先从最核心的 Catalyst 优化器开始------它是 DataFrame 性能远超手写 RDD 的秘密所在。
- Catalyst 是 DataFrame 性能的核心引擎;
- DataFrame 最常用的操作------把每类 API 的用法和背后的执行逻辑对应起来;
- 三种 Join 类型的内部机制对比,这是 SQL 调优最核心的知识点;
- Window 函数和数据读写的完整流程
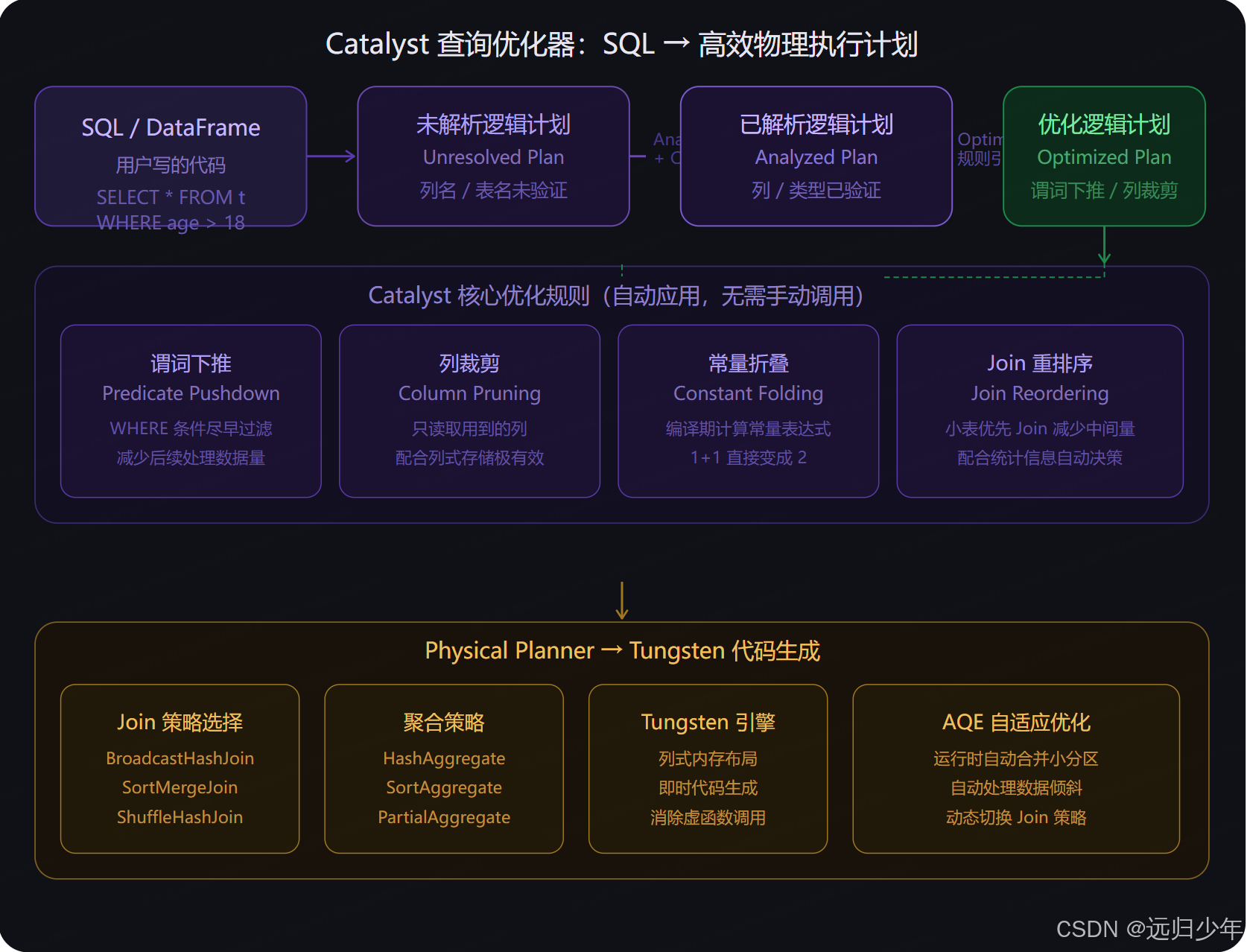
Catalyst 优化器(第一张) 是理解"为什么 DataFrame 比 RDD 快"的关键答案。
写同样逻辑的代码,DataFrame 版会经过四个阶段的自动变换:未解析逻辑计划 → Analyzer 对照 Catalog 验证列名和类型 → Optimizer 应用规则引擎做谓词下推、列裁剪、常量折叠、Join 重排序 → Physical Planner 选择具体执行算法(选哪种 Join、用哪种聚合)→ Tungsten 生成即时机器码执行。
整个过程你不需要做任何事,Spark 全自动完成。AQE(Adaptive Query Execution)是 Spark 3.0 后加入的运行时优化,能在执行过程中根据实际数据量动态调整分区数和 Join 策略,相当于"边跑边优化"。
DataFrame 操作分类(第二张) 把所有常用 API 分成五类。
- 前三类是 Transformation(懒执行):列操作处理列的增删改;行过滤减少数据量;排序和分区控制数据分布。
- 后两类是有状态操作:分组聚合是最常用的统计手段;Join 是最贵的操作,需要谨慎选择策略。
- 最底部的 Action 才是真正触发计算的操作,常见的有
show()、count()、collect()、write.parquet()等。
记住:所有 Transformation 都是懒的,只有 Action 才让 DAG 动起来。

三种 Join 策略(第三张) 是 SQL 调优里最高价值的知识点。
- Broadcast Hash Join 是性能最好的,把小表(默认小于 10MB)广播到每个 Executor 的内存,大表的每行直接在本地查哈希表匹配,完全没有 Shuffle,速度极快;适合大表 join 维度表/字典表。
- Sort Merge Join 是默认的兜底策略,两张大表都按 Join Key 做 Shuffle 重新分区,每个分区内各自排序,再双指针归并,代价最高但对大数据量最稳定。
- Shuffle Hash Join 介于两者之间,Shuffle 之后 Build 侧构建 Hash 表,Probe 侧逐行查,不需要排序,适合一侧中等大小的场景。
实战口诀:能 broadcast 就 broadcast,不能就开 AQE 让 Spark 自己选。

数据读写与 Window 函数(第四张) 是日常开发用得最多的两块。
- 读写 API 的核心是
format+option+mode三件套,写出时partitionBy可以按列分目录存储,极大提升后续查询的谓词下推效率。 - 文件格式方面,列式存储(Parquet / ORC)是大数据场景的首选,Delta Lake 在 Parquet 基础上加了事务日志,支持 ACID、Upsert 和 Time Travel,是 Lakehouse 架构的基石,生产环境优先选 Delta。
- Window 函数是处理"每组内的排名/差值/累计"类需求的利器,核心是先定义
WindowSpec(按哪列分区、按哪列排序、窗口范围多大),然后把任意聚合或分析函数套在over(w)上,原始行数不变但多出一列计算结果,比groupBy后再 join 回来的写法简洁十倍也快十倍。
