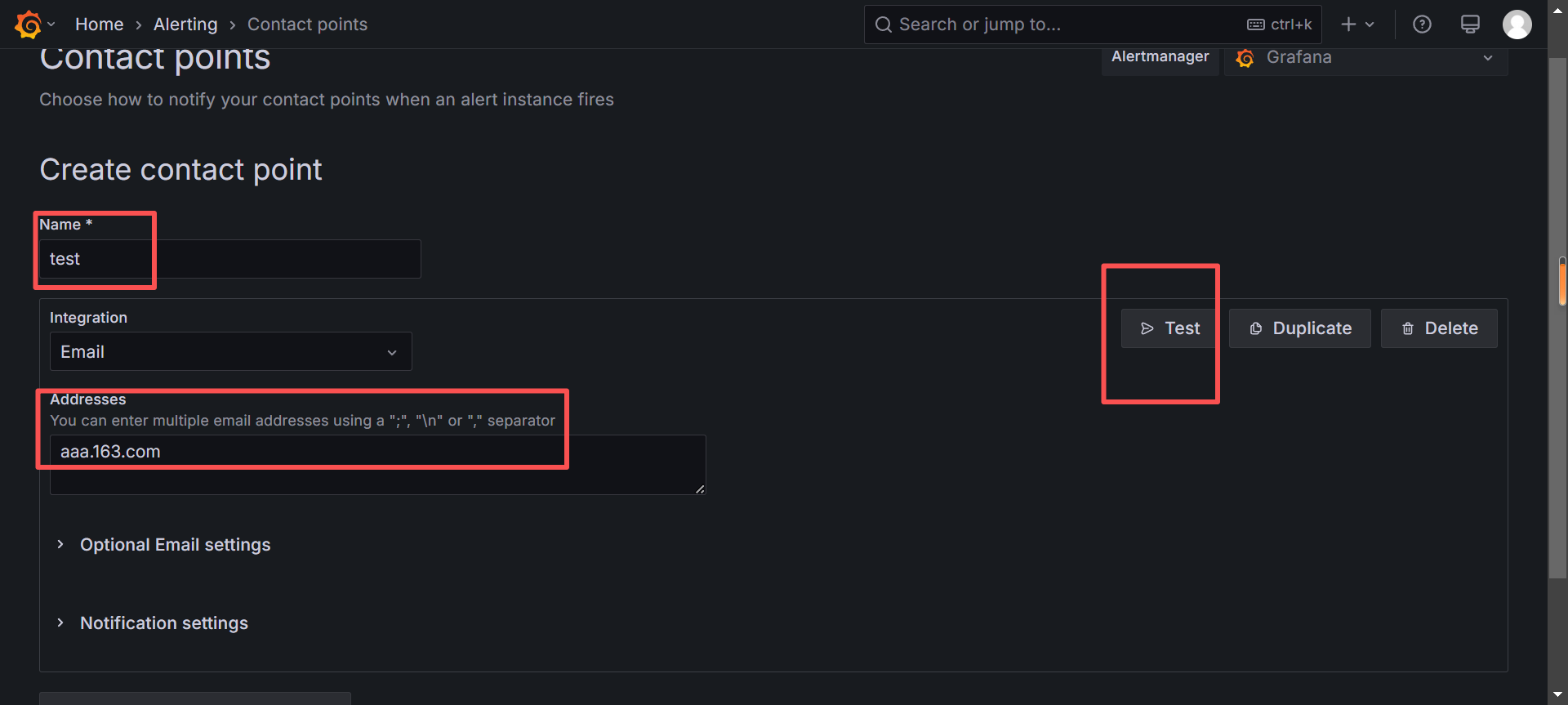
配置自定义告警规则
bash
[root@localhost rules]# cat node_alerts.yml
groups:
- name: node_alerts
interval: 30s
rules:
