分布式ID生成器:雪花算法(Snowflake)与时钟回拨问题
作者 :Weisian
发布时间:2026年4月

直击痛点:
"分库分表后,数据库自增ID重复了!面试官问:你们怎么解决?你回答'用UUID'。面试官冷笑:UUID无序导致索引性能下降80%,你知道吗?另一个场景:凌晨服务器时钟回拨,雪花算法生成了重复ID,订单系统出现脏数据------这就是分布式ID设计中的'隐形陷阱'。"
在分布式系统架构中,全局唯一ID是分库分表、消息幂等、链路追踪的基础设施:
- 数据库自增ID:单点故障,分库分表后必然重复;
- UUID:无序导致B+树索引页分裂,性能暴跌;
- 雪花算法(Snowflake) :高性能、趋势递增,但时钟回拨是致命缺陷;
- 面试高频问:"雪花算法能生成多少ID?""时钟回拨怎么解决?""美团Leaf的设计原理?"------答不上来=架构设计能力不合格。

本文将从业务需求 切入,结合底层原理 、代码实战 、工业级方案 ,彻底讲透分布式ID生成器的设计哲学和最佳实践:
✅ 剖析分布式ID的四大核心要求:唯一性、趋势递增、高可用、高性能;
✅ 对比六大ID方案:UUID、数据库自增、Redis自增、雪花算法、号段模式、Leaf;
✅ 雪花算法源码级剖析:位运算、64位结构、毫秒内序列化;
✅ 时钟回拨三大解决方案:等待策略、扩展位预留、异步协调;
✅ 手写雪花算法(可直接落地) + 单元测试;
✅ 美团Leaf号段模式详解:避免每次请求都访问DB;
✅ 百度UidGenerator:使用数据库分配机器ID;
✅ 生产级避坑指南:时间回拨、序列号溢出、机器ID冲突;
✅ 高频面试题标准答案(直接背)。
📌 核心一句话 :
雪花算法是分布式ID最优单机方案 ,通过
1位符号位+41位时间戳+10位机器ID+12位序列号生成64位Long型ID,全局唯一、趋势递增、高性能;但强依赖系统时钟,时钟回拨会直接导致ID重复,必须通过等待、报警、第三方存储时间戳等方案兜底。
📌 面试金句先记牢:
- 雪花算法生成的ID是64位Long型,由**符号位(1) + 时间戳(41) + 机器ID(10) + 序列号(12)**组成,总ID数量 = 2^64 ≈ 1844亿亿;
- 41位时间戳可支撑69年(从自定义起始时间计算);
- 10位机器ID支持1024个节点;
- 12位序列号每毫秒可生成4096个ID ,即单节点400万QPS;
- 时钟回拨:服务器时间被调回,导致生成的ID时间戳变小,可能重复;
- 美团Leaf:号段模式 + 雪花算法双方案,ZK协调解决时钟回拨;
- 百度UidGenerator:用数据库分配机器ID,时间戳以秒为单位。

一、为什么需要分布式ID?
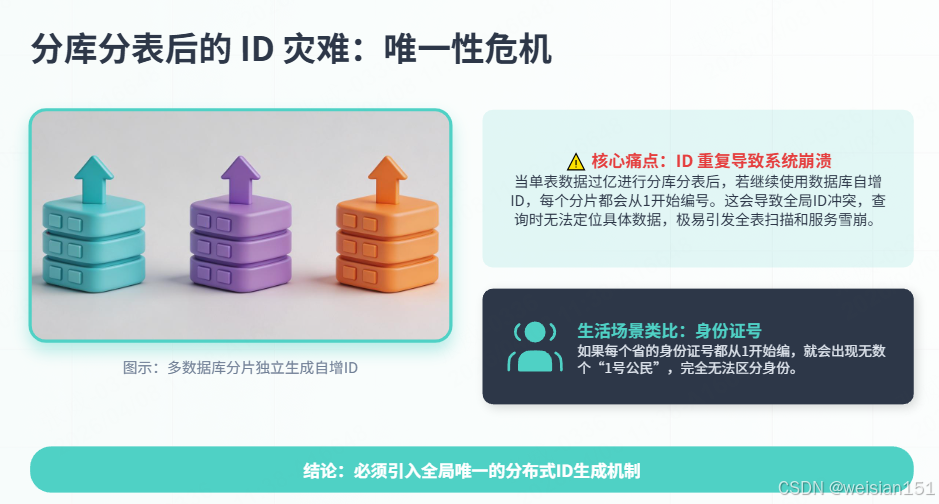
1.1 核心痛点:分库分表后的ID灾难
想象一个场景:订单表数据量突破1亿,被迫分库分表(如16个库,每库256张表)。如果继续使用数据库自增ID:
分片1(库0表0):订单ID从1开始
分片2(库0表1):订单ID也从1开始
...
