一、简要介绍LWGA
LWGA 模块及其子模块结构如下图所示(摘自论文):
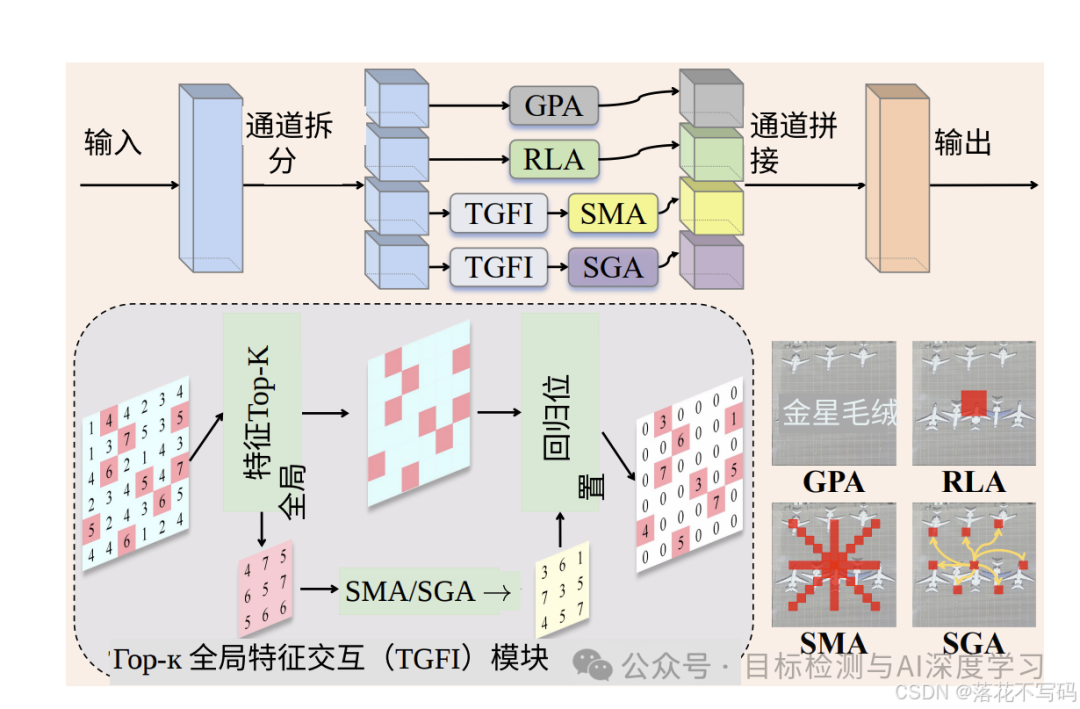
LWGANet 主要是为了解决遥感图像(RS)视觉任务中长期存在的两大痛点:"空间冗余"和"通道冗余" 。作者设计了两个创新模块 :TGFI (处理空间冗余)和 LWGA(处理通道冗余) 。
LWGA架构细节图如下(摘自论文):
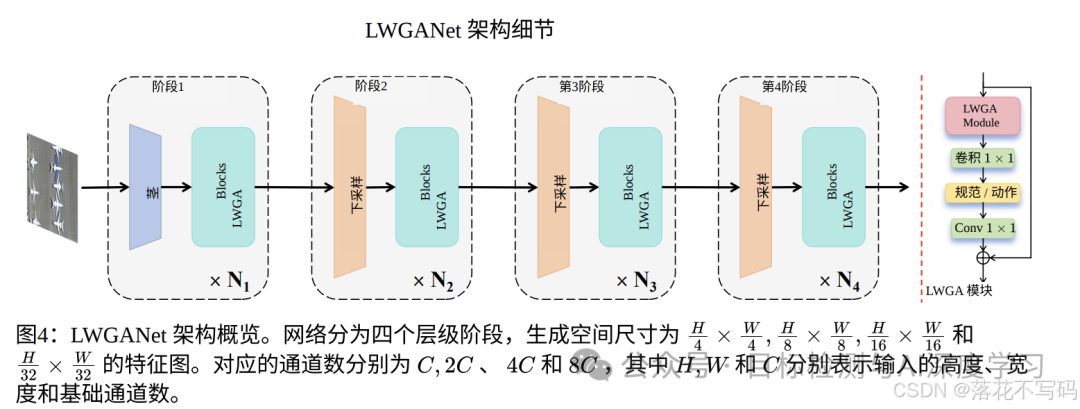
LWGA_Block 结构代码如下(最终加入YOLO的代码有变动):
python
import torch
import torch.nn as nn
from timm.layers import DropPath, trunc_normal_
from typing import List
from torch import Tensor
import os
import copy
import antialiased_cnns
import torch.nn.functional as F
from torchinfo import summary
class DRFD(nn.Module):
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.dim = dim
self.outdim = dim * 2
self.conv = nn.Conv2d(dim, dim * 2, kernel_size=3, stride=1, padding=1, groups=dim)
self.conv_c = nn.Conv2d(dim * 2, dim * 2, kernel_size=3, stride=2, padding=1, groups=dim * 2)
self.act_c = act_layer()
self.norm_c = norm_layer(dim * 2)
self.max_m = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.norm_m = norm_layer(dim * 2)
self.fusion = nn.Conv2d(dim * 4, self.outdim, kernel_size=1, stride=1)
def forward(self, x): # x = [B, C, H, W]
x = self.conv(x) # x = [B, 2C, H, W]
max = self.norm_m(self.max_m(x)) # m = [B, 2C, H/2, W/2]
conv = self.norm_c(self.act_c(self.conv_c(x))) # c = [B, 2C, H/2, W/2]
x = torch.cat([conv, max], dim=1) # x = [B, 2C+2C, H/2, W/2] --> [B, 4C, H/2, W/2]
x = self.fusion(x) # x = [B, 4C, H/2, W/2] --> [B, 2C, H/2, W/2]
return x
class PA(nn.Module):
"""
点注意力模块(PA)
"""
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.p_conv = nn.Sequential(
nn.Conv2d(dim, dim * 4, 1, bias=False),
norm_layer(dim * 4),
act_layer(),
nn.Conv2d(dim * 4, dim, 1, bias=False)
)
self.gate_fn = nn.Sigmoid()
def forward(self, x):
att = self.p_conv(x)
x = x * self.gate_fn(att)
return x
class LA(nn.Module):
"""
局部注意力模块(LA)
"""
def __init__(self, dim, norm_layer, act_layer):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1, bias=False),
norm_layer(dim),
act_layer()
)
def forward(self, x):
x = self.conv(x)
return x
class MRA(nn.Module):
"""
中程注意力模块(MRA)
"""
def __init__(self, channel, att_kernel, norm_layer):
super().__init__()
att_padding = att_kernel // 2
self.gate_fn = nn.Sigmoid()
self.channel = channel
self.max_m1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.max_m2 = antialiased_cnns.BlurPool(channel, stride=3)
self.H_att1 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att1 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.H_att2 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att2 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.norm = norm_layer(channel)
def h_transform(self, x):
