YOLO26 完整学习笔记:从 Anchor-Free、TAL、STAL 到端到端无 NMS 部署
面向目标检测学习、源码阅读与工程部署的系统笔记
整理日期:2026-06-08
主要依据:Ultralytics 官方论文、官方文档与
ultralytics仓库当前main分支论文版本:arXiv v1,2026-06-02 发布,尚不能等同于经过同行评审的正式会议版本
目录
- [0. 阅读前说明](#0. 阅读前说明)
- [1. YOLO26 是什么](#1. YOLO26 是什么)
- [2. 官方论文、文档与源码入口](#2. 官方论文、文档与源码入口)
- [3. YOLO 系列演进:YOLO26 创新点从哪里来](#3. YOLO 系列演进:YOLO26 创新点从哪里来)
- [4. YOLO26 整体结构](#4. YOLO26 整体结构)
- [5. Anchor-Free 到底是什么意思](#5. Anchor-Free 到底是什么意思)
- [6. YOLO11 中的 TAL 标签分配](#6. YOLO11 中的 TAL 标签分配)
- [7. YOLO26 的 STAL:为什么小目标需要特殊处理](#7. YOLO26 的 STAL:为什么小目标需要特殊处理)
- [8. 去掉 DFL 后发生了什么](#8. 去掉 DFL 后发生了什么)
- [9. YOLO26 的损失函数](#9. YOLO26 的损失函数)
- [10. 双头结构:O2M 与 O2O](#10. 双头结构:O2M 与 O2O)
- [11. 为什么最终输出是
(N, 300, 6)](#11. 为什么最终输出是 (N, 300, 6)) - [12. YOLO26 默认端到端后处理](#12. YOLO26 默认端到端后处理)
- [13. 与 YOLOv8、YOLO11、YOLOv10 的对比](#13. 与 YOLOv8、YOLO11、YOLOv10 的对比)
- [14. MuSGD 与 Progressive Loss](#14. MuSGD 与 Progressive Loss)
- [15. 多任务扩展](#15. 多任务扩展)
- [16. 官方实验结果与消融实验](#16. 官方实验结果与消融实验)
- [17. 训练、验证、推理与导出示例](#17. 训练、验证、推理与导出示例)
- [18. ONNX Runtime 与 C++ 部署思路](#18. ONNX Runtime 与 C++ 部署思路)
- [19. RKNN 等后端的特殊注意事项](#19. RKNN 等后端的特殊注意事项)
- [20. 推荐的源码阅读顺序](#20. 推荐的源码阅读顺序)
- [21. 常见误区与问答](#21. 常见误区与问答)
- [22. 一页纸总结](#22. 一页纸总结)
- [附录 A:关键源码索引](#附录 A:关键源码索引)
- [附录 B:进一步阅读](#附录 B:进一步阅读)
0. 阅读前说明
这份笔记重点讲 Ultralytics YOLO26。官方论文标题是:
Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models
请注意以下三点:
- 官方通常写作 YOLO26,不必强行写成 "YOLOv26"。
- YOLO 家族并不是从 YOLOv1 到 YOLO26 始终由同一团队线性开发。多个版本来自不同团队和不同代码路线。
- Ultralytics 仓库的
main分支会持续更新。本笔记引用的是 2026-06-08 前后可访问到的当前实现 。如果需要严格复现实验,应固定具体 release、tag 或 commit,而不是永远追踪main。
本文首先讲普通目标检测,再补充实例分割、Pose、OBB 与 YOLOE-26。
1. YOLO26 是什么
YOLO26 是 Ultralytics 推出的统一实时视觉模型家族。它覆盖:
- 目标检测 Object Detection
- 实例分割 Instance Segmentation
- 图像分类 Classification
- 姿态估计 Pose Estimation
- 旋转框检测 Oriented Bounding Box,OBB
- 开放词汇检测与分割 YOLOE-26
YOLO26 的检测器在 YOLO11 风格骨架基础上,围绕 端到端部署 做了一整套协同设计:
- 默认启用 One-to-One 端到端检测路径
- 默认推理不依赖外部 NMS
- 保留 One-to-Many 传统路径作为兼容与精度优先选项
- 去掉 DFL,改为直接边界框回归
- 用 STAL 改善极小目标的标签分配
- 用 Progressive Loss 调整双分支训练权重
- 用 MuSGD 改善训练优化效率
一句话概括:
YOLO26 并不是单纯把 YOLO11 的骨干网络换几个模块,而是把检测头、标签分配、框回归、损失调度、优化器和部署路径重新协调起来,让默认无 NMS 推理真正可用。
2. 官方论文、文档与源码入口
2.1 原论文
- arXiv 摘要页:https://arxiv.org/abs/2606.03748
- arXiv HTML 全文:https://arxiv.org/html/2606.03748v1
- arXiv PDF:https://arxiv.org/pdf/2606.03748
论文信息:
| 项目 | 内容 |
|---|---|
| 标题 | Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models |
| 作者 | Glenn Jocher, Jing Qiu, Mengyu Liu, Shuai Lyu, Fatih Cagatay Akyon, Muhammet Esat Kalfaoglu |
| 版本 | arXiv:2606.03748v1 |
| 日期 | 2026-06-02 |
| 许可证 | CC BY 4.0 |
2.2 官方文档
- YOLO26 模型文档:https://docs.ultralytics.com/models/yolo26/