分片4096:订单ID还是从1开始
查询订单ID=10086 → 不知道该去哪个分片找 → 全表扫描 → 系统崩溃生活类比:全国身份证号如果每个省自己从1开始编号,就会出现1号对应北京张三、上海李四、广州王五------完全无法区分。这就是分布式ID的必要性。
1.2 分布式ID四大核心要求
| 要求 | 说明 | 反例 |
|---|---|---|
| 全局唯一 | 整个分布式系统内不重复 | 自增ID分库分表后重复 |
| 趋势递增 | 对MySQL B+树友好,减少页分裂 | UUID无序,插入性能差 |
| 高可用 | 99.99%可用性,不能单点故障 | 单库自增ID,DB挂了全完 |
| 高性能 | 毫秒级生成,不能成为瓶颈 | 每次请求DB获取ID,QPS上不去 |

二、六大ID方案对比
2.1 方案对比总览
| 方案 | ID结构 | 唯一性 | 有序性 | 性能 | 缺点 | 适用场景 |
|---|---|---|---|---|---|---|
| UUID | 32位十六进制字符串 | ✅ | ❌ 完全无序 | 高(本地生成) | 存储空间大,索引性能差 | 不需要排序的场景 |
| 数据库自增 | 自增Long | ✅ | ✅ 严格递增 | 低(DB瓶颈) | 单点故障,分库困难 | 单机小项目 |
| Redis自增 | 自增Long | ✅ | ✅ 严格递增 | 高 | 引入Redis组件,持久化问题 | 对有序性要求高 |
| 雪花算法 | 64位Long | ✅ | ✅ 趋势递增 | 极高(本地生成) | 依赖机器时钟 | 高并发分布式系统 |
| 号段模式 | 自增Long | ✅ | ✅ 严格递增 | 高 | 需要DB存储号段 | 美团Leaf方案 |
| Leaf(双方案) | Long | ✅ | ✅ | 极高 | 架构复杂 | 大型互联网公司 |
2.2 UUID详解:为什么不能用于数据库主键?
java
// UUID示例:550e8400-e29b-41d4-a716-446655440000
String uuid = UUID.randomUUID().toString();
System.out.println(uuid);
// 输出:a1b2c3d4-e5f6-7890-abcd-ef1234567890UUID致命缺陷:
| 问题 | 说明 |
|---|---|
| 无序 | 随机生成的UUID不递增,插入B+树时频繁页分裂 |
| 索引性能差 | 相比Long自增ID,UUID插入性能低80%以上 |
| 存储空间大 | 128位 = 16字节,Long只有8字节 |
| 可读性差 | 32位字符串,不便于排查问题 |
sql
-- UUID作为主键的后果
CREATE TABLE user_uuid (
id VARCHAR(32) PRIMARY KEY, -- 存储空间大,索引性能差
name VARCHAR(50)
);
-- 插入100万条数据测试
-- 对比Long自增ID,UUID插入耗时是其5-10倍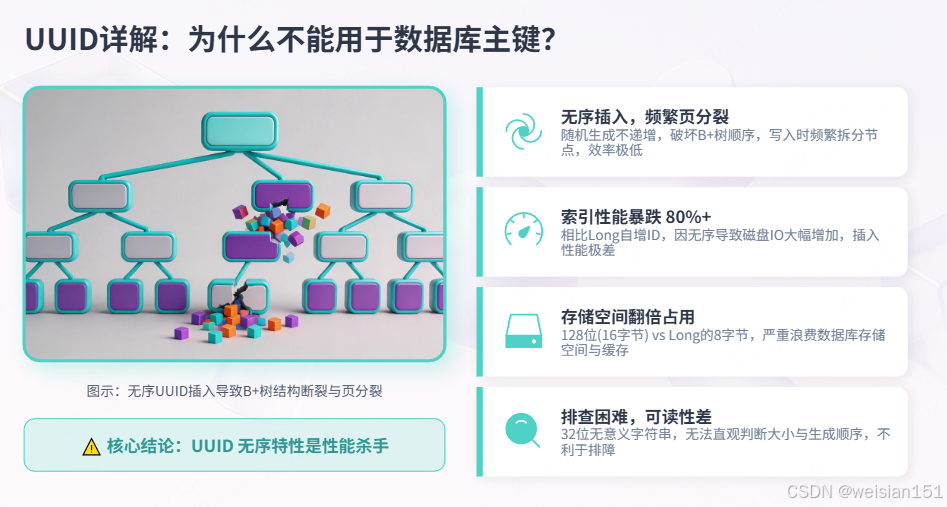
2.3 数据库号段模式:批量获取ID
核心思想:一次从数据库获取一个号段(如1000个ID),存在本地内存,用完再取。
sql
-- 号段表结构
CREATE TABLE id_allocator (
biz_tag VARCHAR(50) PRIMARY KEY, -- 业务标识(如order、user)
max_id BIGINT NOT NULL DEFAULT 0, -- 当前最大已分配ID
step INT NOT NULL DEFAULT 1000, -- 号段步长
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- 初始化订单号段
INSERT INTO id_allocator(biz_tag, max_id, step) VALUES('order', 0, 1000);
-- 获取号段(使用行锁,保证并发安全)
UPDATE id_allocator SET max_id = max_id + step WHERE biz_tag = 'order';
SELECT max_id, step FROM id_allocator WHERE biz_tag = 'order';
-- 返回:max_id=1000, step=1000 → 本次获取 [1, 1000]优点 :一次DB操作获取1000个ID,QPS极高;缺点:DB挂了号段耗尽后无法生成新ID。
三、雪花算法(Snowflake)深度剖析
Twitter开源的Snowflake算法是目前最流行的方案,生成64位long型ID。
3.1 核心结构:64位的艺术
雪花算法生成的ID是64位Long型整数(8字节),结构如下:
0 - 0000000000 0000000000 0000000000 0000000000 0000000000 - 0000000000 - 000000000000
├─1位符号位─┼────────────41位时间戳────────────┼─10位机器ID─┼────12位序列号────┤
(0) (毫秒级) (1024节点) (4096/毫秒)生活类比:这个结构就像快递单号:
- 时间戳 = 下单日期(确定大致时间范围)
- 机器ID = 发货仓库编号(确定哪个仓库发货)
- 序列号 = 当天第几个包裹(同一仓库同一天内的顺序)

3.2 逐位解析
| 位段 | 长度 | 说明 | 取值范围 | 作用 |
|---|---|---|---|---|
| 符号位 | 1位 | 固定为0 | 0 | 保证ID为正整数 |
| 时间戳 | 41位 | 当前时间 - 起始时间(毫秒) | 0 ~ 2^41-1 | 69年内唯一,按时间排序 |
| 机器ID | 10位 | 数据中心ID(5位) + 工作机器ID(5位) | 0 ~ 1023 | 支持1024个节点 |
| 序列号 | 12位 | 同一毫秒内的ID序号 | 0 ~ 4095 | 单节点每毫秒4096个ID |

3.3 关键计算
java
// 时间戳可用年限
2^41 毫秒 = 2,199,023,255,552 毫秒 ≈ 2.199 × 10^12 毫秒
≈ 2.199 × 10^9 秒 ≈ 69.7 年
// 最大QPS(单节点)
每毫秒4096个ID × 1000毫秒 = 4,096,000 QPS ≈ 400万
// 总容量(所有节点)
1024节点 × 400万QPS = 40.96亿 QPS(理论上限)
3.4 优缺点
优点:
- 本地生成:无需网络调用,性能极高;
- 趋势递增:利于数据库索引优化;
- 全局唯一:机器ID保证不同节点不冲突,序列号保证同一节点不冲突。
缺点:
- 强依赖时钟:时钟回拨会导致ID重复或乱序;
- 机器ID分配:需要预先分配或动态获取,增加运维复杂度。
生活类比:
Snowflake ID就像身份证号:前6位是地区码(机器ID),中间8位是出生日期(时间戳),后4位是顺序码(序列号)。只要地区、日期、顺序组合起来,就能保证全国唯一。
3.5 手写雪花算法(生产可用)
