作者:徐可甲(烨陌)
在大规模云上业务持续增长的 10 多年里,我们打磨出了 LoongCollector(前身 iLogtail):在同等硬件上可实现 10 倍吞吐,并带来 80% 资源下降。更重要的是,它在"极限性能"之外,还同时具备企业级可靠性。
引言:AI 与 FinOps 时代,采集性能为什么成了硬指标
随着行业技术的变迁,一个显著的趋势是:可观测数据的"量"和"形态"都在变。除了传统在线业务带来的稳定增量,AI 应用(LLM/RAG/Agent)带来了更碎片化、更高频的事件流;云原生规模化(Kubernetes、服务网格、多 Region/多云)则让实例数量、生命周期与网络拓扑复杂度同时上升。可观测系统需要覆盖更多维度、更多组件、更多租户,而数据规模很容易从 TB 级跃迁至 PB 级。
与此同时,FinOps 让"资源消耗"不再是一个模糊感受,而是可以被精确归因到每一核 CPU、每一 MB 内存、每一次磁盘与网络 I/O:采集 Agent 的成本,开始直接出现在成本报表里。

这让采集性能不再只是"跑得快",而是一个工程化的综合指标:
- 吞吐:能否在峰值与抖动下持续处理海量日志/指标而不积压;
- 单位成本:在同样负载下占用多少 CPU/内存,是否会挤压应用的延迟预算;
- 稳定性:面对下游拥塞、网络抖动与多租户竞争,是否能提供可控背压与隔离。
所以我们需要的不是"能跑的采集器",而是一个在真实生产里长期成立的答案:高吞吐、低开销、可预期扩展,并且在拥塞与抖动下依然稳定。

LoongCollector 正是在这个目标下诞生并持续演进的。它的起点可以追溯到 2013 年的自研实践,随后伴随规模增长、上云迁移与容器化/Kubernetes 普及持续工程化打磨;到 2022 年,我们将其以 LoongCollector 的名字开源,并进一步演进为面向云原生场景的统一采集 OneAgent:在同一套运行时内,支持日志、指标(含 Prometheus 采集)、链路数据(OTLP/Trace)以及 eBPF/主机监控等多类可观测信号的采集与汇聚。
如今 LoongCollector 以千万级的装机量部署在在阿里、蚂蚁及数万家企业客户环境中,每天稳定采集百 PB 级可观测数据,覆盖日志与指标等场景,构建了云上统一采集层。

性能基准:数字不会说谎
当"每天处理 PB 级数据"本身就意味着巨额成本时,性能不再是锦上添花,而是底线工程。于是我们把 LoongCollector 与主流开源方案放到同一套可复现实验里做正面对比。
严谨的测试方法
- 硬件:阿里云 ECS g7(32 vCPU,64GB RAM)
- OS:Ubuntu 20.02(ext4)
- 磁盘:ESSD PL3 1500 GiB(76800 IOPS)
