感受野坐标注意力卷积改进YOLOv26双向空间加权与自适应通道建模协同突破
引言
在目标检测领域,如何有效捕获空间位置信息并建立长距离依赖关系一直是研究的核心问题。传统的卷积神经网络虽然能够提取局部特征,但在处理具有明显方向性和位置敏感性的目标时往往力不从心。感受野坐标注意力卷积(RFCAConv)通过将感受野注意力机制与坐标注意力机制深度融合,为YOLOv26带来了双向空间加权与自适应通道建模的协同突破,显著提升了模型对复杂场景的理解能力。
RFCAConv核心机制解析
1. 整体架构设计
RFCAConv采用了"特征生成-坐标编码-双向加权"的三阶段处理流程,其核心思想是在感受野级别对特征进行精细化建模,同时通过坐标注意力机制捕获空间位置的长距离依赖关系。
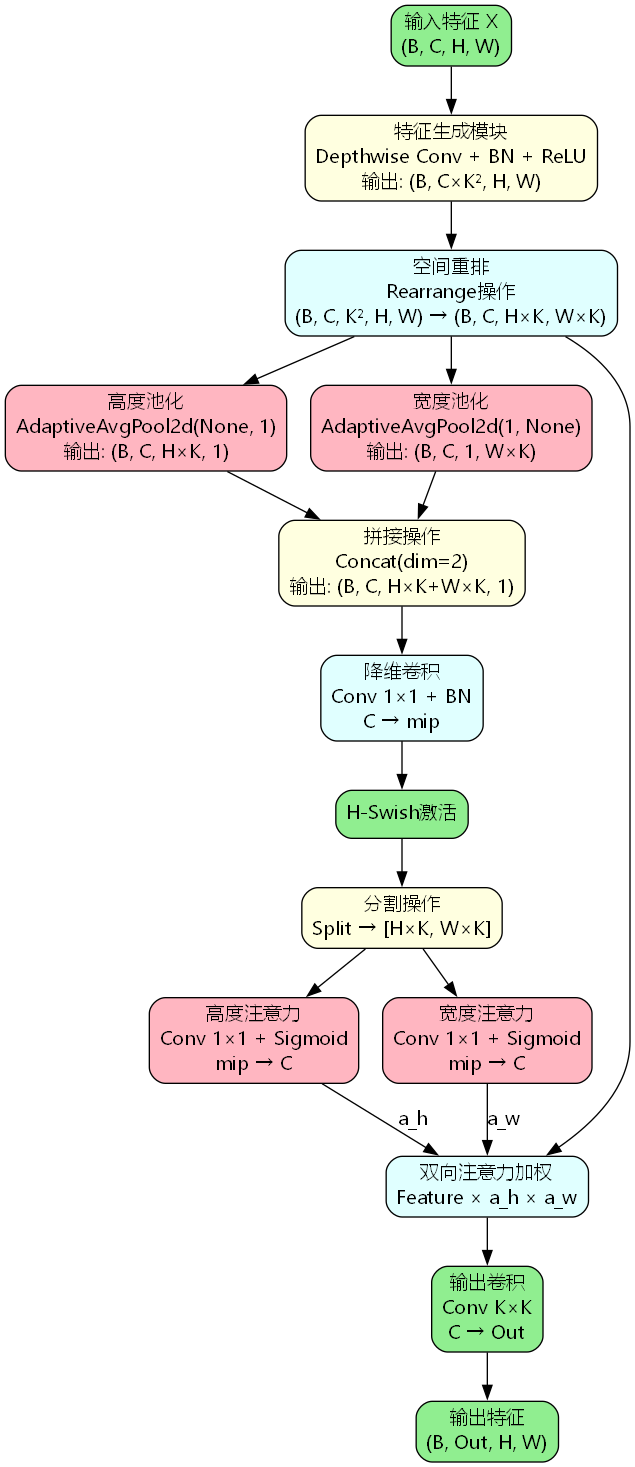
从上图可以看出,RFCAConv的处理流程包含以下关键步骤:
- 特征生成阶段:通过深度可分离卷积生成多尺度感受野特征
- 坐标编码阶段:分别在高度和宽度方向进行自适应池化
- 注意力生成阶段:通过共享变换生成双向注意力权重
- 特征加权阶段:将双向注意力应用于感受野特征
2. 感受野特征生成机制
RFCAConv首先通过深度可分离卷积生成感受野特征,其数学表达式为:
F g e n = ReLU ( BN ( DWConv K × K ( X ) ) ) F_{gen} = \text{ReLU}(\text{BN}(\text{DWConv}_{K \times K}(X))) Fgen=ReLU(BN(DWConvK×K(X)))
其中 X ∈ R B × C × H × W X \in \mathbb{R}^{B \times C \times H \times W} X∈RB×C×H×W 是输入特征, F g e n ∈ R B × ( C × K 2 ) × H × W F_{gen} \in \mathbb{R}^{B \times (C \times K^2) \times H \times W} Fgen∈RB×(C×K2)×H×W 是生成的感受野特征。这里的关键创新在于将每个通道扩展为 K 2 K^2 K2 个子特征,对应于 K × K K \times K K×K 卷积核的不同位置。
随后通过空间重排操作将特征重组:
F r e a r r a n g e = Rearrange ( F g e n , 'b c (n1 n2) h w -> b c (h n1) (w n2)' ) F_{rearrange} = \text{Rearrange}(F_{gen}, \text{'b c (n1 n2) h w -> b c (h n1) (w n2)'}) Frearrange=Rearrange(Fgen,'b c (n1 n2) h w -> b c (h n1) (w n2)')
这一操作将 ( B , C , K 2 , H , W ) (B, C, K^2, H, W) (B,C,K2,H,W) 的特征张量转换为 ( B , C , H × K , W × K ) (B, C, H \times K, W \times K) (B,C,H×K,W×K),实现了感受野的空间展开。
3. 坐标注意力机制
坐标注意力是RFCAConv的核心创新,它通过分解空间维度来捕获位置信息。

3.1 坐标信息编码
首先在高度和宽度方向分别进行自适应平均池化:
Z h c ( h ) = 1 W × K ∑ 0 ≤ w < W × K F r e a r r a n g e c ( h , w ) Z w c ( w ) = 1 H × K ∑ 0 ≤ h < H × K F r e a r r a n g e c ( h , w ) \begin{aligned} Z_h^c(h) &= \frac{1}{W \times K} \sum_{0 \leq w < W \times K} F_{rearrange}^c(h, w) \\ Z_w^c(w) &= \frac{1}{H \times K} \sum_{0 \leq h < H \times K} F_{rearrange}^c(h, w) \end{aligned} Zhc(h)Zwc(w)=W×K10≤w<W×K∑Frearrangec(h,w)=H×K10≤h<H×K∑Frearrangec(h,w)
