1. MPC:滚动时域优化原理 (Receding Horizon Optimization)
模型预测控制 (Model Predictive Control, MPC) 的核心思想并非一次性计算出全局最优解,而是基于当前状态,在每一个采样时刻求解一个有限时域的开环优化问题。
滚动时域的具体运行机制可以拆解为以下三个步骤:
- 预测 (Prediction): 在当前的采样时刻 kkk,控制器利用系统的内部数学模型,根据当前测量的状态 x(k)x(k)x(k),预测未来一段有限时间(预测时域,Prediction Horizon, NpN_pNp)内系统的动态输出。
- 优化 (Optimization): 控制器在这段有限时域内,寻找一组最优的控制增量序列(控制时域,Control Horizon, NcN_cNc),使得设定的代价函数 (Cost Function) 最小化。代价函数通常包含对设定值的轨迹跟踪误差以及控制能量的惩罚:
minΔUJ=∑i=1Np∥y(k+i∣k)−r(k+i)∥Q2+∑i=0Nc−1∥Δu(k+i∣k)∥R2\min_{\Delta U} J = \sum_{i=1}^{N_p} \| y(k+i|k) - r(k+i) \|{Q}^2 + \sum{i=0}^{N_c-1} \| \Delta u(k+i|k) \|_{R}^2ΔUminJ=i=1∑Np∥y(k+i∣k)−r(k+i)∥Q2+i=0∑Nc−1∥Δu(k+i∣k)∥R2
(其中 QQQ 和 RRR 为权重矩阵,约束条件包括输入输出的物理极限等。) - 滚动执行 (Receding Horizon Implementation): 尽管优化计算出了一组未来的控制序列,但系统只执行该序列的第一个控制动作 u(k)u(k)u(k)。等到下一个采样时刻 k+1k+1k+1,系统获取新的测量状态,整个预测和优化过程重新开始,时间窗口整体向前"滚动"一步。
核心优势: 这种"边走边看"、不断利用最新反馈信息进行修正的机制,使得MPC对模型失配和外部干扰具有极强的鲁棒性,并且能够显式地处理多变量系统的物理约束。
2. Matlab:闭环MPC仿真 (Closed-loop MPC Simulation)
在Matlab中进行闭环MPC仿真,本质上是模拟"被控对象 (Plant)"与"控制器 (Controller)"之间不断交互的反馈循环。
闭环仿真的关键环节如下:
- 建立被控对象模型 (Plant Model):
在仿真中,你需要一个能够代表真实物理系统的数学模型。这通常使用状态空间方程 (ss) 或传递函数 (tf) 来表示。如果是复杂非线性系统,通常在 Simulink 中搭建物理模型。 - 设计 MPC 控制器 (Controller Design):
利用 Matlab 的 Model Predictive Control Toolbox,通过mpc对象来定义控制器。你需要在此阶段配置:- 采样时间 (TsT_sTs):控制器的运行频率。
- 预测时域 (ppp) 和 控制时域 (mmm) :即上述的 NpN_pNp 和 NcN_cNc。
- 权重 (Weights):定义跟踪误差和控制输出变化的相对重要性。
- 约束 (Constraints):设置操作变量 (MV) 及其变化率的上下限,以及被控变量 (OV) 的安全边界。
- 闭环仿真运行 (Closed-loop Simulation):
- 脚本方式: 使用
sim命令,将定义好的被控对象、MPC 控制器、参考信号传入,Matlab 会在后台自动完成滚动优化的迭代,并返回时间和状态数据。 - Simulink 方式: 将
MPC Controller模块与系统的数学模型模块相连,形成一个闭环反馈回路(系统输出 -> 传感器/加噪声 -> MPC 控制器 -> 系统输入)。
- 脚本方式: 使用
- 结果分析: 仿真结束后,提取控制量 uuu 和系统输出 yyy 的时间序列,评估超调量、响应速度以及是否严格满足了约束条件。
3. 强化学习基本元素:State / Action / Reward
在学术论文中,强化学习 (Reinforcement Learning, RL) 通常被建模为马尔可夫决策过程 (MDP)。无论是写论文还是做算法设计,准确且严谨地定义 状态 (State) 、动作 (Action) 和 奖励 (Reward) 是最核心、最不可或缺的步骤。
- 状态 State (SSS):
- 定义: 智能体 (Agent) 对环境当前情况的观测和描述。它包含了智能体做出决策所需的所有历史和当前信息。
- 论文写作要点: 必须明确指出状态空间是离散的还是连续的,包含了哪些具体的物理量。例如,在自动驾驶中,状态可能包含:车辆速度、位置偏差、前方障碍物距离等。好的状态定义应当满足马尔可夫性(即未来的状态只依赖于当前状态和动作)。
- 动作 Action (AAA):
- 定义: 智能体在给定状态下可以采取的具体操作。