- 端到端检测迁移指南:https://docs.ultralytics.com/guides/end2end-detection/
- Loss 源码参考文档:https://docs.ultralytics.com/reference/utils/loss/
- TAL 源码参考文档:https://docs.ultralytics.com/reference/utils/tal/
2.3 官方仓库
- Ultralytics 主仓库:https://github.com/ultralytics/ultralytics
建议重点阅读以下文件:
| 文件 | 重点内容 |
|---|---|
ultralytics/cfg/models/26/yolo26.yaml |
YOLO26 网络结构;end2end: True;reg_max: 1 |
ultralytics/nn/modules/head.py |
Detect Head;O2M/O2O;框解码;Top-K 后处理;max_det=300 |
ultralytics/utils/loss.py |
CIoU、BCE、DFL/L1 分支、E2ELoss、Progressive Loss |
ultralytics/utils/tal.py |
Anchor Point 生成;TAL;STAL;冲突消解;dist2bbox |
ultralytics/optim/muon.py |
MuSGD 优化器 |
3. YOLO 系列演进:YOLO26 创新点从哪里来
3.1 不要把 YOLO 家族理解成单线升级
YOLO 的共同精神是:
用尽可能直接、快速的网络完成实时目标检测。
但不同版本由不同团队推动,路线并不完全一致。YOLO26 中很多设计都有前史:
| 版本或路线 | 代表性贡献 | 与 YOLO26 的关系 |
|---|---|---|
| YOLOv1 | 把检测统一为单次前向的回归问题 | YOLO 家族的实时检测起点 |
| YOLOv2 / YOLO9000 | Anchor Box、多尺度训练、联合训练 | 典型 Anchor-Based 思路 |
| YOLOv3 | Darknet-53、多尺度预测 | P3/P4/P5 多尺度检测的经典来源 |
| YOLOv4 | CSP、SPP、PAN、Mosaic 等工程组合 | 强调训练与部署平衡 |
| YOLOv5 | 工程生态、训练与导出体验成熟 | 工程化路线的重要节点 |
| YOLOX | Anchor-Free、解耦头、SimOTA | 推动 Anchor-Free YOLO 普及 |
| YOLOv8 | Ultralytics Anchor-Free、TAL、DFL | YOLO11 与 YOLO26 的重要前置路线 |
| YOLOv10 | 双标签分配、端到端无 NMS 检测 | YOLO26 O2M/O2O 双路径的重要前身 |
| YOLO11 | 更高效的共享骨架、多任务体系 | YOLO26 明确建立在 YOLO11 family 之上 |
| YOLO26 | DFL-Free、STAL、Progressive Loss、MuSGD、默认 O2O | 面向端到端部署的整套协同升级 |
3.2 YOLO26 相比 YOLO11 的主要创新
论文明确将以下组件列为 YOLO26 检测部分的核心:
| 组件 | 作用 |
|---|---|
| Dual Head | 同时支持 O2O 端到端路径与 O2M 传统路径 |
reg_max=1 Direct Regression |
去掉 DFL,直接预测边界框距离 |
| STAL | 为极小目标保留候选 Anchor Point |
| Progressive Loss | 随训练推进逐渐重视 O2O 分支 |
| MuSGD | 改善优化效率与收敛表现 |
4. YOLO26 整体结构
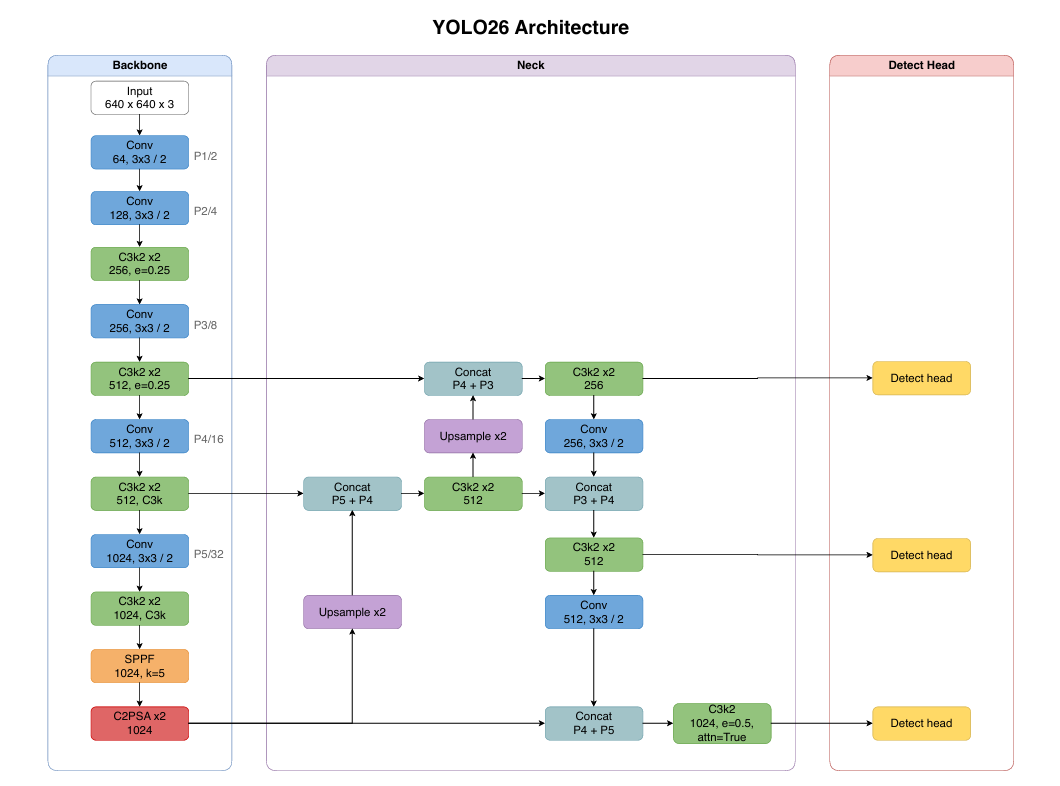
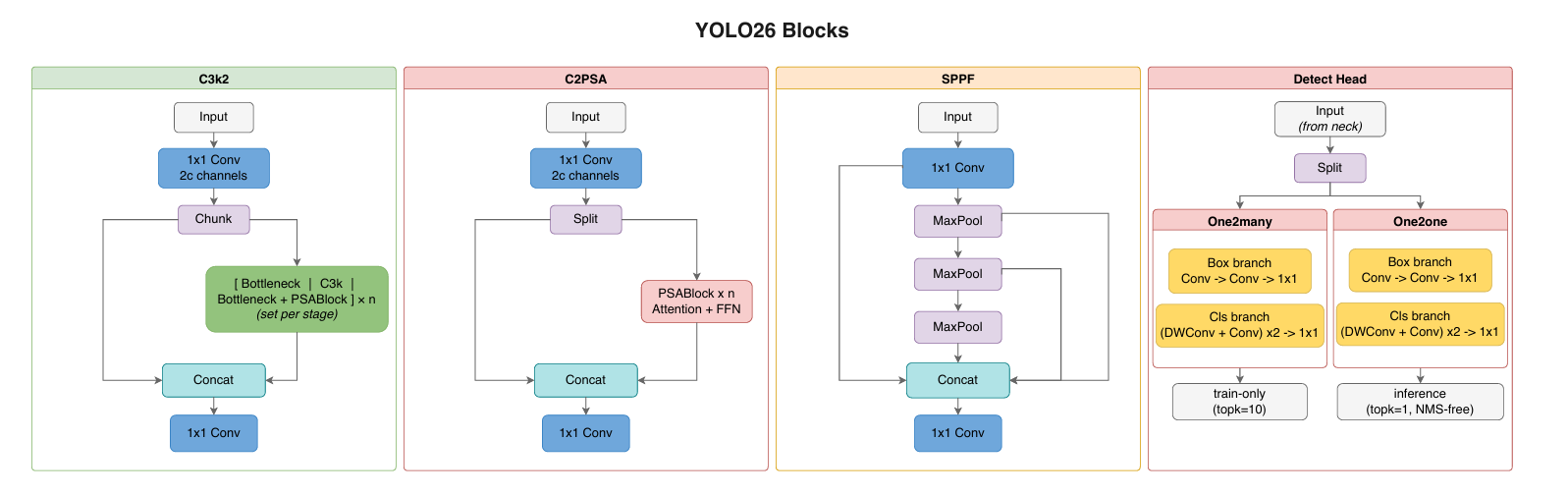
4.1 宏观结构
YOLO26 仍然是典型的 YOLO 风格 CNN 检测器:
text
输入图像
↓
Backbone:提取多尺度语义特征
↓
Neck:融合浅层位置细节与深层语义
↓
P3 / P4 / P5 多尺度特征图
↓
训练时:O2M Head + O2O Head 同时工作
↓
默认推理时:只使用 O2O Head
↓
框解码 + Top-K
↓
最多 300 个最终候选结果4.2 YAML 中的关键配置
官方 YAML 中最值得先看的两行:
yaml
end2end: True
reg_max: 1它们分别表示:
- 默认启用端到端模式
- 回归头的
reg_max=1,因此不再使用传统 DFL 分布解码
4.3 Backbone 与 Neck
YOLO26 的 YAML 中仍然可以看到:
ConvC3k2SPPFC2PSAUpsampleConcat
其多尺度检测层仍为:
| 层级 | Stride | 输入为 640 × 640 时的特征图 |
更适合检测 |
|---|---|---|---|
| P3 | 8 | 80 × 80 |
小目标 |
| P4 | 16 | 40 × 40 |
中目标 |
| P5 | 32 | 20 × 20 |
大目标 |
总位置数:
text
80 × 80 + 40 × 40 + 20 × 20
= 6400 + 1600 + 400
= 8400这组 8400 很重要。即使 YOLO26 最后输出 (N, 300, 6),网络内部仍然先从多尺度特征图产生密集预测。
5. Anchor-Free 到底是什么意思
5.1 Anchor-Free 不是"完全没有 Anchor"
这是最容易混淆的地方。
Anchor-Free 的准确含义是:
不再给每个网格位置预设具有固定宽高比例的 Anchor Box,但仍然使用特征图网格中心作为 Anchor Point,也可称参考点。