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2 * shape[3] - 1)
return x
def inv_h_transform(self, x):
shape = x.size()
x = x.reshape(shape[0], shape[1], -1).contiguous()
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2 * shape[-2])
x = x[..., 0: shape[-2]]
return x
def v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2 * shape[3] - 1)
return x.permute(0, 1, 3, 2)
def inv_v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = x.reshape(shape[0], shape[1], -1)
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2 * shape[-2])
x = x[..., 0: shape[-2]]
return x.permute(0, 1, 3, 2)
def forward(self, x):
x_tem = self.max_m1(x)
x_tem = self.max_m2(x_tem)
x_h1 = self.H_att1(x_tem)
x_w1 = self.V_att1(x_tem)
x_h2 = self.inv_h_transform(self.H_att2(self.h_transform(x_tem)))
x_w2 = self.inv_v_transform(self.V_att2(self.v_transform(x_tem)))
att = self.norm(x_h1 + x_w1 + x_h2 + x_w2)
out = x[:, :self.channel, :, :] * F.interpolate(
self.gate_fn(att), size=(x.shape[-2], x.shape[-1]), mode='nearest'
)
return out
class GA12(nn.Module):
"""
全局注意力模块(GA12)
"""
def __init__(self, dim, act_layer):
super().__init__()
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0)
self.proj_1 = nn.Conv2d(dim, dim, 1)
self.activation = act_layer()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv_spatial = nn.Conv2d(dim, dim, 7, stride=1, padding=9, groups=dim, dilation=3)
self.conv1 = nn.Conv2d(dim, dim // 2, 1)
self.conv2 = nn.Conv2d(dim, dim // 2, 1)
self.conv_squeeze = nn.Conv2d(2, 2, 7, padding=3)
self.conv = nn.Conv2d(dim // 2, dim, 1)
self.proj_2 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
x_, idx = self.downpool(x) #
x_ = self.proj_1(x_)
x_ = self.activation(x_)
attn1 = self.conv0(x_)
attn2 = self.conv_spatial(attn1)
attn1 = self.conv1(attn1)
attn2 = self.conv2(attn2)
attn = torch.cat([attn1, attn2], dim=1)
avg_attn = torch.mean(attn, dim=1, keepdim=True)
max_attn, _ = torch.max(attn, dim=1, keepdim=True)
agg = torch.cat([avg_attn, max_attn], dim=1)
sig = self.conv_squeeze(agg).sigmoid()
attn = attn1 * sig[:, 0, :, :].unsqueeze(1) + attn2 * sig[:, 1, :, :].unsqueeze(1)
attn = self.conv(attn)
x_ = x_ * attn
x_ = self.proj_2(x_)
x = self.uppool(x_, indices=idx)
return x
class D_GA(nn.Module):
"""
深度全局注意力模块(D_GA)
"""
def __init__(self, dim, norm_layer):
super().__init__()
self.norm = norm_layer(dim)
self.attn = GA(dim)
self.downpool = nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)
self.uppool = nn.MaxUnpool2d((2, 2), 2, padding=0)
def forward(self, x):
x_, idx = self.downpool(x)
x = self.norm(self.attn(x_))
x = self.uppool(x, indices=idx)
