OpenCV基本操作
E:\python\opencv
1,图像的io操作,读取和保存方法
读取图像cv.imread()
参数
- 要读取的图像
- 读取方式的标志(1,以彩色模式加载图像,任何图像的透明度都将被忽略(默认参数);0,以灰度模式加载图像;-1,包括alpha通道的加载图像模式)
python
lena=cv2.imread("./data/8565451.jpg",1)显示图像cv.imshow()
参数;
- 显示图像的窗口名称,以字符串类型表示
- 要加载的图像
python
cv2.imshow("image",lena)
cv2.waitKey(0)注意:在调用显示图像的api后,要用cv.waitKey()给图像绘制留下时间,否则窗口会出现无响应情况,并且无法显示出来
也可以使用matplotlib对图像进行显示
python
plt.imshow(lena[:,:,::-1])#cv中的通道为bgr,plt的通道为rgb,需要反转
plt.axis('off') # 隐藏坐标轴
plt.title("Lena Image (RGB Corrected)")
plt.show()保存图像cv.imwrite()
参数:
- 文件名,要保存在哪里
- 要保存的图像
python
cv2.imwrite("./data/test1.jpg",lena)2,在图像上绘制几何图形
绘制直线
cv.line(img,start,end,color,thinkness)
参数:
- img:要绘制直线的图像
- start,end:直线的起点和终点
- color:线条和颜色
- thickness:线条宽度
绘制圆形
cv.circle(img,centerpoint,r,color,thickness)
参数:
img:要绘制圆形的图像
centerpoint,r:圆心和半径
color:线条和颜色
thickness:线条宽度,为-1时生成闭合图案并填充颜色
绘制矩形
cv.rectangle(img,leftupper,rightdown,color,thickness)
参数:
- img:要绘制矩形的图像
- leftupper,rightdown:矩形的左上角和右下角坐标
- color:线条和颜色
- thickness:线条宽度
向图像中添加文字
cv2.putText(img, text, station,font,fontsize,color,thickness,cv.LINE_AA)
参数:
- img:图像
- text:要写入的文本数据
- station:文本的放置位置
- font:字体
- fontsize:字体大小
python
#创建一个空白图像
import numpy as np
img=np.zeros((512,512,3),np.uint8)
#绘制图像
cv2.line(img,(0,0),(511,511),(255,255,255),5)
cv2.rectangle(img,(384,0),(510,128),(0,255,0),3)
cv2.circle(img,(447,63),63,(0,0,255),-1)
font=cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'OpenCv',(10,500),font,4,(255,255,255),2,cv2.LINE_AA)
#图像显示
plt.imshow(img[:,:,::-1])
plt.title('result show'),plt.xticks([]),plt.yticks([])
plt.show()3,怎么获取图像的属性
获取并修改图像中的像素点
我们可以通过行和列的坐标值获取该像素点的像素值。对于BGR图像,它返回一个蓝绿红值的数组。对于灰度图像仅返回相应的强度值。使用相同的方法对像素值进行修改。
python
img=cv2.imread('./data/test1.jpg')
#获取某个像素点的值
px=img[100,100]
print(px)
#仅获取蓝色通道的强度值
blue=img[100,100,0]
#修改某个位置的像素值
img[100,100]=[255,255,255]
plt.imshow(img[:,:,::-1])
plt.show()图像的属性包括行数、列数和通道数,图像数据类型,像素数等。
|------|-----------|
| 属性 | API |
| 形状 | img.shape |
| 图像大小 | img.size |
| 数据类型 | img.dtype |
python
img=cv2.imread('./data/test1.jpg')
print(img.shape)
print(img.dtype)
print(img.size)
'''(1080, 1920, 3)
uint8
6220800'''4,怎么访问图像的像素,进行通道分离,合并等
有时需要在bgr通道图像上单独工作,在这种情况下需要将bgr图像分割为单个通道。或者在其他情况下,可能需要将这些单独的通道合并到bgr图像。你可以通过以下方式完成。
python
#通道拆分
b,g,r=cv2.split(img)
#通道合并
img=cv2.merge((b,g,r))
plt.imshow(g)
plt.show()5,怎么实现颜色空间的变换
色彩空间的改变
cv.cvtColor(input_image,flag)
参数;
- input_image:进行颜色空间转换的图像
- flag:转换类型
cv.COLOR_BGR2GRAY:BGR->Gray
cv.COLOR_BGR2HSV:BGR->HSV
python
hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
plt.imshow(hsv)
plt.show()6,图像的算术运算
图像的加法
你可以使用opencv的cv.add()函数把两幅图像相加,或者可以简单地通过numpy操作添加两个图像,如res=img1+img2.两个图像应该具有相同的大小和类型,或者第二个图像可以是标量值。
注意:opencv加法和numpy加法之间存在差异。OpenCV的加法是饱和操作,而numpy添加是模运算。
python
x=np.uint8([250])
y=np.uint8([10])
print(cv.add(x,y)) #250+10=260->255
print(x+y) #250+10=260%256=4图像的混合
这其实也是加法。但是不同的是两幅图像的权重不同,这就会给人一种混合或者透明的感觉,图像混合的计算公式如下,
cv2.addWeighted(img1,alpha,img2,1-alpha,γ)γ表示常数
几何变换
1,图像缩放
缩放是对图像的大小进行调整,即使图像放大或缩小。
cv2.resize(src,dsize,fx=0,fy=0,interpolation=cv2.INTER_LINEAR)
参数:
src:输入图像
dsize:绝对尺寸,直接制定调整后的图像大小
fx,fy:相对尺寸,将dsize设置为None,然后将fx和fy设置为比例因子即可
interpolation:插值方法
|-------------------|------------|
| 插值 | 含义 |
| cv2.INTER_LINEAR | 双线性插值法(默认) |
| cv2.INTER_NEAREST | 最近邻插值 |
| cv2.INTER_AREA | 像素区域重采样 |
| cv2.INTER_CUBIC | 双三次插值 |
python
img=cv.imread('./data/test1.jpg')
img1=cv.resize(img,dsize=None,fx=0.5,fy=0.5,interpolation=cv.INTER_CUBIC)
plt.imshow(img1[:,:,::-1])
plt.show()
plt.imshow(img[:,:,::-1])
plt.show()2,图像平移
图像平移,将图像按照指定方向和距离移动到相应的位置。
cv.warpAffine(img,M,dsize)
参数:
- img:输入图像
- M:2*3移动矩阵
对于(x,y)处的像素点,要把它移动到处时,M矩阵应如下设置:
注意:将M设置为np.float32类型的Numpy数组。
- dsize:输出图像的大小
注意:输出图像的大小,它应该是(宽度,高度)的形式。请记住,width=列数,height=行数
python
#图像平移
rows,cols=img.shape[:2]
M=np.float32([[1,0,300],[0,1,500]])#平移矩阵
img1=cv.warpAffine(img,M,(cols,rows))
plt.imshow(img1[:,:,::-1])
plt.show()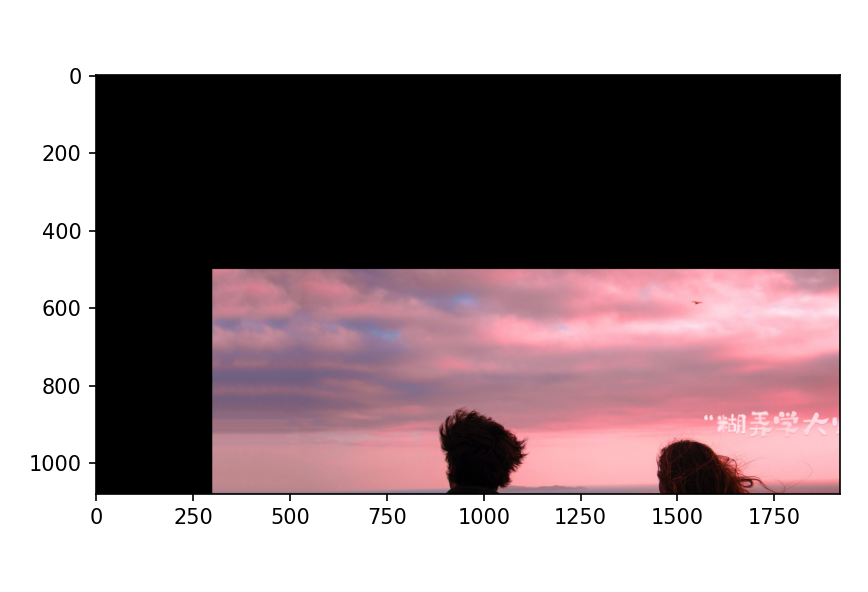
3,图像旋转
图像旋转是指图像按照某个位置转动一定的角度的过程。旋转中图片仍保持着原始尺寸。图像旋转后,图像的水平对称轴,垂直对称轴。及中心坐标原点都可能会发生变化。因此需要对图像旋转中的坐标进行相应转换。
cv2.getRotationMatrix2D(center,angle,scale)
参数:
center:旋转中心
angle:旋转角度
scale:缩放比例
返回:
M:旋转矩阵
调用cv2.warpAffine完成图像的旋转
python
#图像旋转
M=cv.getRotationMatrix2D((cols/2,rows/2),45,1)
img2=cv.warpAffine(img,M,(cols,rows))
plt.imshow(img2[:,:,::-1])
plt.show() 4,图像的仿射变换
4,图像的仿射变换
图像的仿射变换涉及到图像的形状,位置,角度的变化。是深度学习预处理中常用到的功能仿射变化。主要是对图像的缩放,旋转,翻转和平移等操作的组合。
在仿射变换中,原图中所有的平行线在结果图像中同样平行。为了创建这个矩阵,我们需要从原图像中找到三个点,以及他们在输出图像中的位置。然后cv2.getAffineTransform会创建一个2*3的矩阵,最后这个矩阵会被传给函数cv2.warpAffine.