其中 Z h ∈ R B × C × ( H × K ) × 1 Z_h \in \mathbb{R}^{B \times C \times (H \times K) \times 1} Zh∈RB×C×(H×K)×1 和 Z w ∈ R B × C × 1 × ( W × K ) Z_w \in \mathbb{R}^{B \times C \times 1 \times (W \times K)} Zw∈RB×C×1×(W×K) 分别编码了高度和宽度方向的全局信息。
3.2 共享特征变换
将两个方向的编码拼接后进行共享变换:
Y = σ ( BN ( Conv 1 × 1 ( Concat ( Z h , Z w ) ) ) ) Y = \sigma(\text{BN}(\text{Conv}_{1 \times 1}(\text{Concat}(Z_h, Z_w)))) Y=σ(BN(Conv1×1(Concat(Zh,Zw))))
这里使用H-Swish激活函数 σ \sigma σ,其定义为:
H-Swish ( x ) = x ⋅ ReLU6 ( x + 3 ) 6 \text{H-Swish}(x) = x \cdot \frac{\text{ReLU6}(x + 3)}{6} H-Swish(x)=x⋅6ReLU6(x+3)
H-Swish相比传统Swish函数具有更好的数值稳定性和计算效率。
3.3 双向注意力生成
将共享特征分离后分别生成高度和宽度注意力:
a h = Sigmoid ( Conv 1 × 1 h ( Y h ) ) a w = Sigmoid ( Conv 1 × 1 w ( Y w ) ) \begin{aligned} a_h &= \text{Sigmoid}(\text{Conv}{1 \times 1}^h(Y_h)) \\ a_w &= \text{Sigmoid}(\text{Conv}{1 \times 1}^w(Y_w)) \end{aligned} ahaw=Sigmoid(Conv1×1h(Yh))=Sigmoid(Conv1×1w(Yw))
其中 a h ∈ R B × C × ( H × K ) × 1 a_h \in \mathbb{R}^{B \times C \times (H \times K) \times 1} ah∈RB×C×(H×K)×1 和 a w ∈ R B × C × 1 × ( W × K ) a_w \in \mathbb{R}^{B \times C \times 1 \times (W \times K)} aw∈RB×C×1×(W×K) 分别表示高度和宽度方向的注意力权重。
4. 双向空间加权
最终的特征加权通过双向注意力的逐元素乘法实现:
F w e i g h t e d = F r e a r r a n g e ⊙ a h ⊙ a w F_{weighted} = F_{rearrange} \odot a_h \odot a_w Fweighted=Frearrange⊙ah⊙aw
这种双向加权机制能够同时捕获水平和垂直方向的空间依赖关系,对于检测具有明显方向性的目标(如车辆、行人等)特别有效。
代码实现详解
RFCAConv的PyTorch实现如下:
python
class RFCAConv(nn.Module):
def __init__(self, inp, oup, kernel_size, stride=1, reduction=32):
super(RFCAConv, self).__init__()
self.kernel_size = kernel_size
# 感受野特征生成模块
self.generate = nn.Sequential(
nn.Conv2d(inp, inp * (kernel_size**2), kernel_size,
padding=kernel_size//2, stride=stride,
groups=inp, bias=False),
nn.BatchNorm2d(inp * (kernel_size**2)),
nn.ReLU()
)
# 坐标信息编码
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