return x
class GA(nn.Module):
"""
全局注意力模块(GA)
"""
def __init__(self, dim, head_dim=4, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False, **kwargs):
super().__init__()
self.head_dim = head_dim
self.scale = head_dim ** -0.5
self.num_heads = num_heads if num_heads else dim // head_dim
if self.num_heads == 0:
self.num_heads = 1
self.attention_dim = self.num_heads * self.head_dim
self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, C, H, W = x.shape
x = x.permute(0, 2, 3, 1)
N = H * W
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)
x = self.proj(x)
x = self.proj_drop(x)
x = x.permute(0, 3, 1, 2)
return x
class LWGA_Block(nn.Module):
"""
轻量化多尺度门控注意力块(LWGA_Block)
"""
def __init__(self,
dim,
stage,
att_kernel=11,
mlp_ratio=2,
drop_path=0.1,
act_layer=nn.GELU,
norm_layer=nn.BatchNorm2d
):
super().__init__()
self.stage = stage
self.dim_split = dim // 4
self.drop_path = DropPath(drop_path) if drop_path > 0.else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
mlp_layer: List[nn.Module] = [
nn.Conv2d(dim, mlp_hidden_dim, 1, bias=False),
norm_layer(mlp_hidden_dim),
act_layer(),
nn.Conv2d(mlp_hidden_dim, dim, 1, bias=False)
]
self.mlp = nn.Sequential(*mlp_layer)
self.PA = PA(self.dim_split, norm_layer, act_layer) # PA is point attention
self.LA = LA(self.dim_split, norm_layer, act_layer) # LA is local attention
self.MRA = MRA(self.dim_split, att_kernel, norm_layer) # MRA is medium-range attention
if stage == 2:
self.GA3 = D_GA(self.dim_split, norm_layer) # GA3 is global attention (stage of 3)
elif stage == 3:
self.GA4 = GA(self.dim_split) # GA4 is global attention (stage of 4)
self.norm = norm_layer(self.dim_split)
else:
self.GA12 = GA12(self.dim_split, act_layer) # GA12 is global attention (stages of 1and2)
self.norm = norm_layer(self.dim_split)
self.norm1 = norm_layer(dim)
self.drop_path = DropPath(drop_path)
def forward(self, x: Tensor) -> Tensor:
shortcut = x.clone()
x1, x2, x3, x4 = torch.split(x, [self.dim_split, self.dim_split, self.dim_split, self.dim_split], dim=1)
x1 = x1 + self.PA(x1)
x2 = self.LA(x2)
x3 = self.MRA(x3)
if self.stage == 2:
x4 = x4 + self.GA3(x4)
elif self.stage == 3:
x4 = self.norm(x4 + self.GA4(x4))
else:
x4 = self.norm(x4 + self.GA12(x4))
x_att = torch.cat((x1, x2, x3, x4), 1)
x = shortcut + self.norm1(self.drop_path(self.mlp(x_att)))
return x
class BasicStage(nn.Module):
def __init__(self,
dim,
stage,
depth,
att_kernel,
mlp_ratio,
drop_path,
norm_layer,
act_layer
):
super().__init__()
blocks_list = [
LWGA_Block(
dim=dim,
stage=stage,
att_kernel=att_kernel,
mlp_ratio=mlp_ratio,
