🫶 如果你以前总觉得 RNN 是"名字很熟、故事很多、可一到公式脑子就起雾"的东西,这篇文章就是专门来帮你翻盘的。我们不会默认你学过线性代数、高数、神经网络,也不会要求你先会写代码。我们会从最朴素的问题出发,一步一步走到 Elman 1990 这篇论文的核心:为什么模型需要记忆?RNN 到底靠什么把过去带到现在?它到底学到了什么?它又为什么一定会把舞台交给 LSTM? 这一路上我不会只挑几个点举例,而是会把本篇所有核心知识点逐个拆开,每个点都给你配例子、配数字、配人话,让你读的时候更像有人在旁边陪你做题,而不是把你扔进一堆冷冰冰的定义里。🍬
📋 阅读指南
- 这篇适合谁读:对
RNN / LSTM / Transformer这些名字已经眼熟,但一进公式就容易发懵的读者。 - 建议怎么读:先看"为什么今天讲这篇"和"背景与 baseline",然后顺着正文一段一段往下走;每遇到新概念,就当场把它吃透。
- 预计阅读节奏:如果你想真正吃透,建议分
3段读,每段读完都自己复述一句"这一段到底解决了什么问题"。 - 如果你是零基础:看到公式先别慌,先抓直觉、类比和数字;这篇的目标不是考你,而是带你把逻辑链走通。🫶
🗺️ 文章导航
- 为什么今天讲
RNN - 它接住了什么老问题
- 序列任务和前馈网络到底差在哪
- 这篇论文真正的核心公式和时间展开
14个顺链逻辑节点逐步推进- Elman 1990 到底证明了什么
- 为什么下一棒一定自然地交给
LSTM
🌟 为什么今天讲这篇
如果你今天只看一个例子,我想先给你看这个:
- 句子 A:
狗 追 猫 - 句子 B:
猫 追 狗
这两个句子用到的词几乎一样,但意思完全不同。问题就来了:如果一个模型每次只看当前这个词,它怎么知道"狗"在这里是追别人,还是被别人追?
这就是整个序列建模故事的起点。
🍬 你可以先把今天整篇文章想成一部"小侦探片":
- 线索一:当前输入只告诉你"眼前发生了什么"
- 线索二:真正的答案常常藏在"前面已经发生过什么"
- 线索三:RNN 做的,就是把前面的线索带到后面继续破案
只要这三句抓住了,后面的公式其实都不是突然冒出来的黑魔法。
前馈神经网络很擅长处理"当前这一下"的输入。你给它一张图片,它可以判断是猫还是狗;你给它一组特征,它可以判断用户会不会点击。但一旦任务变成"有顺序的东西",问题就立刻不一样了。
- 语言是有顺序的。
- 音频是有顺序的。
- 时间序列是有顺序的。
- 视频帧是有顺序的。
- 智能体看到世界并做决策,本质上也是有顺序的。
也就是说,顺序不是附加信息,顺序本身就是信息。
那么,1990 年的 Elman 做了一件很关键的事:他提出了一个非常朴素但极有威力的想法。
既然现在这一时刻的判断离不开过去,那就把"过去的内部状态"重新送回网络,作为下一时刻的输入之一。
这就是 RNN 的精神内核。
所以今天这篇不是"介绍一个旧模型"那么简单。它承担的是整条 AI 连载主线的第一块地基:
- 它第一次把"模型需要记忆"这件事明确做成了神经网络结构。
- 它让后来的 LSTM、GRU、Seq2Seq、Attention、Transformer 都有了一个必须回应的前史。
- 它还把"内部状态会不会自动学出结构"这个极其迷人的问题摆到了台面上。
如果这篇不吃透,后面所有"门控""注意力""上下文""世界模型"的理解都会飘。
🔁 上一篇回顾
这是整个系列的第一篇,所以严格说并没有上一篇。但它依然不是凭空开始的。它接住的是一个更古老、也更根本的矛盾:
神经网络很会拟合静态输入,可世界上的很多任务根本不是静态的。
你可以把 20 世纪 80 年代末的神经网络理解成一个强大的"当前时刻处理器"。
- 它能把输入向量映射到输出向量。
- 它能通过反向传播调整参数。
- 它能学习非线性关系。
但它默认有一个很强的假设:当前判断只需要当前输入。
可现实不是这样的。
比如:
- 当你听到一句话的后半段时,你对前半段的记忆会影响理解。
- 当你预测下一个字母时,你必须知道前面已经出现了哪些字母。
- 当你控制一个小车时,你不能只看当前一帧图像,还得知道刚才发生了什么。
所以 RNN 不是在回答"怎么把网络做得更深"。
它回答的是:
怎么让网络把"过去"变成"现在的一部分"?
这就是我们今天真正要讲透的主问题。
🗺️ 本篇位置:我们现在走到 AI 故事的哪一段了
在整套系列里,今天这一篇处在"序列建模基础与记忆机制"的开场位置。
它前面没有具体的上一篇,但它后面会自然连到下面这些节点:
LSTM:解决 RNN "会记但记不久"的问题。GRU:用更轻的门控结构改写"记忆更新"。Seq2Seq:把"有记忆的网络"推进到序列到序列任务。Attention:指出"把所有历史压成一个固定状态"还是不够。Transformer:把"递推记忆"替换成"全局注意"。World Models:把"状态记忆"从语言与序列推进到智能体对环境的内部模拟。
所以你可以把这篇看成一颗种子。后面的树会长得很大,但很多枝干,今天就已经出现了雏形。
🎯 你读完会真正掌握什么
如果这篇文章写成功,你读完以后应该能真正做到下面这些事情:
- 你能用最朴素的话解释:为什么前馈网络不够处理序列,RNN 为什么有必要出现。
- 你能准确说出 RNN 的核心公式里每一项是什么意思。
- 你能明白"隐状态"不是玄学词,而是模型当前对过去的压缩总结。
- 你能把 RNN 在时间上展开,看懂它为什么真的在处理序列。
- 你能用具体数字手算一个小型 RNN 的连续状态更新。
- 你能看懂 Elman 1990 论文为什么重要,它到底证明了什么。
- 你也能清楚看到它的局限,所以为什么下一篇一定要讲 LSTM。
如果你能走到最后,你不仅会懂 RNN,还会顺带补上一整批后面会不断复用的基础知识:向量、矩阵乘法、非线性激活、序列预测、状态更新、时间展开、损失函数、链式影响。
✨ 换句话说,这不是一篇"知道 RNN 是什么"的文章,而是一篇"把 RNN 学到手里"的文章。
🧱 背景与 baseline:RNN 出现前,旧方法到底卡在哪
1. 静态任务和动态任务不是一回事
先别急着看神经网络,我们先看任务类型。
有些任务是静态的:
- 看到一张图片,判断是不是猫。
- 给一组表格特征,判断是否违约。
- 给一个人的体检数据,判断风险等级。
这种任务里,当前这个输入样本本身就已经把信息带齐了。你不需要知道"上一个样本是什么",也不需要知道"这个样本之前经历过什么"。
但序列任务完全不同。
比如你要做:
- 下一个单词预测
- 语音识别
- 翻译
- 股票时间序列预测
- 行为决策
这时候,当前时刻的输入往往是不够的。你还必须知道过去。
比如你看到中文里的"了",它前面的上下文会决定它是完成体、语气词,还是结构的一部分。你看到英文里的 bank,要看前面是 river 还是 money 才知道它说的是河岸还是银行。
也就是说,在序列任务里,过去不是背景板,过去是输入的一部分。
2. 前馈网络为什么天然不擅长"记住过去"
前馈网络的结构非常直接:
输入进来,穿过若干层,输出结果,然后就结束。
它一次处理一个样本,一个样本处理完就没有"内部延续"了。你可以把它想成一个没有短期记忆的人:
- 他看到了眼前这一秒。
- 他会做出反应。
- 但这一秒过去以后,模型内部没有一个默认机制,把刚才那一秒留下来,参与下一秒的决策。
这就是前馈网络最本质的限制:
它没有内置的"状态延续"。
当然,你可以硬做一些补丁。比如把过去几个时刻的输入直接拼起来,一起喂给网络。
例如:
- 不是只输入 xt
- 而是输入 (xt−2,xt−1,xt)
这样确实能让模型"看到一点过去"。但这个方案有三个大问题:
- 你必须事先决定窗口长度。看 3 步、5 步还是 100 步?这是硬编码的。
- 一旦需要更长历史,输入维度会迅速膨胀。
- 过去信息不会被模型主动组织,它只是被机械地拼接。
这就像让一个人记忆时,不是允许他"记住重点",而是强迫他每次都把最近 10 页内容整页塞回脑袋里。很笨,也很贵。
3. RNN 的突破不在"更复杂",而在"多了一个状态"
Elman 的关键想法并不复杂,甚至可以说很朴素:
既然当前输出需要过去的信息,那就把上一时刻隐藏层的激活值复制出来,下一时刻再送回网络。
这一步看起来很小,却是神经网络对"时间"真正开的一扇门。
