文章目录
- MLIR简介
- Toy接入MLIR
-
-
- MLIR表达式如何生成
- [MLIR 表达式(类似LLVM IR可读形式)](#MLIR 表达式(类似LLVM IR可读形式))
- MLIR之Dialect简介
- 如何把非MLIR系统接入MLIR系统
- MLIR主要组成部分
- Dialect创建之ODS框架
-
- Dialect以及Operation详解
- 表达式变形
- Lowering过程
-
- [Lowering过程(Dialect Conversion)](#Lowering过程(Dialect Conversion))
- 参考
MLIR简介
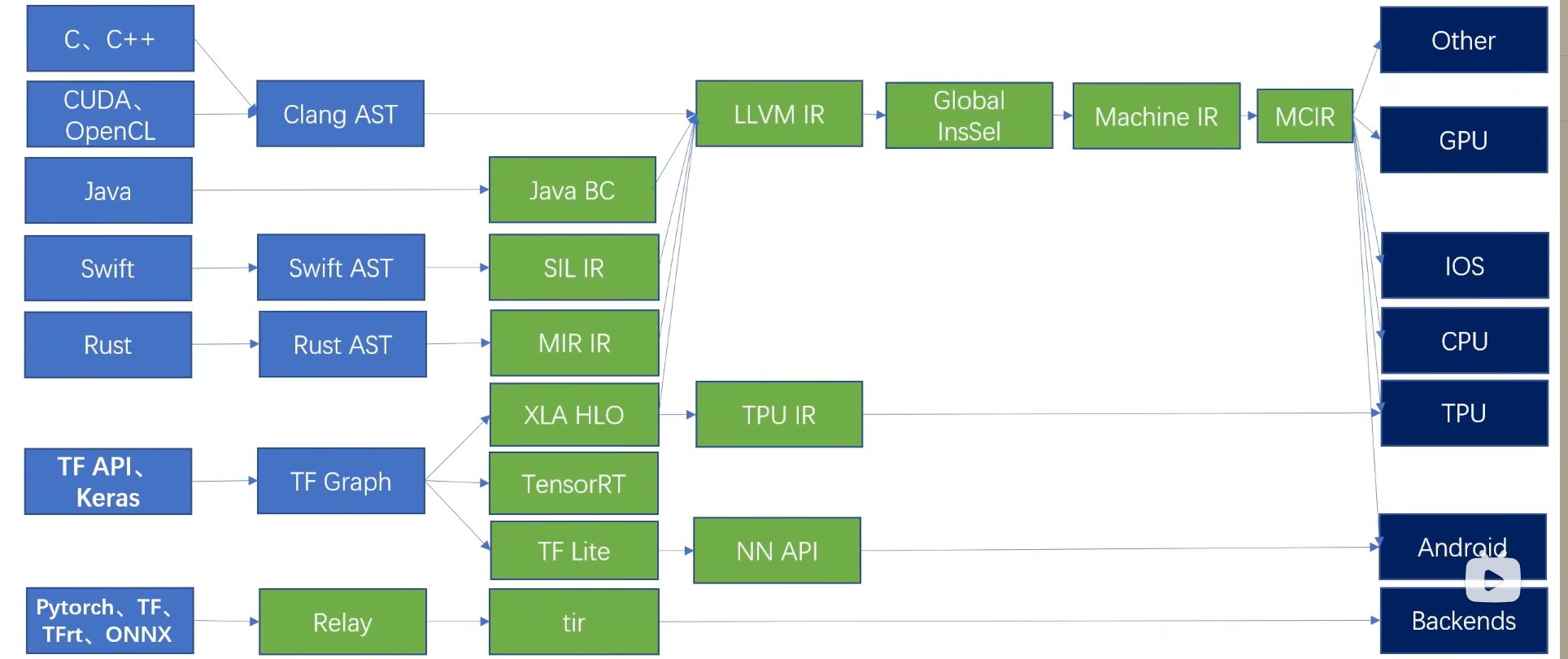
常见的IR表示系统
Clang 对 AST 进行静态分析和转换操作,各个语言的 AST 都需要进行类似的静态分析和转换操作。
当前 IR 存在的问题
- IR 种类太多:针对不同种类 IR 开发的 Pass 可能重复,即不同 IR 的同类 Pass 不兼容;针对新的 IR 编写同类 Pass 需要重新学习 IR 语法,门槛过高。
- 优化不可见:不同类型 IR 所做的 Pass 优化在下一层中不可见。
- 转换开销大:不同类型 IR 间转换开销大,从图 IR 到 LLVM IR 直接转换存在较大开销。
常见的IR种类
Graph IR:DAG,CFG
线性IR:三地址IR
图线性混合IR:LLVM IR
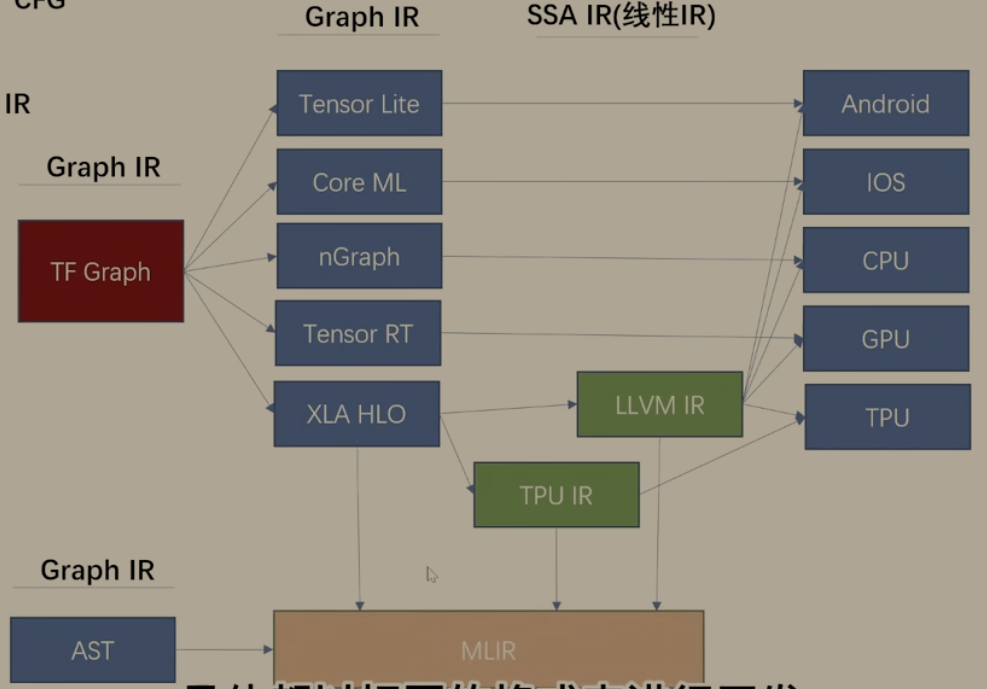
使用Dialect构建的IR表示系统
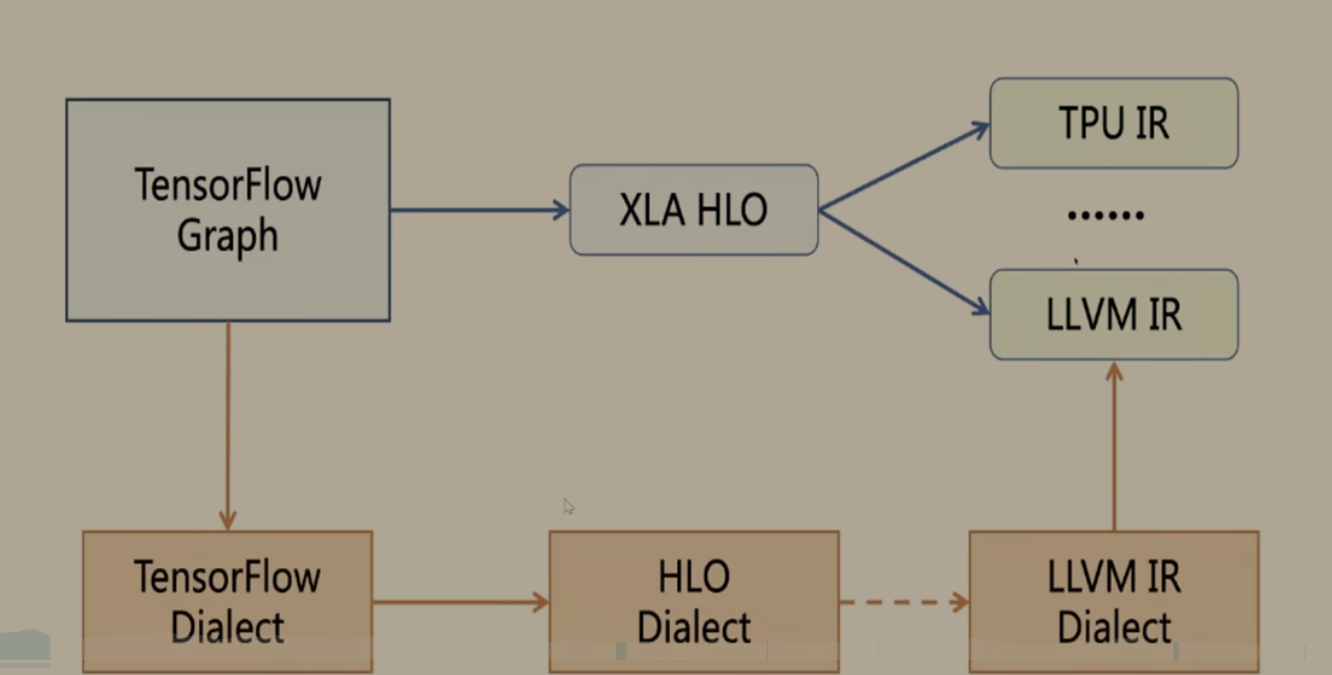
传统 XLA 编译流程
- TensorFlow Graph:TensorFlow 原始的计算图表示,是模型的高层抽象。
- XLA HLO:将 TensorFlow Graph lowered 为 XLA 的高层中间表示(High-Level Optimizer),这是 XLA 编译器的核心 IR。
- 目标 IR 分发:XLA HLO 会被进一步转换为不同硬件 / 后端的专用 IR:
TPU IR:针对谷歌 TPU 芯片的专用 IR
LLVM IR:针对 CPU/GPU 等通用硬件,最终由 LLVM 编译为机器码
还有其他硬件对应的 IR(图中用 ...... 表示)
基于 MLIR Dialect 的新编译流程
MLIR(Multi-Level Intermediate Representation)通过 Dialect(方言) 机制统一了不同层级的 IR:
TensorFlow Dialect:直接在 MLIR 框架内表示 TensorFlow 计算图,保留了 TF 的语义。
HLO Dialect:将 TensorFlow Dialect 转换为 MLIR 版的 HLO 表示,等价于 XLA HLO,但复用 MLIR 基础设施。
LLVM IR Dialect:HLO Dialect 再转换为 MLIR 版的 LLVM IR,最终可以无缝对接 LLVM 后端生成机器码。
Toy语言接入MLIR
MLIR 官方教程中的 Toy 语言------ 一种为演示 MLIR 完整编译流程而设计的极简张量语言
Toy 语言核心特性
-
混合计算与 I/O:支持标量、数组(张量)计算,同时包含 print 这类 I/O 操作。
-
数组形状推导:内置数组形状推断能力,可自动推导张量维度。
-
泛型函数:支持类似 C++ 模板的泛型函数,参数类型可自动推导。
-
功能极简:仅提供少量运算符和内置函数,核心目的是演示 MLIR 流程,而非实用开发。
def foo(a, b, c) {
var c = a + b;
print(transpose(c));
var d<2, 4> = c * foo(c);
return d;
}def foo(a, b, c):定义泛型函数,等价于 C++ 模板 template<typename A, typename B, typename C> auto foo(A a, B b, C c)。
var c = a + b:基于值语义 / SSA 形式的变量声明,变量不可变。
print(transpose(c)):调用内置函数 transpose(张量转置)和 print(输出),体现有限的内置函数集。
var d<2, 4> = c * foo(c):显式声明数组形状 <2,4>,实现张量重塑;同时展示函数递归调用。
return d:返回结果。
