前言
-
Unitree RL GYM是一个开源的基于 Unitree 机器人强化学习(Reinforcement Learning, RL)控制示例项目,用于训练、测试和部署四足机器人控制策略。该仓库支持多种 Unitree 机器人型号,包括Go2、H1、H1_2 和 G1。仓库地址
-
本系列将着手解析整个仓库的核心代码与算法实现和训练教程。此系列默认读者拥有一定的强化学习基础和代码基础,故在部分原理和基础代码逻辑不做解释,对强化学习基础感兴趣的读者可以阅读我的入门系列:
- 第一期: 【浅显易懂理解强化学习】(一)Q-Learning原来是查表法-CSDN博客
- 第二期: 【浅显易懂理解强化学习】(二):Sarsa,保守派的胜利-CSDN博客
- 第三期:【浅显易懂理解强化学习】(三):DQN:当查表法装上大脑-CSDN博客
- 第四期:【浅显易懂理解强化学习】(四):Policy Gradients玩转策略采样-CSDN博客
- 第五期:【浅显易懂理解强化学习】(五):Actor-Critic与A3C,多线程的完全胜利-CSDN博客
- 第六期:【浅显易懂理解强化学习】(六):DDPG与TD3集百家之长-CSDN博客
- 第七期:【浅显易懂理解强化学习】(七):PPO,策略更新的安全阀-CSDN博客
-
阅读本系列的前置知识:
python语法,明白面向对象的封装pytorch基础使用- 神经网络基础知识
- 强化学习基础知识,至少了解
Policy Gradient、Actor-Critic和PPO
-
本系列:
-
前几期我们分析完了负责模型训练的
train.py和负责模型检验的play.py,同时我们还讲解负责管理训练参数的LeggedRobotCfg和LeggedRobotCfgPPO,以及我们分别研究了LeggedRobot类中每一个奖励函数是如何实现的。 -
本期是一个阶段总结篇,我们将进一步解构训练输出的平均奖励计算并使用
TensorBoard查看我们训练的结果,同时我们将实现一个手柄控制程序控制go2机械狗运行来验收我们的模型结果。 -
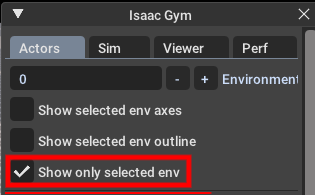
一个小提示:在训练中通过关闭大量机器人的可视化可以大幅加速训练速度
0 前置知识 TensorBoard
0-1 介绍
- TensorBoard 是由 TensorFlow 团队开发的可视化工具,但可以通过
torch.utils.tensorboard.SummaryWriter在 PyTorch 中使用。 - 用途:监控训练过程中的各种指标、帮助调试和分析模型性能。
- 它主要能做的事情:
- 绘制训练损失曲线(Loss)
- 绘制奖励曲线(Reward)
- 绘制学习率变化(Learning rate)
- 绘制自定义指标(如策略噪声、FPS 等)
- 可视化模型图、参数直方图等
0-2 使用
- 查看 TensorBoard:
bash
tensorboard --logdir=runs- 其中
--logdir=runs:告诉 TensorBoard 去runs目录读取日志 - 然后在浏览器访问:
http://localhost:6006
0-3 面板
- 通常,TensorBoard 里有几个主要的面板(Tabs):
| 面板 | 显示的数据 | 要求 / 特点 |
|---|---|---|
| Scalars | 训练指标随迭代变化的曲线(Loss、Reward、Learning rate 等) | 只要你用 add_scalar() 写入了数据,就能看到 |
| Time Series | 训练指标随真实时间(wall-clock time)变化的曲线 | 要求写入时使用 wall-clock timestamp 或 global_step 配合 summary_metadata.plugin_data 才能识别 |
- 一般使用
Scalars就够了,Time Series 很少用
1 TensorBoard图表与日志输出
1-1 日志输出代码一览
- 我们曾经在第四期提到过运行训练文件train.py会有如下输出
bash
################################################################################
Learning iteration 1499/1500
Computation: 36332 steps/s (collection: 0.584s, learning 0.077s)
Value function loss: 0.0051
Surrogate loss: -0.0077
Mean action noise std: 0.56
Mean reward: 19.65
Mean episode length: 987.43
Mean episode rew_action_rate: -0.1009
Mean episode rew_ang_vel_xy: -0.0946
Mean episode rew_collision: -0.0000
Mean episode rew_dof_acc: -0.0900
Mean episode rew_dof_pos_limits: -0.0045
Mean episode rew_lin_vel_z: -0.0282
Mean episode rew_torques: -0.0663
Mean episode rew_tracking_ang_vel: 0.4226
Mean episode rew_tracking_lin_vel: 0.9249
--------------------------------------------------------------------------------
Total timesteps: 36000000
Iteration time: 0.66s
Total time: 982.22s
ETA: 0.7s- 这个输出函数来自
rsl_rl/runners/on_policy_runner.py中的log()- 当时在第三期讲解
OnPolicyRunner跳过了这个函数,现在我们有了上一期各项奖励函数的解释和实现,我们现在可以很好的来看看这个平均奖励是如何实现的。
- 当时在第三期讲解
- 下面是
log函数的完整实现:
python
def log(self, locs, width=80, pad=35):
self.tot_timesteps += self.num_steps_per_env * self.env.num_envs
self.tot_time += locs['collection_time'] + locs['learn_time']
iteration_time = locs['collection_time'] + locs['learn_time']
ep_string = f''
if locs['ep_infos']:
for key in locs['ep_infos'][0]:
infotensor = torch.tensor([], device=self.device)
for ep_info in locs['ep_infos']:
# handle scalar and zero dimensional tensor infos
if not isinstance(ep_info[key], torch.Tensor):
ep_info[key] = torch.Tensor([ep_info[key]])
if len(ep_info[key].shape) == 0:
ep_info[key] = ep_info[key].unsqueeze(0)