因为一旦你允许上一时刻的内部状态参与当前计算,网络就不再只是一个"输入到输出的映射器",它开始变成一个"会随时间演化的动力系统"。
这句话很重要,我们稍微拆开:
- "输入到输出的映射器"意味着:同样输入总是由当前输入直接决定输出。
- "会随时间演化的系统"意味着:同样的当前输入,在不同的过去状态下,输出可以不同。
比如同样看到一个单词 is:
- 如果前面是
The cat,你期待后面接的是动词短语。 - 如果前面是
Running,你对句法结构的判断就会不一样。
也就是说,RNN 让网络从"只看眼前"变成"眼前 + 心里还装着刚才的摘要"。
这就是它的革命性。
🪜 零基础补课:这篇论文需要哪些最小数学与模型前置
接下来我们会碰到公式。但先别慌,真的不用怕。RNN 的数学并不在于"公式多",而在于"状态会一轮一轮递推"。我们把真正需要的前置知识只补到够用为止。
1. 向量到底是什么
向量你可以先理解成"把一个对象压成一串数字"。
比如一个词、一个声音片段、一个传感器读数,都可以被表示成一个向量:
x= x1x2⋮xd
这不是在卖弄形式。这样写的好处是:模型可以统一地处理任何对象,只要你把它变成数字向量。
在 Elman 1990 的某些实验里,单词甚至直接用"正交的 bit 向量"表示。意思很简单:每个词占一个专属位置,出现时那个位置是 1,其他位置是 0。
举个极小的例子:
dog = [1, 0, 0]^\topcat = [0, 1, 0]^\topruns = [0, 0, 1]^\top
你看,这样模型拿到的就是数字,而不是文字。
2. 矩阵乘法到底在干什么
如果向量是一串数字,矩阵就可以理解成"很多组加权规则组成的表"。
当我们写:
Wx
它的本质是在做一件事:
按照矩阵里写好的权重,对输入向量做若干次加权求和,得到新的表示。
比如:
W=1324,x=56
那么:
Wx=1⋅5+2⋅63⋅5+4⋅6=1739
你可以把它想成:第一行权重生成一个新特征,第二行权重再生成另一个新特征。
3. 激活函数为什么需要存在
如果网络每一层都只是线性变换,那么不管堆多少层,本质上都还能被压成一个更大的线性变换。这会限制模型表达复杂模式。
所以我们常常在矩阵乘完以后,加一个非线性函数:
ϕ(⋅)
比如:
tanhsigmoidReLU
在 RNN 的经典表述里,常见的是 tanh 或 sigmoid 类函数。
你现在不用把它想得很复杂。最朴素的理解就是:
它让模型不只是"线性加权",而是能产生更复杂、更弯曲的映射关系。
4. "状态"到底是什么
这是今天最关键的词。
RNN 的状态通常写成:
ht
读作"时刻 t 的隐状态"。
它不是某个外部给你的标签,而是模型自己在内部形成的一份摘要。
你可以把它理解成:
- 它记住了到目前为止最重要的信息。
- 它不等于原始历史的完整拷贝。
- 它更像"模型此刻脑海里的总结"。
比如你读一句话:
- 读到第一个词时,你脑子里会形成某种期待。
- 读到第二个词时,这个期待会更新。
- 读到第三个词时,你对句子结构的判断又会变化。
RNN 里的 ht 就是这个"正在变化的脑内摘要"。
5. 时间展开是什么意思
RNN 图里常画一个环,看起来像网络自己连回自己。但真正分析时,我们通常把它"展开"成时间链条:
h1→h2→h3→⋯
这样你就能清楚看到:
- 第一步处理 x1
- 第二步处理 x2,但也接住 h1
- 第三步处理 x3,但也接住 h2
于是"过去影响现在"的路径就变得可见了。
这一步对后面理解 LSTM、GRU、Transformer 都极其关键。
6. 损失函数先只记一句话
训练网络时,总要有一个"做得好不好"的标准,这就是损失函数。
最朴素的理解就一句:
模型预测得越错,损失越大;训练的目标就是不断减小损失。
在序列任务里,损失常常不是只算一个时间点,而是把所有时间点的误差加起来:
L=t=1∑Tℓ(y^t,yt)
也就是说,序列里的每一步预测都会对总损失负责。
✅ 如果你现在能接受上面这些概念,其实已经足够进入 RNN 本体了。后面遇到具体公式,我们会一边走一边继续补。
🧾 术语与符号表
| 符号 / 术语 | 直觉含义 | 在 RNN 里承担什么角色 |
|---|---|---|
| xt | 第 t 个时间步看到的当前输入 | 告诉模型"眼前是什么" |
| ht | 第 t 个时间步的隐状态 | 模型此刻对过去的内部总结 |
| ht−1 | 上一时刻的隐状态 | 把"昨天"的信息带到"今天" |
| Wxh | 输入到隐状态的权重矩阵 | 决定当前输入怎样影响记忆 |
| Whh | 隐状态到隐状态的权重矩阵 | 决定过去状态怎样影响现在状态 |
| bh | 偏置项 | 给状态更新一个基础平移 |
| ϕ | 激活函数 | 让更新不是单纯线性叠加 |
| ot | 输出层线性结果 | 状态经过输出层后的中间量 |
| y^t | 预测输出 | 模型在第 t 步给出的答案 |
| context units | Elman 文中的上下文单元 | 保存上一时刻隐藏层拷贝的通道 |
| unfolded RNN | 展开后的 RNN | 把"环"变成"时间链"后更容易分析 |
🧠 顺链正文:沿着问题一步一步讲透
从这里开始,不再把"知识点"和"正文"拆成两块。我们直接沿着主线往前走:每走到一个新障碍,就当场把那个知识点讲清楚、把例子放出来、把真实数字算一遍,再继续往下。这样读起来才像一条顺着下去的逻辑链,而不是一堆知识盒子。🫶
在这一段里,我们故意不用"先把所有定义一次性倒给你"的教科书顺序,因为那种写法对小白最不友好:前面听一堆名词时,你还不知道它们为什么重要;等后面真的用上,又早就忘了。更顺的方式是先把眼前的卡点摊开,再只补解决这个卡点必须知道的最小知识,然后立刻用一个小例子和一组真数字把它钉牢。你可以把下面每个逻辑节点都当成一次"边走边学"的现场推演:不是先背一套术语,再去找应用场景,而是跟着论文前进,在需要它的那一刻把它学会。
还有一个阅读小窍门你可以提前带着走:后面每当你看到一个新公式,先不要急着算,也不要急着背字母,而是先在脑子里问自己四个问题。第一个问题,这个公式到底想解决刚才哪一个具体困难;第二个问题,左边那个量是"要更新的旧东西",还是"这一步新算出来的东西";第三个问题,右边哪一项在代表当前输入,哪一项在代表历史摘要;第四个问题,如果我把里面的数字换成一个具体例子,它最后会更像"保留过去"还是"更听当前输入的话"。你只要把这四个问题养成习惯,很多看起来吓人的式子会突然变得很像人话,只不过是把"该记什么、该忘什么、该怎样往下一步传"写成了更正式的数学。
等你把这套读法练熟以后,再回头看任何一个 RNN 公式,你都不会再先被符号吓住,而会先看到它想处理的那个现实问题:到底是顺序、摘要、记忆、输出,还是梯度在这里起作用。这个阅读视角本身,就是后面继续啃 LSTM 和 Transformer 时非常值钱的前置能力。 把这个视角抓牢,你后面会轻松很多。 真的会顺很多。 稳了。
逻辑节点 1:顺序本身就是信息
先把眼前的问题说透:在序列任务里,元素不光看"有没有出现",还要看"按什么顺序出现"。 先别急着上公式,你可以先把它想成:狗 追 猫 和 猫 追 狗 像两杯配料一模一样、但吸管插反位置的奶茶。原料一样,喝到嘴里的感觉完全不同。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
设 id(狗)=1, id(追)=2, id(猫)=3
顺序分数=1⋅首词id+2⋅次词id+3⋅末词id
狗 追 猫=1⋅1+2⋅2+3⋅3=14
猫 追 狗=1⋅3+2⋅2+3⋅1=10
说到这里,这一段已经顺下来了:哪怕词袋完全相同,只要顺序一换,数值表示就会变。这就是"顺序本身就是信息"的最小数字版证据。✨
再往前多想半步,你就会发现这一步其实在替整篇文章定基调:序列任务的难点从来不是"元素够不够多",而是"前后关系有没有被保存"。如果模型只会做加法平均,它看到的永远只是"这一堆东西出现过",却不知道谁先谁后、谁修饰谁、谁决定谁。正因为顺序会改变意义,我们才需要一个能把前文带着走的内部状态。下一个问题也就很自然地冒出来了:这个"带着走"的东西到底长什么样?
