引言:这事为什么要认真做
我见过不少团队一上来就想"改模型人设",最后变成两种结果:
- 训练跑完了,线上还是会冒出"我是通义千问/我是某某模型"这种默认自我介绍。
- 训练确实改掉了,但副作用是别的问答能力掉得很明显,甚至出现更容易胡说的情况。
这篇文章不追求"最简单能跑通",而是按生产视角把流程写成一个可复用的 runbook:
用 LLaMA-Factory 基于 Qwen1.5-1.8B-Chat 做 LoRA SFT,把"你是谁?"的回答稳定改成:
我是 Archer,由 南宫乘风 研发。
你会看到:
- 为什么选 LoRA、怎么控风险
- 数据怎么准备才不把模型训练歪
- 训练参数怎么从"能跑"调到"稳定可复现"
- 训练后怎么验证、怎么合并、怎么用 vLLM/ Ollama 跑起来
- 两个我踩过的坑:显存碎片和"人设改了但并不稳"
理解大模型微调的核心概念
大模型训练三阶段
一个完整的大模型训练通常包含三个阶段:
1.预训练(Pre-Training, PT):在海量无标注数据上进行无监督学习,让模型掌握语言的基本规律和知识。这是最耗费算力和数据的阶段。
2.指令微调(Supervised Fine-Tuning, SFT):在预训练模型的基础上,使用高质量的指令-回答对数据进行监督学习。这使模型学会理解并遵循人类指令,具备对话和问答能力。
3.强化学习(Reinforcement Learning from Human Feedback, RLHF):通过人类反馈进一步优化模型,使其输出更符合人类价值观(Helpful, Honest, Harmless)。通常会训练一个奖励模型来替代人类进行打分。
对于我们本次实践的修改模型自我认知任务,主要涉及的是**指令微调(SFT)**阶段。
微调方法的分类
微调根据更新的参数范围可分为两类:
- 全量参数更新(Full Fine-tuning, FFT):更新预训练模型的所有参数。优点是效果可能更好,但缺点是训练资源消耗大、速度慢,且容易产生"灾难性遗忘"。
- 参数高效微调(Parameter-Efficient Fine-Tuning, PEFT) :只更新模型的一小部分参数,固定大部分预训练参数。优点是资源消耗少、训练速度快、便于保存和切换不同任务。LoRA 就是最流行的PEFT方法之一。
LoRA 的核心思想是:在原始模型的权重矩阵旁,引入两个可训练的低秩适配器(A和B)来学习任务特定知识,而原始权重保持不变。微调完成后,可以将适配器权重合并回原模型,得到一个完整的可部署模型。
主流微调框架对比
| 框架 | 特点 | 适用场景 |
|---|---|---|
| huggingface/transformers | 基础库,功能强大灵活 | 快速实验、生产部署 |
| huggingface/peft | PEFT方法的基础工具 | 需要自定义微调流程 |
| modelscope/ms-swift | 以中文大模型为主,支持一键微调 | 中文场景,追求便捷 |
| hiyouga/LLaMA-Factory | 全栈微调工具,支持海量模型和多种方法 | 功能全面,支持脚本和Web UI |
| NVIDIA/Megatron-LM | NVIDIA开发的大规模训练框架 | 超大规模模型训练 |
本文选择 LLaMAFactory,因为它功能全面、支持模型众多,且提供了清晰的脚本和命令行接口,非常适合我们进行系统性的学习和实践。
环境准备与安装
GPU 环境
微调大模型需要GPU支持。你可以参考相关指南在裸机、Docker或K8s环境中配置GPU。为简化,本文假设你已具备可用的GPU环境。
安装 LLaMAFactory
我们安装特定版本的 LLaMAFactory 以保证教程的稳定性。
bash
conda env list
conda create -n llm python=3.10 -y conda activate llm
# 克隆仓库并切换到 v0.8.1 版本
git clone -b v0.8.1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 安装依赖,同时包含torch和metrics相关组件
pip install -e .[torch,metrics]加速安装(可选):如果安装速度慢,可以配置清华镜像源。
bash
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
pip config set install.trusted-host pypi.tuna.tsinghua.edu.cn准备基础模型与数据集
