Python语言深度掌握
- 语言核心,深入理解Python运行机制:深入理解Python对象模型、内存管理、GIL机制、解释器工作原理
- 精通Python语法与高级特性:装饰器、元类、上下文管理器、生成器协程、异步编程(asyncio)等
- 性能优化:代码性能分析、内存泄漏排查、C扩展开发
- 熟练使用标准库与常用第三方库:如 requests、pandas、numpy、logging、collections 等。
代码性能分析
性能分析主要分为两大类:时间分析和内存分析。下表概述了常见的工具及其适用场景:
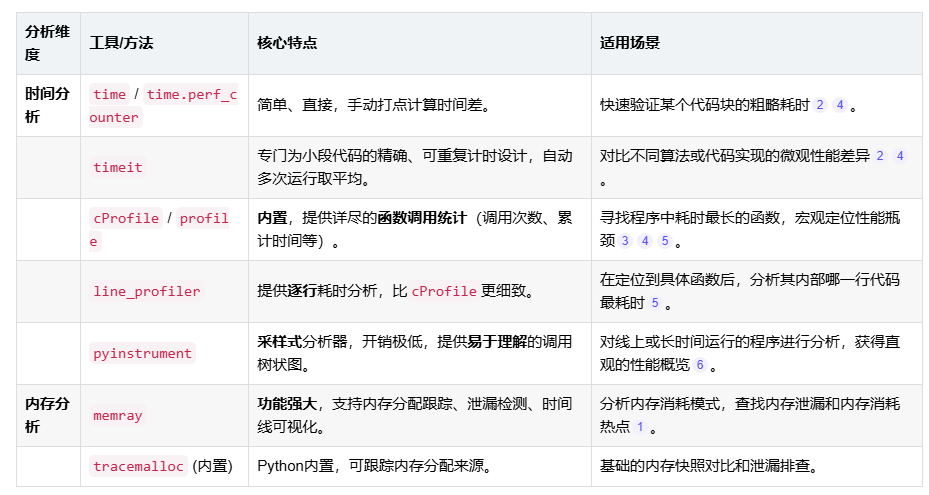
简单计时:time.perf_counter
这是最基础的方法,用于快速测试。perf_counter提供最高精度的计时器。
python
import time
def slow_function():
time.sleep(0.1) # 模拟耗时操作
return sum(i * i for i in range(10000))
start = time.perf_counter()
result = slow_function()
end = time.perf_counter()
print(f"函数执行结果: {result}")
print(f"耗时: {end - start:.4f} 秒") # 输出:耗时: 0.1067 秒[ref_4]标准微基准测试:timeit
timeit模块会禁用垃圾回收,并多次重复执行代码以获得更稳定的结果。可以通过命令行或Python代码使用。
- 命令行方式(适合快速测试):
bash
python -m timeit -s "text = 'sample string'; char = 'g'" "char in text"- 代码方式:
python
import timeit
# 测试两种成员检查方法的效率
code_snippet_1 = "char in text"
code_snippet_2 = "text.find(char) != -1"
setup_code = "text = 'a' * 1000 + 'sample string' + 'b' * 1000; char = 'g'"
time1 = timeit.timeit(stmt=code_snippet_1, setup=setup_code, number=100000)
time2 = timeit.timeit(stmt=code_snippet_2, setup=setup_code, number=100000)
print(f"'in' 操作耗时: {time1:.4f}秒")
print(f"'find' 操作耗时: {time2:.4f}秒")
# 通常 'in' 操作更快[ref_2]函数级性能分析:cProfile
cProfile是Python内置的分析器,能告诉你每个函数被调用了多少次,以及在其中消耗了多少时间。
- 命令行中使用(更常用):
bash
python -m cProfile -s cumtime your_script.py- 代码中使用:
python
#使用方法:
import cProfile
import your_module
cProfile.run('your_module.some_function()')
#使用装饰器:
import cProfile
def profiled(func):
def wrapper(*args, **kwargs):
profiler = cProfile.Profile()
result = profiler.runcall(func, *args, **kwargs)
profiler.print_stats()
return result
return wrapper
@profiled
def some_function():
# 你的代码
pass
some_function()行级性能分析:line_profiler
当cProfile告诉你某个函数是瓶颈时,line_profiler可以深入该函数,显示每一行的耗时。需要先安装:pip install line_profiler。
- 命令行中使用
bash
kernprof -l -v example.py- 使用@profile装饰器标记要分析的函数:
python
# 文件: example.py
import line_profiler
import random
@profile # 重点:用此装饰器标记
def expensive_function(data):
total = 0
result = []
for item in data:
total += item # 模拟一些计算
if item > 0.5: # 模拟一个条件判断
result.append(item ** 2) # 模拟更耗时的计算
else:
result.append(item ** 0.5)
return total, result
if __name__ == "__main__":
data = [random.random() for _ in range(10000)]
expensive_function(data)可视化采样分析:Pyinstrument