逻辑节点 2:隐状态像一张会更新的便签纸
先把眼前的问题说透:隐状态 ht 不是原样记录过去,而是对"接下来最有用的信息"的持续摘要。 先别急着上公式,你可以先把它想成:它像一个认真但不唠叨的小助理,只记"待会儿做题一定会用上的关键词",不会把老师每句废话都抄进笔记里。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
ht=0.6ht−1+xt,h0=0
假设三步输入分别是:
x1=1,x2=2,x3=1
那么:
h1=0.6⋅0+1=1
h2=0.6⋅1+2=2.6
h3=0.6⋅2.6+1=2.56
说到这里,这一段已经顺下来了:第 3 步的状态 2.56 不是只看当前 1 算出来的,它已经把前两步的影响折叠进来了。🌱
很多小白第一次看到隐状态,会误以为它像硬盘备份,负责把过去完整存档。其实不是,它更像一张不断改写的备忘录:新的信息进来,旧的信息有的保留、有的淡出,留下的只是一份对当前任务最有用的摘要。你把这个直觉抓住,后面那些看似吓人的状态公式,本质上都只是在回答一个问题:这张便签纸这一步究竟该怎么改写。
逻辑节点 3:拼固定窗口不等于真的会记忆
先把眼前的问题说透:把过去几个输入硬拼起来,最多只能看到"预设长度"的历史,并不等于模型真的学会了如何记忆。 先别急着上公式,你可以先把它想成:这像考试前只允许你带一张三行的小抄。要是重点恰好写在第 4 行,对不起,老师不认。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
假设真正重要的异常发生在 4 步前:
(xt−3,xt−2,xt−1,xt)=(9,1,1,1)
如果你只拼最近 3 步,模型看到的是:
(xt−2,xt−1,xt)=(1,1,1)
这时窗口和只有:
1+1+1=3
但如果真正决定结果的是"4 步前的冲击 + 当前值",真实关键信号应该是:
xt−3+xt=9+1=10
说到这里,这一段已经顺下来了:窗口拼接能看到一点过去,但看不到窗口外的关键信息;这说明"看见过去几步"不等于"真的会记忆"。🍬
这也解释了为什么"多拼几个过去的输入"看起来像是记忆,实际上只是把失误往后拖了一点点。窗口长度一旦写死,模型就像拿着固定长度的尺子去量所有句子和所有时间序列:短的还能勉强对付,长的就立刻露馅。RNN 真正新鲜的地方,不是把窗口开得更大,而是让模型自己带着一个会更新的摘要继续往前走。
逻辑节点 4:状态是摘要,不是录像回放
先把眼前的问题说透:RNN 的状态是压缩后的任务摘要,不是把完整历史一帧不落地存下来。 先别急着上公式,你可以先把它想成:这像你妈让你去超市买东西,你脑子里记的是"牛奶、鸡蛋、面包"三个关键词,不会把出门路上每辆车的车牌都背下来。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
设一段历史输入是:
(x1,x2,x3,x4)=(2,5,1,4)
我们用两维摘要来压缩它:第一维取平均值,第二维取最大值。
mean=42+5+1+4=3
max=5
于是摘要可以写成:
h=35
但如果另一段历史是:
(5,1,4,2)
它的平均值和最大值仍然是:
mean=3,max=5
说到这里,这一段已经顺下来了:两个不同顺序的序列会压成同一个摘要,所以摘要不是录像,而是"为任务服务的压缩表示"。这也正是 RNN 容易丢细节的根源。🎈
你可以把这里理解成一个很核心的交换:RNN 用"压缩"换来了"能连续往前走"。压缩的好处是历史不会随着序列变长而无限膨胀,坏处是某些细节可能在压缩时被舍掉。所以后面我们既会赞美 RNN 开创了记忆机制,也会看到它为什么天生存在遗忘风险。这个矛盾不是后人硬挑出来的,而是在"状态是摘要"这一刻就已经埋下了。
逻辑节点 5:参数共享就是同一套规则反复上岗
先把眼前的问题说透:RNN 在不同时间步用同一套参数,表示"同一条更新规律"会在时间轴上重复生效。 先别急着上公式,你可以先把它想成:这像一个认真负责的班主任,不会周一按校规批作业、周二按星座、周三按心情。规则一旦定了,每天都按同一套标准执行。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
假设同一套更新规则在每一步都用:
ht=0.5xt+0.5ht−1,h0=0
输入依次为:
x1=2,x2=4,x3=6
那么:
h1=0.5⋅2+0.5⋅0=1
h2=0.5⋅4+0.5⋅1=2.5
h3=0.5⋅6+0.5⋅2.5=4.25
说到这里,这一段已经顺下来了:三个时间步都用了同样的 0.5 和 0.5。这就叫参数共享。模型学到的不是"某一步专属技巧",而是可以沿时间重复应用的统一规则。✅
参数共享听起来像一个工程实现细节,其实它决定了 RNN 能不能成为真正的序列模型。如果每个时间步都换一套权重,模型学到的就只是"第 1 步怎么处理、第 2 步怎么处理",而不是一条可以在任何位置反复使用的规则。正因为规则被强制复用,RNN 才有机会把"处理时间序列"这件事抽象成一种通用能力,而不是只记住一套死板流程。
逻辑节点 6:递推更新 = 当前输入 + 历史摘要
先把眼前的问题说透:RNN 的核心不是单看当前输入,也不是死抱历史不放,而是把"当前证据"和"旧摘要"揉成新摘要。 先别急着上公式,你可以先把它想成:这像你点外卖时不会只看今天想吃什么,还会看昨天是不是刚吃过火锅。当前胃口和历史经验一起决定今天下单什么。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
设一个最小递推规则是:
ht=0.7ht−1+0.3xt
如果上一时刻已经记住了:
ht−1=10
当前输入只有:
xt=2
那么:
ht=0.7⋅10+0.3⋅2=7+0.6=7.6
如果完全不看历史,只看当前输入,那你只能得到 2;而递推后的结果是 7.6。
说到这里,这一段已经顺下来了:RNN 真正厉害的地方,不是它"会看现在",而是它"看现在时还带着昨天的脑子"。这句话你记住,后面所有公式都会顺很多。🫶
看到这里,你可以把 RNN 的灵魂先压缩成一句特别朴素的话:新状态不是凭空冒出来的,它永远是"昨天留下什么"和"今天又看到了什么"的折中结果。这个折中比例一变,模型的记忆性格就会跟着变:更看重历史时,它更稳;更看重当前输入时,它更灵活。后面无论是普通 RNN、GRU 还是 LSTM,本质上都是在重新设计这个折中的方式。
逻辑节点 7:context units 是"上一时刻状态的拷贝通道"
先把眼前的问题说透:Elman 论文里的 context units,本质上就是把上一时刻隐藏层激活值拷贝下来,下一时刻再送回去的通道。 先别急着上公式,你可以先把它想成:它像你做数学题时,在草稿纸角落抄了一遍"上一步最关键的中间结果",下一步继续用,不至于每次都从头算到怀疑人生。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
假设上一时刻隐藏层输出是:
ht−1=0.80.3
Elman 式的 context units 先把它原样拷走:
ct=0.80.3
如果当前输入是:
xt=1.00.0
并设一个极简更新规则:
ht=10010.5000.5 1.00.00.80.3
那么:
ht=1.0+0.5⋅0.80.0+0.5⋅0.3=1.40.15
说到这里,这一段已经顺下来了:context units 不神秘,它只是把"上一时刻的重要中间结果"留了一份副本,方便下一时刻继续用。🍬
Elman 当年把它画成 context units,其实是在用非常直观的结构告诉读者:上一时刻的内部状态,必须有一条明确的物理通路传给下一时刻。你不要把它想得太玄,它不是宇宙记忆仓库,只是一条专门留给"上一拍结果"的回流线。正是这条回流线,让网络第一次真正有了时间上的连续自我。
逻辑节点 8:时间展开让"一个环"变成"可以逐步分析的链"
先把眼前的问题说透:RNN 画成一个回路时看起来像绕口令,但按时间展开后,本质上就是同一个小网络被重复使用很多次。 先别急着上公式,你可以先把它想成:这像你看一盘蚊香时总觉得它很玄,但把它一圈一圈掰直后,你会发现不过就是一条连续的长线。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
设一个最简单的标量 RNN:
ht=xt+ht−1,h0=0
输入是:
x1=1,x2=2,x3=3
按时间展开后逐步计算:
h1=1+0=1
h2=2+1=3
h3=3+3=6
如果你把这条链整体看回去,就会发现:
h3=x3+x2+x1=3+2+1=6
说到这里,这一段已经顺下来了:时间展开的意义,是把"循环结构"变成"可逐步检查的历史链条"。你一旦接受这个视角,RNN 立刻就没那么神秘了。✨
一旦把环拆成链,很多东西一下就清楚了:第 1 步的状态怎样影响第 2 步,第 2 步又怎样继续传到第 3 步,最后为什么一个很早的输入居然会影响最后的输出。更重要的是,训练时的误差信号也必须沿着这条链反向走回来。换句话说,时间展开不仅是画图技巧,它同时决定了我们后来如何理解学习、梯度和长期依赖。
逻辑节点 9:序列损失为什么常常按时间步累加
先把眼前的问题说透:在序列任务里,模型不是只对最后一步负责,往往每一步预测都会贡献一部分损失,所以总损失常写成时间步求和。 先别急着上公式,你可以先把它想成:这像老师批改一篇完形填空,不会只看最后一空答得对不对,而是前面每一空都要算分,错一题扣一题。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
假设 3 个时间步的预测误差分别是:
ℓ1=0.2,ℓ2=0.5,ℓ3=0.1
总损失按时间相加:
L=ℓ1+ℓ2+ℓ3
代入得到:
L=0.2+0.5+0.1=0.8
如果第二步没学好,把 ℓ2 从 0.5 降到 0.2,那么新的总损失就是:
Lnew=0.2+0.2+0.1=0.5
说到这里,这一段已经顺下来了:序列损失按时间求和,意思就是"序列里的每一步都要为整体表现负责",这也解释了为什么训练信号会沿时间链一起回传。🌱
把损失按时间相加,其实是在明确告诉模型:你不是只要最后一拍装作聪明就行,前面每一步的判断也都要对整体结果负责。这个视角很重要,因为它把序列学习从"做一次终局判断"变成了"一路都在接受监督"。而监督一多,训练信号就会沿时间链传播得更复杂,这也正好把我们推向下一个更难但更关键的问题:梯度会不会在长链上失真?