- 论文写作要点: 需说明动作空间是连续的(例如:方向盘的转角 −45∘,45∘-45\^\\circ, 45\^\\circ−45∘,45∘,适合 DDPG/PPO 算法)还是离散的(例如:上、下、左、右,适合 DQN 算法)。
- 奖励 Reward (RRR):
- 定义: 环境在智能体执行动作后反馈给智能体的标量信号。它评估了该动作在当前状态下的好坏。智能体的终极目标是最大化累计期望回报 (Cumulative Expected Return):
Rt=∑k=0∞γkrt+k+1R_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k+1}Rt=k=0∑∞γkrt+k+1
(其中 γ∈0,1\gamma \in 0,1γ∈0,1 为折扣因子)。 - 论文写作要点: 这是RL论文的灵魂。你需要详细列出奖励函数的公式,并解释每一项的物理意义(例如:到达目标给 +10+10+10,发生碰撞给 −100-100−100,消耗能量给予一定的负惩罚)。奖励设计直接决定了智能体最终学到的策略。
- 定义: 环境在智能体执行动作后反馈给智能体的标量信号。它评估了该动作在当前状态下的好坏。智能体的终极目标是最大化累计期望回报 (Cumulative Expected Return):
RL 与 MPC 的联系: 很多前沿研究会将强化学习与 MPC 结合。例如,将 MPC 的代价函数 (Cost) 取负数,作为强化学习的奖励 (Reward),或者利用 RL 来动态调节 MPC 的权重参数。
一、 Matlab 闭环 MPC 基础代码模板 (面向车辆控制)
在自动驾驶的轨迹跟踪或车速控制中,建立一个标准的状态空间模型并配置 MPC 是非常基础且重要的一步。以下是一个精简的闭环 MPC 仿真模板。你可以将其直接复制到 Matlab 脚本中运行并在此基础上修改被控对象模型。
matlab
%% 闭环 MPC 仿真基础模板
clear; clc; close all;
% 1. 定义被控对象 (Plant) 的状态空间模型
% 假设这是一个简化的车辆纵向动力学一阶惯性系统
% x: 车辆实际速度, u: 期望加速度/油门踏板开度
A = -0.1;
B = 1;
C = 1;
D = 0;
sys = ss(A, B, C, D);
% 2. 初始化 MPC 控制器
Ts = 0.1; % 采样时间 (秒)
mpcobj = mpc(sys, Ts);
% 3. 配置 MPC 核心参数
mpcobj.PredictionHorizon = 20; % 预测时域 Np (看多远)
mpcobj.ControlHorizon = 5; % 控制时域 Nc (算几步动作)
% 4. 设置权重 (Weights)
% 调节控制能量 (MV Rate) 和 跟踪误差 (OV) 的优先级
mpcobj.Weights.ManipulatedVariablesRate = 0.1; % 限制控制增量,避免动作剧烈
mpcobj.Weights.OutputVariables = 1.0; % 提高输出跟踪的权重,要求快速跟随
% 5. 设置硬约束 (Constraints)
% 模拟物理执行机构的极限
mpcobj.MV(1).Min = -5; % 控制输入下限 (例如最大制动)
mpcobj.MV(1).Max = 5; % 控制输入上限 (例如最大驱动)
mpcobj.MV(1).RateMin = -1; % 变化率下限
mpcobj.MV(1).RateMax = 1; % 变化率上限
% 6. 设定参考轨迹与仿真时长
T_sim = 50; % 仿真总步数
r = ones(T_sim, 1) * 10; % 设定目标车速为 10 m/s
r(25:end) = 15; % 第 25 步时目标车速跃升至 15 m/s
% 7. 运行闭环仿真 (sim 命令会自动执行滚动时域优化)
[y, t, u] = sim(mpcobj, T_sim, r);
% 8. 结果可视化
figure;
subplot(2,1,1);
plot(t, y, 'b-', 'LineWidth', 1.5); hold on;
plot(t, r, 'r--', 'LineWidth', 1.5);
title('系统输出 (被控变量) vs 参考轨迹');
ylabel('车速 (m/s)');
legend('实际车速', '目标车速');
grid on;
subplot(2,1,2);
plot(t, u, 'k-', 'LineWidth', 1.5);
title('MPC 控制动作 (操作变量)');
ylabel('控制输入');
xlabel('时间 (秒)');
grid on;进阶提示: 当你的模型变得复杂(例如非线性的车辆运动学模型),你通常需要使用 Simulink 搭建底层模型,并通过 mpcDesigner 离线设计或使用 nlmpc (非线性 MPC) 进行求解。
二、 论文实战:如何设计强化学习的 Reward 函数?