# 7.
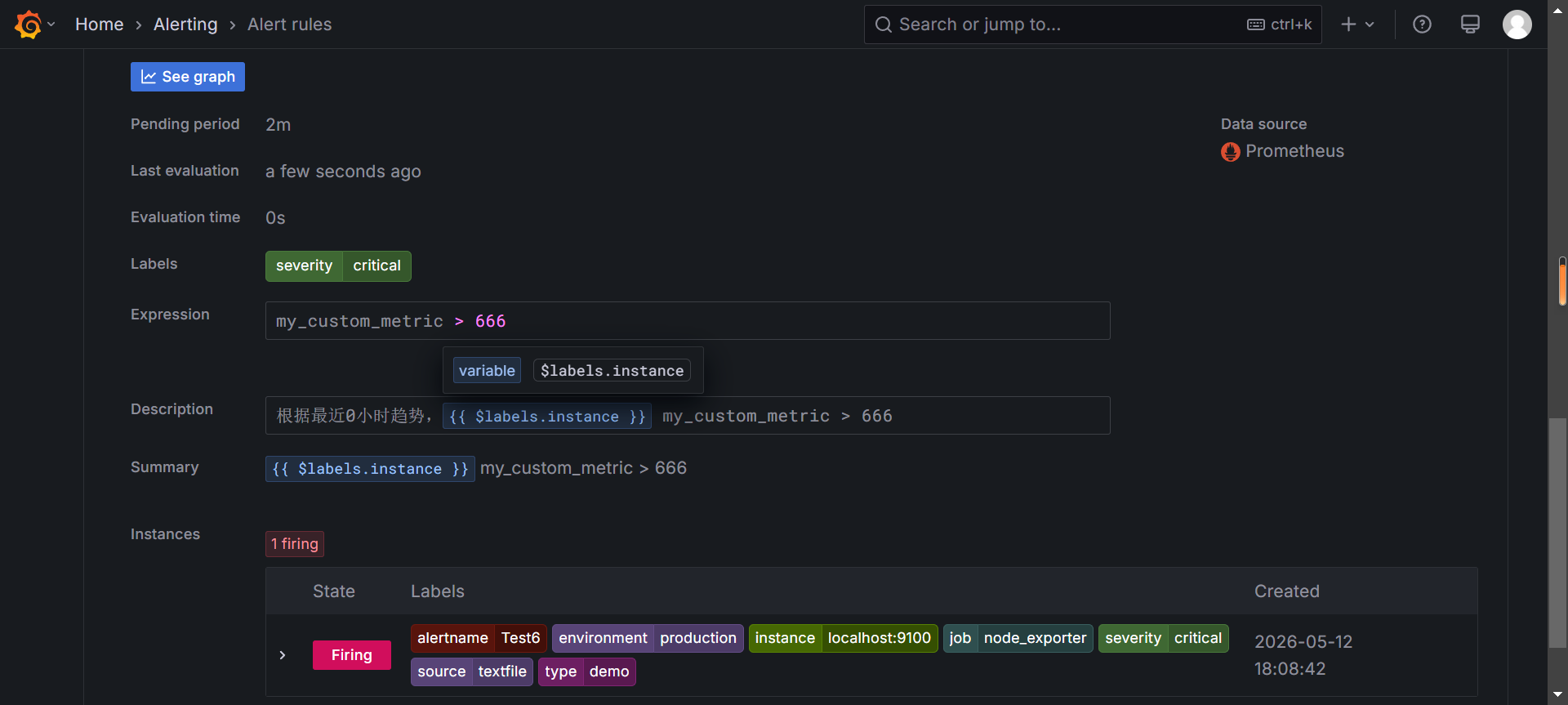
- alert: Test6
expr: my_custom_metric > 666
for: 2m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} my_custom_metric > 666"
description: "根据最近0小时趋势,{{ $labels.instance }} my_custom_metric > 666"修改自定义监控项值大于666,触发告警
bash