drop_path=drop_path[i],
norm_layer=norm_layer,
act_layer=act_layer
)
for i in range(depth)
]
self.blocks = nn.Sequential(*blocks_list)
def forward(self, x: Tensor) -> Tensor:
x = self.blocks(x)
return x
class Stem(nn.Module):
def __init__(self, in_chans, stem_dim, norm_layer):
super().__init__()
self.proj = nn.Conv2d(in_chans, stem_dim, kernel_size=4, stride=4, bias=False)
if norm_layer is not None:
self.norm = norm_layer(stem_dim)
else:
self.norm = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
x = self.norm(self.proj(x))
return x
if __name__ == "__main__":
device = torch.device('cuda:0'if torch.cuda.is_available() else'cpu')
x = torch.randn(1, 64, 32, 32).to(device)
model = LWGA_Block(64, 1, 11, 2, 0.1)
model.to(device)
y = model(x)
print(y.shape)
summary(model,
input_size=(1, 64, 32, 32),
device=device,
col_names=["input_size", "output_size", "num_params", "mult_adds"],
depth=4
)二、改进步骤
第一部分:模块分析与改进方案
1. DRFD (Down-sampling Residual Fusion Device?) 模块
-
它的作用:这是一个具有双分支的下采样模块。它不仅使用步长为 2 的卷积进行下采样,还结合了 MaxPool2d 下采样,最后将两路特征拼接并融合。
-
改进 YOLO11 的位置 :替换标准的下采样卷积。
-
YOLO11 的 Backbone 和 Head 中有很多 -1, 1, Conv, \[dim, 3, 2](即 k = 3,s = 2的卷积,用于降低特征图分辨率并增加通道数。
-
可以将这些层替换为 DRFD,这样可以减少下采样过程中的信息丢失,保留更多的高频(边缘)和低频(背景)信息。
-
2. LWGA_Block (轻量化多尺度门控注意力块)
-
它的作用 :这是一个极其强大的多尺度注意力模块。它将输入通道分为 4 份,分别计算点注意力 (PA) 、局部注意力 (LA) 、中程注意力 (MRA) 和 全局注意力 (GA/GA12),然后拼接并通过 MLP 融合。
-
改进 YOLO11 的位置:
-
方案 A(替换 C2PSA):YOLO11 在 Backbone 的最后一层使用了 C2PSA(一种空间注意力模块)。可以直接用 LWGA_Block 替换 C2PSA,增强深层全局和局部特征的捕获能力。
-
方案 B(结合 CSP 结构替换 C3k2):YOLO11 大量使用 C3k2 进行特征提取。直接把 LWGA_Block 塞进去可能破坏梯度的流动。最好借鉴 YOLO 的 C2f 结构,将 LWGA_Block 封装成 C2f_LWGA 模块,然后用来替换 Backbone 或 Neck 中的 C3k2。
-
第二部分:新建 Python 脚本 (完整代码)
由于LWGA的代码中依赖了外部库 antialiased_cnns (会导致很多报错),并且一些通道和维度定义不符合 YOLO 传参习惯(YOLO 习惯传 c1, c2),所以我对代码进行了适配 YOLO 框架的重构,并去除了对第三方库的依赖(手写了一个轻量级的 BlurPool)。
在 ultralytics/nn/modules/ 目录下新建一个文件命名为 lwga_module.py,并将以下代码完整复制进去:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules.conv import Conv, autopad
# =========================================================
# 手写 BlurPool 替代 antialiased_cnns,避免第三方库依赖报错
# =========================================================
class BlurPool(nn.Module):
def __init__(self, channels, pad_type='reflect', filt_size=3, stride=2, pad_off=0):
super(BlurPool, self).__init__()
self.filt_size = filt_size
self.pad_off = pad_off
self.pad_sizes =[int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2)), int(1.*(filt_size-1)/2), int(np.ceil(1.*(filt_size-1)/2))]
self.pad_sizes =[pad_size+pad_off for pad_size in self.pad_sizes]
self.stride = stride
self.off = int((self.stride-1)/2.)