Toy语言的词法分析器Lexer参考:Kaleidoscope: Kaleidoscope Introduction and the Lexer,语法分析器Parser参考:Kaleidoscope: Implementing a Parser and AST
Toy接入MLIR
MLIR Toy 语言 从源码 → AST → MLIR 代码生成的完整流程
Toy 源码
-
定义了一个函数 multiply_transpose,接收两个参数 a 和 b。
-
函数逻辑:分别对 a 和 b 做转置(transpose),然后将结果相乘并返回。
def multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}AST 结构
Module:顶层模块,包含所有函数定义。
Function:函数节点,包含原型(Proto)、参数列表(Params)和函数体(Block)。
Block:函数体块,包含返回语句(Return)。
BinOp:二元乘法操作,连接两个 transpose 调用。
Call:内置函数调用节点,分别对应 transpose(a) 和 transpose(b),并记录了源码位置信息(如 @test/Examples/Toy/Ch1/ast.toy:5:10)。
MLIR 代码生成逻辑(mlirGen 函数)
-
将 CallExprAST(函数调用 AST 节点)转换为 MLIR 操作的核心代码
mlir::Value mlirGen(CallExprAST &call) {
llvm::StringRef callee = call.getCallee();
auto location = loc(call.loc());// 先生成操作数的 MLIR Value SmallVector<mlir::Value, 4> operands; for (auto &expr : call.getArgs()) { auto arg = mlirGen(*expr); if (!arg) return nullptr; operands.push_back(arg); } // 处理内置函数 `transpose` if (callee == "transpose") { if (call.getArgs().size() != 1) { emitError(location, "MLIR codegen encountered an error: toy.transpose \"does not accept multiple arguments\""); return nullptr; } // 生成 MLIR 的 TransposeOp return builder.create<TransposeOp>(location, operands[0]); } // 处理用户自定义函数调用 return builder.create<GenericCallOp>(location, callee, operands);}
操作数生成:递归生成函数参数的 MLIR Value,作为后续操作的输入。
内置函数特殊处理:识别 transpose 内置函数,检查参数数量后,直接生成 MLIR 原生的 TransposeOp。
自定义函数处理:其他函数调用统一生成 GenericCallOp,将函数名作为属性传递。
MLIR 中 TransposeOp 操作的 build 方法实现,作用是在 MLIR 中构建一个转置操作。
void TransposeOp::build(mlir::OpBuilder &builder, mlir::OperationState &state,
mlir::Value value) {
state.addTypes(UnrankedTensorType::get(builder.getF64Type()));
state.addOperands(value);
}
mlir::OpBuilder &builder:MLIR 操作构建器,用于创建类型、操作等基础设施。
mlir::OperationState &state:待构建操作的状态对象,用来收集操作的结果类型、操作数、属性、位置等信息。
mlir::Value value:输入操作数,即要被转置的张量。
state.addTypes(...):为操作添加结果类型。这里指定输出是一个未排名张量(UnrankedTensorType),元素类型为 64 位浮点数(F64Type)。
state.addOperands(value):将输入的 value 作为该操作的唯一操作数(即被转置的张量)MLIR表达式如何生成