- 可复现性 :完整基准测试脚本见 GitHub(benchmark e2e README ** **1 )
正面对比:最大吞吐
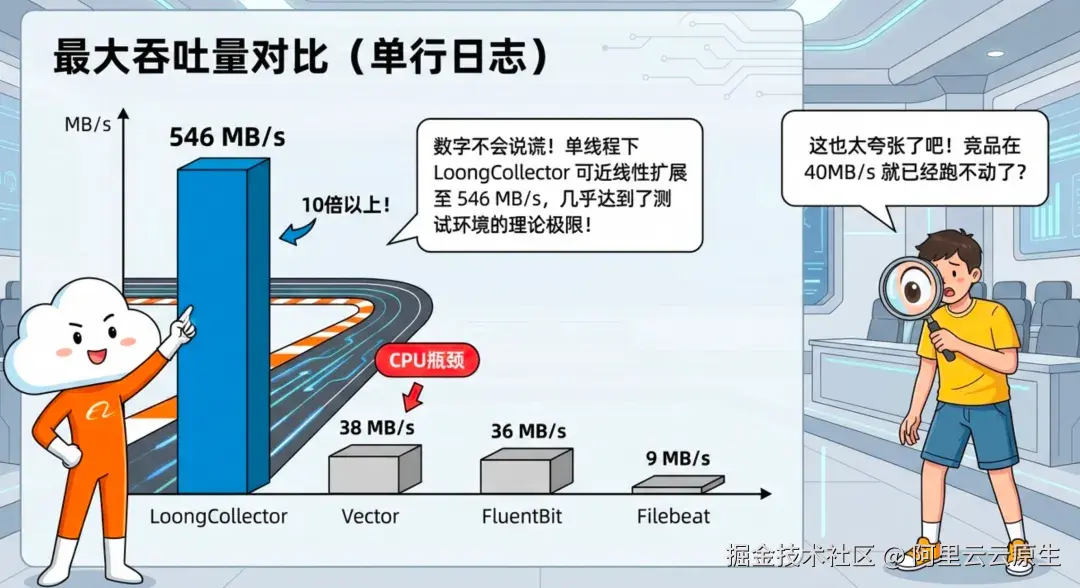
| 日志类型 | LoongCollector | FluentBit | Vector | Filebeat |
|---|---|---|---|---|
| 单行 | 546 MB/s | 36 MB/s | 38 MB/s | 9 MB/s |
| 多行 | 238 MB/s | 24 MB/s | 22 MB/s | 6 MB/s |
| 正则解析 | 68 MB/s | 19 MB/s | 12 MB/s | 不支持 |
对比中我们也观察到"拐点":不少方案在约 40 MB/s 时已接近 CPU 饱和,而 LoongCollector 在单线程下仍可近线性扩展至 546 MB/s(测试环境理论上限附近)。
资源效率:同样的 10 MB/s,谁更"省"

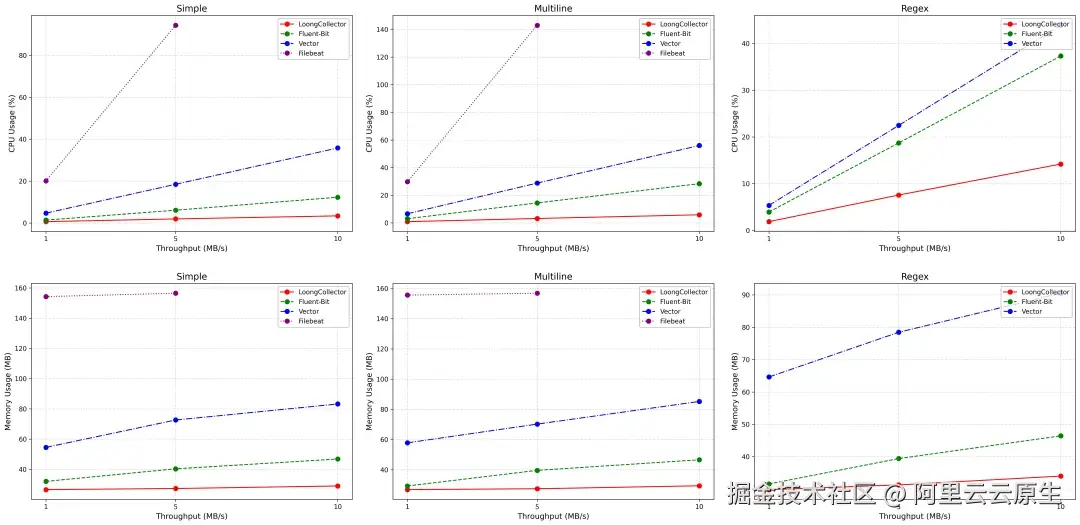
| 场景 | LoongCollector | FluentBit | Vector | Filebeat |
|---|---|---|---|---|
| 单行(512B) | 3.40% CPU29.01 MB RAM | 12.29% CPU(+261%)46.84 MB RAM(+61%) | 35.80% CPU(+952%)83.24 MB RAM(+186%) | 性能不足 |
| 多行(512B) | 5.82% CPU29.39 MB RAM | 28.35% CPU(+387%)46.39 MB RAM(+57%) | 55.99% CPU(+862%)85.17 MB RAM(+189%) | 性能不足 |
| 正则(512B) | 14.20% CPU34.02 MB RAM | 37.32% CPU(+162%)46.44 MB RAM(+36%) | 43.90% CPU(+209%)90.51 MB RAM(+166%) | 不支持 |
性能优势的关键结论
- 10 倍的最大吞吐:同样硬件能处理更多数据
- 80% 的资源下降:直接转化为成本节省
- 近线性扩展:更可预测、更好规划容量
- 可靠性不妥协:在高性能下仍强调"零数据丢失"的工程目标
- 原生多协议能力:OneAgent 的方式无缝处理日志、指标和跟踪,且不以牺牲性能为代价
技术深度探讨:性能架构
1)内存领域:零拷贝字符串处理(Memory Arena)