python
#图像仿射变换
pst1=np.float32([[50,50],[200,50],[50,200]])#原图像中的三个点
pst2=np.float32([[100,100],[200,50],[100,250]])#仿射变换后图像中三个点的位置
M=cv.getAffineTransform(pst1,pst2)
dst=cv.warpAffine(img,M,(cols,rows))
plt.imshow(dst[:,:,::-1])
plt.show()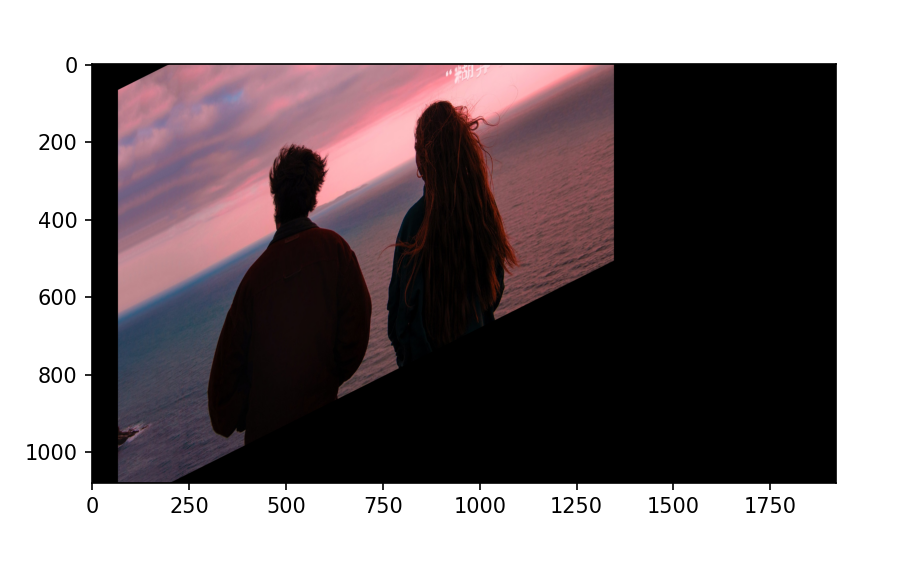
5,透射变换
透射变化是视觉变化的结果,是指利用透视中心,像点,目标点3点共线的条件,按透视旋转定律。使成影片透视面绕迹线,透视轴旋转某一角度,破坏原有的同时引光线束,仍能保持成影面上投影几何图形不变的变化。
在OpenCV中,我们要找到四个点,其中任意三个不共线,然后获取变换矩阵T,再进行透射变换。通过函数cv.getPerspectiveTransform找到变换矩阵,将cv.warpPerspective应用于此3*3变换矩阵。
python
#透射变换
pst1=np.float32([[56,65],[368,52],[28,387],[389,390]])
pst2=np.float32([[100,145],[300,100],[80,290],[310,100]])
T=cv.getPerspectiveTransform(pst1,pst2)
dst=cv.warpPerspective(img,T,(cols,rows))
plt.imshow(dst[:,:,::-1])
plt.show()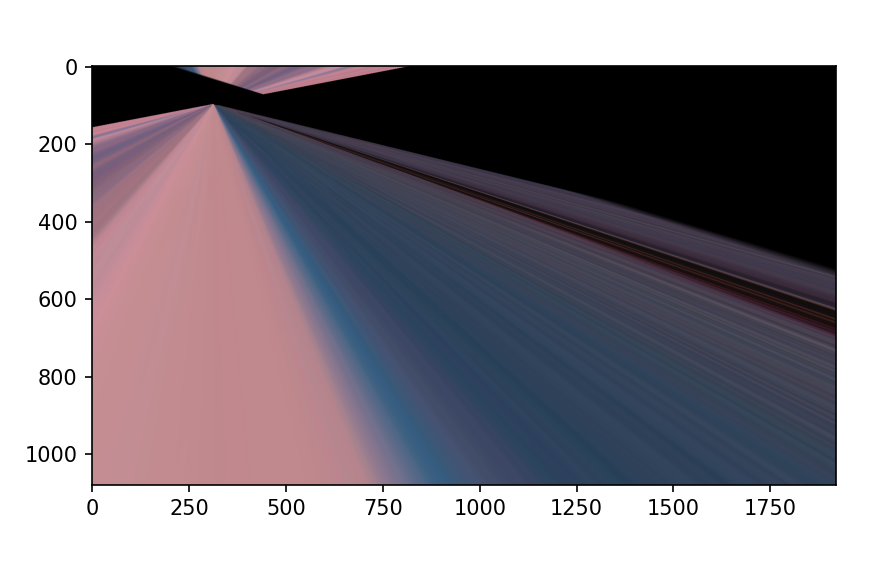
6,图像金字塔
高斯金字塔
图像金字塔是图像多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构。
图像金字塔用于机器视觉和图像压缩。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。
金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。层级越高,图像越小,分辨率越低。
向上采样(放大):从上层到下层,恢复图像尺寸(但无法恢复丢失的细节),步骤为:
- 将图像宽高放大 2 倍(用 0 填充新增像素);
- 对放大后的图像做高斯模糊(平滑填充的空白像素)。
cv.pyrUp(img)对图像进行上采样
- 向下采样(
pyrDown())的高斯卷积过程会进行边界填充 ,默认是镜像填充(BORDER_DEFAULT); - 填充的核心目的:让卷积核能完整覆盖边缘像素,避免边缘模糊失真;
- 填充后先完成全图像高斯模糊,再丢弃偶数行 / 列实现尺寸减半;
- 无需手动填充 ------OpenCV 会自动根据卷积核尺寸计算填充范围,保证模糊结果的完整性。
cv.pyrDown(img)对图像进行下采样
python
#图像金字塔
up_img=cv.pyrUp(img)
down_img=cv.pyrDown(img)
cv.imshow('up',up_img)#变大
cv.imshow('original',img)
cv.imshow('down',down_img)#变小
cv.waitKey(0)
cv.destroyAllWindows()拉普拉斯金字塔
它不直接存储图像的像素信息,而是存储「高斯金字塔层」与「该层向上采样后图像」的差值(即 "高频残差")。这些残差对应图像的边缘、细节等高频信息,结合高斯金字塔的低频信息,可实现图像的无损恢复和无缝融合,这也是拉普拉斯金字塔最核心的价值。
- 顶层 Ln = 高斯金字塔顶层 Gn(无更高层可差值,直接保留);
- 其余层 Ln = 高斯金字塔层 G (n-1) - (Gn 向上采样并匹配尺寸后的图像);
- 这些差值就是图像的高频细节(边缘、纹理),低频信息仍保存在高斯金字塔中。
核心特性
- 残差存储:拉普拉斯金字塔只存 "细节",不存完整图像,节省空间;
- 无损恢复:用拉普拉斯金字塔的残差 + 高斯金字塔的顶层,可逐层恢复出原图;
- 无缝融合:这是拉普拉斯金字塔最经典的应用(如苹果 + 橘子融合),通过融合不同层的残差,实现无拼接痕迹的图像融合。
阈值与平滑处理
图像阈值
ret,dst=cv2.threshold(src,thresh,maxval,type)
参数:
- src:输入图,只能输入单通道图像,通常来说为灰度图
- dst:输出图
- thresh:阈值
- maxval:当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
- type:二值化操作的类型,包含以下5种类型:
cv2.THRESH_BINARY:超过阈值部分取maxval(最大值),否则取0
cv2.THRESH_BINARY_INV:小于阈值的部分取maxval(最大值),否则取0
cv2.THRESH_TRUNC:大于阈值部分设为阈值,否则不变
cv2.THRESH_TOZERO:大于阈值部分不改变,否则设为0
cv2.THRESH_TOZERO_INV:小于阈值部分不改变,否则设置为0
python
#图像阈值
#选取部分图像
img1=img[500:1000,200:700]
# plt.imshow(img1[:,:,::-1])
# plt.show()
#将图像转为单通道
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
# plt.imshow(img1)
# plt.show()
ret,thresh1=cv2.threshold(img1,127,255,cv2.THRESH_BINARY)