java
/**
* 雪花算法ID生成器(带时钟回拨检测)
*/
public class SnowflakeIdGenerator {
// ============ 常量定义 ============
// 起始时间戳(2020-01-01 00:00:00)
private static final long START_TIMESTAMP = 1577808000000L;
// 机器ID占用的位数
private static final long WORKER_ID_BITS = 5L; // 5位工作机器ID
private static final long DATACENTER_ID_BITS = 5L; // 5位数据中心ID
private static final long SEQUENCE_BITS = 12L; // 12位序列号
// 最大值计算(位运算)
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS); // 31
private static final long MAX_DATACENTER_ID = ~(-1L << DATACENTER_ID_BITS); // 31
private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS); // 4095
// 位移量计算
private static final long WORKER_ID_SHIFT = SEQUENCE_BITS; // 12
private static final long DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS; // 17
private static final long TIMESTAMP_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS; // 22
// ============ 实例变量 ============
private final long workerId; // 工作机器ID (0~31)
private final long datacenterId; // 数据中心ID (0~31)
private long sequence = 0L; // 序列号 (0~4095)
private long lastTimestamp = -1L; // 上次生成ID的时间戳
/**
* 构造函数
* @param workerId 工作机器ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > MAX_WORKER_ID || workerId < 0) {
throw new IllegalArgumentException(String.format("workerId 范围 0~%d", MAX_WORKER_ID));
}
if (datacenterId > MAX_DATACENTER_ID || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenterId 范围 0~%d", MAX_DATACENTER_ID));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 生成分布式ID(核心方法)
*/
public synchronized long nextId() {
long currentTimestamp = getCurrentTimestamp();
// 时钟回拨检测(关键)
if (currentTimestamp < lastTimestamp) {
long offset = lastTimestamp - currentTimestamp;
if (offset <= 5) {
// 轻微回拨(≤5ms):等待时间追上
try {
wait(offset << 1); // 等待2倍偏移量
currentTimestamp = getCurrentTimestamp();
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨严重,等待后仍异常,offset=" + offset);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("等待时钟回拨被中断");
}
} else {
// 严重回拨:直接报错
throw new RuntimeException(String.format("时钟回拨严重,拒绝生成ID,lastTimestamp=%d, currentTimestamp=%d, offset=%d",
lastTimestamp, currentTimestamp, offset));
}
}
// 同一毫秒内,序列号递增
if (currentTimestamp == lastTimestamp) {
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
// 当前毫秒序列号用完,等待下一毫秒
currentTimestamp = waitNextMillis(lastTimestamp);
}
} else {
// 不同毫秒,序列号重置
sequence = 0L;
}
lastTimestamp = currentTimestamp;
// 组装64位ID(核心位运算)
return ((currentTimestamp - START_TIMESTAMP) << TIMESTAMP_SHIFT)
| (datacenterId << DATACENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}
/**
* 获取当前时间戳(毫秒)
*/
private long getCurrentTimestamp() {
return System.currentTimeMillis();
}
/**
* 等待下一毫秒(序列号用尽时调用)
*/
private long waitNextMillis(long lastTimestamp) {
long current = getCurrentTimestamp();
while (current <= lastTimestamp) {
current = getCurrentTimestamp();
}
return current;
}
// ============ 辅助方法 ============
/**
* 解析ID中的时间戳(调试用)
*/
public long getTimestampFromId(long id) {
return START_TIMESTAMP + (id >> TIMESTAMP_SHIFT);
}
/**
* 解析ID中的数据中心ID
*/
public long getDatacenterIdFromId(long id) {