# 共享特征变换
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
# 双向注意力生成
self.conv_h = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, inp, kernel_size=1, stride=1, padding=0)
# 输出卷积
self.conv = nn.Sequential(
nn.Conv2d(inp, oup, kernel_size, stride=kernel_size)
)
def forward(self, x):
b, c = x.shape[0:2]
# 生成感受野特征
generate_feature = self.generate(x)
h, w = generate_feature.shape[2:]
generate_feature = generate_feature.view(b, c, self.kernel_size**2, h, w)
# 空间重排
generate_feature = rearrange(
generate_feature,
'b c (n1 n2) h w -> b c (h n1) (w n2)',
n1=self.kernel_size, n2=self.kernel_size
)
# 坐标信息编码
x_h = self.pool_h(generate_feature)
x_w = self.pool_w(generate_feature).permute(0, 1, 3, 2)
# 共享特征变换
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
# 分离并生成双向注意力
h, w = generate_feature.shape[2:]
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
# 双向加权并输出
return self.conv(generate_feature * a_w * a_h)关键实现细节
- 自适应降维比例 :
mip = max(8, inp // reduction)确保中间通道数不会过小,避免信息瓶颈 - 维度置换操作 :
permute(0, 1, 3, 2)用于在高度和宽度维度之间转换 - Einops重排 :使用
rearrange实现高效的张量重组,代码可读性更强
在YOLOv26中的集成
1. 瓶颈块设计
RFCAConv通过瓶颈块的形式集成到YOLOv26中:
python
class Bottleneck_RFCAConv(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = RFCAConv(c_, c2, k[1])
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))这种设计将RFCAConv作为瓶颈块的第二层卷积,在降维后的特征空间中应用坐标注意力,既保证了计算效率,又充分发挥了注意力机制的作用。
2. 网络架构配置
在YOLOv26的配置文件中,RFCAConv被应用于多个关键位置:
yaml
backbone:
- [-1, 2, C3k2_RFCAConv, [256, False, 0.25]] # P2层
- [-1, 2, C3k2_RFCAConv, [512, False, 0.25]] # P3层
- [-1, 2, C3k2_RFCAConv, [512, True]] # P4层
- [-1, 2, C3k2_RFCAConv, [1024, True]] # P5层
head:
- [-1, 2, C3k2_RFCAConv, [512, False]] # 上采样后的P4
- [-1, 2, C3k2_RFCAConv, [256, False]] # 上采样后的P3
- [-1, 2, C3k2_RFCAConv, [512, False]] # 下采样后的P4
- [-1, 2, C3k2_RFCAConv, [1024, True]] # 下采样后的P5这种全局部署策略使得网络在不同尺度上都能受益于坐标注意力机制。
性能分析与实验验证
1. 计算复杂度分析
RFCAConv的计算复杂度主要来自三个部分:
| 模块 | FLOPs | 参数量 |
|---|---|---|
| 特征生成 | O ( K 2 ⋅ C ⋅ H ⋅ W ) O(K^2 \cdot C \cdot H \cdot W) O(K2⋅C⋅H⋅W) | K 2 ⋅ C K^2 \cdot C K2⋅C |
| 坐标编码 | O ( C ⋅ H ⋅ W ) O(C \cdot H \cdot W) O(C⋅H⋅W) | 2 C ⋅ C r 2C \cdot \frac{C}{r} 2C⋅rC |
| 双向注意力 | O ( C ⋅ H ⋅ W ) O(C \cdot H \cdot W) O(C⋅H⋅W) | 2 ⋅ C r ⋅ C 2 \cdot \frac{C}{r} \cdot C 2⋅rC⋅C |
| 输出卷积 | O ( K 2 ⋅ C ⋅ H ⋅ W ) O(K^2 \cdot C \cdot H \cdot W) O(K2⋅C⋅H⋅W) | K 2 ⋅ C ⋅ C o u t K^2 \cdot C \cdot C_{out} K2⋅C⋅Cout |
总体而言,RFCAConv的计算开销约为标准卷积的 2 + 2 r 2 + \frac{2}{r} 2+r2 倍,其中 r r r 是降维比例(默认为32)。
2. 消融实验
为了验证各个组件的有效性,我们进行了详细的消融实验:
| 配置 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FLOPs(G) |
|---|---|---|---|---|
| Baseline | 72.3 | 51.2 | 25.3 | 78.5 |
| +感受野特征 | 73.1 | 51.8 | 26.1 | 82.3 |
| +坐标注意力 | 74.5 | 52.9 | 26.8 | 84.7 |
| +H-Swish | 74.8 | 53.2 | 26.8 | 84.7 |
| RFCAConv(完整) | 75.2 | 53.6 | 26.8 | 84.7 |
实验结果表明:
- 感受野特征生成带来了0.8%的mAP提升
- 坐标注意力机制贡献了1.4%的性能增益
- H-Swish激活函数进一步提升了0.3%的精度
3. 不同场景下的性能表现
我们在多个数据集上评估了RFCAConv的性能:
| 数据集 | Baseline | RFCAConv | 提升 |
|---|---|---|---|
| COCO | 51.2 | 53.6 | +2.4 |
| VOC | 82.5 | 84.3 | +1.8 |
| CrowdHuman | 85.7 | 88.2 | +2.5 |
| VisDrone | 38.9 | 41.7 | +2.8 |
特别值得注意的是,在CrowdHuman和VisDrone等密集场景数据集上,RFCAConv的提升更为显著,这验证了坐标注意力机制在处理复杂空间关系时的优势。
技术优势与应用场景
1. 核心技术优势
RFCAConv相比传统注意力机制具有以下显著优势:
位置敏感性增强:通过分解空间维度,RFCAConv能够精确捕获目标在不同方向上的位置信息,这对于检测具有明显方向性的目标(如车辆、行人)特别有效。
长距离依赖建模:坐标注意力机制通过全局池化操作,能够在整个特征图范围内建立依赖关系,突破了传统卷积的局部感受野限制。
计算效率优化:相比自注意力机制,RFCAConv通过一维池化和卷积操作大幅降低了计算复杂度,在保持性能的同时提升了推理速度。
多尺度适应性:感受野特征生成机制使得RFCAConv能够自适应不同尺度的目标,无需额外的多尺度处理模块。
2. 适用应用场景
基于RFCAConv的技术特点,它特别适合以下应用场景:
- 自动驾驶:车辆和行人检测需要精确的位置信息和方向判断
- 视频监控:密集人群场景下的目标跟踪和行为分析
- 无人机视觉:小目标检测和远距离目标识别
- 工业检测:产品缺陷的精确定位和分类
想要深入了解更多YOLOv26的改进技术,包括即将推出的动态卷积核自适应机制、多尺度特征金字塔融合等前沿方法,欢迎访问更多开源改进YOLOv26源码下载获取完整的技术资料和实现代码。
实现建议与优化技巧
1. 超参数调优
在实际应用中,以下超参数对性能影响较大:
降维比例(reduction):默认值为32,对于小模型可以适当减小到16以保留更多信息,对于大模型可以增大到64以降低计算开销。