ret,thresh2=cv2.threshold(img1,127,255,cv2.THRESH_BINARY_INV)
ret,thresh3=cv2.threshold(img1,127,255,cv2.THRESH_TRUNC)
ret,thresh4=cv2.threshold(img1,127,255,cv2.THRESH_TOZERO)
ret,thresh5=cv2.threshold(img1,127,255,cv2.THRESH_TOZERO_INV)
titles=['original Image','BINARY','BINARY_INV','TRUNC','TOZORE','TOZORE_INV']
images=[img1,thresh1,thresh2,thresh3,thresh4,thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
平滑处理
均值滤波
采用全为1的卷积核进行卷积再除以核的大小
简单的平均卷积操作
cv2.blur(img,kernel)
python
blur=cv2.blur(img1,(3,3))
cv2.imshow('blur',blur)
cv2.waitKey(0)
cv2.destroyAllWindows()方框滤波
cv.boxFilter(src, ddepth: int, ksize,normalize)
ddepth:通常为-1,表示自动计算原始图片的通道
normalize:等于True时,表示需要除以核的大小,效果与均值滤波一致;等于false时,表示卷积和,溢出时像素值为255
python
box=cv2.boxFilter(img1,-1,(3,3),normalize=False)
cv2.imshow('box',box)
cv2.waitKey(0)
cv2.destroyAllWindows()
高斯滤波
高斯滤波的卷积核里的数值是满足高斯分布,相当于更重视中间的
ps:
参数作用src输入图像(支持单通道 / 多通道,如 RGB、灰度图)ksize高斯核尺寸,格式为 (width, height),必须是奇数 (如 (3,3)、(5,5)),数值越大模糊越强sigmaXX 方向的高斯核标准差,控制模糊程度;若设为 0,OpenCV 会自动根据 ksize 计算(推荐)sigmaYY 方向的高斯核标准差,默认等于 sigmaX;若需横向 / 纵向差异化模糊可单独设置
中值滤波
相当于用中值代替
python
#均值滤波
blur=cv2.blur(img1,(3,3))
cv2.imshow('blur',blur)
cv2.waitKey(0)
cv2.destroyAllWindows()
#方框滤波
box=cv2.boxFilter(img1,-1,(3,3),normalize=False)
cv2.imshow('box',box)
cv2.waitKey(0)
cv2.destroyAllWindows()
#高斯滤波
aussian=cv2.GaussianBlur(img1,(5,5),1)
cv2.imshow('aussion',aussian)
cv2.waitKey(0)
cv2.destroyAllWindows()
#中值滤波
median=cv2.medianBlur(img1,5)
cv2.imshow('median',median)
cv2.waitKey(0)
cv2.destroyAllWindows()
#展示所有的结果,hstack横向拼接,vstack列项拼接
res=np.hstack((blur,aussian,median))
cv2.imshow('median vs average',res)
cv2.waitKey(0)
cv2.destroyAllWindows()形态学操作
腐蚀操作
腐蚀是 OpenCV 中最基础的形态学操作之一,核心作用是「侵蚀」图像中的白色前景区域(高亮区域),让前景边界向内收缩,能有效去除小的白色噪点、细化轮廓,或分离相邻的连通区域。
用一个「结构元素(卷积核)」遍历图像的每个像素,只有当结构元素覆盖的所有像素都是白色(255)时,中心像素才保留为白色,否则变为黑色(0)。
-
结构元素越⼤,腐蚀效果越强;
-
结构元素形状(矩形、圆形、十字形)决定腐蚀的方向 / 形态。
dst = cv2.erode(src, kernel, iterations=1, borderType=cv2.BORDER_CONSTANT, borderValue=cv2.morphologyDefaultBorderValue())
关键参数说明:
| 参数 | 作用 |
|---|---|
src |
输入图像(必须是二值图,即黑白图像,灰度图也可但效果需结合阈值) |
kernel |
结构元素(卷积核),常用 cv2.getStructuringElement() 生成 |
iterations |
腐蚀次数(默认 1,次数越多腐蚀越彻底) |
python
no=cv.imread('./data/no.png')
print(no.shape)
no1=no[200:650,600:1500]
kernel=np.ones((5,5),np.uint8)
dst=cv.erode(no1,kernel,iterations=1)
res=np.vstack((no1,dst))
cv.imshow('com',res)
cv.waitKey(0)
cv.destroyAllWindows()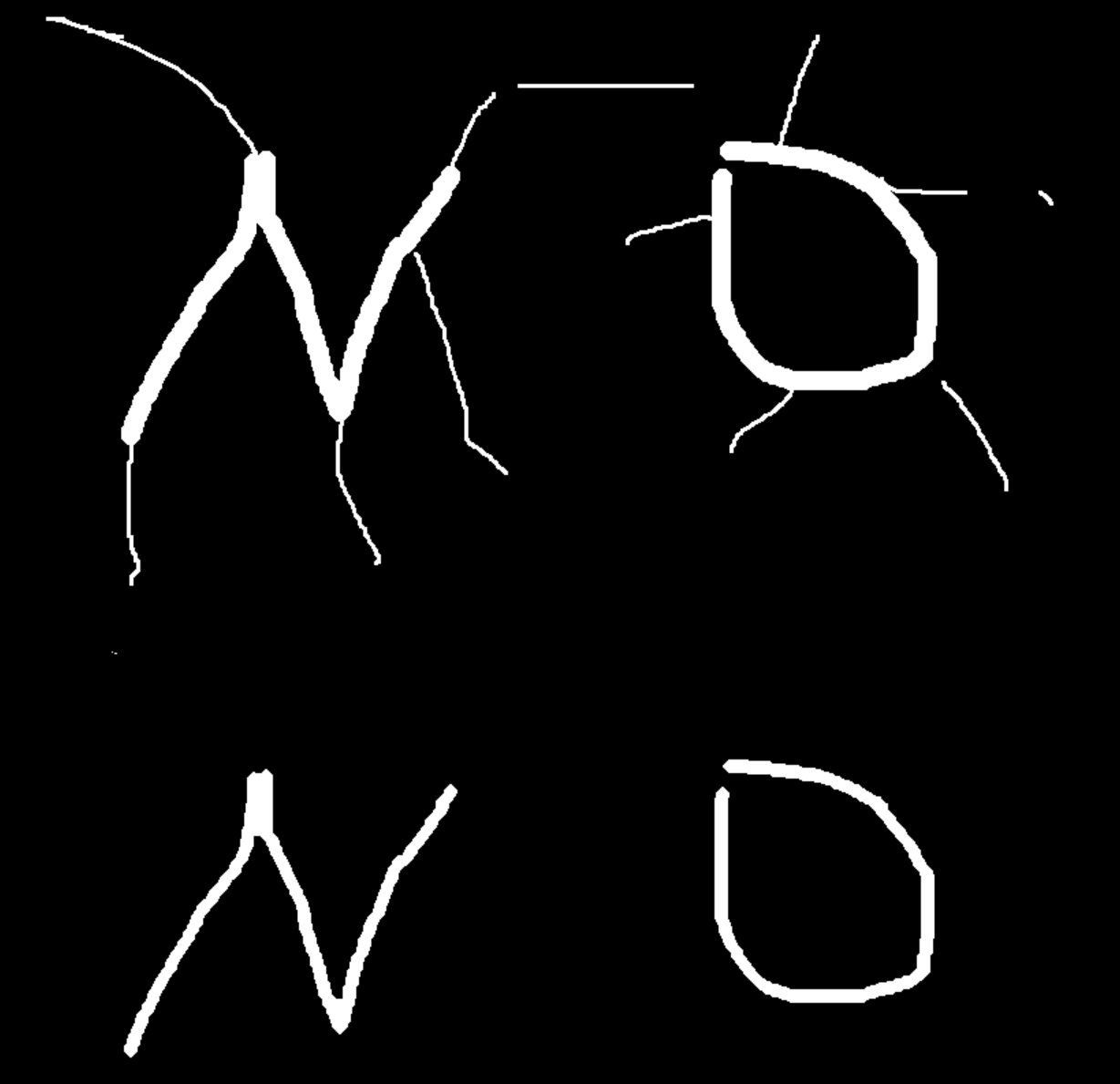
膨胀操作