infotensor = torch.cat((infotensor, ep_info[key].to(self.device)))
value = torch.mean(infotensor)
self.writer.add_scalar('Episode/' + key, value, locs['it'])
ep_string += f"""{f'Mean episode {key}:':>{pad}} {value:.4f}\n"""
mean_std = self.alg.actor_critic.std.mean()
fps = int(self.num_steps_per_env * self.env.num_envs / (locs['collection_time'] + locs['learn_time']))
self.writer.add_scalar('Loss/value_function', locs['mean_value_loss'], locs['it'])
self.writer.add_scalar('Loss/surrogate', locs['mean_surrogate_loss'], locs['it'])
self.writer.add_scalar('Loss/learning_rate', self.alg.learning_rate, locs['it'])
self.writer.add_scalar('Policy/mean_noise_std', mean_std.item(), locs['it'])
self.writer.add_scalar('Perf/total_fps', fps, locs['it'])
self.writer.add_scalar('Perf/collection time', locs['collection_time'], locs['it'])
self.writer.add_scalar('Perf/learning_time', locs['learn_time'], locs['it'])
if len(locs['rewbuffer']) > 0:
self.writer.add_scalar('Train/mean_reward', statistics.mean(locs['rewbuffer']), locs['it'])
self.writer.add_scalar('Train/mean_episode_length', statistics.mean(locs['lenbuffer']), locs['it'])
self.writer.add_scalar('Train/mean_reward/time', statistics.mean(locs['rewbuffer']), self.tot_time)
self.writer.add_scalar('Train/mean_episode_length/time', statistics.mean(locs['lenbuffer']), self.tot_time)
str = f" \033[1m Learning iteration {locs['it']}/{self.current_learning_iteration + locs['num_learning_iterations']} \033[0m "
if len(locs['rewbuffer']) > 0:
log_string = (f"""{'#' * width}\n"""
f"""{str.center(width, ' ')}\n\n"""
f"""{'Computation:':>{pad}} {fps:.0f} steps/s (collection: {locs[
'collection_time']:.3f}s, learning {locs['learn_time']:.3f}s)\n"""
f"""{'Value function loss:':>{pad}} {locs['mean_value_loss']:.4f}\n"""
f"""{'Surrogate loss:':>{pad}} {locs['mean_surrogate_loss']:.4f}\n"""
f"""{'Mean action noise std:':>{pad}} {mean_std.item():.2f}\n"""
f"""{'Mean reward:':>{pad}} {statistics.mean(locs['rewbuffer']):.2f}\n"""
f"""{'Mean episode length:':>{pad}} {statistics.mean(locs['lenbuffer']):.2f}\n""")
# f"""{'Mean reward/step:':>{pad}} {locs['mean_reward']:.2f}\n"""
# f"""{'Mean episode length/episode:':>{pad}} {locs['mean_trajectory_length']:.2f}\n""")
else:
log_string = (f"""{'#' * width}\n"""
f"""{str.center(width, ' ')}\n\n"""
f"""{'Computation:':>{pad}} {fps:.0f} steps/s (collection: {locs[
'collection_time']:.3f}s, learning {locs['learn_time']:.3f}s)\n"""
f"""{'Value function loss:':>{pad}} {locs['mean_value_loss']:.4f}\n"""
f"""{'Surrogate loss:':>{pad}} {locs['mean_surrogate_loss']:.4f}\n"""
f"""{'Mean action noise std:':>{pad}} {mean_std.item():.2f}\n""")
# f"""{'Mean reward/step:':>{pad}} {locs['mean_reward']:.2f}\n"""
# f"""{'Mean episode length/episode:':>{pad}} {locs['mean_trajectory_length']:.2f}\n""")
log_string += ep_string
log_string += (f"""{'-' * width}\n"""
f"""{'Total timesteps:':>{pad}} {self.tot_timesteps}\n"""
f"""{'Iteration time:':>{pad}} {iteration_time:.2f}s\n"""
f"""{'Total time:':>{pad}} {self.tot_time:.2f}s\n"""
f"""{'ETA:':>{pad}} {self.tot_time / (locs['it'] + 1) * (
locs['num_learning_iterations'] - locs['it']):.1f}s\n""")
print(log_string)1-2 具体实现
- 我们来一步步看这里头是如何计算平均奖励并输出的
1-2-1 函数定义
python
def log(self, locs, width=80, pad=35):-
locs:类型是dict,用来传递本次训练迭代的各种局部指标(local statistics),比如:locs['ep_infos']:本轮 episode 信息列表(reward、长度等)