逻辑节点 10:梯度链为什么会让 RNN 又伟大又脆弱
先把眼前的问题说透:RNN 的力量来自"过去真的能影响现在",但训练时这种影响要沿时间反向传播,连续很多步相乘后就容易变得很小或很大。 先别急着上公式,你可以先把它想成:这像你玩传话游戏。每传一轮都只保留原信息的 60%,传五六轮以后,最早那句话基本只剩"啊?你说啥?"。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
假设每一步梯度都近似乘上一个系数 0.6,连续传播 5 步:
0.61=0.6
0.62=0.36
0.63=0.216
0.64=0.1296
0.65=0.07776
也就是说,最早那一步收到的训练信号只剩不到 0.08。
反过来,如果每一步都乘 1.5,连续 5 步就会变成:
1.55=7.59375
说到这里,这一段已经顺下来了:这就是梯度消失和梯度爆炸的数字直觉版。RNN 的时间链越长,这个问题就越尖锐,也因此 LSTM 不是"可有可无的升级包",而是非常自然的接棒者。🎈
RNN 的伟大和脆弱在这里第一次完全重合:正因为很久以前的状态真的能影响现在,所以训练时也必须允许"很久以前的参数选择"被现在的损失追责。问题在于,这条追责链一长,乘积就容易把信息压没或者放炸。于是你会发现,RNN 不是做错了方向,而是提出了一个正确但困难的问题:如何让有用的信息能在很长时间里稳定流动。
逻辑节点 11:输出为什么要从状态里读出来,而不是只看当前输入
先把眼前的问题说透:RNN 的输出通常来自当前状态 ht,因为这个状态已经融合了当前输入和历史摘要,所以比只看 xt 更有上下文。 先别急着上公式,你可以先把它想成:这像你回答"这句话什么意思"时,不会只盯着最后一个词,而是会把整句上下文都先在脑子里过一遍,再开口回答。不然就很容易把 bank 听成银行,而不是河岸。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
设当前状态和当前输入分别是:
ht=4,xt=1
我们想预测"下一步更像类别 A 还是类别 B"。如果只看当前输入,设分类分数是:
sonly-x=2xt=2
如果从状态读出,设分类分数是:
sstate=0.5ht=2
这时两个分数碰巧一样,看不出差别。那我们再看另一个时间点:当前输入仍然是 1,但历史不同,所以状态变成:
ht′=8,xt′=1
只看输入时,分数还是:
sonly-x′=2⋅1=2
但从状态读出时,分数变成:
sstate′=0.5⋅8=4
说到这里,这一段已经顺下来了:相同的当前输入,在不同历史下应该可能导向不同判断;从状态读输出,模型才有机会把"历史背景"也算进去。🍬
这一步可以帮你把"状态到底有没有意义"彻底坐实。要是输出只看当前输入,那前面辛辛苦苦存下来的历史就白带了;只有让输出读状态,模型才真的能说"我现在的判断,包含了前文背景"。所以状态不是论文里为了好看多画的一层,而是把"上下文"真正变成可计算对象的关键枢纽。
逻辑节点 12:时间版 XOR 为什么像 RNN 的最小测谎仪
先把眼前的问题说透:时间版 XOR 看起来题目很小,但它把"模型到底有没有把前面的信息存住"这件事逼到了最前线,是检验记忆能力的极简试纸。 先别急着上公式,你可以先把它想成:它像朋友故意问你:"我刚才前两句话说的两个数字,你现在还能不能做异或?" 这时候你要是脑子里一点前文都没留,就只能露出礼貌而尴尬的微笑。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
普通 XOR 规则是:
0⊕0=0,0⊕1=1,1⊕0=1,1⊕1=0
现在把输入拆成时间到来:
x1=1,x2=0
如果第 3 步要求输出前两步的 XOR,那么正确答案是:
y3=x1⊕x2=1⊕0=1
再换一组:
x1=1,x2=1
此时第 3 步正确输出应该是:
y3=1⊕1=0
注意,第 3 步眼前并没有把 x_1 和 x_2 明晃晃写在脸上。如果模型没有记忆,它根本没法区分这两种情况。
说到这里,这一段已经顺下来了:时间版 XOR 可贵的地方不是题难,而是它特别诚实。模型一旦没记住过去,就一定露馅。✅
时间版 XOR 的漂亮之处就在于它一点不花哨,却极其无情。它不会给模型留下模糊地带:你要么真的把之前的信息带到了现在,要么就当场答错。对于讲解来说,这种任务特别宝贵,因为它能把"模型是否拥有记忆"这件事变成一个一眼就能看懂的真假题。很多复杂论文,最后都能追溯到这种极简测试的精神。
逻辑节点 13:为什么 LSTM 不是岔路,而是 RNN 的自然接棒者
先把眼前的问题说透:LSTM 不是推翻 RNN,而是在保留"状态递推"这个核心思想的前提下,专门修复"长链条里信息很难稳定传递"这个痛点。 先别急着上公式,你可以先把它想成:这像你第一次用普通塑料袋装汤,发现一路漏得到处都是;LSTM 不是说"别装汤了",而是说"还是装,但换成带密封扣的保温盒"。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
回看刚才的梯度链例子,如果每一步都乘 0.6,5 步后只剩:
0.65=0.07776
这几乎已经弱到像隔着五层门在喊话。
如果一种改进结构能把每一步的有效保留系数提到 0.95,那么 5 步后就会变成:
0.955≈0.7737809375
这时最早信息还保留了七成多。
再把 10 步对比一下:
0.610≈0.0060466176
0.9510≈0.5987369392
说到这里,这一段已经顺下来了:这就是为什么读完 RNN 后,下一步不去讲 LSTM 反而奇怪。RNN 把"需要记忆"提出来了,LSTM 则是顺着这个问题继续问:"那怎样才能别忘得这么快?" 🌱
所以 LSTM 的出现根本不是横空出世,而是顺着 RNN 自己暴露出来的矛盾继续深挖。RNN 已经告诉我们:序列必须有状态,当前必须和历史交互;LSTM 接着问的只是:那能不能给这条记忆链装几个更聪明的阀门,让该留的留住、该丢的丢掉?你这样看,RNN 到 LSTM 就不是两篇割裂的论文,而是一场自然接棒的连续讨论。
逻辑节点 14:为什么"结构感"会在预测任务里自己长出来
先把眼前的问题说透:当模型不断被要求"预测下一步是什么"时,它会被迫在内部形成一些能帮助预测的结构化摘要,这种摘要往往就表现出词类、位置、依赖关系之类的"结构感"。 先别急着上公式,你可以先把它想成:这像你陪一个小朋友玩猜词游戏。你一开始也许只是乱猜,但玩多了以后,你会自发总结出"前面如果刚出现主语,后面大概率要接动作;如果刚出现动词,后面更像跟名词"。没人强迫你背语法书,但你的脑子会慢慢长出一套土办法。 如果这个概念第一次出现,这里立刻补一个刚好够用的前置知识:这一步会立刻回调前文已经补过的基础概念,然后直接下到真实数字。 接下来立刻把这个想法换成一组真实数字,从头到尾推一遍:
设我们用一个极简预测任务来模拟这种现象。句子模板只有两种:
名词→动词
动词→名词
我们给词做一个最小编码:
名词=1,动词=2
再设一个最小"期望分数"规则:当前状态越接近 1,就说明接下来更期待动词;当前状态越接近 2,就说明接下来更期待名词。
如果刚读到一个名词,我们把状态记成:
ht=1
此时对"下一个词是动词"的期待分数可以设成:
sverb=3−ht=3−1=2
对"下一个词是名词"的期待分数设成:
snoun=ht−1=1−1=0
也就是说,读到名词后,模型更期待动词。
反过来,如果刚读到动词,状态记成:
ht=2
那么:
sverb=3−2=1
snoun=2−1=1
如果我们再给"动词后更偏名词"一个额外奖励 +1,那么:
snoun′=1+1=2
说到这里,这一段已经顺下来了:一旦任务是"不断预测下一步",模型就会被训练压力逼着把"我现在更像处在哪种结构位置"编码进状态里。Elman 这篇最迷人的地方,正是它暗示了这种结构感可以从时间预测里慢慢长出来。🫶
Elman 这篇最耐人寻味的地方,其实不只在于它做出了一个会记忆的网络,更在于它暗示了"结构"不一定非得手工灌进去。只要任务不断逼着模型预测下一步,它就可能为了更好地完成任务,自发在状态里长出位置感、类别感和依赖感。你如果把这条线继续往后追,会一路看到语言模型、世界模型,甚至今天的大模型。
到这里,其实我们已经把 RNN 这篇论文最重要的主线走完了一遍:为什么需要顺序、为什么需要状态、状态怎样更新、为什么训练会痛苦、为什么这条路自然会通向 LSTM。后面的"主线继续""形式化层"和"推导层",不是重新换一套新东西,而是把你刚才已经理解过的直觉再拧得更紧、写得更正式。你现在如果回头看那些公式,会发现它们不像咒语,更像是刚才这一路人话的数学版。
如果你现在想把前面这十四步在脑子里连成一幅完整的连环画,可以这样回忆:一开始我们先承认"顺序会改变意义",所以模型不能再像传统前馈网络那样只看眼前这一帧;接着我们引入一个会滚动更新的隐藏状态,让它把过去压成一张不断重写的便签纸;然后我们发现,光拼固定窗口只是把问题往后拖,并不是真正解决记忆,于是状态必须成为一种会压缩、会取舍、会在每一步重新摘要的内部表示;再往后,参数共享告诉我们,这不是一堆零散的小技巧,而是一条沿时间反复执行的统一规则;时间展开又把这条规则从"看起来像个圈"的结构,掰直成一条可以被分析、被训练、被追责的时间链。这样一来,RNN 整个骨架就站起来了:过去先被压进状态,状态再带着历史走到现在,现在的输出再从这个带背景的状态里读出来。
但这条主线真正厉害的地方,还在于它一边成立、一边暴露出自己的极限。因为损失往往按时间步累加,所以训练信号也必须沿时间一路倒着传;而一旦这条链太长,梯度就会越来越难保持稳定,久远的信息不是被冲淡,就是被放大失控。你现在再回头看,就会发现 RNN 的几乎每个优点都和它的缺点来自同一个地方:它之所以第一次让神经网络拥有了"时间中的自我",也正因为如此,才必须面对长程依赖、信息压缩和训练不稳定这些硬问题。所以读完这条主线以后,你脑子里最好留下的不是某一个孤零零的公式,而是一组连续的问题链:为什么顺序重要,为什么需要状态,状态如何更新,为什么训练会痛,为什么下一步自然会走向 LSTM。只要这条问题链还在,你后面再读 LSTM、GRU,甚至再往后读 Attention 和 Transformer,就不会觉得自己在学一堆互不相关的新名词,而是在看同一个故事如何被一代一代模型继续讲下去。
🧠 主线继续:把刚才那条顺链再拧紧一点
1. 先用一句人话概括
RNN 做的事情,用最简单的话说就是:
每看一个新输入,就把"当前新信息"和"之前已经记住的信息"揉在一起,更新成一份新的内部摘要。
请你注意这句话里的三个动作:
- 看当前输入
- 取出旧摘要
- 合成新摘要
这三步构成了 RNN 的全部灵魂。
2. 为什么这就足够重要
因为一旦你允许网络这样工作,它就不再只是对当前输入做"瞬时反应",它开始拥有一种极其原始但极其有用的时间意识。
比方说,我们在听一句英语:
The dogs on the hill are...
当你听到 are 的时候,你之所以觉得它合理,是因为你脑中还保留着主语是 dogs 而不是 hill。如果你的大脑每次只看当前词,你根本做不出这种判断。
RNN 的隐状态,就是模型版的这个"短时上下文"。
3. Elman 的 context units 到底是什么
Elman 最早的结构图里,有一个很形象的设计:把隐藏层的激活值复制到一组叫 context units 的单元里,下一时刻再送回隐藏层。
你完全可以把它想成一个小便签纸:
- 当前时刻,隐藏层算出了它对世界的理解。
- 网络把这份理解抄一份,存在便签上。
- 下一时刻,便签连同新输入一起再次参与计算。
这就是"记忆"的最原始实现方式。
它没有门控。 它没有注意力。 它没有外部检索。 它没有 fancy 的缓存结构。
它只是非常直接地说:
把上一步算出来的内部状态带到下一步去。
就这么简单。
4. RNN 不是在保存完整过去,而是在压缩过去
这一点非常重要。
很多初学者会误以为 RNN 的隐状态像硬盘,能原样保存之前所有信息。不是的。隐状态更像摘要,而不是录像回放。
它面临的是一个压缩问题:
- 过去发生了很多事。
- 现在不可能把所有原始细节都完整带上。
- 所以模型必须学会:哪些要保留,哪些可以丢掉。
这个过程既是 RNN 的强大之处,也是它后面问题的来源。
强大之处在于:它能自己学会什么重要。
问题在于:如果历史太长、压缩太狠、路径太深,很多早期信息会被冲淡,甚至彻底遗失。
这就是为什么今天讲 RNN,明天就必须讲 LSTM。
5. 把图真正看懂
先看第一张图:
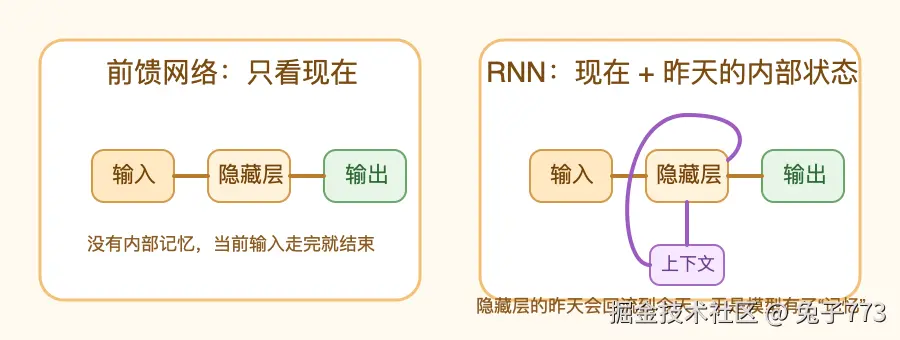
左边的前馈网络只有一条从输入到输出的路径。右边的 RNN 多了一条从"昨天的隐藏层"回到"今天的隐藏层"的路径。
你可以把这多出来的回路理解成一句话:
昨天的内部理解,会变成今天的一部分证据。
🍬 如果你想把这张图看得更轻松一点,也可以这样记:
- 左边像"看完这一眼就翻页"的同学
- 右边像"会顺手在草稿纸上写下注释"的同学
RNN 多出来的不是炫技结构,而是一条把"昨天的理解"送到"今天"的回路。
再看展开图:
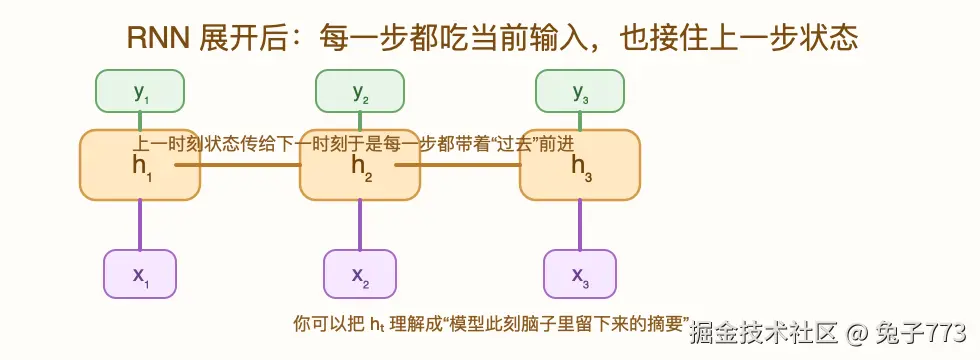
展开以后,RNN 不神秘了。你会发现它其实就是很多个"参数完全共享的小网络"在时间上一个接一个排开:
- 第一步处理 x1,得到 h1
- 第二步处理 x2,但同时用到 h1
- 第三步处理 x3,但同时用到 h2
所以 h3 本质上已经包含了 x1,x2,x3 的影响。只不过这种包含不是原样拷贝,而是经过压缩变形后的内部表示。
✅ 到这里你应该已经抓住 RNN 最关键的直觉了:它是一种"会更新内部摘要"的网络。
✍️ 主线继续:把刚才的直觉翻译成正式公式
现在我们把刚才那句人话正式写成公式。
1. 最核心的状态更新公式
RNN 最经典的状态更新可以写成:
ht=ϕ(Wxhxt+Whhht−1+bh)
这条式子你一定要彻底看懂。它几乎就是 RNN 的身份证。
我们逐项翻译:
- xt:当前输入,也就是"眼前发生了什么"
- ht−1:上一时刻状态,也就是"我刚才脑子里记着什么"
- Wxhxt:当前输入对新状态的贡献
- Whhht−1:旧状态对新状态的贡献
- bh:偏置项,相当于额外的平移
- ϕ(⋅):非线性激活,让模型能学复杂关系
把这些合起来看,这条式子其实只是在说:
新状态 = 当前输入提供的证据 + 旧状态带来的历史,再经过一个非线性整合。
2. 输出层怎么写
如果当前时刻还要做预测,常见写法是先得到一个输出前激活:
ot=Whyht+by
再经过一个输出函数 g(⋅):
y^t=g(ot)
如果是分类任务, g 常常是 softmax;如果是二分类,可能是 sigmoid;如果是回归,甚至可能直接线性输出。
这里最要紧的不是输出函数细节,而是你要看到:输出不是直接从输入算出来的,输出是从"已经带着历史的状态"算出来的。
3. 为什么参数要共享
RNN 有个非常关键、也很容易被忽略的点:不同时间步用的是同一套参数。
也就是说:
- 第一步用的是 Wxh,Whh,Why
- 第二步还是这一套
- 第三步还是这一套
这叫参数共享。
为什么这很重要?