膨胀是 OpenCV 中与腐蚀完全反向的形态学操作,核心作用是「扩张」图像中的白色前景区域(高亮区域),让前景边界向外扩张,能有效填充前景中的小空洞、加粗轮廓,或连接断裂的前景区域。
可以把膨胀理解为:用一个「结构元素(卷积核)」遍历图像的每个像素,只要结构元素覆盖的区域中有任意一个像素是白色(255),中心像素就会被设为白色,否则保持黑色(0)。
-
结构元素越大,膨胀效果越强;
-
结构元素形状(矩形、圆形、十字形)决定膨胀的方向 / 形态;
-
膨胀是腐蚀的 "逆操作":腐蚀收缩白色区域,膨胀扩张白色区域。
dst = cv2.dilate(src, kernel, iterations=1, borderType=cv2.BORDER_CONSTANT, borderValue=cv2.morphologyDefaultBorderValue())
| 参数 | 作用 |
|---|---|
src |
输入图像(优先用二值图,灰度图也可但效果需结合阈值) |
kernel |
结构元素(卷积核),常用 cv2.getStructuringElement() 生成 |
iterations |
膨胀次数(默认 1,次数越多膨胀越彻底) |
python
kernel=np.ones((3,3),np.uint8)
no2=cv.dilate(dst,kernel,iterations=3)
res=np.vstack((dst,no2))
cv.imshow('com',res)
cv.waitKey(0)
cv.destroyAllWindows()
开运算与闭运算
开运算:先腐蚀,再膨胀,可以去除噪点 + 恢复前景大小
python
kernel=np.ones((5,5),np.uint8)
opening=cv.morphologyEx(no1,cv.MORPH_OPEN,kernel)
compare=np.vstack((no1,opening))
cv.imshow('compare',compare)
cv.waitKey(0)
cv.destroyAllWindows()
闭运算:先膨胀,再腐蚀,填充前景中的小空洞 + 恢复前景大小
python
hole=cv.imread('./data/hole.png')
hole=hole[350:650,600:1200]
kernel=np.ones((10,10),np.uint8)
closing=cv.morphologyEx(hole,cv.MORPH_CLOSE,kernel)
compare=np.vstack((hole,closing))
cv.imshow("compare",compare)
cv.waitKey(0)
cv.destroyAllWindows()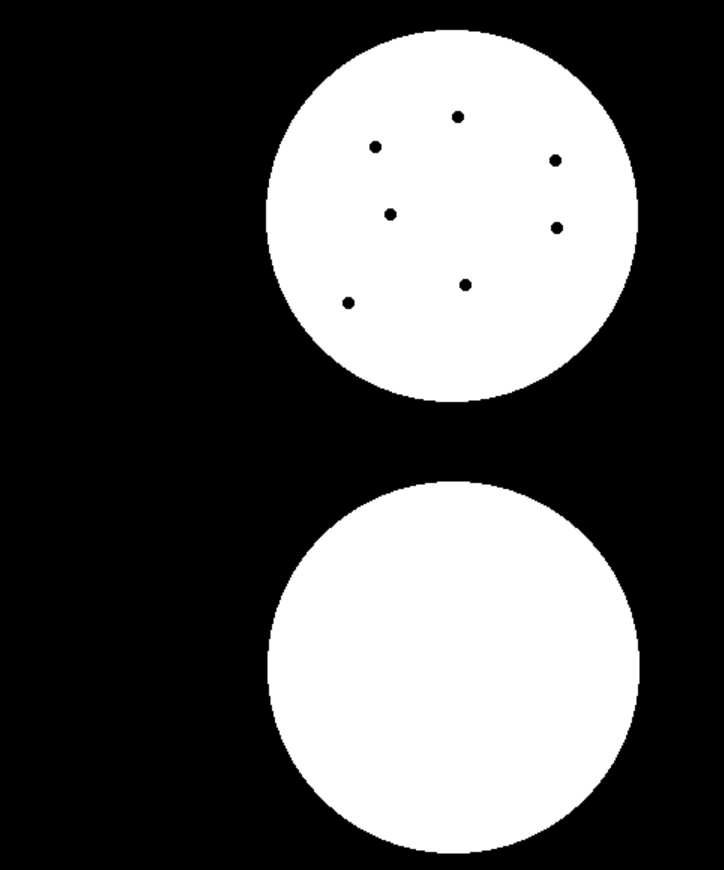
梯度运算
核心作用是提取图像中前景区域的轮廓 / 边缘------ 原理是用「膨胀后的图像」减去「腐蚀后的图像」,差值即为前景的边缘(梯度)。
.通俗理解
可以把形态学梯度拆解为 3 步:
- 对二值图做膨胀:让前景区域向外扩张;
- 对同一张二值图做腐蚀:让前景区域向内收缩;
- 用「膨胀图 - 腐蚀图」:差值部分就是前景的边缘(轮廓)。
类比:把一个物体(前景)"放大一圈" 减去 "缩小一圈",剩下的就是物体的 "外壳"(边缘)。
python
hole=cv.imread('./data/hole.png')
hole=hole[350:650,700:1200]
kernel=np.ones((7,7),np.uint8)
gradient=cv.morphologyEx(hole,cv.MORPH_GRADIENT,kernel)
compare=np.vstack((hole,gradient))
cv.imshow("compare",compare)
cv.waitKey(0)
cv.destroyAllWindows()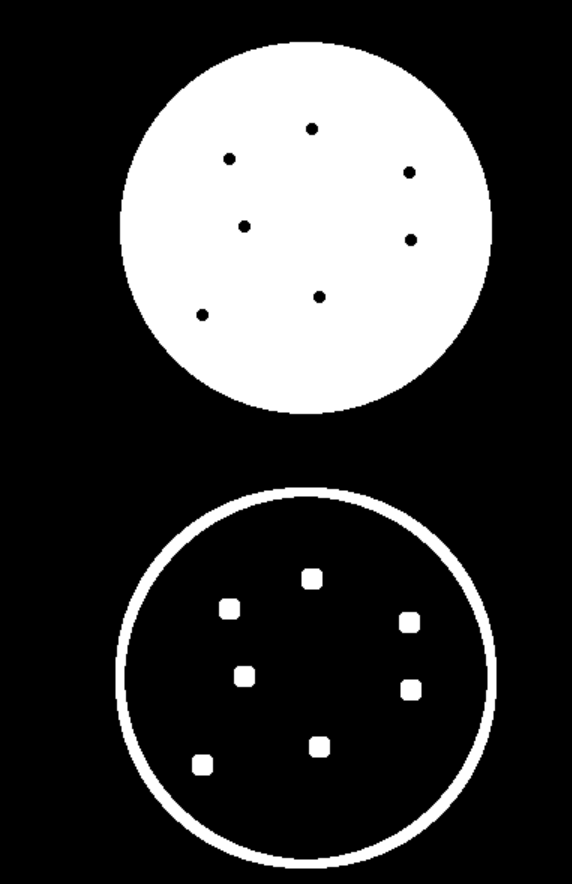
礼帽与黑帽
礼帽图 = 原图 - 开运算图
开运算会去掉原图中的 "亮小点点"(亮噪点),用原图减去开运算图,剩下的就是这些被去掉的「亮噪点 / 局部亮区」,提取图像中比周围区域更亮的小区域(比如黑背景上的白噪点、文字边缘的亮毛刺)。
python
no=cv.imread('./data/no.png')
no = no[200:650, 600:1500]
kernel=np.ones((7,7),np.uint8)
tophat=cv.morphologyEx(no,cv.MORPH_TOPHAT,kernel)
compare=np.vstack((no,tophat))
cv.imshow("compare",compare)
cv.waitKey(0)
cv.destroyAllWindows()
黑帽图 = 闭运算图 - 原图
闭运算会填充原图中的 "暗小点点"(暗空洞),用闭运算图减去原图,剩下的就是这些被填充的「暗噪点 / 局部暗区」,提取图像中比周围区域更暗的小区域(比如白背景上的黑噪点、文字内部的暗空洞)。
python
hole=cv.imread('./data/hole.png')
hole=hole[350:650,700:1200]
kernel=np.ones((7,7),np.uint8)
blackhat=cv.morphologyEx(hole,cv.MORPH_BLACKHAT,kernel)
compare=np.vstack((hole,blackhat))
cv.imshow("compare",compare)
cv.waitKey(0)
cv.destroyAllWindows()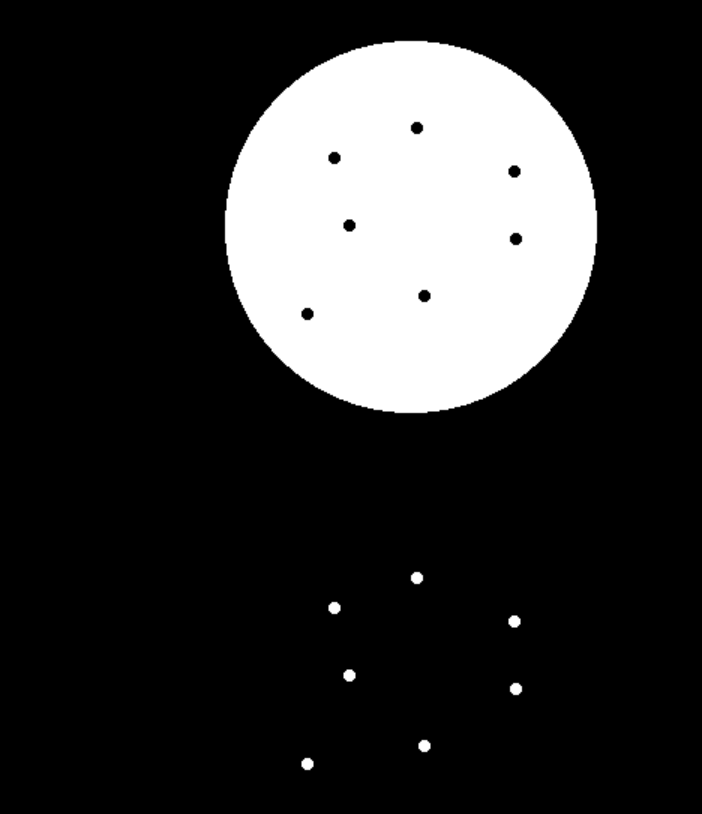