编译流程总览
- Toy 源程序:用户编写的 Toy 语言代码(如示例中的 multiply_transpose 函数)。
- Toy AST:语法分析后生成的抽象语法树,保留了代码的结构和语义。
- Toy IR MLIR 表达式:通过 Toy Dialect 遍历 AST,将每个节点映射为 MLIR 中的 Operation(操作),生成高层 MLIR 表示。
- Lowered MLIR 表达式:对高层 Toy IR 进行逐步 lowering(降级),转换为更底层、更通用的 MLIR Dialect。
- LLVM IR:进一步 lowering 为 LLVM 中间表示,对接 LLVM 后端。
- 目标程序:由 LLVM 编译生成可在目标硬件上运行的机器码。
Toy 源码
def multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}生成的 MLIR IR(Toy Dialect)
func @multiply_transpose(%arg0: tensor<*xf64>, %arg1: tensor<*xf64>)
-> tensor<*xf64> {
%0 = "toy.transpose"(%arg0) : (tensor<*xf64>) -> tensor<*xf64>
%1 = "toy.transpose"(%arg1) : (tensor<*xf64>) -> tensor<*xf64>
%2 = "toy.mul"(%0, %1) : (tensor<*xf64>, tensor<*xf64>) -> tensor<*xf64>
"toy.return"(%2) : (tensor<*xf64>) -> ()
}
函数定义:func @multiply_transpose 对应 Toy 函数,参数 %arg0/%arg1 是未排名 64 位浮点张量(tensor<*xf64>)。
转置操作:toy.transpose 操作对应源码中的 transpose(a)/transpose(b),输入是张量,输出是同类型张量。
乘法操作:toy.mul 操作对应源码中的 *,接收两个转置结果张量,输出乘积张量。
返回操作:toy.return 操作将最终结果返回,对应 return 语句MLIR 表达式(类似LLVM IR可读形式)
核心设计理念:Operations, Not Instructions
- 无预定义指令集:MLIR 没有像 LLVM IR 那样固定的指令集合,所有操作都由 Dialect 定义,高度可扩展。
- 操作是 "不透明函数":对 MLIR 核心框架而言,每个 Operation 就像一个黑盒函数,只需要知道它的输入、输出和属性,具体语义由 Dialect 实现。

%res:2 = "mydialect.morph"(%input#3) {some.attribute = true, other_attribute = 1.5} : (!mydialect<"custom_type">) -> (!mydialect<"other_type">, !mydialect<"other_type">) loc(callsite("foo" at "mysource.cc":10:8))| 部分 | 含义 |
|---|---|
%res:2 |
SSA 结果名,%res 是变量名,:2 表示该操作返回 2 个结果值 |
"mydialect.morph" |
操作全名:mydialect 是 Dialect 前缀,morph 是操作 ID(Op Id) |
(%input#3) |
输入参数,%input#3 是另一个操作的结果,#3 表示该结果在生产者操作的返回值中索引为 3 |
{some.attribute = true, ...} |
属性列表:键值对形式的常量参数,用于存储编译期常量信息 |
(!mydialect<"custom_type">) |
输入类型:! 表示自定义类型,mydialect 是类型所属 Dialect,"custom_type" 是类型名 |
-> (!mydialect<"other_type">, ...) |
输出类型列表:示例中返回 2 个同类型的自定义张量 |
loc(...) |
位置信息:记录该操作对应的源码位置(文件、函数、行号),用于调试和错误报告 |
MLIR之Dialect简介
MLIR Dialect(方言) 的核心组成部分,Dialect 是 MLIR 实现可扩展性的核心机制,用来封装特定领域的语法、类型和操作。