因为如果每个时间步都用不同参数,那模型就不再像一个"统一规律在不同时间重复生效"的系统,而变成了"一堆时间点各自为政的小模型"。
参数共享意味着:
同一个"更新规则"会被反复应用在时间轴上。
这非常像现实中的认知过程:不是第一秒一个脑子、第二秒另一个脑子,而是同一个认知系统持续更新自己的内部状态。
4. 时间展开以后,过去怎样影响现在
先写前两步:
h1=ϕ(Wxhx1+Whhh0+bh)
h2=ϕ(Wxhx2+Whhh1+bh)
把 h1 代进去:
h2=ϕ(Wxhx2+Whhϕ(Wxhx1+Whhh0+bh)+bh)
你现在应该能看见一件极重要的事:
虽然 h2 表面上只显式写了 x2 和 h1,但其实它已经通过 h1 间接依赖了 x1。
继续往下展开:
h3=ϕ(Wxhx3+Whhh2+bh)
而 h2 又依赖 h1, h1 又依赖 x1。
所以从结构上说:
h3 已经把前三个时间步都"吃进去"了。
这就是 RNN 真正能处理序列的原因。
5. 为什么说它"有记忆",但不是"完美记忆"
因为每一步更新都要做一次压缩。
你可以把 ht−1 想成一个已经压缩过一次的摘要;到下一步,它又要和新输入揉在一起,再压成新的摘要。这样一轮一轮下去,模型能记住什么、忘掉什么,就取决于参数是否学会了保留关键因素。
所以 RNN 的记忆更像:
- 一份持续更新的工作笔记
而不是:
- 一个永不失真的时间录像机
这个差别,后面会导致非常深远的后果。
🧮 主线继续:公式到底是怎么一步一步长出来的
很多人一上来就背公式,但真正的吃透一定是"知道它为什么会长成这样"。我们现在从最自然的构造方式出发,把 RNN 的核心式子重新推出来。
第一步:先写一个普通前馈隐藏层
如果没有时间,只处理当前输入,一个普通隐藏层可以写成:
h=ϕ(Wx+b)
意思非常直白:
- 当前输入是 x
- 矩阵 W 负责把输入变换成隐藏表示
- b 做平移
- ϕ 做非线性处理
到这里都还没有"时间"。
第二步:如果当前判断依赖过去,就把过去也当成输入
现在你意识到一个事实:单独的当前输入不够,过去的内部状态也应该参与计算。
那最自然的做法是什么?
答案就是:把"当前输入"和"过去状态"都放进状态更新式里。
于是有:
ht=ϕ(Axt+Bht−1+b)
只是后来习惯上把 A 写成 Wxh,把 B 写成 Whh,强调:
- 一个矩阵负责"输入 → 状态"
- 一个矩阵负责"状态 → 状态"
所以就得到标准形式:
ht=ϕ(Wxhxt+Whhht−1+bh)
你看,这不是从天上掉下来的。它几乎是唯一最自然的构造:
- 当前信息要进来
- 过去摘要也要进来
- 两者线性整合
- 再做非线性变换
第三步:为什么这叫"递推"
因为你不是一次性把整段序列一起算完,而是按时间一格一格往前推进。
第 t 步只知道两样东西:
- 当前输入 xt
- 上一步摘要 ht−1
它并不知道更早的输入是什么,但更早的信息已经被压在 ht−1 里面了。
这就是递推的精髓:
把"所有过去"浓缩成"上一步状态",然后只需要继续更新。
第四步:损失为什么是按时间求和
如果任务要求你在每个时间步都预测一个输出,那么总损失自然要把每一步都算进去:
L=t=1∑Tℓ(y^t,yt)
这意味着:
- 第 1 步预测错了,要罚
- 第 2 步预测错了,也要罚
- 第 3 步预测错了,还是要罚
所以训练的时候,参数更新不是只考虑某一个时间点,而是要考虑整段序列的表现。
第五步:为什么训练会牵一发动全身
因为同一套参数被所有时间步共享。
所以当你修改 Whh 的时候:
- 它会影响第 1 步状态更新
- 也会影响第 2 步
- 还会影响第 3 步
- 甚至会连锁影响所有更晚的状态和输出
这就是 RNN 很有魅力、也很难训练的一点:
它的参数不是对某个时间点局部负责,而是对整个时间链条一起负责。
第六步:为什么后来会出现梯度消失问题
这里我要非常诚实地说一句:Elman 1990 这篇论文的重点不是系统分析梯度消失。
但是站在后来的眼光回看,RNN 这条递推链天然埋着一个问题:
当损失要沿时间反向传播时,早期状态的影响会经过很多次链式乘法传回去。粗略地看,这会长成类似:
∂ht−k∂L=∂ht∂Li=t−k+1∏t∂hi−1∂hi
这条式子先别怕,你只要抓住一个直觉:
- 如果中间这些导数多数都小于 1,那么连乘很多次以后会越来越小,信息传不回去,这就是梯度消失。
- 如果中间这些导数多数都大于 1,那么连乘很多次以后会越来越大,训练会不稳定,这就是梯度爆炸。
所以 RNN 的伟大之处和它的限制,其实来自同一个地方:
它真的让过去影响现在了;也正因为这条影响链太长,训练和长期记忆就会变难。
✨ 这就是为什么下一篇 LSTM 会顺理成章地出现。不是因为 RNN 错了,而是因为 RNN 太早把真正的问题暴露出来了。
🌰 真实数字推演 A:手算一个最小 RNN
现在我们不讲抽象话,直接来一组真正能算的数字。为了让你看清楚"状态如何一轮一轮更新",我们先做一个简化版例子:
- 输入维度是 2
- 隐状态维度是 2
- 为了手算清楚,这里先把激活函数 ϕ 暂时取成恒等映射
请注意:这只是为了教学,不是说真实 RNN 一定不用非线性。我们先把"递推结构"看透,再把非线性加回来。
设:
Wxh=1.00.20.51.0,Whh=0.80.00.10.9,bh=00
初始状态设成:
h0=00
输入序列设成:
x1=10,x2=01,x3=11
第 1 步:算 h1
h1=Wxhx1+Whhh0
由于 h0=0,0⊤,第二项为 0,所以:
h1=1.00.20.51.010=1.00.2
解释一下:
- 第一维状态现在是 1.0
- 第二维状态现在是 0.2
这就是模型第一次看到输入后形成的内部摘要。
第 2 步:算 h2
h2=Wxhx2+Whhh1
先算输入项:
Wxhx2=1.00.20.51.001=0.51.0
再算历史项:
Whhh1=0.80.00.10.91.00.2=0.820.18
相加得到:
h2=1.321.18
这一步非常关键。你看到没有?