Anchor-Based:YOLOv5 风格
典型 Anchor-Based 检测器会在每个网格位置上预设若干矩形:
text
Anchor Box 1:10 × 13
Anchor Box 2:16 × 30
Anchor Box 3:33 × 23网络学习的是相对这些预设框的变化。
Anchor-Free:YOLO11 / YOLO26 风格
每个网格位置只需要一个没有宽高的参考点:
text
Anchor Point = (x, y)网络从该点出发,预测它到框四条边的距离:
text
[l, t, r, b]其中:
l:到左边界的距离t:到上边界的距离r:到右边界的距离b:到下边界的距离
框解码逻辑:
text
x1 = anchor_x - l
y1 = anchor_y - t
x2 = anchor_x + r
y2 = anchor_y + b源码中的核心思想就是:
python
lt, rb = distance.chunk(2, dim)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb5.2 Anchor Point 如何生成
源码中 make_anchors(..., grid_cell_offset=0.5) 使用网格中心作为参考点。
以 P3 为例:
text
stride = 8特征图单位坐标是:
text
(0.5, 0.5), (1.5, 0.5), (2.5, 0.5), ...乘以 stride 映射到原图后:
text
(4, 4), (12, 4), (20, 4), ...
(4,12), (12,12), (20,12), ...画成小网格:
text
x=4 x=12 x=20 x=28
y=4 ● ● ● ●
y=12 ● ● ● ●
y=20 ● ● ● ●
y=28 ● ● ● ●每一个 ● 都是 Anchor Point。
5.3 一个具体框解码例子
假设 Anchor Point 为:
text
A = (20, 20)模型预测:
text
[l, t, r, b] = [8, 6, 14, 10]解码结果:
text
x1 = 20 - 8 = 12
y1 = 20 - 6 = 14
x2 = 20 + 14 = 34
y2 = 20 + 10 = 30最终框:
text
[12, 14, 34, 30]5.4 与 dx, dy, dw, dh 的区别
说"Anchor-Free 在特征图中心点基础上预测坐标偏移量"不算完全错误,但不够精确。
对于 YOLO11 / YOLO26,更准确的说法是:
从 Anchor Point 出发预测四条边距离
l, t, r, b,而不是传统 Anchor-Based 里的中心偏移dx, dy与宽高变化dw, dh。
6. YOLO11 中的 TAL 标签分配
6.1 为什么需要标签分配
推理阶段,每个 Anchor Point 都可以预测一个框和类别分数。
但训练阶段必须回答:
对于某一个 Ground Truth 框,哪些 Anchor Point 应该作为正样本负责学习它?
YOLO11 使用 TAL,也就是 Task-Aligned Assigner。
6.2 TAL 的第一步:几何候选筛选
首先判断:
Anchor Point 的中心是否落在 GT 框内部?
落在 GT 内部的 Anchor Point 获得候选资格。
注意:
text
位于 GT 内部
≠
已经成为最终正样本更准确的表达是:
text
位于 GT 内部
=
进入候选正样本名单6.3 TAL 的第二步:计算 Task-Aligned Metric
进入候选名单后,TAL 还要评估:
- 这个位置对 GT 类别的预测分数高不高?
- 这个位置预测出的框与 GT 的 IoU 高不高?
匹配分数可以简化写成:

其中:
s:该 Anchor Point 对 GT 类别的预测分数IoU:该位置预测框与 GT 的重叠质量- 当前检测损失构造中使用
alpha=0.5、beta=6.0
beta=6.0 意味着定位质量非常重要。
6.4 TAL 的第三步:Top-K 筛选
对于每一个 GT,只保留匹配质量最高的一部分候选点。
例如:
text
GT = 一只猫内部有 6 个 Anchor Point:
| Anchor Point | 猫分数 | 预测框 IoU | 综合表现 |
|---|---|---|---|
A (12,12) |
0.63 | 0.52 | 较低 |
B (20,12) |
0.81 | 0.76 | 较高 |
C (28,12) |
0.48 | 0.39 | 很低 |
D (12,20) |
0.74 | 0.65 | 中等 |
E (20,20) |
0.92 | 0.88 | 最高 |
F (28,20) |
0.67 | 0.56 | 较低 |
TAL 排序后可能得到:
text
E > B > D > F > A > C然后从中选择 Top-K。
6.5 TAL 的第四步:解决冲突
如果一个 Anchor Point 同时被两个 GT 选中,例如两个目标重叠,那么一个位置不能同时负责两个目标。
TAL 会根据重叠质量解决冲突,通常将该 Anchor Point 分配给更合适的 GT。
6.6 TAL 流程总结
text
全部 Anchor Point
↓
筛选:中心是否位于 GT 框内部?
↓
得到几何候选集合
↓
计算分类分数与 IoU
↓
计算 align_metric
↓
每个 GT 选择 Top-K
↓
处理多个 GT 争抢同一 Anchor Point 的冲突
↓
最终正样本7. YOLO26 的 STAL:为什么小目标需要特殊处理
STAL 全称:
text
Small-Target-Aware Label Assignment中文可译为:
text
小目标感知标签分配7.1 普通 TAL 对极小目标的问题
假设 P3 的 stride 为:
text
8P3 Anchor Point 在原图中的坐标大致为:
text
(4,4), (12,4), (20,4), ...