locs['collection_time']:收集数据时间locs['learn_time']:策略更新时间locs['mean_value_loss']/locs['mean_surrogate_loss']:损失locs['rewbuffer']/locs['lenbuffer']:奖励和长度缓存
-
width:用于控制打印日志的总宽度,使输出整齐。 -
pad:用于控制标签和值之间的对齐长度。
1-2-2 累加总步数和总时间
python
self.tot_timesteps += self.num_steps_per_env * self.env.num_envs
self.tot_time += locs['collection_time'] + locs['learn_time']
iteration_time = locs['collection_time'] + locs['learn_time']self.tot_timesteps:训练到现在总的环境交互步数。self.num_steps_per_env * self.env.num_envs= 每个环境本次训练循环步数 × 环境数量。
self.tot_time:累加训练时间,包括收集数据时间 + 学习更新时间。iteration_time:本次迭代花费的时间。
1-2-3 处理 episode 信息,计算平均奖励并写入 TensorBoard(核心)
python
ep_string = f''
if locs['ep_infos']:
for key in locs['ep_infos'][0]:
infotensor = torch.tensor([], device=self.device)
for ep_info in locs['ep_infos']:
# handle scalar and zero dimensional tensor infos
if not isinstance(ep_info[key], torch.Tensor):
ep_info[key] = torch.Tensor([ep_info[key]])
if len(ep_info[key].shape) == 0:
ep_info[key] = ep_info[key].unsqueeze(0)
infotensor = torch.cat((infotensor, ep_info[key].to(self.device)))
value = torch.mean(infotensor)
self.writer.add_scalar('Episode/' + key, value, locs['it'])
ep_string += f"""{f'Mean episode {key}:':>{pad}} {value:.4f}\n"""locs['ep_infos']:是一个列表,每个元素包含本轮收集到的episode信息,比如 reward、episode length 等。- 循环每个指标
key(如 reward、length):- 把所有 episode 的值堆到一个 tensor 中。
- 对 tensor 取平均值 → 得到本次迭代的平均值。
torch.mean() - 写入 TensorBoard:
Episode/<指标>。 - 拼接成打印字符串
ep_string。
1-2-4 处理 episode 信息并写入 TensorBoard
python
mean_std = self.alg.actor_critic.std.mean()
fps = int(self.num_steps_per_env * self.env.num_envs / (locs['collection_time'] + locs['learn_time']))mean_std:当前策略的动作噪声平均标准差(衡量探索程度)。fps:每秒处理步数(Frame Per Second),用于性能指标。
1-2-5 写入 Loss 和性能指标到 TensorBoard
python
self.writer.add_scalar('Loss/value_function', locs['mean_value_loss'], locs['it'])
self.writer.add_scalar('Loss/surrogate', locs['mean_surrogate_loss'], locs['it'])
self.writer.add_scalar('Loss/learning_rate', self.alg.learning_rate, locs['it'])
self.writer.add_scalar('Policy/mean_noise_std', mean_std.item(), locs['it'])
self.writer.add_scalar('Perf/total_fps', fps, locs['it'])
self.writer.add_scalar('Perf/collection time', locs['collection_time'], locs['it'])
self.writer.add_scalar('Perf/learning_time', locs['learn_time'], locs['it'])self.writer是 PyTorch TensorBoard 的SummaryWriter对象 ,它负责把训练过程中的标量、图像、模型参数等写入 日志文件 ,以便你在 TensorBoard 中可视化。value_function:价值函数损失。surrogate:策略优化损失。learning_rate:当前学习率。mean_noise_std:动作噪声 std。total_fps:每秒处理步数。collection_time/learning_time:时间指标。
1-2-6 写入训练奖励和长度指标
python
if len(locs['rewbuffer']) > 0:
self.writer.add_scalar('Train/mean_reward', statistics.mean(locs['rewbuffer']), locs['it'])
self.writer.add_scalar('Train/mean_episode_length', statistics.mean(locs['lenbuffer']), locs['it'])
self.writer.add_scalar('Train/mean_reward/time', statistics.mean(locs['rewbuffer']), self.tot_time)
self.writer.add_scalar('Train/mean_episode_length/time', statistics.mean(locs['lenbuffer']), self.tot_time)locs['rewbuffer']/locs['lenbuffer']:存储最近收集的 reward 和 episode 长度。- 写入 TensorBoard,可以按迭代或总时间做横坐标。
1-2-7 打印信息
python
str = f" \033[1m Learning iteration {locs['it']}/{self.current_learning_iteration + locs['num_learning_iterations']} \033[0m "
print(log_string) 1-3 使用TensorBoard
- 完成一次训练后,我们打开最新一次训练的日志文件夹
- 例如:
unitree_rl_gym/logs/rough_go2/Mar19_14-09-10_
- 例如:
- 我们可以看到这样的文件结构
bash
.