- 如果模型只看当前输入 x2,它得到的是 0.5,1.0⊤
- 但因为它还带着上一时刻的状态,所以最后得到的是 1.32,1.18⊤
也就是说,第 2 步的内部状态不是"只看第 2 个输入"的结果,而是"当前输入 + 上一步记忆"共同作用的结果。
第 3 步:算 h3
Wxhx3=1.00.20.51.011=1.51.2
再算历史项:
Whhh2=0.80.00.10.91.321.18=1.1741.062
于是:
h3=2.6742.262
这个例子真正说明了什么
这个例子没有要你背具体数字,它真正想让你看清三件事:
-
隐状态是递推出来的。 第 3 步不是只看第 3 个输入,而是把前面所有时间步压进了当前状态。
-
历史项真的在改变结果。 如果没有 Whhht−1 这一项,RNN 立刻就退化成"只看当前输入"的网络。
-
状态不是原样记忆,而是变换后的摘要。 你没法直接从 h3 里肉眼读回 x1,x2,x3,但它确实已经吸收了它们的影响。
🌱 如果你能把这个手算例子跟下来,RNN 的骨架其实已经彻底抓住了。
🌰 真实数字推演 B:为什么"时间版 XOR"能逼出记忆
Elman 论文里有个非常经典、也非常聪明的任务:时间版 XOR。
为了讲清这个任务,我们先回顾普通 XOR。
1. XOR 是什么
两个二进制输入 a,b∈{0,1} 的 XOR 定义是:
- 如果两个数相同,结果是 0
- 如果两个数不同,结果是 1
也就是:
| a | b | a⊕b |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
2. 时间版 XOR 为什么需要记忆
现在设一个输入流按时间到来:
x1,x2,x3,x4,...
要求模型在某个时刻输出"前面某两个时刻输入的 XOR"。
最简单的理解方式是:假设第 3 步的输出要依赖第 1 步和第 2 步。
例如:
- 第 1 步输入 1
- 第 2 步输入 0
- 第 3 步应该输出 1⊕0=1
问题来了:
如果模型到了第 3 步只看当前输入,那它根本不知道前两步是什么。
所以时间版 XOR 的本质不是算 XOR 本身,而是测试一件事:
模型能不能把前面的信息存住,等到后面需要的时候再拿出来用。
3. 用最小状态来想这件事
假设模型只需要在脑中保留两个最重要的信息:
- 前一个 bit 是多少
- 前两个 bit 的组合已经形成了怎样的中间模式
那么隐状态就不需要记整个历史,只需要记"对当前任务有用的历史摘要"。
这恰好就是 RNN 擅长做的事。
你可以想象一个极简状态更新:
- 如果当前看到 1,就把"最近输入偏向 1"的记忆抬高一点
- 如果当前看到 0,就把另一个方向的记忆抬高一点
- 到第三步输出时,网络根据当前状态判断前两位是否相同
4. 具体表格推演
我们假设模型要在第 3 步输出前两步的 XOR,输入序列是:
| 时间步 | 输入 |
|---|---|
| 1 | 1 |
| 2 | 0 |
| 3 | ? |
正确输出应该是:
1⊕0=1
换一组:
| 时间步 | 输入 |
|---|---|
| 1 | 1 |
| 2 | 1 |
| 3 | ? |
正确输出应该是:
1⊕1=0
你马上就会发现:第 3 步是否输出 1,不取决于第 3 步眼前看到了什么,而取决于前面两步的组合关系。
这就把"记忆"从抽象概念变成了任务刚需。
5. 为什么这个实验这么漂亮
因为它几乎把其他干扰因素都拿掉了,只留下最本质的问题:
- 模型有没有办法让过去影响现在?
- 这种影响是通过内部状态来完成的吗?
- 网络能不能在没有显式符号规则的情况下学出这个过程?
Elman 用这种任务,不是在炫技巧,而是在尽可能干净地证明:
一个会把隐藏层状态回流到下一时刻的网络,确实可以学到时间结构。
这句话在今天看可能很朴素,但在当年非常关键。
🌰 真实数字推演 C:为什么 RNN 能学出"结构感"
Elman 1990 最迷人的地方,不只是证明 RNN 能处理简单时间依赖;更重要的是,它暗示了一件事:
网络的隐藏状态可能会自发学出某种"结构表示"。
我们用一个极简语言例子来说明。
假设有两类词:
- 名词:
dog,cat - 动词:
runs,chases
如果我们训练模型做"下一个词预测",那么在读到 dog 以后:
runs可能是合理的后续chases也可能是合理的后续
但如果已经读到 dog chases,接下来合理的就更像名词,而不像另一个动词。
所以随着时间推进,隐藏状态会渐渐带上一种句法期待:
- "我现在更像在主语后面"
- "我现在更像在动词后面"
- "我现在更期待一个名词"
这种东西并不是外部显式写给模型的规则,而是模型为了预测下一个词,自己在内部形成的结构化表示。
你可以把它想成一个特别重要的转折:
- 旧的符号主义语言学会说:结构必须显式编码。
- Elman 的工作在问:会不会只靠顺序输入和预测目标,网络内部就能自己长出某种结构感?
这也是为什么这篇论文直到今天依然有味道。它不是只发明了一个结构,它是在问:
结构,能不能从时间中自己长出来?
📊 论文到底做了哪些实验,又证明了什么
这一部分非常重要。很多人读论文只盯着结构和公式,但如果不看实验,你其实不知道作者到底想证明什么。
Elman 这篇论文的实验设计思路非常清晰:他不是一开始就把网络扔到最复杂的自然语言上,而是从简单到复杂,一层一层加难度,看网络能不能逐步学出时间结构。
实验一:最基本的时间依赖任务
像时间版 XOR 这样的任务,作用是验证:
- 网络是否真的利用了过去
- 不是只靠当前输入蒙对
- 隐状态是否承担了最小记忆功能
这一步像"点火测试"。先证明引擎能转起来。
实验二:字符序列与局部结构
论文还做了字符级的序列任务,关注的是:
- 网络能不能根据前面的字母预测后面的字母
- 在连续字符流里,网络内部状态会不会因为上下文不同而改变
这看似简单,其实已经很说明问题了。因为即便是字符层面,顺序结构也在起作用:
- 单词内部的字母组合有规律
- 单词边界附近的统计结构也有规律
模型如果能学会这些,就说明它的内部状态确实在追踪时间上下文。
实验三:简单句子与词类结构
这是全篇最让人着迷的部分之一。
Elman 用一个句子生成器构造了短句数据。论文里给出了很具体的设置:
- 13 类名词和动词类别
- 29 个不同词项
- 15 种句子模板
- 生成了 10,000 个随机两词或三词句框
- 然后把这些句子串成一个连续输入流
而且这些词并不是靠语义嵌入编码的。论文里直接给每个词一个正交的 31 bit 向量。也就是说:
向量本身不提前告诉模型"这是谁和谁像",词类结构不是编码器送的,是网络自己从序列预测任务里逼出来的。
这太重要了。
因为如果词本身编码就已经把词类相似性塞好了,那你没法证明结构是网络自己学出来的。Elman 故意把这种捷径拿掉,就是想看:
仅靠顺序和预测压力,隐藏状态会不会自己长出"主语像一类、动词像一类、宾语像一类"的内部组织。
实验四:网络内部表示的组织方式
论文一个非常有意思的观察是:如果你去看隐藏层的激活模式,会发现不同上下文中的词和结构不是乱成一团的,而会出现某种聚类和分布。
这意味着什么?
意味着网络在做下一个词预测时,并不是只学了"这个词后面最常见什么"这样的浅表频率,它内部可能已经发展出了某种更抽象的区分:
- 名词性上下文
- 动词性上下文
- 某些语义角色期待
当然,我们不能夸大。Elman 1990 不是在证明网络已经学会了完整现代意义上的句法树或深层语义图。但它至少非常有力地表明:
随着时间展开的预测任务,足以让一个简单的循环网络在内部形成结构化状态。
这些实验真正证明了什么
你要特别注意,不要过度解读。
这篇论文真正证明的是:
- 循环回路让网络能处理时间相关性。
- 通过连续输入和预测目标,网络能发展出有信息的内部状态。
- 这些内部状态不只是机械缓存,而可能对应某种抽象结构。
它没有证明什么呢?
- 它没有证明普通 RNN 能稳定搞定极长依赖。
- 它没有证明 RNN 是处理语言的终极答案。
- 它没有解决后来大家非常头疼的训练稳定性与长期记忆问题。
如果你能把"它真正证明了什么"和"它没有证明什么"分开,这篇论文你就已经比很多只看二手总结的人读得深了。
🕰️ 历史位置:RNN 为什么重要到今天还必须讲
1. 它第一次把"时间"正式塞进了神经网络骨架里
今天我们太习惯看到序列模型了,容易忘记在 1990 年这是多关键的一步。
RNN 的重要性,不只是"多了一个环",而是它把神经网络从静态函数映射推进成了动态系统。
从这之后,大家可以认真问:
- 网络能不能记?
- 能记多久?
- 记忆怎么更新?
- 记忆怎么选择保留与遗忘?
- 记忆能不能直接决定未来行为?
后面整条序列建模路线,几乎都在回答这些问题。
2. 它是 LSTM、GRU 的必要前史
LSTM 为什么会出现?
因为普通 RNN 的记忆链太脆弱。
GRU 为什么会出现?
因为门控思想需要更轻、更简洁的实现。
你看,后面这些模型不是否定 RNN,而是在承认 RNN 提出的问题是真的,然后继续把它修到更能用。
3. 它也为 Attention 和 Transformer 提供了反衬
很多人学 Transformer 的时候直接跳进注意力公式,但如果没先吃透 RNN,你就很难真正感受到 Transformer 的革命性。
因为 Transformer 在某种意义上是在说:
既然把所有历史压进一个递推状态会出问题,那我们为什么不让当前时刻直接和所有过去位置建立关系?