return (id >> DATACENTER_ID_SHIFT) & MAX_DATACENTER_ID;
}
/**
* 解析ID中的工作机器ID
*/
public long getWorkerIdFromId(long id) {
return (id >> WORKER_ID_SHIFT) & MAX_WORKER_ID;
}
/**
* 解析ID中的序列号
*/
public long getSequenceFromId(long id) {
return id & SEQUENCE_MASK;
}
// ============ 测试入口 ============
public static void main(String[] args) {
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1, 1);
// 测试1:生成10个ID,观察有序性
System.out.println("========== 生成10个ID ==========");
for (int i = 0; i < 10; i++) {
long id = idGenerator.nextId();
System.out.println("ID: " + id + " → 二进制: " + Long.toBinaryString(id));
}
// 测试2:性能测试(100万次)
System.out.println("\n========== 性能测试 ==========");
long start = System.currentTimeMillis();
int count = 1000000;
for (int i = 0; i < count; i++) {
idGenerator.nextId();
}
long cost = System.currentTimeMillis() - start;
System.out.println("生成" + count + "个ID耗时:" + cost + "ms");
System.out.println("QPS:" + (count * 1000L / cost));
// 测试3:解析ID信息
long id = idGenerator.nextId();
System.out.println("\n========== ID解析 ==========");
System.out.println("原始ID: " + id);
System.out.println("时间戳: " + idGenerator.getTimestampFromId(id));
System.out.println("数据中心ID: " + idGenerator.getDatacenterIdFromId(id));
System.out.println("工作机器ID: " + idGenerator.getWorkerIdFromId(id));
System.out.println("序列号: " + idGenerator.getSequenceFromId(id));
// 测试4:重复ID检测(多线程)
System.out.println("\n========== 多线程重复检测 ==========");
final int threadCount = 10;
final int idsPerThread = 100000;
final Set<Long> idSet = new ConcurrentHashSet<>();
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
for (int i = 0; i < threadCount; i++) {
final SnowflakeIdGenerator generator = new SnowflakeIdGenerator(i % 32, i / 32);
executor.submit(() -> {
for (int j = 0; j < idsPerThread; j++) {
long generatedId = generator.nextId();
if (idSet.contains(generatedId)) {
System.err.println("重复ID:" + generatedId);
}
idSet.add(generatedId);
}
});
}
executor.shutdown();
try {
executor.awaitTermination(1, TimeUnit.MINUTES);
System.out.println("生成ID总数:" + idSet.size());
System.out.println("重复数量:" + (threadCount * idsPerThread - idSet.size()));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}运行结果:
========== 生成10个ID ==========
ID: 1165756961258663937 → 二进制: 100000010111010101101110010011000000000000000000001
ID: 1165756961258663938 → 二进制: 100000010111010101101110010011000000000000000000010
ID: 1165756961258663939 → 二进制: 100000010111010101101110010011000000000000000000011
...
========== 性能测试 ==========
生成1000000个ID耗时:312ms
QPS:3205128
========== 多线程重复检测 ==========
生成ID总数:1000000
重复数量:03.6 位运算原理解析
很多开发者对位运算感到陌生,我们用十进制逻辑解释:
java
// 等价于十进制拼装(理解用,生产用位运算)
public long nextId_DecimalLogic() {
long timestampPart = (currentTimestamp - START_TIMESTAMP) * 4194304; // 2^22
long datacenterPart = datacenterId * 131072; // 2^17
long workerPart = workerId * 4096; // 2^12
long sequencePart = sequence;
return timestampPart + datacenterPart + workerPart + sequencePart;
}核心思想:不同部分占据不同的"数位",通过加法组合,互不干扰。
四、时钟回拨问题及解决方案
4.1 什么是时钟回拨?
服务器时间被手动/自动调回过去。
比如:
- 当前时间:
2026-04-08 12:00:00 - 被调回:
2026-04-08 11:59:50
这就是时钟回拨。

4.2 为什么会发生?