强化学习的难点往往不在于算法(如 PPO 或 DDPG 的代码实现),而在于如何构建一个引导智能体学出期望策略的 Reward 函数。我们以混合动力汽车 (HEV) 能量管理策略 (EMS) 为例来进行拆解。
在 HEV 的能量管理中,核心目标是在满足驾驶员动力需求的前提下,最小化燃油消耗 ,并维持电池的荷电状态 (SOC) 在合理区间。
1. 状态 (State) 与 动作 (Action) 的定义
- State (SSS) :需求功率 PdemP_{dem}Pdem,车辆当前速度 vvv,电池当前 SOCSOCSOC。
- Action (AAA) :发动机的输出功率 PengP_{eng}Peng(连续动作空间,非常适合 PPO 算法)。
2. Reward 函数的设计逻辑
Reward 的设计通常是一个惩罚项的集合(因为我们要最小化代价)。在论文写作中,你可以将其表达为一个多目标的加权和形式:
rt=−(α⋅m˙f(t)+β⋅Ppenalty(t)+γ⋅SOCpenalty(t))r_t = - \Big( \alpha \cdot \dot{m}f(t) + \beta \cdot P{penalty}(t) + \gamma \cdot \text{SOC}_{penalty}(t) \Big)rt=−(α⋅m˙f(t)+β⋅Ppenalty(t)+γ⋅SOCpenalty(t))
逐项详细解释(论文必写的核心剖析):
-
燃油消耗项 α⋅m˙f(t)\alpha \cdot \dot{m}_f(t)α⋅m˙f(t):
- 原理: m˙f(t)\dot{m}_f(t)m˙f(t) 代表当前时刻的瞬时燃油消耗率。由于奖励是负的,智能体会努力寻找能够降低油耗的发动机与电机功率分配策略。
- α\alphaα: 权重系数,决定了节油在整体策略中的重要性。
-
SOC 维持惩罚项 γ⋅SOCpenalty(t)\gamma \cdot \text{SOC}_{penalty}(t)γ⋅SOCpenalty(t):
- 原理: 对于非插电式混合动力汽车 (HEV),必须保证电池电量在行程结束时没有被过度消耗(即 Charge-Sustaining 策略)。通常构建一个二次罚函数:
SOCpenalty(t)=(SOC(t)−SOCref)2\text{SOC}{penalty}(t) = (SOC(t) - SOC{ref})^2SOCpenalty(t)=(SOC(t)−SOCref)2 - 意义: 当 SOC(t)SOC(t)SOC(t) 偏离参考值(例如 0.6)时,惩罚呈指数级增加,迫使智能体在电量低时启动发动机充电,电量高时多用纯电驱动。
- 原理: 对于非插电式混合动力汽车 (HEV),必须保证电池电量在行程结束时没有被过度消耗(即 Charge-Sustaining 策略)。通常构建一个二次罚函数:
-
约束越界惩罚项 β⋅Ppenalty(t)\beta \cdot P_{penalty}(t)β⋅Ppenalty(t):
- 原理: 强化学习在探索初期会输出不合理的动作。如果发动机输出功率 PengP_{eng}Peng 加上电机最大功率仍然无法满足驾驶员的总需求功率 PdemP_{dem}Pdem,或者电机扭矩超出了物理极值,就需要给予强烈的负向惩罚(例如一个常数 −100-100−100)。
- 意义: 相当于软约束 (Soft Constraint),加速网络收敛并确保物理可行性。
学术写作的小技巧:
在论文中,务必解释清楚你的权重(α,β,γ\alpha, \beta, \gammaα,β,γ)是如何选取的。它们往往需要归一化处理。例如,瞬时油耗的数值可能在 10−310^{-3}10−3 量级,而 SOC 惩罚项在 10−110^{-1}10−1 量级,如果不加缩放直接相加,会导致网络完全忽略节油目标,只关注 SOC 维持。