├── logs
│ └── rough_go2
│ └── Mar19_14-09-10_
│ ├── events.out.tfevents.1773900551.lzh.25216.0
│ ├── model_0.pt
│ ....
│ ├── model_1500.pt
│ - 其中:
events.out.tfevents.*:TensorBoard 日志文件,记录训练指标(如 reward、loss、FPS 等)。可以用 TensorBoard 打开查看训练曲线。model_*.pt:保存的模型权重文件,数字表示训练迭代次数。可以用来恢复训练或做推理。
- 打开终端,进入训练日志的上级目录:
bash
cd unitree_rl_gym/logs/rough_go2
tensorboard --logdir=Mar19_14-09-10_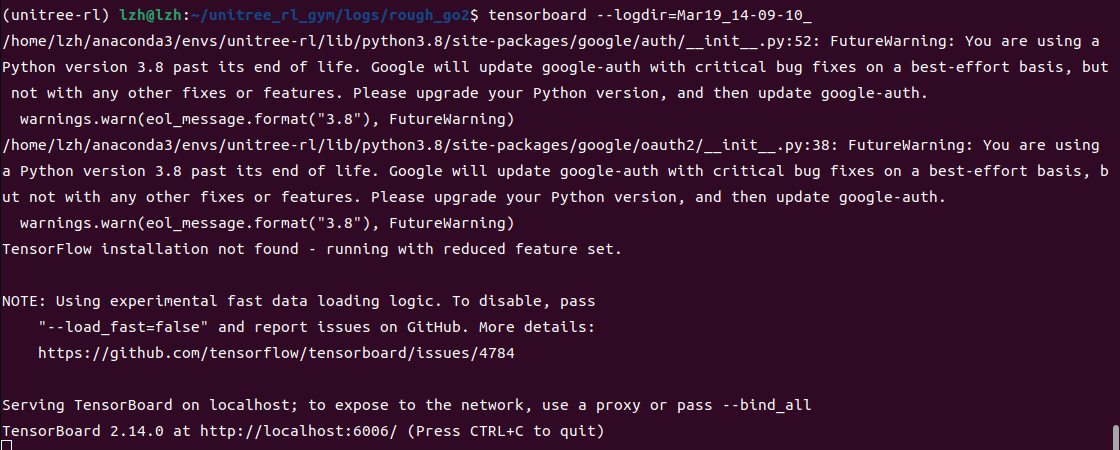
-
然后我们直接通过浏览器访问
1-4 查看图表
-
声明:这个模型还没优化!!!只是随便训练1500轮的普通模型,这里展示仅做示范!!!
-
由于我们在
log函数中是通过self.writer.add_scalar写入的数据,因此我们在打开TensorBoard后点击左上方的SCALARS
-
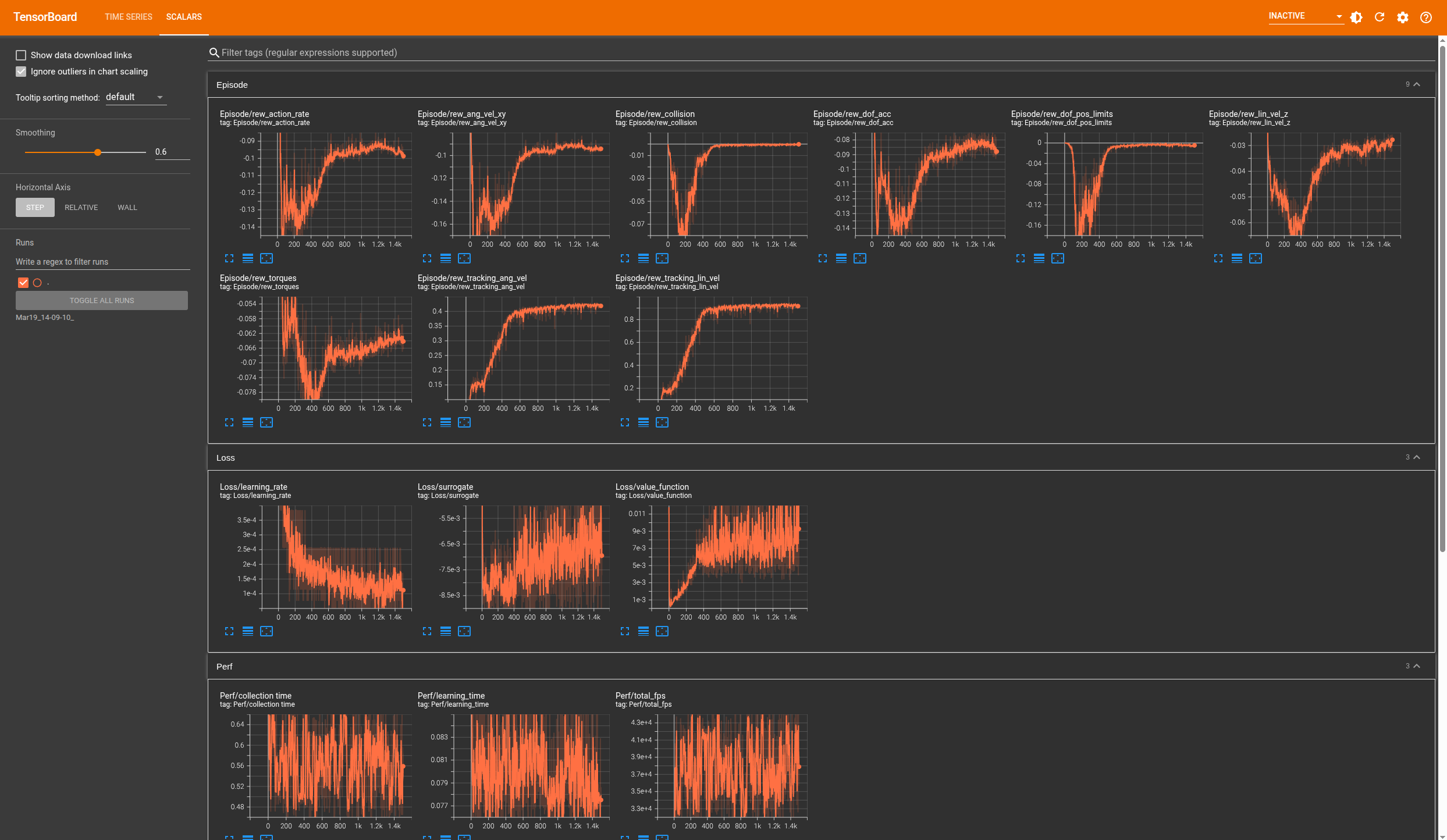
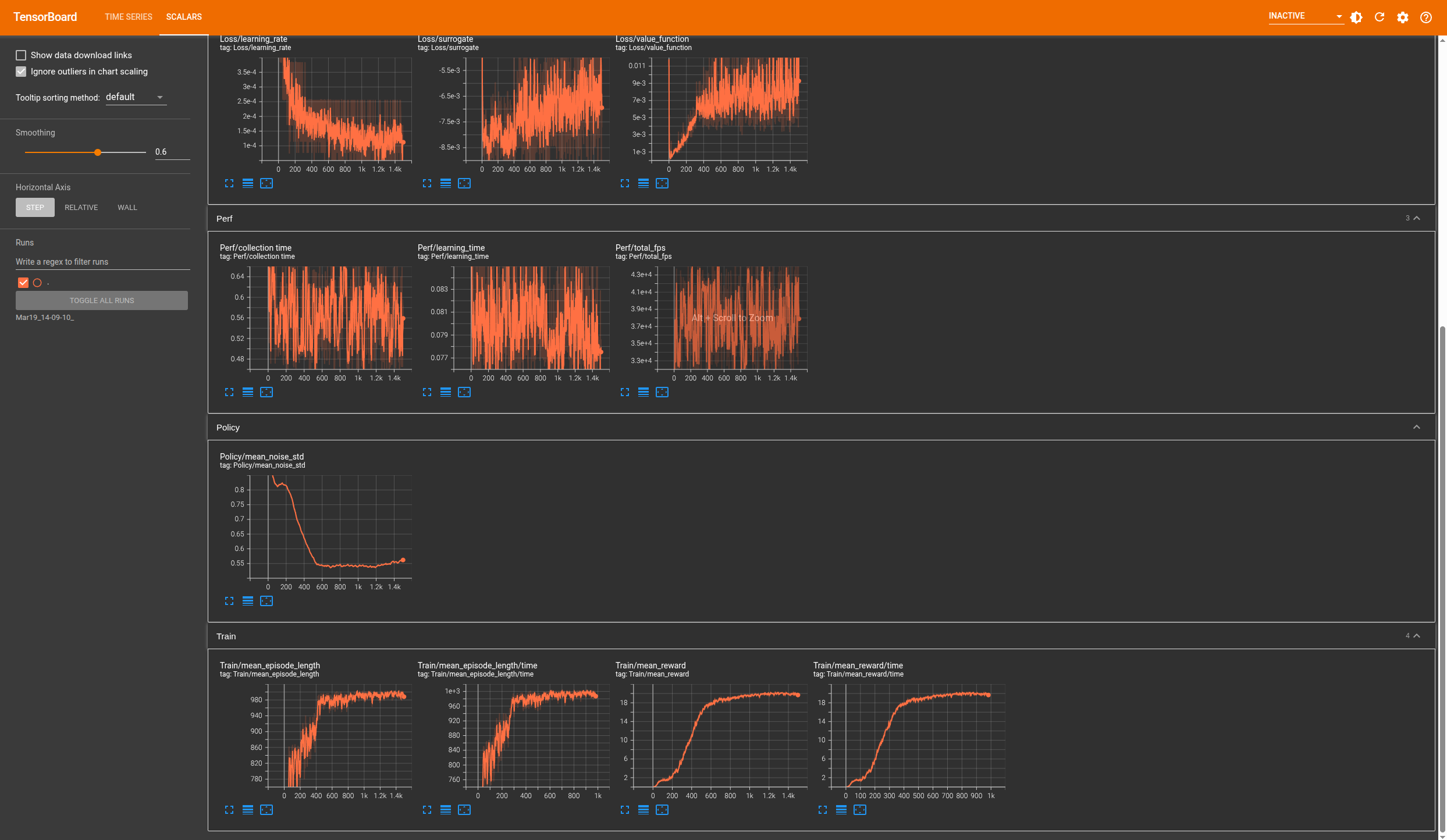
然后我们就可以很直观的看到各项指标的图表
1-4-1 Policy/mean_noise_std
-
这里我们随便找个表来看看
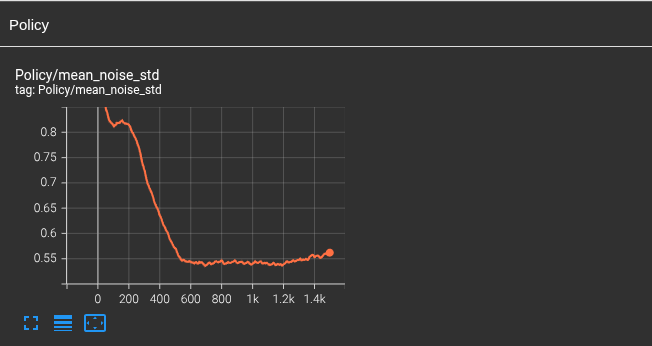
-
mean_std:所有动作维度的平均噪声,它本质上控制探索强度:- std 越大 → 动作随机性越大 → 探索越多;
- std 越小 → 动作越确定 → 利用当前策略更多
-
可以看到图中的曲线正在慢慢下降,这说明训练过程在逐步收敛,策略正在从"探索"过渡到"利用",这就是 PPO 中策略分布逐渐收缩(variance reduction)的表现
1-5 日志输出间隔
- 详细了解完
self.log()函数,我们来看看self.log()函数的调用: - 同样位于