self.channels = channels
if(self.filt_size==1):
a = np.array([1.,])
elif(self.filt_size==2):
a = np.array([1., 1.])
elif(self.filt_size==3):
a = np.array([1., 2., 1.])
elif(self.filt_size==4):
a = np.array([1., 3., 3., 1.])
elif(self.filt_size==5):
a = np.array([1., 4., 6., 4., 1.])
elif(self.filt_size==6):
a = np.array([1., 5., 10., 10., 5., 1.])
elif(self.filt_size==7):
a = np.array([1., 6., 15., 20., 15., 6., 1.])
filt = torch.Tensor(a[:,None]*a[None,:])
filt = filt/torch.sum(filt)
self.register_buffer('filt', filt[None,None,:,:].repeat((self.channels,1,1,1)))
self.pad = nn.ReflectionPad2d(self.pad_sizes)
def forward(self, inp):
if(self.filt_size==1):
if(self.pad_off==0):
return inp[:,:,::self.stride,::self.stride]
else:
return self.pad(inp)[:,:,::self.stride,::self.stride]
else:
return F.conv2d(self.pad(inp), self.filt, stride=self.stride, groups=inp.shape[1])
import numpy as np # 需在文件顶部导入 numpy
# =========================================================
# 1. DRFD 下采样模块 (已适配 YOLO 的 c1, c2 格式)
# =========================================================
class DRFD(nn.Module):
def __init__(self, c1, c2, k=3, s=2, p=1):
super().__init__()
# 为了兼容 c1 -> c2,先进行通道调整,再下采样
self.conv = Conv(c1, c2, k=1, s=1) # 1x1调整通道
self.conv_c = Conv(c2, c2, k=k, s=s) # 卷积下采样
self.max_m = nn.MaxPool2d(kernel_size=k, stride=s, padding=autopad(k, p))
self.norm_m = nn.BatchNorm2d(c2)
self.fusion = Conv(c2 * 2, c2, k=1, s=1) # 融合分支
def forward(self, x):
x = self.conv(x)
max_branch = self.norm_m(self.max_m(x))
conv_branch = self.conv_c(x)
x = torch.cat([conv_branch, max_branch], dim=1)
x = self.fusion(x)
return x
# =========================================================
# 2. 多尺度注意力组件 (PA, LA, MRA, GA)
# =========================================================
class PA(nn.Module):
def __init__(self, dim):
super().__init__()
self.p_conv = nn.Sequential(
nn.Conv2d(dim, dim * 4, 1, bias=False),
nn.BatchNorm2d(dim * 4),
nn.SiLU(),
nn.Conv2d(dim * 4, dim, 1, bias=False)
)
self.gate_fn = nn.Sigmoid()
def forward(self, x):
att = self.p_conv(x)
return x * self.gate_fn(att)
class LA(nn.Module):
def __init__(self, dim):
super().__init__()
self.conv = Conv(dim, dim, k=3, s=1)
def forward(self, x):
return self.conv(x)
class MRA(nn.Module):
def __init__(self, channel, att_kernel=11):
super().__init__()
att_padding = att_kernel // 2
self.gate_fn = nn.Sigmoid()
self.channel = channel
self.max_m1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.max_m2 = BlurPool(channel, stride=3)
self.H_att1 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att1 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.H_att2 = nn.Conv2d(channel, channel, (att_kernel, 3), 1, (att_padding, 1), groups=channel, bias=False)