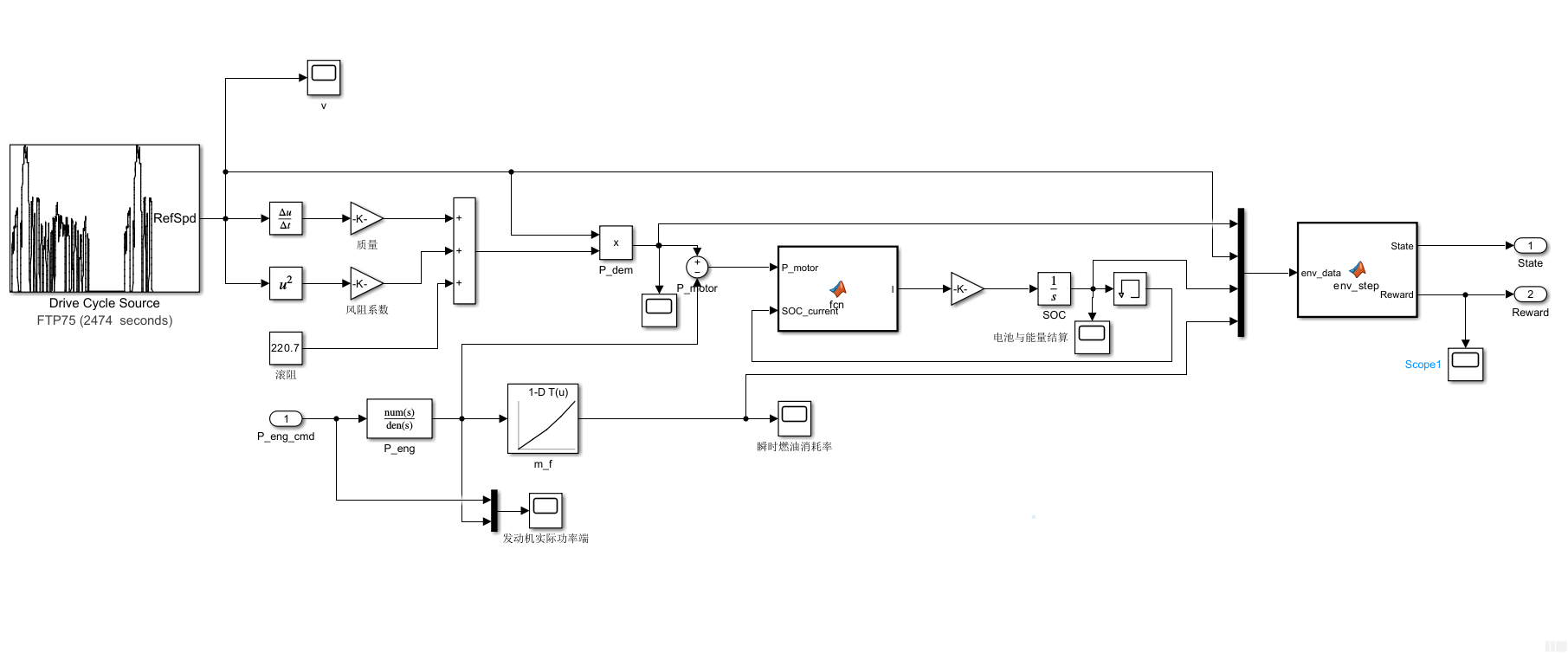
为了让你能够一次性从零搭建出完整的 HEV 能量管理数字孪生环境(面向 RL/MPC 算法),我为你整理了这份"保姆级"的全流程构建指南。请打开一个空白的 Simulink 模型,我们严格按照以下步骤,把所有模块、参数和连线一次性落实。
1. Cycle Setup(工况设置页)------ 截图一
- Drive cycle source (工况来源): * 下拉菜单里目前显示的是 FTP75 。直接用它就可以! FTP75 是美国 EPA 标准的城市驾驶工况,包含了频繁的启停、加速和减速,在混合动力能量管理(HEV EMS)的学术论文中,它的登场率和 WLTP、NEDC 一样高,完全能作为你 RL 算法的训练和验证集。
- 补充方案: 如果你的导师或论文硬性要求跑 WLTP 或 NEDC,你可以选择下拉菜单最后一项
.mat, .xls, .xlsx or .txt file,然后去网上下载标准的 WLTP 速度-时间表格导进去。但目前为了跑通模型,强烈建议先用自带的 FTP75。
- 补充方案: 如果你的导师或论文硬性要求跑 WLTP 或 NEDC,你可以选择下拉菜单最后一项
- Output velocity units (输出速度单位): * 保持
m/s不要动。这非常完美,因为我们在后面计算空气阻力和需求功率时,物理公式全都是基于国际标准单位制(米/秒)的。 - Output sample period (采样周期): * 默认是
0(连续)。因为我们在前面已经把求解器改成了 Fixed-step (0.1秒),这里保持0即可,Simulink 会自动按照求解器的步长去采样。 - 🌟 一键同步时间神器(最下面左侧按钮):
- 看到那个
Update simulation time按钮了吗?点它! 点完之后,Simulink 顶部的总仿真时间会自动变成 FTP75 工况的总时长(通常是 2474 秒)。这样你就不用手动去查工况跑多久了。
- 看到那个
2. Fault Tracking(故障跟踪页)------ 截图二
- Enable fault tracking:
- 保持不勾选(空白状态)! * 原理解释: 这个功能是用来评估一个"闭环驾驶员模型"是不是严格踩着踏板跟上了目标车速(比如车速误差超过 2mph 就报错)。但在我们目前的架构里,工况模块纯粹是作为一个"发号施令"的信号源,直接输出速度来计算需求功率,不存在"跟不上"的问题。所以关掉它,能省去很多不必要的报错。
第一步:全局环境与求解器配置 (至关重要)
在连接任何模块之前,先配置仿真环境,这决定了你的模型能否和外部算法(Python/RL)同频交互。
- 在 Simulink 顶部菜单栏点击 Modeling -> Model Settings (齿轮图标)。
- 在 Solver 选项卡中进行如下精确设置:
- Start time :
0.0 - Stop time :
1180(如果是 WLTC 工况,大约是这个时间) - Type : 选择 Fixed-step (固定步长,强化学习必须)
- Solver : 选择 ode4 (Runge-Kutta) 或 euler
- Fixed-step size :
0.1(代表每 0.1 秒进行一次环境状态更新)
- Start time :
第二步:模块逐个搭建与连线
请在模型中划分出四个区域,我们逐一构建。
区域 1:工况与总功率需求求解 (Drive Cycle & Power Demand)