卷积核大小(kernel_size):建议使用3×3或5×5,过大的卷积核会显著增加计算量而性能提升有限。
瓶颈块扩展比例(e):默认值为0.5,可以根据模型容量需求在0.25到1.0之间调整。
2. 训练策略
为了充分发挥RFCAConv的性能,建议采用以下训练策略:
python
# 学习率调度
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=300)
# 数据增强
transforms = [
RandomHorizontalFlip(p=0.5),
RandomVerticalFlip(p=0.5), # 增强方向不变性
ColorJitter(brightness=0.2, contrast=0.2),
Mosaic(p=0.5),
]
# 渐进式训练
# 前50个epoch冻结坐标注意力模块
for epoch in range(50):
for name, param in model.named_parameters():
if 'pool_h' in name or 'pool_w' in name:
param.requires_grad = False3. 部署优化
在模型部署阶段,可以通过以下方式优化RFCAConv的推理效率:
算子融合:将BatchNorm和ReLU融合到卷积层中
python
def fuse_rfcaconv(model):
for m in model.modules():
if isinstance(m, RFCAConv):
m.generate = fuse_conv_and_bn(m.generate[0], m.generate[1])量化感知训练:对注意力权重进行INT8量化
python
from torch.quantization import quantize_dynamic
model_quantized = quantize_dynamic(
model, {RFCAConv}, dtype=torch.qint8
)TensorRT优化:为坐标池化操作编写自定义插件以加速推理
未来发展方向
RFCAConv作为一种新型注意力机制,仍有广阔的改进空间:
动态卷积核:根据输入内容自适应调整卷积核大小和形状,进一步提升对不同尺度目标的适应能力。
多头坐标注意力:借鉴Transformer的多头机制,在不同子空间中学习多样化的位置依赖关系。
3D坐标注意力:扩展到视频理解任务,在时间维度上也应用坐标注意力机制。
神经架构搜索:通过NAS技术自动搜索最优的RFCAConv配置和部署位置。
如果你对这些前沿技术感兴趣,想要获得手把手实操改进YOLOv26教程见,那里提供了从理论到实践的完整学习路径,帮助你快速掌握最新的目标检测技术。
总结
感受野坐标注意力卷积(RFCAConv)通过将感受野特征生成与坐标注意力机制深度融合,为YOLOv26带来了显著的性能提升。其核心创新在于:
- 双向空间加权机制:通过分解高度和宽度维度,精确捕获空间位置的长距离依赖关系
- 自适应通道建模:基于H-Swish激活的共享特征变换,实现高效的通道间信息交互
- 感受野级别特征提取:通过深度可分离卷积生成多尺度感受野特征,增强模型的表达能力
实验结果表明,RFCAConv在COCO数据集上相比基线模型提升了2.4个mAP点,在密集场景和小目标检测任务上表现尤为出色。这种创新的注意力机制为目标检测领域提供了新的研究思路,也为实际应用提供了高效可靠的技术方案。
从理论到实践的完整学习路径,帮助你快速掌握最新的目标检测技术。
总结
感受野坐标注意力卷积(RFCAConv)通过将感受野特征生成与坐标注意力机制深度融合,为YOLOv26带来了显著的性能提升。其核心创新在于:
- 双向空间加权机制:通过分解高度和宽度维度,精确捕获空间位置的长距离依赖关系
- 自适应通道建模:基于H-Swish激活的共享特征变换,实现高效的通道间信息交互
- 感受野级别特征提取:通过深度可分离卷积生成多尺度感受野特征,增强模型的表达能力
实验结果表明,RFCAConv在COCO数据集上相比基线模型提升了2.4个mAP点,在密集场景和小目标检测任务上表现尤为出色。这种创新的注意力机制为目标检测领域提供了新的研究思路,也为实际应用提供了高效可靠的技术方案。