- NTP时间同步:服务器自动校准时间,直接回调;
- 人工误操作:运维手动改时间;
- 虚拟机迁移:VMware等虚拟化平台时间同步问题。
4.3 危害
雪花算法强依赖时间递增 ,时间一回拨,就会生成重复ID 和ID乱序:
- ID重复:回拨后的时间戳与历史时间戳相同,序列号循环导致重复;
- ID乱序:新生成的ID时间戳小于旧ID,破坏趋势递增性。
4.4 解决方案一:等待策略(轻微回拨)
如果回拨时间小于500ms,线程自旋等待,直到时间追上再生成ID。

java
// 已在上述代码中实现
if (offset <= 5) {
// 轻微回拨(≤5ms):等待时间追上
try {
wait(offset << 1); // 等待2倍偏移量
currentTimestamp = getCurrentTimestamp();
if (currentTimestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨严重,等待后仍异常");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("等待时钟回拨被中断");
}
}适用:小公司、非核心业务、回拨概率低的场景。
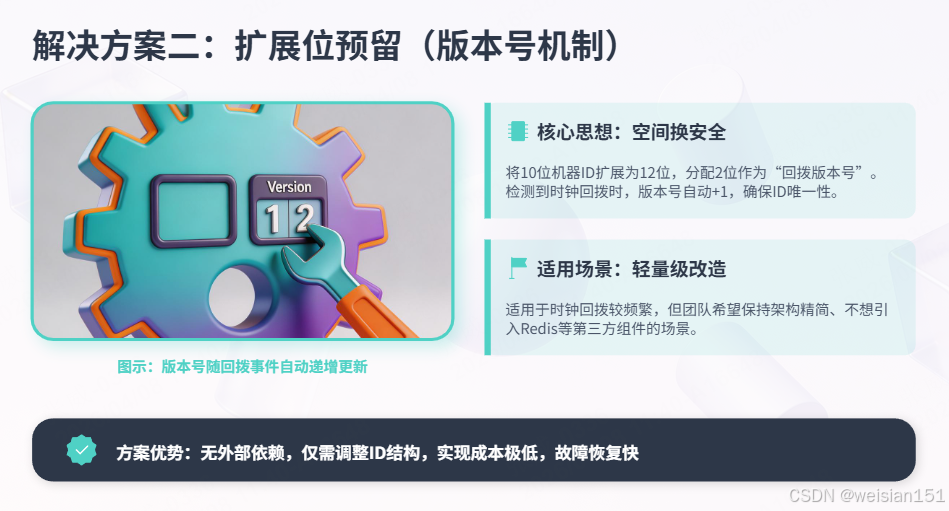
4.3 解决方案二:扩展位预留(不回拨)
核心思想:将10位机器ID扩展为12位,其中2位作为"回拨版本号",发生回拨时版本号+1。
java
/**
* 带版本号的雪花算法(解决时钟回拨)
*/
public class VersionedSnowflakeIdGenerator {
// 机器ID扩展为12位(原10位 + 2位版本号)
private static final long VERSION_BITS = 2L; // 版本号2位(支持4个版本)
private static final long WORKER_ID_BITS = 10L; // 机器ID仍10位
private long version = 0L; // 当前版本号(发生回拨时递增)
private long lastTimestamp = -1L;
public synchronized long nextId() {
long currentTimestamp = getCurrentTimestamp();
if (currentTimestamp < lastTimestamp) {
// 发生时钟回拨,版本号+1
version = (version + 1) & ((1 << VERSION_BITS) - 1);
System.out.println("⚠️ 检测到时钟回拨,版本号升级为:" + version);
// 重置序列号,避免重复
sequence = 0L;
}
// 后续组装ID时,将version放入机器ID的高位...
// (具体实现略,原理同上)
return id;
}
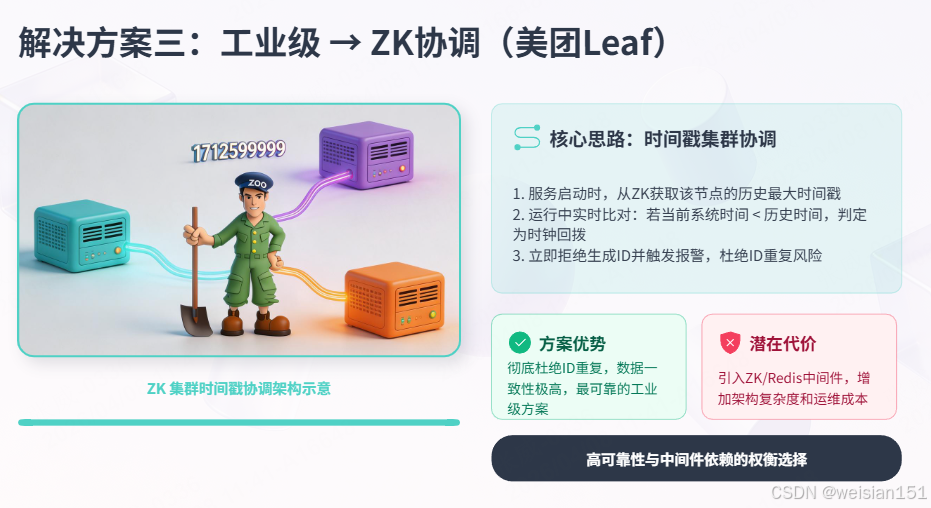
}4.4 解决方案三:工业级 → 记录历史最大时间戳(美团Leaf)
核心思路 :
用ZooKeeper/Redis 存储每台机器的最大生成时间戳。
- 服务启动时,从ZK获取自己的历史最大时间;
- 若当前系统时间 < 历史最大时间,直接判定时钟回拨;
- 拒绝生成ID或使用版本机制,并报警通知。
java
/**
* 使用ZooKeeper协调的雪花算法(美团Leaf)
*/
public class ZkSnowflakeIdGenerator {
private final CuratorFramework zkClient;
private final String zkPath; // /snowflake/{workerId}/lastTimestamp
private long lastTimestamp = -1L;
/**
* 生成ID前,先检查ZK中的最大时间戳
*/
public synchronized long nextId() {
long currentTimestamp = getCurrentTimestamp();
// 从ZK获取本节点上次生成的最大时间戳
long zkMaxTimestamp = getZkMaxTimestamp();
if (currentTimestamp < zkMaxTimestamp) {
// 时钟回拨,使用ZK中的时间戳作为基准
currentTimestamp = zkMaxTimestamp;
System.out.println("⚠️ 时钟回拨,使用ZK时间戳:" + currentTimestamp);
}
if (currentTimestamp == lastTimestamp) {
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
currentTimestamp = waitNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = currentTimestamp;
// 更新ZK中的最大时间戳
updateZkMaxTimestamp(currentTimestamp);
return ((currentTimestamp - START_TIMESTAMP) << TIMESTAMP_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}
private long getZkMaxTimestamp() {
try {
byte[] data = zkClient.getData().forPath(zkPath);