传统采集器在解析时容易出现"层层复制":一条日志进来,从原文到字段提取再到下游结构体,字符串反复分配与拷贝,CPU 时间与内存碎片都被悄悄吃掉。
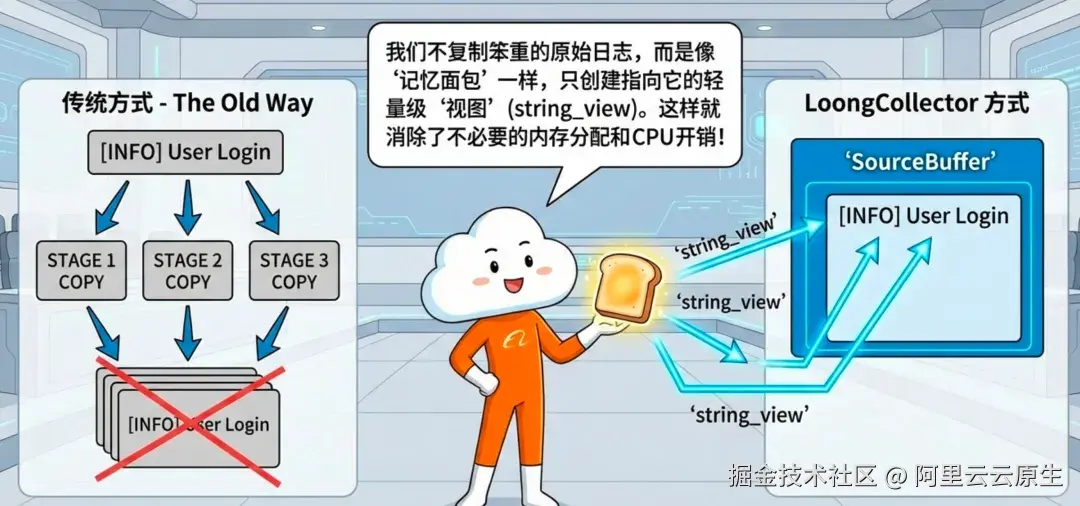
LoongCollector 的做法是:以 PipelineEventGroup 为单位,用共享内存池 SourceBuffer 存一次原始内容;字段提取不再复制字符串,而是用 string_view 指向原数据切片,实现"引用式解析"。
| 组件 | 传统方案 | LoongCollector | 改善 |
|---|---|---|---|
| 字符串拷贝 | 4 次 | 0 次 | 100% 消除 |
| 内存分配 | 按字段 | 按组 | 80% 减少 |
| 正则提取 | 4 次字段拷贝 | 4 个 string_view 引用 |
拷贝清零 |
| CPU 负担 | 高 | 低 | 约 15% 改善 |
2)无锁事件池架构:把"创建/销毁对象"从热路径里拿走
传统的日志代理会为每个日志条目创建和销毁 PipelineEvent 对象,从而导致频繁的内存分配和释放,此方法会导致大量的 CPU 开销(占总处理时间的 10%),并造成内存碎片。而简单的全局对象池又会在多线程下产生锁竞争,thread-local 池则难以覆盖跨线程交付场景。
LoongCollector 用线程感知的事件池策略,尽量做到"同线程无锁复用、跨线程批量转移",把同步成本压到最低。
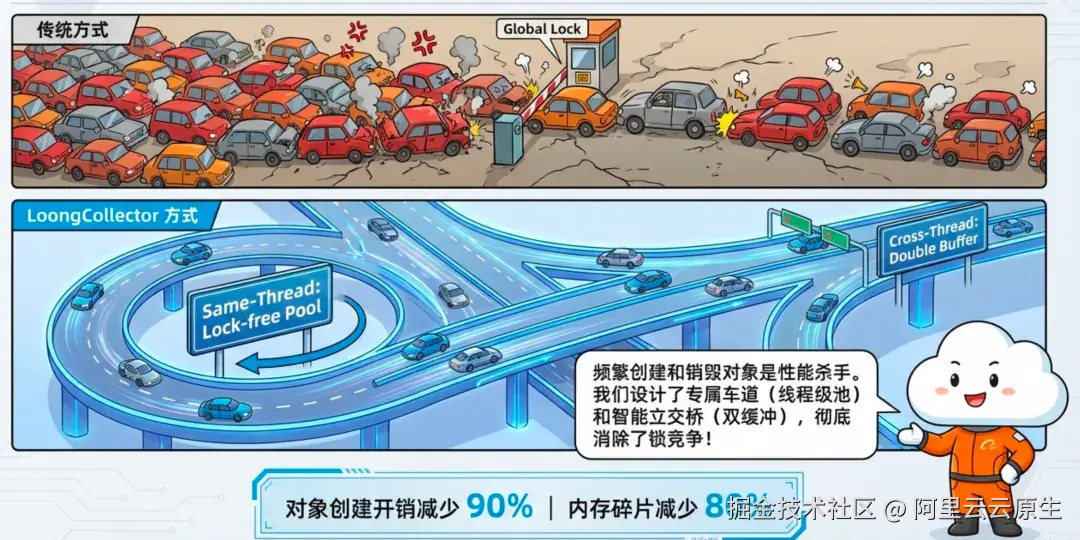
同线程分配/释放:线程级 Lock-free Pool
c
┌──────────────────┐
│ Processor Thread │──── [Lock-free Pool] ──── Direct Reuse
└──────────────────┘跨线程分配/释放:双缓冲 Pool + 批量回收
css
┌────────────────┐ ┌─────────────────┐
│ Input Thread │────▶│ Processor Thread│
└────────────────┘ └─────────────────┘
│ │
└── [Double Buffer Pool] ──┘- Input Runner:维护自己的事件池以进行分配
- Processor Runner:维护自己的事件池进行释放,支持按
PipelineEventGroup批量归还 - 仅在 Input 池空时触发批量转移
- 批量释放显著降低访问频率 90%
| 维度 | 传统方案 | LoongCollector | 改善 |
|---|---|---|---|