图像梯度计算
sobel算子
Sobel 算子是图像处理中最经典的一阶梯度算子 ,专门用于检测图像边缘 ------ 它通过计算像素在 X(横向)和 Y(纵向)方向的灰度变化率(梯度),找到像素值突变的区域(边缘)。相比普通梯度计算,Sobel 算子加入了高斯平滑的思想(对邻域像素加权),抗噪性更好,是边缘检测的首选基础算子。
dst=cv2.Sobel(src,ddepth,dx,dy,ksize)
通俗来说,就是该点右边的像素值减去左边的像素值,如果出现负数则被截断为0,所以要取绝对值
参数:
- src:输入图像(优先用灰度图,彩色图需先转灰度)
- ddepth:图像的深度
- dx和dy:分别表示水平和竖直方向
- ksize:是Sobel算子的大小
python
def cv_show(imgname,img):
cv.imshow(imgname,img)
cv.waitKey(0)
cv.destroyAllWindows()
#sobel算子
circle=cv.imread('./data/circle.png')
circle=circle[350:650,800:1200]
# cv_show('circle',circle)
sobelx=cv.Sobel(circle,cv.CV_64F,1,0,ksize=3)
# cv_show('sobelx',sobelx)
sobelAbsx=cv.convertScaleAbs(sobelx)
# cv_show('sobelAbsx',sobelAbsx)
sobely=cv.Sobel(circle,cv.CV_64F,0,1,ksize=3)
sobelAbsy=cv.convertScaleAbs(sobely)
sobelxy=cv.addWeighted(sobelAbsx,0.5,sobelAbsy,0.5,0)
sobelxy11=cv.Sobel(circle,cv.CV_64F,1,1,ksize=3)
titles=['circle','sobelx','sobelAbsx','sobely','sobelAbsy','sobelxy','sobelxy11']
images=[circle,sobelx,sobelAbsx,sobely,sobelAbsy,sobelxy,sobelxy11]
for i in range(7):
plt.subplot(3,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()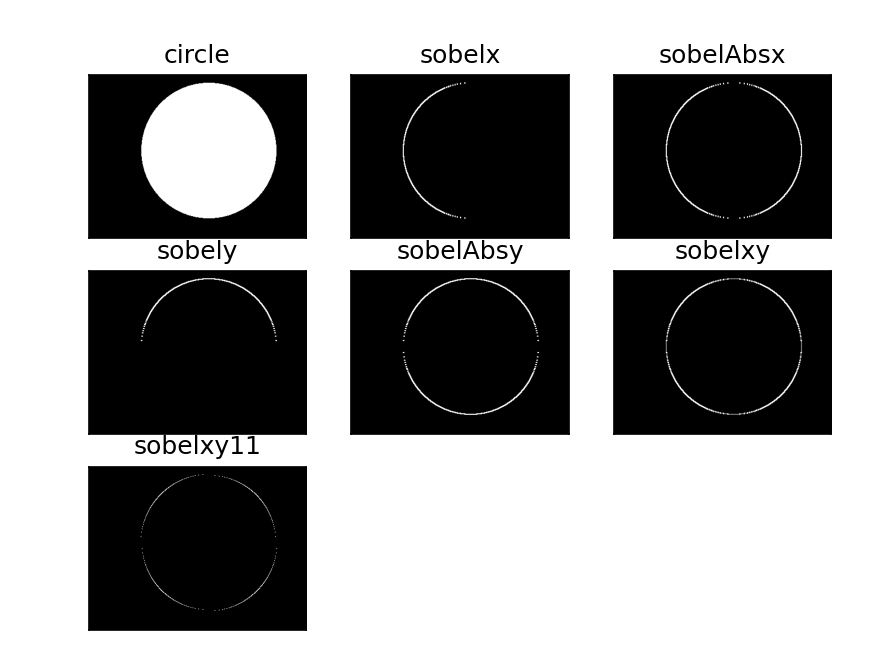
- Scharr 算子 :是 Sobel 算子的「高精度版本」,专门解决小核(3×3)Sobel 梯度计算精度低的问题,仍属于一阶梯度;
- Laplacian 算子 :直接计算二阶梯度,对细线边缘 / 微小变化更敏感,但易放大噪点。
Scharr算子
Scharr 算子是 3×3 核的 "增强版 Sobel",通过调整权重系数提升梯度计算精度(尤其是斜向边缘),仅支持 3×3 核(无更大核尺寸)。
laplacian
python
scharrx=cv.Scharr(circle,cv.CV_64F,1,0)
scharry=cv.Scharr(circle,cv.CV_64F,0,1)
scharrx=cv.convertScaleAbs(scharrx)
scharry=cv.convertScaleAbs(scharry)
scharrxy=cv.addWeighted(scharrx,0.5,scharry,0.5,0)
laplacian=cv.Laplacian(circle,cv.CV_64F)
laplacian=cv.convertScaleAbs(laplacian)
titles=['circle','sobel','scharr','laplaction']
images=[circle,sobelxy,scharrxy,laplacian]
for i in range(4):
plt.subplot(1,4,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()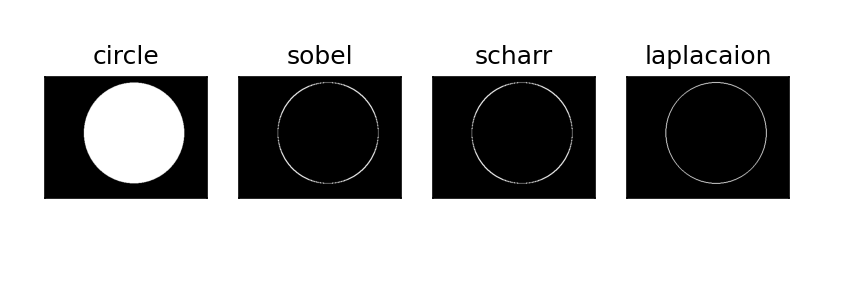
边缘检测(canny)
边缘检测步骤:
1,应用高斯滤波器,以平滑图像,滤除噪声(降噪)
2,计算图像中每个像素点的梯度大小和方向(梯度)
3,使用非极大值抑制,消除边缘检测带来的不利影响(非极大值抑制)
4,应用双阈值检测确定真实和潜在的边缘(双阈值检测)
梯度值>maxVal:则处理为边界
minVal<梯度值<macVal:连有边界则保留,否则舍弃
梯度值<minVal:舍弃
5,通过抑制独立的弱边缘完成边缘检测(完成检测)
dst=cv2.Canny(src,minval,maxval)
python
canny1=cv.Canny(img,80,150)
canyy2=cv.Canny(img,50,100)
res=np.hstack((canny1,canyy2))
cv_show('canny',res)
图像金字塔与轮廓检测
图像轮廓
轮廓就是一连串连续的点,组成图像中物体的边界、形状、外围线条。
作用:
- 找物体形状
- 检测目标位置
- 计算面积、周长、外接矩形
- 物体分类、识别
轮廓的前提(非常重要)
- **必须是二值图像(黑白图不是灰度图)**轮廓只能在 0/255 二值图上找。
- 通常先做预处理
- 灰度化
- 阈值二值化 / Canny 边缘检测
- 白色是前景,黑色是背景(反了会找错)
python