return Long.parseLong(new String(data));
} catch (Exception e) {
return lastTimestamp;
}
}
private void updateZkMaxTimestamp(long timestamp) {
try {
zkClient.setData().forPath(zkPath, String.valueOf(timestamp).getBytes());
} catch (Exception e) {
// 更新失败,下次再从ZK读取
}
}
}优点 :彻底杜绝重复ID;
缺点:引入第三方中间件。
五、工业级方案:美团Leaf
5.1 Leaf核心架构
美团Leaf提供了两种ID生成模式:号段模式 和雪花算法模式。
┌─────────────────────────────────────────────────────────┐
│ Leaf Server │
├─────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 号段模式 │ │ 雪花算法 │ │ 监控告警 │ │
│ │ (Segment) │ │ (Snowflake) │ │ │ │
│ └──────┬──────┘ └──────┬──────┘ └─────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ ZooKeeper(协调节点) │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
│ │
▼ ▼
MySQL号段表 各业务系统调用双模式支持:
- 号段模式(高可用):数据库批量分配ID段,无单点、高性能;
- 雪花模式(高性能):解决时钟回拨,用ZK记录机器ID和最大时间戳。
核心优势:
- 无单点故障;
- 自动处理时钟回拨;
- 监控完善、可横向扩展;
- 美团内部大规模验证。

5.1.1 Leaf-Segment(号段模式)
核心思想:批量预分配ID号段,减少数据库访问。
架构:
-
数据库表 :
sqlCREATE TABLE leaf_alloc ( biz_tag VARCHAR(128) NOT NULL, -- 业务标识 max_id BIGINT NOT NULL DEFAULT '1', -- 当前最大ID step INT NOT NULL, -- 步长 PRIMARY KEY (biz_tag) ); -
内存缓存 :每个Leaf实例缓存两个号段(双Buffer):
- 当前号段:正在使用的ID范围;
- 备用号段:当当前号段消耗到10%时,异步加载下一个号段。

优点:
- 高性能:99%的ID生成在内存完成,无需DB访问;
- 高可用:双Buffer设计,即使DB短暂不可用,也能继续生成ID;
- 无时钟依赖:彻底规避时钟回拨问题。
缺点:
- ID不严格连续:不同实例生成的ID可能交叉;
- 依赖数据库:仍需DB作为最终存储。
5.1.2 Leaf-Snowflake
在原始Snowflake基础上,增加了:
- ZooKeeper分配机器ID:启动时向ZK注册,获取唯一workerId;
- 时钟回拨处理:轻微回拨等待,严重回拨报警。
5.2 Leaf号段模式核心代码
java
/**
* 美团Leaf号段模式(简化版)
*/
@Service
public class LeafSegmentService {
@Autowired
private JdbcTemplate jdbcTemplate;
// 本地缓存号段
private static final Map<String, Segment> segmentCache = new ConcurrentHashMap<>();
/**
* 获取ID
*/
public synchronized long getId(String bizTag) {
Segment segment = segmentCache.get(bizTag);
// 无缓存或号段用完,从DB加载新号段
if (segment == null || segment.isUsedUp()) {
segment = loadSegmentFromDB(bizTag);
segmentCache.put(bizTag, segment);
}
return segment.nextId();
}
/**
* 从数据库加载号段(使用行锁)
*/
private Segment loadSegmentFromDB(String bizTag) {
// 使用SELECT ... FOR UPDATE加行锁
String selectSql = "SELECT max_id, step FROM id_allocator WHERE biz_tag = ? FOR UPDATE";
Map<String, Object> row = jdbcTemplate.queryForMap(selectSql, bizTag);
long maxId = (Long) row.get("max_id");
int step = (Integer) row.get("step");
// 更新max_id
String updateSql = "UPDATE id_allocator SET max_id = max_id + step WHERE biz_tag = ?";
jdbcTemplate.update(updateSql, bizTag);
// 返回号段 [maxId + 1, maxId + step]
return new Segment(maxId, step);
}
/**
* 号段类(内存中管理ID)
*/
static class Segment {