| 对象创建 | 事件级 | 池化复用 | 约 90% 减少 |
| 内存碎片 | 高 | 低 | 约 80% 减少 |
3)零拷贝序列化:绕过中间对象(直接写 Wire Format)
常见做法是先构造一层中间 Protobuf 对象,再序列化成字节流发往网络;在高吞吐场景下,这一步会带来额外的对象构造、拷贝与内存压力。
LoongCollector 直接按 Protobuf wire format 将 PipelineEventGroup 写成序列化字节,跳过中间对象。
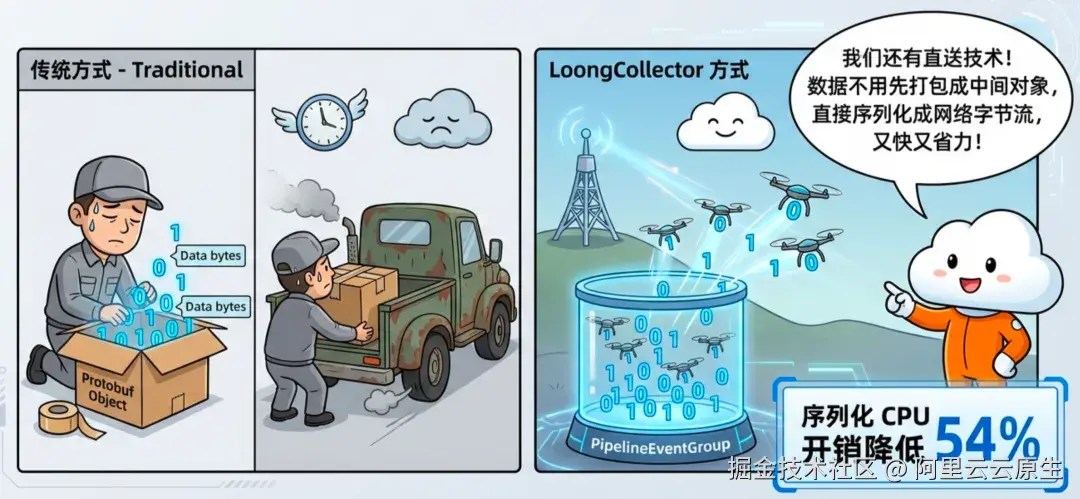
| 指标 | 传统方案 | LoongCollector | 改善 |
|---|---|---|---|
| 序列化 CPU 占比 | 12.5% | 5.8% | 54% 降低 |
| 内存拷贝/分配 | 3 次 | 1 次 | 67% 降低 |
技术深入探讨:可靠性架构------超越性能
1)多租户流水线隔离:高低水位反馈队列
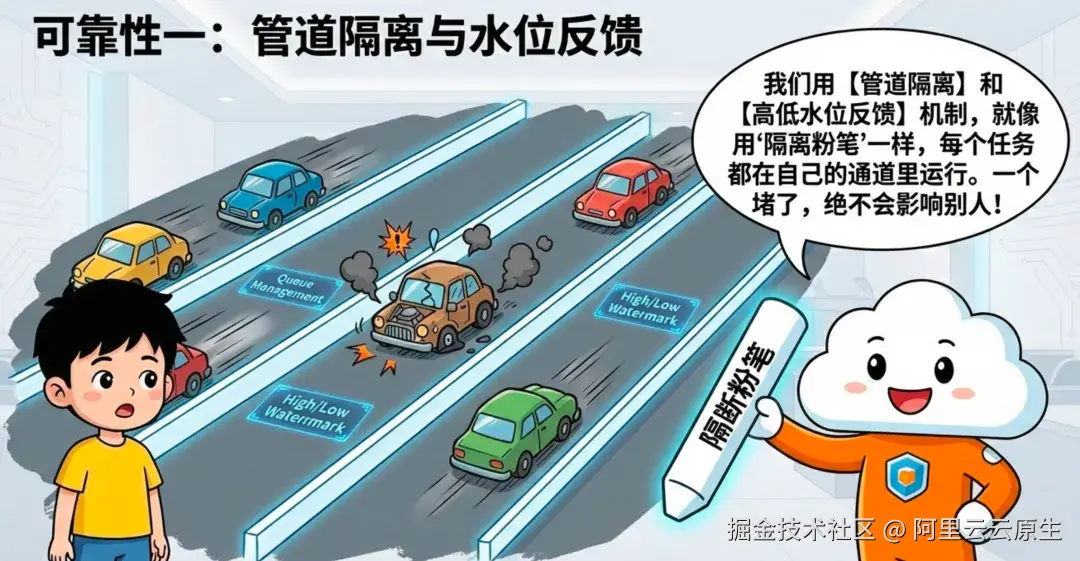
企业环境里往往同时运行多条 Pipeline:有的关键(安全/审计),有的普通(调试/业务埋点)。如果它们共享资源、缺乏隔离,就会出现"一个下游慢,全局都堵"的雪崩效应。
LoongCollector 采用多租户架构:每条 Pipeline 维护独立的有界队列,并在队列到达高水位/低水位时形成反馈链路,对上游施加背压与恢复信号,避免单条 Pipeline 影响全局。
高低水位反馈机制(示意)
kotlin
┌─ High-Low Watermark Feedback System ─────────────────────┐
│ │
│ ┌─ Queue State Management ─┐ ┌─ Feedback Mechanism ──┐ │
│ │ │ │ │ │
│ │ ┌─── Normal State ───┐ │ │ ┌──── Upstream ────┐ │ │
│ │ │ Size < Low │ │ │ │ Check │ │ │
│ │ │ Accept all data │ │ │ │ Before Write │ │ │
│ │ └────────────────────┘ │ │ └──────────────────┘ │ │
│ │ │ │ │ │ │
│ │ ▼ │ │ │ │
│ │ ┌── High Watermark ──┐ │ │ │ │
│ │ │ Size >= High │ │ │ ┌──── Downstream ──┐ │ │
│ │ │ Stop accepting │ │ │ │ Feedback Enabled │ │ │