Dialect 的核心组成
-
前缀(Prefix)
相当于命名空间,用来隔离不同 Dialect 的操作和类型,避免命名冲突。比如 toy.、llvm.、linalg. 都是典型的 Dialect 前缀。
-
自定义类型列表
每个类型都对应一个 C++ 类,用来描述领域特有的数据类型。比如 Toy 语言的 tensor<*xf64>、LLVM 的指针类型,都由各自 Dialect 定义。
-
操作列表(核心部分)
每个操作都有唯一名称和对应的 C++ 实现,包含:
验证器(Verifier):检查操作的不变量是否合法,比如 toy.print 必须只有一个操作数,toy.transpose 参数数量必须为 1。
语义信息(Semantics):描述操作的行为特性,比如是否无副作用、是否支持常量折叠、是否允许公共子表达式消除(CSE)等,这些信息会被 MLIR 优化器利用。
-
自定义解析器与汇编打印机(可选)
用于实现该 Dialect 特有的文本语法解析和打印,让 MLIR 文件更易读、更贴近领域语言习惯。
-
Passes(分析、转换与方言转换)
封装针对该 Dialect 的分析逻辑(如形状推断)、变换优化(如算子融合),以及与其他 Dialect 的转换规则(如 Toy IR → Linalg IR → LLVM IR)
Dialect 是 MLIR 的模块化扩展单元:
- 它把领域特定的类型、操作、优化逻辑打包在一起,让 MLIR 可以同时支持多层级抽象(从高层张量计算到底层机器码)。
- 不同 Dialect 之间可以通过转换 Pass 互相 lowering,实现渐进式编译,避免了传统多 IR 架构的碎片化问题。
- 这种设计让 MLIR 成为了一个通用编译基础设施,既可以用于深度学习框架,也可以用于传统编程语言、硬件设计等领域。
如何把非MLIR系统接入MLIR系统
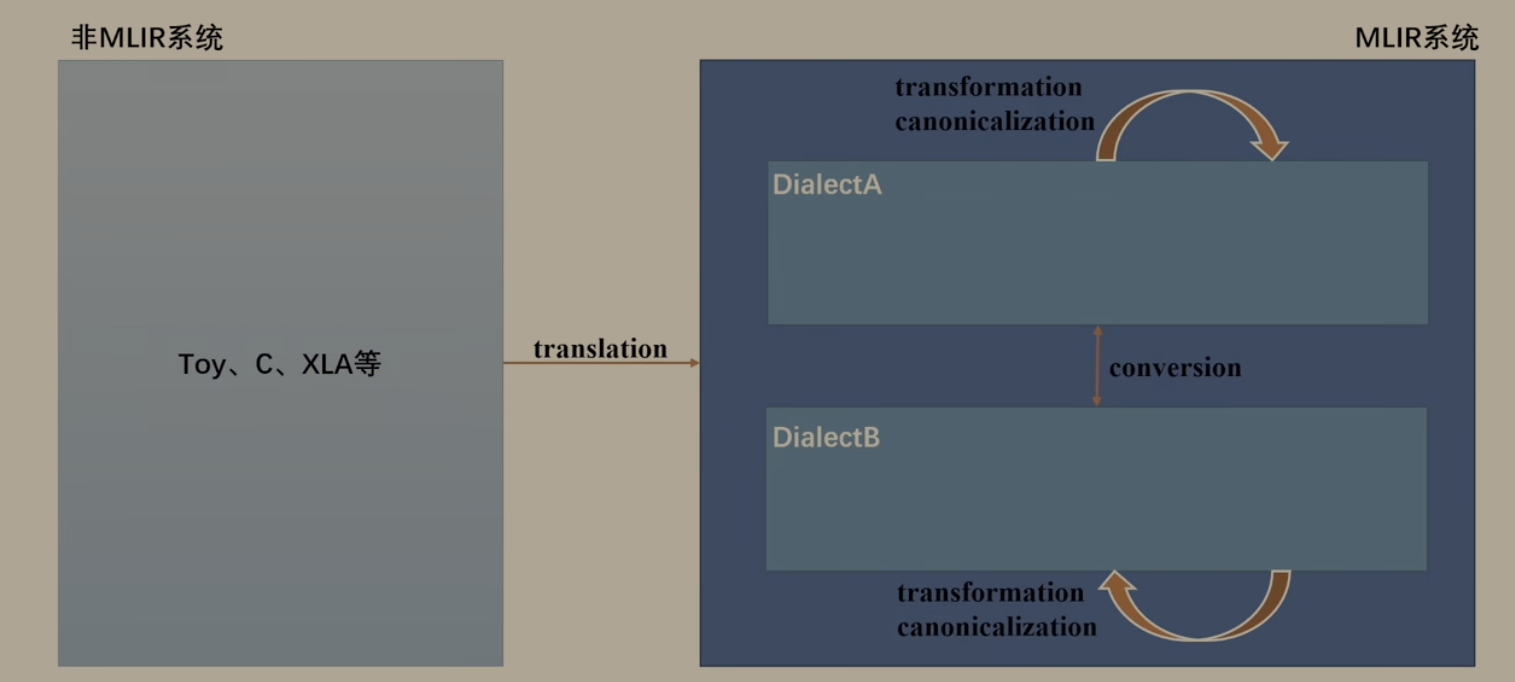
MLIR 体系中 Translation、Conversion、Transformation 三个核心概念
Translation(翻译)
作用:非 MLIR 系统 ↔ MLIR 系统 之间的转换
场景示例:
Toy 语言源码 → Toy Dialect MLIR
C 语言 → LLVM Dialect MLIR
XLA HLO → MHLO Dialect MLIR
本质:把外部语言 / IR 翻译成 MLIR 能理解的 Dialect 形式,是 "进入 MLIR 世界" 的入口
Conversion(转换)
作用:MLIR 内部不同 Dialect 之间 的等价转换
场景示例:
Toy Dialect → Linalg Dialect
Linalg Dialect → SCF Dialect
SCF Dialect → LLVM Dialect
本质:在保留语义的前提下,从高层 Dialect 逐步 lowering 到更底层、更接近硬件的 Dialect,是 MLIR 渐进式编译的核心
Transformation(变换)
作用:同一 Dialect 内部 的优化与规范化
典型操作:
Canonicalization(规范化):消除冗余、统一表达形式
常量折叠、公共子表达式消除(CSE)、算子融合等
本质:不改变 Dialect 层级,只优化当前 Dialect 内的操作序列,提升代码质量或为后续 lowering 做准备。
| 概念 | 作用范围 | 核心目标 | 典型例子 |
|---|---|---|---|
| Translation | 非 MLIR ↔ MLIR | 导入 / 导出外部表示 | Toy 源码 → Toy Dialect |
| Conversion | MLIR Dialect 之间 | 跨 Dialect 语义等价转换 | Toy → Linalg → LLVM |
| Transformation | 同一 Dialect 内部 | 优化 / 规范化 | 常量折叠、算子融合 |
MLIR主要组成部分

MLIR 的核心构件与 Dialect 间的交互关系,清晰呈现了从操作定义到方言转换的完整技术
Dialect 内部核心构件
每个 Dialect(如 DialectA、DialectB)都包含以下核心元素
- Operation(操作):方言语义的基本单元,是 Dialect 最重要的组成部分,对应具体的计算 / 控制流行为(如 toy.transpose、toy.mul)
- Operation 子构件:
Attribute:编译期常量参数(如算子的固定参数、形状信息)。