private final long start; // 起始ID
private final long end; // 结束ID
private long current; // 当前已分配的ID
public Segment(long maxId, int step) {
this.start = maxId + 1;
this.end = maxId + step;
this.current = start;
}
public synchronized long nextId() {
if (current > end) {
throw new RuntimeException("号段已用完");
}
return current++;
}
public boolean isUsedUp() {
return current > end;
}
}
}5.3 Leaf vs 原生雪花算法对比
| 特性 | 原生雪花算法 | 美团Leaf(雪花模式) |
|---|---|---|
| 时钟回拨解决 | 需自行实现 | ZK协调,自动处理 |
| 机器ID分配 | 手动配置 | ZK自动分配,避免冲突 |
| 高可用 | 单节点 | 集群部署,ZK协调 |
| 运维成本 | 低 | 高(需部署ZK) |
六、百度UidGenerator
6.1 核心特点
百度的UidGenerator对雪花算法做了两个重要改进:
- 时间戳以秒为单位:减少序列号位数,增加节点数;
- 使用数据库分配机器ID:避免手动配置冲突。
特点:
- RingBuffer预分配:预先生成未来一段时间的ID,放入环形缓冲区;
- 容忍时钟回拨:通过RingBuffer的滑动窗口,允许一定范围的时钟回拨;
- 高性能:单机QPS可达600万+。
RingBuffer结构:
- 每个Slot存储一个时间戳对应的ID范围;
- 时钟回拨时,从RingBuffer中查找对应时间戳的Slot,继续分配ID。
java
/**
* 百度UidGenerator结构(以秒为单位)
*
* 1位符号位 + 28位时间戳(秒) + 22位机器ID + 13位序列号
*
* - 28位时间戳:可支撑 2^28秒 ≈ 8.5年
* - 22位机器ID:支持 2^22 ≈ 419万个节点
* - 13位序列号:每秒 2^13 = 8192个ID
*/
public class BaiduUidGenerator {
// 时间戳占28位(秒级)
private static final long TIMESTAMP_BITS = 28;
// 机器ID占22位
private static final long WORKER_ID_BITS = 22;
// 序列号占13位
private static final long SEQUENCE_BITS = 13;
// 起始时间(2016-05-20)
private static final long START_EPOCH = 1463673600000L / 1000; // 秒级
}适用场景:微服务节点数超过1024的大型分布式系统。
七、面试高频真题(标准答案直接背)

7.1 基础必答
Q1:雪花算法生成的ID由哪几部分组成?每部分的作用是什么?
答案:
- 1位符号位:固定为0,保证ID为正整数;
- 41位时间戳:记录当前时间与起始时间的差值(毫秒),保证ID趋势递增,可支撑69年;
- 10位机器ID:支持1024个节点,避免不同机器生成重复ID;
- 12位序列号:同一毫秒内可生成4096个ID,解决并发冲突。
Q2:雪花算法有什么缺点?
答案:
- 依赖机器时钟:时钟回拨会导致ID重复或异常;
- 机器ID需手动配置:分布式环境下容易冲突;
- 趋势递增而非严格递增:同一毫秒内ID顺序可能被打乱。
Q3:什么是时钟回拨?如何解决?
答案:
- 定义:系统时间被调回(如NTP同步、运维误操作、虚拟机快照恢复),导致生成的时间戳变小,可能生成重复ID;
- 解决方案 :
- 等待策略:轻微回拨(≤5ms)时等待时间追上;
- 扩展位预留:增加回拨版本号,版本号+1;
- ZooKeeper协调:记录每个节点生成的最大时间戳,发生回拨时以ZK为准。
7.2 深度追问
Q4:雪花算法每毫秒可以生成多少个ID?单节点最大QPS是多少?
答案:
- 12位序列号 → 每毫秒最多
2^12 = 4096个ID; - 单节点最大QPS =
4096 × 1000 = 4,096,000(约400万); - 理论上是足够的,实际生产环境中单节点QPS很少超过10万。
Q5:机器ID不够用怎么办?
答案:
- 方案一:压缩时间戳位数,增加机器ID位数(如百度UidGenerator,时间戳28位,机器ID22位,支持419万个节点);
- 方案二:使用数据库或ZooKeeper动态分配机器ID,支持更多节点;
- 方案三:引入数据中心ID(5位+5位=10位),支持1024个节点,通常足够。
Q6:美团Leaf号段模式的核心思想是什么?
答案:
- 核心思想:一次从数据库获取一个号段(如1000个ID),存在本地内存中,用完再取;
- 优势 :
- 减少数据库访问(1000个ID只需1次DB操作);
- 高可用(DB短时故障不影响本地号段);
- 严格递增;
- 缺点:DB故障且本地号段耗尽时,无法生成新ID。
Q7:如何保证雪花算法生成的ID不重复(多节点部署)?
答案:
- 核心保障:通过机器ID区分不同节点(支持1024个节点);
- 配置方式 :
- 手动配置:在配置文件中为每个节点分配唯一的workerId;
- ZK自动分配:节点启动时向ZooKeeper申请机器ID;
- 数据库分配:使用数据库记录已分配的机器ID;
- 兜底策略:启动时检查机器ID是否冲突,冲突则报错退出。
Q8:雪花算法的时间戳溢出怎么办?