contours, hierarchy = cv2.findContours(
binary_img, # 二值图
cv2.RETR_EXTERNAL, # 检索模式(mode)
cv2.CHAIN_APPROX_SIMPLE # 近似方法(method)
)参数:
mode:轮廓检索模式
- RETR_EXTERNAL:只检索最外面的轮廓
- RETR_LIST:检索所有的轮廓,并将其保存到一条链条中
- RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界
- RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次
method:轮廓逼近方法
CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)
CHAIN_APPROX_SIMPLE:压缩水平的,垂直的和斜的部分,也就是,函数只保留他们的终点部分。
注意:需要备份图像,drawcountours是在原图上绘制
python
people=cv.imread('./data/people.jpg')
# cv_show('people',people)
people=cv.resize(people,dsize=None,fx=0.5,fy=0.5)
# cv_show('people',people)
gray_img=cv.cvtColor(people,cv.COLOR_BGR2GRAY)
ret,thresh=cv.threshold(gray_img,127,255,cv.THRESH_BINARY)
# cv_show('black',thresh)
contours,hierarchy=cv.findContours(thresh,cv.RETR_TREE,cv.CHAIN_APPROX_NONE)
draw_img=people.copy()
#传入绘制图像,轮廓,轮廓索引(-1表示所有),颜色模式,线条厚度
res=cv.drawContours(draw_img,contours,-1,(0,0,255),2)
cv_show('contours',res)
轮廓特征
python
cnt=contours[7]
#面积
print(cv.contourArea(cnt))
#周长,True表示闭合的
print(cv.arcLength(cnt,True))轮廓近似
python
polygon=cv.imread('./data/polygon.png')
polygon=cv.resize(polygon,dsize=None,fx=0.5,fy=0.5)
gray_img=cv.cvtColor(polygon,cv.COLOR_BGR2GRAY)
ret,threshold=cv.threshold(gray_img,127,255,cv.THRESH_BINARY)
# cv_show('polygon',polygon)
countours,hierarchy=cv.findContours(threshold,cv.RETR_TREE,cv.CHAIN_APPROX_SIMPLE)
draw_img=polygon.copy()
# res=cv.drawContours(draw_img,countours,-1,(0,0,255),1)
# cv_show('polygon',res)
cnt=countours[4]
#近似阈值,越小越接近原型
epsilon=0.1*cv.arcLength(cnt,True)
approx=cv.approxPolyDP(cnt,epsilon,True)
res=cv.drawContours(draw_img,[approx],-1,(0,0,255),2)
cv_show('res',res)

模板匹配
简单说,就是在一张「大图(源图像)」中,寻找和「小图(模板图像)」最相似的区域,常用于目标定位、特征匹配等场景(比如在截图中找按钮、在视频帧中找特定物体)。
核心原理
模板匹配的本质是滑动窗口比较:
- 把模板图像当作 "滑动窗口",从源图像的左上角滑到右下角;
- 每滑动到一个位置,计算窗口内的源图像区域与模板的「相似度」(通过不同的匹配算法);
- 输出一个「匹配结果图」(单通道),每个像素值表示对应位置的相似度,值越大 / 越小(取决于算法)表示越匹配。
result = cv2.matchTemplate(img, templ, method, result=None, mask=None)
| 参数 | 作用 |
|---|---|
img |
源图像(大图):支持灰度图 / 彩色图(需和模板图像通道数一致) |
templ |
模板图像(小图):尺寸必须小于等于源图像,通道数和源图像一致 |
method |
匹配算法(核心参数):共 6 种,常用 cv2.TM_CCOEFF_NORMED(归一化相关系数) |
mask |
模板掩码(可选):仅 TM_CCORR_NORMED/TM_CCOEFF_NORMED 支持,用于指定模板的有效区域 |
| 算法常量 | 特点 | 最优值 | 适用场景 |
|---|---|---|---|
TM_CCOEFF_NORMED |
归一化相关系数,抗亮度变化,最常用 | 接近 1 | 通用场景(推荐) |
TM_CCORR_NORMED |
归一化相关匹配,对亮度敏感 | 接近 1 | 亮度一致的图像 |
TM_SQDIFF_NORMED |
归一化平方差匹配,计算快 | 接近 0 | 简单场景(精度一般) |
python
#模板匹配
circle=cv.imread('./data/circle.png')
template=circle[350:650,800:1200]
