文章目录
- 摘要
- abstract
- [一、mclip的论文-Multilingual CLIP via Cross-lingual Transfer-23.](#一、mclip的论文-Multilingual CLIP via Cross-lingual Transfer-23.)
- 二、实践
- 总结
摘要
围绕多语言图文检索模型mCLIP论文展开学习,论文提出了一种多语言视觉-语言预训练模型。核心创新在于通过三角形跨模态知识蒸馏(TriKD),将冻结的CLIP图像编码器与增强后的多语言文本编码器XLM-R对齐。该方法仅训练少量新增投影层,高效地实现了多语言对齐。为提升XLM-R的检索能力,论文进一步设计了结合神经机器翻译和对比损失的两阶段增强方案,强化了token级与句子级的跨语言表示。
在实践环节,将mCLIP迁移至多模态推荐任务,在Amazon三个子数据集上进行了验证。实验复现了BPR、LightGCN及多模态VBPR作为基线。初步结果表明,该模型结构在推荐场景中具备可行性,整体性能符合预期,为后续工作提供了基础。
abstract
This paper focuses on the multilingual image-text retrieval model mCLIP, proposing a multilingual vision-language pre-trained model. The core innovation lies in aligning the frozen CLIP image encoder with the enhanced multilingual text encoder XLM-R through Triangular Cross-Modal Knowledge Distillation (TriKD). This method trains only a few additional projection layers, efficiently achieving multilingual alignment. To improve the retrieval capability of XLM-R, the paper further designs a two-stage enhancement scheme combining neural machine translation and contrastive loss, strengthening token-level and sentence-level cross-lingual representations.
In the practical application, mCLIP is transferred to a multimodal recommendation task and validated on three Amazon datasets. Experiments reproduce BPR, LightGCN, and multimodal VBPR as baselines. Preliminary results show that the model structure is feasible in recommendation scenarios, with overall performance meeting expectations, providing a foundation for future work.