self.V_att2 = nn.Conv2d(channel, channel, (3, att_kernel), 1, (1, att_padding), groups=channel, bias=False)
self.norm = nn.BatchNorm2d(channel)
def h_transform(self, x):
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2 * shape[3] - 1)
return x
def inv_h_transform(self, x):
shape = x.size()
x = x.reshape(shape[0], shape[1], -1).contiguous()
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2 * shape[-2])
x = x[..., 0: shape[-2]]
return x
def v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = torch.nn.functional.pad(x, (0, shape[-1]))
x = x.reshape(shape[0], shape[1], -1)[..., :-shape[-1]]
x = x.reshape(shape[0], shape[1], shape[2], 2 * shape[3] - 1)
return x.permute(0, 1, 3, 2)
def inv_v_transform(self, x):
x = x.permute(0, 1, 3, 2)
shape = x.size()
x = x.reshape(shape[0], shape[1], -1)
x = torch.nn.functional.pad(x, (0, shape[-2]))
x = x.reshape(shape[0], shape[1], shape[-2], 2 * shape[-2])
x = x[..., 0: shape[-2]]
return x.permute(0, 1, 3, 2)
def forward(self, x):
x_tem = self.max_m1(x)
x_tem = self.max_m2(x_tem)
x_h1 = self.H_att1(x_tem)
x_w1 = self.V_att1(x_tem)
x_h2 = self.inv_h_transform(self.H_att2(self.h_transform(x_tem)))
x_w2 = self.inv_v_transform(self.V_att2(self.v_transform(x_tem)))
att = self.norm(x_h1 + x_w1 + x_h2 + x_w2)
out = x[:, :self.channel, :, :] * F.interpolate(
self.gate_fn(att), size=(x.shape[-2], x.shape[-1]), mode='nearest'
)
return out
class GA(nn.Module):
def __init__(self, dim, head_dim=4):
super().__init__()
self.head_dim = head_dim
self.scale = head_dim ** -0.5
self.num_heads = max(1, dim // head_dim)
self.attention_dim = self.num_heads * self.head_dim
self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=False)
self.proj = nn.Linear(self.attention_dim, dim, bias=False)
def forward(self, x):
B, C, H, W = x.shape
x_perm = x.permute(0, 2, 3, 1)
N = H * W
qkv = self.qkv(x_perm).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x_out = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim)
x_out = self.proj(x_out).permute(0, 3, 1, 2)
return x_out
# =========================================================
# 3. 核心块:LWGA_Block
# =========================================================
class LWGA_Block(nn.Module):
def __init__(self, c1, c2, stage=3, att_kernel=11, mlp_ratio=2):
super().__init__()
# 为防止 c2 无法被 4 整除,调整通道
self.c = c2
self.dim_split = c2 // 4
self.rem = c2 % 4
# 统一维度
if c1 != c2:
self.align = Conv(c1, c2, 1, 1)
else:
self.align = nn.Identity()
mlp_hidden_dim = int(c2 * mlp_ratio)
self.mlp = nn.Sequential(
nn.Conv2d(c2, mlp_hidden_dim, 1, bias=False),
nn.BatchNorm2d(mlp_hidden_dim),