Type:自定义数据类型(如 Toy 的张量类型 tensor<*xf64>)。
Constraint:操作 / 类型的合法性约束(如 toy.transpose 只能有一个操作数)。
Interface:操作的通用接口(如可序列化、可形状推断的接口)。
Trait:操作的语义标记(如 NoSideEffect、Commutative,用于优化器决策
Dialect 级构件:
- Interface:Dialect 层面的通用能力接口。
Attribute:Dialect 全局的自定义属性。 - Type:Dialect 全局的自定义类型。
Dialect 间的转换机制
- DialectConversion 是跨 Dialect 转换的核心组件,配套工具包括:
TypeConverter:负责类型在不同 Dialect 间的等价转换(如 Toy 张量 → Linalg 张量)。
ConversionTarget:定义转换目标 Dialect 的约束(如只允许目标 Dialect 的操作)。
ConversionPattern:具体的转换规则(如 toy.transpose → linalg.transpose)
优化与规范化
Transformation:同一 Dialect 内的优化变换(如算子融合、死代码消除)。
Canonicalization:规范化变换,统一操作表达形式、消除冗余(如 a + 0 → a),是后续优化和转换的基础。
定义与重写工具
ODS (Operation Definition Specification):用于声明式定义 Operation、Type、Attribute,避免手写大量重复 C++ 代码(写td文件,利用tablegen生成C++代码)。
DRR (Declarative Rewrite Rule):用于声明式定义转换模式,简化 Dialect 间的转换规则编写。
Dialect创建之ODS框架
如何用 C++ 声明一个自定义 Dialect 的核心结构:
/// This is the definition of the Toy dialect. A dialect inherits from
/// mlir::Dialect and registers custom attributes, operations, and types. It can
/// also override virtual methods to change some general behavior, which will be
/// demonstrated in later chapters of the tutorial.
class ToyDialect : public mlir::Dialect {
public:
explicit ToyDialect(mlir::MLIRContext *ctx);
/// Provide a utility accessor to the dialect namespace.
static llvm::StringRef getDialectNamespace() { return "toy"; }
/// An initializer called from the constructor of ToyDialect that is used to
/// register attributes, operations, types, and more within the Toy dialect.
void initialize();
};
继承关系:ToyDialect 继承自 mlir::Dialect,这是所有 MLIR 自定义 Dialect 的基类。
构造函数:explicit ToyDialect(mlir::MLIRContext *ctx) ------ 接收 MLIRContext(MLIR 的全局上下文,管理类型、操作、Dialect 等),完成 Dialect 的初始化。
命名空间:static llvm::StringRef getDialectNamespace() { return "toy"; } ------ 定义 Dialect 的命名空间为 toy,所有该 Dialect 的操作都会以 toy. 为前缀(如 toy.transpose),避免命名冲突。
初始化方法:void initialize() ------ 构造函数中会调用此方法,用于注册该 Dialect 包含的自定义属性、操作、类型等,是 Dialect 功能的核心加载入口。ODS 框架与 Dialect 关系