答案:
- 41位时间戳可支撑69年(从起始时间算起);
- 解决方案:
- 修改起始时间,重新开始计算;
- 增加时间戳位数(需改变ID结构,不推荐);
- 系统升级到128位ID(如UUID但保持有序)。
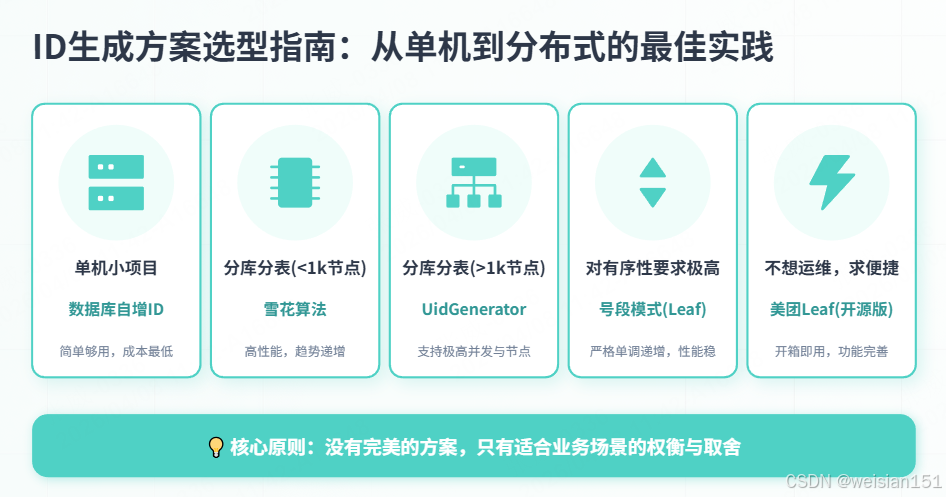
八、选型指南
| 方案 | 全局唯一 | 趋势递增 | 高可用 | 高性能 | 时钟依赖 | 适用场景 |
|---|---|---|---|---|---|---|
| UUID | ✅ | ❌ | ✅ | ✅ | ❌ | 临时ID、低并发 |
| 数据库自增 | ❌(分库后) | ✅ | ❌ | ❌ | ❌ | 单机系统 |
| Redis自增 | ✅ | ✅ | ⚠️(依赖Redis) | ✅ | ❌ | 计数场景 |
| Snowflake | ✅ | ✅ | ✅ | ✅ | ✅ | 高并发有序ID |
| Leaf-Segment | ✅ | ✅(大致) | ✅ | ✅ | ❌ | 极致高可用 |
| UidGenerator | ✅ | ✅ | ✅ | ✅✅ | ⚠️(容忍回拨) | 超高并发 |
8.1 选型原则
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 单机小项目 | 数据库自增ID | 简单够用 |
| 分库分表(<1024节点) | 雪花算法 | 性能高,有序 |
| 分库分表(>1024节点) | 百度UidGenerator | 支持更多节点 |
| 对有序性要求极高 | 号段模式(Leaf) | 严格递增 |
| 不想运维 | 美团Leaf(开源) | 开箱即用 |
| 云原生环境 | 数据库号段模式 | 部署简单 |
- 优先Leaf-Segment:如果团队有能力维护数据库,这是最稳妥的选择;
- 次选Snowflake:如果追求极致性能且能处理时钟问题;
- 避免UUID:除非业务对性能完全不敏感;
- 禁用单机自增:分库分表场景下绝对不要用。
8.2 运维最佳实践
- NTP配置 :所有服务器必须配置NTP,并设置
maxpoll和minpoll限制同步频率; - 禁用人工改时:通过运维规范禁止手动修改系统时间;
- 监控告警:部署时钟偏差、ID生成延迟、ID重复等监控项;
- 机器ID管理:建立机器ID分配和回收流程,避免冲突。
总结
1. 核心知识点速记口诀
分布式ID要唯一,趋势递增不能乱,
UUID无序性能差,数据库自增产瓶颈。
雪花算法64位,时间戳加机器ID,
41年毫秒存,69年放心用,
10位机器一千个,12序列四千九。
时钟回拨是隐患,等待报错扩展位,
美团Leaf两模式,ZK协调更可靠。2. 核心要点回顾
- 分布式ID:分库分表必备,核心要求全局唯一、趋势递增;
- 雪花算法:64位Long型ID,41位时间戳 + 10位机器ID + 12位序列号;本地生成、高性能、无依赖,唯一缺陷时钟回拨;
- 时钟回拨:NTP同步导致的时间倒退,可通过等待、版本号、ZK解决;
- 生产最佳实践:美团Leaf(号段+雪花)、百度UidGenerator;
- 禁忌:UUID绝不做主键,原生雪花绝不直接上生产。
3. 实战选型建议
- 中小型项目:雪花算法+等待回拨方案;
- 中大型项目:直接接入美团Leaf;
- 核心金融/支付:百度UidGenerator+强时钟校验;
- 分库分表:必须用分布式ID,禁止数据库自增。
写在最后
从数据库自增ID到雪花算法,再到美团Leaf,分布式ID生成器的演进始终围绕"唯一性、有序性、高可用、高性能"四个核心诉求。
雪花算法以其简洁的64位结构和极高的性能,成为分布式ID生成的事实标准。但时钟回拨这个"阿喀琉斯之踵"需要每个架构师认真对待------在面试中,能完整讲清楚时钟回拨的三种解决方案,是区分普通开发者和架构师的分水岭。
记住:没有完美的方案,只有适合场景的权衡。雪花算法虽好,但如果你只有10个节点且对有序性要求极高,号段模式可能是更好的选择。
如果觉得有帮助,欢迎点赞、收藏、转发!