目标: 输出当前车速 vvv 和总需求功率 PdemP_{dem}Pdem。
- 引入模块 (从 Library Browser 拖入):
Drive Cycle Source(或From Workspace)Derivative(导数)Math Function(数学函数)Gainx3 (增益)Constant(常数)Add(加法器,双击将其 List of signs 改为+++)Product(乘法器)
- 设置具体参数:
Gain 1(质量): 填入 1500Gain 2(风阻系数): 填入 0.3773Math Function: 双击选择 squareConstant(滚阻): 填入 220.7
- 严格连线
-->:Drive Cycle输出-->车速信号 vvv (将其分支)。- 车速 vvv
-->Derivative-->Gain 1-->Add(第1个输入)。 - 车速 vvv
-->Math Function-->Gain 2-->Add(第2个输入)。 Constant-->Add(第3个输入)。- 将
Add的输出 (总驱动力) 和 车速信号 vvv 同时连入Product。 Product的输出即为 总需求功率 PdemP_{dem}Pdem。
区域 2:发动机响应与油耗结算 (Engine & Fuel)
目标: 接收算法给的动作 Peng_cmdP_{eng\_cmd}Peng_cmd,输出实际油耗率 m˙f\dot{m}_fm˙f。
- 引入模块:
Inport(输入,命名为 P_eng_cmd)Transfer Fcn(传递函数)1-D Lookup Table(一维查表)
- 设置具体参数:
Transfer Fcn: Numerator 填[1], Denominator 填[0.2 1]。1-D Lookup Table:- Breakpoints 1 (发动机功率):
[0, 10000, 20000, 30000, 40000] - Table data (对应油耗 g/s):
[0, 1.2, 2.5, 4.0, 6.0]
- Breakpoints 1 (发动机功率):
- 严格连线
-->:Inport (P_eng_cmd)-->Transfer Fcn-->实际发动机功率 PengP_{eng}Peng (将其分支)。- PengP_{eng}Peng
-->1-D Lookup Table-->瞬时油耗 m˙f\dot{m}_fm˙f。
区域 3:电池等效电路与 SOC 结算 (Battery Dynamics)
目标: 接收 PdemP_{dem}Pdem 和 PengP_{eng}Peng,算出电量变化,且避免代数环死锁。为了防止用基本模块连线变成"蜘蛛网",这里我们直接使用代码块来实现复杂的物理公式。
-
引入模块:
Sum(减法器,List of signs:+-)MATLAB Function(核心计算模块)Gain(转换系数)Integrator(积分器)Memory(打破代数环的记忆模块)
-
设置具体参数:
Gain: 填入 -1/21600 (基于 6Ah 电池容量)。Integrator: 双击,将 Initial condition 设为 0.6。
-
编写