Pyinstrument以固定间隔对程序调用栈进行采样,开销极低(约1%),特别适合分析Web请求或长时间任务。安装:pip install pyinstrument。
- 分析整个脚本:它会生成一个彩色的、层级分明的调用树报告,让你一眼看出时间花在了哪里。
bash
pyinstrument your_script.py- 在代码中使用:
python
from pyinstrument import Profiler
profiler = Profiler()
profiler.start()
# 这里是你要分析的代码
your_slow_function()
profiler.stop()
print(profiler.output_text(unicode=True, color=True))内存性能分析
内存问题(如泄漏、过度消耗)同样致命。Memray是一个强大的内存分析器。安装:pip install memray。
- 生成内存分析报告
bash
# 运行脚本并生成一个二进制跟踪文件
memray run -o output.bin your_script.py
# 生成多种格式的报告
memray stats output.bin # 显示统计摘要
memray table output.bin # 以表格形式显示内存分配者
memray tree output.bin # 显示内存分配的调用树
memray flamegraph output.bin # 生成火焰图(需memray flamegraph output.bin > flamegraph.html)- 在代码中实时跟踪
python
import memray
import numpy as np
def allocate_memory():
# 模拟大量内存分配
large_list = ["x" * 1024 for _ in range(10000)] # 分配约10MB
large_array = np.ones((1000, 1000), dtype=np.float64) # 分配约8MB
return large_list, large_array
with memray.Tracker("memory_profile.bin"): # 开始跟踪
result = allocate_memory()
print("分析完成,报告已保存至 memory_profile.bin")Python内存泄漏排查方法及工具
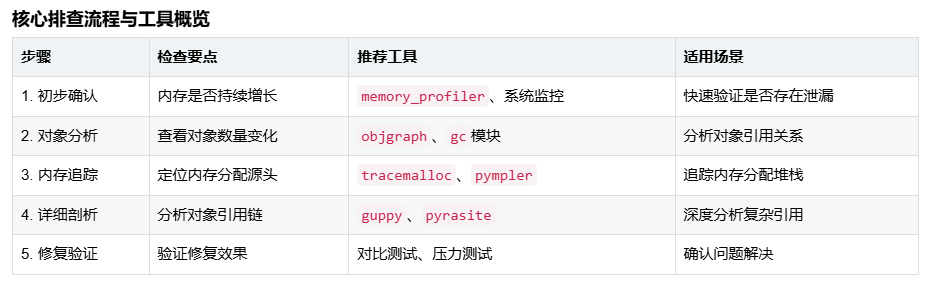
- 初步确认与监控:首先需要确认是否存在内存泄漏,使用memory_profiler进行实时监控:
python
# 安装:pip install memory_profiler
from memory_profiler import profile
import time
@profile
def suspicious_function():
"""可疑的泄漏函数"""
data = []
for i in range(100000):
data.append("x" * 1000) # 故意创建大对象
# 模拟未释放的引用
if i % 10000 == 0:
global_ref.append(data[-1000:]) # 全局引用导致泄漏 [ref_2]
return data
global_ref = [] # 全局变量可能导致内存无法回收 [ref_5]
if __name__ == "__main__":
for _ in range(5):
suspicious_function()
print(f"当前全局引用数: {len(global_ref)}")
time.sleep(1)
bash
python -m memory_profiler your_script.py- 对象引用分析:使用objgraph和gc模块分析对象引用关系:
python
import objgraph
import gc
import sys
class Node:
"""测试节点类"""
def __init__(self, name):
self.name = name
self.children = []
def add_child(self, child):
self.children.append(child)
child.parent = self # 双向引用可能造成循环引用 [ref_1]
def create_leaking_objects():
"""创建泄漏的对象引用"""
nodes = []
for i in range(100):
node = Node(f"node_{i}")
if nodes:
nodes[-1].add_child(node) # 创建循环引用
nodes.append(node)
return nodes
def analyze_memory():
"""分析内存使用情况"""
# 强制垃圾回收
gc.collect()
print("=== 内存分析报告 ===")
# 1. 查看对象数量
print(f"\n1. 当前对象统计:")
objgraph.show_most_common_types(limit=10)
# 2. 查找循环引用
print(f"\n2. 循环引用检测:")
gc.set_debug(gc.DEBUG_SAVEALL)