h,w=template.shape[:2]
#执行模板匹配(用最常用的归一化相关系数)
res=cv.matchTemplate(circle,template,cv.TM_CCOEFF_NORMED)
#找最佳匹配位置(相似度最高的坐标)
minval,maxval,minloc,maxloc=cv.minMaxLoc(res)
# TM_CCOEFF_NORMED 的最优值是max_val,对应max_loc
left_top=maxloc # 匹配框的左上角坐标
bottom_right = (left_top[0] + w, left_top[1] + h) # 匹配框的右下角坐标
#在源图像上绘制匹配框(BGR格式,红色=(0,0,255))
img_match=circle.copy()
cv.rectangle(img_match,left_top,bottom_right,(0,0,255),2)
cv_show('match',img_match)
匹配多个对象
python
threshold=0.8
#获取匹配程度大于80%的坐标
loc=np.where(res>=threshold)
for pt in zip(*loc[::-1]:
bottom_right=(pt[0]+w,pt[1]+h)
cv.rectangle(img,pt,bottom_right,(0,0,255),2)
cv_show('img',img)直方图与傅里叶变换
直方图
图像直方图是统计图像中不同像素值出现频率的工具 ------ 简单说,它以「像素值(0~255)」为横轴,「该值出现的像素数量 / 占比」为纵轴,直观反映图像的亮度、对比度、色彩分布特征。
核心用途:
- 分析图像曝光(过亮 / 过暗);
- 图像增强(直方图均衡化);
- 图像分割(阈值选择);
- 图像匹配 / 检索(直方图相似度)。
python
hist = cv2.calcHist(
images, # 输入图像(列表格式,如[img])
channels, # 通道索引(灰度图=[0],彩色图=[0]/[1]/[2]对应B/G/R)
mask, # 掩码(None表示整幅图,用于统计局部区域)
histSize, # 直方图分箱数(如[256]表示0~255每个值一个箱)
ranges # 像素值范围(灰度图=[0,256],注意是左闭右开)
)灰度图
python
img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
hist=cv.calcHist(img,[0],None,[256],[0,256])
plt.hist(img.ravel(),256)
plt.show()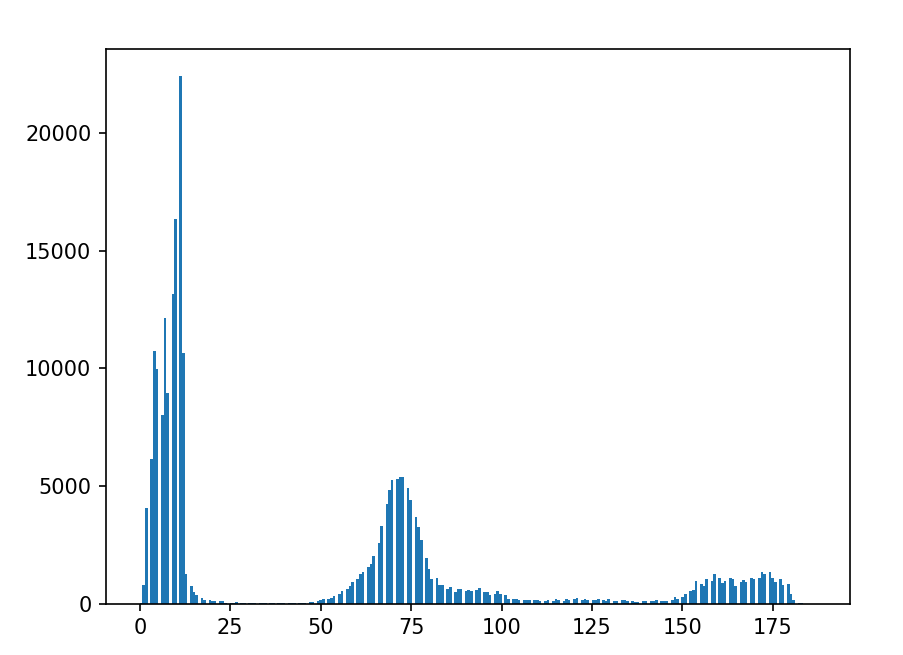
彩色图
python
color=('b','g','r')
for i,col in enumerate(color):
histr=cv.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color=col)
plt.xlim([0,256])
plt.show()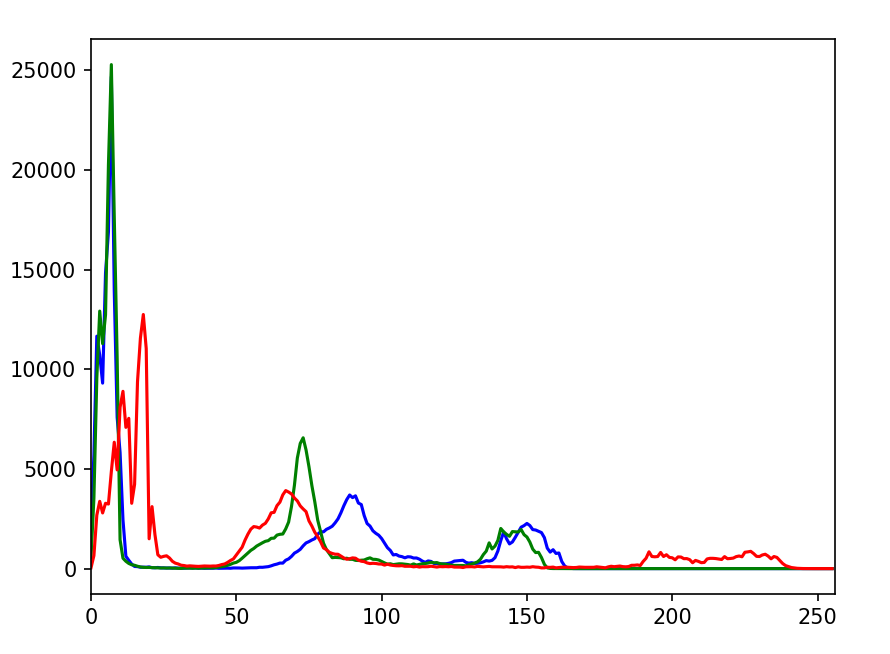
掩码
cv2.bitwise_and 是 OpenCV 中用于对图像进行按位与运算的核心函数 ------ 它逐像素对两张图像(或图像与标量)执行二进制 "与" 操作,是图像处理中掩码(Mask)、区域提取、图像融合的基础工具。
| 像素 A | 像素 B | A & B(按位与) |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
dst = cv2.bitwise_and(src1, src2, mask=None)
直方图均衡化(图像增强核心应用)
直方图均衡化是通过拉伸像素值分布,提升图像对比度的方法 ------ 把集中在窄范围的像素值分散到 0~255 全范围,解决图像过暗 / 过亮、对比度低的问题。
核心原理(数学层面)
直方图均衡化的本质是累积分布函数(CDF)的映射,步骤如下:
- 计算原始图像的直方图 H(r)(r 为像素值,0~255);
- 计算累积分布函数:CDF(r)=∑i=0rH(i)/(W×H)(归一化到 0~1);
- 映射新像素值:s=255×CDF(r)(将 CDF 拉伸到 0~255);
- 用映射表替换原始像素值,得到均衡化图像。
python
equ=cv.equalizeHist(img)
plt.hist(equ.ravel(),256)
plt.show()
res=np.hstack((img,equ))
cv_show('res',res)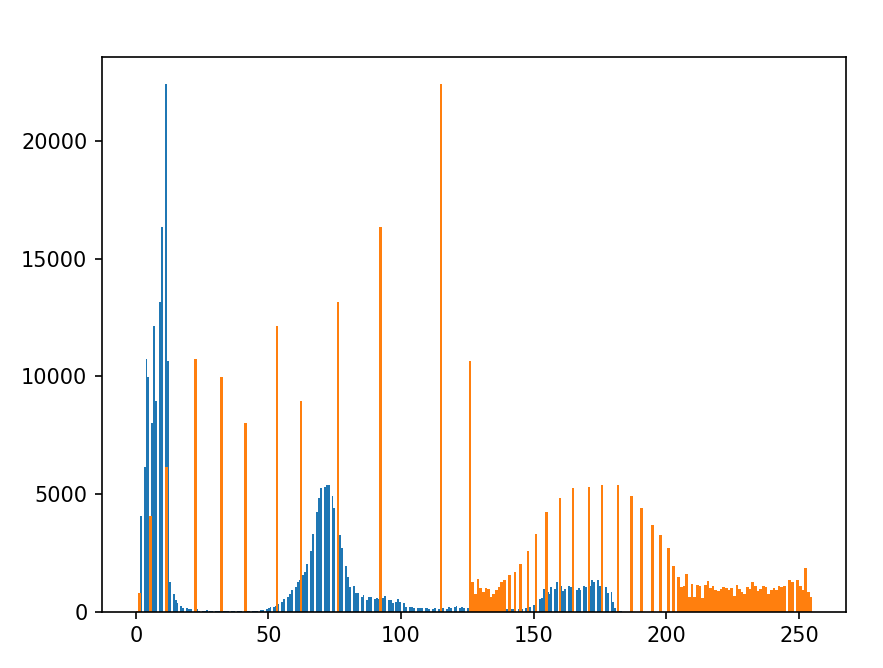

自适应直方图均衡化
普通均衡化的问题:全局拉伸会导致局部过曝 / 细节丢失(如亮区更亮、暗区更暗)。
✅ 解决方案:自适应直方图均衡化(CLAHE) ------ 将图像分成多个小区域(tiles),分别做局部均衡化,限制对比度避免过曝。
1. 创建CLAHE对象(限制对比度,tile尺寸8×8)
-
clipLimit:对比度限制(默认40,越小越柔和)
-
tileGridSize:局部区域尺寸(越小局部效果越细)
python
clahe=cv.createCLAHE(clipLimit=2.0,tileGridSize=(8,8))
res_clahe=clahe.apply(img)
res=np.hstack((img,equ,res_clahe))
cv_show('res',res) 傅里叶变换
傅里叶变换
