前言
早期做目标检测的人,都知道,anchor是标配,anchor尺寸是需要调整的参数之一,one-stage的检测器,yolo系列,SSD,RetinaNet都是基于anchor的,从FCOS开始,目标检测开始逐渐anchor-free,再看下,FCOS对yolo系列的进化的影响:
YOLOv1:没有 anchor,是直接回归坐标 → 严格说是 anchor-free
YOLOv2 / YOLO9000:引入 anchor 框机制 → anchor-based
YOLOv3:多尺度 anchor,基于 Darknet-53 → anchor-based
YOLOv4:改进 backbone 与 PAN,但仍使用 anchor → anchor-based
YOLOv5 (ultralytics):继续使用 anchor → anchor-based
YOLOv6 (megvii):默认 anchor-based,同时支持 anchor-free 模式 → 可配置
YOLOv7:主要 anchor-based,同时部分变体(如 E-ELAN)尝试 anchor-free 技术
YOLOv8 (ultralytics):默认 anchor-free,完全去掉 anchor → anchor-free
当读FCOS的时候,只有一句话,时尚是个轮回呀,yolov1开始的时候,就是没有anchor,那么为什么FCOS可以把anchor-free的性能做上去,这篇论文真的值得好好读一读了。
一、Anchor-based检测器
任何复杂的方法,出发点,即想要解决的问题都是直观的,因此,先理解,anchor-based的思想,以及为什么一经问世,就迅速被各大检测器应用,以及它本身的问题。
1.1、anchor-based的思想 :anchor思想最早是在faster-rcnn的RPN中被应用,论文中是这样形容RPN的:"To generate region proposals, we slide a small network over the conv feature map output by the last shared conv layer. This network is fully connected to an n × n spatial window of the input conv feature map" 。
例如使用VGG作为特征提取器,输入为224x224,那么使用con5_3作为特征层,14x14x512,作者在14x14的特征层中做了3x3的卷积,类似滑动窗,然后每个窗口提取为一维特征256维或者512维,这些特征被送入到box回归分支和类别预测分支,这些分支使用全连接层。紧接着,anchors的概念被提出,每个滑动窗口,3个尺度,3个宽高比,9个anchor。faster_rcnn作者是这样总结的,在Fast-rcnn中,目标框的回归是从任意大小的区域中提取的特征,然会所有的区域尺寸共享回归权重,但是在Faster-RCNN中,用于回归的特征,在特征图上具有相同的空间大小,为了处理变化的尺寸,设置了k个位置回归器,每个回归器负责一个尺寸和一个宽高比的回归,这里的k个,就是anchor的个数9,每个回归器权重不共享,例如在14x14x512进行回归,回归出14x14x36,每个位置上的512维特征,回归9个目标框,每个目标框4个预测值,从512变为36,就是回归的过程,权重维度 512x36,也可以理解为,这36个预测值的权重都是独立的,不共享。