│ │ │ non-urgent data │ │ │ └──────────────────┘ │ │
│ │ └────────────────────┘ │ │ │ │
│ │ │ │ │ │ │
│ │ ▼ │ │ │ │
│ │ ┌─ Recovery State ──┐ │ │ │ │
│ │ │ Size <= Low │ │ │ │ │
│ │ │ Resume accepting data │ │ │ │
│ │ └───────────────────┘ │ │ │ │
│ └──────────────────────────┘ └───────────────────────┘ │
└──────────────────────────────────────────────────────────┘- 独立队列管理:每个管道都维护自己的具有可配置容量的有界队列
- 反馈链路:下游拥塞时,上游可快速感知并降速
- 资源隔离:每个管道的内存和 CPU 分配可防止资源争用
- 自动恢复:处理恢复后,数据流自动回到正常状态
2)公平资源分配:多租户优先调度(Priority-aware Round-robin)

隔离只能避免"互相拖累",但还需要解决"谁先被服务"。LoongCollector 的调度策略强调两点:优先级严格生效 ,同时同一优先级内部公平轮转,避免"饿死"或长期偏置。
sql
┌─ High Priority ────────────────────────────────────────────────────┐
│ ┌───────────┐ │
│ │ Pipeline1 │ ◄─── Always processed first │
│ └───────────┘ │
│ │ │
│ ▼ (Priority transition) │
└────────────────────────────────────────────────────────────────────┘
┌─ Medium Priority (Round-robin cycle) ──────────────────────────────┐
│ ┌───────────┐ ┌─────────────────┐ ┌────────────┐ │
│ │ Pipeline2 │───▶│ Pipeline3(Last) │───▶│ Pipeline 4 │ │
│ └───────────┘ └─────────────────┘ └────────────┘ │
│ ▲ │ │
│ └────────────────────────────────────────┘ │