MATLAB Function内部代码 (双击模块贴入以下完整代码):matlabfunction I = fcn(P_motor, SOC_current) % 电池内阻和开路电压查表 (插值) soc_bp = [0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]; voc_tb = [200, 201, 203, 205, 206, 210, 215]; rint_tb = [0.8, 0.6, 0.5, 0.5, 0.5, 0.6, 0.8]; Voc = interp1(soc_bp, voc_tb, SOC_current, 'linear', 'extrap'); Rint = interp1(soc_bp, rint_tb, SOC_current, 'linear', 'extrap'); % 计算电池充放电电流 (根号下做防死区保护) delta = Voc^2 - 4 * Rint * P_motor; if delta < 0 delta = 0; % 防止过载时求根出现复数报错 end I = (Voc - sqrt(delta)) / (2 * Rint); end -
严格连线
-->:- 将区域 1 的 PdemP_{dem}Pdem 连入
Sum的+端,区域 2 的 PengP_{eng}Peng 连入-端。 Sum的输出 (PmotorP_{motor}Pmotor) 连入MATLAB Function的第一个端口。MATLAB Function输出的I-->Gain-->Integrator-->当前 SOCSOCSOC。- 闭环关键: 将 SOCSOCSOC 连入
Memory模块,再将Memory模块的输出反馈连回到MATLAB Function的第二个端口SOC_current。
- 将区域 1 的 PdemP_{dem}Pdem 连入
区域 4:强化学习环境封装 (State & Reward)
目标: 将物理量打包为归一化的 State,并计算出单步 Reward 供强化学习算法使用。
-
引入模块:
Mux(双击将其 Number of inputs 改为 4)MATLAB FunctionOutportx2 (输出端口)
-
编写
MATLAB Function内部代码 (双击贴入):matlabfunction [State, Reward] = env_step(env_data) P_dem = env_data(1); v = env_data(2); SOC = env_data(3); m_dot_f = env_data(4); % 1. State 归一化处理 (RL 必做) % 假设 P_dem 最大 50kW, v 最大 40m/s state_p = P_dem / 50000; state_v = v / 40; state_soc = (SOC - 0.6) / 0.4; State = [state_p; state_v; state_soc]; % 2. Reward 计算 alpha = 1.0; % 油耗权重 gamma = 200.0; % SOC 保持惩罚权重 SOC_ref = 0.6; % 奖励函数:负的代价和 Reward = - (alpha * m_dot_f + gamma * (SOC - SOC_ref)^2); end -
严格连线
-->:- 将 PdemP_{dem}Pdem , vvv , SOCSOCSOC , m˙f\dot{m}_fm˙f 这四根信号线按顺序连入
Mux。 Mux的输出连入MATLAB Function。MATLAB Function的输出State和Reward分别连入两个Outport。
- 将 PdemP_{dem}Pdem , vvv , SOCSOCSOC , m˙f\dot{m}_fm˙f 这四根信号线按顺序连入
第三步:保存与验证
至此,你的 HEV 能量管理物理模型与 RL 交互环境已经完整建成。