图像傅里叶变换(FT/Fourier Transform)是将图像从空间域 (像素的位置和亮度)转换到频率域的数学工具 ------ 简单说,它把图像拆解成 "低频分量"(整体轮廓、大结构)和 "高频分量"(边缘、细节、噪点),是图像滤波、去噪、增强、特征提取的核心基础。
核心概念(新手易懂版):
- 空间域:我们看到的图像,每个像素有坐标 (x,y) 和亮度值,关注 "哪里亮、哪里暗";
- 频率域 :看不到的 "隐藏维度",关注 "亮度变化的快慢":
- 低频:亮度变化慢(如纯色背景、大物体轮廓);
- 高频:亮度变化快(如边缘、纹理、噪点)。
核心用途:
- 图像去噪(过滤高频噪点);
- 图像增强(强化高频边缘 / 低频轮廓);
- 特征提取(频率域的独特模式);
- 图像压缩(保留低频,舍弃冗余高频)。
滤波:
低通滤波器:只保留低频,会使图像模糊
高频滤波器:只保留高频,会使得图像细节增强
- 傅里叶变换核心是空间域→频率域的转换,将图像拆解为低频(轮廓)和高频(细节);
- 核心操作:
fft2()变换 (将原图像转换为频率)→fftshift()移位(将高频和低频分开,把低频放中间) → 频率域滤波(利用掩码进行滤波) →ifftshift()逆移位 (将频率还原)→ifft2()逆变换;(将频率图转换为原图)
注意输入图像必须先转换成np.float32格式
低通滤波
python
img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
img_float32=np.float32(img)
#转换为频率图,双通道不能可视化
dft=cv.dft(img_float32,flags=cv.DFT_COMPLEX_OUTPUT)
#低频移到中心(便于观察)
dft_shift=np.fft.fftshift(dft)
#得到灰度图能表示的形式
magnitufe_spectrun=20*np.log(cv.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img,cmap='gray')
plt.title("Input Image"),plt.xticks([]),plt.yticks([])
plt.subplot(122),plt.imshow(magnitufe_spectrun,cmap='gray')
plt.title('magnitude spectrum'),plt.xticks([]),plt.yticks([])
plt.show()
python
img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
img_float32=np.float32(img)
#转换为频率图,双通道不能可视化
dft=cv.dft(img_float32,flags=cv.DFT_COMPLEX_OUTPUT)
#低频移到中心(便于观察)
dft_shift=np.fft.fftshift(dft)
#计算中心点位置
rows,cols=img.shape
crow,ccol=int(rows/2),int(cols/2)
#低通滤波器,创建全0掩码,中心保留,四周屏蔽
mask=np.zeros((rows,cols,2),np.uint8)
mask[crow-30:crow+30,ccol-30:ccol+30]=1
#频率域滤波(仅保留掩码非0区域的频率)
fshit=dft_shift*mask
#逆变换还原
f_ishift=np.fft.ifftshift(fshit)
img_back=cv.idft(f_ishift)
img_back=cv.magnitude(img_back[:,:,0],img_back[:,:,1])
plt.subplot(121),plt.imshow(img,cmap='gray')
plt.title("Input Image"),plt.xticks([]),plt.yticks([])
plt.subplot(122),plt.imshow(img_back,cmap='gray')
plt.title('result'),plt.xticks([]),plt.yticks([])
plt.show()
高通滤波
python
#高通滤波
img=cv.cvtColor(img,cv.COLOR_BGR2GRAY)
img_float32=np.float32(img)
rows,cols=img.shape
crow,ccol=int(rows/2),int(cols/2)
mask=np.ones((rows,cols,2),np.uint8)
mask[crow-30:crow+30,ccol-30:ccol+30]=0
dft=cv.dft(img_float32,flags=cv.DFT_COMPLEX_OUTPUT)
dft_shift=np.fft.fftshift(dft)
fshift=dft_shift*mask
f_ishift=np.fft.ifftshift(fshift)
img_back=cv.idft(f_ishift)
img_back=cv.magnitude(img_back[:,:,0],img_back[:,:,1])
plt.subplot(121),plt.imshow(img,cmap='gray')
plt.title('Input Image'),plt.xticks([]),plt.yticks([])
plt.subplot(122),plt.imshow(img_back,cmap='gray')
plt.title('frequent filter'),plt.xticks([]),plt.yticks([])
plt.show()