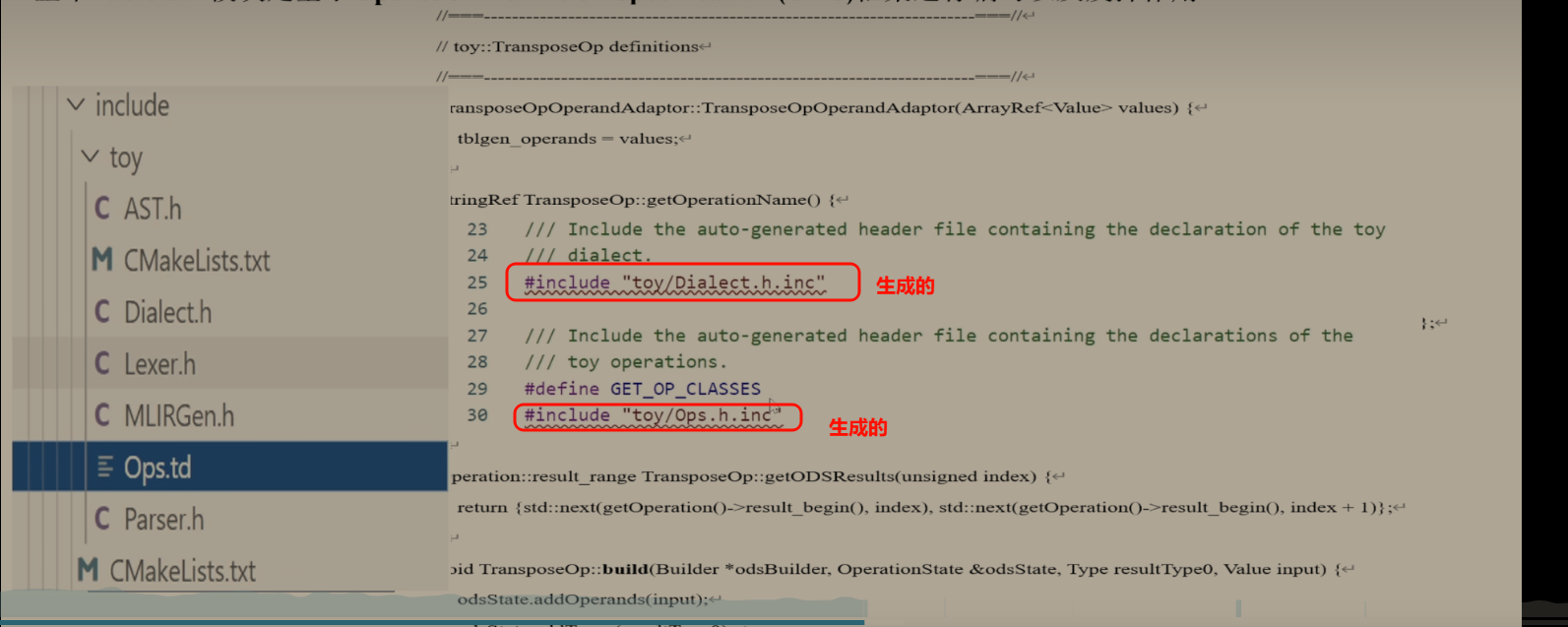
ODS(Operation Definition Specification) 是 MLIR 提供的声明式定义工具,用来简化 Dialect 中 Operation、Type、Attribute 的定义,避免手写大量重复的 C++ 模板代码。
这段代码是 Toy Dialect 的 C++ 骨架,后续会通过 ODS 生成具体的 Operation 实现(如 TransposeOp、MulOp),并在 initialize() 方法中注册到 MLIR 系统
在ToyDialect中创建一些operation(手写C++)
class ConstantOp : public mlir::Op<
ConstantOp,
mlir::OpTrait::ZeroOperands,
mlir::OpTrait::OneResult,
mlir::OpTraits::OneTypedResult<TensorType>::Impl> {
public:
using Op::Op;
static llvm::StringRef getOperationName() { return "toy.constant"; }
mlir::DenseElementsAttr getValue();
LogicalResult verifyInvariants();
static void build(mlir::OpBuilder &builder,
mlir::OperationState &state,
mlir::Type result, mlir::DenseElementsAttr value);
static void build(mlir::OpBuilder &builder,
mlir::OperationState &state,
mlir::DenseElementsAttr value);
static void build(mlir::OpBuilder &builder,
mlir::OperationState &state,
double value);
};
继承 mlir::Op<ConstantOp, ...>:这是 MLIR 自定义操作的基类模板,第一个模板参数是自身类型(CRTP 模式)。
ZeroOperands Trait:标记该操作没有输入操作数(常量是直接由属性提供值)。
OneResult Trait:标记该操作只返回一个结果值。
OneTypedResult<TensorType>::Impl Trait:进一步约束返回值必须是 TensorType 类型,保证 Toy 常量是张量常量核心方法解析
- using Op::Op:继承基类的构造函数,支持直接从 MLIR Operation* 构建 ConstantOp 实例。
- getOperationName():返回操作的全名 toy.constant,对应 MLIR IR 中的写法(Dialect 前缀 + 操作名)。
- getValue():获取常量的存储数据,返回 DenseElementsAttr(MLIR 中存储稠密张量数据的属性类型)。
- verifyInvariants():验证操作的合法性,比如检查常量值是否有效、类型是否匹配等。
- 重载 build(...) 方法:提供多种便捷构造方式,用于在代码生成时创建 ConstantOp:
显式指定结果类型 + 稠密张量属性
自动推导结果类型(从属性中提取)+ 稠密张量属性
直接传入 double 标量(内部会自动封装为 0 维张量属性)
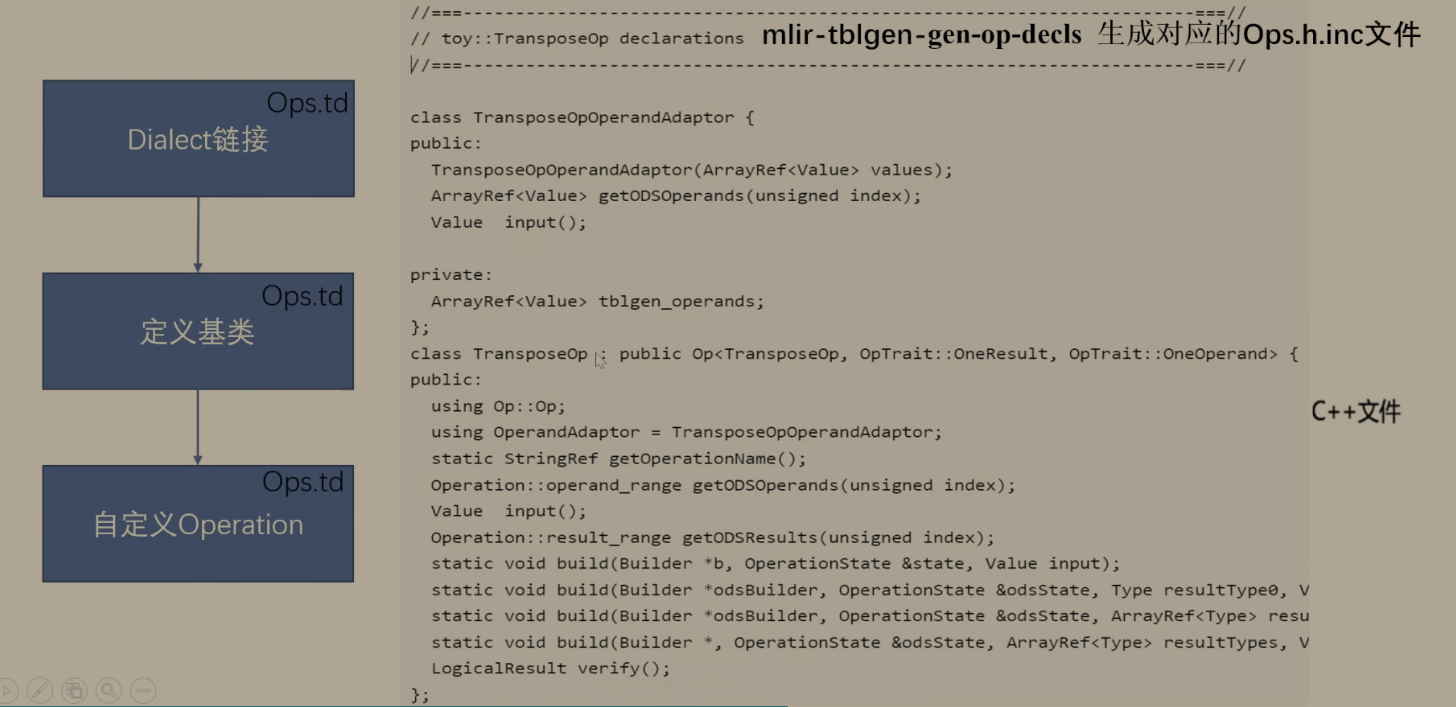
使用TableGen去创建Dialect以及operation(手写td)
MLIR ODS(Operation Definition Specification)框架下,Toy Dialect 的声明式定义与自动生成的 C++ 代码,体现了 "声明式定义 + 代码生成" 的核心工作流。
Dialect以及Operation详解
TableGen 声明式定义(.td 文件)
-
这是用 MLIR TableGen 语法编写的 Dialect 定义,是开发者直接维护的源码:
def Toy_Dialect : Dialect {
let summary = "Toy IR Dialect";
let description = [{
This is a much longer description of the Toy dialect.