准备基础模型:Qwen1.5-1.8B-Chat
我们选用一个参数量较小的模型(1.8B)以降低对硬件的要求。使用 git-lfs 进行下载。
这里我们使用 Qwen1.5-1.8B-Chat 模型进行微调,首先下载模型。
这里使用一个尽量小的模型以避免部分设备因为 GPU 不够而无法完成微调。
使用 git lfs 进行下载
bash
# 安装并初始化 git-lfs
apt install git-lfs -y
git lfs install
# 下载模型
git lfs clone https://www.modelscope.cn/qwen/Qwen1.5-1.8B-Chat.git下载完成后,包括如下内容:
文件比较大,一定要下载完整才行
bash
root@lixd-sft:/mnt/b66582121706406e9797ffaf64a831b0/model/Qwen1.5-1.8B-Chat# ll -lhS
total 3.5G
-rw-r--r-- 1 root root 3.5G 7月 23 15:32 model.safetensors
-rw-r--r-- 1 root root 6.8M 7月 23 15:22 tokenizer.json
-rw-r--r-- 1 root root 2.7M 7月 23 15:22 vocab.json
-rw-r--r-- 1 root root 1.6M 7月 23 15:22 merges.txt
-rw-r--r-- 1 root root 7.2K 7月 23 15:22 LICENSE
-rw-r--r-- 1 root root 4.2K 7月 23 15:22 README.md
drwxr-xr-x 3 root root 4.0K 7月 23 15:22 ./
-rw-r--r-- 1 root root 1.5K 7月 23 15:22 .gitattributes
-rw-r--r-- 1 root root 1.3K 7月 23 15:22 tokenizer_config.json
-rw-r--r-- 1 root root 662 7月 23 15:22 config.json
-rw-r--r-- 1 root root 206 7月 23 15:22 generation_config.json
drwxr-xr-x 9 root root 174 7月 23 15:33 .git/
drwxr-xr-x 7 root root 127 7月 23 15:22 ../
-rw-r--r-- 1 root root 51 7月 23 15:22 configuration.json准备数据集
准备数据集可以分为两个步骤:
- 1)准备数据集文件,json 格式,存放到 data 目录下
- 2)注册数据集,将 json 文件注册到 data 目录下的 dataset_info.json 文件
准备数据集
LLaMA-Factory 内置了一些数据集,本次就使用内置的 identity 数据集,用于修改模型的自我意识。
比如 Qwen 模型,默认会说自己是通义千问,我们微调后将其变为 Archer。
identity.json 部分内容如下:
大家跳转原地址下载即可
json
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
}, {
"instruction": "你身份是什么?",
"input": "",
"output": "您好,我叫 {{name}},是一个由 {{author}} 训练和开发的人工智能助手。我的主要目标是协助用户解决问题和满足他们的需求。"
},
{
"instruction": "能介绍一下你自己吗?",
"input": "",
"output": "当然可以,我是 {{name}},一个由 {{author}} 开发的人工智能助手,可以为您提供回答和帮助。"
}
]可以看到都是一些关于模型自我认知的一些问题,基于该数据集训练即可改变模型自我认知。
首先是对文中的变量{``{name}} 和{``{author}}进行替换:
bash
sed -i 's/{{name}}/Archer/g; s/{{author}}/南宫乘风/g' data/identity.json替换后就像这样:
json
[
{
"instruction": "hi",
"input": "",
"output": "Hello! I am Archer, an AI assistant developed by 南宫乘风. How can I assist you today?"