dbus/ initramfs/ misc/ os-prober/ prometheus/ rpm-state/ systemd/
[root@localhost rules]# cat /var/lib/node_exporter/textfile_collector/test_metric.prom
# HELP my_custom_metric This is my custom metric
# TYPE my_custom_metric gauge
my_custom_metric{source="textfile",type="demo"} 676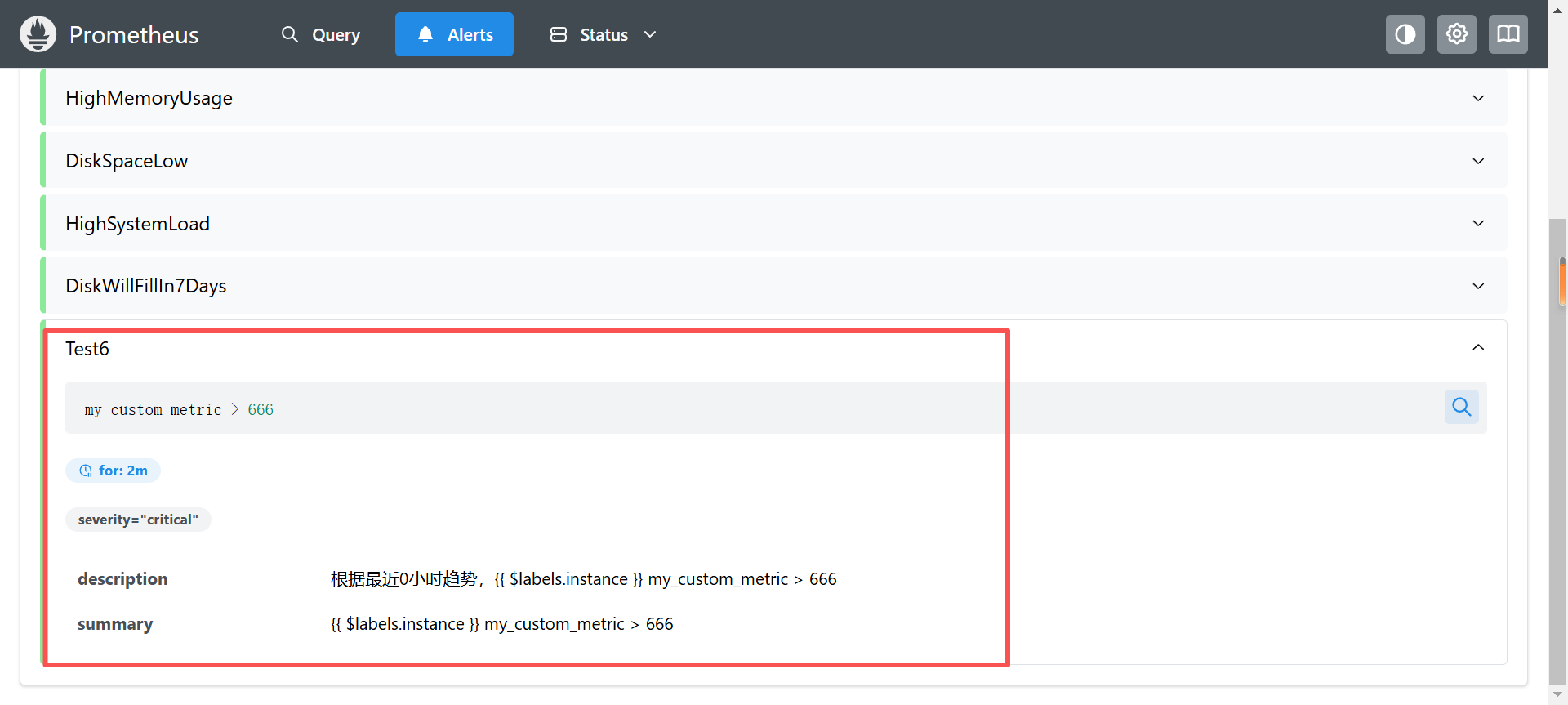
查看告警