一、mclip的论文-Multilingual CLIP via Cross-lingual Transfer-23.
检索高效的双流多语言VLP模型,通过一种新颖的三角形跨模态知识蒸馏(TriKD)方法,通过对齐CLIP模型和多语言文本编码器(MTE)进行训练。
避免灾难性遗忘预训练CLIP和MTE中已学习的知识,它们在训练过程中保持冻结。三角形对齐通过调整CLIP顶部的线性投影器和MTE顶部的浅层基于Transformer的X投影器来实现。由于用于初始化MTE的XLM-R在直接用于检索任务时表现不佳,在执行TriKD之前,建议通过机器翻译任务和对比损失来增强MTE,以改进token级和句子级的多语言表示。
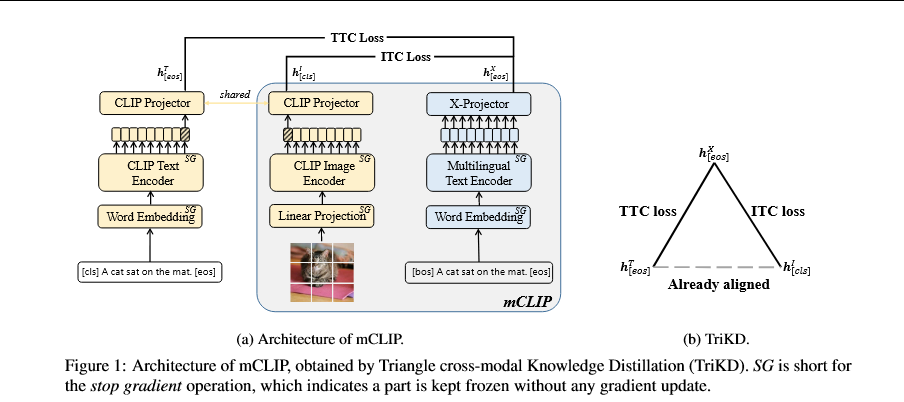
图像-文本对比损失。ITC图像到文本损失和文本到图像损失的平均值。
文本-文本对比损失。TTC损失:CLIP文本特征到XLM-R特征以及反之两个方向对比损失的平均值。
非英语图像-文本对的训练,仅应用ITC损失,因为CLIP文本编码器不支持非英语语言。
视觉变换器(ViT)被用作一种CLIP图像编码器,它将图像块作为输入并通过基于Transformer的模型生成最终特征。在图像块之前添加额外的cls令牌,其在最后一个Transformer层的输出代表图像的全局特征。
不是使用原始CLIP的英语文本编码器,而是使用具有增强token级和句子级跨语言表示的多语言编码器XLM-R。
冻结CLIP的图像和文本编码器的参数,并在它们顶部使用共享的线性投影(即CLIP投影器)。
保持XLM-R已学习的多语言性,冻结参数,并通过优化可学习的X投影器将其对齐到CLIP的多模态空间,该投影器由两个随机初始化的XLM-R Transformer层组成。
多语言文本编码器
在纯文本多语言平行语料库上,通过神经机器翻译(NMT)任务和对比学习来增强XLM-R不同语言之间用于检索任务的token级和句子级对齐。NMT解码器通过与编码器输出的token级交互生成语义等价的翻译,鼓励编码器输出保持细粒度的token级信息,在TriKD期间训练X投影器时需要,因为是基于token级输入训练的。另一方面,对比损失通过显式对齐平行句子的句子级表示来受益于跨语言迁移。
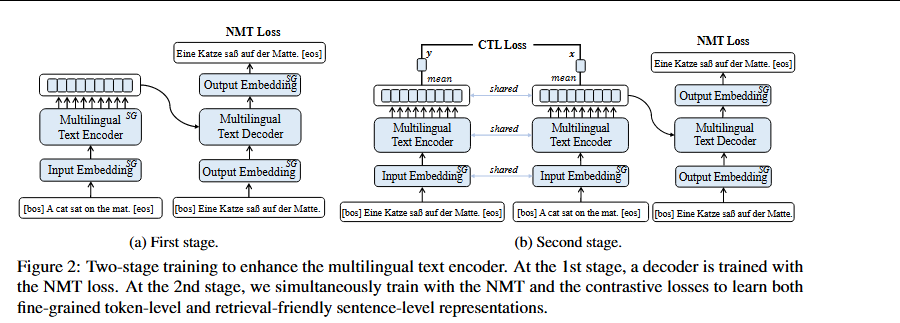
采用两阶段训练计划以避免灾难性遗忘预训练XLM-R编码器的强大多语言性。在联合训练NMT和对比损失之前。
在第一阶段在平行文本语料库上用NMT任务冻结编码器并训练该解码器(注意所有嵌入都用XLM-R初始化并始终保持固定)。
记 x i x_i xi和 y i y_i yi为一批N个配对句子中的第 i i i个源句和目标句, ∥ y i ∥ \|y_i\| ∥yi∥是句子 y i y_i yi的长度
NMT损失可公式化为:
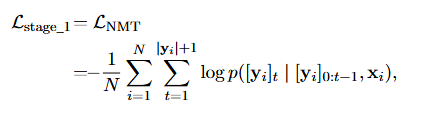
在第二阶段,用NMT和对比损失同时微调XLM-R编码器和解码器(图2b)。注意不微调嵌入,经验上没有观察到进一步的改进。
对于第 i i ii个句子对,记 h i S h_i^S hiS、 h i O h_i^O hiO为最后一个编码器层源句和目标句所有token的平均表示。记 h S = { h i S } i = 1 N h^S = \{h_i^S\}_{i=1}^N hS={hiS}i=1N,对比损失和训练损失为:
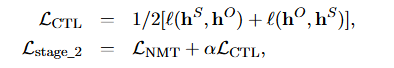
α \alpha α是平衡两个损失项的权重,在实验中设置为 α = 2.0 \alpha = 2.0 α=2.0。 ℓ ( ⋅ , ⋅ ) \ell(\cdot, \cdot) ℓ(⋅,⋅)是定义的对比损失。
在第二阶段计算对比损失时,选择所有token的平均表示作为句子级文本特征,而不是eos特征,因为前者在跨模态检索任务中经验上表现更好。推测这是因为X投影器使用来自MTE的token级输出而不是eos表示来学习图像和文本之间的对齐。
Multi30K和MSCOCO上零样本和微调的跨模态检索结果。全语言微调对于mCLIP和mCLIP+都具有最高的平均召回分数。(推测这是因为具有多种语言的图像-文本对允许投影器显式学习多语言多模态对齐,而不是依赖嵌入在MTE中的隐式多语言性。)
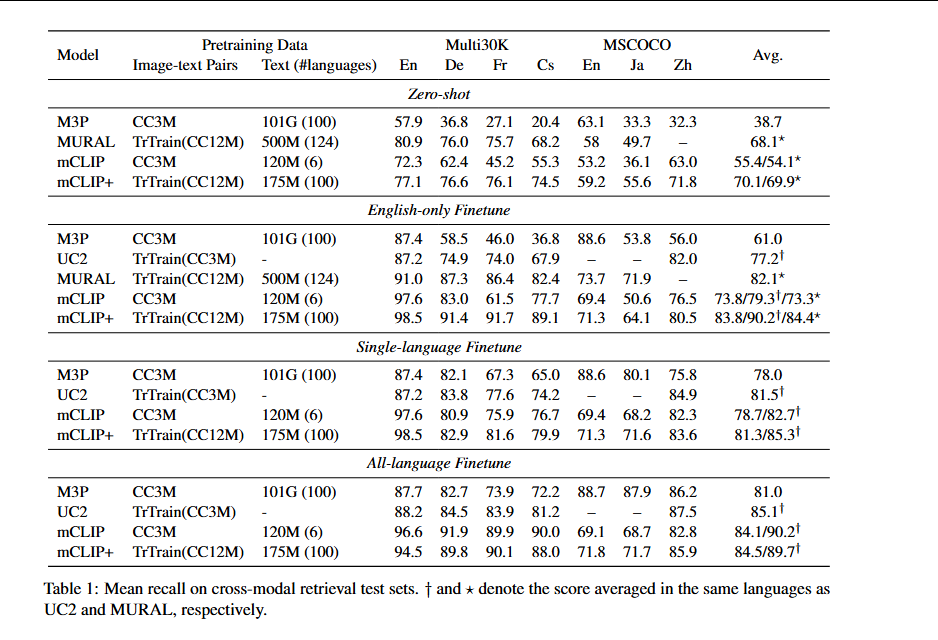
在CC3M上预训练的mCLIP进行消融研究,并报告零样本多语言图像-文本检索任务的结果。
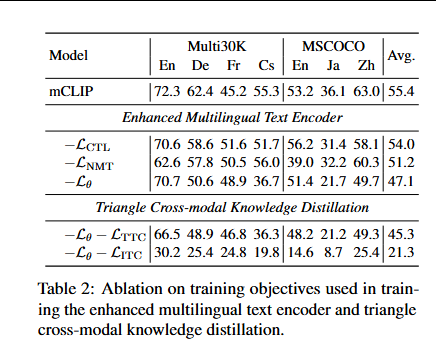
在TriKD中,图像-文本和文本-文本对比损失都对性能有积极贡献,且图像-文本对比损失 L I T C \mathcal{L}{ITC} LITC\mathcal{L}{ITC}对检索性能更为关键。在增强MTE的学习中,对比损失和NMT损失都提高了非英语语言的性能。
然而,NMT损失提高了英语图像-文本检索,而对比损失降低了它。推测是因为NMT损失允许MTE学习更细粒度的token级文本表示,并促进依赖于这些token级输入的X投影器的学习。
结论:mCLIP,一种新颖的多语言视觉-语言预训练模型,通过三角形跨模态知识蒸馏对齐CLIP和增强的多语言文本编码器。这种蒸馏方法在参数上是高效的,仅训练mCLIP总参数的3%,并且在数据上是高效的,仅需英语图像-文本对。
通过使用来自更多语言的更多平行文本语料库和来自翻译训练流程的多语言图像-文本对,可以进一步提高mCLIP的性能。实证表明,提出的mCLIP+在多语言图像-文本检索任务上达到了最先进性能。(23年)
二、实践
在多模态推荐方面,在amazon_clothing,baby,sports上跑。验证了基线模型:跑了BPR和lightGCN以及多模态的VBPR。
结果方面,在数据集上,符合相关基线模型的一般性能。
总结
在本周的工作中,学习多模态与推荐算法的结合是主线,同时关于基线模型代码实践方面的工作占据更多的时间,实验的复现与学习对以后很有帮助。