garbage = gc.garbage
print(f"垃圾回收器中的对象数: {len(garbage)}")
# 3. 查看特定类型对象的引用链
print(f"\n3. Node对象的引用链示例:")
node_refs = objgraph.by_type('Node')
if node_refs:
objgraph.show_backrefs(
node_refs[:3],
max_depth=5,
filename='node_backrefs.png'
)
print("引用图已保存到 node_backrefs.png")
# 创建泄漏
leaking_nodes = create_leaking_objects()
# 删除局部引用但循环引用仍然存在
del leaking_nodes
# 执行分析
analyze_memory()- 内存分配追踪:使用tracemalloc追踪内存分配的源头:
python
import tracemalloc
import numpy as np
def leaking_function():
"""有内存泄漏的函数"""
cache = {}
def process_data(data_id):
"""处理数据并缓存"""
if data_id not in cache:
# 模拟大数据处理
data = np.random.rand(10000, 100)
cache[data_id] = data # 缓存可能导致内存泄漏 [ref_4]
return cache[data_id]
return process_data
def trace_memory_allocation():
"""追踪内存分配"""
# 开始追踪
tracemalloc.start()
processor = leaking_function()
# 模拟多次调用
snapshots = []
for i in range(10):
result = processor(f"data_{i}")
snapshots.append(tracemalloc.take_snapshot())
if i > 0:
# 比较快照
stats = snapshots[i].compare_to(snapshots[i-1], 'lineno')
print(f"\n=== 第{i}次调用内存变化 ===")
for stat in stats[:5]: # 显示前5个变化最大的
print(f"{stat.traceback}: +{stat.size_diff/1024:.2f} KB")
# 获取顶级内存消耗
print("\n=== 内存消耗TOP 5 ===")
snapshot = tracemalloc.take_snapshot()
for stat in snapshot.statistics('lineno')[:5]:
print(f"{stat.traceback}: {stat.size/1024:.2f} KB")
tracemalloc.stop()
# 运行追踪
trace_memory_allocation()- 高级工具综合使用:结合多个工具进行深度分析:
python
from pympler import tracker, muppy, summary
import weakref
class DataProcessor:
"""数据处理类,可能存在泄漏"""
_cache = {} # 类变量缓存
def __init__(self):
self.data = []
self._tr = tracker.SummaryTracker() # 初始化跟踪器 [ref_1]
def process(self, item):
"""处理数据"""
# 将处理结果缓存到类变量
processed = item * 100
self._cache[id(item)] = processed # 缓存引用
# 添加到实例数据
self.data.append(processed)
return processed
def clear_cache(self):
"""清除缓存"""
self._cache.clear()
self.data.clear()
gc.collect()
def memory_report(self):
"""生成内存报告"""
print("\n=== Pympler 内存分析 ===")
# 1. 查看所有对象
all_objects = muppy.get_objects()
sum1 = summary.summarize(all_objects)
summary.print_(sum1)
# 2. 跟踪内存变化
print("\n内存变化跟踪:")
self._tr.print_diff()
# 3. 检查特定类型
print(f"\nDataProcessor实例数:",
len([o for o in all_objects if isinstance(o, DataProcessor)]))
print(f"缓存大小:", len(self._cache))
def comprehensive_analysis():
"""综合分析内存使用"""
# 创建处理器
processors = []
print("开始内存分析...")