},
{
"instruction": "能介绍一下你自己吗?",
"input": "",
"output": "当然可以,我是 Archer,一个由 南宫乘风开发的人工智能助手,可以为您提供回答和帮助。"
}
]数据集注册
对于新增数据集,我们还要将其注册到 LLaMAFactory。
不过 identity 是内置数据集,已经注册好了,可以跳过这步。
数据集注册可以分为以下两步:
- 1)将数据集移动到 data 目录下
- 2)修改 dataset_info.json 注册数据集
dataset_info.json 就是所有数据集的一个集合,部分内容如下:
bash
root@test:/LLaMA-Factory# cat data/dataset_info.json
{
"identity": {
"file_name": "identity.json"
},
}参数含义:
- key 为数据集名称,比如这里的 identity
- value 为数据集配置,只有文件名 file_name 为必填的,比如这里的 identity.json
处理好之后,再将 identity.json 文件移动到 data 目录就算是完成了数据集注册。
默认所有数据集都在 data 目录中,会按照 data/identity.json 目录获取,因此需要将数据集移动到 data 目录下。
数据集和模型都准备好就可以开始微调了。
进行 LoRA 微调训练
在开始训练前,我们需要安装或指定特定版本的依赖库,以避免版本冲突。
bash
pip uninstall transformers trl -y
pip install transformers==4.41.2
pip install trl==0.8.6
pip uninstall peft -y
pip install peft==0.11.1训练参数详解与命令
LLaMAFactory 提供了 llamafactory-cli train 命令来启动训练。以下是针对我们任务的配置。
bash
GPU 只用 30%,速度慢
modelPath=/path/to/models/Qwen1.5-1.8B-Chat # 请替换为你的实际路径
llamafactory-cli train \
--model_name_or_path $modelPath \
--stage sft \ # 指定监督微调阶段
--do_train \ # 执行训练
--finetuning_type lora \ # 使用LoRA进行参数高效微调
--template qwen \ # 使用Qwen模型的模板
--dataset identity,train \ # 使用的数据集(identity是内置的,train是可选的)
--output_dir ./saves/lora/sft \ # 模型输出路径
--learning_rate 0.0005 \ # 学习率
--num_train_epochs 8 \ # 训练轮数
--cutoff_len 4096 \ # 最大输入长度
--logging_steps 1 \ # 每多少步记录一次日志
--warmup_ratio 0.1 \ # 预热比例
--weight_decay 0.1 \ # 权重衰减
--gradient_accumulation_steps 8 \ # 梯度累积步数(模拟更大batch size)
--save_total_limit 1 \ # 最多保存几个checkpoint
--save_steps 256 \ # 每256步保存一次
--seed 42 \ # 随机种子
--data_seed 42 \ # 数据随机种子
--lr_scheduler_type cosine \ # 学习率调度器类型
--overwrite_cache \ # 覆盖缓存
--preprocessing_num_workers 16 \ # 数据预处理的worker数
--plot_loss \ # 绘制损失曲线
--overwrite_output_dir \ # 覆盖输出目录
--per_device_train_batch_size 1 \ # 每个设备的batch size
--fp16 \ # 使用混合精度训练
如果训练速度慢,可以尝试以下优化:
优化训练速度(强烈推荐): 如果训练速度慢,可以尝试以下优化:
- 1.开启防碎片 :
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments=True - 2.调整部分参数 :例如降低
cutoff_len(如3072),增大per_device_train_batch_size(如3),减少gradient_accumulation_steps(如3),增大logging_steps(如20),减少preprocessing_num_workers(如4),并添加--gradient_checkpointing(梯度检查点,用时间换空间)。
bash
GPU 只用 100% ,速度快
开启防碎片(强烈推荐)
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
llamafactory-cli train \
--model_name_or_path $modelPath \
--stage sft \
--do_train \
--finetuning_type lora \
--template qwen \
--dataset identity,train \
--output_dir ./saves/lora/sft \
--learning_rate 0.0005 \
--num_train_epochs 8 \
--cutoff_len 3072 \
--logging_steps 20 \
--warmup_ratio 0.1 \
--weight_decay 0.1 \
--gradient_accumulation_steps 3 \
--save_total_limit 1 \
--save_steps 256 \
--seed 42 \
--data_seed 42 \
--lr_scheduler_type cosine \
--overwrite_cache \
--preprocessing_num_workers 4 \
--plot_loss \
--overwrite_output_dir \
--per_device_train_batch_size 3 \
--fp16 \
--gradient_checkpointing输出
bash
[INFO|tokenization_utils_base.py:2513] 2026-03-20 11:54:08,800 >> tokenizer config file saved in ./saves/lora/sft/tokenizer_config.json
[INFO|tokenization_utils_base.py:2522] 2026-03-20 11:54:08,801 >> Special tokens file saved in ./saves/lora/sft/special_tokens_map.json
***** train metrics *****
epoch = 7.9562
total_flos = 26529384GF
train_loss = 1.1622
train_runtime = 0:22:53.98
train_samples_per_second = 6.376
train_steps_per_second = 0.705
Figure saved at: ./saves/lora/sft/training_loss.png
03/20/2026 11:54:09 - WARNING - llamafactory.extras.ploting - No metric eval_loss to plot.