│ │
│ Note: Last processed was Pipeline3, so next starts from Pipeline4 │
│ │ │
│ ▼ (Priority transition) │
└────────────────────────────────────────────────────────────────────┘
┌─ Low Priority (Round-robin cycle) ─────────────────────────────────┐
│ ┌───────────┐ ┌───────────┐ │
│ │ Pipeline5 │───▶│ Pipeline6 │ │
│ └───────────┘ └───────────┘ │
│ ▲ │ │
│ └───────────────────┘ │
│ │
│ Note: Processed only when higher priority pipelines have no data │
└────────────────────────────────────────────────────────────────────┘3)故障隔离:自愈网络弹性(AIMD 自适应并发限制)
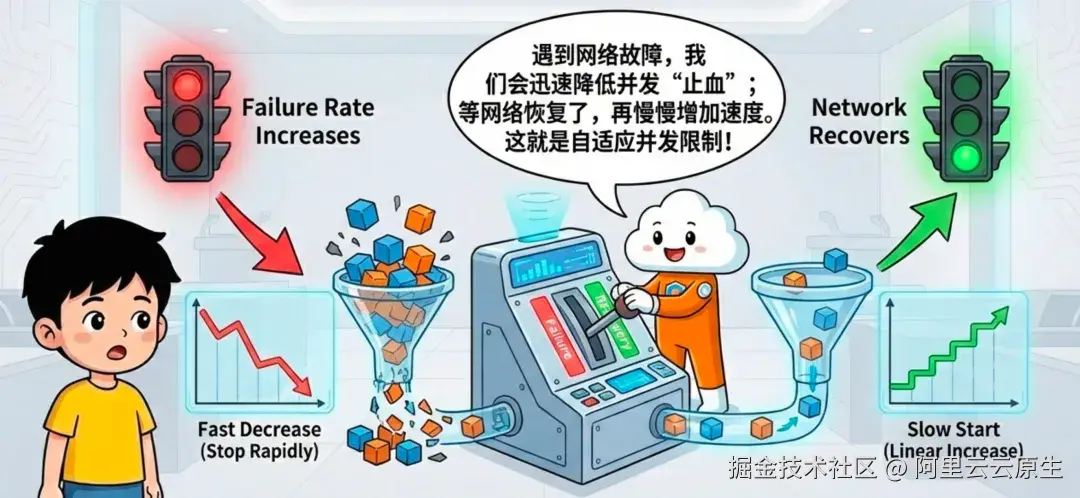
传统采集器面对某个目的端(destination)网络异常时,常见问题是:失败重试占满线程与队列,进而拖慢甚至影响其他目的端的正常发送。
LoongCollector 针对每个目的端引入自适应并发限制(受 AIMD:加性增、乘性减启发)。失败率升高时快速降并发,恢复稳定后再缓慢爬升,既能"止血",又能在网络恢复后及时自愈。
vbnet
┌─ ConcurrencyLimiter Configuration ───────────────────────────────────────┐
│ │
│ ┌─ Failure Rate Thresholds ────────────────────────────────────────────┐ │
│ │ │ │
│ │ ┌─ No Fallback Zone ─┐ ┌─ Slow Fallback Zone ─┐ ┌─ Fast Fallback ──┐ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ 0% ─────────── 10% │ │ 10% ──────────── 40% │ │ 40% ─────── 100% │ │ │
│ │ │ │ │ │ │ │ │ │
