数据结构:
单链表的增删改查操作、实现思路
bash
// 向单向链表的指定位置插入数据
// p保存链表的头指针 post 插入的位置 data插入的数据
int InsertIntoPostLinkList(link_node_t *p, int post, datatype data)
{
// 0.容错判断
if (post < 0 || post > LengthLinkList(p))
{
perror("InsertIntoPostLinkList err");
return -1;
}
// 1.将头指针指向被插入位置的前一个节点
for (int i = 0; i < post; i++)
p = p->next;
// 2.创建一个新节点,存放数据
link_list_t pnew = (link_list_t)malloc(sizeof(link_node_t));
if (pnew == NULL)
{
perror("pnew malloc err");
return -1;
}
pnew->data = data;
pnew->next = NULL;
// 3.将新节点插入链表中(先连后面,再连前面)
pnew->next = p->next;
p->next = pnew;
return 0;
}
//6.判断单向链表是否为空 1代表空 0代表非空
int IsEpLinkList(link_node_t *p)
{
return p->next == NULL;
}
// 5.删除单向链表中指定位置的数据 post 代表的是删除的位置
int DeletePostLinkList(link_node_t *p, int post)
{
// 0.容错判断
if (post < 0 || post >= LengthLinkList(p))
{
perror("DeletePostLinkList err");
return -1;
}
// 1.将头指针指向被删除位置的前一个节点
for (int i = 0; i < post; i++)
p = p->next;
// 2.进行删除操作
// 1)定义一个指针pdel指向被删除位置
link_list_t pdel = p->next;
// 2)跨过被删除节点
p->next = pdel->next;
// 3)释放被删除节点
free(pdel);
pdel = NULL;
return 0;
}
//9.删除单向链表中出现的指定数据,data代表将单向链表中出现的所有data数据删除
int DeleteDataLinkList(link_node_t *p, datatype data)
{
//1.定义一个指针q指向头结点的前一个节点,此时可以看做q指向一个无头单向链表
link_list_t q = p->next;
//2.用q遍历链表,将每一个节点的数据域与data作比较,如果相同就删除该节点
while(q != NULL)
{
if(q->data == data)//如果相等,删除
{
p->next = q->next;
free(q);
q = p->next;
}
else//如果不相等,指针向后移动
{
p=p->next;
q=p->next;
}
}
return 0;
}
//7.修改指定位置的数据 post 被修改的位置 data修改成的数据
int ChangePostLinkList(link_node_t *p, int post, datatype data)
{
//0.容错判断
if(post < 0 || post >=LengthLinkList(p))
{
perror("ChangePostLinkList");
return -1;
}
//1.将头指针指向被修改的节点
for(int i=0;i<=post;i++)
p=p->next;
//2.修改数据
p->data = data;
return 0;
}
//8.查找指定数据出现的位置 data被查找的数据 //search 查找
int SearchDataLinkList(link_node_t *p, datatype data)
{
//1.定义变量记录查找位置
int post=0;
//2.遍历链表,查找数据
while(p->next != NULL)
{
p=p->next;
if(p->data == data)
return post;
post++;
}
return -1;
}单链表的倒置思路
(1) 将头节点与当前链表断开,断开前保存下头节点的下一个节点,保证后面链表能找得到,定义一个q保存头节点的下一个节点,断开后前面相当于一个空的链表,后面是一个无头的单向链表
(2) 遍历无头链表的所有节点,将每一个节点当做新节点,插入空链表头节点的下一个节点(每次插入的头节点的下一个节点位置)
bash
void ReverseLinkList(link_node_t *p)
{
link_node_t *q = p->next;
link_node_t *temp = NULL;
/*将头节点和下一个节点断开 */
p->next = NULL;
/*遍历无头单向节点 */
while (q != NULL)
{
temp = q->next;
/*进行插入操作 */
q->next = p->next;
p->next = q;
q = temp;
}
}单链表和双向链表的区别
单链表(Singly Linked List)和双向链表(Doubly Linked List)是两种常见的链式存储结构,它们在数据结构中有一些不同之处。