1.2、anchor-based训练过程 :ahchors 和 所有的ground-truth进行匹配,正样本原则正样本(positive)1、IoU ≥ 正阈值(如 0.7);2、或者与某个 GT 的 IoU 最大的 anchor(即使 IoU 很低,也强制设为正样本)。判断完正样本后,才预测正样本与GT的offset;
1.3、anchor-based预测过程 :每个anchor都加上自己的预测的offset,得到预测的目标框位置,通过类别分数过滤误检。
1.4、anchor-based目标检测的问题:
- 依赖anchor的设计
- 正负样本严重不平衡;
- 正负样本由 IoU 阈值决定不合理,IOU不能代表学习价值;
- anchor是固定形状,GT是任意形状,anchor与目标不对齐;
二、FCOS
2.1、FCOS的结构
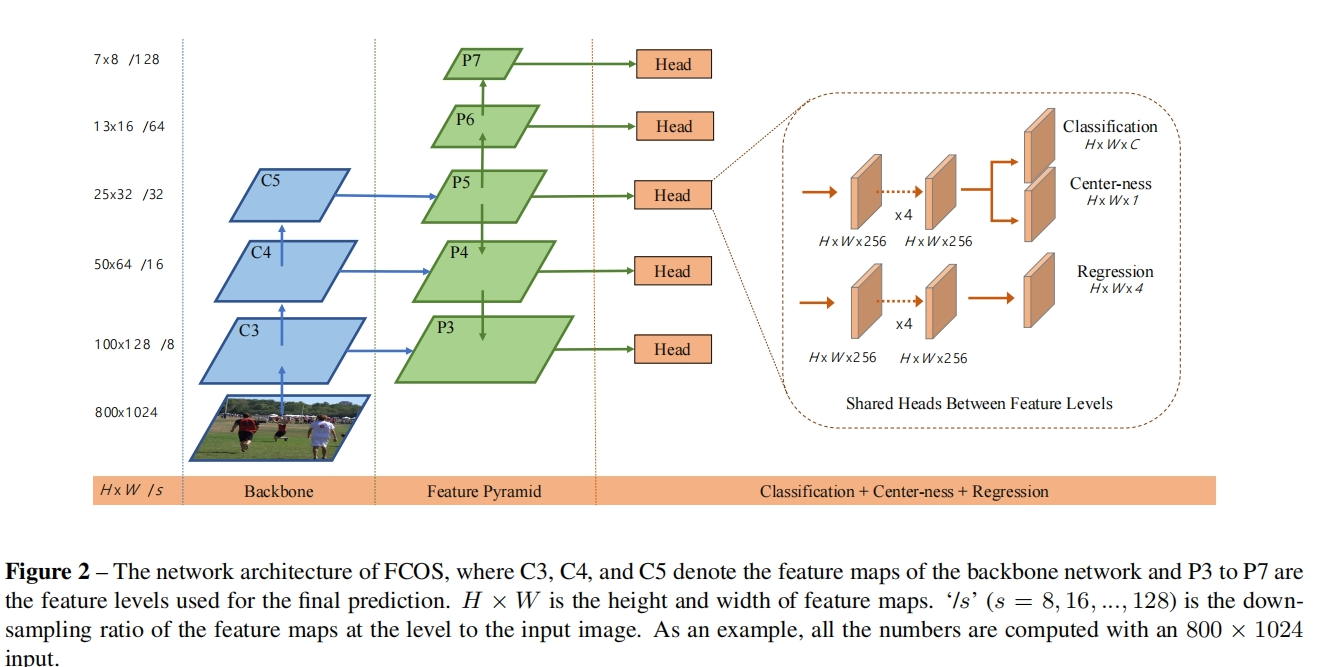
直接上FCOS的结构,基础网络FPN,输出5个特征层,每个特征层学习自己的head头,在head头里面,有两个分支,一个分支是目标狂位置的回归,一个分支用于预测类别和center-ness;需要注意,从FPN的特征层出来后,位置分支和类别分支,各自需要经历4层的卷积层,学习各自的特征,特征维度还是HxWx256。
2.2、FCOS的anchor-free
输入图片的GT框集合为{Bi},Bi=(x0(i),y0(i),x1(i),y1(i),c(i))\{B_i\},B_i=(x_0^{(i)},y_0^{(i)},x_1^{(i)},y_1^{(i)},c^{(i)}){Bi},Bi=(x0(i),y0(i),x1(i),y1(i),c(i)),对于特征图FiF_iFi上的每个位置(x,y)(x,y)(x,y),可以映射到原图位置(s/2+xs,s/2+ys)(s/2 + xs, s/2 + ys)(s/2+xs,s/2+ys),和anchors-based不同的是,FCOS在位置(x,y)(x,y)(x,y)上直接回归目标框,这个类似基于FCN的语义分割,像素级别的预测。
正样本判断标准:如果位置(x,y)(x,y)(x,y)落入到GT框中,并且类别是真实类别,这个位置被判定为正样本;
FCOS回归的是t∗=(l∗,t∗,r∗,b∗)t^* = (l^*, t^*, r^*, b^*)t∗=(l∗,t∗,r∗,b∗),t∗t^*t∗是位置(x,y)(x,y)(x,y)距离GT框左上角和右下角的距离。
当然,位置(x,y)(x,y)(x,y)有可能会落入多个GT框中,选择最小面积GT框作为回归目标。
2.3、FCOS的anchor-free与yolov1的anchor-free