│ │ │ Maintain Current │ │ Multiply by 0.8 │ │ Multiply by 0.5 │ │ │
│ │ │ Concurrency │ │ (Slow Decrease) │ │ (Fast Decrease) │ │ │
│ │ └────────────────────┘ └──────────────────────┘ └──────────────────┘ │ │
│ └──────────────────────────────────────────────────────────────────────┘ │
│ │
│ ┌─ Recovery Mechanism ─┐ │
│ │ • Additive Increase │ ← +1 when success rate = 100% │
│ │ • Gradual Recovery │ ← Linear scaling back to max │
│ └──────────────────────┘ │
└──────────────────────────────────────────────────────────────────────────┘统计会以窗口/批次聚合,避免网络抖动引起并发剧烈震荡;当某个目的端出现异常时,其发送额度会迅速衰减,最大化降低对其他目的端的影响。
生产验证:经过大规模实战测试
LoongCollector 的"快"不是实验室产物,它是大规模生产的结果。作为阿里云 SLS(Simple Log Service) ** **2 的核心采集引擎之一,它承载着海量企业的真实负载。
- 日处理量:百 PB 级(通过 SLS)
- 实例规模:千万级生产部署
- 地域覆盖:50+ 国家与地区
- 企业级应用:金融、零售、制造领域的财富 500 强公司利用 SLS 支持的可观测性
在极端压测与演练中,也验证了:
- 可扩展性
- 最大集群压测中验证 1,000,000+ 实例级别高压场景
- 单机可支持 2k+ 并发 Pipeline,毫秒级延迟
- 并发下接近线性扩展
- 网络韧性
- 目标端网络故障下强调"零数据丢失"的工程目标,并提供长时间容错(例如 6 小时量级)
- 跨地域故障隔离(自适应并发限制)
- 背压与恢复联动,支持秒级自愈
- 混沌工程
- 随机 Pipeline 故障、10 倍流量尖刺
- 极端资源约束(CPU/内存/IO 逼近 90%)
- 跨地域网络退化与抖动
招聘:阿里云智能-AI Infra 可观测高级研发工程师-上海
前面聊了性能数字、也聊了背后的架构取舍。真正让这些结论成立的,不是某个"神奇优化",而是一群长期追求极致性能与稳定性的技术人:把每一次拷贝、每一次锁竞争、每一次序列化的中间对象,都当作可被削减的成本。