(4,12), (12,12), (20,12), ...
(4,20), (12,20), (20,20), ...现在有一个真实小框:
text
GT = [13, 13, 18, 19]尺寸:
text
宽 = 18 - 13 = 5
高 = 19 - 13 = 6附近参考点:
text
(12,12) (20,12)
┌───────┐
│ GT │
│ 5×6 │
└───────┘
(12,20) (20,20)逐个检查:
| Anchor Point | 是否位于 GT 内? |
|---|---|
(12,12) |
否 |
(20,12) |
否 |
(12,20) |
否 |
(20,20) |
否 |
结果:
text
候选 Anchor Point 数量 = 0那么:
text
没有候选正样本
→ 无法继续做匹配质量排序
→ 无法选出最终正样本
→ 这个 GT 不会贡献有效分类与定位训练信号7.2 STAL 的核心思想
STAL 不会修改真实标注框。
它只在 寻找候选 Anchor Point 时,临时放大过小目标的候选筛选范围。
可以类比成招聘:
text
原始 GT 框:真实工作地点
代理框:临时扩大招聘范围
Anchor Point:求职者扩大的是"允许来面试的范围",不是最终工作地点。
7.3 STAL 的判断条件
常见金字塔 stride:
text
[8, 16, 32]STAL 检查 GT 的宽度与高度。如果某个维度小于最小 stride 8,候选筛选阶段临时将该维度替换为第二个 stride 16。
源码逻辑可以概括为:
python
xywh = xyxy_to_xywh(gt_boxes)
small = xywh[..., 2:] < smallest_stride
xywh[..., 2:] = where(small, next_stride, xywh[..., 2:])
surrogate_boxes = xywh_to_xyxy(xywh)7.4 完整数值例子
原始框:
text
[13, 13, 18, 19]中心点:
text
cx = (13 + 18) / 2 = 15.5
cy = (13 + 19) / 2 = 16原始尺寸:
text
5 × 6因为:
text
5 < 8
6 < 8候选筛选时临时使用:
text
16 × 16中心不变,因此代理框为:
text
x1 = 15.5 - 16 / 2 = 7.5
y1 = 16 - 16 / 2 = 8
x2 = 15.5 + 16 / 2 = 23.5
y2 = 16 + 16 / 2 = 24代理框:
text
[7.5, 8, 23.5, 24]画出来:
text
x=12 x=20
┌────────────────────┐
y=12 │ ● ● │
│ │
│ ┌──────┐ │
│ │ 原始 │ │
│ │ 5×6 │ │
│ └──────┘ │
│ │
y=20 │ ● ● │
└────────────────────┘
临时候选筛选框 16 × 16于是:
text
(12,12)
(20,12)
(12,20)
(20,20)都获得参加后续 TAL 排序的资格。
7.5 最关键的一点:回归目标仍是原始框
后续真正计算:
- 分类标签
- IoU 匹配质量
- 最终正样本
- 框回归损失
仍然基于原始 GT:
text
[13, 13, 18, 19]而不是代理框:
text
[7.5, 8, 23.5, 24]一句话记忆:
STAL 放大的不是目标,而是小目标寻找候选 Anchor Point 时的搜索范围。
7.6 宽和高是分别处理的
假设细长目标尺寸:
text
5 × 30只有宽度小于 8,所以代理尺寸是:
text
16 × 30不是 16 × 16。
7.7 为什么去掉 DFL 有利于 STAL
STAL 可能让原始 GT 框外部附近的 Anchor Point 也进入候选集合。
例如选中:
text
Anchor Point = (12,12)
GT = [13,13,18,19]按照 ltrb 表达:
text
l = 12 - 13 = -1
t = 12 - 13 = -1
r = 18 - 12 = 6
b = 19 - 12 = 7可以看到 l 和 t 为负数。
传统 DFL 将距离建模为有限的离散分布,更自然地适合非负距离。YOLO26 去掉 DFL 后使用直接回归,范围更加自由,更适合与 STAL 配合。
7.8 STAL 不参与推理
STAL 只发生在训练阶段的标签分配中。
text
训练:使用 STAL 选正样本
推理:没有 GT,因此不会执行 STAL所以它不会增加部署后处理耗时。
8. 去掉 DFL 后发生了什么
8.1 YOLOv8 / YOLO11 中的 DFL
在 YOLOv8、YOLO11 中,边界框的每一条边不是只输出一个连续数值,而是输出一个离散分布。
假设:
text
reg_max = 16对于 left 距离,输出:
text
[p0, p1, p2, ..., p15]经过概率归一化后,通过期望值得到连续距离。
例如:
text
P(distance=5) = 0.7
P(distance=6) = 0.3期望距离:
text
5 × 0.7 + 6 × 0.3 = 5.3四条边合计输出:
text
4 × 16 = 64个回归 logits。
8.2 YOLO26 的直接回归
YOLO26 配置:
yaml
reg_max: 1此时每个位置的框回归输出只有:
text
[l, t, r, b]即 4 个连续数值。
源码中:
python
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()当 reg_max=1 时,DFL 模块退化为恒等映射。
8.3 为什么要移除 DFL
论文给出的动机包括:
- 降低检测头参数量和计算量
- 简化导出和部署路径
- 避免有限离散支持范围限制大目标回归
- 与 STAL 的更自由直接回归相互配合
8.4 一个容易误解的兼容字段
YOLO26 的训练配置中仍然可能出现:
yaml
dfl: 6.0这不代表 DFL 还在工作。
官方论文补充材料明确说明:
在 YOLO26 中,
dfl字段为了向后兼容仍被保留,但实际用于缩放 L1 直接回归损失。
所以在日志里看到 dfl_loss 或配置里的 dfl,需要结合 reg_max 判断真实含义。
9. YOLO26 的损失函数
9.1 普通检测分支有哪些损失
对于单个检测分支,YOLO26 并不是只剩下"一个 Box Loss + 一个分类损失"。更准确的结构是:
text
CIoU Box Loss
+
BCE Classification Loss
+
L1 Direct Regression Loss可以写为:
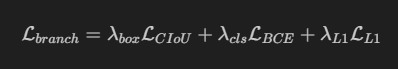
其中:
CIoU Loss:关注整体框重叠、中心距离、宽高比例BCE Classification Loss:分类损失L1 Loss:直接约束 Anchor Point 到四条边的回归误差
9.2 为什么 CIoU 与 L1 都需要
它们观察问题的角度不同。
L1:逐边修正
text
左边差多少?
上边差多少?
右边差多少?
下边差多少?CIoU:整体框修正
text
预测框与 GT 重叠得怎么样?
中心距离是否合理?