单链
- 单链表中的每个节点包含两个部分:数据域和指针域(通常称为next指针)。
- 每个节点只有一个指针,指向下一个节点,最后一个节点的next指针指向NULL,表示链表结束。
- 单链表只能从头节点开始依次遍历访问节点,无法从后往前访问。
- 在单链表中,如果要删除某个节点,需要知道其前驱节点,因为只有前驱节点的next指针可以修改。
双向链表:
- 双向链表中的每个节点包含三个部分:数据域、前驱指针(prev指针)和后继指针(next指针)。
- 每个节点有两个指针,分别指向前一个节点和后一个节点。第一个节点的prev指针和最后一个节点的next指针指向NULL,表示链表的开始和结束。
- 双向链表可以从头节点开始正向遍历访问节点,也可以从尾节点开始反向遍历访问节点,这使得双向链表的某些操作更加高效。
- 在双向链表中,如果要删除某个节点,可以直接通过前驱指针和后继指针完成删除操作,不需要知道其前驱节点。
区别总结:
- 单链表每个节点只有一个指针域,只能从头节点开始单向遍历。
双向链表每个节点有两个指针域,可以从头节点开始正向遍历,也可以从尾节点开始反向遍历,灵活性更高。
- 双向链表相对于单链表,每个节点多了一个prev指针,这增加了一定的内存开销。
- 在插入和删除操作上,双向链表的操作可能比单链表更复杂一些,因为需要同时修改前驱和后继节点的指针。但是在一些情况下,双向链表的操作效率更高,特别是对于涉及到反向遍历或删除操作时。
栈和队列的区别
- 特点
栈:栈是一种后进先出(Last In First Out,LIFO)的数据结构,类似于把元素放在一个垂直的栈中,最后放入的元素最先被取出。
队列:队列是一种先进先出(First In First Out,FIFO)的数据结构,类似于排队,最先放入的元素最先被取出。
- 插入和删除操作:
栈:栈的插入操作称为入栈(Push),删除操作称为出栈(Pop)。元素只能从栈顶进。
队列:队列的插入操作称为入队(Enqueue),删除操作称为出队(Dequeue)。元素只能从队列的前端出队,从队列的后端入队。
- 访问限制:
栈:栈只允许访问栈顶的元素,无法直接访问其他位置的元素。
队列:队列只允许访问队列的前端和后端元素,无法直接访问其他位置的元素。
- 应用场景:
栈:常用于函数调用和递归调用的内存管理、表达式求值、括号匹配等场景。
1)方法调用和递归:在方法调用过程中,每次调用一个方法时将其压入栈,方法执行完毕后再将其弹出,保证方法调用的顺序。
2)表达式求值:在计算表达式的过程中,使用栈来存储运算符和操作数,根据运算符的优先级进行计算。
3)括号匹配:使用栈来判断括号的匹配情况,当遇到左括号时将其压入栈,遇到右括号时弹出栈顶元素并进行匹配。
队列:常用于任务调度、缓冲区管理、打印任务队列等场景。
1)消息队列:在分布式系统中,使用队列来进行消息的传递和处理,确保消息的顺序和可靠性。
2)多线程任务调度:使用队列来存储待执行的任务,并由多个线程从队列中取出任务进行执行。
3)打印任务队列:在打印机服务中,使用队列来存储待打印的任务,保证打印任务的顺序和公平性。
两个栈怎样实现一个队列,思路说一下
- 使用栈 A 作为入队栈,栈 B 作为出队栈。
- 入队操作时,直接将元素压入栈 A。
- 出队操作时,首先检查栈 B 是否为空,如果不为空,则直接弹出栈顶元素;如果栈 B 为空,则将栈 A 中的所有元素逐个弹出并压入栈 B,然后再弹出栈 B 的栈顶元素作为出队元素。

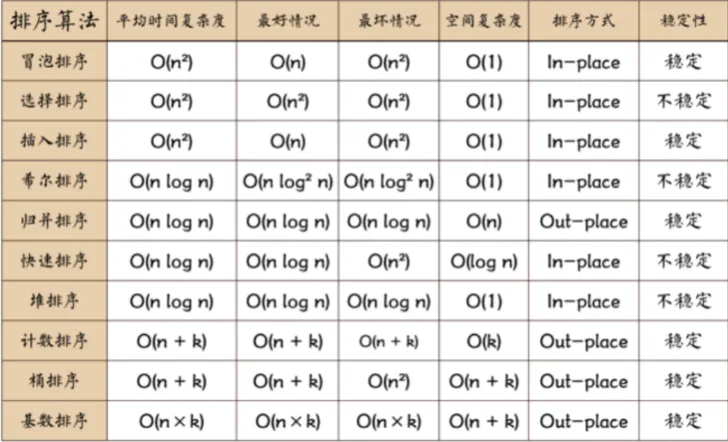
冒泡排序原理?时间复杂度多少?
原理:冒泡排序是一种简单的排序算法,每次比较相邻的两个元素,如果它们的顺序错误,则交换位置,通过多次遍历,将最大的元素逐渐冒泡到正确的位置上。
时间复杂度:冒泡排序的平均时间复杂度为O(n²),其中n是待排序元素的数量,最好情况下时间复杂度为O(n)
什么是二叉树、满二叉树?
二叉树:是一种特殊的树结构,每个节点最多有两个子树,分别称为左子树和右子树
满二叉树:深度为k(k>=1)时,节点数为2k - 1(2的k次幂-1)个的二叉树。
有空再了解一下平衡二叉树和红黑树的相关知识。
二叉树的前序中序后序遍历
(1)前序遍历:先访问根节点,然后按照左子树、右子树的顺序进行遍历
(2)中序遍历:按照左子树、根节点、右子树的顺序进行遍历
(3)后序遍历:按照左子树、右子树、根节点的顺序进行遍历
查找算法学过哪些 ?二分查找的时间复杂度多少?
顺序查找:从头到尾逐个比较查找,时间复杂度为O(n)
二分查找:对有序数组进行查找,每次将查找区间二分,并与目标值进行比较,时间复杂度为O(nlog n )
分块查找:块间有序、块内无序 ,时间复杂度为O(log(m)+n/m)
哈希表的原理?
哈希表:是一种通过哈希函数将键映射到存储位置的数据结构。查找元素时,先使用哈希函数计算出键的哈希值,然后根据哈希值找到对应的存储位置,在哈希冲突的情况下,通常采用开放地址法、活链地址法来解决.
排序算法学过哪些?快速排序的实现原理?
- 冒泡排序:比较相邻元素,将较大的元素向后移动,时间复杂度为O(n²)
- 选择排序:从数列中找最小值,找到后和第一个位置的数据进行交互,再从剩下数中找最小值,依次类推。
- 快速排序:采用"分治"的思想,对于一组数据,选择一个基准元素(base),通常选择第一个或最后一个元素,通过第一轮扫描,比base小的元素都在base左边,比base大的元素都在base右边,再有同样方法递归排序这两部分,直到序列中所有数据均有序为止。