...
}];// The namespace of our dialect. let name = "toy"; // The C++ namespace that the dialect class definition resides in. let cppNamespace = "toy";}
Toy_Dialect:定义一个名为 Toy_Dialect 的 Dialect。
summary / description:提供 Dialect 的摘要和详细描述,用于文档生成。
name = "toy":指定 Dialect 的命名空间为 toy,所有操作都会以 toy. 为前缀(如 toy.constant)。
cppNamespace = "toy":指定生成的 C++ 类所在的命名空间为 toy
自动生成的 C++ 类
ODS 框架会根据上面的 TableGen 定义,自动生成对应的 C++ 类
class ToyDialect : public mlir::Dialect {
public:
ToyDialect(mlir::MLIRContext *context)
: mlir::Dialect("toy", context,
mlir::TypeID::get<ToyDialect>()) {
initialize();
}
static llvm::StringRef getDialectNamespace() {
return "toy";
}
void initialize();
};继承 mlir::Dialect:所有自定义 Dialect 都必须继承这个基类。
构造函数:
- 调用基类构造函数,传入 Dialect 名 "toy"、MLIRContext 和唯一的 TypeID。
- 在构造函数中调用 initialize(),用于注册该 Dialect 包含的操作、类型、属性等。
getDialectNamespace():静态方法,返回 Dialect 的命名空间 "toy",与 TableGen 中的 name 对应。
initialize():纯虚方法,需要开发者手动实现,完成 Dialect 组件的注册。
TableGen 声明operation解析
def ConstantOp : Toy_Op<"constant", [NoSideEffect]> {
// 1. 元信息:摘要+文档
let summary = "constant";
let description = [{
常量操作:将字面量转为 SSA 值,数据存储在属性中
示例:%0 = toy.constant dense<[[1.0,2.0]]> : tensor<2x1xf64>
}];
// 2. 输入输出定义
let arguments = (ins F64ElementsAttr:$value); // 输入:64位浮点张量属性
let results = (outs F64Tensor); // 输出:64位浮点张量
// 3. 语法优化:自定义汇编格式
let hasCustomAssemblyFormat = 1;
// 4. 便捷构造器(重载)
let builders = [
// 构造器1:接收稠密张量属性,自动推导类型
OpBuilder<(ins "DenseElementsAttr":$value), [{
build($_builder, $_state, value.getType(), value);
}]>,
// 构造器2:接收double标量,自动封装为0维张量
OpBuilder<(ins "double":$value)>
];
}- NoSideEffect:标记操作无副作用(优化器可安全重排 / 删除)。
- 无输入操作数:常量数据存储在 Attribute 中(而非 SSA 输入),符合 MLIR 常量设计规范
自动生成的 C++ 类解析
class ConstantOp : public mlir::Op<
ConstantOp,
mlir::OpTrait::ZeroOperands, // 自动继承:无输入操作数
mlir::OpTrait::OneResult, // 自动继承:单输出
mlir::OpTraits::OneTypedResult<TensorType>::Impl> { // 输出必须是张量
public:
using Op::Op; // 继承基类构造器
// 1. 操作名:固定为 "toy.constant"(与TableGen对应)
static llvm::StringRef getOperationName() { return "toy.constant"; }
// 2. 核心方法(自动生成骨架)
mlir::DenseElementsAttr getValue(); // 获取常量属性值
LogicalResult verifyInvariants(); // 验证操作合法性
// 3. 重载build方法(对应TableGen的builders)
static void build(..., mlir::DenseElementsAttr value); // 张量构造
static void build(..., double value); // 标量构造
};自动映射规则:
- TableGen 中的 arguments/results → 生成 Trait 约束(ZeroOperands/OneResult)。
- TableGen 中的 builders → 生成对应重载的 build 方法。
- TableGen 中的 NoSideEffect → 自动关联 MLIR 内置 Trait。
TableGen是基于ODS框架进行编写来发挥作用的



表达式变形
MLIR表达式变形(canonicalization规范化优化)
核心是通过模式匹配消除冗余操作,以 transpose(transpose(x)) 为例。
Toy 源码
def transpose_transpose(x) {
return transpose(transpose(x));
}变形前 MLIR 表达式
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = "toy.transpose"(%arg0) : (tensor<*xf64>) -> tensor<*xf64>
%1 = "toy.transpose"(%0) : (tensor<*xf64>) -> tensor<*xf64>
"toy.return"(%1) : (tensor<*xf64>) -> ()
}问题:连续两次转置 transpose(transpose(x)) 等价于原张量 x,存在冗余操作。
优化目标:将 %1 = toy.transpose(%0) 直接替换为 %arg0,消除两次连续转置。
手动模式匹配与重写代码
mlir::PatternMatchResult matchAndRewrite(TransposeOp op, mlir::PatternRewriter &rewriter) const override {
// 1. 获取当前 transpose 操作的输入操作数
mlir::Value transposeInput = op.getOperand();
TransposeOp transposeInputOp = llvm::dyn_cast_or_null<TransposeOp>(transposeInput.getDefiningOp());
// 2. 检查输入是否由另一个 transpose 操作定义
if (!transposeInputOp)
return matchFailure(); // 不匹配,不优化
// 3. 匹配成功:用内层 transpose 的输入替换当前操作
rewriter.replaceOp(op, {transposeInputOp.getOperand()});
return matchSuccess();
}
getOperand():获取当前 transpose 的输入值。