宽高比例是否合理?二者配合更稳。
9.3 L1 数值例子
假设 Anchor Point:
text
(100, 80)真实框:
text
[84, 67, 140, 113]真实距离:
text
l = 100 - 84 = 16
t = 80 - 67 = 13
r = 140 - 100 = 40
b = 113 - 80 = 33模型预测:
text
[15, 15, 37, 35]逐边误差:
text
|15 - 16| = 1
|15 - 13| = 2
|37 - 40| = 3
|35 - 33| = 2平均 L1 误差:
text
(1 + 2 + 3 + 2) / 4 = 2当前实现还会按照图像宽高归一化 ltrb,再计算 L1。
9.4 为什么源码还叫 loss_dfl
在当前代码中,损失向量仍保留:
text
loss[0] = box
loss[1] = cls
loss[2] = dfl但是当 reg_max=1 时:
text
loss[2] 实际上是 L1 直接回归损失这是兼容旧命名,不是 DFL 真正启用。
9.5 是否还有独立 Objectness Loss
普通 YOLO26 Detect Head 没有单独的 Objectness 输出通道。
每个位置的输出通道为:
text
4 × reg_max + ncYOLO26:
text
reg_max = 1因此:
text
4 + ncCOCO 有 80 类:
text
4 + 80 = 84不是旧式结构中的:
text
4 + 1 + 80 = 85因此,普通检测任务中没有单独列出的 Objectness Loss。
10. 双头结构:O2M 与 O2O
10.1 为什么需要两个 Head
YOLO26 训练时同时使用:
text
One-to-Many Head,简称 O2M
One-to-One Head,简称 O2O共享 Backbone 与 Neck,但输出头与标签分配收紧程度不同。
10.2 O2M:监督丰富,适合训练稳定性
O2M 允许一个 GT 分配给多个 Anchor Point。
例如一只猫:
text
GT 猫
├── Anchor Point A:正样本
├── Anchor Point B:正样本
├── Anchor Point C:正样本
└── Anchor Point D:正样本好处:
- 正样本更多
- 训练早期更容易学习
- 梯度信号丰富
缺点:
- 推理时容易输出多个重复框
- 需要 NMS 去重
当前 E2ELoss 源码中:
python
self.one2many = loss_fn(model, tal_topk=10)即 O2M 每个 GT 使用较丰富的正样本集合。
10.3 O2O:适合默认无 NMS 推理
O2O 希望每个 GT 最终主要由一个 Anchor Point 负责。
text
GT 猫
└── Anchor Point A:最终主要正样本当前源码中:
python
self.one2one = loss_fn(model, tal_topk=7, tal_topk2=1)理解方式:
text
第一轮:选出表现较好的 7 个候选
第二轮:进一步收紧,只保留 1 个这里 tal_topk2=1 是 One-to-One 分配的关键。
10.4 双头训练流程
text
共享 Backbone + Neck 特征
│
├── O2M Head
│ └── TAL Top-K 更丰富
│ └── 提供更多训练监督
│
└── O2O Head
└── TAL 候选后再次收紧为 1
└── 学习干净、接近唯一的预测默认推理时,只保留 O2O 路径。
10.5 O2O 与 DETR 的区别
YOLO26 的 O2O 输出最多 300 个检测结果,但它不等于 DETR 的固定 Query 结构。
| DETR 风格 | YOLO26 |
|---|---|
| 通常预设固定数量 Object Query | 仍然从 P3/P4/P5 的密集位置预测 |
| Query 数属于模型结构的重要组成 | 300 是端到端后处理保留上限 |
| 从 Query 集合直接形成结果 | 先有 8400 个密集位置,再做 Top-K |
11. 为什么最终输出是 (N, 300, 6)
11.1 网络不是只预测 300 个位置
以输入 640 × 640 为例:
text
P3:80 × 80 = 6400
P4:40 × 40 = 1600
P5:20 × 20 = 400
合计:8400每一个位置会预测:
text
4 个框回归值
+
nc 个类别分数COCO 80 类时,原始 O2O 解码张量可理解为:
text
[N, 8400, 84]其中:
text
84 = 4 + 8011.2 300 是 max_det
Detect Head 中默认:
python
max_det = 300含义:
每张图最终最多输出 300 个检测结果。
它不是:
- 网格点数量
- 模型内部只预测的框数量
- DETR Query 数量
- 图像中必须存在的目标数
它是一个工程上可控的输出上限。
11.3 为什么是 300
300 是精度、密集场景覆盖、输出张量大小和后处理开销之间的折中。
text
太小:密集场景可能截断真实目标
太大:低质量候选更多,输出与排序开销更高官方文档说明,默认检查点按照 max_det=300 优化。虽然推理或导出时可以改大,但超过 300 的额外结果质量可能下降。如果业务常常需要超过 300 个目标,建议以更高 max_det 重新训练。
11.4 结果中的 6 个数
端到端检测输出:
text
[N, 300, 6]每一条结果:
text
[x1, y1, x2, y2, confidence, class_id]例如:
text
[108.4, 76.2, 246.7, 319.5, 0.94, 0]表示:
text
左上角 = (108.4, 76.2)
右下角 = (246.7, 319.5)
置信度 = 0.94
类别索引 = 012. YOLO26 默认端到端后处理
12.1 与传统 YOLO 后处理的区别
YOLOv8 / YOLO11 传统路径
text
输出 [N, nc + 4, 8400]
↓
转置与解析
↓
每个位置取最大类别分数
↓
置信度过滤
↓
坐标格式转换或框解码
↓
执行 NMS
↓
映射回原图YOLO26 默认 O2O 路径
text
模型内部解码并执行 Top-K
↓
输出 [N, 300, 6]
↓
置信度筛选
↓
LetterBox 逆变换
↓
裁剪坐标到原图范围不需要再次做 NMS。
12.2 内部 Top-K 具体做什么
原始分数张量:
text
scores.shape = [N, 8400, nc]以 COCO 为例:
text
[N, 8400, 80]当前源码采用两阶段 Top-K 思路。
第一阶段:从 Anchor Point 中找有希望的位置
每个 Anchor Point 先取最高类别分数:
text
8400 个 Anchor Point
↓
每个位置取 max(class_scores)
↓
保留最高的 K 个 Anchor Point其中:
text
K = max_det = 300第二阶段:从位置与类别组合中再取最高分
保留下来的 300 个位置仍然有多个类别分数:
text
300 × nc展开后再选最高的 300 个位置-类别组合。
最终拼接:
text
boxes + confidence + class_id得到:
text
[N, 300, 6]12.3 Top-K 不是 NMS
Top-K 只按分数排序,没有显式比较框与框之间的 IoU。
text
Top-K:谁分数高,谁留下
NMS:谁和高分框重叠太大,谁被删除YOLO26 默认能省掉 NMS,依赖的是 O2O 训练策略:模型在训练时已经被要求尽量只为每一个真实目标产生一个高分预测。
12.4 自定义后处理最小流程
如果你确认导出的模型输出就是:
text
[1, 300, 6]则自定义部署后处理只需要:
text
遍历 300 条结果
↓
confidence >= threshold
↓
去掉 LetterBox padding
↓
除以 scale 恢复原图尺度
↓
clip 到原图边界
↓
丢弃宽高非法框12.5 坐标映射回原图例子
原图:
text
1280 × 720模型输入:
text
640 × 640LetterBox 缩放比例:
text
scale = min(640 / 1280, 640 / 720)
= min(0.5, 0.8889)
= 0.5缩放后:
text
640 × 360上下填充:
text
pad_y = (640 - 360) / 2 = 140
pad_x = 0模型输出:
text
[100, 190, 300, 390]恢复原图:
text
x1 = (100 - 0) / 0.5 = 200
y1 = (190 - 140) / 0.5 = 100
x2 = (300 - 0) / 0.5 = 600
y2 = (390 - 140) / 0.5 = 500最终框:
text
[200, 100, 600, 500]13. 与 YOLOv8、YOLO11、YOLOv10 的对比