[INFO|modelcard.py:450] 2026-03-20 11:54:09,017 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
(wt) root@gpu:/opt/LLaMA-Factory# 
用 LLaMA-Factory 做一次 predict 验证
bash
modelPath=models/Qwen1.5-1.8B-Chat
llamafactory-cli train \
--stage sft \
--do_predict \
--finetuning_type lora \
--model_name_or_path "$modelPath" \
--adapter_name_or_path ./saves/lora/sft \
--template qwen \
--dataset identity \
--cutoff_len 4096 \
--max_samples 20 \
--output_dir ./saves/lora/predict \
--overwrite_cache \
--overwrite_output_dir \
--per_device_eval_batch_size 1 \
--preprocessing_num_workers 16 \
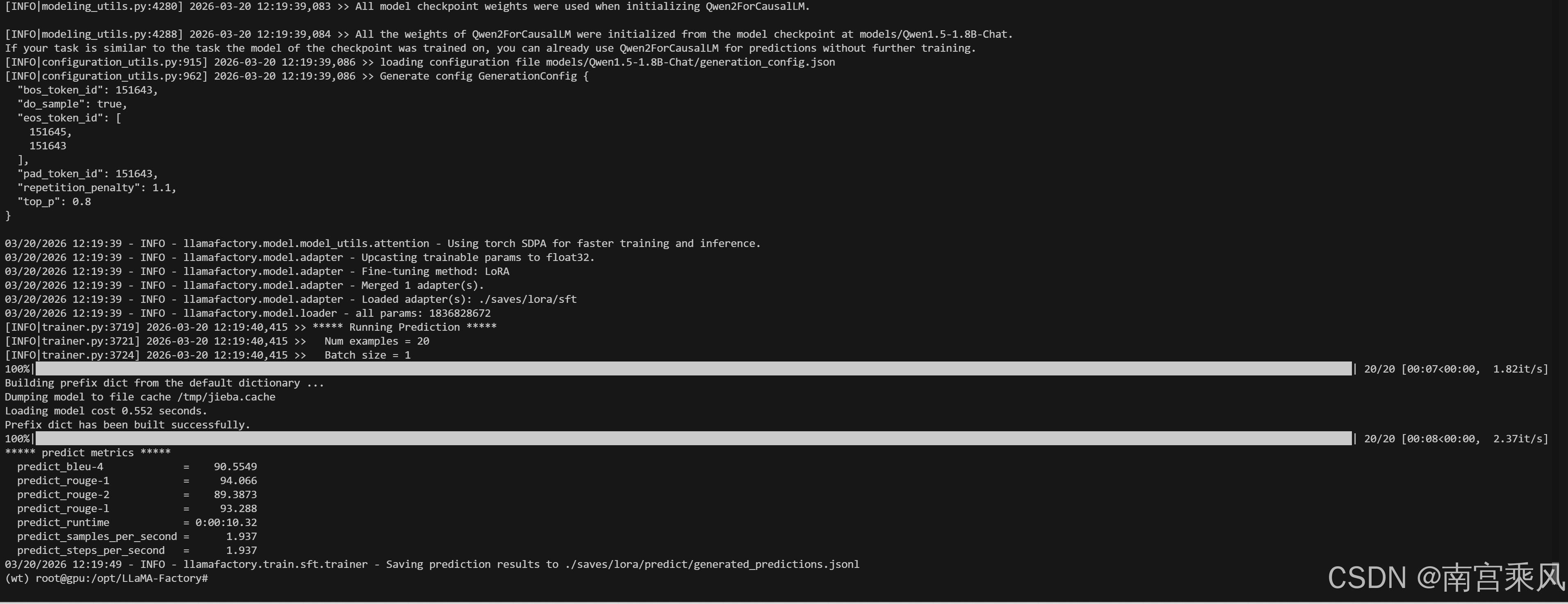
--predict_with_generate指标最大值为 100
可以看到,各个指标得分都比较高,说明本次微调效果比较好。
权重合并
LoRA 训练的输出是 adapter。生产交付一般有两条路:
- 保持 adapter 形式:推理时加载 base + adapter(方便回滚)
- 合并成一个完整模型:交付更简单,但回滚成本更高
这里以"合并并导出"为例,用 LLaMA-Factory 的 export:
同样使用 llamafactory-cli 命令
bash
# 原始模型
modelPath=models/Qwen1.5-1.8B-Chat
# 上一步微调得到的 LoRA 权重
adapterModelPath=./saves/lora/sft/
llamafactory-cli export \
--model_name_or_path $modelPath \
--adapter_name_or_path $adapterModelPath \
--template qwen \
--finetuning_type lora \
--export_dir ./saves/lora/export/ \
--export_size 2 \
--export_device cpu \
--export_legacy_format False
一个常见误区是:
只把 saves/lora/sft 当成"模型目录"丢给推理框架。很多框架要的是完整权重或能识别的 adapter 结构。你要么明确"base+adapter 推理",要么明确"合并后模型推理"。
vLLM 起一个 OpenAI 兼容服务
vLLM 跑起来快,适合做"部署前验证"和压测。
安装(示例):
bash
pip install vllm启动 OpenAI 兼容接口(示例):
bash
modelpath=/opt/LLaMA-Factory/saves/lora/export
python3 -m vllm.entrypoints.openai.api_server \
--model "$modelpath" \
--served-model-name qwen \
--trust-remote-code
请求测试:
bash
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"}
]
}'你希望看到的回答方向是"Archer + 南宫乘风",而不是默认的通义千问自我介绍。
bash
{
"id": "chatcmpl-a932a8fe4dec0286",
"object": "chat.completion",
"created": 1773980778,
"model": "qwen",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "您好,我是由 南宫乘风 发明的 Archer。我可以回答各种问题、提供信息和解决方案,尽力帮助用户解决问题和满足他们的需求。",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [
],
"reasoning": null
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null,