nn.SiLU(),
nn.Conv2d(mlp_hidden_dim, c2, 1, bias=False)
)
self.PA = PA(self.dim_split)
self.LA = LA(self.dim_split)
self.MRA = MRA(self.dim_split, att_kernel)
self.GA = GA(self.dim_split + self.rem)
self.norm_ga = nn.BatchNorm2d(self.dim_split + self.rem)
self.norm1 = nn.BatchNorm2d(c2)
def forward(self, x):
x = self.align(x)
shortcut = x
# 按照 1:1:1:1+余数 划分通道
split_sizes =[self.dim_split, self.dim_split, self.dim_split, self.dim_split + self.rem]
x1, x2, x3, x4 = torch.split(x, split_sizes, dim=1)
x1 = x1 + self.PA(x1)
x2 = self.LA(x2)
x3 = self.MRA(x3)
x4 = self.norm_ga(x4 + self.GA(x4))
x_att = torch.cat((x1, x2, x3, x4), 1)
out = shortcut + self.norm1(self.mlp(x_att))
return out
# =========================================================
# 4. CSP 封装版本 (为了完美替换 C3k2)
# =========================================================
class C2f_LWGA(nn.Module):
"""CSP Bottleneck with 2 convolutions and LWGA Block"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(LWGA_Block(self.c, self.c) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))第三部分:将模块注册到 Ultralytics 中
打开 ultralytics/nn/modules/init.py,在文件中添加导入:
python
# 找到这里类似的代码并加上
from .lwga_module import DRFD, LWGA_Block, C2f_LWGA
__all__ = (
..., # 原本的代码
"DRFD",
"LWGA_Block",
"C2f_LWGA"
)第四部分:修改 task.py文件
为了让自定义模块(DRFD, LWGA_Block, C2f_LWGA)能够被 YOLO 的引擎正确识别和组装,我们需要在 tasks.py 中进行 3 处修改。
第一步:将模块导入到 tasks.py 中
原理解释:在 tasks.py 解析 YAML 文件时,它会读取模块名称(比如 "DRFD"),然后通过 globals()m 去寻找对应的 Python 类。因此,我们必须先在文件开头把这三个类导入进来。
找到 tasks.py 文件开头的 from ultralytics.nn.modules import (...) 部分,在其中加入你的模块:
python
# 找到类似这样的代码块(大约 12 行附近)
from ultralytics.nn.modules import (
AIFI,
C1,
C2,
C2PSA,
C3,
C3TR,
ELAN1,
# ... 省略中间代码 ...
WorldDetect,
YOLOEDetect,
YOLOESegment,
v10Detect,
# === 👇 新增的模块 👇 ===
DRFD,
LWGA_Block,
C2f_LWGA,
# === 👆 新增的模块 👆 ===
)第二步:将模块注册到 base_modules 中(核心通道推导逻辑)
原理解释 :
在 parse_model 函数中,有一个集合叫 base_modules。如果改进的模块在这个集合里,YOLO 的解析引擎会自动帮你处理 输入通道 (c1) 和 输出通道 (c2) 。
在上一轮封装的代码中,所有的模块定义都满足 init(self, c1, c2, ...) 的格式,所以必须将它们加入 base_modules,这样模型在构建时才能正确地拼接每一层的通道数。
修改方法 :
向下滚动,找到 parse_model 函数,在里面找到 base_modules = frozenset({...}),把这 3 个模块加进去:
python
base_modules = frozenset(
{
Classify,
......这里省略掉
A2C2f,
# === 👇 新增的模块 👇 ===
DRFD,
LWGA_Block,
C2f_LWGA,
# === 👆 新增的模块 👆 ===
}
)第三步:将 C2f_LWGA 注册到 repeat_modules 中(控制模块深度/重复次数)
原理解释 :
在 YOLO 的 YAML 配置文件中,有一列参数是 repeats(也就是 n,比如 -1, 3, C2f, \[128] 里的 3)。
-
对于普通的模块(比如 DRFD 或普通的 Conv),如果 n=3,YOLO 会在外部生成一个包裹了 3 个该模块的 nn.Sequential。
-
但对于类似 C2f 这样的核心提取网络,为了性能和结构特征,它们在模块内部自身消化了 n 参数 (例如我们在 C2f_LWGA 代码中写了 self.m = nn.ModuleList(LWGA_Block(...) for _ in range(n)))。
因此,必须告诉解析器哪些模块自带 n 属性,将其加入到 repeat_modules 集合中。注意:这里只需要加 C2f_LWGA,不需要加 DRFD 和 LWGA_Block。