| 维度 | YOLOv8 | YOLO11 | YOLOv10 | YOLO26 |
|---|---|---|---|---|
| 检测范式 | Anchor-Free Dense | Anchor-Free Dense | 双路径端到端方向 | 双路径,默认 O2O |
| 特征层 | P3/P4/P5 | P3/P4/P5 | 多尺度 | P3/P4/P5 |
| 默认是否依赖 NMS | 是 | 是 | 目标为 NMS-Free | 否 |
| 是否保留传统 NMS 路径 | 是 | 是 | 视实现 | 是,O2M 可选 |
| 回归头 | DFL | DFL | 通常仍涉及 DFL 路线 | DFL-Free Direct Regression |
reg_max 典型值 |
16 | 16 | 依实现 | 1 |
| 每个位置框回归通道 | 64 | 64 | 依实现 | 4 |
| 标签分配 | TAL | TAL | Consistent Dual Assignments | TAL + STAL + O2M/O2O |
| 小目标候选保障 | 普通 TAL | 普通 TAL | 依实现 | STAL |
| 双头动态权重 | 无 | 无 | 相同或固定思路 | Progressive Loss |
| 训练优化器重点 | SGD / AdamW | SGD / AdamW | 依实现 | MuSGD |
| 默认检测输出 | 密集输出后 NMS | 密集输出后 NMS | 端到端方向 | (N,300,6) |
注意:当前 Ultralytics main 分支中的共享组件会持续演进。概念对比应以论文描述和固定版本代码为准;不要仅因为当前仓库中多个模型复用同一个 TaskAlignedAssigner 类,就误以为历史发布版本具有完全相同的行为。
14. MuSGD 与 Progressive Loss
14.1 Progressive Loss
YOLO26 同时训练 O2M 与 O2O 分支,但两者的重要性会随训练推进变化。
总损失可简化表示为:
在这里插入图片描述
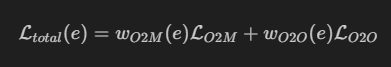
其中 e 表示训练进度。
论文消融实验中的最佳调度:
text
训练开始:O2M = 0.8,O2O = 0.2
训练结束:O2M = 0.1,O2O = 0.9理解方式:
text
训练早期:
依靠 O2M 丰富监督,先学会找到目标
训练后期:
强化 O2O,学会产生干净、接近唯一的预测14.2 MuSGD
MuSGD 是 Muon 与 SGD-Momentum 的混合优化器。
论文与源码说明:
- 对适合 Muon 的高维参数,使用正交化后的 Muon 风格更新,并保留 SGD 分量
- 对一维参数等不适合 Muon 的参数,使用标准 SGD
- Muon 更新中使用 Newton-Schulz 迭代做轻量正交化
不要误解成:
text
MuSGD 每一步一定比 SGD 更快更准确的说法是:
论文重点展示的是达到目标精度所需训练计划更有效;每一步的实际墙钟耗时仍需在具体硬件上测量。
15. 多任务扩展
YOLO26 不只是 Detect。
15.1 实例分割
端到端实例分割输出:
text
(N, 300, 6 + nm)
+
proto: (N, nm, H, W)其中 nm 是 Mask 系数数量,官方文档列出的默认值为 32。
论文还提出:
- Multi-Scale Proto Module
- 辅助语义分割监督
辅助分支只用于训练,不必增加最终部署开销。
15.2 Pose
端到端 Pose 输出:
text
(N, 300, 57)对于 COCO Pose:
text
17 个关键点 × 3
=
51 个关键点相关值再加检测基础字段。
论文中引入 RLE,即 Residual Log-Likelihood Estimation,用于建模关键点位置与不确定性。
15.3 OBB
端到端 OBB 输出:
text
(N, 300, 7)相较普通检测,多一个旋转角度相关字段。
YOLO26 针对旋转框参数化以及接近正方形目标的角度问题做了专门改进。
15.4 YOLOE-26
YOLOE-26 是开放词汇扩展,支持:
- 文本提示
- 视觉提示
- 无提示推理
适合需要动态类别或更开放语义能力的场景。
16. 官方实验结果与消融实验
16.1 COCO 检测结果
论文给出的 released YOLO26 检测结果:
| 模型 | 输入 | 标准 mAP | E2E mAP | CPU ONNX | T4 TensorRT10 | 参数量 | FLOPs |
|---|---|---|---|---|---|---|---|
| YOLO26n | 640 | 40.9 | 40.1 | 38.9 ms | 1.7 ms | 2.4M | 5.4B |
| YOLO26s | 640 | 48.6 | 47.8 | 87.2 ms | 2.5 ms | 9.5M | 20.7B |
| YOLO26m | 640 | 53.1 | 52.5 | 220.0 ms | 4.7 ms | 20.4M | 68.2B |
| YOLO26l | 640 | 55.0 | 54.4 | 286.2 ms | 6.2 ms | 24.8M | 86.4B |
| YOLO26x | 640 | 57.5 | 56.9 | 525.8 ms | 11.8 ms | 55.7M | 193.9B |
其中:
- 标准 mAP:O2M + NMS 路径
- E2E mAP:默认 O2O 无 NMS 路径
可以看到 E2E 路径通常比标准路径低约 0.6 ~ 0.8 AP,换来更简单的部署链路。
16.2 DFL 移除消融
| 输入尺寸 | DFL | AP | APS | APM | APL |
|---|---|---|---|---|---|
| 640 | 使用 | 46.0 | 27.3 | 50.4 | 62.8 |
| 640 | 移除 | 46.3 | 27.9 | 50.6 | 63.8 |
| 1280 | 使用 | 49.8 | 36.0 | 55.7 | 61.8 |
| 1280 | 移除 | 51.1 | 35.9 | 55.2 | 64.0 |
论文指出,移除 DFL 对高分辨率大目标回归的收益更明显。
16.3 STAL 消融
| 方法 | 参考尺寸 | AP | APS | APM | APL |
|---|---|---|---|---|---|
| TAL baseline | --- | 46.6 | 29.0 | 51.4 | 63.9 |
| STAL | 8 | 46.6 | 27.7 | 51.6 | 63.8 |
| STAL | 16 | 46.8 | 29.6 | 51.6 | 63.8 |
| STAL | 32 | 46.5 | 28.3 | 51.3 | 63.7 |
解释:
- 代理尺寸太小:覆盖改善不足
- 代理尺寸太大:候选范围过宽,引入噪声
16:在覆盖与匹配质量之间取得更好平衡
16.4 Progressive Loss 消融
起始权重 (O2M,O2O) |
结束权重 (O2M,O2O) |
E2E mAP |
|---|---|---|
(0.5,0.5) |
(0.5,0.5) |
46.4 |
(1.0,0.0) |
(0.1,0.9) |
46.4 |
(1.0,0.0) |
(0.2,0.8) |
46.4 |
(1.0,0.0) |
(0.3,0.7) |
46.3 |
(0.8,0.2) |
(0.1,0.9) |
46.7 |
(0.9,0.1) |
(0.1,0.9) |
46.3 |
结论:
O2O 分支从训练一开始就应该获得非零监督,但后期应逐步增强其权重。
17. 训练、验证、推理与导出示例
17.1 安装
bash
pip install -U ultralytics由于 YOLO26 很新,建议记录实际安装版本:
bash
python -c "import ultralytics; print(ultralytics.__version__)"17.2 推理
python
from ultralytics import YOLO
model = YOLO("yolo26n.pt")
results = model.predict("image.jpg")Ultralytics Python API 会自动处理默认端到端路径。
17.3 自定义数据训练
python
from ultralytics import YOLO
model = YOLO("yolo26s.pt")
model.train(
data="data.yaml",
epochs=100,
imgsz=640,
batch=16,
)17.4 验证默认 E2E 路径
python
metrics_e2e = model.val(data="data.yaml")17.5 验证传统 O2M + NMS 路径
python
metrics_nms = model.val(
data="data.yaml",
end2end=False,
)17.6 导出 ONNX 端到端版本
python