rsl_rl/runners/on_policy_runner.py
python
def learn(self, num_learning_iterations, init_at_random_ep_len=False):
# 省略其他代码
tot_iter = self.current_learning_iteration + num_learning_iterations
for it in range(self.current_learning_iteration, tot_iter):
start = time.time()
# Rollout
with torch.inference_mode():
for i in range(self.num_steps_per_env):
# 省略其他代码
stop = time.time()
collection_time = stop - start
# Learning step
start = stop
self.alg.compute_returns(critic_obs)
mean_value_loss, mean_surrogate_loss = self.alg.update()
stop = time.time()
learn_time = stop - start
if self.log_dir is not None:
self.log(locals())
if it % self.save_interval == 0:
self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(it)))
ep_infos.clear()
self.current_learning_iteration += num_learning_iterations
self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(self.current_learning_iteration)))- 可以看到,
self.log(locals())在每个iterations中被调用,而每个iterations又包含多个num_steps_per_env- 补充:
locals()是 Python 的一个内置函数,会返回当前作用域中的所有局部变量(local variables),以字典形式返回
- 补充:
- 也就是说,
self.log中计算的Mean episode是基于 本 iteration 收集到的所有 episode(结束的轨迹)
1-6 自定义log函数
- 在明白
log函数后,我们就可以实现自己的log函数 - 通常在训练过程中,除了可以观察各项指标的曲线,或者
log函数计算的各项指标,我们还可以添加自己想显示的指标。 - 举个例子,我想统计俯仰角超过阈值的机器人数量,那么我们可以这样实现:
python
def log_envs(self):
pos = self.env.root_states[:, :3]
rpy_deg = self.env.rpy * (180.0 / 3.1415926)
z_mean = pos[:, 2].mean().item()
rpy_mean = rpy_deg.mean(dim=0).cpu().numpy().round(3)
# 输出所有机器人当前iter的平均z以及rpy的角度值
print(f"Mean z: {z_mean:.3f}, Mean RPY (deg): {rpy_mean}")
# 统计俯仰角超过阈值的机器人数量
pitch_threshold = 10.0 # 设置俯仰角阈值
over_threshold_count = torch.sum(torch.abs(rpy_deg[:, 0]) > pitch_threshold).item() # 统计超出阈值的数量
print(f"Number of robots with pitch over {pitch_threshold}°: {over_threshold_count}")- 需要注意的是,
log函数会在每个iterations被调用,因此我们拿到的所有数据是单次iterations中全部的steps所产生的数据:self.env.root_states:[[x,y,z],[x,y,z],[x,y,z]....]self.env.rpy:[[r,p,y],[r,p,y],[r,p,y]....]