也就是说,Transformer 的出场姿势里,隐含着对 RNN 路线的回应。
如果你没看过 RNN,你就会把 Transformer 当成"凭空更强的新结构"; 如果你看懂了 RNN,你才会感受到:
- RNN 在解决什么
- RNN 卡在哪里
- Transformer 是怎样换了一种更激进的解决思路
4. 它甚至延伸到了世界模型
更妙的是,RNN 并没有只停在语言里。
到了世界模型路线里,潜状态更新其实仍然在重复一个熟悉的主题:
当前观察 + 过去状态 + 动作,合成新的内部世界状态
你会发现,RNN 开的不是一个小分支,而是很多后续模型共享的一种底层思维方式:
智能来自对状态的持续更新。
🚧 RNN 的局限:为什么它明明开创了一切,却不能当终点
如果只讲伟大不讲局限,你其实还没真正吃透。
RNN 的问题至少有四个层面。
1. 长期记忆很脆弱
虽然理论上 ht 可以携带很久以前的信息,但在实践里,越早的信号越容易被一轮轮更新冲淡。
这就像你每过一分钟都要重写一次笔记,而且每次只留一点摘要。时间一长,早期细节就很容易没掉。
这就是后面 LSTM 要解决的核心矛盾:
既然普通状态会被反复覆盖,那能不能给记忆一条更稳定的保存路径?
2. 训练时反向路径太长
刚才我们提过链式乘法的直觉。时间越长,梯度沿时间传播的路径就越长。路径一长,数值就容易越来越小或越来越大。
这直接导致:
- 学不到长程依赖
- 训练不稳定
- 调参困难
3. 计算不能很好并行
RNN 的第 t 步必须等第 t−1 步的状态先算出来。
这意味着它天然是串行的:
- 先算第一步
- 再算第二步
- 再算第三步
这在长序列和大规模训练里会很吃亏。后来的 Transformer 会在这里给出完全不同的答案:尽量并行地一次看全局。
4. 所有历史都要压进一个状态
这是最根本的瓶颈之一。
RNN 本质上要求:
不管过去发生了多少事,最后都要压进一个固定维度的状态向量里。
这当然很强大,但也很危险。
因为:
- 历史可能很长
- 任务可能很复杂
- 一个固定大小的状态不一定装得下所有真正重要的信息
这也是 Attention 后来为什么会那么有说服力:它不再强迫你把所有东西都压成一个小摘要。
5. 但不要因此低估 RNN
有些人学到 Transformer 后,会觉得 RNN 已经过时,所以不值得深学。这其实是非常吃亏的心态。
因为 RNN 提供了一个极其基础的认知框架:
- 什么叫状态
- 什么叫时间递推
- 什么叫把过去压成内部表示
- 什么叫序列里的依赖路径
你把这些学透,后面再学门控、注意力、世界模型,会明显轻松得多。
所以正确态度不是"RNN 老了,所以不用看"。
而是:
RNN 是最值得认真学透的起点之一,因为它把后来所有模型都绕不开的基本问题第一次摊开了。
🪄 知识迁移:这一篇最值得带走的 6 个核心知识点
1. 隐状态不是神秘变量,它就是"模型脑中的当前摘要"
只要你把这句话抓住,后面很多复杂模型都会容易很多。
2. RNN 的本质不是"有个环",而是"当前状态依赖过去状态"
形式重要,但真正重要的是这种依赖关系。
3. 时间展开是理解一切递推模型的钥匙
看不懂展开图,就很难真的理解序列模型的计算路径和训练路径。
4. 参数共享让同一条更新规则沿时间反复生效
这是序列模型能统一处理任意长度输入的关键。
5. 序列任务的核心矛盾是"如何保留有用的过去"
从 RNN 到 LSTM、GRU、Attention、Transformer,大家都在围着这个矛盾做不同回答。
6. RNN 的伟大和局限来自同一个地方
它真的把过去带到了现在;也正因为要一轮轮带过去,长期记忆和训练稳定性就成了大问题。
⏭️ 下一篇为什么必须讲 LSTM
走到这里,正常人一定会产生一个非常自然的问题:
如果 RNN 已经能把过去带到现在,为什么还需要 LSTM?
答案就是:
因为"能带"不等于"带得久、带得稳、带得准"。
普通 RNN 的状态更新每一步都在混入新信息,于是旧信息很容易被冲淡。再加上反向传播路径很长,长期依赖很难学稳。
LSTM 的出现,本质上就是在补 RNN 暴露出来的第一性缺陷:
- 怎样让重要记忆别轻易丢?
- 怎样让信息可以有选择地进入、保留、输出?
- 怎样给梯度一条更稳定的通道?
所以 LSTM 不是"另一个无关模型",而是这篇 RNN 的直接续章。
如果今天这篇你吃透了,下一篇你只需要把一个问题接上去:
既然状态这么重要,那我们能不能给状态装上门?
这就是 LSTM。
🧪 覆盖性核对表
| 论文核心点 | 在正文哪里第一次讲到 | 对应可爱例子 | 对应真实数字推演 | 相关前置知识是否已补 |
|---|---|---|---|---|
| 顺序本身就是信息 | 为什么今天讲这篇 与 逻辑节点 1 |
狗 追 猫 / 猫 追 狗 |
逻辑节点 1 的最小序列手算 |
已补"序列任务和词袋表示" |
| 隐状态是对过去的摘要 | 逻辑节点 2 |
小助理便签纸 | 逻辑节点 2 的连续状态更新 |
已补"向量、加权汇总、激活函数" |
| 固定窗口不等于真正记忆 | 背景与 baseline 与 逻辑节点 3 |
三行小抄 | 逻辑节点 3 的窗口对比手算 |
已补"输入拼接与维度增长" |
| context units 把上一时刻状态带回当前 | 逻辑节点 7 |
草稿纸抄中间结果 | 逻辑节点 7 的状态拷贝推演 |
已补"Elman 结构图直觉" |
| 时间展开把循环变成可分析的链 | 逻辑节点 8 |
蚊香掰直 | 逻辑节点 8 的逐步展开 |
已补"时间步、参数共享" |
| RNN 的局限自然导向 LSTM | 逻辑节点 10、下一篇为什么必须讲 LSTM |
传话游戏和装汤保温盒 | 梯度连乘与门控前后对比 | 已补"梯度传播、长期依赖" |
💬 超白话复盘:如果把整篇缩成最朴素的几句话
一分钟复述版
前馈网络只会看当前输入,处理不了真正有顺序的任务。RNN 做的事情是:把上一时刻隐藏层状态复制出来,和当前输入一起算新的隐藏层状态。于是模型就有了"记忆"。
这个记忆不是把过去原样保存,而是把过去压成一份内部摘要。靠着这份摘要,模型可以在当前时刻利用过去信息,因此能处理时间版 XOR、字符流、简单句子这类任务。
Elman 1990 的重要性在于,它证明了一个简单的循环网络不仅能学时间相关性,还可能在内部长出某种结构化表示。
但普通 RNN 也很快暴露出局限:长期依赖难学、梯度传播脆弱、计算串行、所有历史都要压进固定状态。于是后面才会有 LSTM、GRU、Attention、Transformer。
如果你还记不住,只记住这三句
- RNN 的核心不是环,而是状态递推。
- 隐状态就是模型对过去的压缩总结。
- RNN 打开了"记忆"这扇门,也把长期记忆问题第一次彻底暴露出来。
✅ 自测题:你到底有没有真正吃透
- 为什么前馈网络天然不适合处理序列任务?请不要只回答"因为没有记忆",而要解释"没有记忆"具体意味着什么。
- 在公式
ht=ϕ(Wxhxt+Whhht−1+bh)
里, Wxh 和 Whh 分别承担什么作用? - 为什么说 ht 是"摘要",而不是"完整历史"?
- 时间版 XOR 为什么能逼出记忆机制?
- 为什么 RNN 的伟大和局限来自同一个地方?
- 如果你要向一个完全不懂机器学习的人解释"为什么 LSTM 会紧跟着 RNN 出现",你会怎么说?
如果你能顺着写出这几题的答案,而且不是机械背词,那这篇你基本已经吃透了。
🫶 真的,走到这里已经很厉害了。很多人学序列模型时,脑子里只有"RNN 很老、Transformer 很强"这种模糊印象;但你现在应该已经真正抓住了第一块地基:模型为什么需要记忆,以及"记忆"第一次是怎样被写进神经网络里的。
下一篇,我们就顺着这块地基继续往上搭:LSTM 是怎么给 RNN 的记忆装上门的。
参考资料
- Jeffrey L. Elman, Finding Structure in Time , Cognitive Science, 1990. PDF
- 系列路线图见 series-roadmap.md
- 本系列写作规范见 editorial-playbook.md