model.export(
format="onnx",
)17.7 导出传统路径
python
model.export(
format="onnx",
end2end=False,
)17.8 调整 max_det
python
model.predict("image.jpg", max_det=100)
model.export(format="onnx", max_det=500)但请记住:默认检查点按 max_det=300 优化。如果业务确实需要每张图超过 300 个高质量结果,最好重新训练并验证。
18. ONNX Runtime 与 C++ 部署思路
18.1 Python 后处理伪代码
python
import numpy as np
def postprocess_yolo26_e2e(
output: np.ndarray,
original_width: int,
original_height: int,
input_width: int = 640,
input_height: int = 640,
confidence_threshold: float = 0.25,
):
"""output 通常为 [1, 300, 6],每行为 [x1,y1,x2,y2,conf,class_id]。"""
if output.ndim != 3 or output.shape[0] != 1 or output.shape[2] != 6:
raise ValueError(f"Unexpected shape: {output.shape}")
scale = min(input_width / original_width, input_height / original_height)
resized_w = original_width * scale
resized_h = original_height * scale
pad_x = (input_width - resized_w) / 2
pad_y = (input_height - resized_h) / 2
detections = []
for x1, y1, x2, y2, confidence, class_id in output[0]:
if confidence < confidence_threshold:
continue
x1 = (x1 - pad_x) / scale
y1 = (y1 - pad_y) / scale
x2 = (x2 - pad_x) / scale
y2 = (y2 - pad_y) / scale
x1 = np.clip(x1, 0, original_width)
y1 = np.clip(y1, 0, original_height)
x2 = np.clip(x2, 0, original_width)
y2 = np.clip(y2, 0, original_height)
if x2 <= x1 or y2 <= y1:
continue
detections.append({
"box": [float(x1), float(y1), float(x2), float(y2)],
"confidence": float(confidence),
"class_id": int(class_id),
})
return detections18.2 C++ 风格伪代码
cpp
struct Detection {
float x1, y1, x2, y2;
float confidence;
int class_id;
};
std::vector<Detection> postprocess_yolo26_e2e(
const float* output, // [1, 300, 6]
int original_width,
int original_height,
int input_width = 640,
int input_height = 640,
float threshold = 0.25f
) {
const float scale = std::min(
static_cast<float>(input_width) / original_width,
static_cast<float>(input_height) / original_height
);
const float pad_x = (input_width - original_width * scale) / 2.0f;
const float pad_y = (input_height - original_height * scale) / 2.0f;
std::vector<Detection> results;
for (int i = 0; i < 300; ++i) {
const float* det = output + i * 6;
const float score = det[4];
if (score < threshold) continue;
float x1 = (det[0] - pad_x) / scale;
float y1 = (det[1] - pad_y) / scale;
float x2 = (det[2] - pad_x) / scale;
float y2 = (det[3] - pad_y) / scale;
x1 = std::clamp(x1, 0.0f, static_cast<float>(original_width));
y1 = std::clamp(y1, 0.0f, static_cast<float>(original_height));
x2 = std::clamp(x2, 0.0f, static_cast<float>(original_width));
y2 = std::clamp(y2, 0.0f, static_cast<float>(original_height));
if (x2 <= x1 || y2 <= y1) continue;
results.push_back({
x1, y1, x2, y2,
score,
static_cast<int>(det[5]),
});
}
return results;
}18.3 部署时一定要先确认输出形状
不要只根据模型名字写死后处理。
请先打印导出模型实际输出:
text
[1, 300, 6]如果是这个形状,通常走端到端路径:
text
置信度筛选 + 坐标恢复如果输出类似:
text
[1, nc + 4, 8400]则是传统路径,需要:
text
解析 + 置信度筛选 + NMS + 坐标恢复19. RKNN 等后端的特殊注意事项
不是所有导出格式都支持端到端 O2O 图。
官方文档列出的原生支持端到端路径的常见格式包括:
- ONNX
- TensorRT
- CoreML
- OpenVINO
- TFLite
- TF.js
- MNN
官方文档列出的自动回退到 O2M 路径的格式包括:
- NCNN
- RKNN
- PaddlePaddle
- ExecuTorch
- IMX
- Edge TPU
- Qualcomm QNN
原因通常是某些后端不支持端到端解码中的算子,例如 torch.topk。
因此,对于 RK3588 / RKNN 部署:
text
不能想当然地认为输出一定是 [1,300,6]更稳妥的流程:
text
导出 RKNN 或转换模型
↓
打印实际输出 shape
↓
若回退 O2M:继续使用 NMS
↓
在目标设备上验证精度与延迟20. 推荐的源码阅读顺序
第一阶段:先懂结构
1. yolo26.yaml
重点:
yaml
end2end: True
reg_max: 1以及:
text
P3 / P4 / P5
C3k2
SPPF
C2PSA2. head.py
重点:
text
Detect.max_det = 300
DFL 或 Identity
O2M Head
O2O Head
make_anchors
框解码
postprocess
get_topk_index第二阶段:再懂标签分配
3. tal.py
建议按顺序看:
text
make_anchors
↓
dist2bbox
↓
TaskAlignedAssigner
↓
select_candidates_in_gts
↓
STAL 的 surrogate geometry
↓
select_topk_candidates
↓
冲突消解
↓
topk2 二次筛选第三阶段:再懂损失
4. loss.py
重点:
text
BboxLoss
↓
reg_max > 1:DFL
reg_max = 1:L1
↓
CIoU
↓
BCE classification
↓
E2ELoss
↓
O2M topk=10
O2O topk=7, topk2=1
↓
Progressive Loss 权重调度第四阶段:再看优化器
5. optim/muon.py
重点:
text
Muon 更新
SGD 更新
参数组
Newton-Schulz 正交化
混合更新策略21. 常见误区与问答
Q1:Anchor-Free 是不是完全没有 Anchor?