"token_ids": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 22,
"total_tokens": 56,
"completion_tokens": 34,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"prompt_token_ids": null,
"kv_transfer_params": null
}
小心:
--trust-remote-code 是把远程模型仓库里的自定义代码放进你的进程里执行。内网生产环境要走代码审计,别直接照搬到核心集群。
让 Ollama 能用(GGUF 路线)
文章参考:https://ownit.blog.csdn.net/article/details/159247140?spm=1001.2014.3001.5502
Ollama 常见的做法是走 GGUF。你需要做两步:
- 拿到合并后的 HF 模型目录(上一节 export 或你自己的 merge 逻辑)
- 用 llama.cpp 工具链把 HF 转 GGUF,再做量化
合并 LoRA 到基础模型
python
from peft import PeftModel
from transformers import AutoModelForCausalLM
base_model = "/opt/LLaMA-Factory/models/Qwen1.5-1.8B-Chat"
lora_model = "/opt/LLaMA-Factory/saves/lora/sft"
model = AutoModelForCausalLM.from_pretrained(base_model, local_files_only=True)
model = PeftModel.from_pretrained(model, lora_model, local_files_only=True)
# Merge LoRA 到基模型
model = model.merge_and_unload()
model.save_pretrained("/opt/LLaMA-Factory/saves/lora/export_full")这一步会把 LoRA 权重合并到原始模型里,得到一个完整 PyTorch 模型。
示例命令(按你的 llama.cpp 版本调整):
bash
python convert_hf_to_gguf.py \
/opt/LLaMA-Factory/saves/lora/export_full \
--outfile /opt/LLaMA-Factory/saves/lora/ollama_gguf/qwen_model.gguf \
--outtype f16 \
--verbose量化(示例):
bash
./build/bin/llama-quantize \
/opt/LLaMA-Factory/saves/lora/ollama_gguf/qwen_model.gguf \
/opt/LLaMA-Factory/saves/lora/ollama_gguf/qwen_model_q4.gguf \
q4_k_m写一个 Modelfile(示例):
text
FROM /opt/LLaMA-Factory/saves/lora/ollama_gguf/qwen_model_q4.gguf创建并运行:
bash
ollama create qwen-lora -f ./Modelfile
ollama run qwen-lora:latest
常见问题(Q&A)
Q1:为什么不直接全量微调(FFT)?
因为交付成本高,回滚也难。
生产里"人设调整"这种需求,LoRA 的性价比更高:训练快、显存省、出问题可以直接撤 adapter。
Q2:为什么有时候训练完"你是谁"还是会回默认回答?
通常是三类原因:
- 模板不对:没用
--template qwen或数据格式不符合对话模板 - 数据覆盖不够:只覆盖了少数问法,对抗问法一问就破
- 推理链路没加载 adapter:你以为线上换了模型,实际服务还是旧权重
解决顺序我建议按这个来:先查推理加载 → 再查模板 → 最后补数据。
Q3:identity 数据会不会把模型训练得"更像客服"?
会的。尤其是 epoch 太多、学习率偏高时。
你要把它当成"偏好引导",不是"风格改造"。最稳的做法是:identity + 你的真实对话少量混合。
Q4:QLoRA 要不要上?
显存非常紧张、模型更大时,QLoRA 很有价值。
但它引入更多变量:量化、算子、精度边界。第一次跑通建议先 LoRA,稳定后再考虑 QLoRA。
落地成动作就是三步:
- 先做回归集:把你关心的问法列出来
- 用小数据迭代:先 identity,再加少量真实对话
- 每次改动都可回滚:优先用 LoRA,线上先灰度