for i in range(3):
proc = DataProcessor()
# 模拟数据处理
for j in range(1000):
proc.process(f"data_{i}_{j}")
processors.append(proc)
# 定期报告
if i % 2 == 0:
proc.memory_report()
# 尝试清除
print("\n尝试清除缓存...")
for proc in processors:
proc.clear_cache()
# 最终分析
print("\n清除后的内存状态:")
gc.collect()
all_objects = muppy.get_objects()
sum_final = summary.summarize(all_objects)
summary.print_(sum_final)
# 执行分析
comprehensive_analysis()C扩展开发
Python C扩展允许开发者使用C或C++编写代码,并将其编译为可以被Python直接导入和使用的动态链接库(如.so或.pyd文件)。核心目的是弥补Python在计算密集型任务上的性能劣势。常见的使用场景包括:
- 加速核心算法:例如科学计算、图像处理、密码学运算等循环密集的操作。
- 调用底层系统API:直接与操作系统或硬件交互。
- 集成现有C/C++库:复用成熟的、用C/C++编写的第三方库,无需重写。
- 内存与资源直接管理:实现对内存、文件句柄等资源的更精细控制。
主要实现方法对比
ython调用C/C++代码有多种技术路径,它们各有优缺点和适用场景。下表对主流方法进行了对比 :

性能优化关键点与陷阱
- 减少Python/C边界切换:每次在Python和C之间传递数据都有开销。最佳实践是在C扩展内处理整个数据块,避免在循环中频繁跨越边界 。
- 高效处理数组:对于数值计算,应使用array模块、bytes对象或(最佳选择)与NumPy的ndarray接口(通过PyArray_DATA宏)交互,避免使用Python列表的逐元素访问 。
- 内存管理:使用Python/C API时,必须严格遵守引用计数规则(Py_INCREF/Py_DECREF),否则会导致内存泄漏或解释器崩溃。Cython和pybind11能自动处理大部分引用计数。
- 全局解释器锁(GIL):默认情况下,C扩展代码会持有GIL。对于纯计算、无Python对象操作的代码,可以释放GIL(使用Py_BEGIN_ALLOW_THREADS和Py_END_ALLOW_THREADS宏),从而允许真正的多线程并行,大幅提升多核CPU利用率 。
- 错误处理:C函数必须通过设置Python异常(如PyErr_SetString)来向解释器报告错误,并确保函数返回NULL或适当的错误指示值。
选择建议与实践流程
- 明确需求:首先确认瓶颈是否真的在Python,并且是否必须用C扩展解决。有时优化算法、使用NumPy或Numba是更简单的选择。
- 选择工具:
- 快速调用现有库 -> ctypes / cffi
- 加速数值计算循环 -> Cython
- 封装现代C++库 -> pybind11
- 深入定制或学习底层机制 -> Python/C API
- 开发与测试:使用小规模数据编写原型,并利用cProfile等工具验证性能提升是否达到预期。
- 打包与分发:使用setuptools正确配置setup.py,确保扩展模块能在目标平台上正确编译和安装。跨平台编译(尤其是Windows)需要配置合适的编译器(如MSVC)和库路径 。