不是。
Anchor-Free 没有预设宽高的 Anchor Box,但仍然使用 Anchor Point,也就是特征图网格中心参考点。
Q2:YOLO11 是不是从 Anchor Point 预测坐标偏移量?
可以粗略这么说,但更准确的是预测到四条边的距离:
text
[l, t, r, b]而不是传统 Anchor-Based 中的:
text
[dx, dy, dw, dh]Q3:某个 Anchor Point 位于 GT 内部,它就是正样本吗?
还不是。
它只是候选正样本。TAL 还要计算分类分数与 IoU,选择 Top-K,并处理冲突。
Q4:STAL 是把小目标放大后训练吗?
不是。
STAL 只在候选 Anchor Point 筛选阶段临时放大搜索范围。真实回归目标仍是原始小框。
Q5:去掉 DFL 后是不是只剩 Box Loss 和分类损失?
不能这么简化。
普通 YOLO26 检测分支仍包含:
text
CIoU Box Loss
+
BCE Classification Loss
+
L1 Direct Regression LossQ6:配置里为什么还有 dfl?
向后兼容。
YOLO26 中该字段实际缩放 L1 直接回归损失,不代表 DFL 启用。
Q7:输出 (1,300,6) 是否只需要置信度筛选?
在真正的端到端导出模型中,是的。
还需要:
text
LetterBox 逆变换
坐标裁剪
非法框检查但不需要 NMS。
Q8:300 是不是网络只预测 300 个框?
不是。
网络仍然从 P3/P4/P5 产生 8400 个密集位置。300 是 Top-K 后的最大输出数量。
Q9:所有后端都输出 (1,300,6) 吗?
不是。
例如 RKNN、NCNN 等格式可能自动回退到 O2M 传统路径,需要 NMS。
Q10:当前 main 源码是否永远等于论文发布时源码?
不一定。
仓库持续更新。严格实验应固定 tag 或 commit,并记录:
text
ultralytics 版本
Git commit
模型权重文件
导出参数
推理后端版本
输入尺寸
max_det
end2end22. 一页纸总结
text
YOLO26
│
├── 基础骨架
│ ├── YOLO11 family 风格
│ ├── Backbone + Neck
│ └── P3/P4/P5 多尺度特征
│
├── Anchor-Free
│ ├── 没有预设 Anchor Box
│ ├── 仍有 Anchor Point
│ └── 从参考点直接回归 l/t/r/b
│
├── TAL
│ ├── GT 内 Anchor Point 先进入候选集合
│ ├── 分类分数 + IoU 计算 align_metric
│ ├── Top-K
│ └── 冲突消解
│
├── STAL
│ ├── 解决极小 GT 内可能没有 Anchor Point 的问题
│ ├── 只临时扩大候选搜索范围
│ ├── 原始 GT 仍用于评分和回归
│ └── 只在训练中使用
│
├── DFL-Free
│ ├── YOLO11:4 × reg_max 个分布 logits
│ ├── YOLO26:reg_max=1
│ ├── 每位置直接输出 4 个 ltrb 数值
│ └── 检测头更轻、范围更自由
│
├── Loss
│ ├── CIoU
│ ├── BCE Classification
│ ├── L1 Direct Regression
│ └── 配置中的 dfl 字段保留但实际缩放 L1
│
├── 双 Head
│ ├── O2M:tal_topk=10,监督丰富,需要 NMS
│ ├── O2O:tal_topk=7, tal_topk2=1,默认推理
│ └── Progressive Loss:后期更强调 O2O
│
├── 输出
│ ├── 原始密集位置:8400,输入 640 时
│ ├── 内部两阶段 Top-K
│ ├── max_det=300
│ └── 默认输出 [N,300,6]
│
└── 默认后处理
├── 置信度筛选
├── LetterBox 逆变换
├── 坐标裁剪
└── 不需要 NMS附录 A:关键源码索引
A.1 模型配置
重点搜索:
text
end2end: True
reg_max: 1
DetectA.2 Detect Head
重点搜索:
text
class Detect
max_det = 300
self.dfl
one2many
one2one
postprocess
get_topk_indexA.3 Loss
重点搜索:
text
class BboxLoss
F.l1_loss
BCEWithLogitsLoss
class E2ELoss
tal_topk=10
tal_topk=7, tal_topk2=1A.4 TAL 与 STAL
重点搜索:
text
class TaskAlignedAssigner
select_candidates_in_gts
wh_mask
stride_val
make_anchors
dist2bbox
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
topk2A.5 MuSGD
重点搜索:
text
class MuSGD
Newton-Schulz
use_muon附录 B:进一步阅读
B.1 YOLO26 官方资料
-
Ultralytics YOLO26 原论文
-
YOLO26 官方模型文档
-
YOLO26 端到端迁移指南
-
Ultralytics 官方仓库
B.2 相关论文
-
YOLOv1
You Only Look Once: Unified, Real-Time Object Detection
-
YOLO9000 / YOLOv2
YOLO9000: Better, Faster, Stronger
-
YOLOv3
YOLOv3: An Incremental Improvement
-
YOLOX
YOLOX: Exceeding YOLO Series in 2021
-
YOLOv10
YOLOv10: Real-Time End-to-End Object Detection
-
Generalized Focal Loss / DFL
Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
-
Task Alignment Learning
TOOD: Task-aligned One-stage Object Detection
结束语
学习 YOLO26 时,最重要的不是记住一堆模块名字,而是建立一条完整逻辑链:
text
Anchor-Free 参考点
↓
TAL 为 GT 选择负责位置
↓
极小目标可能没有内部参考点
↓
STAL 临时扩大候选筛选范围
↓
去掉 DFL 后使用更自由的 ltrb 直接回归
↓
O2M 提供丰富监督,O2O 学习唯一匹配
↓
Progressive Loss 后期强化 O2O
↓
推理时用 O2O + Top-K
↓
输出 [N,300,6]
↓
置信度筛选 + 坐标还原,无需 NMS理解这条链以后,YOLO26 的结构、损失、STAL 与部署方式就不再是零散知识点,而是一套相互配合的设计。