getDefiningOp():获取生成该输入值的操作,尝试转为 TransposeOp。
matchFailure():若输入不是 transpose,则不优化。
replaceOp():若匹配成功,用内层 transpose 的输入(即原张量 x)替换当前 transpose 操作声明式 DRR(Declarative Rewrite Rule),并以 transpose(transpose(x)) 为例
Toy 源码
def transpose_transpose(x) {
return transpose(transpose(x));
}变形前 MLIR(存在冗余操作)
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = "toy.transpose"(%arg0) : (tensor<*xf64>) -> tensor<*xf64>
%1 = "toy.transpose"(%0) : (tensor<*xf64>) -> tensor<*xf64>
"toy.return"(%1) : (tensor<*xf64>) -> ()
}DRR 声明式重写规则
// Transpose(Transpose(x)) = x
def TransposeTransposeOptPattern : Pat<
(TransposeOp(TransposeOp $arg)),
(replaceWithValue $arg)>;语法直观:直接用模式 (TransposeOp(TransposeOp arg)) 描述要匹配的结构,用 (replaceWithValue arg) 描述替换逻辑。
自动生成:MLIR 会自动将此声明转换为和手动编码等价的 C++ 重写逻辑。
优势:可读性极强,开发效率高,无需处理底层细节
MLIR表达式变形之DDR框架
MLIR 中 DRR(Declarative Rewrite Rules)声明式重写规则 的应用,以消除冗余的 reshape 操作为例,完整呈现 "问题场景 → DRR 规则定义 → 优化效果" 的流程。
Toy 源码
def main() {
var a<2,1> = [1, 2];
var b<2,1> = a;
var c<2,1> = b;
print(c);
}变形前 MLIR 表达式(存在冗余 reshape)
module {
func @main() {
%0 = "toy.constant"() {value = dense<[1.0, 2.0]> : tensor<2xf64>} : () -> tensor<2xf64>
%1 = "toy.reshape"(%0) : (tensor<2xf64>) -> tensor<2x1xf64>
%2 = "toy.reshape"(%1) : (tensor<2x1xf64>) -> tensor<2x1xf64> // 冗余:形状未变
%3 = "toy.reshape"(%2) : (tensor<2x1xf64>) -> tensor<2x1xf64> // 冗余:形状未变
"toy.print"(%3) : (tensor<2x1xf64>) -> ()
"toy.return"() : () -> ()
}
}问题:多次 reshape 操作的输入和输出形状完全一致,属于无意义冗余操作。
优化目标:若 reshape 操作的输入和输出类型相同,直接用输入替换该 reshape,消除冗余
DRR 声明式重写规则
// 定义约束:检查两个值的类型是否完全一致
def TypesAreIdentical : Constraint<CPred<"$0.getType() == $1.getType()">>;
// 定义重写模式:匹配 reshape 操作,若类型一致则用输入替换
def RedundantReshapeOptPattern : Pat<
(ReshapeOp:$res $arg), // 匹配模式:ReshapeOp 操作,结果命名为 $res,输入为 $arg
(replaceWithValue $arg), // 重写逻辑:直接用输入 $arg 替换整个 ReshapeOp
[(TypesAreIdentical $res, $arg)] // 约束条件:结果 $res 和输入 $arg 的类型必须一致
>;Constraint<CPred<...>>:自定义约束 TypesAreIdentical,用于判断两个值的类型是否完全相同。
Pat<sourcePattern, resultPattern, constraints>:
- sourcePattern:要匹配的 IR 结构,这里是 ReshapeOp:res arg。
- resultPattern:匹配成功后的替换逻辑,这里直接用输入 $arg 替换整个 reshape 操作。
- constraints:附加约束,只有满足 TypesAreIdentical res, arg 时才触发重写。
优化后,所有形状不变的 reshape 操作都会被直接消除
module {
func @main() {
%0 = "toy.constant"() {value = dense<[1.0, 2.0]> : tensor<2xf64>} : () -> tensor<2xf64>
%1 = "toy.reshape"(%0) : (tensor<2xf64>) -> tensor<2x1xf64>
"toy.print"(%1) : (tensor<2x1xf64>) -> ()
"toy.return"() : () -> ()
}
}冗余的 %2、%3 两个 reshape 操作被完全移除,代码更简洁,语义保持不变。
Lowering过程
Lowering过程(Dialect Conversion)
Lowering 核心定义回顾
核心任务:将源 Dialect(如高层的 ToyDialect)转换为目标 Dialect(如更底层的 AffineOps、StandardOps)。
目标子集特性:目标 Dialect 可以是源 Dialect 的子集,即逐步剥离高层抽象,保留底层实现
三大核心组件:Conversion Target 详解
Conversion Target 是整个转换流程的 "法律法官",负责明确什么操作 / Dialect 是合法的,什么是非法的。
(1) 合法 Dialect 定义 (addLegalDialect)
target.addLegalDialect<mlir::AffineOpsDialect, mlir::StandardOpsDialect>();作用:将 AffineOpsDialect(仿射操作 Dialect)和 StandardOpsDialect(标准操作 Dialect)标记为合法 Dialect。
含义:转换过程中,若遇到这两个 Dialect 的操作,无需转换,可以直接保留。
应用场景:作为 Lowering 的阶段性目标,例如先将 Toy 转换为 Standard Dialect
(2) 非法 Dialect 定义 (addIllegalDialect)
target.addIllegalDialect<ToyDialect>();作用:将 ToyDialect 标记为非法 Dialect。
含义:转换过程结束后,IR 中绝对不能包含任何 Toy Dialect 的操作。如果最终还有残留,编译流程会报错失败。
应用场景:强制要求高层抽象(如 Toy)必须被完全降级为底层 Dialect(如 LLVM Dialect)。
(3) 合法 / 非法操作定义 (addLegalOp / addIllegalOp)
target.addLegalOp<PrintOp>(); // 保留 toy.print
// target.addIllegalOp<...>(); // 强制转换某些特定操作作用:对 Dialect 内的具体操作进行细粒度的控制。
示例:虽然 ToyDialect 整体是非法的,但可以允许 toy.print 操作合法存在,用于后续的打印逻辑(通常 I/O 操作会特殊处理)。
41:47