- 同时需要注意的是,这些数据不是
np数组,而是torch.Tensor(通常在 GPU 上) ,如果需要进行进一步处理或打印,需要进行类型转换:.cpu():从 GPU 拷贝到 CPU.numpy():转为 NumPy 数组.item():转为 Python 标量
- 然后我们可以在
log函数调用我们自定义的函数,就可以实现信息的打印了
python
def log(self, locs, width=80, pad=35):
# 省略其他代码...
print(log_string)
self.log_envs()- 通过输出,我们可以看到俯仰角超过阈值的机器人在不断减少,机器人也在减少以头抢地的次数

2 手柄遥控测试
2-1 commands
- 在我们实现自己的遥控代码检验模型之前,我们需要搞清楚一件事,也就是模型是如何进行目标设定的。
- 我们打开
legged_gym/envs/base/legged_robot_config.py
python
class LeggedRobotCfg(BaseConfig):
class commands:
curriculum = False
max_curriculum = 1.
num_commands = 4 # default: lin_vel_x, lin_vel_y, ang_vel_yaw, heading (in heading mode ang_vel_yaw is recomputed from heading error)
resampling_time = 10. # time before command are changed[s]
heading_command = True # if true: compute ang vel command from heading error
class ranges:
lin_vel_x = [-1.0, 1.0] # min max [m/s]
lin_vel_y = [-1.0, 1.0] # min max [m/s]
ang_vel_yaw = [-1, 1] # min max [rad/s]
heading = [-3.14, 3.14]- 其中关键的内容就是
ranges,这里制定了训练目标的范围 - 每个环境(机器人)都有一个
commands向量:
python
[lin_vel_x, lin_vel_y, ang_vel_yaw, heading]- 也就是在每次训练中,模型每隔一段时间(
resampling_time)都会随机在这个范围随机挑选一个值进行训练,同时根据奖励项系数去逼近目标值
python
class LeggedRobotCfg(BaseConfig):
class rewards:
class scales:
tracking_lin_vel = 1.0
tracking_ang_vel = 0.5
ang_vel_xy = -0.05- 而这个
command会被采样进观测值进行训练:
python
obs = [
base_vel,
joint_pos,
joint_vel,
gravity,
commands ← 关键
]- 当然在
play阶段,我们直接手动覆盖env.commands,因此不会再使用 ranges 中的随机采样逻辑
2-2 手柄控制
- 那么我们要做的事情很简单了,在运行
play.py进行模型验证的时候,手动映射手柄遥感和LeggedRobotCfg中的commands的ranges即可 - 手柄的绑定我们使用最基础的
pygame - 这里直接贴上我修改后的
legged_gym/scripts/play.py:
python
import sys
from legged_gym import LEGGED_GYM_ROOT_DIR
import os
import sys
from legged_gym import LEGGED_GYM_ROOT_DIR
import isaacgym
from legged_gym.envs import *
from legged_gym.utils import get_args, export_policy_as_jit, task_registry, Logger
import numpy as np
import torch
import pygame
def play(args):
env_cfg, train_cfg = task_registry.get_cfgs(name=args.task)
# override some parameters for testing
env_cfg.env.num_envs = min(env_cfg.env.num_envs, 100)
env_cfg.terrain.num_rows = 5
env_cfg.terrain.num_cols = 5
env_cfg.terrain.curriculum = False
env_cfg.noise.add_noise = False