加入该岗位,你将参与构建面向 AI 时代的下一代可观测数据基础设施。
官网招聘链接:careers.aliyun.com/off-campus/...
你将做什么
- 打造国内超大规模的可观测基础设施:通过实时采集、索引、存储、压缩等技术,实时处理来自千万设备的海量日志数据,并针对 AI 应用场景进行特定优化,提供智能、自动化数据分析服务;
- 深度参与 AI Infra 核心能力建设:从数据采集到智能分析,构建面向 LLM、Agent、多模态等前沿 AI 场景的统一可观测底座;
- 开源引领行业标准:主导 LoongCollector 开源项目,推动云原生可观测采集器成为 AI 时代的新一代 OneAgent。
具体职责
- 参与阿里云战略级产品 SLS 研发,参与面向AI应用场景的数据采集、处理、查询分析等功能开发与设计;
- 参与千万级实例、数百 PB 流量的云原生可观测采集器 LoongCollector/iLogtail 及管控系统开发,打造云上统一的 OneAgent 能力,服务于日志、指标、eBPF、主机监控、安全等多种场景;
- 深度参与并打造高性能、高可靠的数据采集与管控系统,深入底层优化,提升网络、内存和 CPU 等关键资源的利用效率;
- 面向 AI 应用构建高性能、安全的多模态数据处理与数据集管理平台,参与上下游 AI 生态建设。
职位要求
-
扎实的算法基础和良好的编码习惯,精通 C++、Java、Go、Python 中任何一门语言;
-
在高性能数据结构、编码压缩、向量处理、异步 IO、内存管理、多线程并发等领域有深入实践;有 Linux 内核、eBPF 开发经验更佳;
-
理解分布式系统,包括调度、分布式锁、负载均衡等;
-
加分项(AI 相关)
-
熟悉 LLM 应用框架、Prompt 设计、Agent 框架(如 LangGraph、Dify、AutoGen、Google ADK、工具链集成等)者优先;
-
有 AI 训练/推理日志分析、Agent 行为追踪、多模态数据处理经验者优先;
-
-
对 LoongCollector、OpenTelemetry、Fluentbit、Vector、Tetragon、Falco 源代码有深入研究者优先;
-
有强烈技术热情和好奇心,自我驱动能力和学习能力强;
-
具备良好的分析解决问题的能力、沟通以及团队合作能力;
-
喜欢挑战性的技术研发工作,善于攻坚克难,有创新热情,积极乐观,坚韧抗压,结果导向,能够持续推动技术问题的解决和突破。
相关链接:
1 benchmark e2e README
2 阿里云 SLS(Simple Log Service)