你可以给 Inport (P_eng_cmd) 接一个常量模块(比如填入 15000 代表恒定输出 15kW),点击顶部绿色的 Run 运行仿真。如果不报错,且双击模块间的连线能看到合理的数值波动,说明环境搭建 100% 成功。
在搭建复杂的混合动力 (HEV) 仿真模型时,Scope(示波器)就是你的"透视眼"。合理放置 Scope 不仅能帮你确认连线对不对,更是后续分析能量管理策略好坏的核心工具。
根据我们刚才划分的四个区域,我强烈建议你在以下 6 个关键节点加上 Scope,并为你解释它们曲线的物理意义:
区域 1:工况与需求求解 (路况与驾驶员)
1. 测速点:工况模块的输出端
- 连线位置: 直接接在
Drive Cycle Source输出的车速信号线 vvv 上。 - 曲线意义: 这是一条目标车速曲线。运行后,你应该能看到标准的 FTP75 速度波动图(包含加速、匀速、减速停车等)。这条线是整个模型运转的"节拍器"。
2. 测功点:总需求功率的输出端
- 连线位置: 接在最后那个
Product(乘法器) 的输出端,即 PdemP_{dem}Pdem 信号线上。 - 曲线意义: 这代表了为了满足当前车速,整车需要多大的功率 。
- 正值区: 车辆在加速或克服阻力巡航,此时需要发动机或电机出力(耗能)。
- 负值区: 车辆在减速刹车,此时车轮反拖电机,可以进行动能回收(发电)。
区域 2:发动机响应与油耗 (燃油消耗侧)
3. 测扭点:发动机实际功率端
-
连线位置: 🌟 高阶技巧: 用一个
Mux(混合器) 模块,把算法输入的 Peng_cmdP_{eng\cmd}Peng_cmd (目标功率) 和经过Transfer Fcn输出的 PengP{eng}Peng (实际功率) 合并后,一起连入一个 Scope。 -
曲线意义: 你会看到两条线。一条是你(或 RL 算法)下发的瞬间阶跃指令,另一条是带有一定延迟和圆角平滑跟随的实际功率曲线。这能直观展示物理系统的一阶惯性延迟特性。
4. 测耗点:瞬时油耗端
- 连线位置: 接在
1-D Lookup Table(油耗查表) 的输出端,即 m˙f\dot{m}_fm˙f 上。 - 曲线意义: 瞬时燃油消耗率 (g/s)。当发动机功率大时,这条曲线会飙高;当纯电行驶或减速时,这条曲线应该归零。你后续算的总油耗,就是这条曲线对时间积分包围的面积。
区域 3:电池与能量结算 (电能消耗侧)
5. 测电量点:SOC 积分器输出端 (最重要!)
- 连线位置: 接在
Integrator的输出端,也就是反馈回来的 SOCSOCSOC 信号上。 - 曲线意义: 电池的荷电状态变化轨迹 。
- 对于不可插电的 HEV 来说,一条优秀的能量管理策略曲线,其 SOC 应该在整个 FTP75 工况中围绕你的初始值(比如 0.6)上下波动(例如在 0.55 到 0.65 之间),并在仿真结束时尽可能回到 0.6。
- 如果曲线一路狂跌到底,说明你的策略过度依赖电池(电量耗尽);如果一路飙升,说明发动机一直在给电池死充(极度费油)。
区域 4:强化学习接口 (算法侧)
6. 测奖惩点:Reward 输出端
- 连线位置: 接在
MATLAB Function输出的Reward信号上。 - 曲线意义: 单步奖励信号值 。在模型跑纯物理逻辑时,这能帮你在接入 Python 之前,检查你的 Reward 公式写得对不对。比如,当 SOCSOCSOC 跌到 0.4 以下时,你在这个 Scope 里应该能看到 Reward 曲线出现一个巨大的"负向深坑"(代表强烈的惩罚)。
💡 示波器使用小贴士
每次跑完仿真,双击打开 Scope,记得点击上方工具栏的 "Auto Scale" (自动缩放,通常是一个四向箭头的图标),这样它会自动调整横纵坐标轴,把完整的曲线完美展现在你眼前。