修改方法 :
紧接着 base_modules 下方,找到 repeat_modules = frozenset({...})(,在其中加入 C2f_LWGA:
python
repeat_modules = frozenset( # modules with 'repeat' arguments
{
BottleneckCSP,
......这里省略掉
A2C2f,
# === 👇 新增带有内部重复参数的模块 👇 ===
C2f_LWGA,
# === 👆 新增的模块 👆 ===
}
)第五部分:修改 YOLO11 YAML 配置文件
现在改进的模块已经可以在配置文件中调用了。以下是设计的两种改进版本的 yolo11.yaml 配置文件,可以根据实际训练效果进行选择。
改进方案一:极致下采样版(使用 DRFD 替换步长卷积,并引入全局注意力 C2PSA -> LWGA_Block)
这个版本用 DRFD 替换了 Backbone 的特征下采样,减少池化带来的像素丢失,同时在主干末端使用 LWGA_Block 提取多尺度感知特征。
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11-DRFD-LWGA
nc: 1 # number of classes
scales:
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
backbone:
#[from, repeats, module, args]
- [-1, 1, Conv,[64, 3, 2]] # 0-P1/2
- [-1, 1, DRFD,[128]] # 1-P2/4 (使用 DRFD 下采样)
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, DRFD, [256]] # 3-P3/8 (使用 DRFD 下采样)
- [-1, 2, C3k2,[512, False, 0.25]]
- [-1, 1, DRFD,[512]] # 5-P4/16 (使用 DRFD 下采样)
- [-1, 2, C3k2, [512, True]]
- [-1, 1, DRFD, [1024]] # 7-P5/32 (使用 DRFD 下采样)
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, LWGA_Block, [1024]] # 10 (原 C2PSA 替换为 LWGA_Block 多尺度注意力)
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, DRFD, [256]] # 17 (Head 中同样使用 DRFD 下采样)
- [[-1, 13], 1, Concat,[1]] # cat head P4
- [-1, 2, C3k2,[512, False]] # 19 (P4/16-medium)
- [-1, 1, DRFD, [512]] # 20 (Head 中同样使用 DRFD 下采样)
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)改进方案二:深层特征提取版(使用 C2f_LWGA 替换深层 C3k2)
这个版本保留了原本的卷积下采样,但将深层特征提取的模块替换为了结合 CSP 结构的 C2f_LWGA,专注于提高模型对复杂特征的识别能力。
python
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11-LWGA-Feature
nc: 1
scales:
n: [0.50, 0.25, 1024]
s: [0.50, 0.50, 1024]
m: [0.50, 1.00, 512]
l: [1.00, 1.00, 512]
x: [1.00, 1.50, 512]
backbone:
- [-1, 1, Conv,[64, 3, 2]] # 0-P1/2
- [-1, 1, Conv,[128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2,[512, False, 0.25]]
- [-1, 1, Conv,[512, 3, 2]] # 5-P4/16
- [-1, 2, C2f_LWGA, [512]] # 6 用 C2f_LWGA 替换深层特征提取
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C2f_LWGA, [1024]] # 8 用 C2f_LWGA 替换深层特征提取
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]]
- [-1, 2, C2f_LWGA, [512]] # 13 颈部特征融合也采用 LWGA
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]]
- [-1, 2, C3k2, [256, False]] # 16
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]]
- [-1, 2, C2f_LWGA, [512]] # 19
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]]
- [-1, 2, C2f_LWGA, [1024]] # 22
- [[16, 19, 22], 1, Detect, [nc]]三、模型训练
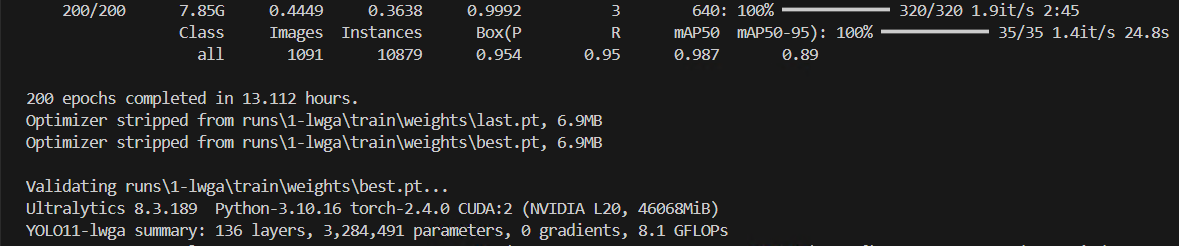
在我的数据集上,模型训练之后的Precision从0.945提升至0.954,但是模型的参数量和GFLOPs增加

如果有想法改进YOLO(比如想引入一个模块用于改进某个模块),但是自己不懂代码不会改进的可以联系我,我可以远程教学,需要的可以联系我