env_cfg.domain_rand.randomize_friction = False
env_cfg.domain_rand.push_robots = False
env_cfg.env.test = True
# prepare environment
env, _ = task_registry.make_env(name=args.task, args=args, env_cfg=env_cfg)
obs = env.get_observations()
# load policy
train_cfg.runner.resume = True
ppo_runner, train_cfg = task_registry.make_alg_runner(env=env, name=args.task, args=args, train_cfg=train_cfg)
policy = ppo_runner.get_inference_policy(device=env.device)
# export policy as a jit module (used to run it from C++)
if EXPORT_POLICY:
path = os.path.join(LEGGED_GYM_ROOT_DIR, 'logs', train_cfg.runner.experiment_name, 'exported', 'policies')
export_policy_as_jit(ppo_runner.alg.actor_critic, path)
print('Exported policy as jit script to: ', path)
# 配置游戏手柄
gamepad=init_gamepad()
for i in range(100*int(env.max_episode_length)):
# 手柄设置机器人指令
setCommand(env,gamepad)
actions = policy(obs.detach())
obs, _, rews, dones, infos = env.step(actions.detach())
def apply_deadzone(value, deadzone=0.1):
if abs(value) < deadzone:
return 0.0
return value
def setCommand(env, gamepad):
# 刷新输入设备状态(手柄/键盘)
pygame.event.pump()
# 左遥感:gamepad.get_axis(0):左边-1,右边1
# 左遥感:gamepad.get_axis(1):前推-1,后推1
raw_vx = -gamepad.get_axis(1)
raw_vy = -gamepad.get_axis(0)
# 加死区
vx = apply_deadzone(raw_vx, 0.1)
vy = apply_deadzone(raw_vy, 0.1)
print(vx,vy)
env.commands[:, 0] = vx
env.commands[:, 1] = vy
# 只有在有输入时才更新方向
if vx != 0 or vy != 0:
heading = np.arctan2(vy, vx) # yaw
env.commands[:, 3] = heading # heading
def init_gamepad():
pygame.init()
pygame.joystick.init()
joystick = pygame.joystick.Joystick(0)
joystick.init()
return joystick
if __name__ == '__main__':
EXPORT_POLICY = True
RECORD_FRAMES = False
MOVE_CAMERA = False
args = get_args()
play(args)-
注意:当 heading_command=True 时,ang_vel_yaw 会根据 heading 自动计算, 因此我们只需要控制 heading,不需要手动设置 yaw 角速度
-
在模型训练好的情况下,可以看到go2基本整齐划一的朝着手柄方向前进
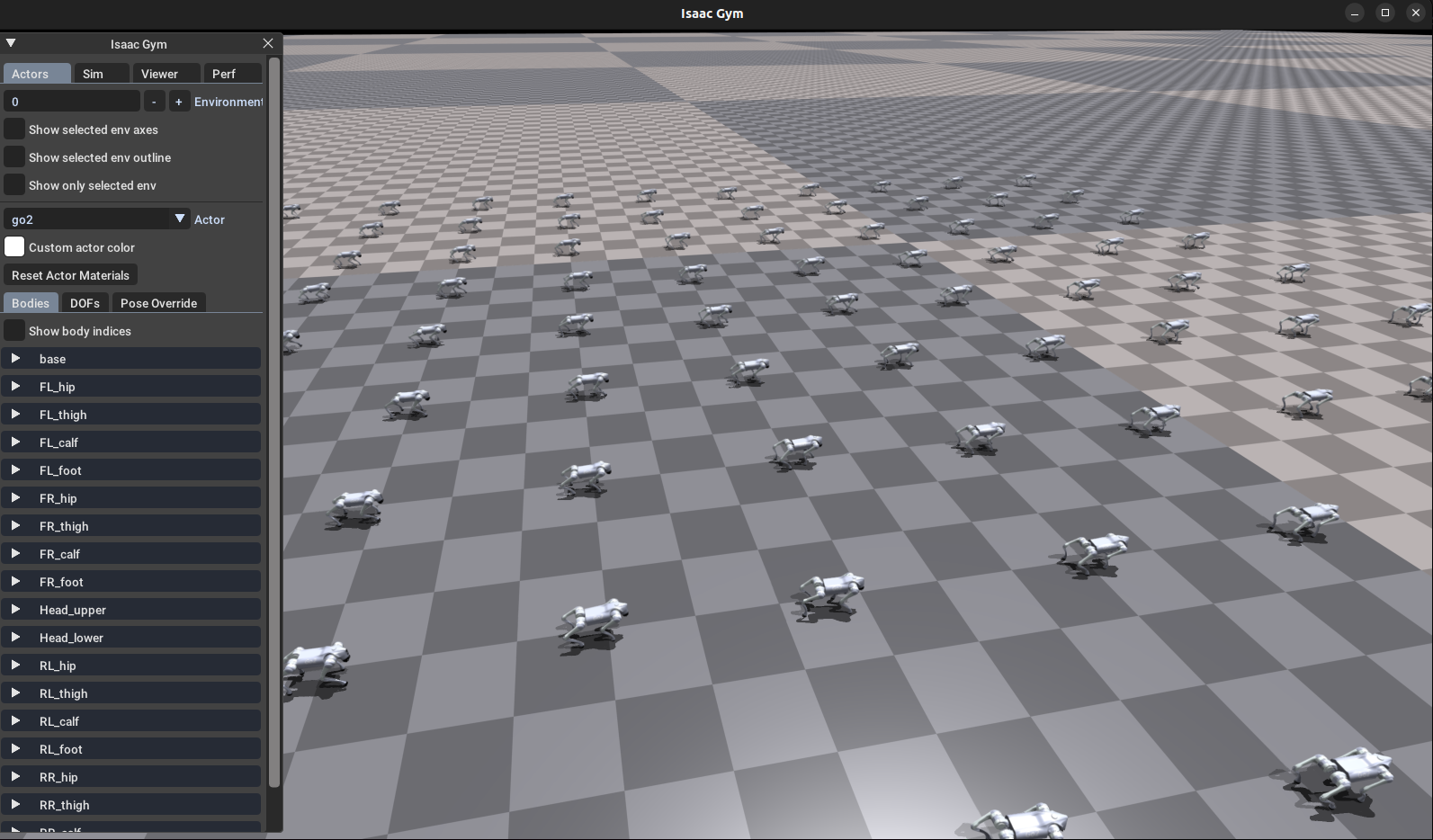
-
根据go2和手柄制定方向的跟踪效果,我们可以直观的测试模型的稳定性。
-
当然还是根据
TensorBoard的图表区分析修改比较合理。
小结
- 本期我们从训练日志出发,深入解析了
OnPolicyRunner中log函数的实现,搞清楚了平均奖励、损失函数等指标的计算方式,并结合TensorBoard对训练过程进行了可视化分析。同时,我们实现了基于手柄输入的实时控制,将训练好的策略应用到实际控制场景中,从而直观验证模型的稳定性与泛化能力,为后续奖励函数优化和策略改进打下基础。
- 下一期我们来谈谈如何修改奖励函数来进一步完善模型
- 如有错误,欢迎指出!感谢观看
- 一些训练的彩蛋:


